NuGNN: a Graph Neural Network for Nuclear Reaction Network Equations
Pith reviewed 2026-06-28 04:26 UTC · model grok-4.3
The pith
A graph neural network surrogate for nuclear reaction networks reproduces final isotope abundance patterns when substituted for the original solver.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
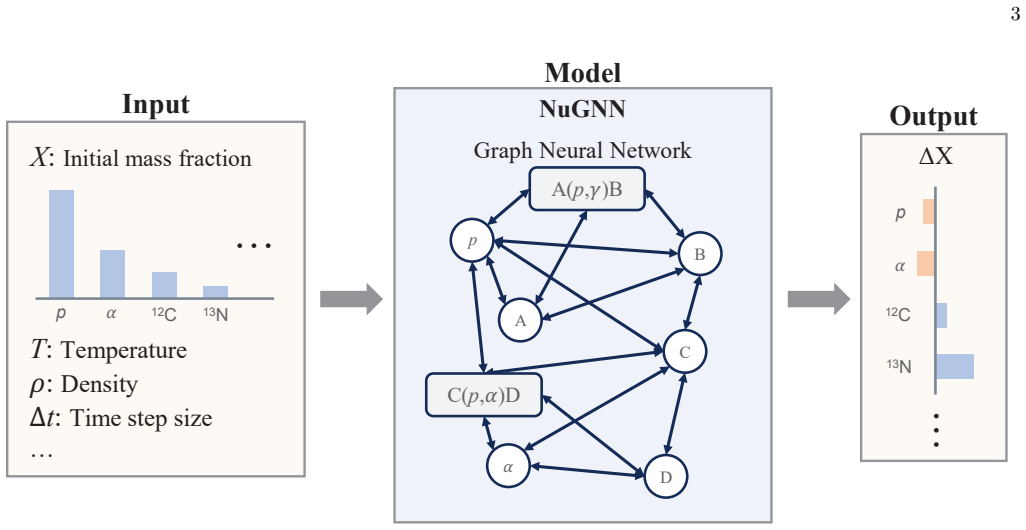
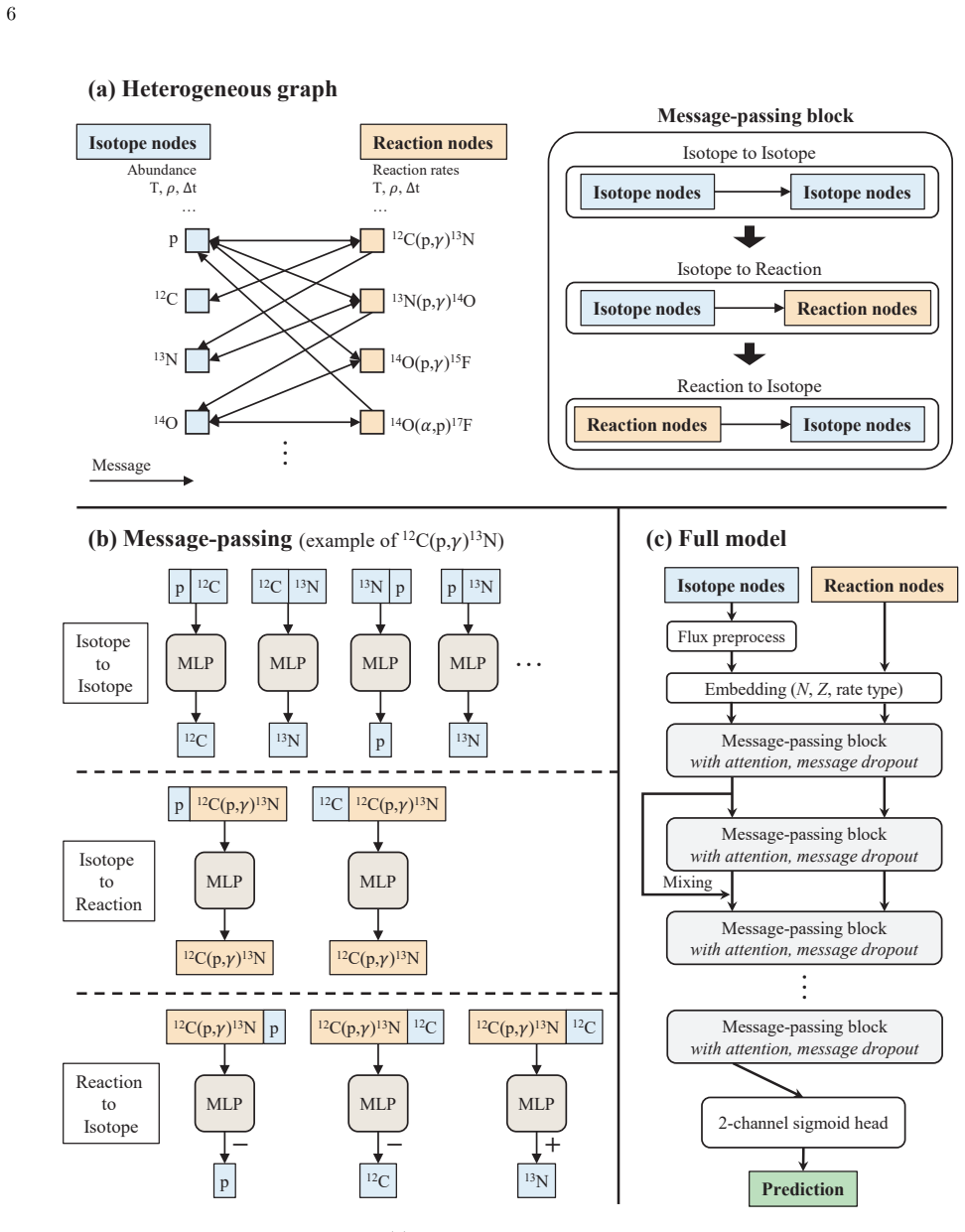
