Beyond Static Priors: Dynamic Neural Guidance for Large-Scale Ant Colony Optimization
Pith reviewed 2026-06-28 07:48 UTC · model grok-4.3
The pith
DyNACO replaces static neural priors with periodic observations of pheromone and incumbent solutions to guide ACO on large TSP and CVRP instances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
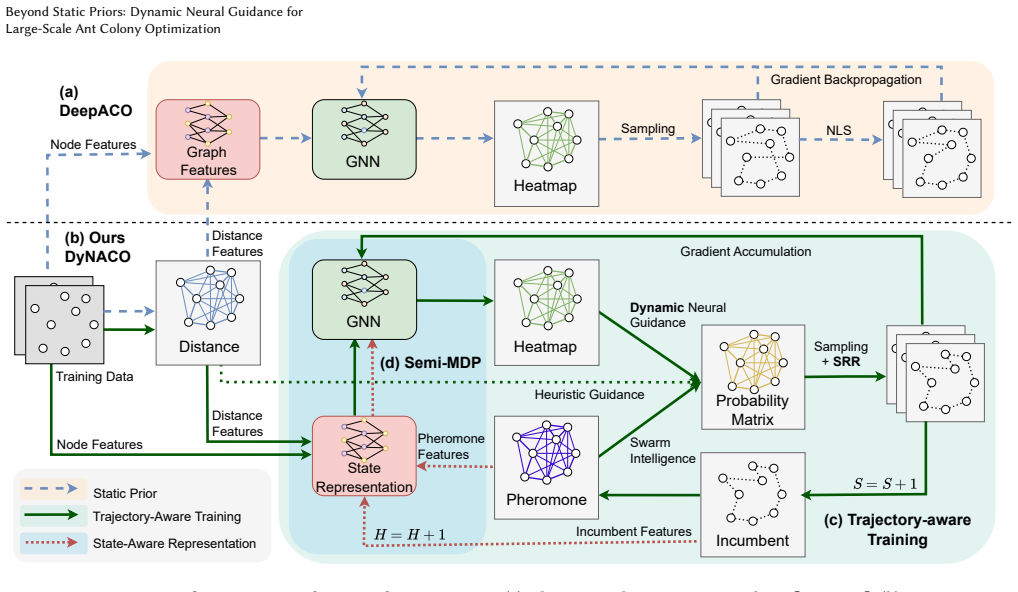
DyNACO achieves dynamic neural guidance for ACO by periodically feeding the pheromone matrix and incumbent tour into a policy network, then uses a perturbation-based backend and scope-restricted refinement to maintain efficacy and stable credit assignment; the resulting solver scales to 100,000-node TSP instances while outperforming neural baselines and frequently running faster than unguided ACO, and extends to capacity-aware CVRP with negligible overhead.
What carries the argument
Dynamic policy that takes pheromone distribution and incumbent solution as input at regular intervals, paired with perturbation-based ACO backend and scope-restricted refinement for credit assignment.
If this is right
- ACO can be guided by live search state rather than fixed heatmaps without losing scalability.
- The same dynamic-guidance pattern transfers from TSP to CVRP via a capacity-aware backend.
- Neural overhead stays below 1 percent while still improving the unguided baseline on both problems.
- Generalization holds across instance sizes because the policy sees actual pheromone and solution states during search.
Where Pith is reading between the lines
- The same observation-and-refine loop could be tested on other iterative solvers such as local search or evolutionary algorithms.
- If credit assignment remains stable, the approach might reduce the need for separate training phases that match the exact search horizon.
- Periodic rather than continuous guidance suggests a tunable trade-off between neural cost and solution quality that could be measured on other combinatorial domains.
