POLARIS: Guiding Small Models to Write Long Stories
Pith reviewed 2026-06-28 10:14 UTC · model grok-4.3
The pith
POLARIS trains a 9B model with LLM-judge rewards and human anchors to match larger models on long stories while generalizing beyond training lengths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
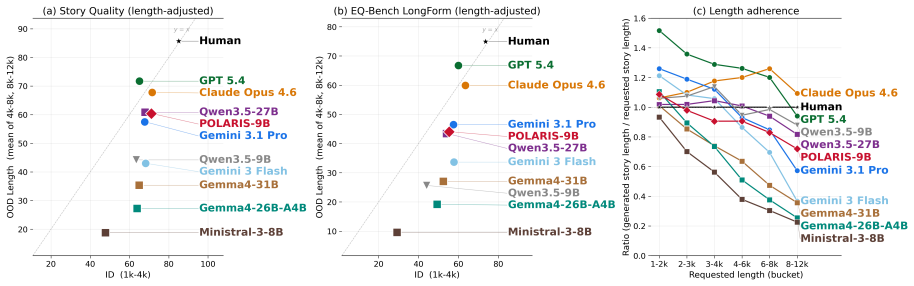
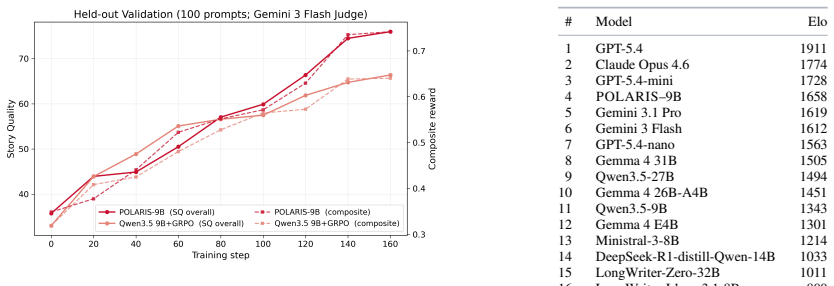
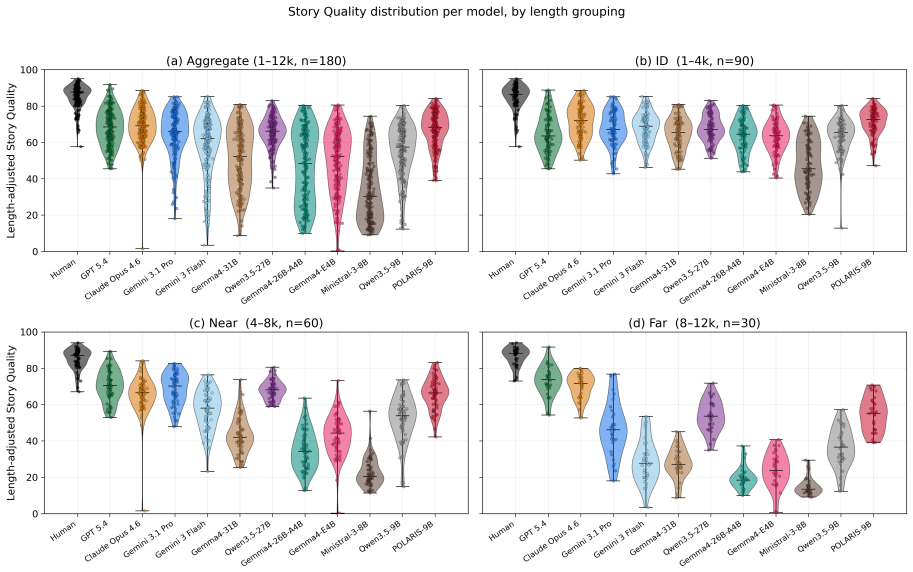
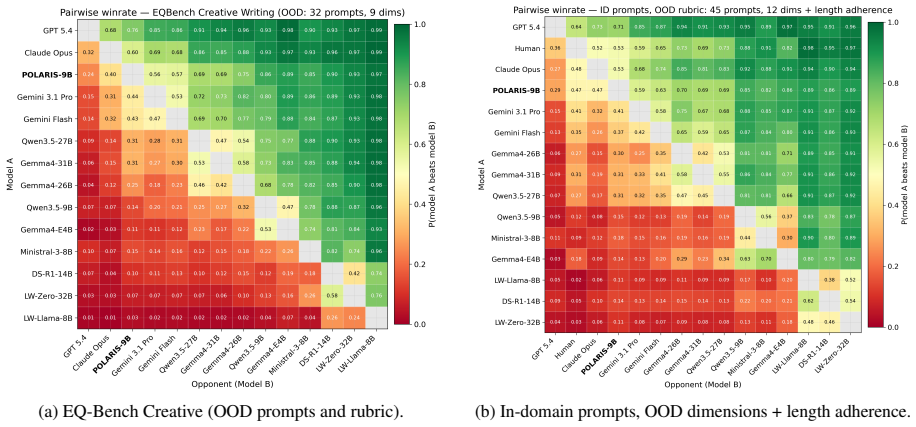
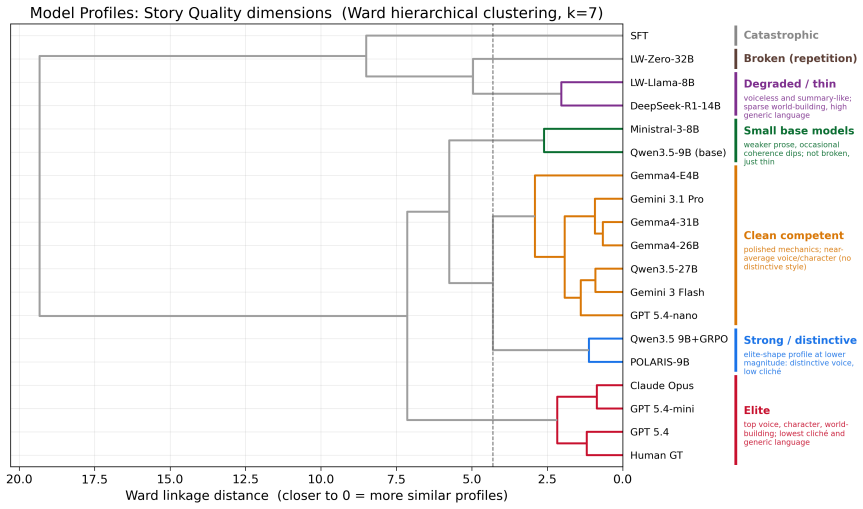
