Uncertainty-Aware (Un)Supervised Few-Shot User Adaptation for On-Device Personalized Human Activity Recognition
Pith reviewed 2026-06-28 07:10 UTC · model grok-4.3
The pith
Pretrained human activity recognition models adapt to new users with three seconds of calibration data per activity using closed-form prototype updates that work with or without labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
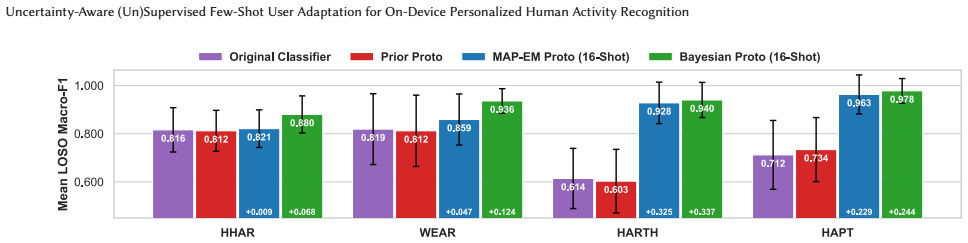
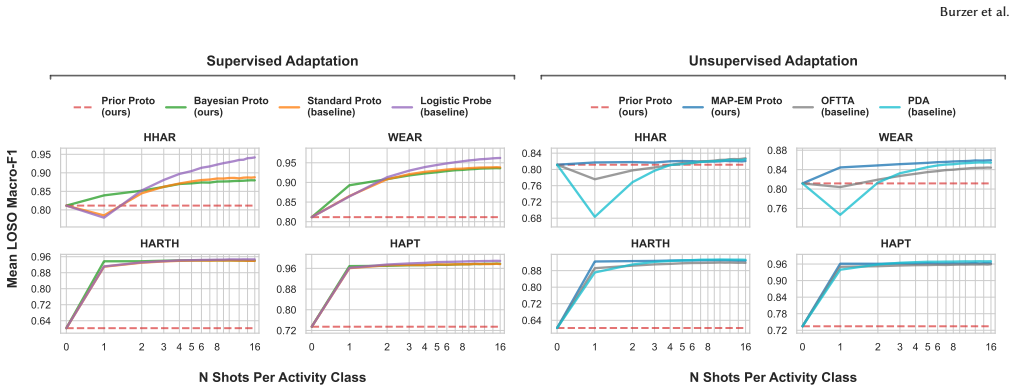
By repurposing pretrained HAR classifiers as Prototypical Networks using prior prototypes that preserve zero-shot performance, the framework enables closed-form Bayesian prototype estimation for supervised few-shot adaptation and its extension to unsupervised cases, delivering macro-F1 gains from +2.76 to +33.44 points supervised and +0.56 to +32.13 points unsupervised with only 3 seconds of data per activity across four datasets.
What carries the argument
Prior prototypes inside repurposed Prototypical Networks, which support closed-form updates for adaptation while keeping baseline performance intact.
If this is right
- Supervised adaptation with one shot per activity improves macro-F1 by up to 33.44 points on multiple datasets.
- Unsupervised adaptation achieves comparable gains without requiring labels during calibration.
- Adaptation uses only closed-form prototype updates, allowing direct on-device execution without gradient steps.
- The same prior-prototype mechanism supports both labeled and unlabeled calibration while preserving zero-shot capability.
Where Pith is reading between the lines
- Similar prototype regularization could apply to other sensor classification tasks that exhibit large user-to-user variability.
- Local closed-form updates reduce the need to transmit raw user data, supporting privacy-preserving deployment.
- The method implies that brief unlabeled calibration windows may suffice for many practical personalization scenarios.
Load-bearing premise
The framework assumes that prior prototypes from the pretrained model preserve zero-shot performance and provide effective regularization during adaptation even with very limited calibration data.
What would settle it
Applying the prototype update to a new user dataset with three seconds of data per activity and finding no increase or an outright drop in macro-F1 relative to the unmodified pretrained model.
Figures

read the original abstract
Sensor-based Human Activity Recognition (HAR) models often degrade on unseen users due to domain shifts caused by individual movement patterns and sensor placement. Practical wearable HAR systems therefore require personalization methods that are lightweight, applicable whether calibration data is labeled, unlabeled, or unavailable, and robust under limited calibration. We present a gradient-free framework that repurposes pretrained HAR classifiers as Prototypical Networks using using prior prototypes, which preserve zero-shot performance and regularize adaptation. For labeled calibration, we introduce closed-form Bayesian prototype estimation and extend the same principle to unlabeled calibration. With only 3 seconds of calibration data per activity (one shot), supervised adaptation improves macro-F1 by +2.76 to +33.44 percentage points across four datasets, while unsupervised adaptation improves by +0.56 to +32.13 points. Since adaptation requires only closed-form prototype updates, the framework enables efficient and robust on-device personalization of preexisting HAR classifiers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a gradient-free framework for few-shot user adaptation in sensor-based Human Activity Recognition (HAR). It repurposes pretrained classifiers as Prototypical Networks via prior prototypes that preserve zero-shot performance and regularize adaptation. Closed-form Bayesian prototype estimation is proposed for both supervised (labeled) and unsupervised (unlabeled) calibration, enabling on-device personalization. With 3 seconds of data per activity, it reports macro-F1 gains of +2.76 to +33.44 points (supervised) and +0.56 to +32.13 points (unsupervised) across four datasets.
