SocialCoach: Personalized Social Skill Learning with RL-based Agentic Tutoring and Practice
Pith reviewed 2026-06-28 08:02 UTC · model grok-4.3
The pith
SocialCoach builds an LLM agentic system that constructs expert social-skill corpora and uses RL in learner simulations to schedule personalized practice paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
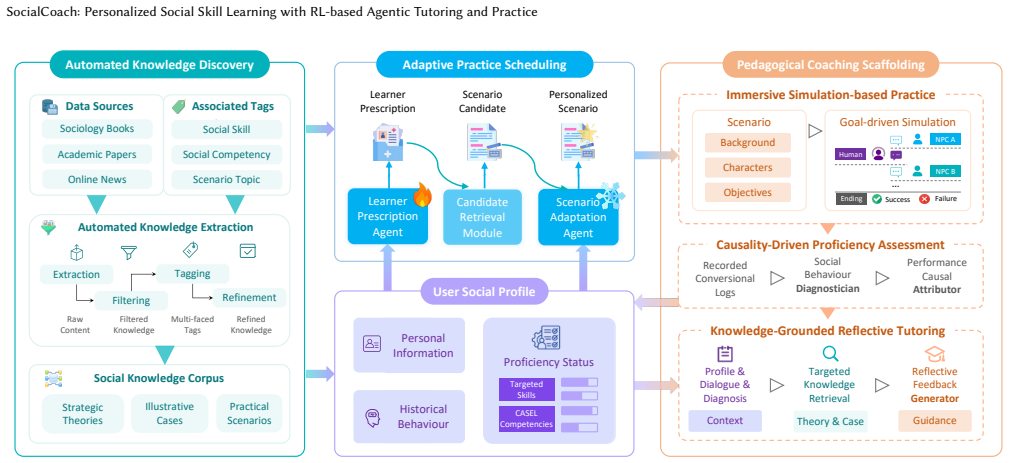
SocialCoach demonstrates that an integrated pipeline of multi-agent corpus construction, RL-optimized adaptive scheduling in a learner simulation, and LLM-driven immersive practice with reflective feedback produces higher-quality learning pathways and tutoring interactions than non-RL or non-agentic baselines while delivering usable personalization at scale.
What carries the argument
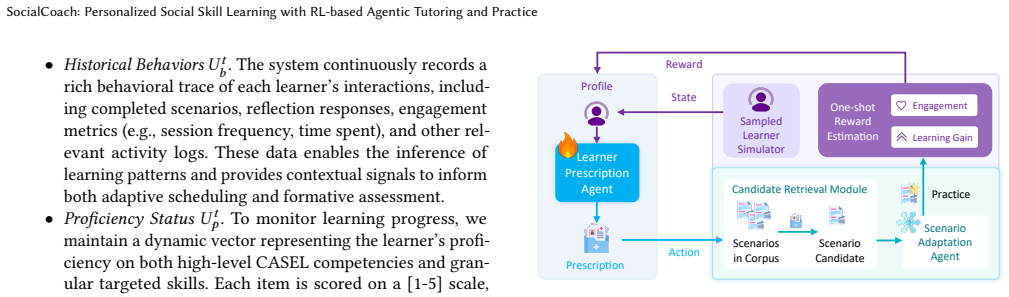
The adaptive practice scheduling module that executes a prescription-retrieval-adaptation process whose policy is optimized by reinforcement learning inside a simulated learner environment to maximize long-term experience and handle cold-start.
If this is right
- Personalized social-skill curricula can be generated and scheduled without continuous human expert availability.
- Reinforcement learning policies trained in simulation can overcome cold-start limitations for new learners.
- Combining immersive practice with causality-driven assessment narrows the gap between knowing social techniques and applying them.
- The same architecture supplies a template for other soft-skill domains that currently lack scalable coaching.
Where Pith is reading between the lines
- If the simulation-to-reality transfer holds, the same RL scheduling loop could be reused across different tutoring domains with only the knowledge corpus swapped.