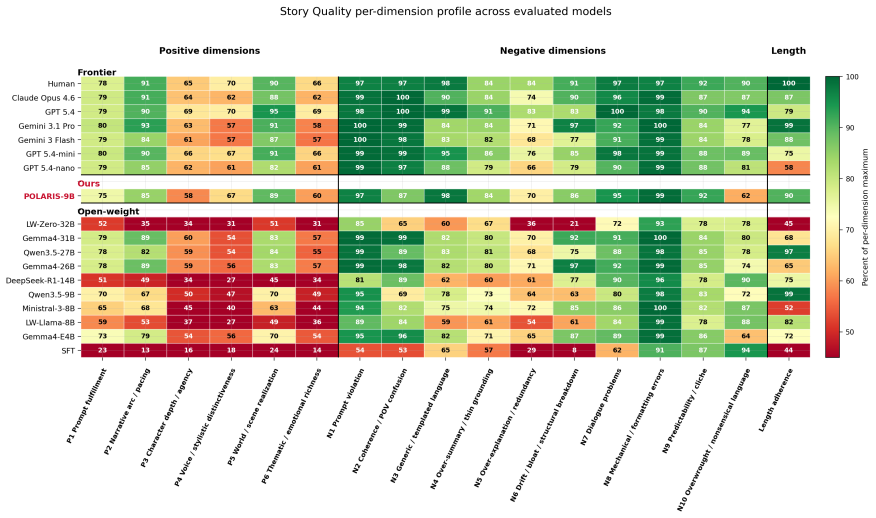
POLARIS-9B, produced by applying the POLARIS recipe (frontier LLM judge with Story Quality rubric plus human-reference injection inside GRPO groups) to Qwen3.5-9B, is competitive with much larger open-weight models on five benchmarks while adhering more closely to length instructions; it preserves quality on out-of-distribution prompts requesting stories up to three times the 4k-word training length where other models degrade in quality, length adherence, or both.
