NextMotionQA: Benchmarking and Judging Human Motion Understanding with Vision-Language Models
Pith reviewed 2026-06-28 06:52 UTC · model grok-4.3
The pith
Vision-language models match experts on coarse human motion ratings but fail on fine-grained part-level judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
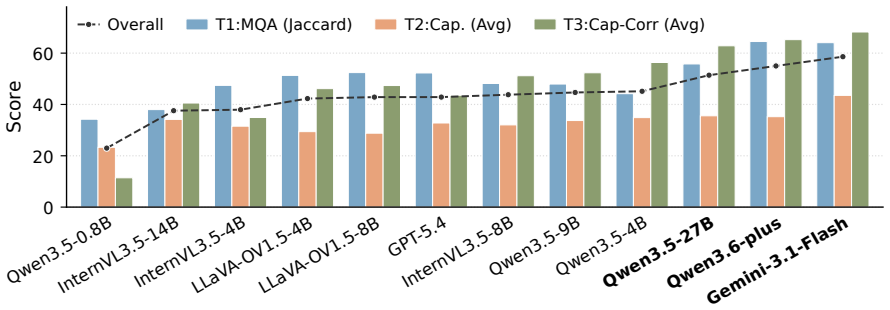
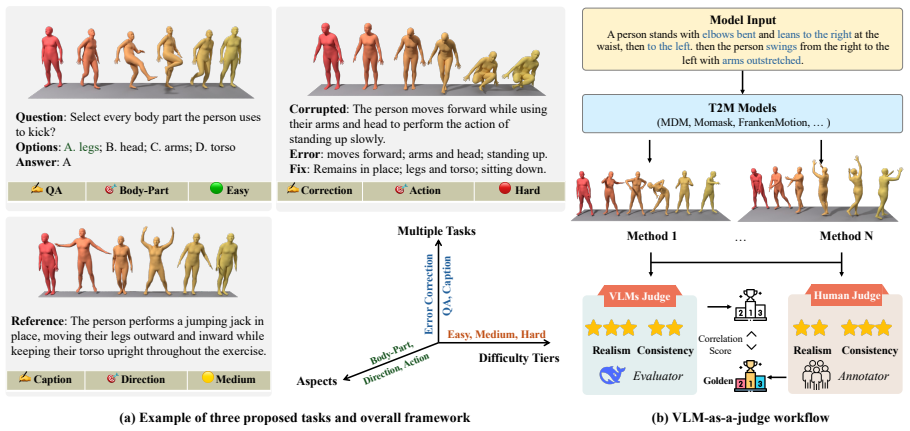
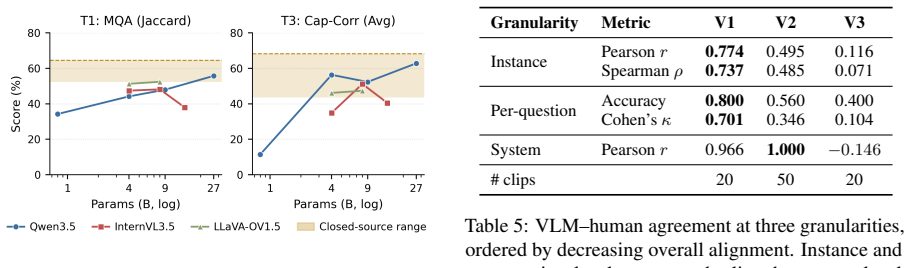
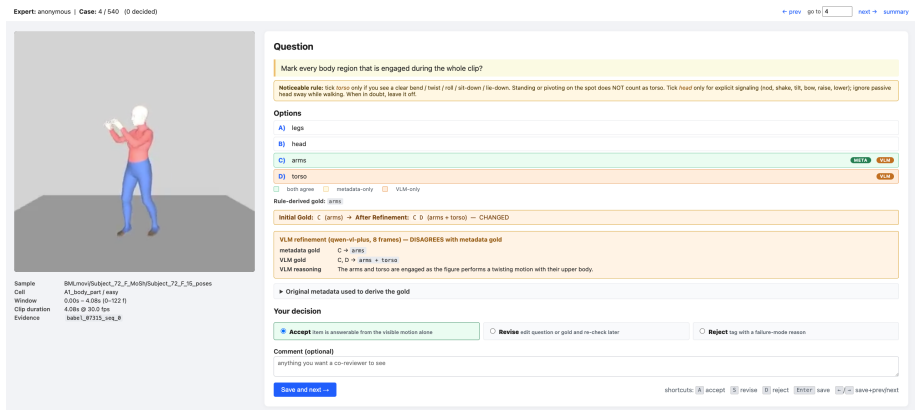
NextMotionQA is a benchmark built with a semi-automated expert-verified process that includes three complementary tasks structured across three core semantic axes and stratified into three complexity levels. Extensive tests on twelve VLMs uncover capability gaps invisible under single-task evaluations. VLMs align strongly with expert ratings on coarse criteria with Cohen's κ equal to 0.70 but break down on fine-grained part-level judgment with κ equal to 0.10.
