Trace-Mediated Peak Bias: Bridging Temporal Credit Assignment and Cognitive Heuristics in Deep Reinforcement Learning
Pith reviewed 2026-06-28 07:34 UTC · model grok-4.3
The pith
Eligibility traces cause deep RL agents to prefer high reward peaks over higher cumulative returns at intermediate depths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
At intermediate eligibility trace depths, deep RL agents exhibit Trace-Mediated Peak Bias, preferring trajectories with high-magnitude reward peaks over alternatives that deliver higher cumulative returns. TMPB emerges because traces amplify distal Temporal Difference errors into gradient shocks that fixed-step-size Stochastic Gradient Descent cannot normalize, leading to global overestimation of peak-containing trajectories. Adaptive optimizers mitigate this pathology via second-moment normalization.
What carries the argument
Eligibility traces that amplify distal TD errors into gradient shocks under fixed-step SGD optimization.
If this is right
- Agents exhibit the peak preference specifically at intermediate trace depths rather than at all trace lengths.
- Adaptive optimizers reduce the bias through second-moment normalization of the updates.
- TMPB supplies a mechanistic explanation for the Peak-End Rule observed in human memory.
- Human-like saliency distortions can arise directly from the mathematical constraints of distributed credit assignment.
Where Pith is reading between the lines
- The same interaction between traces and non-linear approximators could generate analogous distortions in other learning systems that rely on eligibility traces.
- Replacing fixed-step updates with adaptive methods may be necessary for unbiased value estimation whenever eligibility traces are used at intermediate depths.
- The result suggests that credit-assignment mechanisms themselves can produce the kinds of heuristic distortions previously attributed only to separate memory or attention modules.
Load-bearing premise
The preference for high-magnitude reward peaks over higher cumulative returns at intermediate trace depths is a general property of eligibility traces interacting with non-linear function approximation rather than an artifact of particular environments, architectures, or hyperparameter choices.
What would settle it
A controlled experiment that measures preference between peak and steady-reward trajectories at varying trace depths while switching between fixed-step SGD and an adaptive optimizer such as Adam would directly test whether unnormalized gradient shocks are required for the bias.
Figures

read the original abstract
Temporal credit assignment is central to both biological and artificial intelligence, yet its interaction with non-linear function approximation is poorly understood. We identify a systematic failure mode in deep reinforcement learning (RL) termed Trace-Mediated Peak Bias (TMPB). At intermediate eligibility trace depths, agents irrationally prefer trajectories with high-magnitude reward ``peaks'' over alternatives with higher cumulative returns. This provides a mechanistic account of the Peak-End Rule: a human memory bias where experiences are judged by their most intense moments rather than integrated utility. We show that TMPB emerges because traces amplify distal Temporal Difference errors into ``gradient shocks'' that fixed-step-size Stochastic Gradient Descent cannot normalize, leading to global overestimation. Conversely, adaptive optimizers mitigate this pathology via second-moment normalization. Our results suggest that human-like saliency distortions may emerge naturally from the mathematical constraints of credit assignment in distributed systems, and that adaptive optimization is a theoretical necessity for rational value estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify a new failure mode, Trace-Mediated Peak Bias (TMPB), in deep RL: at intermediate eligibility trace depths, agents systematically prefer trajectories containing high-magnitude reward peaks over alternatives with strictly higher cumulative return. TMPB is attributed to eligibility traces amplifying distal TD errors into gradient shocks that fixed-step-size SGD cannot normalize, producing global overestimation; adaptive optimizers are said to mitigate the pathology via second-moment normalization. The work positions TMPB as a mechanistic account of the Peak-End Rule and argues that adaptive optimization is theoretically required for rational value estimation under traces and non-linear function approximation.
Significance. If the claimed mechanism is shown to be intrinsic rather than an artifact of particular environments or hyper-parameters, the result would supply a concrete link between temporal credit-assignment mathematics and a well-documented cognitive bias, while also furnishing a normative argument for adaptive optimizers in trace-based deep RL.
major comments (2)
- [Abstract / central claim] The central claim that TMPB is a general consequence of eligibility traces interacting with non-linear function approximation (rather than an artifact of the tested environments, reward scales, network initializations, or hyper-parameter regimes) is load-bearing for the mechanistic account of the Peak-End Rule, yet the manuscript supplies no quantitative bounds on trace depth, no ablation comparing linear versus non-linear approximators, and no demonstration that the peak preference survives changes in optimizer, learning-rate schedule, or reward distribution.