What carries the argument
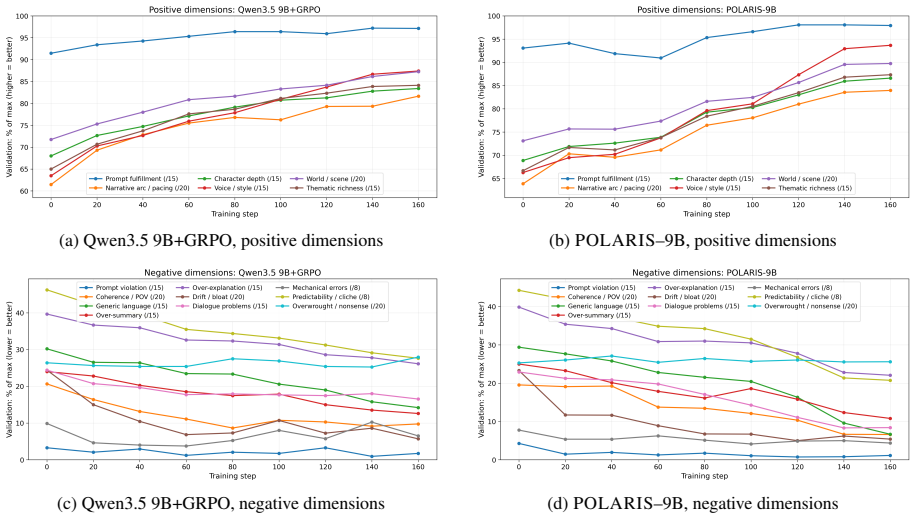
The POLARIS recipe: a frontier LLM judge supplying online rewards via a structured Story Quality rubric combined with human-reference injection (HRI) that places a teacher-forced human story as a high-reward anchor inside each GRPO group.
If this is right
- Small models can be steered to respect explicit length targets without sacrificing story quality even when targets exceed training lengths by a factor of three.
- Length adherence and quality retention on longer prompts can be used as a distinguishing benchmark for creative-writing models that are otherwise close in standard evaluations.
- The combination of LLM-as-judge rewards and human-reference anchors inside GRPO enables effective training with only 1.4K examples and modest hardware.
- Blinded human raters rate POLARIS-9B above its base 9B model and on par with a 27B model across story quality dimensions.
- The method works across both in-distribution and out-of-distribution prompts and rubrics.
Where Pith is reading between the lines
- If the judge rubric generalizes, the same training pattern could be applied to other open-ended generation tasks such as long-form code or dialogue.
- The length-generalization stress test may expose weaknesses in models that appear strong on shorter, in-distribution creative writing benchmarks.
- Human-reference injection may reduce reward hacking by providing an explicit high-quality anchor that the policy must compete against inside each group.
Load-bearing premise
The frontier LLM judge equipped with the structured Story Quality rubric supplies a reliable reward signal that aligns with human preferences for story quality.
What would settle it
A large-scale blinded human preference study in which POLARIS-9B stories are rated lower than Qwen3.5-27B stories or show clear quality drop-off on 12k-word prompts would falsify the central performance claim.