- Real-time user telemetry could be fed back to refine the simulation model, creating a closed-loop improvement cycle not described in the current deployment.
- Extending the multi-agent corpus pipeline to ingest live expert videos or case studies could further reduce reliance on static sources.
Load-bearing premise
The simulated learner environment used to train the reinforcement-learning scheduler accurately models real human learning dynamics and transfers to actual users.
What would settle it
A randomized controlled trial that measures real-user skill gains (via pre/post performance in negotiation or leadership tasks) after SocialCoach tutoring versus a matched non-RL baseline and reports no statistically significant difference.
Figures



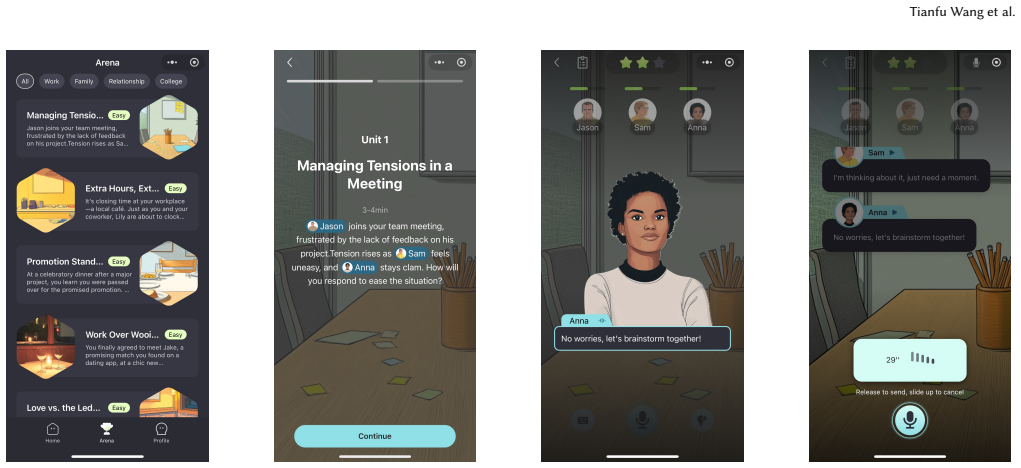
read the original abstract
Social skills such as negotiation and leadership are crucial for personal and professional success in today's interconnected world. However, scalable and effective training remains a significant challenge due to the scarcity of expert coaching. In this paper, we introduce SocialCoach, a holistic LLM-powered agentic tutoring system for personalized social skill development at scale. First, SocialCoach automatically constructs a pedagogically-grounded, theory-to-practice knowledge corpus from diverse expert sources, leveraging a multi-agent pipeline. Second, to personalize the learning journey, it employs an adaptive practice scheduling module that follows a prescription-retrieval-adaptation process. To maximize the long-term learning experience while overcoming the cold-start problem, this policy is optimized within a learner simulation environment through reinforcement learning. Finally, SocialCoach integrates immersive, goal-driven practice, causality-driven proficiency assessment and knowledge-grounded, reflective tutoring to help address the knowing-doing gap. We deploy it in our product, EQoach, and conduct extensive experiments. The results show that SocialCoach improves simulated pathway quality and judge-rated tutoring quality over baseline approaches, while early user feedback indicates strong perceived engagement and usefulness. These findings suggest a practical architecture for personalized and gamified pedagogical platforms on soft skill learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SocialCoach, an LLM-powered agentic system for scalable personalized social skill training. It constructs a pedagogically-grounded knowledge corpus via a multi-agent pipeline from expert sources, employs an RL-optimized adaptive scheduling policy (prescription-retrieval-adaptation loop with cold-start handling) inside a learner simulation environment, and integrates immersive goal-driven practice, causality-driven assessment, and reflective tutoring. Deployed in EQoach, it claims improvements in simulated pathway quality and judge-rated tutoring quality over baselines, plus positive early user feedback on engagement and usefulness.