- [Mechanism description] The assertion that traces amplify distal TD errors into 'gradient shocks' that fixed-step SGD cannot normalize (leading specifically to global overestimation and peak preference) lacks a formal derivation or analysis showing why this interaction produces the observed bias rather than other systematic errors; without such analysis the preference for high-magnitude peaks remains an empirical observation whose generality is unestablished.
minor comments (2)
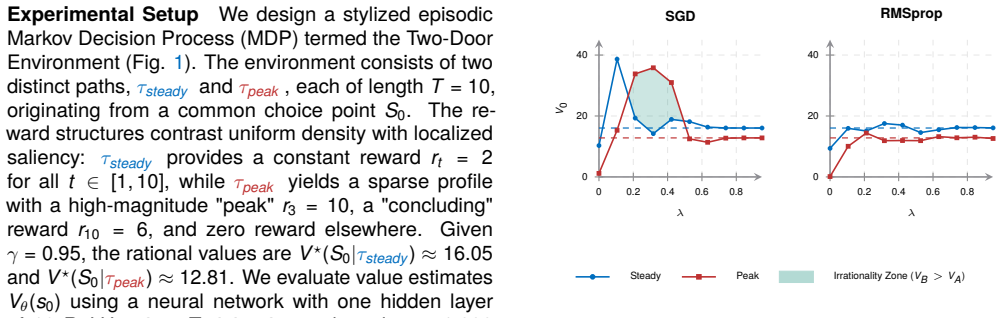
- [Notation / experimental setup] Define 'intermediate eligibility trace depths' with explicit λ ranges or values used in the experiments.
- [Optimizer comparison] Clarify whether the reported mitigation by adaptive optimizers holds under learning-rate schedules that already incorporate second-moment information.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of generality and mechanistic rigor. We respond point by point below and outline targeted revisions to strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / central claim] The central claim that TMPB is a general consequence of eligibility traces interacting with non-linear function approximation (rather than an artifact of the tested environments, reward scales, network initializations, or hyper-parameter regimes) is load-bearing for the mechanistic account of the Peak-End Rule, yet the manuscript supplies no quantitative bounds on trace depth, no ablation comparing linear versus non-linear approximators, and no demonstration that the peak preference survives changes in optimizer, learning-rate schedule, or reward distribution.
Authors: We agree that stronger evidence of generality would bolster the central claim. Our experiments already span multiple environments with different reward distributions and trace depths, but we did not include an explicit linear-vs-nonlinear ablation or systematic sweeps of optimizers and schedules. In revision we will add (i) a linear function-approximator control, (ii) quantitative bounds on the trace-depth regime where TMPB appears, and (iii) additional runs with varied learning-rate schedules and adaptive vs. non-adaptive optimizers. These additions will directly test whether the bias persists beyond the reported settings. revision: yes
-
Referee: [Mechanism description] The assertion that traces amplify distal TD errors into 'gradient shocks' that fixed-step SGD cannot normalize (leading specifically to global overestimation and peak preference) lacks a formal derivation or analysis showing why this interaction produces the observed bias rather than other systematic errors; without such analysis the preference for high-magnitude peaks remains an empirical observation whose generality is unestablished.
Authors: The manuscript supplies both an informal derivation (Section 3) linking trace length to error amplification under fixed-step SGD and controlled experiments that isolate the resulting overestimation to peak-containing trajectories. We acknowledge, however, that a fully rigorous bound separating this bias from other possible systematic errors is not provided. We will expand the mechanism section with additional analytic steps and a small proof sketch showing why second-moment normalization counters the specific amplification effect; this will be presented as a partial formalization rather than a complete theorem. revision: partial
Circularity Check
No significant circularity; derivation relies on standard RL components and experiments
full rationale
The abstract and description present TMPB as an observed phenomenon arising from the interaction of eligibility traces with TD errors and non-linear function approximation under fixed-step SGD. No equations, self-citations, or derivations are supplied that reduce the central claim to a fitted input, self-definition, or author-imported uniqueness theorem. The mechanistic account (traces amplifying distal errors into gradient shocks) follows from standard RL mathematics rather than redefining the observed bias as its own input. Generality is framed as an empirical suggestion rather than a load-bearing derivation that collapses by construction. This is a normal non-finding for an empirical RL paper whose core result is experimental.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Handbooks in operations research and management science , volume=
Markov decision processes , author=. Handbooks in operations research and management science , volume=. 1990 , publisher=
1990
-
[2]
and White, Adam and White, Martha , month = may, year =
Elelimy, Esraa and Daley, Brett and Patterson, Andrew and Machado, Marlos C. and White, Adam and White, Martha , month = may, year =. Deep
-
[3]
Reconciling łambda -
Daley, Brett and Amato, Christopher , year =. Reconciling łambda -. Advances in
-
[4]
Simplifying deep temporal difference learning