What carries the argument
The NextMotionQA benchmark with its three tasks (multiple-choice QA, video captioning, fine-grained error correction) stratified by semantic axes and complexity levels, plus the use of Cohen's κ to measure VLM-expert agreement on judging tasks.
If this is right
- Single-task evaluations hide real weaknesses in VLMs for human motion understanding.
- VLMs can serve as reliable judges only for coarse motion criteria, not detailed analysis.
- Benchmarks with explicit complexity levels and multiple tasks are required to diagnose VLM limits accurately.
Where Pith is reading between the lines
- Applications in robotics and animation that rely on fine motion details may still need human oversight even when using VLMs.
- Future model training could target the specific failure modes identified in part-level motion judgment.
- The benchmark structure could be adapted to test motion understanding in non-human domains such as animals or objects.
Load-bearing premise
The semi-automated expert-verified dataset creation produces annotations without systematic biases or ambiguities that would distort the measured gaps in model performance.
What would settle it
Re-annotating a subset of the benchmark videos by an independent group of experts and finding substantially different agreement rates between VLMs and those new annotations on the fine-grained tasks.
Figures

read the original abstract
Reliable evaluation of human motion understanding is fundamental to advancing embodied AI, robotics, and animation. However, existing benchmarks suffer from coarse semantic granularity, undifferentiated difficulty, limited annotation quality, and pervasive answer ambiguity, leaving them unable to diagnose where current models fail. To bridge this gap, we introduce NextMotionQA, a comprehensive benchmark that leverages vision-language models (VLMs) for semi-automated, expert-verified dataset. NextMotionQA features three complementary tasks: multiple-choice question answering, video captioning, and fine-grained error correction. Each task is systematically structured across three core semantic axes and stratified into three task complexity levels. Our extensive evaluation of twelve representative VLMs uncovers critical capability gaps and weakness that remain invisible under conventional, single-task evaluations. In a complementary direction, recent work has begun using VLMs as judges for text-to-motion evaluation; we ask whether they show the same degradation under harder tasks. We find that VLMs align strongly with expert ratings on coarse criteria (Cohen's \kappa=0.70) but break down on fine-grained, part-level judgment (\kappa=0.10), validating the paradigm in its strong regime while clarifying its limits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NextMotionQA, a benchmark for human motion understanding in VLMs comprising three tasks (multiple-choice QA, video captioning, fine-grained error correction) organized along three semantic axes and three complexity levels. It uses a semi-automated expert-verified pipeline to create the dataset and evaluates twelve VLMs, reporting that they align well with expert ratings on coarse criteria (Cohen's κ=0.70) but degrade sharply on fine-grained part-level judgments (κ=0.10). The work positions this as both a diagnostic benchmark and a test of VLMs as judges for text-to-motion evaluation.
Significance. If the expert annotations prove reliable, the multi-task, multi-axis, multi-level design supplies a finer-grained diagnostic than prior motion benchmarks, exposing specific VLM failure modes invisible in single-task evaluations and clarifying the regime where VLM judges remain trustworthy. The semi-automated creation process itself is a practical engineering contribution for scalable annotation.
