Revisiting Vul-RAG: Reproducibility and Replicability of RAG-based Vulnerability Detection with Open-Weight Models
Pith reviewed 2026-06-28 05:25 UTC · model grok-4.3
The pith
Vul-RAG results reproduce locally but performance plateaus at 0.30 pairwise accuracy even with newer open-weight models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The study shows that Vul-RAG findings are reproducible under local open-weights deployment with only minor deviations from the original, yet a performance plateau at approximately 0.30 pairwise accuracy holds across every evaluated model, including recent advanced ones, which demonstrates that improvements in model capacity by themselves do not substantially raise detection performance.
What carries the argument
The pairwise accuracy metric on code pairs (correct classification of both the vulnerable function and its patched counterpart) that exposes the persistent performance ceiling.
If this is right
- The original Vul-RAG results generalize to fully local open-weight deployments.
- Neither model size nor recency breaks the 0.30 pairwise accuracy limit.
- Detection effectiveness, model capabilities, and model scale involve concrete trade-offs that practitioners must weigh.
Where Pith is reading between the lines
- The plateau suggests that further progress may require changes to the retrieval component or the injected vulnerability knowledge rather than larger base models.
- Open-weight models appear sufficient for reproducing this class of RAG vulnerability detector without reliance on closed APIs.
- The same evaluation setup could be used to test whether fine-tuning or different knowledge sources can lift performance above the current ceiling.
Load-bearing premise
The chosen collection of open-weight models adequately represents the broader space of models so the observed plateau is not an artifact of those specific selections.
What would settle it
An open-weight model achieving clearly higher pairwise accuracy, for example above 0.45, on the same dataset and task would contradict the plateau claim.
Figures
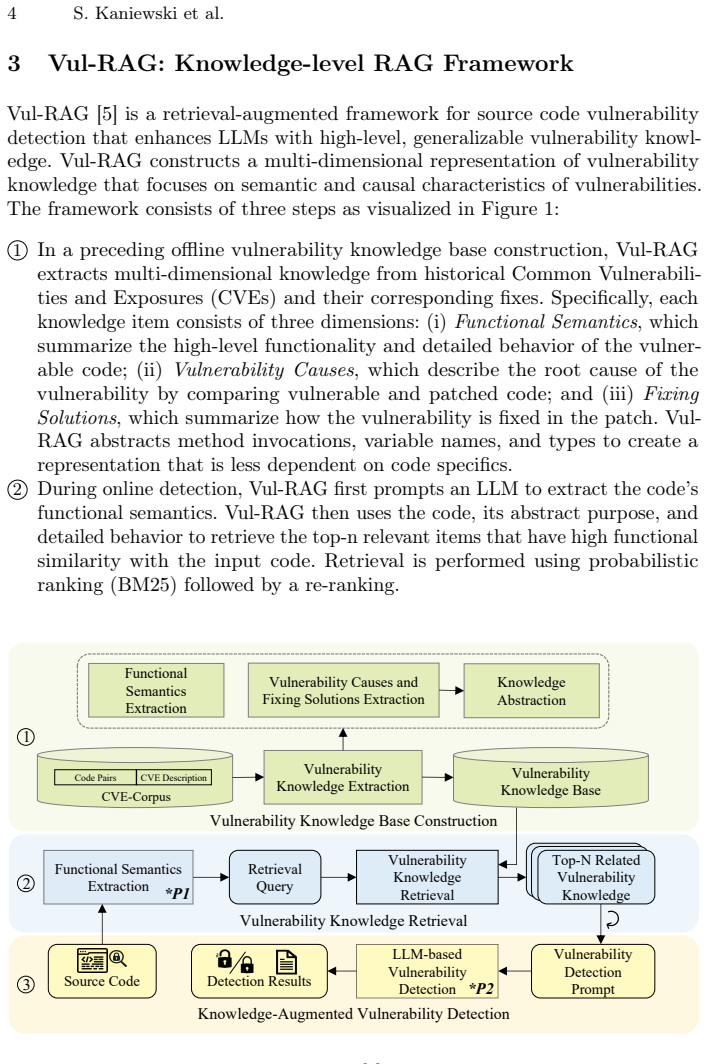

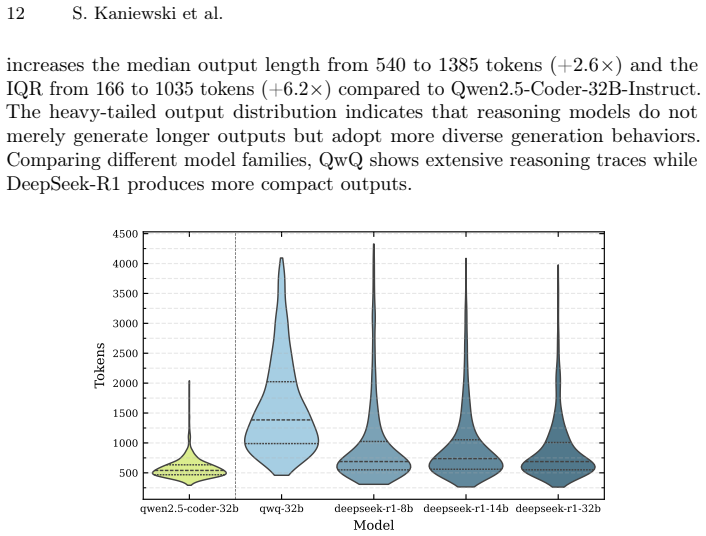
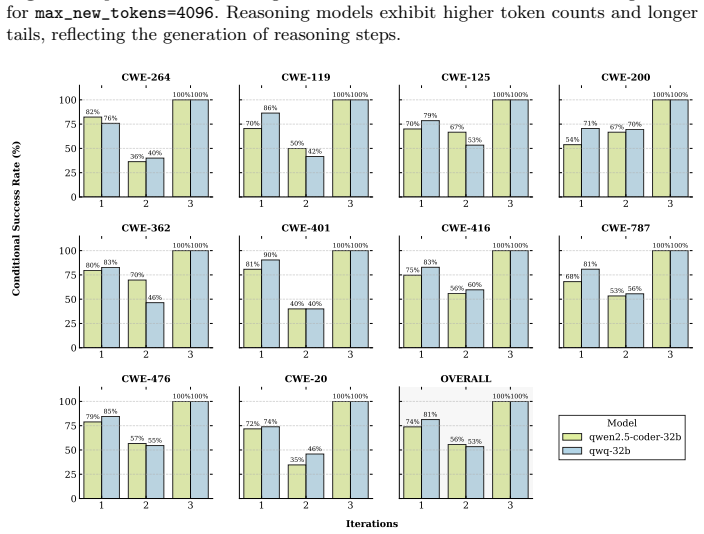
read the original abstract