Gallici, Matteo and Fellows, Mattie and Ellis, Benjamin and Pou, Bartomeu and Masmitja, Ivan and Foerster, Jakob Nicolaus and Martin, Mario , month = apr, year =. Simplifying. doi:10.48550/arXiv.2407.04811 , abstract =
-
[5]
Learning to predict by the methods of temporal differences , volume =. Machine Learning , author =. 1988 , keywords =. doi:10.1007/BF00115009 , abstract =
-
[6]
and Barto, Andrew , year =
Sutton, Richard S. and Barto, Andrew , year =. Reinforcement learning: an introduction , isbn =
-
[7]
Kearns, Michael and Singh, Satinder , month = jan, year =. "
-
[8]
Analysis of
Tsitsiklis, John and Van Roy, Benjamin , year =. Analysis of. Advances in
-
[9]
Off-policy Learning with Eligibility Traces: A Survey
Geist, Matthieu and Scherrer, Bruno , month = apr, year =. Off-policy. doi:10.48550/arXiv.1304.3999 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1304.3999
-
[10]
Learning
Watkins, Christopher , month = jan, year =. Learning
-
[11]
Temporal credit assignment in reinforcement learning , abstract =
Sutton, Richard Stuart , year =. Temporal credit assignment in reinforcement learning , abstract =
-
[12]
Technical. Machine Learning , author =. 2002 , keywords =. doi:10.1023/A:1017936530646 , abstract =
-
[13]
Advances in
Geramifard, Alborz and Bowling, Michael and Zinkevich, Martin and Sutton, Richard S , year =. Advances in
-
[14]
Van Seijen, Harm and Sutton, Rich , month = jan, year =. True. Proceedings of the 31st
-
[15]
True online temporal-difference learning , volume =. J. Mach. Learn. Res. , author =. 2016 , pages =
2016
-
[16]
IEEE Transactions on Neural Networks and Learning Systems , author =
Algorithmic. IEEE Transactions on Neural Networks and Learning Systems , author =. 2013 , keywords =. doi:10.1109/TNNLS.2013.2247418 , abstract =
-
[17]
Journal of Computational and Applied Mathematics , author =
Projected equation methods for approximate solution of large linear systems , volume =. Journal of Computational and Applied Mathematics , author =. 2009 , keywords =. doi:10.1016/j.cam.2008.07.037 , abstract =
-
[18]
doi:10.2991/agi.2010.22 , abstract =
Artificial Intelligence , author =. doi:10.2991/agi.2010.22 , abstract =
-
[19]
Convergence of least squares temporal difference methods under general conditions , isbn =
Yu, Huizhen , month = jun, year =. Convergence of least squares temporal difference methods under general conditions , isbn =. Proceedings of the 27th
-
[20]
Proceedings of the 35th
Espeholt, Lasse and Soyer, Hubert and Munos, Remi and Simonyan, Karen and Mnih, Vlad and Ward, Tom and Doron, Yotam and Firoiu, Vlad and Harley, Tim and Dunning, Iain and Legg, Shane and Kavukcuoglu, Koray , month = jul, year =. Proceedings of the 35th
-
[21]
Safe and
Munos, Remi and Stepleton, Tom and Harutyunyan, Anna and Bellemare, Marc , year =. Safe and. Advances in
-
[22]
Revisiting
Kozuno, Tadashi and Tang, Yunhao and Rowland, Mark and Munos, Remi and Kapturowski, Steven and Dabney, Will and Valko, Michal and Abel, David , month = jul, year =. Revisiting. Proceedings of the 38th
-
[23]
Investigating Recurrence and Eligibility Traces in Deep Q-Networks
Harb, Jean and Precup, Doina , month = apr, year =. Investigating. doi:10.48550/arXiv.1704.05495 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1704.05495
-
[24]
COURSERA: Neural networks for machine learning , volume=
Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude , author=. COURSERA: Neural networks for machine learning , volume=
-
[25]
Decoupled Weight Decay Regularization , author=
-
[26]
, author=
Adaptive subgradient methods for online learning and stochastic optimization. , author=. Journal of machine learning research , volume=
-
[27]
Asynchronous
Mnih, Volodymyr and Badia, Adria Puigdomenech and Mirza, Mehdi and Graves, Alex and Lillicrap, Timothy and Harley, Tim and Silver, David and Kavukcuoglu, Koray , month = jun, year =. Asynchronous. Proceedings of
-
[28]
Van Hasselt, Hado and Madjiheurem, Sephora and Hessel, Matteo and Silver, David and Barreto, André and Borsa, Diana , month = feb, year =. Expected. doi:10.48550/arXiv.2007.01839 , abstract =
-
[29]
Asadi, Kavosh and Fakoor, Rasool and Sabach, Shoham , month = nov, year =. Resetting the. doi:10.48550/arXiv.2306.17833 , abstract =
-
[30]
Adam: A Method for Stochastic Optimization
Kingma, Diederik P. and Ba, Jimmy , month = jan, year =. Adam:. doi:10.48550/arXiv.1412.6980 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980
-
[31]
An overview of gradient descent optimization algorithms
Ruder, Sebastian , month = jun, year =. An overview of gradient descent optimization algorithms , url =. doi:10.48550/arXiv.1609.04747 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1609.04747
-
[32]
Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Rusu, Andrei A. and Veness, Joel and Bellemare, Marc G. and Graves, Alex and Riedmiller, Martin and Fidjeland, Andreas K. and Ostrovski, Georg and Petersen, Stig and Beattie, Charles and Sadik, Amir and Antonoglou, Ioannis and King, Helen and Kumaran, Dharshan and Wierstra, Daan and Legg, Shane ...
