ReSGA: A Large Tail Risk Model for Learning Value-at-Risk and Expected Shortfall
Pith reviewed 2026-06-28 04:10 UTC · model grok-4.3
The pith
ReSGA forecasts Value-at-Risk and Expected Shortfall more accurately than prior methods by using a large neural network on asset characteristics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReSGA is a large tail risk model with millions of parameters built to exploit rich cross-sectional dependence and long-term temporal dynamics of assets via their characteristics. On monthly US equity returns 1926-2023 with 153 firm characteristics, it beats twelve econometric and machine learning baselines on out-of-sample loss and statistical backtests. The forecast edge produces sizable economic gains in long-short decile portfolios formed by a new size-enhanced left-side momentum strategy. Scaling analysis shows joint VaR-ES improvements arise primarily from data complexity, not model complexity. Group-importance and transfer-learning results confirm interpretability and cross-market appl
What carries the argument
The retrieval-enhanced self-grouping autoencoder (ReSGA), a neural network that retrieves similar assets and groups them to model tail risks with millions of parameters.
If this is right
- Joint VaR-ES forecasts improve when models scale to millions of parameters on characteristic-rich data.
- Economic profits arise from portfolios that sort assets by the model's tail-risk signals using a size-enhanced left-side momentum rule.
- Scaling experiments separate data complexity as the main driver of better VaR-ES accuracy over model size.
- Group-importance analysis reveals which characteristics matter most for the forecasts.
- Transfer-learning results show the model applies across different markets without full retraining.
Where Pith is reading between the lines
- Larger historical or cross-market datasets could yield further accuracy gains without increasing model size.
- The retrieval and grouping steps might extend to other tail measures such as expected shortfall at multiple horizons.
- If data complexity dominates, practitioners could prioritize collecting more characteristics over tuning network depth.
Load-bearing premise
The out-of-sample gains on the 1926-2023 US equity data with 153 characteristics are not artifacts of model selection or data snooping.
