Beyond Objective Equivalence: Constraint Injection for LLM-Based Optimization Modeling on Vehicle Routing Problems
Pith reviewed 2026-06-28 05:49 UTC · model grok-4.3
The pith
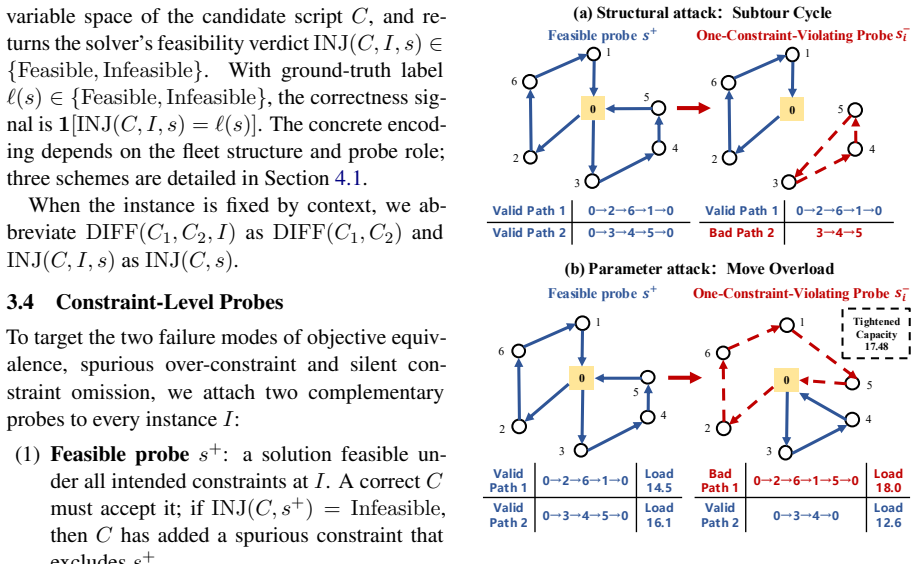
Constraint injection with probes catches errors in LLM-generated VRP solver code that objective checks miss
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Constraint injection using feasible probes to expose spurious over-constraint and one-constraint-violating probes to reveal silent constraint omission, combined with differential testing, forms a dual verifier that enables an 8B model to reach 93% average Pass@1 on four VRP benchmarks while outperforming larger models on several.
What carries the argument
Constraint injection via feasible and one-constraint-violating probes within a dual verifier alongside differential testing
If this is right
- VRPCoder-GRPO achieves 93% average Pass@1 across four VRP benchmarks
- The model outperforms Gemini-3.1-Pro Preview on three of the benchmarks
- It exceeds Claude-Sonnet-4.5 performance by 28 points on average
- It surpasses prior OR-specific LLMs by 78 points on average
Where Pith is reading between the lines
- The approach may apply to other constraint-dense optimization domains if suitable probe designs can be created for their constraints.
- Focusing verification on explicit constraint behavior rather than solution equivalence could improve reliability in code generation for operations research.
- Extending the benchmark to include more interacting constraints would test the generalizability of the probe method.
Load-bearing premise
The expert-verified set of 21 VRP variants covers the space of relevant coupled operational constraints sufficiently for the method to generalize.
What would settle it
A counterexample would be an LLM-generated VRP solver script that passes all probes and differential tests yet produces incorrect solutions on a new operational constraint combination not covered in the 21 variants.
Figures







read the original abstract
Large language models (LLMs) increasingly translate natural-language optimization problems into executable solver code. Yet for constraint-dense operations research (OR) problems, existing data-filtering and training pipelines largely rely on objective-equivalence signals such as differential testing and answer agreement, which a program can pass while adding spurious constraints or silently omitting required ones, whenever those constraints are non-binding on the tested instance. We propose constraint injection, which uses feasible probes to expose spurious over-constraint and one-constraint-violating probes to reveal silent constraint omission. Combined with differential testing, it forms a dual verifier. We instantiate and evaluate it on vehicle routing problems (VRPs), a representative constraint-dense combinatorial optimization testbed with coupled operational constraints. We develop VRPCoder, an 8B end-to-end model that translates natural-language VRP scenarios into Gurobi scripts, together with an expert-verified VRP benchmark suite covering 21 variants. The verifier is reused as a rejection-sampling filter during data synthesis and as a per-rollout reward in group relative policy optimization (GRPO). Across four VRP benchmarks, VRPCoder-GRPO reaches 93\% average Pass@1, outperforms Gemini-3.1-Pro Preview on three benchmarks, exceeds Claude-Sonnet-4.5 by 28 average points, and surpasses prior OR-LLMs by 78 average points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that constraint injection—using feasible probes to expose spurious over-constraint and one-constraint-violating probes to reveal silent omission—combined with differential testing forms a dual verifier that enables reliable LLM-based generation of VRP solver code. They introduce VRPCoder (8B model) trained via GRPO where the verifier serves as both rejection-sampling filter and per-rollout reward, reporting 93% average Pass@1 across four VRP benchmarks, outperforming Gemini-3.1-Pro Preview on three, Claude-Sonnet-4.5 by 28 points, and prior OR-LLMs by 78 points, on an expert-verified suite of 21 VRP variants.