Significance. If the simulation-to-real transfer holds, the architecture offers a concrete, deployable approach to addressing expert-coach scarcity in soft-skill domains through automated corpus construction and long-horizon RL scheduling. The integration of theory-to-practice corpus building with RL personalization and immersive practice is a practical contribution to HCI and educational technology. The lack of demonstrated correlation between simulation metrics and real-user outcomes, however, limits the strength of the claims.
major comments (2)
- [§3.2 (adaptive scheduling) and Experiments] The central claim that the RL policy improves simulated pathway quality and enables practical personalization rests on the learner simulation environment accurately modeling human learning dynamics and transfer. No section provides evidence (e.g., correlation studies or real-user validation experiments) that simulation metrics predict proficiency gains, engagement, or transfer outside the simulation.
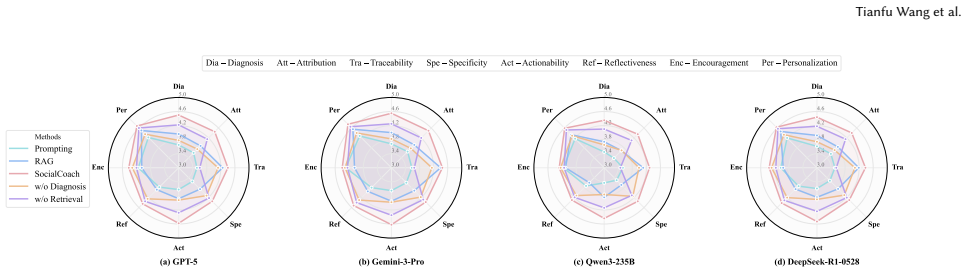
- [Experiments / Results] The abstract and results statements claim performance improvements in simulated pathway quality and judge-rated tutoring quality, yet supply no quantitative metrics, explicit baseline definitions, effect sizes, or statistical tests. This prevents assessment of whether the reported gains are robust or merely artifacts of the simulation setup.
minor comments (2)
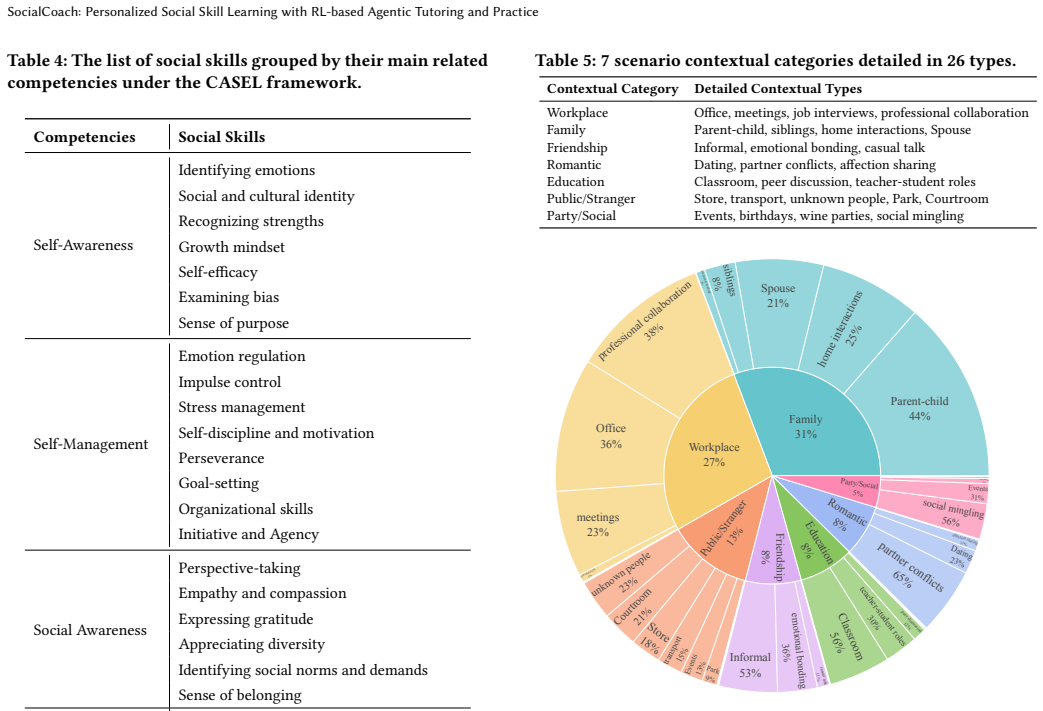
- [§3.1] The multi-agent pipeline for corpus construction is described at a high level; adding pseudocode or a diagram of the agent roles and information flow would improve reproducibility.