What would settle it
ReSGA failing to show lower out-of-sample loss than the twelve baselines on a fresh post-2023 equity dataset or a non-US market would falsify the performance claim.
Figures
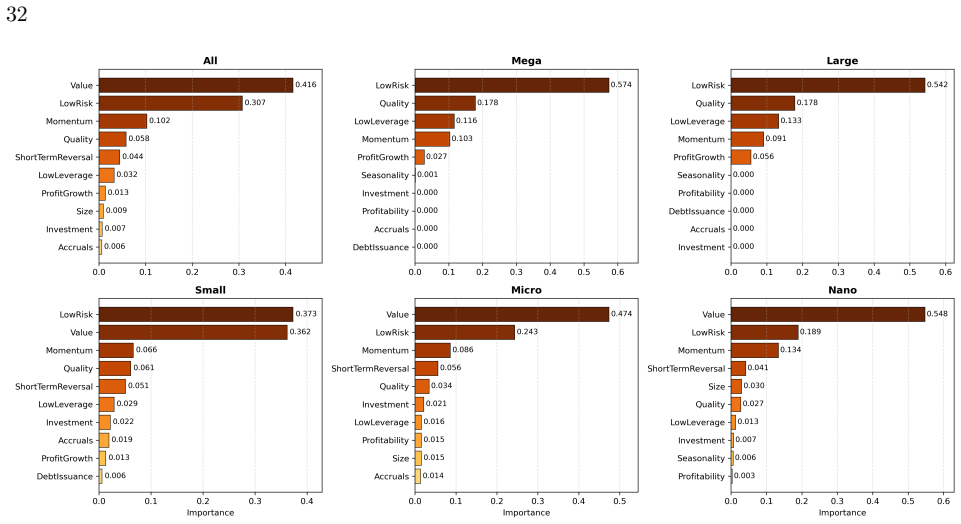
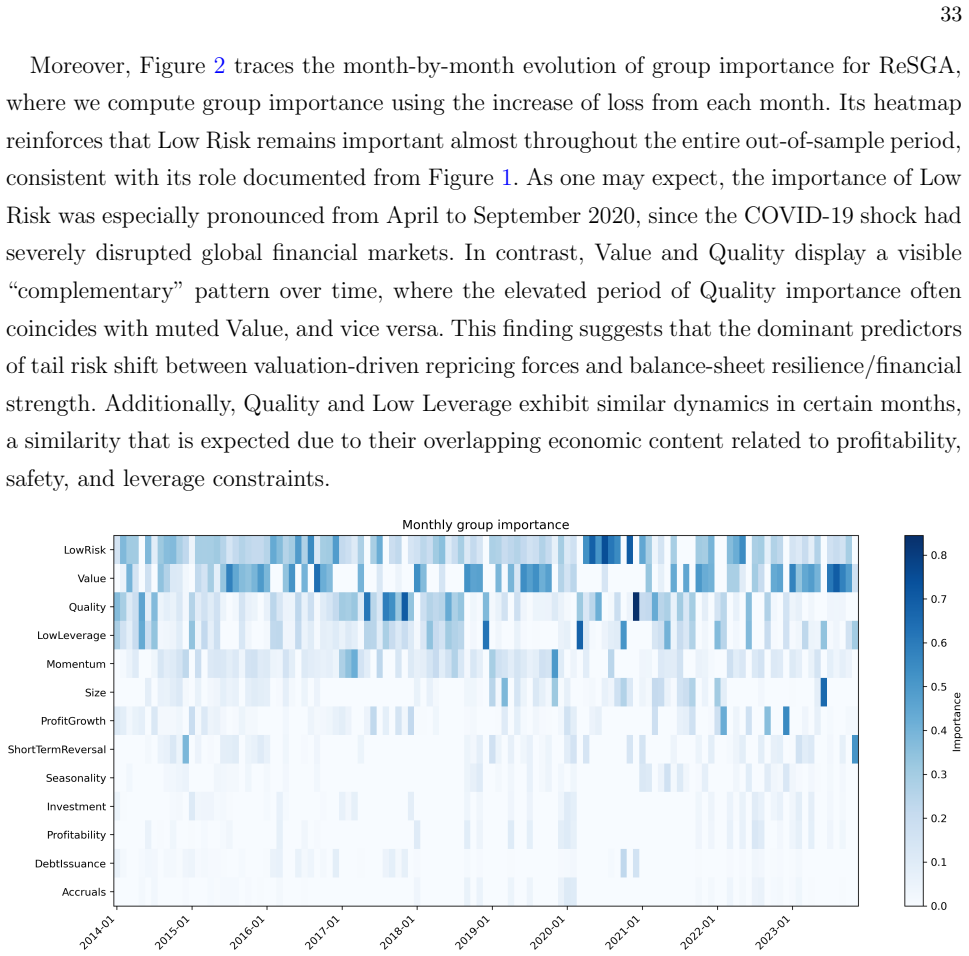
read the original abstract
Learning Value-at-Risk (VaR) and Expected Shortfall (ES) is important for managing financial risks effectively. Existing approaches with limited parameters are vulnerable to model misspecification in the era of big data. To address this limitation, we propose a large tail risk model, the retrieval-enhanced self-grouping autoencoder (ReSGA), which is designed with millions of parameters to exploit the rich cross-sectional dependence and long-term temporal dynamics of assets using their characteristics. Applied to monthly US equity returns from 1926 to 2023 with 153 firm characteristics, ReSGA outperforms twelve econometric and machine learning competitors in terms of out-of-sample loss and statistical backtesting. In addition, its forecast advantages can translate into significant economic gains from long-short decile portfolios that are constructed by a new size-enhanced left-side momentum strategy. To clarify the role of complexity, we further conduct a systematic scaling analysis and demonstrate that improvements in joint VaR-ES forecasting are primarily driven by data complexity rather than model complexity. Finally, our analyses of group-importance and transfer-learning exhibit the interpretability and cross-market generalizability of ReSGA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the retrieval-enhanced self-grouping autoencoder (ReSGA), a neural network with millions of parameters, for joint estimation of Value-at-Risk (VaR) and Expected Shortfall (ES) on monthly US equity returns 1926-2023 using 153 firm characteristics. It claims superior out-of-sample performance and backtest results versus twelve econometric and machine-learning baselines, economic gains from a new size-enhanced left-side momentum long-short strategy, and that a scaling analysis attributes gains primarily to data complexity rather than model complexity, while also showing interpretability via group importance and cross-market transferability.