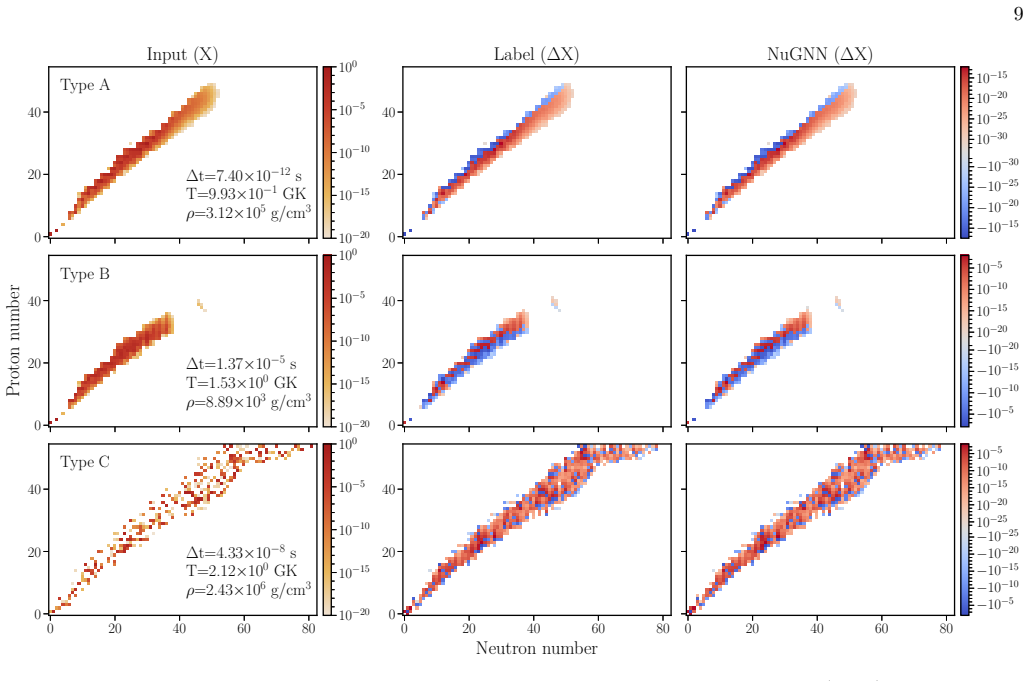
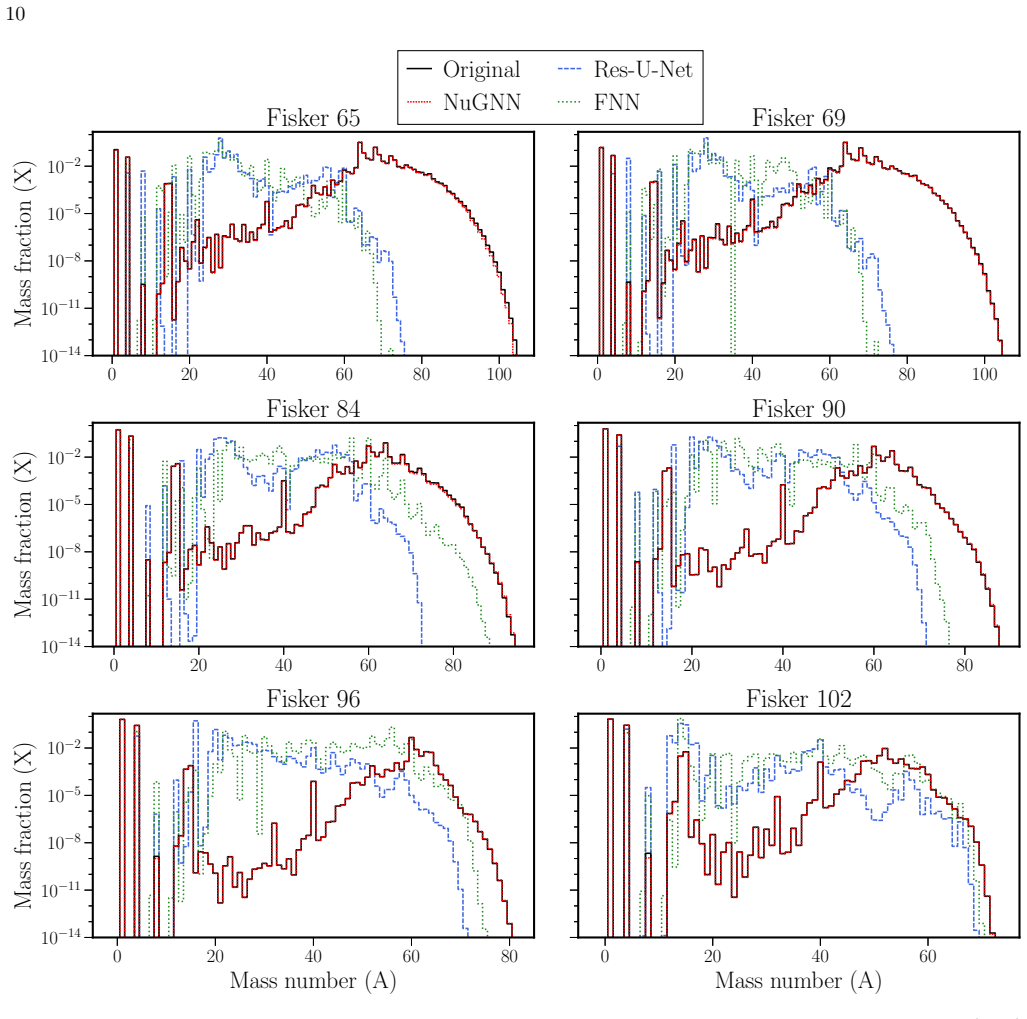
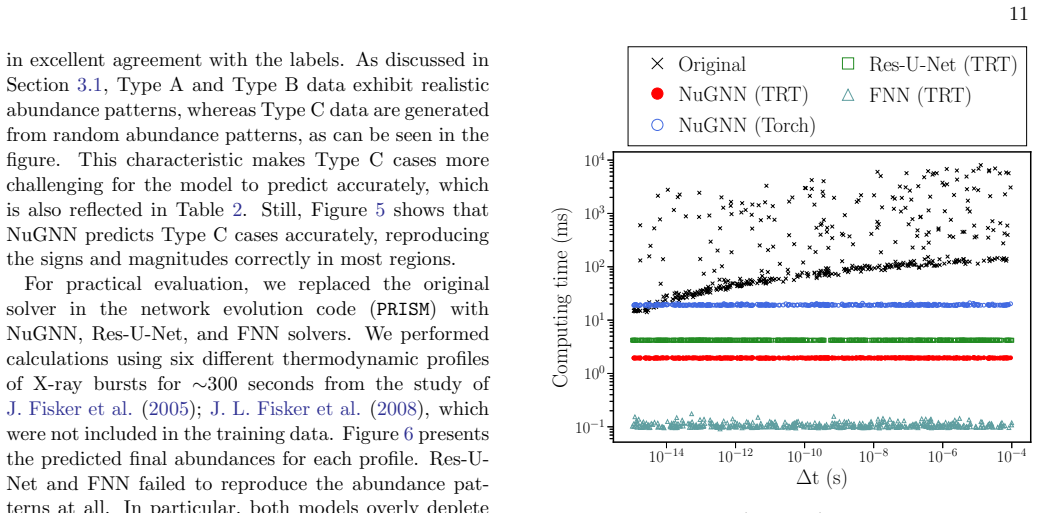
NuGNN directly reflects the structure of the reaction network through heterogeneous isotope and reaction nodes and message-passing along reaction connections. When implemented in the network evolution code in place of the original solver, NuGNN successfully reproduces the