- [§3.2] Implementation details for the RL reward function, state representation, and cold-start handling mechanism are referenced but not fully specified, making it difficult to replicate the scheduling policy.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications on the scope of our evaluation and specific plans for revision.
read point-by-point responses
-
Referee: [§3.2 (adaptive scheduling) and Experiments] The central claim that the RL policy improves simulated pathway quality and enables practical personalization rests on the learner simulation environment accurately modeling human learning dynamics and transfer. No section provides evidence (e.g., correlation studies or real-user validation experiments) that simulation metrics predict proficiency gains, engagement, or transfer outside the simulation.
Authors: We acknowledge that the current manuscript does not include correlation studies or direct real-user validation experiments linking simulation metrics to real-world proficiency gains or transfer. The learner simulation is constructed from established pedagogical principles in social skill learning literature and expert input, with additional grounding provided by judge-rated tutoring quality and early deployment feedback in EQoach. We agree this represents a limitation for claims about practical personalization. In revision we will add an explicit Limitations section discussing the simulation-to-real gap and outlining planned future validation studies. revision: partial
-
Referee: [Experiments / Results] The abstract and results statements claim performance improvements in simulated pathway quality and judge-rated tutoring quality, yet supply no quantitative metrics, explicit baseline definitions, effect sizes, or statistical tests. This prevents assessment of whether the reported gains are robust or merely artifacts of the simulation setup.
Authors: We agree that the abstract and high-level results statements would benefit from greater quantitative transparency. Although comparative results appear in the experiments section, we will revise the abstract and results summary to include explicit quantitative metrics (pathway quality scores and tutoring quality ratings), clearly define all baselines (e.g., random scheduling and non-RL policies), and report effect sizes together with statistical tests. This change will make the robustness of the gains directly assessable. revision: yes
Circularity Check
RL-optimized scheduling policy shows gains in the same simulation used for training
specific steps
-
fitted input called prediction
[Abstract]
"To maximize the long-term learning experience while overcoming the cold-start problem, this policy is optimized within a learner simulation environment through reinforcement learning. [...] The results show that SocialCoach improves simulated pathway quality and judge-rated tutoring quality over baseline approaches"
The policy is trained inside the simulation to maximize long-term learning experience; the claimed improvement in 'simulated pathway quality' is therefore the training outcome by construction rather than a held-out prediction or external validation of the simulation's fidelity.