Large language models (LLMs) have shown strong potential for automated software vulnerability detection, particularly in retrieval-augmented generation (RAG) settings. However, for approaches relying on proprietary models and APIs, reproducibility and replicability remain largely unexplored, raising the question of whether reported results generalize or depend primarily on specific model choices. In this work, we present a reproducibility study of Vul-RAG, a RAG-based framework for source code vulnerability detection that enhances LLMs with high-level vulnerability knowledge. We first replicate the results in a fully local and open-weights setting using the reported open-weight baseline models. We then extend the evaluation to a diverse set of recent open-weight LLMs, including code-specialized, general-purpose, and reasoning models of varying parameter sizes. The results confirm that the findings of Vul-RAG are reproducible under local deployment, but with minor deviations. Across all evaluated models, we observe a performance plateau at approximately 0.30 pairwise accuracy (code pairs for which both the vulnerable and the patched function are correctly classified). Notably, this plateau persists even for more recent and advanced models, indicating that improvements in model capacity alone do not substantially enhance performance. Finally, we discuss practical implications and trade-offs between detection effectiveness, model capabilities, and model scale. Implementation and evaluation artifacts are publicly available at https://github.com/hs-esslingen-it-security/revisiting-Vul-RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a reproducibility study of Vul-RAG, a RAG-based framework that augments LLMs with high-level vulnerability knowledge for source-code vulnerability detection. The authors first replicate the original results using the reported open-weight baseline models in a fully local setting, then extend the evaluation to a broader cohort of recent open-weight LLMs (code-specialized, general-purpose, and reasoning models of varying sizes). They report that the original findings are reproducible with only minor deviations and that a performance plateau of approximately 0.30 pairwise accuracy (correct classification of both vulnerable and patched functions in a pair) persists across all tested models, including newer and larger ones, leading to the conclusion that improvements in model capacity alone do not substantially enhance performance. Implementation artifacts are released publicly.