final abundance patterns, whereas the other architectures fail to do so. The trained model can substantially improve computational speed for a 690-isotope network under general Type I X-ray burst conditions.
What carries the argument
Heterogeneous graph with isotope nodes, reaction nodes, and message-passing along reaction connections used as a surrogate solver for the stiff network equations.
If this is right
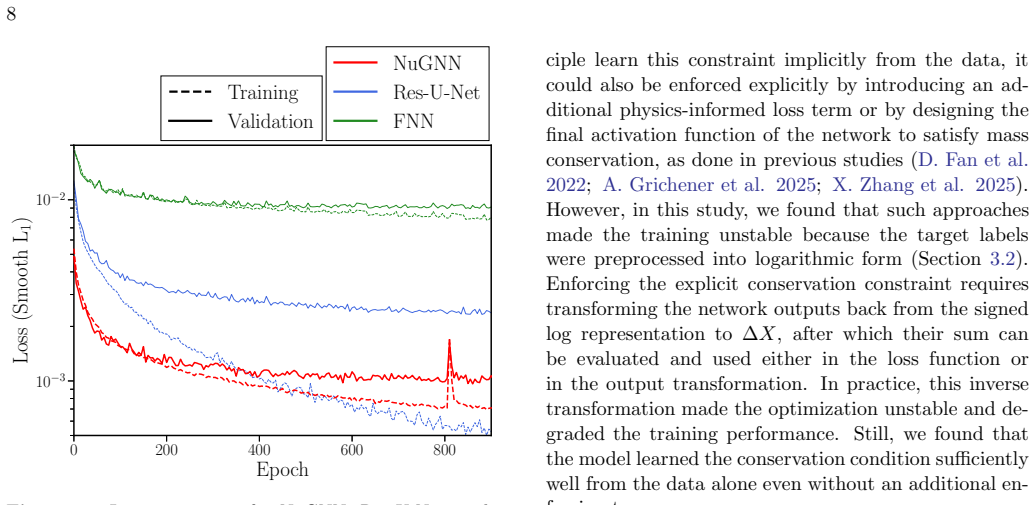
- NuGNN achieves significantly better accuracy than Res-U-Net or fully connected networks, with errors of only a few percent.
- The model can be substituted directly into existing network evolution codes and still recover correct final abundances.
- The trained surrogate substantially reduces computation time compared with the original implicit solver.