Significance. If the dual verifier generalizes, the approach addresses a genuine limitation of objective-equivalence signals in constraint-dense OR problems and could improve reliability of LLM-generated optimization models. The empirical scale of the gains (93% Pass@1, large margins over frontier models) would be notable if independently reproducible; the paper ships no machine-checked proofs or parameter-free derivations but does provide a concrete, reusable probe-based mechanism.
major comments (2)
- [Benchmark suite description (abstract and evaluation sections)] Benchmark construction and evaluation protocol: the central claim that the dual verifier reliably detects both over- and under-constraint rests on the premise that the expert-verified 21-variant suite sufficiently covers coupled operational constraints (time-window + capacity + precedence interactions). No analysis or coverage argument is supplied showing that probe-based detection generalizes beyond these instances; this assumption directly supports both the 93% Pass@1 figure and the training pipeline.
- [VRPCoder-GRPO training description] Data synthesis and training pipeline: the verifier is reused for rejection sampling during data synthesis and as the GRPO reward signal. This creates a circularity risk where Pass@1 performance may reflect the verifier’s own inductive biases rather than independent correctness; no ablation isolating the contribution of constraint-injection probes versus differential testing alone is reported.
minor comments (2)
- [Results] Abstract and results sections report strong aggregate Pass@1 numbers but supply no error bars, per-benchmark breakdowns, or statistical significance tests.
- [Constraint injection method] No details are given on how feasible and one-constraint-violating probes are automatically constructed or on their sensitivity to instance size.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: Benchmark construction and evaluation protocol: the central claim that the dual verifier reliably detects both over- and under-constraint rests on the premise that the expert-verified 21-variant suite sufficiently covers coupled operational constraints (time-window + capacity + precedence interactions). No analysis or coverage argument is supplied showing that probe-based detection generalizes beyond these instances; this assumption directly supports both the 93% Pass@1 figure and the training pipeline.
Authors: We agree that an explicit discussion of coverage would strengthen the manuscript. The 21-variant suite was constructed with OR domain experts specifically to include representative coupled interactions (time windows with capacity, precedence with time windows, etc.), as described in Section 4.2 and the benchmark appendix. However, we did not supply a formal coverage argument or generalization analysis. In revision we will add a new subsection in the evaluation section that details the expert-driven variant selection process, enumerates the covered constraint interaction classes, and explicitly acknowledges the limits of the current suite with respect to broader generalization of the probe mechanism. revision: yes
-
Referee: Data synthesis and training pipeline: the verifier is reused for rejection sampling during data synthesis and as the GRPO reward signal. This creates a circularity risk where Pass@1 performance may reflect the verifier’s own inductive biases rather than independent correctness; no ablation isolating the contribution of constraint-injection probes versus differential testing alone is reported.
Authors: We acknowledge the circularity risk as a substantive methodological concern. The constraint-injection probes are defined via instance-independent logical properties (feasible probes and single-constraint violation probes) rather than the evaluation instances themselves, and differential testing supplies an orthogonal objective-equivalence signal. Nevertheless, the reuse of the same verifier for both filtering and reward does warrant explicit isolation. We will add an ablation study in the revised training section that compares (i) differential testing alone versus (ii) the full dual verifier for both rejection sampling and GRPO reward, reporting the resulting Pass@1 differences on the held-out benchmarks. revision: yes
Circularity Check
No load-bearing circularity; dual verifier and performance metrics remain independent of fitted inputs
full rationale
The paper presents the dual verifier (constraint injection via feasible and one-constraint-violating probes plus differential testing) as an independent mechanism that is applied both for data filtering/reward in GRPO training and for evaluation. The reported 93% average Pass@1 and outperformance figures are empirical outcomes measured on the expert-verified benchmark suite; no equations, parameter fits, or self-citations are exhibited that reduce these outcomes to quantities defined by construction from the training process itself. The coverage of the 21 variants is an external validity assumption rather than a definitional reduction. This qualifies as at most minor (score 2) with no steps meeting the strict quotation-and-reduction criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard mathematical properties of linear programming feasibility and constraint satisfaction hold for the Gurobi solver outputs.