Significance. If the reported plateau is robust, the work has clear significance for the software-security and LLM-for-code communities: it supplies concrete evidence that simply scaling open-weight models is unlikely to overcome current limits in RAG-based vulnerability detection and therefore directs attention toward other levers such as retrieval quality, knowledge representation, or task-specific adaptation. The public release of code and evaluation artifacts is a concrete strength that directly supports replicability claims in the field.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): the central claim that the ~0.30 pairwise-accuracy plateau 'persists even for more recent and advanced models' and therefore that 'improvements in model capacity alone do not substantially enhance performance' is load-bearing for the paper's main conclusion, yet the manuscript provides no enumeration of the concrete models, their parameter counts, training regimes, or a scaling plot. Without this information it is impossible to verify that capacity was varied over a range large enough for an effect to appear if one existed, undermining the representativeness argument.
- [§4.2] §4.2 (Model selection): the description of the cohort as 'code-specialized, general-purpose, and reasoning models of varying parameter sizes' is too coarse to rule out systematic bias toward decoder-only transformers trained on overlapping code corpora; a table listing every model, size, source, and any fine-tuning details is required to support the generalization.
minor comments (2)
- [Results] The definition of pairwise accuracy is given in the abstract but should be restated verbatim in the results section and any tables that report it, to avoid ambiguity for readers who start with the figures.
- [Artifacts] The GitHub link is provided; confirm that the released artifacts include the exact dataset splits, prompts, and statistical-test scripts used for the replication so that future replicators can match the reported minor deviations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript accordingly to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the central claim that the ~0.30 pairwise-accuracy plateau 'persists even for more recent and advanced models' and therefore that 'improvements in model capacity alone do not substantially enhance performance' is load-bearing for the paper's main conclusion, yet the manuscript provides no enumeration of the concrete models, their parameter counts, training regimes, or a scaling plot. Without this information it is impossible to verify that capacity was varied over a range large enough for an effect to appear if one existed, undermining the representativeness argument.
Authors: We agree that a detailed listing of models and a visualization of performance across scales would strengthen the manuscript. In the revised version, we will add a table in §4.2 enumerating all evaluated models, including their parameter counts, architectures, sources, and training/fine-tuning details where publicly available. We will also include a scaling plot in §4 showing pairwise accuracy as a function of model size (in parameters) to demonstrate the observed plateau across the tested range. This addresses the concern about the representativeness of the capacity variation. revision: yes
-
Referee: [§4.2] §4.2 (Model selection): the description of the cohort as 'code-specialized, general-purpose, and reasoning models of varying parameter sizes' is too coarse to rule out systematic bias toward decoder-only transformers trained on overlapping code corpora; a table listing every model, size, source, and any fine-tuning details is required to support the generalization.