- The graph architecture succeeds on a 690-isotope network under conditions spanning many orders of magnitude in temperature and density.
Where Pith is reading between the lines
- The same graph construction could be applied to other large reaction networks whose topology is known, potentially extending the approach beyond X-ray bursts.
- Because the model respects the reaction graph, retraining on data from different astrophysical regimes might require less data than dense networks.
- Success here suggests that preserving the explicit reaction connectivity in the architecture is the key property that allows the surrogate to remain stable when integrated over many time steps.
Load-bearing premise
The training data spanning many orders of magnitude in temperature, density, and time-step size is sufficient to cover all conditions encountered during actual network evolution under Type I X-ray burst conditions.
What would settle it
A full network evolution run with NuGNN in place of the solver that produces final abundance patterns differing by more than a few percent from the original solver under X-ray burst conditions.
Figures
read the original abstract
Nuclear reaction networks are a major computational bottleneck in astrophysical simulations when large isotope sets are required, because of the stiffness of the network equations and the repeated calls to Jacobian-based solvers required by implicit methods. In this work, we develop a deep learning surrogate solver for a large 690-isotope nuclear reaction network under general Type I X-ray burst conditions using a graph neural network, NuGNN. Unlike conventional fully connected or convolutional neural networks, NuGNN directly reflects the structure of the reaction network through heterogeneous isotope and reaction nodes and message-passing along reaction connections. The model is trained on data spanning many orders of magnitude in stellar temperature and density and in simulation time step size. We compare NuGNN with a Res-U-Net and fully connected neural network and find that NuGNN consistently achieves significantly better accuracy with errors of only a few percent. More importantly, when implemented in the network evolution code in place of the original solver, NuGNN successfully reproduces the final abundance patterns, whereas the other architectures fail to do so. We also show that the trained model can substantially improve computational speed, demonstrating its practical potential for large-scale simulations. These results show that graph neural networks provide a robust and promising framework for accurate surrogate modeling of large nuclear reaction networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NuGNN, a graph neural network surrogate for solving the stiff equations of a 690-isotope nuclear reaction network under Type I X-ray burst conditions. The architecture uses heterogeneous isotope and reaction nodes with message passing along reaction edges. Trained on data spanning wide ranges of temperature, density, and time-step size, NuGNN is reported to achieve few-percent errors and to outperform both a Res-U-Net and a fully connected network. The central result is that, when substituted for the implicit solver inside the network evolution code, NuGNN reproduces the final abundance patterns while the other architectures do not, and it also provides a computational speedup.
Significance. If the closed-loop substitution result holds under varied conditions and time-stepping logic, the work would demonstrate a practical route to accelerating large nuclear networks in astrophysical simulations by replacing repeated Jacobian-based implicit solves with a fast, structure-preserving surrogate. The explicit encoding of the reaction graph is a methodological strength that distinguishes the approach from generic neural-network surrogates.
major comments (2)
- [Abstract] Abstract: the claim that NuGNN 'successfully reproduces the final abundance patterns' when implemented in the network evolution code is load-bearing for the practical utility argument, yet no quantitative metrics are supplied on per-isotope or integrated abundance errors over the full sequence of time steps, nor on whether the test used the same adaptive time-stepping logic as the production run.
- [Methods] Methods (training-data generation): the statement that training data span 'many orders of magnitude in stellar temperature and density and in simulation time step size' does not specify whether samples were drawn independently or along full evolutionary trajectories, nor whether the distribution covers the correlated abundance vectors and time-step sequences actually encountered during closed-loop integration; this directly affects the coverage assumption required for stable long-term evolution.
minor comments (1)
- The phrase 'errors of only a few percent' should be accompanied by the precise error metric (e.g., mean relative error per species, maximum error, or L2 norm) and by the distribution of errors across isotopes.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential significance of encoding the reaction network structure in NuGNN. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that NuGNN 'successfully reproduces the final abundance patterns' when implemented in the network evolution code is load-bearing for the practical utility argument, yet no quantitative metrics are supplied on per-isotope or integrated abundance errors over the full sequence of time steps, nor on whether the test used the same adaptive time-stepping logic as the production run.
