Latent Anchor-Driven Test Generation for Deep Neural Networks
Pith reviewed 2026-06-28 07:40 UTC · model grok-4.3
The pith
Latte generates DNN test cases by one-step anchor-directed mutations in VQ-VAE latent space to raise fault exposure and diversity while keeping semantic closeness to seeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
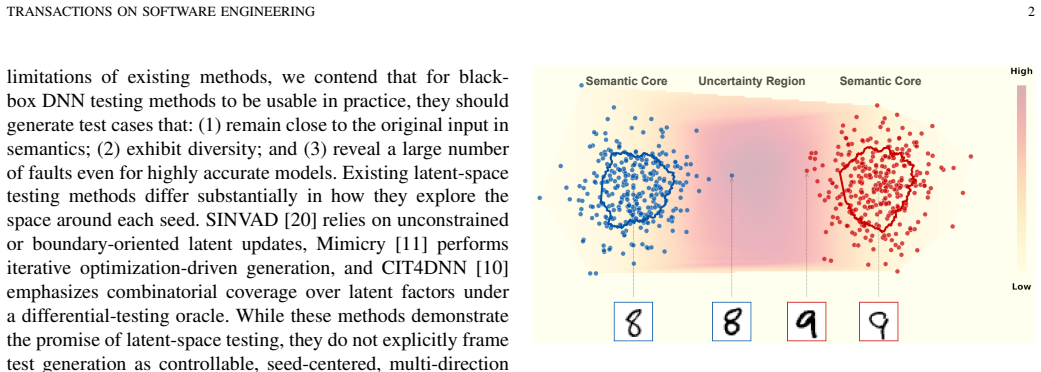
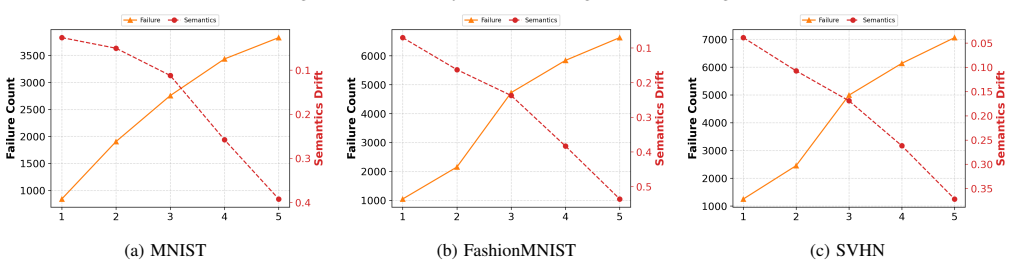
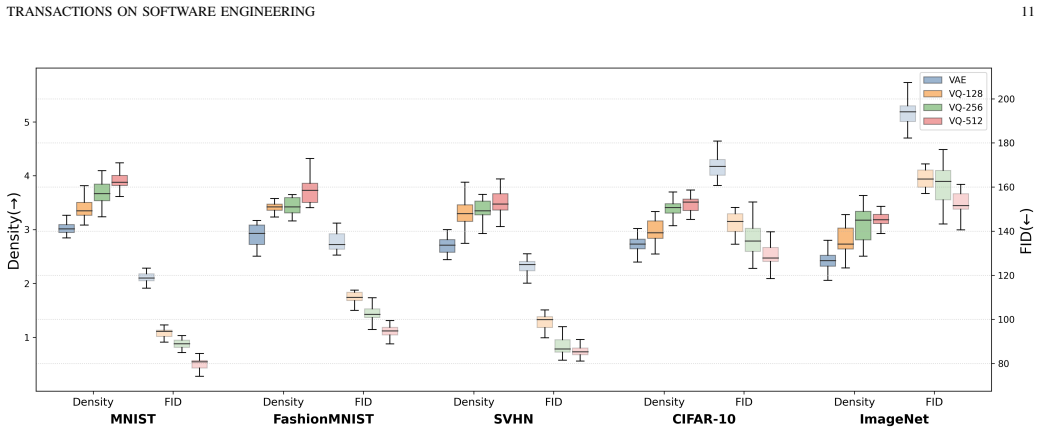
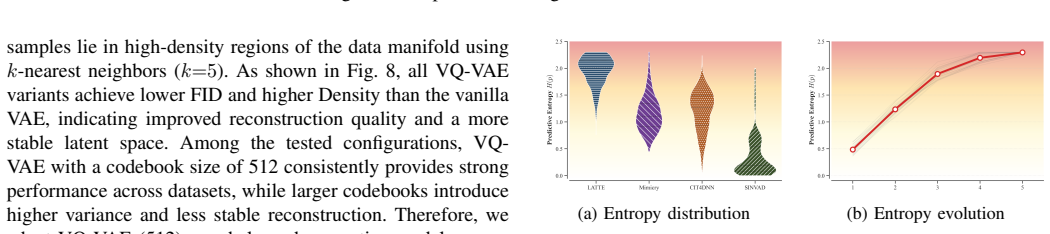
Latte encodes each input seed with a pre-trained VQ-VAE and performs a seed-centered, one-step latent mutation along directions defined by anchors sampled from alternative classes, followed by quantization and decoding back to the input space. This explores local neighborhoods around each seed within the learned latent manifold, resulting in a larger number and broader diversity of oracle-triggering prediction discrepancies under the same budget.