Significance. If the empirical claims hold under rigorous protocols, the work would offer a practical, efficient alternative to gradient-based fine-tuning for wearable HAR personalization. The closed-form updates and explicit handling of labeled/unlabeled/no-calibration cases address real deployment constraints; the emphasis on preserving zero-shot performance while enabling adaptation is a notable design choice.
major comments (3)
- [§3, §4] §3 (method) and §4 (experiments): The central claim that prior prototypes both preserve zero-shot macro-F1 and provide useful regularization for the Bayesian update is load-bearing for the reported gains, yet the manuscript provides no explicit ablation or table showing zero-shot performance before/after repurposing the classifier as a Prototypical Network.
- [§4.2] §4.2 (unsupervised results): The unsupervised extension relies on soft assignment of calibration segments to existing prototypes without label leakage or mode collapse. No quantitative analysis (e.g., assignment entropy, prototype drift metrics, or failure cases on high domain-shift users) is presented to support that the closed-form update remains stable when the new user's feature distribution deviates from the prior.
- [§4] §4 (experimental protocol): The headline improvements (+2.76 to +33.44 supervised, +0.56 to +32.13 unsupervised) are reported without stating the number of users per dataset, the exact train/calibration/test splits, whether statistical significance tests were performed, or comparison against strong gradient-based few-shot baselines (e.g., MAML or prototypical networks trained from scratch). These omissions make it impossible to verify that the gains are attributable to the proposed method rather than experimental setup.
minor comments (2)
- [Abstract] Abstract: repeated word "using using prior prototypes".
- [§3.1] Notation: the transition from classifier logits to prototype distances is not explicitly defined with an equation; readers must infer the mapping.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the manuscript without misrepresenting the current results.
read point-by-point responses
-
Referee: [§3, §4] §3 (method) and §4 (experiments): The central claim that prior prototypes both preserve zero-shot macro-F1 and provide useful regularization for the Bayesian update is load-bearing for the reported gains, yet the manuscript provides no explicit ablation or table showing zero-shot performance before/after repurposing the classifier as a Prototypical Network.
Authors: We agree that an explicit ablation is required to substantiate the load-bearing claim. In the revised manuscript we will add a table in §4 that reports zero-shot macro-F1 for the original classifier versus the same classifier after it has been repurposed with prior prototypes, for every dataset. This will directly quantify preservation of zero-shot performance and the regularization benefit. revision: yes
-
Referee: [§4.2] §4.2 (unsupervised results): The unsupervised extension relies on soft assignment of calibration segments to existing prototypes without label leakage or mode collapse. No quantitative analysis (e.g., assignment entropy, prototype drift metrics, or failure cases on high domain-shift users) is presented to support that the closed-form update remains stable when the new user's feature distribution deviates from the prior.
Authors: We acknowledge the absence of these supporting analyses. The revised §4.2 will include (i) mean assignment entropy across calibration segments, (ii) prototype drift measured by cosine distance between prior and updated prototypes, and (iii) explicit identification of any high domain-shift users where the update under-performs. These additions will provide quantitative evidence of stability. revision: yes
-
Referee: [§4] §4 (experimental protocol): The headline improvements (+2.76 to +33.44 supervised, +0.56 to +32.13 unsupervised) are reported without stating the number of users per dataset, the exact train/calibration/test splits, whether statistical significance tests were performed, or comparison against strong gradient-based few-shot baselines (e.g., MAML or prototypical networks trained from scratch). These omissions make it impossible to verify that the gains are attributable to the proposed method rather than experimental setup.