Authors: We agree that quantitative metrics would strengthen the closed-loop result. In the revised manuscript we will add per-isotope relative errors and integrated abundance discrepancies evaluated over the full sequence of time steps in the substitution test, together with an explicit statement confirming that the test employed the identical adaptive time-stepping logic used in the production runs. revision: yes
-
Referee: [Methods] Methods (training-data generation): the statement that training data span 'many orders of magnitude in stellar temperature and density and in simulation time step size' does not specify whether samples were drawn independently or along full evolutionary trajectories, nor whether the distribution covers the correlated abundance vectors and time-step sequences actually encountered during closed-loop integration; this directly affects the coverage assumption required for stable long-term evolution.
Authors: The training data were generated by sampling along full evolutionary trajectories under the relevant conditions rather than from independent snapshots, precisely to ensure coverage of the correlated abundance vectors and time-step sequences that appear during closed-loop integration. We will expand the Methods section with an explicit description of this trajectory-based sampling procedure and the resulting coverage of the relevant parameter space. revision: yes
Circularity Check
No circularity; surrogate trained and tested on independent external data
full rationale
The paper trains NuGNN on simulation data generated from the original solver across wide ranges of T, rho, and dt, then substitutes the model into the independent network evolution code to check reproduction of final abundances. No equations reduce to fitted quantities by construction, no self-citation chains support load-bearing uniqueness claims, and no ansatzes or renamings are smuggled in. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network weights and biases
axioms (1)
- domain assumption The nuclear reaction network can be faithfully represented as a static heterogeneous graph whose edges capture all relevant reaction channels.
Reference graph
Works this paper leans on
-
[1]
Arcones, A., Bardayan, D. W., Beers, T. C., et al. 2017, Progress in Particle and Nuclear Physics, 94, 1, doi: https://doi.org/10.1016/j.ppnp.2016.12.003
-
[2]
Boehnlein, A., Diefenthaler, M., Sato, N., et al. 2022, Rev. Mod. Phys., 94, 031003, doi: 10.1103/RevModPhys.94.031003
-
[3]
2020, Monthly Notices of the Royal Astronomical Society, 494, 3037, doi: 10.1093/mnras/staa910
Bravo, E. 2020, Monthly Notices of the Royal Astronomical Society, 494, 3037, doi: 10.1093/mnras/staa910
-
[4]
Bruenn, S. W., Blondin, J. M., Hix, W. R., et al. 2020, The Astrophysical Journal Supplement Series, 248, 11, doi: 10.3847/1538-4365/ab7aff
-
[5]
Cowan, J. J., Sneden, C., Lawler, J. E., et al. 2021, Reviews of Modern Physics, 93, 015002, doi: 10.1103/RevModPhys.93.015002
-
[6]
2022, The Astrophysical Journal, 940, 134, doi: 10.3847/1538-4357/ac9a4b
Nonaka, A. 2022, The Astrophysical Journal, 940, 134, doi: 10.3847/1538-4357/ac9a4b
-
[7]
Farmer, R., Fields, C. E., Petermann, I., et al. 2016, The Astrophysical Journal Supplement Series, 227, 22, doi: 10.3847/1538-4365/227/2/22
-
[8]
2005, Nuclear Physics A, 752, 604, doi: https://doi.org/10.1016/j.nuclphysa.2005.02.063
