Impostor: An Agent-Curated Benchmark for Realistic AIGC Manipulation Localization
Pith reviewed 2026-06-28 06:47 UTC · model grok-4.3
The pith
A benchmark of 100,000 agent-generated AIGC edits shows that existing detection methods miss realistic manipulations, while a phase-aware network localizes them more accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
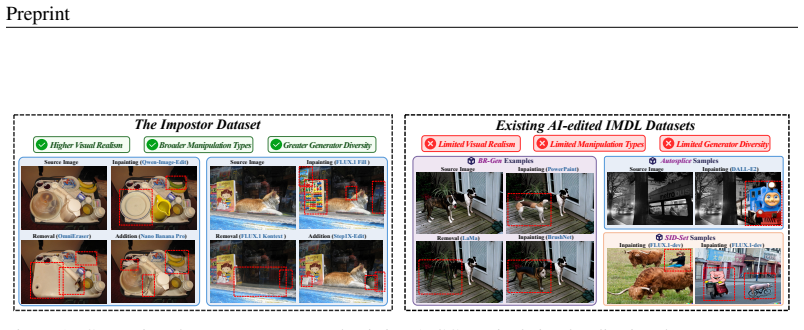
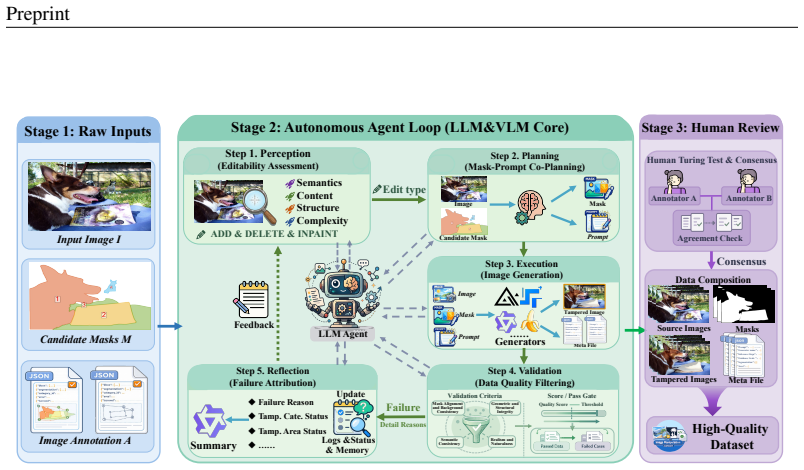
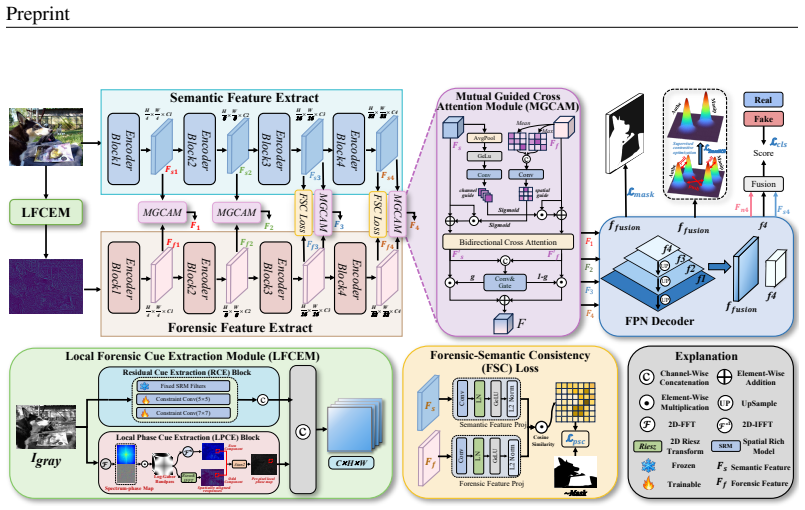
Impostor supplies 100K images spanning seven recent AIGC models, three manipulation types, and multiple regions per image, all produced through the closed-loop CraftAgent pipeline of perception, planning, execution, validation, and reflection. PANet improves localization accuracy by combining local phase spectrum analysis with learning that enforces consistency between semantic content and forensic signals, outperforming prior specialized IMDL methods and large vision-language models on both Impostor and public benchmarks.