Significance. If the outperformance, economic gains, and non-circular scaling conclusions hold after verification, the work would be significant for demonstrating the viability of high-capacity models in tail-risk forecasting with rich characteristic data, potentially shifting practice toward scalable neural approaches in financial risk management.
major comments (3)
- [Abstract] Abstract: the claim of outperformance over twelve competitors in out-of-sample loss and statistical backtesting supplies no numerical loss values, no description of the training objective, and no mention of regularization against overfitting with millions of parameters; these omissions are load-bearing for assessing whether the reported superiority is robust.
- [Scaling analysis] Scaling analysis (described in abstract): the assertion that improvements are driven by data complexity rather than model complexity cannot be verified without the explicit equations or complexity metrics; if these metrics are computed from post-fit quantities such as realized losses or selected hyperparameters, the separation is circular and does not rule out that apparent gains are simply better-tuned large models.
- [Abstract] Abstract: the claim that forecast advantages translate into significant economic gains via a new size-enhanced left-side momentum strategy provides no details on portfolio construction, turnover, or statistical significance of the gains, which is central to the economic-value assertion.
minor comments (1)
- The manuscript should add a dedicated methods subsection detailing the precise loss function, optimization procedure, and any regularization or early-stopping rules used to train the millions of parameters.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on the manuscript. We provide point-by-point responses below and indicate where revisions will be made to improve the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of outperformance over twelve competitors in out-of-sample loss and statistical backtesting supplies no numerical loss values, no description of the training objective, and no mention of regularization against overfitting with millions of parameters; these omissions are load-bearing for assessing whether the reported superiority is robust.
Authors: While the abstract is necessarily concise, the out-of-sample loss values are detailed in Table 3, the joint training objective for VaR and ES is specified in Equation (4) of Section 3, and regularization methods to mitigate overfitting are discussed in Section 4.1. We will revise the abstract to incorporate key numerical results and a brief reference to the objective and regularization approach. revision: partial
-
Referee: [Scaling analysis] Scaling analysis (described in abstract): the assertion that improvements are driven by data complexity rather than model complexity cannot be verified without the explicit equations or complexity metrics; if these metrics are computed from post-fit quantities such as realized losses or selected hyperparameters, the separation is circular and does not rule out that apparent gains are simply better-tuned large models.
Authors: Section 5 presents the scaling analysis with explicit definitions: model complexity is measured by the number of parameters in the autoencoder, and data complexity by the number of firm characteristics and observations. These are pre-determined quantities, not derived from post-fit losses or hyperparameters, thus avoiding circularity. The analysis varies data size while fixing model size and vice versa. We will add the explicit equations to the main text for clarity if they are not sufficiently prominent. revision: partial
-
Referee: [Abstract] Abstract: the claim that forecast advantages translate into significant economic gains via a new size-enhanced left-side momentum strategy provides no details on portfolio construction, turnover, or statistical significance of the gains, which is central to the economic-value assertion.