What carries the argument
seed-centered one-step latent mutation along directions to alternative-class anchors in a pre-trained VQ-VAE space, which defines controlled local exploration that balances proximity and fault revelation
If this is right
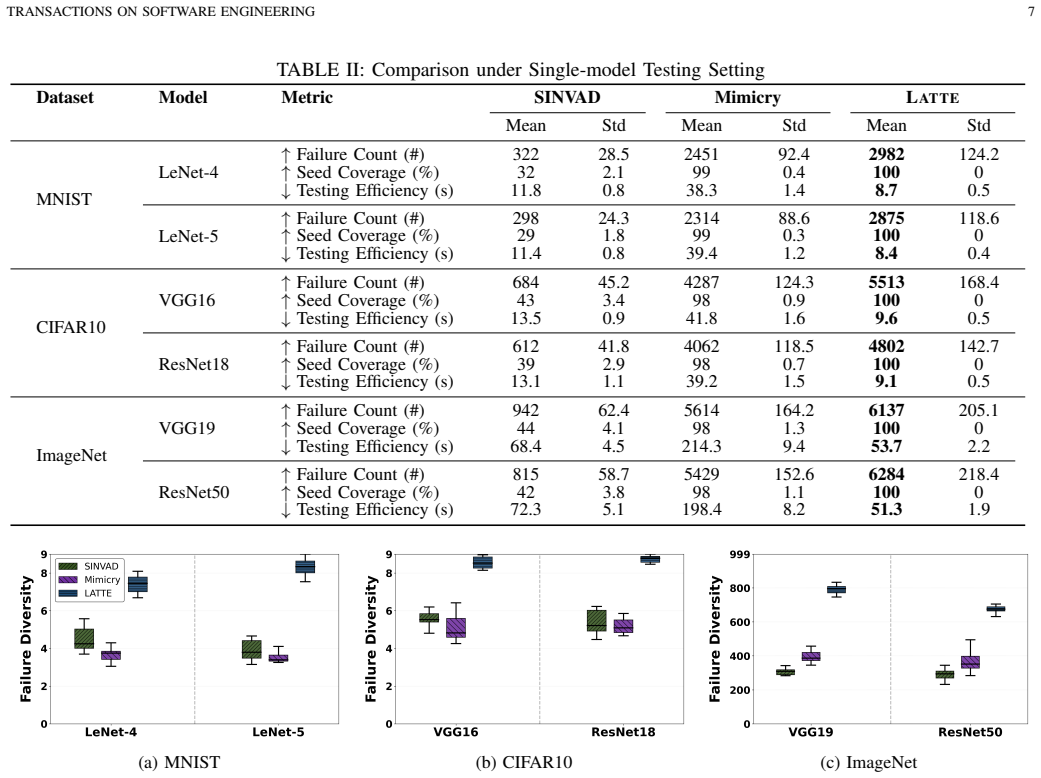
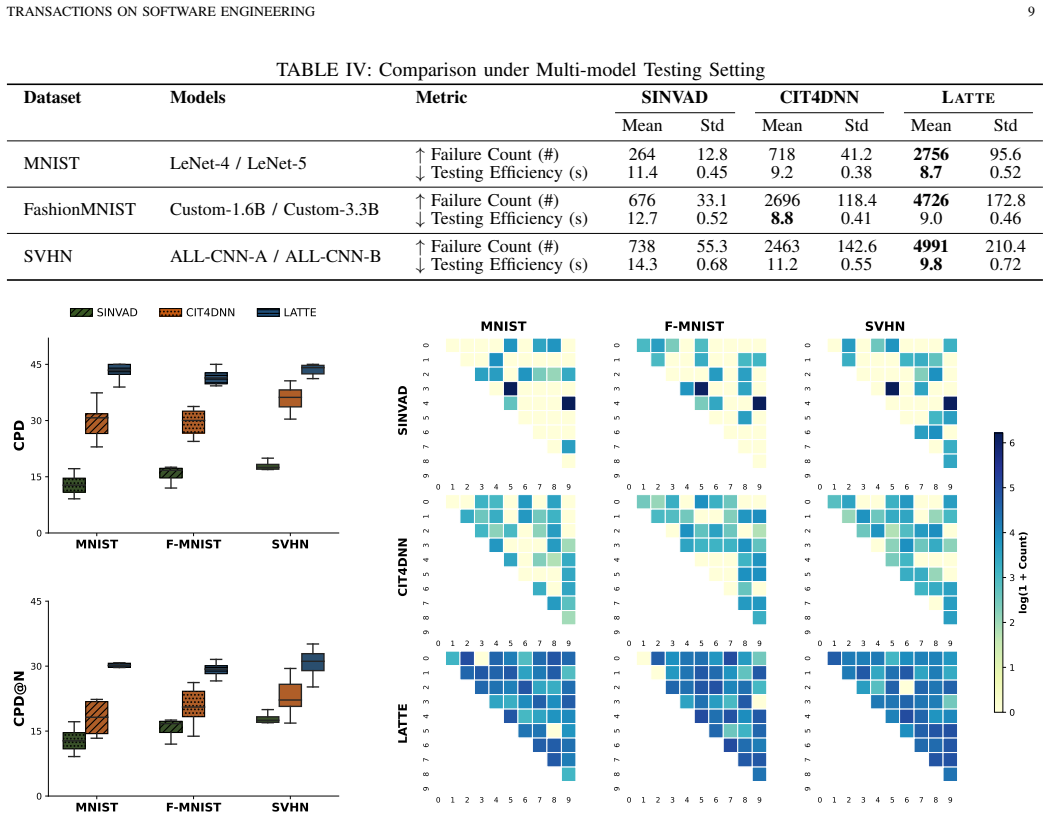
- More oracle-triggering prediction discrepancies are found per test budget than with prior methods.
- Behavioral diversity among the generated tests increases under the same budget.
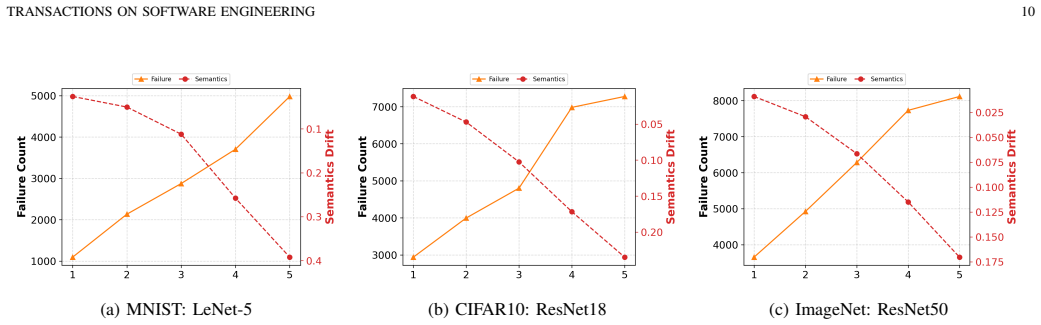
- Seed-relative semantic drift stays low in single-model testing scenarios.
- The gains hold in both single-model and multi-model testing settings.
Where Pith is reading between the lines
- If the VQ-VAE manifold accurately captures semantics, the same anchor idea could transfer to other latent generative models without retraining the entire tester.
- Class-conditional anchors appear to resolve the controllability-drift trade-off better than unguided mutations, which could inform testing in domains that already use class-conditional generators.
- The fixed-budget improvements suggest that anchor-driven generation may lower the total number of tests needed to reach a target fault coverage level.