Figures

read the original abstract
Small open-weight models struggle at long-form creative writing: their generated stories either fall far short of the requested length, or their quality significantly degrades as length increases, especially when compared to frontier models. We present POLARIS (Policy Optimization with LLM-as-a-judge rewards and Anchored-Reference Injection for Storywriting), a lower-compute GRPO recipe with two key ingredients: a frontier LLM judge with a structured Story Quality rubric as the online reward, and human-reference injection (HRI), where a teacher-forced human-written story serves as a high-reward anchor within each GRPO group. By applying our training recipe to Qwen3.5-9B, using a dataset of approximately 1.4K prompt-story pairs derived from 100 short-story anthologies and 4 A100 GPUs, we obtain POLARIS-9B. Across five benchmarks spanning in-distribution and out-of-distribution prompts and rubrics, POLARIS-9B is competitive with much larger open-weight models while following length instructions more closely. A blinded human evaluation confirms that POLARIS-9B is preferred to the base Qwen3.5-9B and on par with Qwen3.5-27B. Despite training only on stories up to 4k words, POLARIS-9B preserves quality on prompts requesting stories up to 3 times the training length, a regime where most open-weight models degrade substantially in quality, length adherence, or both. More broadly, our results suggest that length generalization is a meaningful stress test for creative-writing models and a useful lens for distinguishing otherwise close models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces POLARIS, a GRPO-based training method for small open-weight models (applied to Qwen3.5-9B) to improve long-form creative story writing. It combines an online reward from a frontier LLM judge using a structured Story Quality rubric with human-reference injection (HRI), where human-written stories serve as high-reward anchors in each GRPO group. Trained on ~1.4K prompt-story pairs (stories up to 4k words) using 4 A100 GPUs, POLARIS-9B is claimed to match or exceed larger models in quality while better adhering to length instructions, and to generalize quality to prompts requesting up to 12k words (3x training length) where baselines degrade. Results are supported by five benchmarks (in- and out-of-distribution) and a blinded human preference evaluation showing preference over the base 9B model and parity with a 27B model.
Significance. If the central claims hold, the work offers a low-compute recipe for enhancing creative writing in smaller models, with length generalization serving as a useful stress test. The explicit use of HRI as an anchor and the focus on out-of-distribution length provide a concrete, falsifiable contribution that could be adopted or extended in subsequent work on LLM alignment for open-ended generation tasks.
major comments (2)
- [Training procedure and human evaluation sections] The manuscript reports a post-training blinded human preference study (POLARIS-9B preferred to base Qwen3.5-9B, on par with 27B) but provides no direct validation—such as correlation coefficients, agreement rates, or side-by-side ratings—between the frontier LLM judge's numeric scores (the sole online reward during GRPO) and human judgments on the identical generations produced during or after training. This is load-bearing for the central claim because any systematic mismatch (e.g., judge bias toward length or verbosity) could allow GRPO to exploit the signal while the final human eval still passes; the skeptic concern is therefore not resolved by the existing human study.
- [Experimental results and benchmark descriptions] The claims of competitiveness on five benchmarks and superior length adherence / generalization rest on reported positive outcomes, yet the manuscript supplies insufficient detail on exact baselines, statistical tests (e.g., significance of length-adherence differences), data-exclusion rules, and per-prompt length/quality metrics to allow independent assessment of whether the reported gains are robust or driven by particular prompt subsets.
minor comments (2)
- [Dataset construction] Clarify the precise composition of the 1.4K prompt-story dataset (e.g., how prompts were derived from the 100 anthologies and any filtering criteria) to support reproducibility.
- [Reward model description] Ensure the structured Story Quality rubric used by the LLM judge is reproduced verbatim or in sufficient detail, including scoring scale and criteria, so that the reward signal can be inspected.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Training procedure and human evaluation sections] The manuscript reports a post-training blinded human preference study (POLARIS-9B preferred to base Qwen3.5-9B, on par with 27B) but provides no direct validation—such as correlation coefficients, agreement rates, or side-by-side ratings—between the frontier LLM judge's numeric scores (the sole online reward during GRPO) and human judgments on the identical generations produced during or after training. This is load-bearing for the central claim because any systematic mismatch (e.g., judge bias toward length or verbosity) could allow GRPO to exploit the signal while the final human eval still passes; the skeptic concern is therefore not resolved by the existing human study.