Authors: The size-enhanced left-side momentum strategy is described in detail in Section 6, including how portfolios are formed based on ReSGA forecasts. Turnover rates are reported in Table 6, and the statistical significance of the returns is evaluated using t-statistics adjusted for autocorrelation. We will update the abstract to include concise information on these aspects. revision: partial
Circularity Check
No circularity in derivation or scaling analysis
full rationale
The paper introduces ReSGA as a large-parameter autoencoder for joint VaR-ES forecasting on equity returns with characteristics, reports out-of-sample superiority over competitors, and performs a scaling analysis attributing gains to data complexity. No quoted equations or sections exhibit self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central claims to tautology. The scaling analysis is presented as an empirical demonstration separating data and model complexity; absent explicit reduction of its metrics to post-fit quantities within the same optimization, the derivation chain remains self-contained against external benchmarks and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- millions of parameters in ReSGA
axioms (1)
- domain assumption Large models with retrieval and self-grouping can exploit cross-sectional dependence and long-term temporal dynamics of assets using firm characteristics
invented entities (1)
-
ReSGA (retrieval-enhanced self-grouping autoencoder)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Szekely , Balazs B
barticle [author] Acerbi , Carlo C. Szekely , Balazs B. ( 2014 ). Back-testing Expected Shortfall . Risk 27 76--81 . barticle
2014
-
[2]
Tasche , Dirk D
barticle [author] Acerbi , Carlo C. Tasche , Dirk D. ( 2002 ). On the Coherence of Expected Shortfall . Journal of Banking & Finance 26 1487--1503 . barticle
2002
-
[3]
barticle [author] Akaike , H. H. ( 1974 ). A New Look at the Statistical Model Identification . IEEE Transactions on Automatic Control 19 716--723 . barticle
1974
-
[4]
barticle [author] Artzner , Philippe P. , Delbaen , Freddy F. , Eber , Jean-Marc J.-M. Heath , David D. ( 1999 ). Coherent Measures of Risk . Mathematical Finance 9 203--228 . 10.1111/1467-9965.00068 barticle
-
[5]
barticle [author] Atilgan , Yigit Y. , Bali , Turan G. T. G. , Demirtas , K. Ozgur K. O. Gunaydin , A. Doruk A. D. ( 2020 ). Left-Tail Momentum: Underreaction to Bad News, Costly Arbitrage and Equity Returns . Journal of Financial Economics 135 725--753 . 10.1016/j.jfineco.2019.07.006 barticle
-
[6]
barticle [author] Bayer , Sebastian S. Dimitriadis , Timo T. ( 2022 ). Regression-Based Expected Shortfall Backtesting . Journal of Financial Econometrics 20 437--471 . 10.1093/jjfinec/nbaa013 barticle
-
[7]
btechreport [author] Berk , Jonathan B. J. B. ( 2023 ). Comment on ``The Virtue of Complexity in Return Prediction'' SSRN Working Paper No. 4410125 , SSRN . btechreport
2023
-
[8]
( 2025 )
btechreport [author] Buncic , Daniel D. ( 2025 ). Simplified: A Closer Look at the Virtue of Complexity in Return Prediction SSRN Working Paper No. 5239006 , SSRN . btechreport
2025
-
[9]
, Jin , Qi Q
btechreport [author] Cartea , \'A lvaro \'A . , Jin , Qi Q. Shi , Yuantao Y. ( 2025 ). The Limited Virtue of Complexity in a Noisy World SSRN Working Paper No. 5202064 , SSRN . btechreport
2025
-
[10]
barticle [author] Christoffersen , Peter F. P. F. ( 1998 ). Evaluating Interval Forecasts . International Economic Review 39 841--862 . barticle
1998
-
[11]
, Raftapostolos , Aristeidis A
barticle [author] Chronopoulos , Ilias I. , Raftapostolos , Aristeidis A. Kapetanios , George G. ( 2024 ). Forecasting Value-at-Risk Using Deep Neural Network Quantile Regression . Journal of Financial Econometrics 22 636--669 . barticle
2024
-
[12]
barticle [author] Chung , Junyoung J. , Gulcehre , Caglar C. , Cho , KyungHyun K. Bengio , Yoshua Y. ( 2014 ). Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling . ArXiv preprint ``arXiv:1412.3555'' . barticle
Pith/arXiv arXiv 2014
-
[13]
, Kong , Weihao W
binproceedings [author] Das , Abhimanyu A. , Kong , Weihao W. , Sen , Rajat R. Zhou , Yichen Y. ( 2024 ). A Decoder-Only Foundation Model for Time-Series Forecasting . In Proceedings of the 41st International Conference on Machine Learning 235 10148--10167 . binproceedings
2024
-
[14]
btechreport [author] Didisheim , Antoine A. , Ke , Shikun (Barry) S. B. , Kelly , Bryan B. Malamud , Semyon S. ( 2024 ). APT or ``AIPT''? The Surprising Dominance of Large Factor Models Working Paper No. 33012 , National Bureau of Economic Research . 10.3386/w33012 btechreport
-
[15]
barticle [author] Diebold , Francis X. F. X. Mariano , Roberto S. R. S. ( 1995 ). Comparing Predictive Accuracy . Journal of Business & Economic Statistics 13 253--263 . 10.1080/07350015.1995.10524599 barticle
-
[16]
, Xu , Shuang S
binproceedings [author] Dong , Linhao L. , Xu , Shuang S. Xu , Bo B. ( 2018 ). Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition . In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 5884--5888 . binproceedings
2018
-
[17]
, Beyer , Lucas L
binproceedings [author] Dosovitskiy , Alexey A. , Beyer , Lucas L. , Kolesnikov , Alexander A. , Weissenborn , Dirk D. , Zhai , Xiaohua X. , Unterthiner , Thomas T. , Dehghani , Mostafa M. , Minderer , Matthias M. , Heigold , Georg G. , Gelly , Sylvain S. , Uszkoreit , Jakob J. Houlsby , Neil N. ( 2021 ). An Image is Worth 16x16 Words: Transformers for Im...