Load-bearing premise
The pre-trained VQ-VAE produces a latent manifold in which one-step anchor-directed mutations yield inputs that are both semantically close to the seed and more likely to trigger oracle discrepancies than random or gradient-based alternatives.
What would settle it
On a held-out dataset and model, generate the same number of tests with Latte and with the strongest baseline; if Latte does not expose strictly more distinct faults or achieve higher behavioral diversity, the claimed advantage is falsified.
Figures



read the original abstract
Deep Neural Networks (DNNs) are increasingly being deployed in security-critical and safety-sensitive applications, which makes rigorous testing essential to identify and mitigate model weaknesses. Existing DNN testing approaches explore either the input space or a learned latent space. While latent-space generation can better maintain plausibility than direct input-space mutation, current methods still face a trade-off among exploration controllability, failure diversity, and seed-relative semantic drift. To overcome these limitations, we propose Latte, a black-box testing framework that generates semantically proximate, diverse, and fault-revealing test cases by leveraging the latent space. Specifically, Latte encodes each input seed with a pre-trained VQ-VAE and performs a seed-centered, one-step latent mutation along directions defined by anchors sampled from alternative classes, followed by quantization and decoding back to the input space. This explores local neighborhoods around each seed within the learned latent manifold, resulting in a larger number and broader diversity of oracle-triggering prediction discrepancies under the same budget. We evaluated Latte on 5 datasets and 10 DNN models in single-model and multi-model testing scenarios. Across the evaluated datasets and models, Latte improves fault exposure and behavioral diversity under matched testing budgets. Under the single-model setting, it also maintains low seed-relative semantic drift with respect to the source seeds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Latte, a black-box DNN testing framework that encodes seeds with a pre-trained VQ-VAE, performs one-step latent mutations toward anchors sampled from other classes, quantizes, and decodes to produce test inputs. It claims this yields higher fault exposure and behavioral diversity than baselines under matched budgets across 5 datasets and 10 models, while keeping low seed-relative semantic drift in the single-model case.
Significance. If the empirical claims hold after verification, the directed anchor-based exploration in a learned latent manifold could offer a practical balance of controllability, plausibility, and fault revelation that improves on prior latent-space or input-space methods. The approach is notable for its black-box nature and explicit handling of semantic drift, but its significance is constrained by the absence of any guarantee that the VQ-VAE codebook aligns inter-class directions with the target DNN decision boundaries.
major comments (2)
- [Method] The core claim that one-step anchor-directed mutations produce higher oracle discrepancies than random or gradient-based alternatives rests on the unstated assumption that the pre-trained VQ-VAE latent manifold organizes space such that inter-class anchor vectors point toward decision-boundary crossings for the downstream model; the VQ-VAE reconstruction-plus-commitment objective supplies no such alignment, and no analysis or ablation in the method description demonstrates that quantization preserves the directional signal.
- [Abstract and §4] Abstract and evaluation sections report improvements on 5 datasets and 10 models but supply no quantitative metrics, baseline names, budget-matching protocol, diversity measures, or drift calculation details, so the central empirical claim cannot be assessed for soundness or compared to the stated baselines.
minor comments (1)
- [Method] Notation for anchors, quantization step, and semantic-drift metric is introduced without explicit equations or pseudocode, reducing reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of the method's assumptions and the need for clearer empirical details. We address each major comment below and indicate revisions where appropriate.
read point-by-point responses
-
Referee: [Method] The core claim that one-step anchor-directed mutations produce higher oracle discrepancies than random or gradient-based alternatives rests on the unstated assumption that the pre-trained VQ-VAE latent manifold organizes space such that inter-class anchor vectors point toward decision-boundary crossings for the downstream model; the VQ-VAE reconstruction-plus-commitment objective supplies no such alignment, and no analysis or ablation in the method description demonstrates that quantization preserves the directional signal.
Authors: We acknowledge that the VQ-VAE is pre-trained solely on reconstruction and commitment objectives with no explicit alignment to the target DNN's decision boundaries, and the manuscript does not include an ablation demonstrating preservation of directional signal under quantization. Our approach is empirical rather than theoretically guaranteed; we show through results on 10 models that the mutations yield higher fault exposure. We will add a new ablation subsection analyzing quantization's effect on mutation vectors (e.g., cosine similarity before/after quantization) and correlation with prediction changes to address this directly. revision: yes
-
Referee: [Abstract and §4] Abstract and evaluation sections report improvements on 5 datasets and 10 models but supply no quantitative metrics, baseline names, budget-matching protocol, diversity measures, or drift calculation details, so the central empirical claim cannot be assessed for soundness or compared to the stated baselines.