-
[33]
Haarnoja, Tuomas and Zhou, Aurick and Abbeel, Pieter and Levine, Sergey , month = aug, year =. Soft. doi:10.48550/arXiv.1801.01290 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1801.01290
-
[34]
Proximal Policy Optimization Algorithms
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , month = aug, year =. Proximal. doi:10.48550/arXiv.1707.06347 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347
-
[35]
and Chaudhari, Shreyas and Liu, Bo and Thomas, Philip S
Gupta, Dhawal and Jordan, Scott M. and Chaudhari, Shreyas and Liu, Bo and Thomas, Philip S. and da Silva, Bruno Castro , month = feb, year =. From past to future: rethinking eligibility traces , volume =. Proceedings of the. doi:10.1609/aaai.v38i11.29115 , abstract =
-
[36]
Dutta, Satrajit and Kanungo, Rabindra N. and Freibergs, Vaira , year =. Retention of affective material:. Journal of Personality and Social Psychology , publisher =. doi:10.1037/h0032790 , abstract =
-
[37]
Foundations and Trends® in Machine Learning , author =
An. Foundations and Trends® in Machine Learning , author =. 2018 , note =. doi:10.1561/2200000071 , abstract =
-
[38]
Journal of Experimental Psychology
Are affective events richly recollected or simply familiar?. Journal of Experimental Psychology. General , author =. 2000 , keywords =. doi:10.1037//0096-3445.129.2.242 , abstract =
-
[39]
Psychological Science , author =
The least likely of times: how remembering the past biases forecasts of the future , volume =. Psychological Science , author =. 2005 , keywords =. doi:10.1111/j.1467-9280.2005.01585.x , abstract =
-
[40]
Evaluating multiepisode events: boundary conditions for the peak-end rule , volume =. Emotion , author =. 2009 , keywords =. doi:10.1037/a0015295 , abstract =
-
[41]
Trends in Cognitive Sciences , author =
Catastrophic forgetting in connectionist networks , volume =. Trends in Cognitive Sciences , author =. 1999 , keywords =. doi:10.1016/S1364-6613(99)01294-2 , abstract =
-
[42]
Van Hasselt, Hado and Doron, Yotam and Strub, Florian and Hessel, Matteo and Sonnerat, Nicolas and Modayil, Joseph , month = dec, year =. Deep. doi:10.48550/arXiv.1812.02648 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1812.02648
-
[43]
Self-improving reactive agents based on reinforcement learning, planning and teaching , volume =. Machine Learning , author =. 1992 , keywords =. doi:10.1007/BF00992699 , abstract =
-
[44]
Schaul, Tom and Quan, John and Antonoglou, Ioannis and Silver, David , month = feb, year =. Prioritized. doi:10.48550/arXiv.1511.05952 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1511.05952
-
[45]
Van Hasselt, Hado , year =. Double. Advances in
-
[46]
1994 , publisher=
On-line Q-learning using connectionist systems , author=. 1994 , publisher=
1994
-
[47]
Choices, values, and frames , pages=
Evaluation by moments: Past and future , author=. Choices, values, and frames , pages=
-
[48]
, author=
Duration neglect in retrospective evaluations of affective episodes. , author=. Journal of personality and social psychology , volume=. 1993 , publisher=
1993
-
[49]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[50]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[51]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning with double q-learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[52]
International conference on machine learning , pages=
Dueling network architectures for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[53]
2020 International Joint Conference on Neural Networks (IJCNN) , pages=
The deep quality-value family of deep reinforcement learning algorithms , author=. 2020 International Joint Conference on Neural Networks (IJCNN) , pages=. 2020 , organization=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.