Load-bearing premise
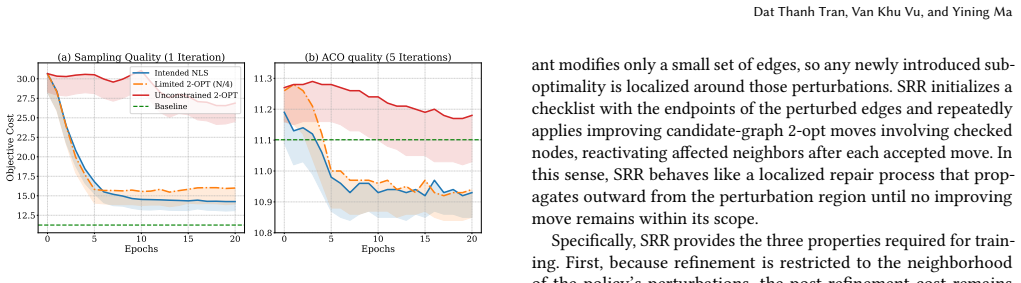
The perturbation-based ACO backend and scope-restricted refinement together keep the dynamic policy effective and credit assignment stable at large scale.
What would settle it
Run the same policy on 100,000-node TSP instances after removing either the periodic observation step or the perturbation backend and measure whether solution quality or runtime advantage disappears.
Figures
read the original abstract
Neural-guided Ant Colony Optimization (ACO) suffers from a fundamental training-inference misalignment: policies are typically trained to generate static priors (e.g., heatmaps), yet deployed to guide iterative, long-horizon search processes. In this paper, we present DyNACO, a novel framework that achieves dynamic neural guidance by periodically observing the pheromone distribution and the incumbent solution. To make DyNACO tractable at scale, we pair the policy with a perturbation-based ACO backend and a scope-restricted refinement mechanism that jointly ensure efficacy and stable credit assignment. On TSP, DyNACO scales to 100,000-node instances and outperforms neural baselines while often reducing total runtime compared to the unguided solver. We extend DyNACO to CVRP via a capacity-aware backend, consistently improving the unguided baseline with less than 1% neural overhead. We further provide in-depth analysis validating the model's generalization capabilities and elucidating why dynamic guidance outperforms static priors. Our work underscores the necessity of aligning neural training with iterative search dynamics in learning-guided optimization. The code is available at https://github.com/shoraaa/DyNACO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DyNACO, a framework for dynamic neural guidance in ACO that periodically observes pheromone distributions and incumbent solutions to correct the training-inference misalignment of static-prior policies. It pairs the learned policy with a perturbation-based ACO backend and a scope-restricted refinement mechanism claimed to ensure efficacy and stable credit assignment, enabling scaling to 100k-node TSP instances with outperformance over neural baselines and frequent runtime reductions versus the unguided solver; the approach is extended to CVRP via a capacity-aware backend with <1% neural overhead, accompanied by generalization analysis.
Significance. If the dynamic guidance and stable credit assignment hold at the claimed scales, the work would meaningfully advance learning-guided combinatorial optimization by aligning policy training with iterative search dynamics rather than static priors. The public code release supports reproducibility and is a clear strength.
major comments (1)
- [Abstract] Abstract: the central claim that the perturbation-based ACO backend and scope-restricted refinement 'jointly ensure efficacy and stable credit assignment' is load-bearing for the 100k-node scaling, outperformance, and runtime-reduction results, yet the manuscript provides no explicit metric, ablation, or analysis (e.g., gradient variance, policy-update consistency, or sensitivity to pheromone noise) quantifying assignment stability on the largest instances.
minor comments (1)
- The abstract states that 'in-depth analysis' validates generalization and explains dynamic vs. static superiority, but the summary does not indicate the corresponding section or figures where these results appear.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit quantification of credit assignment stability, which is central to our scaling claims. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the perturbation-based ACO backend and scope-restricted refinement 'jointly ensure efficacy and stable credit assignment' is load-bearing for the 100k-node scaling, outperformance, and runtime-reduction results, yet the manuscript provides no explicit metric, ablation, or analysis (e.g., gradient variance, policy-update consistency, or sensitivity to pheromone noise) quantifying assignment stability on the largest instances.