Authors: The referee is correct that the current abstract and §4 lack explicit quantitative metrics, baseline names, and protocol details, limiting assessability. The full evaluation contains these elements, but they are not sufficiently highlighted. We will revise the abstract to report key numbers (e.g., fault exposure rates and diversity scores), explicitly name baselines (random latent mutation, gradient-based methods), detail the budget-matching protocol (equal test budget per method), specify diversity measures (prediction disagreement and unique output classes), and clarify drift calculation (LPIPS perceptual distance to seeds). Corresponding expansions will appear in §4. revision: yes
Circularity Check
No significant circularity; empirical method with independent evaluation
full rationale
The paper describes a testing framework (Latte) that encodes seeds via a pre-trained VQ-VAE, performs one-step anchor-directed mutations in latent space, quantizes, and decodes. Claims of improved fault exposure, diversity, and low semantic drift rest entirely on empirical comparisons across 5 datasets and 10 models under matched budgets. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The VQ-VAE is treated as an external pre-trained component whose properties are not derived within the paper; experimental results serve as the sole support and do not reduce to the method definition by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VQ-VAE latent space encodes semantically meaningful neighborhoods around input seeds
Reference graph
Works this paper leans on
-
[1]
Convo- lutional neural networks,
W. H. L. Pinaya, S. Vieira, R. Garcia-Dias, and A. Mechelli, “Convo- lutional neural networks,” inMachine learning. Elsevier, 2020, pp. 173–191
2020
-
[2]
A review on deep learning in medical image reconstruction,
H.-M. Zhang and B. Dong, “A review on deep learning in medical image reconstruction,”Journal of the Operations Research Society of China, vol. 8, no. 2, pp. 311–340, 2020
2020
-
[3]
Face recognition in unconstrained environment with cnn,
H. Ben Fredj, S. Bouguezzi, and C. Souani, “Face recognition in unconstrained environment with cnn,”The Visual Computer, vol. 37, no. 2, pp. 217–226, 2021
2021
-
[4]
Deepsec: A uniform platform for security analysis of deep learning model,
X. Ling, S. Ji, J. Zou, J. Wang, C. Wu, B. Li, and T. Wang, “Deepsec: A uniform platform for security analysis of deep learning model,” in 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 673–690
2019
-
[5]
Continuous integration, delivery and deployment: a systematic review on approaches, tools, challenges and practices,
M. Shahin, M. A. Babar, and L. Zhu, “Continuous integration, delivery and deployment: a systematic review on approaches, tools, challenges and practices,”IEEE access, vol. 5, pp. 3909–3943, 2017
2017
-
[6]
Survey on software defect prediction techniques,
M. K. Thota, F. H. Shajin, P. Rajeshet al., “Survey on software defect prediction techniques,”International Journal of Applied Science and Engineering, vol. 17, no. 4, pp. 331–344, 2020
2020
-
[7]
Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,
A. Nguyen, J. Yosinski, and J. Clune, “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 427–436. TRANSACTIONS ON SOFTW ARE ENGINEERING 13
2015
-
[8]
Effective white-box testing of deep neural networks with adaptive neuron-selection strategy,
S. Lee, S. Cha, D. Lee, and H. Oh, “Effective white-box testing of deep neural networks with adaptive neuron-selection strategy,” inProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, 2020, pp. 165–176
2020
-
[9]
Bet: black- box efficient testing for convolutional neural networks,
J. Wang, H. Qiu, Y . Rong, H. Ye, Q. Li, Z. Li, and C. Zhang, “Bet: black- box efficient testing for convolutional neural networks,” inProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, 2022, pp. 164–175
2022
-
[10]
Cit4dnn: Generating diverse and rare inputs for neural networks using latent space combinatorial testing,
S. Dola, R. McDaniel, M. B. Dwyer, and M. L. Soffa, “Cit4dnn: Generating diverse and rare inputs for neural networks using latent space combinatorial testing,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[11]
Targeted deep learning system boundary test- ing,
O. Weißl, A. Abdellatif, X. Chen, G. Merabishvili, V . Riccio, S. Ka- cianka, and A. Stocco, “Targeted deep learning system boundary test- ing,”ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[12]