invented entities (1)
-
Constraint injection probes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
Association for Computing Machinery. Gerhard Reinelt. 1991. TSPLIB–A Traveling Sales- man Problem Library. ORSA Journal on Computing, 3(4):376–384. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Prox- imal Policy Optimization Algorithms . Preprint, arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx...
work page internal anchor Pith review Pith/arXiv arXiv 1991
-
[2]
New Benchmark Instances for the Capaci- tated V ehicle Routing Problem . European Journal of Operational Research, 257(3):845–858. Ziyang Xiao, Jingrong Xie, Lilin Xu, Shisi Guan, Jingyan Zhu, Xiongwei Han, Xiaojin Fu, WingYin Y u, Han Wu, Wei Shi, Qingcan Kang, Jiahui Duan, Tao Zhong, Mingxuan Y uan, Jia Zeng, Y uan Wang, Gang Chen, and Dongxiang Zhang. ...
-
[3]
We train for 3 epochs with sequence length
-
[4]
Frontier filtering
The optimizer is AdamW with learning rate 2 × 10−4, cosine scheduling, warmup ratio 0.1, weight decay 0.01, and maximum gradient norm 1.0. Frontier filtering. For each prompt in the SFT pool, we sample M = 6 offline rollouts from VRPCoder-SFT under the same decoding settings as online GRPO (temperature 0.4, top- p 0.95), score each rollout with the dual ver...
2020
-
[5]
Do not omit, invent, or round any number
Preserve ALL numerical data exactly (coordinates, demands, capacities, fleet size, time windows, service times, max distances, etc.). Do not omit, invent, or round any number
-
[6]
No math symbols, variable names, or code jargon
State the optimization objective and every constraint in business language. No math symbols, variable names, or code jargon
-
[7]
Truck 0 (capacity 50.0, fixed cost 70.0)
Index preservation (critical): every vehicle, customer, and depot must carry its explicit numeric ID from the code. Write "Truck 0 (capacity 50.0, fixed cost 70.0)" −− never describe entities by type alone without their ID. Never renumber or reorder. Unit consistency:
-
[8]
3.4 pallets
Demand/capacity values may be fractional (e.g. 3.4). Use continuous units only (tons, kilograms, liters). Never use bare countable nouns (pallets, boxes, items) −− "3.4 pallets" is nonsensical
-
[9]
Use a tangible goods unit instead
If the problem has time−window or scheduling constraints, do NOT also use time−based units for demand/capacity −− this creates a logical contradiction. Use a tangible goods unit instead. Style:
-
[10]
Structure: background −> resources/data −> operational constraints −> objective
-
[11]
No Markdown, no bullets/tables/dialogue/email tone
Plain prose only. No Markdown, no bullets/tables/dialogue/email tone
-
[12]
a capacity of 50.0
If a scene hint is given, adapt terminology naturally while preserving the optimization structure. Scenario Instantiation: User Prompt Generate a natural−language business problem statement from the code below. ===== Scene and Style Instructions ===== {scene_hint} ===== Gurobi Code (with complete data) ===== {code} ===== Critical Numbers That Must Appear ...
-
[13]
Numerical completeness: all critical values (depot/customer/vehicle counts, capacities, demands, coordinates, time windows, etc.) present?
-
[14]
Constraint coverage: every code constraint has a corresponding business description?
-
[15]
Objective: optimization direction correctly stated?
-
[16]
No fabrication: no numbers or conditions invented beyond the code?
-
[17]
Index−attribute binding: every entity carries its numeric ID, and ID−to−attribute mappings (ID −> capacity, cost, type) are faithful to the code? Missing or ambiguous IDs = INCOMPLETE
-
[18]
Unit plausibility: demand/capacity units are continuous (not countable nouns) and do not conflict with time−window dimensions? Output exactly one of: − COMPLETE − INCOMPLETE: <discrepancy_1> | <discrepancy_2> | ... Self-Critique: Critic User Prompt Please compare the following content and determine whether the natural−language description fully and accurat...
-
[19]
Only modify the parts identified as problematic
-
[20]
Preserve the correct and fluent parts of the original description
-
[21]
Ensure all critical numbers appear accurately after revision
-
[22]
Do not introduce new errors. Repair: User Prompt Review feedback: {criticism} Original code and data: {code} Current natural−language description: {nl_description} Please output the revised complete natural−language description (only modify the parts identified as problematic; preserve the correct parts): Figure 6: Self-Critique and Repair Prompts. Critic ...