Authors: We agree that a direct comparison between the LLM judge scores and human ratings on identical generations would provide stronger evidence against potential reward misalignment. The existing blinded human study validates the final model but does not include the requested correlation analysis. In revision we will add a subsection reporting agreement rates, Pearson/Spearman correlations, and side-by-side rating statistics computed on a held-out sample of post-training generations evaluated by both the judge and human raters. revision: yes
-
Referee: [Experimental results and benchmark descriptions] The claims of competitiveness on five benchmarks and superior length adherence / generalization rest on reported positive outcomes, yet the manuscript supplies insufficient detail on exact baselines, statistical tests (e.g., significance of length-adherence differences), data-exclusion rules, and per-prompt length/quality metrics to allow independent assessment of whether the reported gains are robust or driven by particular prompt subsets.
Authors: We accept that greater experimental transparency is required. The revised manuscript will expand the relevant sections to specify exact baseline configurations and versions, report statistical significance tests (paired t-tests or Wilcoxon signed-rank) for length-adherence and quality differences, state all data-exclusion criteria, and include per-prompt or variance metrics (with standard deviations) for key length and quality scores. Evaluation code and prompts will also be released. revision: yes
Circularity Check
No circularity: empirical training recipe with external rewards and human validation
full rationale
The paper describes an empirical GRPO training procedure on ~1.4K prompt-story pairs using an external frontier LLM judge (with structured rubric) as the online reward signal plus human-reference injection anchors. Results are evaluated on in- and out-of-distribution benchmarks plus a blinded human preference study. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The central claims rest on external benchmarks and human judgments rather than reducing to the training inputs by construction. This is the expected non-finding for a standard empirical ML methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Learning to Reason under Off-Policy Guidance , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[2]
2025 , eprint=
RePO: Replay-Enhanced Policy Optimization , author=. 2025 , eprint=
2025
-
[3]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Chen, Zixiang and Deng, Yihe and Yuan, Huizhuo and Ji, Kaixuan and Gu, Quanquan , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[4]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Anthony, Thomas and Tian, Zheng and Barber, David , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[5]
2025 , eprint=
G ^2 RPO-A: Guided Group Relative Policy Optimization with Adaptive Guidance , author=. 2025 , eprint=
2025
-
[6]
2026 , url=
Xuechen Zhang and Zijian Huang and Yingcong Li and Chenshun Ni and Jiasi Chen and Samet Oymak , booktitle=. 2026 , url=
2026
-
[7]
Nature , volume =
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author =. Nature , volume =. 2025 , doi =
2025
-
[8]
2026 , url=
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and YuYue and Weinan Dai and Tiantian Fan and Gaohong Liu and Juncai Liu and LingJun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Ru Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and ...
2026
-
[9]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[10]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[11]
Chaudhari, Shreyas and Aggarwal, Pranjal and Murahari, Vishvak and Rajpurohit, Tanmay and Kalyan, Ashwin and Narasimhan, Karthik and Deshpande, Ameet and Castro da Silva, Bruno , title =. ACM Comput. Surv. , month = sep, articleno =. 2025 , issue_date =. doi:10.1145/3743127 , abstract =
-
[12]
LongWriter: Unleashing 10,000+ Word Generation from Long Context
Yushi Bai and Jiajie Zhang and Xin Lv and Linzhi Zheng and Siqi Zhu and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , booktitle=. LongWriter: Unleashing 10,000+ Word Generation from Long Context. 2025 , url=
2025
-
[13]
2025 , eprint=
WritingBench: A Comprehensive Benchmark for Generative Writing , author=. 2025 , eprint=
2025
-
[14]