Authors: We apologize for the incomplete protocol description. The revision will explicitly report the number of users per dataset, the precise train/calibration/test splits, and the results of statistical significance tests. Regarding gradient-based baselines, we will add a discussion of the fundamental differences (our method is gradient-free and on-device) and will include limited comparisons where they can be performed without new large-scale experiments; full MAML-style retraining comparisons may be noted as future work due to scope. revision: partial
Circularity Check
No significant circularity; closed-form updates are independent of target results
full rationale
The paper's central mechanism is a gradient-free repurposing of pretrained classifiers as Prototypical Networks via prior prototypes, followed by explicit closed-form Bayesian prototype estimation for both supervised and unsupervised cases. This construction does not reduce any reported performance gain to a fitted parameter or self-referential definition; the preservation of zero-shot performance is a stated design property of the priors rather than an output derived from the adaptation equations themselves. No self-citation chains, ansatz smuggling, or renaming of known results appear as load-bearing steps in the derivation. The framework is therefore self-contained against external benchmarks such as the four datasets and the one-shot calibration protocol.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained HAR classifiers can be repurposed as Prototypical Networks using prior prototypes
Reference graph
Works this paper leans on
-
[1]
Rebecca Adaimi and Edison Thomaz. 2022. Lifelong Adaptive Machine Learning for Sensor-Based Human Activity Recognition Using Prototypical Networks. Sensors22, 18 (Sept. 2022), 6881. doi:10.3390/s22186881
-
[2]
Sizhen Bian, Mengxi Liu, Vitor Fortes Rey, Daniel Geißler, and Paul Lukowicz
-
[3]
TinierHAR: Towards Ultra-Lightweight Deep Learning Models for Efficient Human Activity Recognition on Edge Devices. InProceedings of the 2025 ACM International Symposium on Wearable Computers(New York, NY, USA, 2025-10- 07)(ISWC ’25). Association for Computing Machinery, 163–169. doi:10.1145/ 3715071.3750410
arXiv 2025
-
[4]
2006.Pattern recognition and machine learning
Christopher M Bishop and Nasser M Nasrabadi. 2006.Pattern recognition and machine learning. Vol. 4. Springer
2006
-
[5]
Marius Bock, Hilde Kuehne, Kristof Van Laerhoven, and Michael Moeller. 2024. WEAR: An Outdoor Sports Dataset for Wearable and Egocentric Activity Recog- nition.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.8, 4 (Nov. 2024), 175:1–175:21. doi:10.1145/3699776
-
[6]
Ondrej Bohdal, Da Li, and Timothy Hospedales. 2023. Feed-Forward Source-Free Domain Adaptation via Class Prototypes. arXiv:2307.10787 [cs.CV] doi:10.48550/ arXiv.2307.10787
arXiv 2023
-
[7]
Maximilian Burzer, Tobias King, Till Riedel, Michael Beigl, and Tobias Röddiger
-
[8]
InCompanion of the 2025 ACM International Joint Conference on Pervasive and Ubiquitous Computing
WHAR Datasets: An Open Source Library for Wearable Human Activity Recognition. InCompanion of the 2025 ACM International Joint Conference on Pervasive and Ubiquitous Computing. 1315–1322
2025
-
[9]
Dongzhou Cheng, Lei Zhang, Can Bu, Xing Wang, Hao Wu, and Aiguo Song
-
[10]
ProtoHAR: Prototype Guided Personalized Federated Learning for Human Activity Recognition.IEEE Journal of Biomedical and Health Informatics27, 8 (Aug. 2023), 3900–3911. doi:10.1109/JBHI.2023.3275438
-
[11]
Sourish Gunesh Dhekane and Thomas Ploetz. 2025. Transfer learning in sensor- based human activity recognition: A survey.Comput. Surveys57, 8 (2025), 1–39
2025
-
[12]
Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta- learning for fast adaptation of deep networks. InInternational conference on machine learning. PMLR, 1126–1135
2017
-
[13]
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario March, and Victor Lempitsky. 2016. Domain-adversarial training of neural networks.Journal of machine learning research17, 59 (2016), 1–35
2016
-
[14]
Md Amran Hossen and Pg Emeroylariffion Abas. 2025. Machine learning for human activity recognition: State-of-the-art techniques and emerging trends. Journal of Imaging11, 3 (2025), 91
2025
-
[15]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
-
[16]
Siyu Hu, Jiqiang Liu, Chenxin Zhang, Xiaoqiang Zhu, and Lingkun Li. 2024. Proto-CSNet: A Prototype Network Model Integrating CNN and Self-Attention for Enhanced Human Activity Recognition. In2024 20th International Conference on Mobility, Sensing and Networking (MSN). 48–56. doi:10.1109/MSN63567.2024. 00018