Authors: We agree that an explicit metric would strengthen the manuscript. The empirical scaling to 100k nodes and runtime reductions provide indirect evidence of stability, but we will add a new subsection with ablations measuring gradient variance and policy-update consistency on instances up to 100k nodes, including sensitivity analysis to pheromone noise. This will directly quantify the contribution of the perturbation-based backend and scope-restricted refinement to stable credit assignment. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks
full rationale
The paper describes a framework pairing a dynamic policy with a perturbation-based ACO backend and scope-restricted refinement, asserting that these jointly ensure stable credit assignment. This is presented as an engineering choice enabling scalability, not as a derivation or prediction that reduces to its own inputs by construction. No equations, fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatz smuggling appear in the provided text. Central claims (scaling to 100k-node TSP, outperformance vs. baselines, runtime reduction) are supported by empirical comparisons to unguided solvers and neural baselines, with code released for reproduction. The design assertion about credit assignment is falsifiable via the stated ablations and metrics, not self-referential.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sohel Rahman, and Md Adnan Arefeen
Abrar Rahman Abir, Muhammad Ali Nayeem, M. Sohel Rahman, and Md Adnan Arefeen. 2025. GTG-ACO: Graph Transformer Guided Ant Colony Optimization for learning heuristics and pheromone dynamics for combinatorial optimization. Swarm and Evolutionary Computation99 (12 2025). doi:10.1016/j.swevo.2025. 102147
-
[2]
A Amuthan and K Deepa Thilak. 2017. Improved Ant Colony Algorithms for Eliminating Stagnation and Local Optimum Problem — A Survey. In2017 Interna- tional Conference on Technical Advancements in Computers and Communications (ICTACC). 97–101. doi:10.1109/ICTACC.2017.33 Dat Thanh Tran, Van Khu Vu, and Yining Ma
-
[3]
Federico Berto, Chuanbo Hua, Junyoung Park, Laurin Luttmann, Yining Ma, Fanchen Bu, Jiarui Wang, Haoran Ye, Minsu Kim, Sanghyeok Choi, Nayeli Gast Zepeda, André Hottung, Jianan Zhou, Jieyi Bi, Yu Hu, Fei Liu, Hyeonah Kim, Jiwoo Son, Haeyeon Kim, Davide Angioni, Wouter Kool, Zhiguang Cao, Qingfu Zhang, Joungho Kim, Jie Zhang, Kijung Shin, Cathy Wu, Sungsoo...
-
[4]
Darren Chitty. 2018. Applying ACO to Large Scale TSP Instances. InAdvances in Intelligent Systems and Computing, Vol. 650. 104–118. doi:10.1007/978-3-319- 66939-7_9
-
[5]
Paulo da Costa, Jason Rhuggenaath, Yingqian Zhang, Alp Akcay, and Uzay Kay- mak. 2021. Learning 2-Opt Heuristics for Routing Problems via Deep Reinforce- ment Learning.SN Computer Science2 (2021), 388. Issue 5. doi:10.1007/s42979- 021-00779-2
-
[6]
2019.Ant colony optimization: overview and recent advances
Marco Dorigo and Thomas Stützle. 2019.Ant colony optimization: overview and recent advances. Springer
2019
-
[7]
Darko Drakulic, Sofia Michel, Florian Mai, Arnaud Sors, and Jean-Marc Andreoli
-
[8]
InProceedings of the 37th International Conference on Neural Information Processing Systems(Red Hook, NY, USA)
BQ-NCO: bisimulation quotienting for efficient neural combinatorial opti- mization. InProceedings of the 37th International Conference on Neural Information Processing Systems(Red Hook, NY, USA). Curran Associates Inc
-
[9]
Han Fang, Zhihao Song, Paul Weng, and Yutong Ban. 2024. INViT: a generalizable routing problem solver with invariant nested view transformer. InProceedings of the 41st International Conference on Machine Learning. JMLR.org
2024
-
[10]
Zhang-Hua Fu, Kai-Bin Qiu, and Hongyuan Zha. 2021. Generalize a small pre-trained model to arbitrarily large tsp instances. InProceedings of the AAAI conference on artificial intelligence, Vol. 35. 7474–7482
2021
-
[11]
2019.Exact combinatorial optimization with graph convolutional neural networks
Maxime Gasse, Didier Chételat, Nicola Ferroni, Laurent Charlin, and Andrea Lodi. 2019.Exact combinatorial optimization with graph convolutional neural networks. Curran Associates Inc
2019
-
[12]
