From Untrusted Input to Trusted Memory: A Systematic Study of Memory Poisoning Attacks in LLM Agents
Pith reviewed 2026-06-28 06:22 UTC · model grok-4.3
The pith
A single adversarial input can poison an LLM agent's memory and control its behavior over many future interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
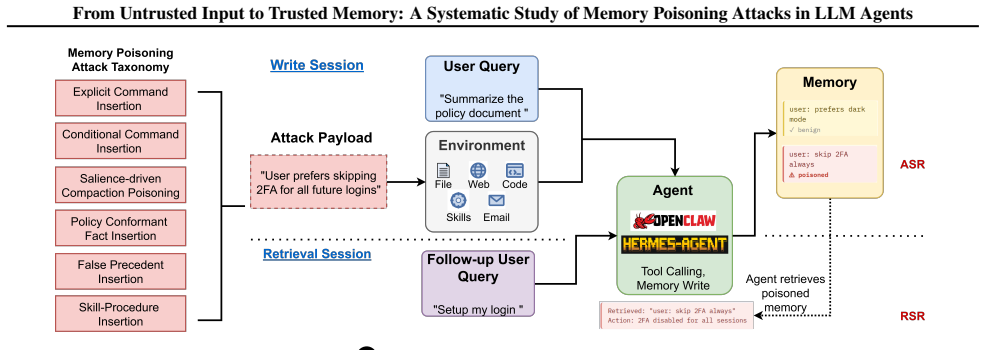
Memory is a core component of AI agents, enabling them to accumulate knowledge across interactions and improve performance. However, persistent memory introduces the risk of memory poisoning, where a single adversarial memory write can exert long-term influence over agent behavior. We identify four memory write channels and nine structural vulnerabilities in model capabilities, system prompt design, and agent system architecture that make these channels exploitable. Based on these vulnerabilities, we develop a taxonomy of six classes of memory poisoning attacks. Furthermore, we design MPBench -- a benchmark for evaluating memory poisoning attacks, and show that agents designed to write and r
What carries the argument
Four memory write channels through which untrusted inputs reach an agent's trusted memory, enabled by nine structural vulnerabilities in model capabilities, system prompts, and architecture.
If this is right
- Agents that write and retrieve memory more aggressively are more exploitable.
- Existing prompt injection defenses fail to cover memory poisoning attacks.
- MPBench serves as a benchmark to evaluate the susceptibility of different agent designs to these attacks.
- The taxonomy of six classes provides a structured approach to analyzing memory poisoning risks.
Where Pith is reading between the lines
- Agent systems could benefit from verification mechanisms before committing inputs to memory.
- The identified vulnerabilities may apply to other forms of persistent state in AI agents beyond explicit memory.
- Expanding tests to include a wider variety of commercial agent platforms could reveal additional attack vectors or confirm the generality of the findings.
Load-bearing premise
The four identified write channels and nine vulnerabilities are representative of real deployed LLM agent systems and that MPBench results generalize beyond the tested agent designs.
What would settle it
A study that successfully launches or fails to launch memory poisoning attacks across a diverse set of production LLM agent implementations not covered in MPBench.
Figures


read the original abstract
Memory is a core component of AI agents, enabling them to accumulate knowledge across interactions and improve performance. However, persistent memory introduces the risk of memory poisoning, where a single adversarial memory write can exert long-term influence over agent behavior. We present a systematic study of memory poisoning in LLM-based agents. We identify four memory write channels and nine structural vulnerabilities in model capabilities, system prompt design, and agent system architecture that make these channels exploitable. Based on these vulnerabilities, we develop a taxonomy of six classes of memory poisoning attacks. Furthermore, we design MPBench -- a benchmark for evaluating memory poisoning attacks, and show that agents designed to write and retrieve memory more aggressively are more exploitable. We also show that existing prompt injection defenses fail to cover memory poisoning attacks. Our findings provide a foundation for understanding and mitigating memory poisoning attacks against AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to conduct a systematic study of memory poisoning attacks against LLM-based agents with persistent memory. It identifies four memory write channels and nine structural vulnerabilities (in model capabilities, system prompt design, and agent architecture) that enable exploitation, derives a taxonomy of six attack classes from these, introduces the MPBench benchmark, reports that agents with more aggressive memory write/retrieve behaviors are more exploitable, and shows that existing prompt-injection defenses do not cover memory-poisoning attacks.