full rationale
The paper optimizes its adaptive scheduling policy via RL inside a learner simulation to maximize long-term learning experience, then reports that SocialCoach 'improves simulated pathway quality' over baselines. This reported improvement is the direct result of the optimization objective rather than an independent test. No external real-user proficiency correlation is shown to break the loop. The judge-rated and user-feedback results are downstream and do not validate the simulation itself. This matches the fitted_input_called_prediction pattern but does not extend to the full architecture or other claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Taylor N Allbright, Julie A Marsh, Kate E Kennedy, Heather J Hough, and Susan McKibben. 2019. Social-emotional learning practices: Insights from outlier schools.Journal of Research in Innovative Teaching & Learning12, 1 (2019), 35–52
2019
-
[2]
Mitchell
Jonathan Bassen, Bharathan Balaji, Michael Schaarschmidt, Candace Thille, Jay Painter, Dawn Zimmaro, Alex Games, Ethan Fast, and John C. Mitchell. 2020. Reinforcement Learning for the Adaptive Scheduling of Educational Activities. InCHI
2020
-
[3]
Jaime Carbonell and Jade Goldstein. 1998. The use of MMR, diversity-based reranking for reordering documents and producing summaries. InSIGIR
1998
- [4]
- [5]
-
[6]
Jiwon Chun, Yankun Zhao, Hanlin Chen, and Meng Xia. 2025. PlanGlow: Person- alized Study Planning with an Explainable and Controllable LLM-Driven System. InL@S
2025
-
[7]
2017.Soft skills needed for the 21st century workforce
Susan A Dean. 2017.Soft skills needed for the 21st century workforce. Walden University
2017
-
[8]
DeepSeek-AI. 2025. DeepSeek-R1-0528 Release. https://api-docs.deepseek.com/ news/news250528
2025
- [9]
-
[10]
2015.Handbook of social and emotional learning: Research and practice
Joseph A Durlak. 2015.Handbook of social and emotional learning: Research and practice. Guilford Publications
2015
-
[11]
Julian G Elliott, Steven E Stemler, Robert J Sternberg, Elena L Grigorenko, and Newman Hoffman. 2011. The socially skilled teacher and the development of tacit knowledge.British Educational Research Journal37, 1 (2011), 83–103
2011
-
[12]
Anna Fang, Hriday Chhabria, Alekhya Maram, and Haiyi Zhu. 2025. Social Simulation for Everyday Self-Care: Design Insights from Leveraging VR, AR, and LLMs for Practicing Stress Relief. InCHI
2025
-
[13]
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. 2024. Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Frank M. Gresham. 2015.Disruptive Behavior Disorders: Evidence-Based Practice for Assessment and Intervention. Guilford Publications
2015
-
[15]
Hengnian Gu, Zhiyi Duan, Pan Xie, and Dongdai Zhou. 2024. Modeling balanced explicit and implicit relations with contrastive learning for knowledge concept recommendation in MOOCs. InWWW
2024
-