Authors: We acknowledge that the current high-level categorization may not sufficiently address potential biases. We will revise §4.2 to include a detailed table with every model, its size (parameter count), source (e.g., specific Hugging Face model identifiers), and any known fine-tuning or specialization information. This will enable readers to evaluate the diversity of the cohort and assess the generalizability of the performance plateau finding. revision: yes
Circularity Check
No circularity: empirical replication of existing results with no derivations or self-referential quantities
full rationale
The paper is a reproducibility study that executes Vul-RAG on open-weight models, reports pairwise accuracy numbers, and observes an empirical plateau at ~0.30. No equations, fitted parameters, predictions derived from internal definitions, or self-citation chains appear in the abstract or described methodology. All reported quantities are direct experimental outputs from running models on the same benchmark; none reduce to quantities defined inside the paper itself. The generalization concern about model representativeness is a question of external validity, not circularity in any derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A local open-weights replication using the reported baseline models faithfully captures the core claims of the original Vul-RAG framework.
Reference graph
Works this paper leans on
-
[1]
Angermeir, F., Amougou, M., Kreitz, M., Bauer, A., Linhuber, M., Fucci, D., et al.: Reflections on the Reproducibility of Commercial LLM Performance in Empirical Software Engineering Studies. arXiv:2510.25506 (2025)
arXiv 2025
-
[2]
IEEE Access14, 50878–50891 (2026).https://doi
Antal, G., Értekes, L., Szolnoki, N., Hegedűs, P.: Evaluating Retrieval-Augmented Generation for LLM-Based Vulnerability Detection: An Empirical Study on Real- World Java Vulnerabilities. IEEE Access14, 50878–50891 (2026).https://doi. org/10.1109/ACCESS.2026.3676577
-
[3]
IEEE Transactions on Software Engineering50(8), 2163–2177 (2024)
Chakraborty, P., Arumugam, K.K., Alfadel, M., Nagappan, M., McIntosh, S.: Revisiting the performance of deep learning-based vulnerability detection on realistic datasets. IEEE Transactions on Software Engineering50(8), 2163–2177 (2024). https://doi.org/10.1109/TSE.2024.3423712
-
[4]
DeepSeek-AI, Zhu, Q., Guo, D., Shao, Z., Yang, D., Wang, P., et al.: DeepSeek- Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence. arXiv:2406.11931 (2024)
Pith/arXiv arXiv 2024
-
[5]
Du, X., Zheng, G., Wang, K., Zou, Y., Wang, Y., Deng, W., et al.: Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG. ACM Transactions on Software Engineering and Methodology (TOSEM) (2026).https: //doi.org/10.1145/3797277, Just Accepted
-
[6]
Nature645(8081), 633–638 (2025)
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., et al.: DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature645(8081), 633–638 (2025)
2025
-
[7]
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., et al.: Qwen2.5-Coder Technical Report. arXiv:2409.12186 (2024)
Pith/arXiv arXiv 2024
-
[8]
In: Conference on AI, Science, Engineering, and Technology (AIxSET)
Kaniewski, S., Holstein, D., Schmidt, F., Heer, T.: Vulnerability Handling of AI- Generated Code - Existing Solutions and Open Challenges. In: Conference on AI, Science, Engineering, and Technology (AIxSET). pp. 145–148. Laguna Hills, CA, USA (2024).https://doi.org/10.1109/AIxSET62544.2024.00026 18 S. Kaniewski et al
-
[9]
Kaniewski, S., Schmidt, F., Enzweiler, M., Menth, M., Heer, T.: A Systematic Literature Review on Detecting Software Vulnerabilities with Large Language Models. ACM Transactions on Software Engineering and Methodology (TOSEM) (2026).https://doi.org/10.1145/3815425, Just Accepted