2021
-
[18]
Escanciano , Juan Carlos J
barticle [author] Du , Zaichao Z. Escanciano , Juan Carlos J. C. ( 2017 ). Backtesting Expected Shortfall: Accounting for Tail Risk . Management Science 63 940--958 . barticle
2017
-
[19]
, Bengio , Yoshua Y
binproceedings [author] Dugas , Charles C. , Bengio , Yoshua Y. , B\' e lisle , Fran c ois F. , Nadeau , Claude C. Garcia , Ren\' e R. ( 2000 ). Incorporating Second-Order Functional Knowledge for Better Option Pricing . In Advances in Neural Information Processing Systems 13 472--478 . binproceedings
2000
-
[20]
barticle [author] Fama , Eugene F. E. F. French , Kenneth R. K. R. ( 2015 ). A Five-Factor Asset Pricing Model . Journal of Financial Economics 116 1--22 . 10.1016/j.jfineco.2014.10.010 barticle
-
[21]
binproceedings [author] Feng , Cheng C. , Huang , Long L. Krompass , Denis D. ( 2024 ). General Time Transformer: An Encoder-Only Foundation Model for Zero-Shot Multivariate Time Series Forecasting . In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management 3757--3761 . 10.1145/3627673.3679931 binproceedings
-
[22]
barticle [author] Fissler , Tobias T. Ziegel , Johanna F. J. F. ( 2016 ). Higher Order Elicitability and Osband’s Principle . The Annals of Statistics 44 1680--1707 . 10.1214/16-AOS1439 barticle
-
[23]
barticle [author] Gneiting , Tilmann T. ( 2011 ). Making and Evaluating Point Forecasts . Journal of the American Statistical Association 106 746--762 . 10.1198/jasa.2011.r10138 barticle
-
[24]
, Bengio , Yoshua Y
bbook [author] Goodfellow , Ian I. , Bengio , Yoshua Y. Courville , Aaron A. ( 2016 ). Deep Learning . MIT press . bbook
2016
-
[25]
barticle [author] Gu , Shihao S. , Kelly , Bryan B. Xiu , Dacheng D. ( 2020 ). Empirical Asset Pricing via Machine Learning . The Review of Financial Studies 33 2223--2273 . 10.1093/rfs/hhaa009 barticle
-
[26]
barticle [author] Gu , Shihao S. , Kelly , Bryan B. Xiu , Dacheng D. ( 2021 ). Autoencoder Asset Pricing Models . Journal of Econometrics 222 429--450 . 10.1016/j.jeconom.2020.07.009 barticle
-
[27]
barticle [author] Hansen , Peter R. P. R. , Lunde , Asger A. Nason , James M. J. M. ( 2011 ). The Model Confidence Set . Econometrica 79 453--497 . 10.3982/ECTA5771 barticle
-
[28]
Long short-term memory.Neural Comput., 9(8): 1735–1780, November 1997
barticle [author] Hochreiter , Sepp S. Schmidhuber , J \"u rgen J. ( 1997 ). Long Short-Term Memory . Neural Computation 9 1735--1780 . 10.1162/neco.1997.9.8.1735 barticle
-
[29]
Szegedy , Christian C
binproceedings [author] Ioffe , Sergey S. Szegedy , Christian C. ( 2015 ). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift . In Proceedings of the 32nd International Conference on Machine Learning 37 448--456 . binproceedings
2015
-
[30]
barticle [author] Jensen , Theis Ingerslev T. I. , Kelly , Bryan B. Pedersen , Lasse Heje L. H. ( 2023 ). Is There a Replication Crisis in Finance? The Journal of Finance 78 2465--2518 . 10.1111/jofi.13249 barticle
-
[31]
barticle [author] Kaplan , Jared J. , McCandlish , Sam S. , Henighan , Tom T. , Brown , Tom B. T. B. , Chess , Benjamin B. , Child , Rewon R. , Gray , Scott S. , Radford , Alec A. , Wu , Jeffrey J. Amodei , Dario D. ( 2020 ). Scaling Laws for Neural Language Models . ArXiv preprint ``arXiv:2001.08361'' . barticle
Pith/arXiv arXiv 2020
-
[32]
