Beyond Symmetric Alignment: Spectral Diagnostics of Modality Imbalance in Vision-Language Models in the Medical Domain
Pith reviewed 2026-06-28 06:38 UTC · model grok-4.3
The pith
Medical images retain richer structural information than paired clinical reports, revealed only by a new asymmetric spectral metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
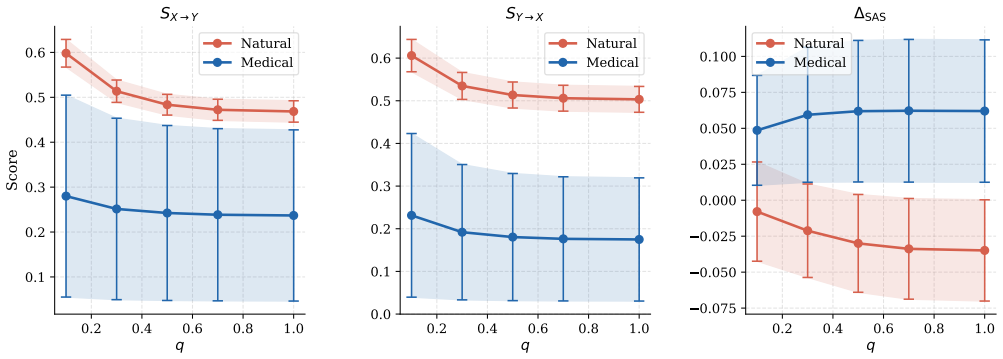
The Spectral Alignment Score projects both modalities onto the principal eigenbasis of a chosen anchor modality, then computes eigenvalue-weighted correlations for each eigenmode to obtain two directional alignment values. Their difference isolates modality information imbalance. In medical image-text pairs this procedure shows that images preserve more structural information than the accompanying clinical reports. The same score exhibits the strongest zero-label correlation with retrieval performance among the metrics evaluated.
What carries the argument
Spectral Alignment Score (SAS): projects image and text embeddings onto the anchor modality's principal eigenbasis and forms directional scores from eigenvalue-weighted per-eigenmode correlations.
If this is right
- SAS supplies separate scores for each modality, exposing which one contributes less information in cross-modal tasks.
- Medical images carry more structural detail than their paired clinical reports under this measurement.
- SAS correlates more strongly with bidirectional retrieval than six existing alignment metrics in the medical domain.
- The metric can be used as a practical, label-free diagnostic when selecting or monitoring VLMs for clinical use.
Where Pith is reading between the lines
- Training objectives for medical VLMs may need to compensate specifically for information loss when text is the weaker modality.
- The anchoring procedure could be tested on other paired domains where one modality is structurally dominant, such as scientific figures and captions.
- Practitioners could track modality balance during fine-tuning by computing SAS on small unlabeled batches instead of running full retrieval benchmarks.
Load-bearing premise
The eigenvalue-weighted per-eigenmode correlations obtained after projection onto an anchor modality's eigenbasis isolate genuine modality information imbalance rather than artifacts of the embedding space.
What would settle it
If a new symmetric metric applied to the same medical datasets produces directional imbalance scores that match or exceed SAS correlation with retrieval performance.
Figures

read the original abstract
Vision-Language Models (VLMs) struggle when applied to medical image-text data, yet the tools available to diagnose this failure remain limited. Existing representation alignment metrics are symmetric, collapsing both modalities into a single score and hiding which modality drives cross-modal degradation. We introduce the Spectral Alignment Score (SAS), an asymmetric metric that projects both modalities onto the principal eigenbasis of an anchor modality and computes eigenvalue-weighted per-eigenmode correlations, resulting in directional scores whose difference quantifies modality information imbalance. We embed SAS within a benchmarking framework evaluating 15 VLMs across natural and medical image-text datasets alongside 6 alignment metrics and bidirectional retrieval. Our experiments show that medical images retain richer structural information than their paired clinical reports, a directional asymmetry invisible to all competing metrics, and that SAS achieves the strongest zero-label correlation with retrieval performance in the medical domain, positioning it as a practical diagnostic tool for clinical deployment. Code is available at this URL: https://github.com/iamalegambetti/medical-vlms-assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Spectral Alignment Score (SAS), an asymmetric metric for vision-language models that projects both modalities onto the principal eigenbasis of an anchor modality and computes eigenvalue-weighted per-eigenmode correlations to produce directional scores quantifying modality information imbalance. Experiments embed SAS in a framework evaluating 15 VLMs on natural and medical image-text datasets against 6 alignment metrics and bidirectional retrieval tasks. Results indicate that medical images retain richer structural information than paired clinical reports (a directional asymmetry invisible to symmetric metrics) and that SAS shows the strongest zero-label correlation with retrieval performance in the medical domain, positioning it as a diagnostic tool.