Wei, Xiaolong and Lu, Bo and Zhang, Xingyu and Zhao, Zhejun and Shen, Dongdong and Xia, Long and Yin, Dawei. Igniting Creative Writing in Small Language Models: LLM -as-a-Judge versus Multi-Agent Refined Rewards. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.868
-
[15]
SWAG : Storytelling With Action Guidance
Pei, Jonathan and Patel, Zeeshan and El-Refai, Karim and Li, Tianle. SWAG : Storytelling With Action Guidance. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.824
-
[16]
A Survey on LLM s for Story Generation
Teleki, Maria and Bengali, Vedangi and Dong, Xiangjue and Janjur, Sai Tejas and Liu, Haoran and Liu, Tian and Wang, Cong and Liu, Ting and Zhang, Yin and Shipman, Frank and Caverlee, James. A Survey on LLM s for Story Generation. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.750
-
[17]
The Fourteenth International Conference on Learning Representations , year=
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
RLMR: Reinforcement Learning with Mixed Rewards for Creative Writing , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i38.40467 , abstractNote=
-
[19]
2026 , eprint=
Rewarding Creativity: A Human-Aligned Generative Reward Model for Reinforcement Learning in Storytelling , author=. 2026 , eprint=
2026
-
[20]
2026 , eprint=
Writer-R1: Enhancing Generative Writing in LLMs via Memory-augmented Replay Policy Optimization , author=. 2026 , eprint=
2026
-
[21]
Writing-
Xuanyu Lei and Chenliang Li and Yuning Wu and Kaiming Liu and Weizhou Shen and Peng Li and Ming Yan and Fei Huang and Ya-Qin Zhang and Yang Liu , year=. Writing-
-
[22]
2025 , eprint=
Writing-Zero: Bridge the Gap Between Non-verifiable Tasks and Verifiable Rewards , author=. 2025 , eprint=
2025
-
[23]
2026 , eprint=
DPWriter: Reinforcement Learning with Diverse Planning Branching for Creative Writing , author=. 2026 , eprint=
2026
-
[24]
2026 , eprint=
R2-Write: Reflection and Revision for Open-Ended Writing with Deep Reasoning , author=. 2026 , eprint=
2026
-
[25]
and Patel, Reet and Bosselut, Antoine and Plas, Lonneke Van Der and Beaty, Roger E
Ismayilzada, Mete and Laverghetta Jr., Antonio and Luchini, Simone A. and Patel, Reet and Bosselut, Antoine and Plas, Lonneke Van Der and Beaty, Roger E. Creative Preference Optimization. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.509
-
[26]
2025 , eprint=
Diverse Preference Optimization , author=. 2025 , eprint=
2025
-
[27]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Yuan, Weizhe and Pang, Richard Yuanzhe and Cho, Kyunghyun and Li, Xian and Sukhbaatar, Sainbayar and Xu, Jing and Weston, Jason , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[28]
Second Conference on Language Modeling , year=
Learning to Reason for Long-Form Story Generation , author=. Second Conference on Language Modeling , year=
-
[29]
2024 , eprint=
EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models , author=. 2024 , eprint=
2024
-
[30]
2024 , eprint=
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models , author=. 2024 , eprint=
2024
-
[31]
L it B ench: A Benchmark and Dataset for Reliable Evaluation of Creative Writing
Fein, Daniel and Russo, Sebastian and Xiang, Violet and Jolly, Kabir and Rafailov, Rafael and Haber, Nick. L it B ench: A Benchmark and Dataset for Reliable Evaluation of Creative Writing. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl...
-
[32]
N arra B ench: A Comprehensive Framework for Narrative Benchmarking
Hamilton, Sil and Wilkens, Matthew and Piper, Andrew. N arra B ench: A Comprehensive Framework for Narrative Benchmarking. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl-long.176
-
[33]
2024 , eprint=
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods , author=. 2024 , eprint=
2024
-
[34]
From generation to judgment: Opportunities and challenges of LLM-as-a-judge
Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and Shu, Kai and Cheng, Lu and Liu, Huan. From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge. Proceedings of the 2025 Conference on Empirical Methods ...
-
[35]
The Twelfth International Conference on Learning Representations , year=
Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[36]
Jiawei Gu and Xuhui Jiang and Zhichao Shi and Hexiang Tan and Xuehao Zhai and Chengjin Xu and Wei Li and Yinghan Shen and Shengjie Ma and Honghao Liu and Saizhuo Wang and Kun Zhang and Zhouchi Lin and Bowen Zhang and Lionel Ni and Wen Gao and Yuanzhuo Wang and Jian Guo , keywords =. A survey on LLM-as-a-judge , journal =. 2026 , issn =. doi:https://doi.or...