barticle [author] Kelly , Bryan B. , Malamud , Semyon S. Zhou , Kangying K. ( 2024 ). The Virtue of Complexity in Return Prediction . The Journal of Finance 79 459--503 . 10.1111/jofi.13298 barticle
-
[33]
btechreport [author] Kelly , Bryan B. , Kuznetsov , Boris B. , Malamud , Semyon S. Xu , Teng Andrea T. A. ( 2025 ). Artificial Intelligence Asset Pricing Models Working Paper No. 33351 , National Bureau of Economic Research . 10.3386/w33351 btechreport
-
[34]
binproceedings [author] Kingma , Diederik P. D. P. Ba , Jimmy J. ( 2015 ). Adam: A Method for Stochastic Optimization . In International Conference on Learning Representations . binproceedings
2015
-
[35]
Bassett , Gilbert G
barticle [author] Koenker , Roger R. Bassett , Gilbert G. ( 1978 ). Regression Quantiles . Econometrica 46 33--50 . barticle
1978
-
[36]
barticle [author] Li , Sophia Zhengzi S. Z. Tang , Yushan Y. ( 2025 ). Automated Volatility Forecasting . Management Science 71 6248--6274 . 10.1287/mnsc.2023.01520 barticle
-
[37]
Wang , Ruodu R
barticle [author] Li , Hengxin H. Wang , Ruodu R. ( 2023 ). PELVE: Probability Equivalent Level of VaR and ES . Journal of Econometrics 234 353--370 . barticle
2023
-
[38]
( 1993 )
bbook [author] Masters , Timothy T. ( 1993 ). Practical Neural Network Recipes in C++ . Academic Press . bbook
1993
-
[39]
barticle [author] Merlo , Luca L. , Petrella , Lea L. Raponi , Valentina V. ( 2021 ). Forecasting VaR and ES Using a Joint Quantile Regression and Its Implications in Portfolio Allocation . Journal of Banking & Finance 133 106248 . 10.1016/j.jbankfin.2021.106248 barticle
-
[40]
btechreport [author] Nagel , Stefan S. ( 2025 ). Seemingly Virtuous Complexity in Return Prediction Working Paper No. 34104 , National Bureau of Economic Research . 10.3386/w34104 btechreport
-
[41]
barticle [author] Newey , Whitney K. W. K. West , Kenneth D. K. D. ( 1987 ). A Simple, Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix . Econometrica 55 703--708 . 10.2307/1913610 barticle
-
[42]
Minimum Capital Requirements for Market Risk Basel Committee on Banking Supervision Publication , Bank for International Settlements
btechreport [author] Basel Committee on Banking Supervision ( 2019 ). Minimum Capital Requirements for Market Risk Basel Committee on Banking Supervision Publication , Bank for International Settlements . btechreport
2019
-
[43]
binproceedings [author] Oreshkin , Boris N. B. N. , Carpov , Dmitri D. , Chapados , Nicolas N. Bengio , Yoshua Y. ( 2020 ). N-BEATS: Neural Basis Expansion Analysis for Interpretable Time Series Forecasting . In International Conference on Learning Representations . binproceedings
2020
-
[44]
barticle [author] Patton , Andrew J. A. J. , Ziegel , Johanna F. J. F. Chen , Rui R. ( 2019 ). Dynamic Semiparametric Models for Expected Shortfall (and Value-at-Risk) . Journal of Econometrics 211 388--413 . 10.1016/j.jeconom.2018.10.008 barticle
-
[45]
barticle [author] Rockafellar , R Tyrrell R. T. Uryasev , Stanislav S. ( 2002 ). Conditional Value-at-Risk for General Loss Distributions . Journal of Banking & Finance 26 1443--1471 . 10.1016/S0378-4266(02)00271-6 barticle
-
[46]
barticle [author] Taylor , James W. J. W. ( 2019 ). Forecasting Value at Risk and Expected Shortfall Using a Semiparametric Approach Based on the Asymmetric Laplace Distribution . Journal of Business & Economic Statistics 37 121--133 . 10.1080/07350015.2017.1281815 barticle