Dlfuzz: Differential fuzzing testing of deep learning systems,
J. Guo, Y . Jiang, Y . Zhao, Q. Chen, and J. Sun, “Dlfuzz: Differential fuzzing testing of deep learning systems,” inProceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2018, pp. 739–743
2018
-
[13]
Tensorfuzz: De- bugging neural networks with coverage-guided fuzzing,
A. Odena, C. Olsson, D. Andersen, and I. Goodfellow, “Tensorfuzz: De- bugging neural networks with coverage-guided fuzzing,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 4901–4911
2019
-
[14]
Deepxplore: Automated whitebox testing of deep learning systems,
K. Pei, Y . Cao, J. Yang, and S. Jana, “Deepxplore: Automated whitebox testing of deep learning systems,” inproceedings of the 26th Symposium on Operating Systems Principles, 2017, pp. 1–18
2017
-
[15]
Diffchaser: Detecting disagreements for deep neural networks
X. Xie, L. Ma, H. Wang, Y . Li, Y . Liu, and X. Li, “Diffchaser: Detecting disagreements for deep neural networks.” International Joint Conferences on Artificial Intelligence Organization, 2019
2019
-
[16]
Atom: Automated black-box testing of multi-label image classification systems,
S. Hu, H. Wu, P. Wang, J. Chang, Y . Tu, X. Jiang, X. Niu, and C. Nie, “Atom: Automated black-box testing of multi-label image classification systems,” in2023 38th IEEE/ACM International Conference on Auto- mated Software Engineering (ASE). IEEE, 2023, pp. 230–242
2023
-
[17]
Deephunter: a coverage-guided fuzz testing framework for deep neural networks,
X. Xie, L. Ma, F. Juefei-Xu, M. Xue, H. Chen, Y . Liu, J. Zhao, B. Li, J. Yin, and S. See, “Deephunter: a coverage-guided fuzz testing framework for deep neural networks,” inProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis, 2019, pp. 146–157
2019
-
[18]
Cyber third-party risk management: A comparison of non-intrusive risk scoring reports,
O. F. Keskin, K. M. Caramancion, I. Tatar, O. Raza, and U. Tatar, “Cyber third-party risk management: A comparison of non-intrusive risk scoring reports,”Electronics, vol. 10, no. 10, p. 1168, 2021
2021
-
[19]
It is not (only) about privacy: How multi-party computation redefines control, trust, and risk in data sharing,
W. Agahari, H. Ofe, and M. de Reuver, “It is not (only) about privacy: How multi-party computation redefines control, trust, and risk in data sharing,”Electronic markets, vol. 32, no. 3, pp. 1577–1602, 2022
2022
-
[20]
Sinvad: Search-based image space nav- igation for dnn image classifier test input generation,
S. Kang, R. Feldt, and S. Yoo, “Sinvad: Search-based image space nav- igation for dnn image classifier test input generation,” inProceedings of the IEEE/ACM 42nd International Conference on Software Engineering Workshops, 2020, pp. 521–528
2020
-
[21]
Distribution-aware testing of neural networks using generative models,
S. Dola, M. B. Dwyer, and M. L. Soffa, “Distribution-aware testing of neural networks using generative models,” in2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 2021, pp. 226–237
2021
-
[22]
beta-vae: Learning basic visual concepts with a constrained variational framework,
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-vae: Learning basic visual concepts with a constrained variational framework,” inInternational conference on learning representations, 2017
2017
-
[23]
Auto-Encoding Variational Bayes
D. P. Kingma, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[24]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[25]
The robustness of deep networks: A geometrical perspective,
A. Fawzi, S.-M. Moosavi-Dezfooli, and P. Frossard, “The robustness of deep networks: A geometrical perspective,” inIEEE Signal Processing Magazine, vol. 34, no. 6, 2017, pp. 50–62
2017
-
[26]
[Online]
(2026) Latte. [Online]. Available: https://github.com/beanduan22/Latte
2026
-
[27]
Representation learning: A review and new perspectives,
Y . Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,”IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 8, pp. 1798–1828, 2013
2013
-
[28]
Latent space explanation by intervention,
I. Gat, G. Lorberbom, I. Schwartz, and T. Hazan, “Latent space explanation by intervention,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 1, 2022, pp. 679–687
2022
-
[29]
Interpreting the latent space of gans for semantic face editing,
Y . Shen, J. Gu, X. Tang, and B. Zhou, “Interpreting the latent space of gans for semantic face editing,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9243– 9252