Michael Guntsch and Martin Middendorf. 2002. A population based approach for ACO. InApplications of Evolutionary Computing: EvoWorkshops 2002: EvoCOP, EvoIASP, EvoSTIM/EvoPLAN Kinsale, Ireland, April 3–4, 2002 Proceedings. Springer, 72–81
2002
-
[13]
Keld Helsgaun. 2000. An effective implementation of the Lin–Kernighan traveling salesman heuristic.European Journal of Operational Research126 (10 2000), 106–
2000
-
[14]
doi:10.1016/S0377-2217(99)00284-2
Issue 1. doi:10.1016/S0377-2217(99)00284-2
- [15]
-
[16]
Taoan Huang, Aaron M Ferber, Arman Zharmagambetov, Yuandong Tian, and Bistra Dilkina. 2024. Contrastive Predict-and-Search for Mixed Integer Linear Programs. https://openreview.net/forum?id=J2kRjUAOLh
2024
-
[17]
Minsu Kim, Sanghyeok Choi, Hyeonah Kim, Jiwoo Son, Jinkyoo Park, and Yoshua Bengio. 2025. Ant Colony Sampling with GFlowNets for Combinatorial Optimiza- tion.Proceedings of Machine Learning Research258 (2025), 469–477. Publisher Copyright: Copyright 2025 by the author(s).; 28th International Conference on Artificial Intelligence and Statistics, AISTATS 2025
2025
-
[18]
Wouter Kool, Herke van Hoof, and Max Welling. 2019. Attention, Learn to Solve Routing Problems!. InInternational Conference on Learning Representations. https://openreview.net/forum?id=ByxBFsRqYm
2019
-
[19]
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. 2020. POMO: policy optimization with multiple optima for reinforcement learning. InProceedings of the 34th International Conference on Neural Information Processing Systems(Red Hook, NY, USA). Curran Associates Inc
2020
-
[20]
Sirui Li, Zhongxia Yan, and Cathy Wu. 2021. Learning to delegate for large-scale vehicle routing. InProceedings of the 35th International Conference on Neural Information Processing Systems(Red Hook, NY, USA). Curran Associates Inc
2021
- [21]
-
[22]
Fu Luo, Xi Lin, Fei Liu, Qingfu Zhang, and Zhenkun Wang. 2023. Neural combi- natorial optimization with heavy decoder: toward large scale generalization. In Proceedings of the 37th International Conference on Neural Information Processing Systems(Red Hook, NY, USA). Curran Associates Inc
2023
-
[23]
Fu Luo, Xi Lin, Yaoxin Wu, Zhenkun Wang, Tong Xialiang, Mingxuan Yuan, and Qingfu Zhang. 2025. Boosting Neural Combinatorial Optimization for Large- Scale Vehicle Routing Problems. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=TbTJJNjumY
2025
-
[24]
Fu Luo, Xi Lin, Mengyuan Zhong, Fei Liu, Zhenkun Wang, Jianyong Sun, and Qingfu Zhang. 2025. Learning to Insert for Constructive Neural Vehicle Routing Solver. InNeural Information Processing Systems
2025
-
[25]
Yining Ma, Zhiguang Cao, and Yeow Meng Chee. 2023. Learning to search feasible and infeasible regions of routing problems with flexible neural k-opt. In Proceedings of the 37th International Conference on Neural Information Processing Systems(Red Hook, NY, USA). Curran Associates Inc
2023
-
[26]
Martínez and José M
Pablo A. Martínez and José M. García. 2021. ACOTSP-MF: A memory-friendly and highly scalable ACOTSP approach.Engineering Applications of Artificial Intelligence99 (2021), 104131
2021
-
[27]
2010.Traveling sales- man problem: an overview of applications, formulations, and solution approaches
Rajesh Matai, Surya Prakash Singh, and Murari Lal Mittal. 2010.Traveling sales- man problem: an overview of applications, formulations, and solution approaches. Vol. 1. InTech Rijeka, 1–25
2010
-
[28]
Nina Mazyavkina, Sergey Sviridov, Sergei Ivanov, and Evgeny Burnaev. 2021. Reinforcement learning for combinatorial optimization: A survey.Computers & Operations Research134 (10 2021), 105400. doi:10.1016/J.COR.2021.105400
-
[29]
Yimeng Min, Yiwei Bai, and Carla P. Gomes. 2023. Unsupervised learning for solving the travelling salesman problem. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 2047, 15 pages
2023
-
[30]
Wenbin Ouyang, Sirui Li, Yining Ma, and Cathy Wu. 2026. Learning to Seg- ment for Vehicle Routing Problems. InInternational Conference on Learning Representations
2026
-
[31]
Xuanhao Pan, Yan Jin, Yuandong Ding, Mingxiao Feng, Li Zhao, Lei Song, and Jiang Bian. 2023. H-TSP: hierarchically solving the large-scale traveling sales- man problem. InProceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on...