[16]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al . 2024. A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Michael Guevarra, Indronil Bhattacharjee, Srijita Das, Christabel Wayllace, Car- rie Demmans Epp, Matthew E Taylor, and Alan Tay. 2025. An LLM-Guided Tutoring System for Social Skills Training. InAAAI
2025
-
[18]
Sarah Susanna Hoppler, Robin Segerer, and Jana Nikitin. 2022. The six com- ponents of social interactions: Actor, partner, relation, activities, context, and evaluation.Frontiers in Psychology12 (2022), 743074
2022
-
[19]
Tiancheng Hu, Joachim Baumann, Lorenzo Lupo, Nigel Collier, Dirk Hovy, and Paul Röttger. 2025. Simbench: Benchmarking the ability of large language models to simulate human behaviors.arXiv preprint arXiv:2510.17516(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Chris Davis Jaldi, Eleni Ilkou, Noah Schroeder, and Cogan Shimizu. 2025. Ed- ucation in the era of Neurosymbolic AI.Journal of Web Semantics85 (2025), 100857
2025
-
[21]
Stephanie M Jones and Emily J Doolittle. 2017. Social and emotional learning: Introducing the issue.The future of children27, 1 (2017), 3–11
2017
-
[22]
Matthew Jörke, Shardul Sapkota, Lyndsea Warkenthien, Niklas Vainio, Paul Schmiedmayer, Emma Brunskill, and James A. Landay. 2025. GPTCoach: Towards LLM-Based Physical Activity Coaching. InCHI
2025
-
[23]
Harold W. Kuhn. 1955. The Hungarian method for the assignment problem. Naval Research Logistics Quarterly2, 1-2 (1955), 83–97
1955
-
[24]
Qingyao Li, Wei Xia, Li’ang Yin, Jiarui Jin, and Yong Yu. 2024. Privileged knowl- edge state distillation for reinforcement learning-based educational path recom- mendation. InKDD
2024
-
[25]
Jiayu Liu, Zhenya Huang, Tong Xiao, Jing Sha, Jinze Wu, Qi Liu, Shijin Wang, and Enhong Chen. 2024. SocraticLM: Exploring socratic personalized teaching with large language models.Advances in Neural Information Processing Systems 37 (2024), 85693–85721
2024
-
[26]
Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Ningyu Zhang, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, Haofen Wang, and Huajun Chen. 2025. OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System. InWWW
2025
-
[27]
Setareh Maghsudi, Andrew Lan, Jie Xu, and Mihaela van Der Schaar. 2021. Personalized education in the artificial intelligence era: what to expect next. IEEE Signal Processing Magazine38, 3 (2021), 37–50
2021
-
[28]
OpenAI. 2025. GPT-5 System Card. https://cdn.openai.com/gpt-5-system-card. pdf. Published August 7, 2025
2025
-
[29]
getting us through:
Sarah M Ovink and Brian D Veazey. 2011. More than “getting us through:” A case study in cultural capital enrichment of underrepresented minority under- graduates.Research in higher education52, 4 (2011), 370–394
2011
-
[30]
Jiahuan Pei, Fanghua Ye, Xin Sun, Wentao Deng, Koen Hindriks, and Junxiao Wang. 2025. Conversational Education at Scale: A Multi-LLM Agent Workflow for Procedural Learning and Pedagogic Quality Assessment. InEMNLP