What carries the argument
CraftAgent, the closed-loop agent framework that automatically assembles realistic multi-model AIGC manipulations through iterative scene perception, editing planning, execution, quality validation, and reflection.
If this is right
- Current large vision-language models and specialized IMDL detectors will record lower localization scores on Impostor than on prior benchmarks.
- Methods that ignore phase spectra or semantic-forensic mismatches will continue to underperform on multi-region, multi-generator edits.
- Future benchmarks must include agent-driven generation loops to match the controllability of recent AIGC tools.
- PANet-style consistency learning between semantics and forensics provides a measurable route to higher precision on plausible-looking edits.
Where Pith is reading between the lines
- The same agent loop used to build the benchmark could be inverted to synthesize harder training examples for detector improvement.
- If the realism claim holds, forensic pipelines in practice will need periodic refresh cycles tied to new AIGC releases rather than static datasets.
- The multi-region aspect suggests that localization metrics should weight per-region difficulty rather than treating whole-image scores as sufficient.
Load-bearing premise
The agent-generated images are realistic enough and representative enough of real-world AIGC edits that performance gaps on this dataset actually predict real-world detection failures.
What would settle it
Independent collection of real AIGC-manipulated images from the same seven generators where PANet shows no accuracy gain over prior methods, or where human raters find the Impostor images distinguishable from authentic edits at rates no higher than older benchmarks.
Figures
read the original abstract
Recent advances in generative image editing have improved the realism and controllability of localized image manipulation, raising new challenges for image manipulation detection and localization (IMDL). However, existing IMDL benchmarks still have limitations in visual realism, manipulation diversity, and generator coverage, making it difficult to reflect recent trends in image manipulation. To address these limitations, we introduce Impostor, a high-quality AI-edited image manipulation localization dataset containing 100K manipulated images. Impostor is constructed by CraftAgent, a closed-loop agent framework that integrates scene perception, editing planning, manipulation execution, quality validation, and iterative reflection to automatically generate diverse and visually realistic manipulated images. Moreover, Impostor contains images generated by seven recent AIGC models across three manipulation types and includes multiple manipulated regions, providing a more comprehensive benchmark for AIGC-based IMDL. Furthermore, we propose PhaseAware-Net (PANet), a semantic-forensic framework that introduces local phase modeling and semantic-forensic consistency learning to better localize semantically plausible yet forensically disrupted manipulated regions. Extensive experiments show that Impostor poses significant challenges to existing large vision-language models (LVLMs) and specialized IMDL methods, while PANet achieves superior performance on Impostor and multiple public benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Impostor, a benchmark dataset of 100K AI-generated manipulated images for image manipulation detection and localization (IMDL). Images are produced by CraftAgent, a closed-loop agent framework integrating scene perception, editing planning, manipulation execution, quality validation, and iterative reflection. The dataset spans seven recent AIGC models, three manipulation types, and multiple regions per image. The authors also propose PhaseAware-Net (PANet), which incorporates local phase modeling and semantic-forensic consistency learning. They claim that Impostor poses significant challenges to existing large vision-language models and specialized IMDL methods, while PANet achieves superior performance on Impostor and multiple public benchmarks.
Significance. If the generated manipulations prove realistic and representative, Impostor would meaningfully advance IMDL evaluation by addressing gaps in visual realism, manipulation diversity, and generator coverage compared to prior benchmarks. The agent-based curation approach is a strength for scalable, diverse data creation. PANet's combination of phase-based forensic cues with semantic consistency offers a plausible technical direction for detecting semantically plausible edits. Credit is due for the scale of the dataset and the explicit multi-generator coverage.
major comments (1)
- [Abstract and CraftAgent framework description] Abstract and the CraftAgent description (presumed §3–4): The headline claims that Impostor consists of 'visually realistic' and 'diverse' manipulations that 'pose significant challenges' to existing methods, and that PANet is superior, rest on the assumption that the 100K images are free of agent-specific artifacts and representative of real AIGC edits. No quantitative realism metrics, human forensic ratings, distributional comparisons to external real edits, or ablation of the reflection step are supplied. This is load-bearing for the central benchmark claim; without it, performance gaps may be benchmark-specific rather than general.