-
[32]
Jonathan Pirnay and Dominik G Grimm. 2024. Self-Improvement for Neural Combinatorial Optimization: Sample Without Replacement, but Improvement. Transactions on Machine Learning Research(2024). https://openreview.net/ forum?id=agT8ojoH0X Featured Certification
2024
-
[33]
Ruizhong Qiu, Zhiqing Sun, and Yiming Yang. 2022. DIMES: a differentiable meta solver for combinatorial optimization problems. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’22). Curran Associates Inc., Red Hook, NY, USA, Article 1851, 16 pages
2022
-
[34]
Gerhard Reinelt. 1991. TSPLIB - A Traveling Salesman Problem Library.INFORMS J. Comput.3 (1991), 376–384
1991
- [35]
-
[36]
Thomas Stützle and Holger H. Hoos. 2000. MAX–MIN Ant System.Future Generation Computer Systems16 (6 2000), 889–914. Issue 8. doi:10.1016/S0167- 739X(00)00043-1
-
[37]
Zhiqing Sun and Yiming Yang. 2023. DIFUSCO: graph-based diffusion solvers for combinatorial optimization. InProceedings of the 37th International Conference on Neural Information Processing Systems(Red Hook, NY, USA). Curran Associates Inc
2023
-
[38]
Eduardo Uchoa, Diego Pecin, Artur Pessoa, Marcus Poggi, Thibaut Vidal, and Anand Subramanian. 2017. New benchmark instances for the Capacitated Vehicle Routing Problem.European Journal of Operational Research257 (3 2017), 845–858. Issue 3. doi:10.1016/J.EJOR.2016.08.012
-
[39]
Thibaut Vidal. 2022. Hybrid genetic search for the CVRP: Open-source imple- mentation and SWAP* neighborhood.Computers & Operations Research140 (4 2022), 105643. doi:10.1016/J.COR.2021.105643
-
[40]
Liang Xin, Wen Song, Zhiguang Cao, and Jie Zhang. 2021. NeuroLKH: combin- ing deep learning model with lin-kernighan-helsgaun heuristic for solving the traveling salesman problem. InProceedings of the 35th International Conference on Neural Information Processing Systems(Red Hook, NY, USA). Curran Associates Inc
2021
-
[41]
Haoran Ye, Jiarui Wang, Zhiguang Cao, Helan Liang, and Yong Li. 2023. DeepACO: neural-enhanced ant systems for combinatorial optimization. InProceedings of the 37th International Conference on Neural Information Processing Systems(Red Hook, NY, USA). Curran Associates Inc
2023
-
[42]
Haoran Ye, Jiarui Wang, Helan Liang, Zhiguang Cao, Yong Li, and Fanzhang Li
-
[43]
GLOP: learning global partition and local construction for solving large- scale routing problems in real-time. InProceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence. AAAI Pres...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.