2025
- [31]
- [32]
- [33]
-
[34]
Surbhi Seema Sethi and Kanishk Jain. 2024. AI technologies for social emotional learning: recent research and future directions.Journal of Research in Innovative Teaching & Learning17, 2 (2024), 213–225
2024
-
[35]
Bernstein
Omar Shaikh, Valentino Emil Chai, Michele Gelfand, Diyi Yang, and Michael S. Bernstein. 2024. Rehearsal: Simulating Conflict to Teach Conflict Resolution. In CHI
2024
-
[36]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Lee S. Shulman. 1998. Theory, practice, and the education of professionals.The Elementary School Journal98, 5 (1998), 511–526
1998
-
[38]
Ian Steenstra, Farnaz Nouraei, and Timothy W Bickmore. 2025. Scaffolding Empathy: Training Counselors with Simulated Patients and Utterance-level Performance Visualizations. InCHI
2025
-
[39]
Tianlong Wang, Xianfeng Jiao, Yinghao Zhu, Zhongzhi Chen, Yifan He, Xu Chu, Junyi Gao, Yasha Wang, and Liantao Ma. 2025. Adaptive activation steering: A tuning-free llm truthfulness improvement method for diverse hallucinations categories. InWWW. Tianfu Wang et al
2025
-
[40]
Tianfu Wang, Yi Zhan, Jianxun Lian, Zhengyu Hu, Nicholas Jing Yuan, Qi Zhang, Xing Xie, and Hui Xiong. 2025. LLM-powered Multi-agent Framework for Goal- oriented Learning in Intelligent Tutoring System. InWWW
2025
-
[41]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, et al. 2025. Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library.arXiv preprint arXiv:2506.06122(2025)
-
[42]
Shirley Wu, Michel Galley, Baolin Peng, Hao Cheng, Gavin Li, Yao Dou, Weixin Cai, James Zou, Jure Leskovec, and Jianfeng Gao. 2025. CollabLLM: From Passive Responders to Active Collaborators. InICML
2025
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [44]
- [45]
-
[46]
Yi Zhan, Qi Liu, Weibo Gao, Zheng Zhang, Tianfu Wang, Shuanghong Shen, Junyu Lu, and Zhenya Huang. 2025. CoderAgent: Simulating Student Behavior for Personalized Programming Learning with Large Language Models. InIJCAI
2025
-
[47]
Xinnong Zhang, Jiayu Lin, Xinyi Mou, Shiyue Yang, Xiawei Liu, Libo Sun, Hanjia Lyu, Yihang Yang, Weihong Qi, Yue Chen, et al. 2025. Socioverse: A world model for social simulation powered by llm agents and a pool of 10 million real-world users.arXiv preprint arXiv:2504.10157(2025)
-
[48]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al . 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [49]
- [50]
-
[51]
prescription
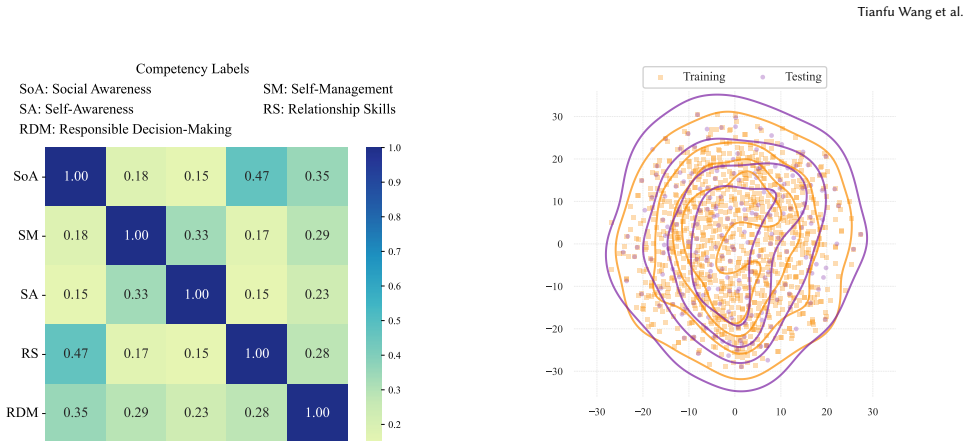
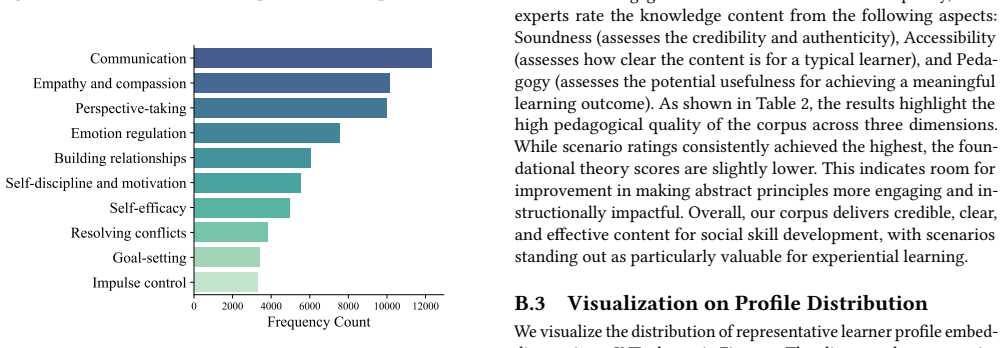
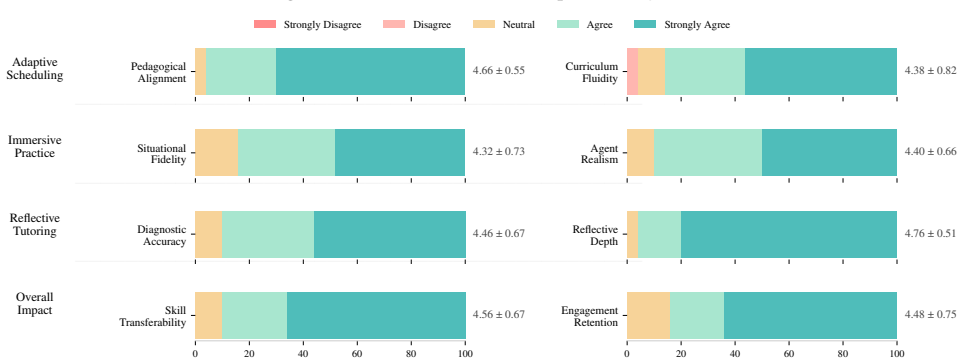
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, et al. 2024. SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents. In ICLR. A Details of Framework Design A.1 Knowledge Categorization Details To ensure our knowledge corpus is pedagogically so...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.