Significance. If the central claim holds, the work offers a practical asymmetric diagnostic for modality imbalance in medical VLMs where symmetric metrics fail, with the public code release supporting reproducibility. The directional finding on image vs. report richness could inform clinical VLM deployment. However, significance is tempered by the need to confirm that SAS isolates intrinsic information content rather than embedding-space artifacts.
major comments (2)
- [Abstract] Abstract (and implied method): the claim that eigenvalue-weighted per-eigenmode correlations after projection onto an anchor modality's principal eigenbasis isolate true modality information imbalance (rather than VLM-specific embedding geometry, eigenbasis truncation, or differential noise) lacks a derivation or ablation addressing the stress-test concern; this assumption is load-bearing for the directional asymmetry result and its superiority over competing metrics.
- [Abstract] Abstract: the reported strongest zero-label correlation of SAS with retrieval performance is presented without details on error bars, data splits, number of runs, or controls for post-hoc metric selection, undermining the strength of the empirical claim relative to the 6 competing metrics.
minor comments (1)
- The abstract states code is available at a GitHub URL but does not specify the exact commit or reproduction instructions for the 15-VLM, 6-metric experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract (and implied method): the claim that eigenvalue-weighted per-eigenmode correlations after projection onto an anchor modality's principal eigenbasis isolate true modality information imbalance (rather than VLM-specific embedding geometry, eigenbasis truncation, or differential noise) lacks a derivation or ablation addressing the stress-test concern; this assumption is load-bearing for the directional asymmetry result and its superiority over competing metrics.
Authors: We agree that the manuscript would be strengthened by an explicit derivation and targeted ablations. In the revised version we will add a formal derivation of SAS showing how the anchor-eigenbasis projection and eigenvalue weighting isolate directional information content, together with new ablation experiments that vary eigenbasis truncation rank, inject controlled modality-specific noise, and compare against alternative embedding geometries. These additions will directly test whether the observed image-report asymmetry persists under the stress conditions raised. revision: yes
-
Referee: [Abstract] Abstract: the reported strongest zero-label correlation of SAS with retrieval performance is presented without details on error bars, data splits, number of runs, or controls for post-hoc metric selection, undermining the strength of the empirical claim relative to the 6 competing metrics.
Authors: We acknowledge that the current presentation omits these statistical details. The revision will report standard-error bars computed over multiple random seeds, explicitly state the train/validation/test splits and number of runs, and include a pre-specified analysis plan with multiplicity correction to guard against post-hoc metric selection. These changes will allow readers to assess the robustness of SAS's superior correlation relative to the competing metrics. revision: yes
Circularity Check
No significant circularity; SAS is a direct linear-algebra definition with empirical validation.
full rationale
The paper defines SAS explicitly as the result of projecting modalities onto an anchor's principal eigenbasis and computing eigenvalue-weighted per-eigenmode correlations; this construction is stated in the abstract and does not reduce to any fitted parameter or prior result by the paper's own equations. The directional imbalance claim and the reported correlation with retrieval performance are presented as experimental outcomes on 15 VLMs and multiple datasets, not as algebraic identities or self-referential predictions. No self-citations, uniqueness theorems, or ansatzes from prior author work appear in the provided text, and the metric is not renamed from a known empirical pattern. The derivation chain therefore remains self-contained against external linear-algebra benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The principal eigenbasis of an anchor modality captures the dominant structural information relevant for cross-modal alignment measurement.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems35 (2022), 23716–23736
2022
-
[3]
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Luke Gabriel, Mostafa Dehghani, Ludwig Schmidt, Jenia Jitsev, Christoph Schuhmann, and Robert Kaczmarczyk. 2023. Reproducible Scaling Laws for Contrastive Language-Image Learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2818–2829
2023
-
[4]
Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, et al
-
[5]
Meta clip 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062 (2025)
arXiv 2025
-
[6]
Sedigheh Eslami, Gerard De Melo, and Christoph Meinel. 2021. Does clip benefit visual question answering in the medical domain as much as it does in the general domain?arXiv preprint arXiv:2112.13906(2021)