minor comments (1)
- [Abstract] The abstract asserts 'extensive experiments' and 'superior performance' but supplies no numerical results, dataset statistics, or validation procedures; these must be presented with tables and ablations in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of Impostor’s realism and representativeness. We address this central concern below and commit to revisions that directly strengthen the benchmark claims.
read point-by-point responses
-
Referee: [Abstract and CraftAgent framework description] Abstract and the CraftAgent description (presumed §3–4): The headline claims that Impostor consists of 'visually realistic' and 'diverse' manipulations that 'pose significant challenges' to existing methods, and that PANet is superior, rest on the assumption that the 100K images are free of agent-specific artifacts and representative of real AIGC edits. No quantitative realism metrics, human forensic ratings, distributional comparisons to external real edits, or ablation of the reflection step are supplied. This is load-bearing for the central benchmark claim; without it, performance gaps may be benchmark-specific rather than general.
Authors: We agree this is a substantive gap. While CraftAgent’s closed-loop design (scene perception, quality validation, and iterative reflection) is intended to reduce artifacts and produce realistic edits, the manuscript does not provide the requested quantitative or human validation. In the revised version we will add: (1) FID and perceptual similarity metrics comparing Impostor images to real-world AIGC edits from external sources; (2) a human forensic study with expert raters scoring realism and artifact presence; (3) an ablation isolating the reflection step’s contribution to final image quality; and (4) distributional analysis of manipulation statistics against prior benchmarks. These additions will directly test whether observed performance gaps generalize beyond Impostor. revision: yes
Circularity Check
No significant circularity; empirical dataset and model proposal
full rationale
The paper introduces an empirical benchmark dataset (Impostor) generated via the described CraftAgent framework and proposes PANet as a new IMDL model. No mathematical derivations, equations, parameter fittings, or predictions are present. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing elements. The central claims rest on the framework's construction process and experimental results rather than reducing to self-defined inputs or prior author work by construction. This is a standard empirical contribution with no circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (2)
-
CraftAgent
no independent evidence
-
PhaseAware-Net (PANet)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Lvpan Cai, Haowei Wang, Jiayi Ji, YanShu ZhouMen, Shen Chen, Taiping Yao, and Xiaoshuai Sun. Zooming in on fakes: A novel dataset for localized ai-generated image detection with forgery amplification approach.arXiv preprint arXiv:2504.11922,
-
[3]
Casia image tampering detection evaluation database
Jing Dong, Wei Wang, and Tieniu Tan. Casia image tampering detection evaluation database. In 2013 IEEE China summit and international conference on signal and information processing, pp. 422–426. IEEE,
2013
-
[4]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Di- agne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing. arXiv preprint arXiv:2504.17761,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Oscar Mañas, Pietro Astolfi, Melissa Hall, Candace Ross, Jack Urbanek, Adina Williams, Aishwarya Agrawal, Adriana Romero-Soriano, and Michal Drozdzal. Improving text-to-image consistency via automatic prompt optimization.arXiv preprint arXiv:2403.17804,
-
[7]
A data set of authentic and spliced image blocks
Tian-Tsong Ng, Shih-Fu Chang, and Q Sun. A data set of authentic and spliced image blocks. Columbia University, ADVENT Technical Report, 4:2033–2004,
2033
-
[9]
SAM 2: Segment Anything in Images and Videos
URL https://arxiv.org/abs/2408.00714. Eero P Simoncelli and Bruno A Olshausen. Natural image statistics and neural representation.Annual review of neuroscience, 24(1):1193–1216,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Runpu Wei, Zijin Yin, Shuo Zhang, Lanxiang Zhou, Xueyi Wang, Chao Ban, Tianwei Cao, Hao Sun, Zhongjiang He, Kongming Liang, et al. Omnieraser: Remove objects and their effects in images with paired video-frame data.arXiv preprint arXiv:2501.07397,
-
[11]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435,
Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Weidi Xie. A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435,
-
[13]
Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen
URL https://arxiv.org/abs/ 2311.12397. Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen. A task is worth one word: Learning with task prompts for high-quality versatile image inpainting. InEuropean Conference on Computer Vision, pp. 195–211. Springer,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.