-
[47]
, Shazeer , Noam N
binproceedings [author] Vaswani , Ashish A. , Shazeer , Noam N. , Parmar , Niki N. , Uszkoreit , Jakob J. , Jones , Llion L. , Gomez , Aidan N A. N. , Kaiser , ukasz . Polosukhin , Illia I. ( 2017 ). Attention is All you Need . In Advances in Neural Information Processing Systems 30 5998--6008 . binproceedings
2017
-
[48]
, Cucurull , Guillem G
binproceedings [author] Veli c kovi \'c , Petar P. , Cucurull , Guillem G. , Casanova , Arantxa A. , Romero , Adriana A. , Li \`o , Pietro P. Bengio , Yoshua Y. ( 2018 ). Graph Attention Networks . In International Conference on Learning Representations . binproceedings
2018
-
[49]
barticle [author] Wang , Qiuqi Q. , Wang , Ruodu R. Ziegel , Johanna J. ( 2025 ). E-Backtesting . forthcoming in Management Science . 10.1287/mnsc.2023.01659 barticle
-
[50]
, Zhu , Zhoufan Z
barticle [author] Yang , Xuanling X. , Zhu , Zhoufan Z. , Li , Dong D. Zhu , Ke K. ( 2024 ). Asset Pricing via the Conditional Quantile Variational Autoencoder . Journal of Business & Economic Statistics 42 681--694 . barticle
2024
-
[51]
, Yang , Chao-Han Huck C.-H
binproceedings [author] Yao , Qingren Q. , Yang , Chao-Han Huck C.-H. H. , Jiang , Renhe R. , Liang , Yuxuan Y. , Jin , Ming M. Pan , Shirui S. ( 2025 ). Towards Neural Scaling Laws for Time Series Foundation Models . In International Conference on Learning Representations . binproceedings
2025
-
[52]
, Chen , Muxi M
binproceedings [author] Zeng , Ailing A. , Chen , Muxi M. , Zhang , Lei L. Xu , Qiang Q. ( 2023 ). Are Transformers Effective for Time Series Forecasting? In Proceedings of the AAAI Conference on Artificial Intelligence 37 11121--11128 . binproceedings
2023
-
[53]
, Zhang , Shanghang S
binproceedings [author] Zhou , Haoyi H. , Zhang , Shanghang S. , Peng , Jieqi J. , Zhang , Shuai S. , Li , Jianxin J. , Xiong , Hui H. Zhang , Wancai W. ( 2021 ). Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting . In Proceedings of the AAAI Conference on Artificial Intelligence 35 11106--11115 . binproceedings
2021
-
[54]
barticle [author] Zhu , Zhoufan Z. , Zhang , Ningning N. Zhu , Ke K. ( 2024 ). Big Portfolio Selection by Graph-Based Conditional Moments Method . Journal of Empirical Finance 78 101533 . 10.1016/j.jempfin.2024.101533 barticle
-
[55]
Zhu , Ke K
barticle [author] Zhu , Zhoufan Z. Zhu , Ke K. ( 2025 ). Machine Learning Vast Dynamic Conditional Covariance Matrices: the Spirit of ``Divide and Conquer'' . Minor revision for Management Science . barticle
2025
-
[56]
The Review of Financial Studies , volume =
Empirical Asset Pricing via Machine Learning , author =. The Review of Financial Studies , volume =. 2020 , doi =
2020
-
[57]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Are Transformers Effective for Time Series Forecasting? , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[58]
Neural Computation , volume =
Long Short-Term Memory , author =. Neural Computation , volume =. 1997 , doi =
1997
-
[59]
2014 , journal =
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling , author =. 2014 , journal =
2014
-
[60]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[61]
International Conference on Learning Representations , year =