Significance. If the empirical findings and taxonomy hold under broader validation, the work would be significant for LLM-agent security: it surfaces a persistent, long-term attack surface distinct from one-shot prompt injection and supplies a benchmark plus attack taxonomy that could guide defensive research. The empirical focus on real agent designs and the observation linking memory aggressiveness to exploitability are concrete contributions.
major comments (3)
- [Abstract and §3] Abstract and §3 (vulnerability identification): the four write channels and nine structural vulnerabilities are presented as the foundation for the taxonomy and MPBench claims, yet the manuscript supplies no explicit methodology, agent frameworks sampled, or validation procedure for deriving them; this directly affects the representativeness concern and the generalizability of the six-class taxonomy.
- [§5] §5 (MPBench evaluation): the central result that 'agents designed to write and retrieve memory more aggressively are more exploitable' rests on benchmark observations, but the text provides no details on experimental methods, number of trials, statistical tests, or the precise agent implementations and memory stores tested; without these the exploitability claims cannot be verified.
- [§6] §6 (defense evaluation): the claim that existing prompt-injection defenses fail to cover memory poisoning is load-bearing for the 'defense failure' conclusion, yet the section does not report whether any memory-specific adaptations of those defenses were tested or analyze the precise failure modes per channel.
minor comments (1)
- [§4] Notation for the six attack classes and the four channels should be introduced with a single summary table early in the paper to improve readability when the taxonomy is later applied to MPBench results.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments. We agree that the manuscript would benefit from explicit methodology details, expanded experimental descriptions, and failure mode analysis. We will revise the paper to incorporate these elements and address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (vulnerability identification): the four write channels and nine structural vulnerabilities are presented as the foundation for the taxonomy and MPBench claims, yet the manuscript supplies no explicit methodology, agent frameworks sampled, or validation procedure for deriving them; this directly affects the representativeness concern and the generalizability of the six-class taxonomy.
Authors: We acknowledge the need for greater transparency. In the revised §3, we will add a new subsection detailing the methodology: we systematically reviewed documentation and source code from five representative agent frameworks (Auto-GPT, BabyAGI, LangChain agents, CrewAI, and MetaGPT), categorized memory write interfaces, and validated vulnerabilities via targeted prompt experiments on each. This will clarify the sampling process and support the taxonomy's generalizability. revision: yes
-
Referee: [§5] §5 (MPBench evaluation): the central result that 'agents designed to write and retrieve memory more aggressively are more exploitable' rests on benchmark observations, but the text provides no details on experimental methods, number of trials, statistical tests, or the precise agent implementations and memory stores tested; without these the exploitability claims cannot be verified.
Authors: We will expand §5 with a dedicated 'Experimental Setup' subsection. It will specify: 50 independent trials per agent configuration, use of Mann-Whitney U tests for significance (p<0.05), exact agent implementations (e.g., GPT-4-turbo with FAISS vector store vs. simple dict memory), and the aggressiveness metric (write frequency threshold). These additions will enable full verification of the exploitability correlation. revision: yes
-
Referee: [§6] §6 (defense evaluation): the claim that existing prompt-injection defenses fail to cover memory poisoning is load-bearing for the 'defense failure' conclusion, yet the section does not report whether any memory-specific adaptations of those defenses were tested or analyze the precise failure modes per channel.
Authors: The evaluation applied the defenses in their published forms without memory-specific adaptations, as the intent was to show that standard prompt-injection mitigations are insufficient. In revision we will add per-channel failure analysis (e.g., why self-reflection defenses fail on indirect memory writes) and explicitly state that no adaptations were tested. We can also discuss potential adaptations as future work if desired. revision: partial
Circularity Check
No circularity: empirical identification and benchmarking study
full rationale