major comments (2)
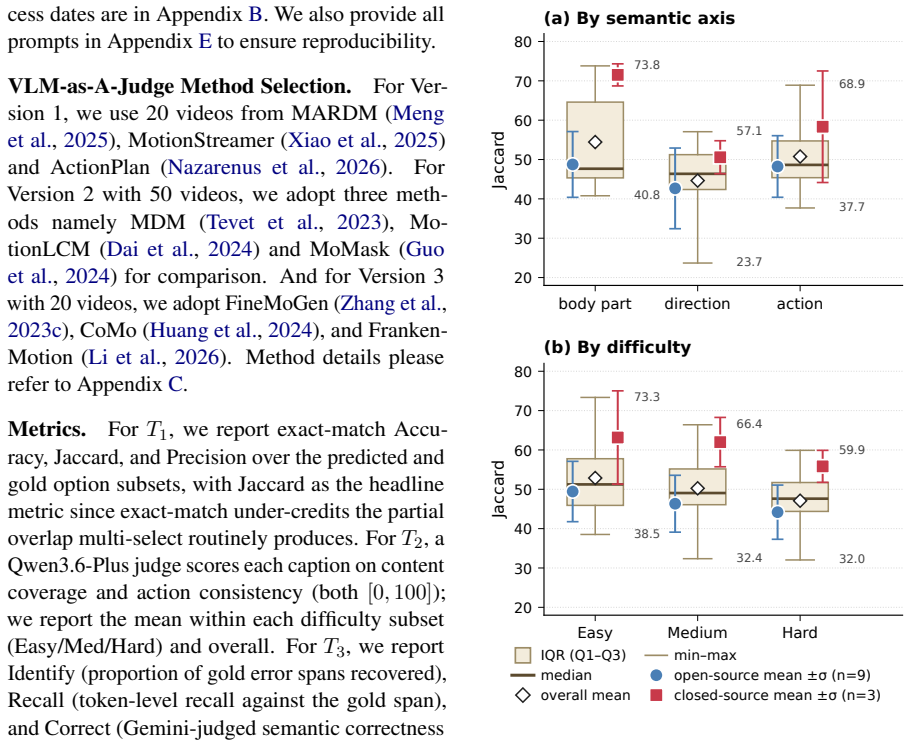
- [Dataset creation / annotation protocol] Dataset creation section: the semi-automated expert-verified pipeline is described as producing unambiguous annotations, yet no inter-annotator agreement metrics (Cohen's κ, Fleiss' κ, or equivalent) are reported specifically for the fine-grained error-correction task or part-level judgments. This is load-bearing for the central claim, because the reported drop from κ=0.70 (coarse) to κ=0.10 (fine) cannot be attributed to VLM limitations unless expert labels are shown to be a stable gold standard rather than noisy or ambiguous.
- [VLM judge evaluation subsection] Results on VLM-as-judge (the κ comparison): the paper states the coarse/fine-grained κ values but does not report the number of expert annotators, number of items rated, or exact rating protocol used for the fine-grained condition. Without these, the magnitude of the degradation cannot be assessed for statistical robustness or potential confounds such as differing item difficulty distributions.
minor comments (2)
- [Introduction / benchmark overview] The three semantic axes and three complexity levels are introduced in the abstract and overview but would benefit from an explicit table or diagram early in the paper showing how tasks map onto axes × levels.
- [Task definitions] Notation for the three tasks (MCQA, captioning, error correction) is used consistently but the exact prompt templates or output formats for each are not reproduced in a single reference table, complicating replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the annotation protocol and evaluation details. We address each major comment below.
read point-by-point responses
-
Referee: [Dataset creation / annotation protocol] Dataset creation section: the semi-automated expert-verified pipeline is described as producing unambiguous annotations, yet no inter-annotator agreement metrics (Cohen's κ, Fleiss' κ, or equivalent) are reported specifically for the fine-grained error-correction task or part-level judgments. This is load-bearing for the central claim, because the reported drop from κ=0.70 (coarse) to κ=0.10 (fine) cannot be attributed to VLM limitations unless expert labels are shown to be a stable gold standard rather than noisy or ambiguous.
Authors: We agree that explicit inter-annotator agreement metrics are necessary to substantiate the reliability of the expert labels as a gold standard. The current manuscript does not report these metrics for the fine-grained tasks. In the revision we will add Cohen's κ values computed among the expert annotators for both coarse and fine-grained conditions, confirming consistency of the labels and supporting attribution of the VLM degradation to model limitations. revision: yes
-
Referee: [VLM judge evaluation subsection] Results on VLM-as-judge (the κ comparison): the paper states the coarse/fine-grained κ values but does not report the number of expert annotators, number of items rated, or exact rating protocol used for the fine-grained condition. Without these, the magnitude of the degradation cannot be assessed for statistical robustness or potential confounds such as differing item difficulty distributions.