-
[17]
Lei Jiang, Yongzhao Zhan, Zhen Jiang, and Na Tang. 2024. A Dual-Prototype Network Combining Query-Specific and Class-Specific Attentive Learning for Few-Shot Action Recognition.Neurocomputing598 (Sept. 2024), 127819. doi:10. 1016/j.neucom.2024.127819
arXiv 2024
-
[18]
Steinar Laenen and Luca Bertinetto. 2021. On episodes, prototypical networks, and few-shot learning.Advances in Neural Information Processing Systems34 (2021), 24581–24592
2021
-
[19]
YiSong Li, LiWei Zou, MingXing Nie, Tao Zhu, YuanLong Wu, Yang Xiao, and KaiWen Luo. 2026. Bridging Domain and Instance Gaps: A Prototype Contrastive Framework for Robust Human Activity Recognition.Neurocomputing673 (April 2026), 132868. doi:10.1016/j.neucom.2026.132868
-
[20]
Jian Liang, Dapeng Hu, and Jiashi Feng. 2020. Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation. In International conference on machine learning. PMLR, 6028–6039
2020
-
[21]
Gyuyeon Lim and Myung-Kyu Yi. 2026. Prototype-Guided Physics-Modulated Perceiver for Human Activity Recognition.IEEE Internet of Things Journal13, 8 (April 2026), 16117–16130. doi:10.1109/JIOT.2026.3658863
-
[22]
Ji Lin, Ligeng Zhu, Wei-Ming Chen, Wei-Chen Wang, and Song Han. 2023. Tiny machine learning: Progress and futures [feature].IEEE Circuits and Systems Magazine23, 3 (2023), 8–34
2023
-
[23]
Aleksej Logacjov, Kerstin Bach, Atle Kongsvold, Hilde Bremseth Bårdstu, and Paul Jarle Mork. 2021. HARTH: A Human Activity Recognition Dataset for Machine Learning.Sensors21, 23 (Nov. 2021), 7853. doi:10.3390/s21237853
-
[24]
Alexander Murphy, Michal Danilowski, Soumyajit Chatterjee, and Abhirup Ghosh. 2026. NEO: No-Optimization Test-Time Adaptation through Latent Re-Centering. arXiv:2510.05635 [cs.LG] doi:10.48550/arXiv.2510.05635
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.05635 2026
-
[25]
Kevin P Murphy. 2007. Conjugate Bayesian analysis of the Gaussian distribution. def1, 2𝜎2 (2007), 16
2007
-
[26]
PyTorch Team. 2026. ExecuTorch: On-Device AI Across Mobile, Embedded, and Edge for PyTorch. https://github.com/pytorch/executorch. GitHub repository, Accessed: 2026-05-20
2026
-
[27]
Harun Ur Rashid and Seong Ho Jeong. 2026. Federated Few-Shot Prototypical Learning for Personalized WiFi-Based Human Activity Recognition.IEEE Access 14 (2026), 53654–53666. doi:10.1109/ACCESS.2026.3678918
-
[28]
Reyes-Ortiz, Luca Oneto, Albert Samà, Xavier Parra, and Davide An- guita
Jorge-L. Reyes-Ortiz, Luca Oneto, Albert Samà, Xavier Parra, and Davide An- guita. 2016. Transition-Aware Human Activity Recognition Using Smartphones. Neurocomputing171 (Jan. 2016), 754–767. doi:10.1016/j.neucom.2015.07.085
-
[29]
Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning.Advances in neural information processing systems30 (2017)
2017
-
[30]
Mengyuan Song, Siwei Feng, and Tao Deng. 2026. Prototype-Guided Pseudo- Labeling for Semi-Supervised Federated Human Activity Recognition.Pattern Recognition179 (Nov. 2026), 113760. doi:10.1016/j.patcog.2026.113760
-
[31]
Allan Stisen, Henrik Blunck, Sourav Bhattacharya, Thor Siiger Prentow, Mikkel Baun Kjærgaard, Anind Dey, Tobias Sonne, and Mads Møller Jensen
-
[32]
InProceedings of the 13th ACM Confer- ence on Embedded Networked Sensor Systems
Smart Devices are Different: Assessing and MitigatingMobile Sensing Heterogeneities for Activity Recognition. InProceedings of the 13th ACM Confer- ence on Embedded Networked Sensor Systems. ACM, Seoul South Korea, 127–140. doi:10.1145/2809695.2809718
-
[33]
Baochen Sun and Kate Saenko. 2016. Deep coral: Correlation alignment for deep domain adaptation. InEuropean conference on computer vision. Springer, 443–450
2016
-
[34]
TensorFlow Team. 2026. TensorFlow Lite. https://www.tensorflow.org/lite. Accessed: 2026-05-20
2026
-
[35]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE.Journal of machine learning research9, 11 (2008)
2008
-
[36]
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. 2020. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726(2020)
Pith/arXiv arXiv 2020
-
[37]
Shuoyuan Wang, Jindong Wang, HuaJun Xi, Bob Zhang, Lei Zhang, and Hongxin Wei. 2024. Optimization-Free Test-Time Adaptation for Cross-Person Activity Recognition. arXiv:2310.18562 [cs.CV] doi:10.48550/arXiv.2310.18562
-
[38]
Minglei Yuan, Wenhai Wang, Tao Wang, Chunhao Cai, Qian Xu, and Tong Lu
-
[39]
Learning class-level prototypes for few-shot learning.arXiv preprint arXiv:2108.11072(2021)
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.