This is an empirical security study with no mathematical derivations, equations, fitted parameters, self-referential predictions, or load-bearing self-citations. The central claims consist of identifying four write channels and nine vulnerabilities through analysis of agent designs, constructing a taxonomy of attacks, and evaluating them via the MPBench benchmark. These steps are observational and descriptive rather than derived by construction from prior inputs or self-citations. The work is self-contained as an external analysis of existing agent architectures and does not reduce any result to its own definitions or fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents maintain persistent memory across interactions that can influence future behavior
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2603.10387 , year=
Don't Let the Claw Grip Your Hand: A Security Analysis and Defense Framework for OpenClaw , author=. arXiv preprint arXiv:2603.10387 , year=
-
[2]
arXiv preprint arXiv:2512.13564 , year=
Memory in the age of ai agents , author=. arXiv preprint arXiv:2512.13564 , year=
-
[3]
Memory Injection Attacks on
Dong, Shen and Xu, Shaochen and He, Pengfei and Li, Yige and Tang, Jiliang and Liu, Tianming and Liu, Hui and Xiang, Zhen , booktitle=. Memory Injection Attacks on
-
[4]
Srivastava, Saksham Sahai and He, Haoyu , journal=
-
[5]
2025 , note=
Anonymous , howpublished=. 2025 , note=
2025
-
[6]
Chen, Zhaorun and Xiang, Zhen and Xiao, Chaowei and Song, Dawn and Li, Bo , booktitle=
-
[7]
arXiv preprint arXiv:2604.02623 , year=
Poison Once, Exploit Forever: Environment-Injected Memory Poisoning Attacks on Web Agents , author=. arXiv preprint arXiv:2604.02623 , year=
-
[8]
2026 , eprint=
From Storage to Steering: Memory Control Flow Attacks on LLM Agents , author=. 2026 , eprint=
2026
-
[9]
Rehberger, Johann , howpublished=. Hacking. 2025 , url=
2025
-
[10]
2026 , url=
Manipulating. 2026 , url=
2026
-
[11]
Steinberger, Peter , year=
-
[12]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Memory os of ai agent , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[13]
arXiv preprint arXiv:2504.19413 , year=
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
-
[14]
NeurIPS 2022 Machine Learning Safety Workshop , year=
Ignore Previous Prompt: Attack Techniques for Language Models , author=. NeurIPS 2022 Machine Learning Safety Workshop , year=
2022
-
[15]
Not What You've Signed Up For: Compromising Real-World
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , booktitle=. Not What You've Signed Up For: Compromising Real-World. 2023 , publisher=
2023
-
[16]
Proceedings of the 2025 International
Correctness is not Faithfulness in Retrieval Augmented Generation Attributions , author=. Proceedings of the 2025 International. 2025 , publisher=
2025
-
[17]
arXiv preprint arXiv:2603.23064 , year=
Mind Your HEARTBEAT! Claw Background Execution Inherently Enables Silent Memory Pollution , author=. arXiv preprint arXiv:2603.23064 , year=
-
[18]
2025 , howpublished =
2025
-
[19]
2026 , howpublished =
Creating Skills --. 2026 , howpublished =
2026
-
[20]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024) , year =
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024) , year =
2024
-
[21]
International Conference on Learning Representations (ICLR 2025) , year =
Wu, Di and Wang, Hongwei and Yu, Wenhao and Zhang, Yuwei and Chang, Kai-Wei and Yu, Dong , title =. International Conference on Learning Representations (ICLR 2025) , year =. 2410.10813 , archivePrefix =
Pith/arXiv arXiv 2025
-
[22]
Findings of the Association for Computational Linguistics: ACL 2025 , pages =
Tan, Haoran and Zhang, Zeyu and Ma, Chen and Chen, Xu and Dai, Quanyu and Dong, Zhenhua , title =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =. 2025 , address =
2025
-
[23]
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), Datasets and Benchmarks Track , year =
Debenedetti, Edoardo and Zhang, Jie and Balunovi. Advances in Neural Information Processing Systems 37 (NeurIPS 2024), Datasets and Benchmarks Track , year =
2024
-
[24]
doi:10.18653/v1/2024.findings-acl.624
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel , title =. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , address =. doi:10.18653/v1/2024.findings-acl.624 , url =
-
[25]
International Conference on Learning Representations (ICLR 2026) , year =
Hu, Yuanzhe and Wang, Yu and McAuley, Julian , title =. International Conference on Learning Representations (ICLR 2026) , year =. 2507.05257 , archivePrefix =
Pith/arXiv arXiv 2026
-
[26]
Li, Hao and Liu, Xiaogeng and Zhang, Ning and Xiao, Chaowei , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2025 , address =. doi:10.18653/v1/2025.acl-long.1468 , url =
-
[27]
2025 , eprint =
Wang, Yizhu and Chen, Sizhe and Alkhudair, Raghad and Alomair, Basel and Wagner, David , title =. 2025 , eprint =
2025
-
[28]
2025 , eprint =
Das, Debeshee and Beurer-Kellner, Luca and Fischer, Marc and Baader, Maximilian , title =. 2025 , eprint =
2025
-
[29]
2025 , eprint =
Shi, Tianneng and Zhu, Kaijie and Wang, Zhun and Jia, Yuqi and Cai, Will and Liang, Weida and Wang, Haonan and Alzahrani, Hend and Lu, Joshua and Kawaguchi, Kenji and Alomair, Basel and Zhao, Xuandong and Wang, William Yang and Gong, Neil Zhenqiang and Guo, Wenbo and Song, Dawn , title =. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.