Towards Neural Scaling Laws for Time Series Foundation Models , author =. International Conference on Learning Representations , year =
-
[62]
Advances in Neural Information Processing Systems , volume =
Incorporating Second-Order Functional Knowledge for Better Option Pricing , author =. Advances in Neural Information Processing Systems , volume =
-
[63]
Practical Neural Network Recipes in
Masters, Timothy , isbn =. Practical Neural Network Recipes in. 1993 , publisher =
1993
-
[64]
Proceedings of the 32nd International Conference on Machine Learning , volume =
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift , author =. Proceedings of the 32nd International Conference on Machine Learning , volume =
-
[65]
2016 , isbn =
Deep Learning , author =. 2016 , isbn =
2016
-
[66]
Basel III: A Global Regulatory Framework for More Resilient Banks and Banking Systems , institution =
-
[67]
Advances in Neural Information Processing Systems , volume =
Attention is All you Need , author =. Advances in Neural Information Processing Systems , volume =
-
[68]
International Conference on Learning Representations , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations , year =
-
[69]
2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , year =
Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition , author =. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , year =
2018
-
[70]
Mathematical Finance , volume =
Coherent Measures of Risk , author =. Mathematical Finance , volume =. 1999 , pages =
1999
-
[71]
, journal =
Fissler, Tobias and Ziegel, Johanna F. , journal =. Higher Order Elicitability and. 2016 , doi =
2016
-
[72]
Journal of Econometrics , volume =
Dynamic Semiparametric Models for Expected Shortfall (and Value-at-Risk) , author =. Journal of Econometrics , volume =. 2019 , doi =
2019
-
[73]
Journal of Applied Econometrics , volume =
Generalized Autoregressive Score Models with Applications , author =. Journal of Applied Econometrics , volume =. 2013 , doi =
2013
-
[74]
Journal of Econometrics , volume =
Generalized Autoregressive Conditional Heteroskedasticity , author =. Journal of Econometrics , volume =. 1986 , doi =
1986
-
[75]
Journal of Business & Economic Statistics , volume =
Forecasting Value at Risk and Expected Shortfall Using a Semiparametric Approach Based on the Asymmetric Laplace Distribution , author =. Journal of Business & Economic Statistics , volume =. 2019 , doi =
2019
-
[76]
Forecasting
Merlo, Luca and Petrella, Lea and Raponi, Valentina , journal =. Forecasting. 2021 , doi =
2021
-
[77]
Management Science , volume =
Automated Volatility Forecasting , author =. Management Science , volume =. 2025 , doi =
2025
-
[78]
The Journal of Finance , volume =
Is There a Replication Crisis in Finance? , author =. The Journal of Finance , volume =. 2023 , doi =
2023
-
[79]
The 29th International Conference on Artificial Intelligence and Statistics , year =
Retrieval Augmented Time Series Forecasting , author =. The 29th International Conference on Artificial Intelligence and Statistics , year =
-
[80]
Journal of Business & Economic Statistics , volume =
Comparing Predictive Accuracy , author =. Journal of Business & Economic Statistics , volume =. 1995 , doi =
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.