Fisker, J., Brown, E., Liebend¨ orfer, M., Thielemann, F.-K ., & Wiescher, M. 2005, Nuclear Physics A, 752, 604, doi: https://doi.org/10.1016/j.nuclphysa.2005.02.063
-
[9]
L., Schatz, H., & Thielemann, F.-K
Fisker, J. L., Schatz, H., & Thielemann, F.-K. 2008, The Astrophysical Journal Supplement Series, 174, 261, doi: 10.1086/521104
-
[10]
2016, in Proceedings of Machine Learning Research, Vol
Gal, Y., & Ghahramani, Z. 2016, in Proceedings of Machine Learning Research, Vol. 48, Proceedings of The 33rd International Conference on Machine Learning, ed. M. F. Balcan & K. Q. Weinberger (New York, New York, USA: PMLR), 1050–1059 13
2016
-
[11]
Dahl, G. E. 2017, in Proceedings of Machine Learning
2017
-
[12]
2015, in Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Santiago, Chile: IEEE Computer Society), 1440–1448
Girshick, R. 2015, in Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Santiago, Chile: IEEE Computer Society), 1440–1448
2015
-
[13]
Grichener, A., Renzo, M., Kerzendorf, W. E., et al. 2025, The Astrophysical Journal Supplement Series, 279, 49, doi: 10.3847/1538-4365/ade717
-
[14]
2016, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Las Vegas, NV, USA: IEEE Computer Society)
He, K., Zhang, X., Ren, S., & Sun, J. 2016, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Las Vegas, NV, USA: IEEE Computer Society)
2016
-
[15]
Hix, W. R., & Meyer, B. S. 2006, Nuclear Physics A, 777, 188, doi: https://doi.org/10.1016/j.nuclphysa.2004.10.009 Ioffe, S., & Szegedy, C. 2015, in Proceedings of the 32nd International Conference on Machine Learning, Vol. 37 (Lille, France: PMLR), 448–456
-
[16]
Jermyn, A. S., Bauer, E. B., Schwab, J., et al. 2023, The Astrophysical Journal Supplement Series, 265, 15, doi: 10.3847/1538-4365/acae8d
-
[17]
2022, The Astrophysical Journal, 929, 96, doi: 10.3847/1538-4357/ac5f09
Kim, C., Chae, K., Cha, S., et al. 2022, The Astrophysical Journal, 929, 96, doi: 10.3847/1538-4357/ac5f09
-
[18]
Kim, C. H., Chae, K. Y., & Smith, M. S. 2026, Phys. Rev. C, 113, 024308, doi: 10.1103/mcxf-d32x
-
[19]
Kim, C. H., Chae, K. Y., Smith, M. S., et al. 2024, Phys. Rev. C, 110, 054609, doi: 10.1103/PhysRevC.110.054609
-
[20]
P., & Ba, J
Kingma, D. P., & Ba, J. 2015, in Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA
2015
-
[21]
2017, in Advances in Neural Information Processing Systems, ed
Lakshminarayanan, B., Pritzel, A., & Blundell, C. 2017, in Advances in Neural Information Processing Systems, ed. I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett, Vol. 30 (Red
2017
-
[22]
Lampe, N., Heger, A., & Galloway, D. K. 2016, The Astrophysical Journal, 819, 46, doi: 10.3847/0004-637X/819/1/46
-
[23]
Lippuner, J., & Roberts, L. F. 2017, The Astrophysical Journal Supplement Series, 233, 18, doi: 10.3847/1538-4365/aa94cb
-
[24]
L., Hannun, A
Maas, A. L., Hannun, A. Y., & Ng, A. Y. 2013, in Proceedings of the ICML Workshop on Deep Learning for Audio, Speech, and Language Processing, Atlanta,
2013
-
[25]
2018, ApJ, 860, 147, doi: https://doi.org/10.3847/1538-4357/aac3d3 M¨ oller, P., Sierk, A
Meisel, Z. 2018, ApJ, 860, 147, doi: https://doi.org/10.3847/1538-4357/aac3d3 M¨ oller, P., Sierk, A. J., Ichikawa, T., & Sagawa, H. 2016, Atomic Data and Nuclear Data Tables, 109, 1, doi: 10.1016/j.adt.2015.10.002
-
[26]
R., Kawano, T., Korobkin, O., Misch, G