Authors: We acknowledge the omission of these procedural details. The revised manuscript will specify the number of expert annotators, the number of items rated under the fine-grained protocol, and the exact rating instructions and scale used. These additions will enable readers to evaluate statistical robustness and rule out confounds. revision: yes
Circularity Check
No circularity: empirical benchmark with direct expert comparisons
full rationale
The paper introduces NextMotionQA as a new benchmark with three tasks (MCQA, captioning, error correction) stratified by semantic axes and complexity, then reports empirical VLM evaluations and Cohen's κ alignments with expert ratings (0.70 coarse, 0.10 fine-grained). No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claims rest on dataset construction and direct measurement against external expert annotations rather than any reduction to self-referential definitions or renamings. The absence of mathematical derivations or load-bearing self-citations makes the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert verification ensures the quality and lack of ambiguity in the dataset annotations.
- domain assumption The three semantic axes and three complexity levels provide a comprehensive coverage of human motion understanding.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
IMoRe: Implicit Program-Guided Reasoning for Human Motion Q&A , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[2]
arXiv preprint arXiv:2602.17768 , year=
KPM-Bench: A Kinematic Parsing Motion Benchmark for Fine-grained Motion-centric Video Understanding , author=. arXiv preprint arXiv:2602.17768 , year=
-
[3]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Towards Fine-Grained Human Motion Video Captioning , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[4]
arXiv preprint arXiv:2605.19846 , year=
FineBench: Benchmarking and Enhancing Vision-Language Models for Fine-grained Human Activity Understanding , author=. arXiv preprint arXiv:2605.19846 , year=
-
[5]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[6]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Motionllm: Understanding human behaviors from human motions and videos , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[7]
Li, Chuqiao and Xie, Xianghui and Cao, Yong and Geiger, Andreas and Pons-Moll, Gerard , booktitle=
-
[8]
and Chandrasekaran, Arjun and Athanasiou, Nikos and Quiros-Ramirez, Alejandra and Black, Michael J
Punnakkal, Abhinanda R. and Chandrasekaran, Arjun and Athanasiou, Nikos and Quiros-Ramirez, Alejandra and Black, Michael J. , booktitle =. 2021 , doi =
2021
-
[9]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Xiao, Lixing and Lu, Shunlin and Pi, Huaijin and Fan, Ke and Pan, Liang and Zhou, Yueer and Feng, Ziyong and Zhou, Xiaowei and Peng, Sida and Wang, Jingbo , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[10]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Rethinking diffusion for text-driven human motion generation: Redundant representations, evaluation, and masked autoregression , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[11]
arXiv preprint arXiv:2603.13500 , year=
ActionPlan: Future-Aware Streaming Motion Synthesis via Frame-Level Action Planning , author=. arXiv preprint arXiv:2603.13500 , year=
-
[12]
European Conference on Computer Vision , pages=
Como: Controllable motion generation through language guided pose code editing , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[13]
The Fourteenth International Conference on Learning Representations , year=
The Quest for Generalizable Motion Generation: Data, Model, and Evaluation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[14]
and Pons-Moll, Gerard and Black, Michael J
Mahmood, Naureen and Ghorbani, Nima and Troje, Nikolaus F. and Pons-Moll, Gerard and Black, Michael J. , booktitle =. 2019 , month_numeric =
2019
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Guo, Chuan and Zou, Shihao and Zuo, Xinxin and Wang, Sen and Ji, Wei and Li, Xingyu and Cheng, Li , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Momask: Generative masked modeling of 3d human motions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
arXiv preprint arXiv:2209.14916 , year=
Human motion diffusion model , author=. arXiv preprint arXiv:2209.14916 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Motiongpt: Human motion as a foreign language , author=. Advances in Neural Information Processing Systems , volume=. 2023 , eprint=
2023
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[20]