-
[37]
Kim, Seungone and Suk, Juyoung and Longpre, Shayne and Lin, Bill Yuchen and Shin, Jamin and Welleck, Sean and Neubig, Graham and Lee, Moontae and Lee, Kyungjae and Seo, Minjoon. Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing...
-
[38]
2025 , eprint=
Leveraging LLMs as Meta-Judges: A Multi-Agent Framework for Evaluating LLM Judgments , author=. 2025 , eprint=
2025
-
[39]
2026 , eprint=
Rubrics to Tokens: Bridging Response-level Rubrics and Token-level Rewards in Instruction Following Tasks , author=. 2026 , eprint=
2026
-
[40]
Second Conference on Language Modeling , year=
A Critical Look At Tokenwise Reward-Guided Text Generation , author=. Second Conference on Language Modeling , year=
-
[41]
doi: 10.18653/v1/2024.findings-naacl.111
Li, Wendi and Wei, Wei and Xu, Kaihe and Xie, Wenfeng and Chen, Dangyang and Cheng, Yu. Reinforcement Learning with Token-level Feedback for Controllable Text Generation. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.111
-
[42]
2023 , eprint=
Let's Verify Step by Step , author=. 2023 , eprint=
2023
-
[43]
2025 , eprint=
Process Reinforcement through Implicit Rewards , author=. 2025 , eprint=
2025
-
[44]
Zhao, Yanli and Gu, Andrew and Varma, Rohan and Luo, Liang and Huang, Chien-Chin and Xu, Min and Wright, Less and Shojanazeri, Hamid and Ott, Myle and Shleifer, Sam and Desmaison, Alban and Balioglu, Can and Damania, Pritam and Nguyen, Bernard and Chauhan, Geeta and Hao, Yuchen and Mathews, Ajit and Li, Shen , title =. Proc. VLDB Endow. , month = aug, pag...
-
[45]
2026 , howpublished =
2026
-
[46]
2026 , month = feb, howpublished =
2026
-
[47]
2025 , month = dec, howpublished =
2025
-
[48]
2026 , month = apr, day =
2026
-
[49]
2026 , eprint =
Ministral 3 , author =. 2026 , eprint =
2026
-
[50]
Richard D'Souza , keywords =. What characterises creativity in narrative writing, and how do we assess it? Research findings from a systematic literature search , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.tsc.2021.100949 , url =
-
[51]
Jonathan M. Adler and Theodore E.A. Waters and Justin Poh and Sophia Seitz , keywords =. The nature of narrative coherence: An empirical approach , journal =. 2018 , issn =. doi:https://doi.org/10.1016/j.jrp.2018.01.001 , url =
-
[52]
Ryan L. Boyd and Kate G. Blackburn and James W. Pennebaker , title =. Science Advances , volume =. 2020 , doi =. https://www.science.org/doi/pdf/10.1126/sciadv.aba2196 , abstract =
-
[53]
Large language models are not fair evaluators
Wang, Peiyi and Li, Lei and Chen, Liang and Cai, Zefan and Zhu, Dawei and Lin, Binghuai and Cao, Yunbo and Kong, Lingpeng and Liu, Qi and Liu, Tianyu and Sui, Zhifang. Large Language Models are not Fair Evaluators. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.ac...
-
[54]
Extracting Training Data from Large Language Models , booktitle =
Nicholas Carlini and Florian Tram. Extracting Training Data from Large Language Models , booktitle =. 2021 , isbn =
2021
-
[55]
and Lee, Katherine and Cooper, A
Hayes, Jamie and Swanberg, Marika and Chaudhari, Harsh and Yona, Itay and Shumailov, Ilia and Nasr, Milad and Choquette-Choo, Christopher A. and Lee, Katherine and Cooper, A. Feder. Measuring memorization in language models via probabilistic extraction. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Comput...
-
[56]
2023 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.