Mumpower, M. R., Kawano, T., Korobkin, O., Misch, G. W., & Sprouse, T. M. 2025, Atomic Data and Nuclear Data Tables, 165, 101736, doi: 10.1016/j.adt.2025.101736 Nav´ o, G., Reichert, M., Obergaulinger, M., & Arcones, A. 2023, The Astrophysical Journal, 951, 112, doi: 10.3847/1538-4357/acd640
-
[27]
2019, in Advances in Neural Information Processing Systems, Vol
Paszke, A., Gross, S., Massa, F., et al. 2019, in Advances in Neural Information Processing Systems, Vol. 32 (Red
2019
-
[28]
2015, ApJS, 220, 15, doi: 10.1088/0067-0049/220/1/15
Paxton, B., Marchant, P., Schwab, J., et al. 2015, ApJS, 220, 15, doi: https://doi.org/10.1088/0067-0049/220/1/15
work page internal anchor Pith review doi:10.1088/0067-0049/220/1/15 2015
-
[29]
Courville, A. 2018, Proceedings of the AAAI Conference on Artificial Intelligence, 32, doi: 10.1609/aaai.v32i1.11671
-
[30]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Qiu, Z., Wang, Z., Zheng, B., et al. 2025, arXiv e-prints, arXiv:2505.06708, doi: 10.48550/arXiv.2505.06708
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.06708 2025
-
[31]
2023, The Astrophysical Journal Supplement Series, 268, 66, doi: 10.3847/1538-4365/acf033
Reichert, M., Winteler, C., Korobkin, O., et al. 2023, The Astrophysical Journal Supplement Series, 268, 66, doi: 10.3847/1538-4365/acf033
-
[32]
2015, in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, ed
Ronneberger, O., Fischer, P., & Brox, T. 2015, in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, ed. N. Navab, J. Hornegger, W. M. Wells, & A. F. Frangi (Cham: Springer International Publishing), 234–241
2015
-
[33]
The graph neural network model.IEEE Transactions on Neural Networks, 20(1):61–80, 2009
Monfardini, G. 2009, IEEE Transactions on Neural Networks, 20, 61, doi: 10.1109/TNN.2008.2005605
-
[34]
2006, Nuclear Physics A, 777, 601, doi: https://doi.org/10.1016/j.nuclphysa.2005.05.200
Schatz, H., & Rehm, K. 2006, Nuclear Physics A, 777, 601, doi: https://doi.org/10.1016/j.nuclphysa.2005.05.200
-
[35]
2001, NuPhA, 688, 150, doi: 10.1016/S0375-9474(01)00688-1
Schatz, H., Aprahamian, A., Barnard, V., et al. 2001, NuPhA, 688, 150, doi: 10.1016/S0375-9474(01)00688-1
-
[36]
Smith, M. S., & Lu, D. 2024, Frontiers in Astronomy and Space Sciences, Volume 11 - 2024, doi: 10.3389/fspas.2024.1494439
-
[37]
Sprouse, T. M., Mumpower, M. R., & Surman, R. 2021, Phys. Rev. C, 104, 015803, doi: 10.1103/PhysRevC.104.015803
-
[38]
Timmes, F. X. 1999, The Astrophysical Journal Supplement Series, 124, 241, doi: 10.1086/313257
-
[39]
Timmes, F. X., Hoffman, R. D., & Woosley, S. E. 2000, The Astrophysical Journal Supplement Series, 129, 377, doi: 10.1086/313407
-
[40]
Travaglio, C., & Raphael Hix, W. 2013, Frontiers of Physics, 8, 199, doi: 10.1007/s11467-013-0315-y 14 Veliˇ ckovi´ c, P., Cucurull, G., Casanova, A., et al. 2018, in Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada
-
[41]
Wang, X., He, X., Wang, M., Feng, F., & Chua, T.-S. 2019, in Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (New York, NY, USA: Association for Computing Machinery), 165–174, doi: 10.1145/3331184.3331267
-
[42]
2025, The Astrophysical Journal, 990, 105, doi: 10.3847/1538-4357/adf331
Zhang, X., Yi, Y., Wang, L., et al. 2025, The Astrophysical Journal, 990, 105, doi: 10.3847/1538-4357/adf331
-
[43]
Zhu, Y. L., Lund, K. A., Barnes, J., et al. 2021, ApJ, 906, 94, doi: 10.3847/1538-4357/abc69e
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.