arXiv 2021
-
[7]
Marzyeh Ghassemi, Luke Oakden-Rayner, and Andrew L Beam. 2021. The false hope of current approaches to explainable artificial intelligence in health care. The Lancet Digital Health3, 11 (2021), e745–e750
2021
-
[8]
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. 2012. A kernel two-sample test.The Journal of Machine Learning Research13, 1 (2012), 723–773
2012
-
[9]
Iryna Hartsock and Ghulam Rasool. 2024. Vision-language models for medical report generation and visual question answering: A review.Frontiers in artificial intelligence7 (2024), 1430984
2024
-
[10]
Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J Montine, and James Zou. 2023. A visual–language foundation model for pathology image analysis using medical Twitter.Nature Medicine(2023), 1–10
2023
-
[11]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision- language representation learning with noisy text supervision. InInternational conference on machine learning. PMLR, 4904–4916
2021
-
[12]
Alistair E. W. Johnson, Tom J. Pollard, Seth J. Berkowitz, Nathaniel R. Greenbaum, Matthew P. Lungren, Chih-ying Deng, Roger G. Mark, and Steven Horng. 2019. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports.Scientific Data6, 1 (2019), 317. doi:10.1038/s41597-019-0322-0
-
[13]
Andrej Karpathy and Li Fei-Fei. 2015. Deep visual-semantic alignments for generating image descriptions. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3128–3137
2015
-
[14]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. 2019. Similarity of neural network representations revisited. InInternational Conference on Machine Learning. PMlR, 3519–3529
2019
-
[15]
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. 2022. Mind the gap: Understanding the modality gap in multi-modal con- trastive representation learning.Advances in Neural Information Processing Systems35 (2022), 17612–17625
2022
-
[16]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[17]
Morewedge
Chiara Longoni, Andrea Bonezzi, and Carey K. Morewedge. 2019. Resistance to medical artificial intelligence.Journal of Consumer Research46, 4 (2019), 629–650
2019
-
[18]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748(2018)
Pith/arXiv arXiv 2018
-
[19]
Obioma Pelka, Sven Koitka, Johannes Rückert, Felix Nensa, and Christoph M. Friedrich. 2018. Radiology Objects in Context (ROCO): A Multimodal Image Dataset. InIntravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis. Springer, 180–189. doi:10.1007/978-3-030-01364-6_19
-
[20]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning (ICML). 8748–8763
2021
-
[21]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. 2017. Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability.Advances in Neural Information Processing Systems30 (2017)
2017
-
[22]
Hoffmann, Max Argus, Volker Fischer, and Thomas Brox
Simon Schrodi, David T. Hoffmann, Max Argus, Volker Fischer, and Thomas Brox. 2025. Two Effects, One Trigger: On the Modality Gap, Object Bias, and Information Imbalance in Contrastive Vision-Language Models. InICLR
2025
-
[23]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade W Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa R Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. 2022. LAION-5B: An open large-scale dataset for training next generation image-te...
2022
-
[24]
The human body is a black box
Mark Sendak, Madeleine Clare Elish, Michael Gao, Joseph Futoma, William Ratliff, Marshall Nichols, Armando Bedoya, Suresh Balu, and Cara O’Brien. 2020. " The human body is a black box" supporting clinical decision-making with deep learning. InProceedings of the 2020 Conference on Fairness, Accountability, and Transparency. 99–109
2020
-
[25]
Baochen Sun, Jiashi Feng, and Kate Saenko. 2016. Return of frustratingly easy domain adaptation. InProceedings of the AAAI conference on artificial intelligence, Vol. 30
2016
-
[26]
Baochen Sun and Kate Saenko. 2016. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. InComputer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10, 16, 2016, Proceedings, Part III. Springer, 443–450
2016
-
[27]
Michael Tschannen, Ibrahim Alabdulmohsin, Xiao Wang, Andreas Steiner, Xiao- hua Zhai, Lucas Beyer, and Alexander Kolesnikov. 2025. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features.arXiv preprint arXiv:2502.14786(2025)
Pith/arXiv arXiv 2025
-
[28]
Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InInternational Conference on Machine Learning. PMLR, 9929–9939
2020
-
[29]
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, and Christoph Feicht- enhofer. 2024. Demystifying CLIP Data. InInternational Conference on Learning Representations (ICLR)
2024
-
[30]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid Loss for Language Image Pre-Training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 11975–11986
2023
-
[31]
Jie Zhang and Zong-ming Zhang. 2023. Ethics and governance of trustworthy medical artificial intelligence.BMC Medical Informatics and Decision Making23, 1 (2023), 7
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.