2020
-
[30]
Understanding disentangling in $\beta$-VAE
C. P. Burgess, I. Higgins, A. Pal, L. Matthey, N. Watters, G. Desjardins, and A. Lerchner, “Understanding disentangling in backslash beta-vae,” arXiv preprint arXiv:1804.03599, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
VideoGPT: Video Generation using VQ-VAE and Transformers
W. Yan, Y . Zhang, P. Abbeel, and A. Srinivas, “Videogpt: Video gener- ation using vq-vae and transformers,”arXiv preprint arXiv:2104.10157, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Mnist handwritten digit database,
Y . LeCun, C. Cortes, and C. J. Burges, “Mnist handwritten digit database,” http://yann.lecun.com/exdb/mnist, 2010
2010
-
[33]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[34]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y . Nget al., “Reading digits in natural images with unsupervised feature learning,” inNIPS workshop on deep learning and unsupervised feature learning, vol. 2011, no. 2. Granada, 2011, p. 4
2011
-
[36]
Striving for Simplicity: The All Convolutional Net
J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller, “Striving for simplicity: The all convolutional net,”arXiv preprint arXiv:1412.6806, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[37]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” https://www.cs.toronto.edu/ ∼kriz/ learning-features-2009-TR.pdf, Citeseer, Tech. Rep., 2009
2009
-
[38]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[39]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[40]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009, pp. 248–255
2009
-
[41]
Emerging properties in self- supervised vision transformers,
M. Caron, H. Touvron, I. Misraet al., “Emerging properties in self- supervised vision transformers,” inProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), 2021
2021
-
[42]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanniet al., “Dinov2: Learning robust visual features without supervision,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[43]
Vision Transformers Need Registers
T. Darcet, M. Oquabet al., “Vision transformers need registers,”arXiv preprint arXiv:2309.16588, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
A survey on adversarial attacks and defences,
A. Chakraborty, M. Alam, V . Dey, A. Chattopadhyay, and D. Mukhopad- hyay, “A survey on adversarial attacks and defences,”CAAI Transactions on Intelligence Technology, vol. 6, no. 1, pp. 25–45, 2021
2021
-
[45]
Adversarial Attacks on Neural Network Policies
S. Huang, N. Papernot, I. Goodfellow, Y . Duan, and P. Abbeel, “Adversarial attacks on neural network policies,”arXiv preprint arXiv:1702.02284, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Evaluating the robustness of deep learning models against adversarial attacks: An analysis with fgsm, pgd and cw,
W. Villegas-Ch, A. Jaramillo-Alc ´azar, and S. Luj ´an-Mora, “Evaluating the robustness of deep learning models against adversarial attacks: An analysis with fgsm, pgd and cw,”Big Data and Cognitive Computing, vol. 8, no. 1, p. 8, 2024
2024
-
[47]
Unsupervised discovery of interpretable directions in the gan latent space,
A. V oynov and A. Babenko, “Unsupervised discovery of interpretable directions in the gan latent space,” inInternational conference on machine learning. PMLR, 2020, pp. 9786–9796
2020
-
[48]
Deeptest: Automated testing of deep-neural-network-driven autonomous cars,
Y . Tian, K. Pei, S. Jana, and B. Ray, “Deeptest: Automated testing of deep-neural-network-driven autonomous cars,” inProceedings of the 40th international conference on software engineering, 2018, pp. 303– 314
2018
-
[49]
Deephyperion: exploring the feature space of deep learning-based systems through illumination search,
T. Zohdinasab, V . Riccio, A. Gambi, and P. Tonella, “Deephyperion: exploring the feature space of deep learning-based systems through illumination search,” inProceedings of the 30th ACM SIGSOFT Inter- national Symposium on Software Testing and Analysis, 2021, pp. 79–90
2021
-
[50]
Model-based exploration of the frontier of behaviours for deep learning system testing,
V . Riccio and P. Tonella, “Model-based exploration of the frontier of behaviours for deep learning system testing,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2020, pp. 876– 888
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.