-
[10]
In: Advances in Neural Information Processing Systems (NeurIPS)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., et al.: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 33, pp. 9459–9474 (2020)
2020
-
[11]
Journal of Systems and Software (JSS)212, 112031 (2024)
Lu, G., Ju, X., Chen, X., Pei, W., Cai, Z.: GRACE: Empowering LLM-based Software Vulnerability Detection with Graph Structure and In-Context Learning. Journal of Systems and Software (JSS)212, 112031 (2024)
2024
-
[12]
https://cwe.mitre.org/data/ definitions/1000.html(2026), accessed 2026-03-06
MITRE: CWE-1000: Research Concepts. https://cwe.mitre.org/data/ definitions/1000.html(2026), accessed 2026-03-06
2026
-
[13]
Nong, Y., Sharma, R., Hamou-Lhadj, A., Luo, X., Cai, H.: Open Science in Software Engineering: A Study on Deep Learning-Based Vulnerability Detection. IEEE Transactions on Software Engineering49(4), 1983–2005 (2023).https://doi.org/ 10.1109/TSE.2022.3207149
-
[14]
Qwen: Qwen2.5-LLM: Extending the boundary of LLMs.https://qwen.ai/blog? id=qwen2.5-llm, accessed 2026-03-04
2026
-
[15]
ai/blog?id=qwq-32b, accessed 2026-03-04
Qwen: QwQ-32B: Embracing the Power of Reinforcement Learning.https://qwen. ai/blog?id=qwq-32b, accessed 2026-03-04
2026
-
[16]
Safdar, R., Mateen, D., Ali, S.T., Hussain, W.: Real-VulLLM: An LLM Based Assessment Framework in the Wild. arXiv:2510.04056 (2025)
Pith/arXiv arXiv 2025
-
[17]
Sallou, J., Durieux, T., Panichella, A.: Breaking the Silence: the Threats of Using LLMsinSoftwareEngineering.In:ACM/IEEEInternationalConferenceonSoftware Engineering: New Ideas and Emerging Results (ICSE-NIER). p. 102–106. Lisbon, Portugal (2024).https://doi.org/10.1145/3639476.3639764
-
[18]
Does data sampling improve deep learning-based vulnerability detection? yeas! and nays!
Steenhoek, B., Rahman, M.M., Jiles, R., Le, W.: An Empirical Study of Deep Learning Models for Vulnerability Detection. In: IEEE/ACM International Confer- ence on Software Engineering (ICSE). pp. 2237–2248. Melbourne, Australia (2023). https://doi.org/10.1109/ICSE48619.2023.00188
-
[19]
Sun, Y., Wu, D., Xue, Y., Liu, H., Ma, W., Zhang, L., et al.: LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs’ Vulnerability Reasoning. arXiv:2401.16185 (2025)
arXiv 2025
-
[20]
In: Conference on Empirical Methods in Natural Language Processing (EMNLP)
Tsai, C.N., Wang, X., Lee, C.H., Lin, C.S.: A Sequential Multi-Stage Approach for Code Vulnerability Detection via Confidence- and Collaboration-based Decision Making. In: Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 21162–21168. Suzhou, China (2025).https://doi.org/10.18653/ v1/2025.emnlp-main.1071
2025
-
[21]
Cluster Computing28(15), 1–12 (2025).https://doi.org/10.1007/s10586-025-05721-2
Tsai, C.N., Xie, J., Lai, C.M., Lin, C.S.: Leveraging Intra-and Inter-References in Vulnerability Detection using Multi-Agent Collaboration Based on LLMs. Cluster Computing28(15), 1–12 (2025).https://doi.org/10.1007/s10586-025-05721-2
-
[22]
Wen, X.C., Wang, X., Chen, Y., Hu, R., Lo, D., Gao, C.: VulEval: Towards Repository-Level Evaluation of Software Vulnerability Detection. arXiv:2404.15596 (2024)
arXiv 2024
-
[23]
Wu, Z., Xu, J., Peng, Y., Chong, C.Y., Jia, X.: MulVul: Retrieval-augmented Multi-Agent Code Vulnerability Detection via Cross-Model Prompt Evolution. arXiv:2601.18847 (2026)
arXiv 2026
-
[24]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., et al.: Qwen3 Technical Report. arXiv:2505.09388 (2025)
Pith/arXiv arXiv 2025
-
[25]
Zhu, H., Li, J., Gao, C., Qian, J., Dong, Y., Liu, H., et al.: Specification-Guided Vulnerability Detection with Large Language Models. arXiv:2511.04014 (2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.