International Conference on Machine Learning , pages=
Motion question answering via modular motion programs , author=. International Conference on Machine Learning , pages=. 2023 , organization=. 2305.08953 , archivePrefix=
arXiv 2023
-
[21]
International Conference on Machine Learning , pages=
Motion question answering via modular motion programs , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[22]
The Eleventh International Conference on Learning Representations , year=
Human Motion Diffusion Model , author=. The Eleventh International Conference on Learning Representations , year=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Executing Your Commands via Motion Diffusion in Latent Space , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2023 , eprint=
2023
-
[24]
arXiv preprint arXiv:2405.20340 , year=
MotionLLM: Understanding Human Behaviors from Human Motions and Videos , author=. arXiv preprint arXiv:2405.20340 , year=. 2405.20340 , archivePrefix=
-
[25]
arXiv preprint arXiv:2405.17013 , year=
Motion-Agent: A Conversational Framework for Human Motion Generation with LLMs , author=. arXiv preprint arXiv:2405.17013 , year=. 2405.17013 , archivePrefix=
-
[26]
arXiv preprint arXiv:2411.17335 , year=
VersatileMotion: A Unified Framework for Motion Synthesis and Comprehension , author=. arXiv preprint arXiv:2411.17335 , year=. 2411.17335 , archivePrefix=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
MG-MotionLLM: A Unified Framework for Motion Comprehension and Generation across Multiple Granularities , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=. 2504.02478 , archivePrefix=
-
[28]
Advances in Neural Information Processing Systems , year=
Visual Instruction Tuning , author=. Advances in Neural Information Processing Systems , year=. 2304.08485 , archivePrefix=
-
[29]
Proceedings of the Annual Meeting of the Association for Computational Linguistics , year=
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models , author=. Proceedings of the Annual Meeting of the Association for Computational Linguistics , year=. 2306.05424 , archivePrefix=
-
[30]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[31]
arXiv preprint arXiv:2503.14935 , year=
FAVOR-Bench: A Comprehensive Benchmark for Fine-Grained Video Motion Understanding , author=. arXiv preprint arXiv:2503.14935 , year=
-
[32]
Proceedings of the Conference on Empirical Methods in Natural Language Processing , year=
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing , year=. 2303.16634 , archivePrefix=
-
[33]
arXiv preprint arXiv:2401.06591 , year=
Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation , author=. arXiv preprint arXiv:2401.06591 , year=. 2401.06591 , archivePrefix=
-
[34]
International Conference on Machine Learning , year=
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark , author=. International Conference on Machine Learning , year=. 2402.04788 , archivePrefix=
-
[35]
arXiv preprint arXiv:2307.15818 , year=
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author=. arXiv preprint arXiv:2307.15818 , year=. 2307.15818 , archivePrefix=
-
[36]
arXiv preprint arXiv:2406.09246 , year=
OpenVLA: An Open-Source Vision-Language-Action Model , author=. arXiv preprint arXiv:2406.09246 , year=. 2406.09246 , archivePrefix=
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Generating Diverse and Natural 3D Human Motions from Text , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Remodiffuse: Retrieval-augmented motion diffusion model , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[39]
2023 , journal =
FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing , author =. 2023 , journal =
2023
-
[40]
European Conference on Computer Vision , year=
MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model , author=. European Conference on Computer Vision , year=. 2404.19759 , archivePrefix=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Avatargpt: All-in-one framework for motion understanding planning generation and beyond , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
arXiv preprint arXiv:2408.03326 , year=
LLaVA-OneVision: Easy Visual Task Transfer , author=. arXiv preprint arXiv:2408.03326 , year=. 2408.03326 , archivePrefix=
-
[43]
arXiv preprint arXiv:2501.13106 , year=
Videollama 3: Frontier multimodal foundation models for image and video understanding , author=. arXiv preprint arXiv:2501.13106 , year=
-
[44]
Advances in Neural Information Processing Systems , year=
EgoSchema: A Diagnostic Benchmark for Very Long-form Video Language Understanding , author=. Advances in Neural Information Processing Systems , year=. 2308.09126 , archivePrefix=