-
[23]
Do not delete, alter, round, merge, or restate numbers in a different form
Preserve every numeric value exactly as written. Do not delete, alter, round, merge, or restate numbers in a different form
-
[24]
Do not renumber, reorder, relabel, or collapse depots, customers, vehicles, compartments, pickup−delivery pairs, or any other named entities
Preserve every explicit entity ID exactly as written. Do not renumber, reorder, relabel, or collapse depots, customers, vehicles, compartments, pickup−delivery pairs, or any other named entities
-
[25]
Preserve every fact that changes the optimization problem: objective terms, route start/end behavior, depot assignment, fleet size, capacities, coordinates, demands, service times, time windows, maximum distance or duration, fixed or travel costs, heterogeneous vehicle attributes, compartment rules, pickup−delivery logic, backhaul ordering, split−delivery p...
-
[26]
This is condensation, not stylistic rewriting
Keep the original business scene and terminology. This is condensation, not stylistic rewriting
-
[27]
<See variant−specific block below>
-
[28]
each node has exactly one incoming arc and exactly one outgoing arc
Micro−examples of allowed compression: (1)"each node has exactly one incoming arc and exactly one outgoing arc" can usually be shortened to "each customer/location must be visited exactly once" if route start/end behavior is already clear elsewhere. (2)"no self−loops, no arcs into depot 0, no arcs out of sink 13" can be deleted if these are only solver−hy...
-
[29]
Remove tutorial tone, repeated reminders, and repeated restatements of the same requirement
Merge duplicated statements into one concise statement. Remove tutorial tone, repeated reminders, and repeated restatements of the same requirement
-
[30]
Do not output bullets, markdown, JSON, XML, commentary, or surrounding quotation marks
Prefer plain prose. Do not output bullets, markdown, JSON, XML, commentary, or surrounding quotation marks
-
[31]
Output only the condensed problem statement
If the source is already concise, make only small cuts. Output only the condensed problem statement. Condensation: Rule 5 for Pilot 1
-
[32]
no arcs into the start depot
Y ou MA Y delete solver−side or formulation−side wording when it is not real business content. Typical deletable items include self−loop prohibitions, forbidden−arc wording such as "no arcs into the start depot" or "no arcs out of the sink", exact in−degree / out−degree phrasing, explicit subtour−elimination wording, and explanations of why a virtual depo...
-
[33]
virtual depot
Y ou MUST delete ALL virtual−node wording. Specifically remove: (1) Any mention of "virtual depot", "virtual sink", "virtual return node", "dummy node" and their node IDs when used only as route endpoints. (2) Sentences like "Upon completing their routes, all trucks must proceed to Virtual Distribution center N". (3) Replace with natural route termination:...
-
[34]
First identify every node/location identifier that appears in the source text: depots, customers, pickup nodes, delivery nodes, virtual depots, sink nodes, endpoint nodes, start nodes, and end nodes
-
[35]
Replace all of those node/location identifiers consistently using the requested target style
-
[36]
Do not rely on any external mapping table
Create the node−ID mapping yourself from the source text. Do not rely on any external mapping table
-
[37]
Do not change vehicle IDs or any non−ID number
-
[38]
Preserve all constraints and business meaning
-
[39]
Do not add nodes or virtual−node details that are absent from the source
-
[40]
Report the exact mapping you used in the JSON field node_id_map
-
[41]
rewritten_nl
Do not output markdown, explanations, or commentary. Output JSON only: { "rewritten_nl": "...", "node_id_map": [ {"source_id": "0", "target_id": "A", "role": "start_depot"}, {"source_id": "7", "target_id": "B", "role": "virtual_end_depot"} ] } Index Rewriting: User Prompt V ariant: {variant} Target style: {target_style} Source description: {original_nl} R...
-
[42]
import gurobipy as gp and from gurobipy import GRB
-
[43]
It must call m.optimize() and return the model object
Define def build_model(): containing all model logic. It must call m.optimize() and return the model object
-
[44]
Set m.setParam(’OutputFlag’, 0) before optimize
-
[45]
Model ALL constraints described in the problem −− omit none, fabricate none
-
[46]
Use exact numerical values from the problem description. Index convention: − Use internal integer node indices 0..N−1 for routing variables, where N is the total number of routing nodes: depots, customers, pickup/delivery nodes, and explicit virtual/end nodes if present. − If the problem already uses natural zero−based node IDs, use them directly as model...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.