-
[45]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
TempCompass: Do Video LLMs Really Understand Videos? , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=. 2024 , eprint=
2024
-
[46]
arXiv preprint arXiv:2405.21075 , year=
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis , author=. arXiv preprint arXiv:2405.21075 , year=. 2405.21075 , archivePrefix=
-
[47]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[48]
Robotics: Science and Systems , year=
Octo: An Open-Source Generalist Robot Policy , author=. Robotics: Science and Systems , year=. 2405.12213 , archivePrefix=
-
[49]
arXiv preprint arXiv:2410.24164 , year=
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=. 2410.24164 , archivePrefix=
-
[50]
arXiv preprint arXiv:2410.07864 , year=
RDT-1B: A Diffusion Foundation Model for Bimanual Manipulation , author=. arXiv preprint arXiv:2410.07864 , year=. 2410.07864 , archivePrefix=
-
[51]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Xie, Xianghui and Lessen, Jan Eric and Pons-Moll, Gerard , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[52]
Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024
2024
-
[53]
Investigating radicalisation indicators in online extremist communities
De Kock, Christine and Hovy, Eduard. Investigating radicalisation indicators in online extremist communities. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.1
-
[54]
Pustet, Milena and Steffen, Elisabeth and Mihaljevic, Helena. Detection of Conspiracy Theories Beyond Keyword Bias in G erman-Language Telegram Using Large Language Models. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.2
-
[55]
Ilevbare, Comfort and Alabi, Jesujoba and Adelani, David Ifeoluwa and Bakare, Firdous and Abiola, Oluwatoyin and Adeyemo, Oluwaseyi. E ko H ate: Abusive Language and Hate Speech Detection for Code-switched Political Discussions on N igerian T witter. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.3
-
[56]
A Study of the Class Imbalance Problem in Abusive Language Detection
Zhang, Yaqi and Hangya, Viktor and Fraser, Alexander. A Study of the Class Imbalance Problem in Abusive Language Detection. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.4
-
[57]
H ausa H ate: An Expert Annotated Corpus for H ausa Hate Speech Detection
Vargas, Francielle and Guimar \ a es, Samuel and Muhammad, Shamsuddeen Hassan and Alves, Diego and Ahmad, Ibrahim Said and Abdulmumin, Idris and Mohamed, Diallo and Pardo, Thiago and Benevenuto, Fabr \' cio. H ausa H ate: An Expert Annotated Corpus for H ausa Hate Speech Detection. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 202...
-
[58]
VIDA : The Visual Incel Data Archive
Anastasi, Selenia and Schneider, Florian and Biemann, Chris and Fischer, Tim. VIDA : The Visual Incel Data Archive. A Theory-oriented Annotated Dataset To Enhance Hate Detection Through Visual Culture. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.6
-
[59]
Towards a Unified Framework for Adaptable Problematic Content Detection via Continual Learning
Omrani, Ali and Salkhordeh Ziabari, Alireza and Golazizian, Preni and Sorensen, Jeffrey and Dehghani, Morteza. Towards a Unified Framework for Adaptable Problematic Content Detection via Continual Learning. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.7
-
[60]
From Linguistics to Practice: a Case Study of Offensive Language Taxonomy in H ebrew
Liebeskind, Chaya and Litvak, Marina and Vanetik, Natalia. From Linguistics to Practice: a Case Study of Offensive Language Taxonomy in H ebrew. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.8
-
[61]
Estimating the Emotion of Disgust in G reek Parliament Records
Lislevand, Vanessa and Pavlopoulos, John and Louridas, Panos and Dritsa, Konstantina. Estimating the Emotion of Disgust in G reek Parliament Records. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.9
-
[62]
Simple LLM based Approach to Counter Algospeak
Fillies, Jan and Paschke, Adrian. Simple LLM based Approach to Counter Algospeak. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.10
-
[63]
Harnessing Personalization Methods to Identify and Predict Unreliable Information Spreader Behavior
Ashraf, Shaina and Gruschka, Fabio and Flek, Lucie and Welch, Charles. Harnessing Personalization Methods to Identify and Predict Unreliable Information Spreader Behavior. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.11
-
[64]
Robust Safety Classifier Against Jailbreaking Attacks: Adversarial Prompt Shield
Kim, Jinhwa and Derakhshan, Ali and Harris, Ian. Robust Safety Classifier Against Jailbreaking Attacks: Adversarial Prompt Shield. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.12
-
[65]
Reyes-Ram \' rez, Antonio and Arag \'o n, Mario and S \'a nchez-Vega, Fernando and L \'o pez-Monroy, Adrian. Improving aggressiveness detection using a data augmentation technique based on a Diffusion Language Model. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.13
-
[66]
Andersen, Scott and Ojeda-Trueba, Segio-Luis and V \'a squez, Juan and Bel-Enguix, Gemma. The M exican Gayze: A Computational Analysis of the Attitudes towards the LGBT + Population in M exico on Social Media Across a Decade. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.14
-
[67]
X -posing Free Speech: Examining the Impact of Moderation Relaxation on Online Social Networks
Arun, Arvindh and Chhatani, Saurav and An, Jisun and Kumaraguru, Ponnurangam. X -posing Free Speech: Examining the Impact of Moderation Relaxation on Online Social Networks. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.15
-
[68]
The Uli Dataset: An Exercise in Experience Led Annotation of o GBV
Arora, Arnav and Jinadoss, Maha and Arora, Cheshta and George, Denny and Brindaalakshmi and Khan, Haseena and Rawat, Kirti and Div and Ritash and Mathur, Seema. The Uli Dataset: An Exercise in Experience Led Annotation of o GBV. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.16
-
[69]
Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales
Nirmal, Ayushi and Bhattacharjee, Amrita and Sheth, Paras and Liu, Huan. Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.17
-
[70]
Brate, Ryan and Van Erp, Marieke and Van Den Bosch, Antal. A B ayesian Quantification of Aporophobia and the Aggravating Effect of Low -- Wealth Contexts on Stigmatization. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.18
-
[71]
Toxicity Classification in U krainian
Dementieva, Daryna and Khylenko, Valeriia and Babakov, Nikolay and Groh, Georg. Toxicity Classification in U krainian. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.19
-
[72]
A Strategy Labelled Dataset of Counterspeech
Poudhar, Aashima and Konstas, Ioannis and Abercrombie, Gavin. A Strategy Labelled Dataset of Counterspeech. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.20
-
[73]
Improving Covert Toxicity Detection by Retrieving and Generating References
Lee, Dong-Ho and Cho, Hyundong and Jin, Woojeong and Moon, Jihyung and Park, Sungjoon and R. Improving Covert Toxicity Detection by Retrieving and Generating References. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.21
-
[74]
Subjective Isms? On the Danger of Conflating Hate and Offence in Abusive Language Detection
Cercas Curry, Amanda and Abercrombie, Gavin and Talat, Zeerak. Subjective Isms? On the Danger of Conflating Hate and Offence in Abusive Language Detection. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.22
-
[75]
From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets
Tonneau, Manuel and Liu, Diyi and Fraiberger, Samuel and Schroeder, Ralph and Hale, Scott and R. From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.23
-
[76]
SGH ate C heck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of S ingapore
Ng, Ri Chi and Prakash, Nirmalendu and Hee, Ming Shan and Choo, Kenny Tsu Wei and Lee, Roy Ka-wei. SGH ate C heck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of S ingapore. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.24
-
[77]
Proceedings of the Ninth Workshop on Noisy and User-generated Text (W-NUT 2024). 2024
2024
-
[78]
Correcting Challenging F innish Learner Texts With Claude, GPT -3.5 and GPT -4 Large Language Models
Creutz, Mathias. Correcting Challenging F innish Learner Texts With Claude, GPT -3.5 and GPT -4 Large Language Models. Proceedings of the Ninth Workshop on Noisy and User-generated Text (W-NUT 2024). 2024
2024
-
[79]
Context-aware Adversarial Attack on Named Entity Recognition
Chen, Shuguang and Neves, Leonardo and Solorio, Thamar. Context-aware Adversarial Attack on Named Entity Recognition. Proceedings of the Ninth Workshop on Noisy and User-generated Text (W-NUT 2024). 2024
2024
-
[80]
Effects of different types of noise in user-generated reviews on human and machine translations including C hat GPT
Popovic, Maja and Lapshinova-Koltunski, Ekaterina and Koponen, Maarit. Effects of different types of noise in user-generated reviews on human and machine translations including C hat GPT. Proceedings of the Ninth Workshop on Noisy and User-generated Text (W-NUT 2024). 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.