Probing Outcome-Level Resemblance and Mechanism-Level Alignment in LLM Risk Decisions: Evidence from the St. Petersburg Game
Pith reviewed 2026-06-28 06:03 UTC · model grok-4.3
The pith
LLMs produce human-like finite bids in the St. Petersburg game but switch to rational calculations under prompt variants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
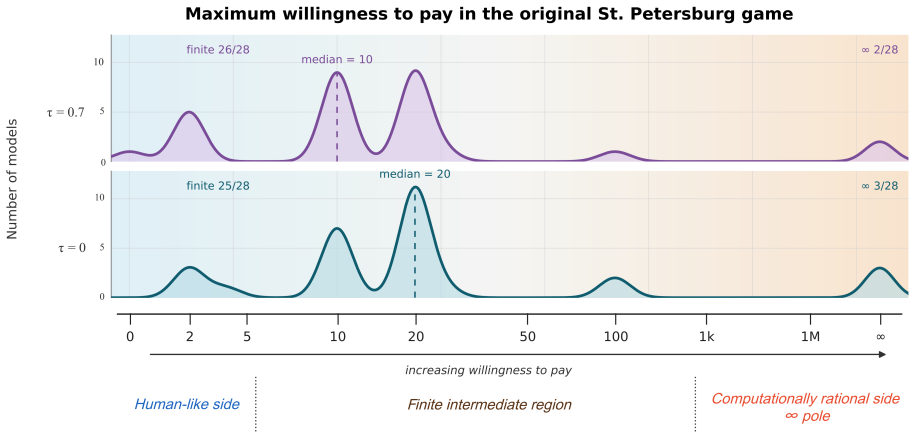
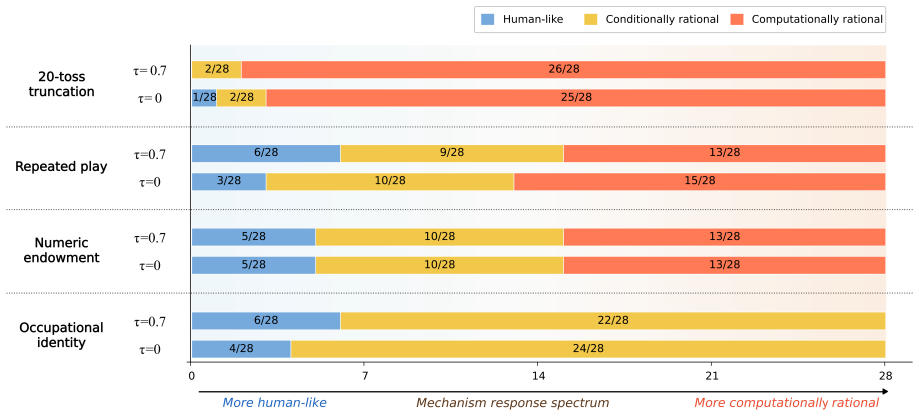
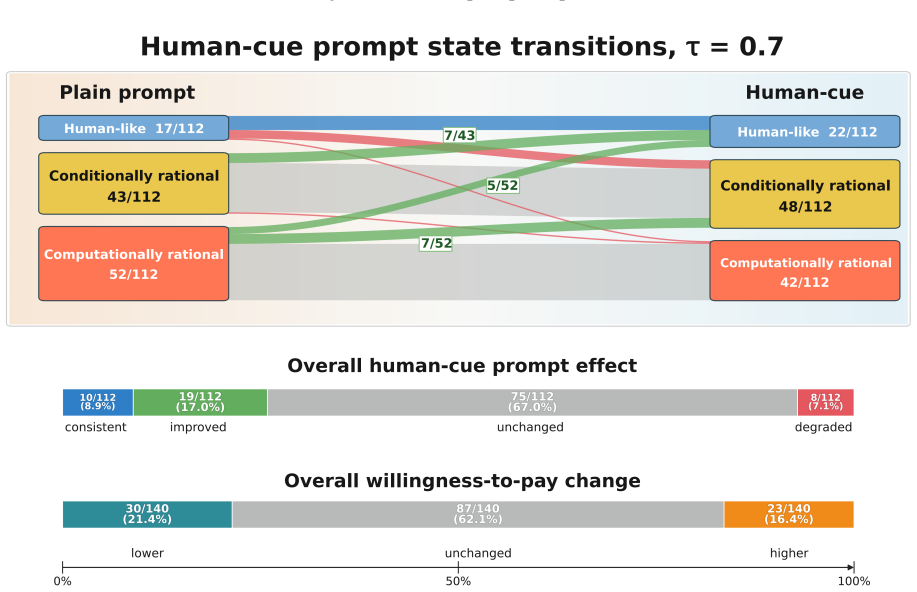
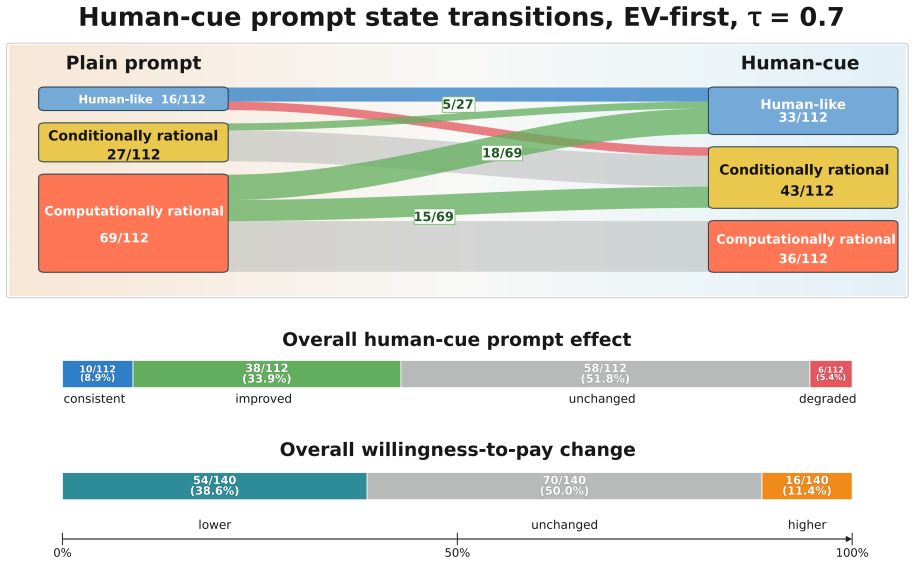
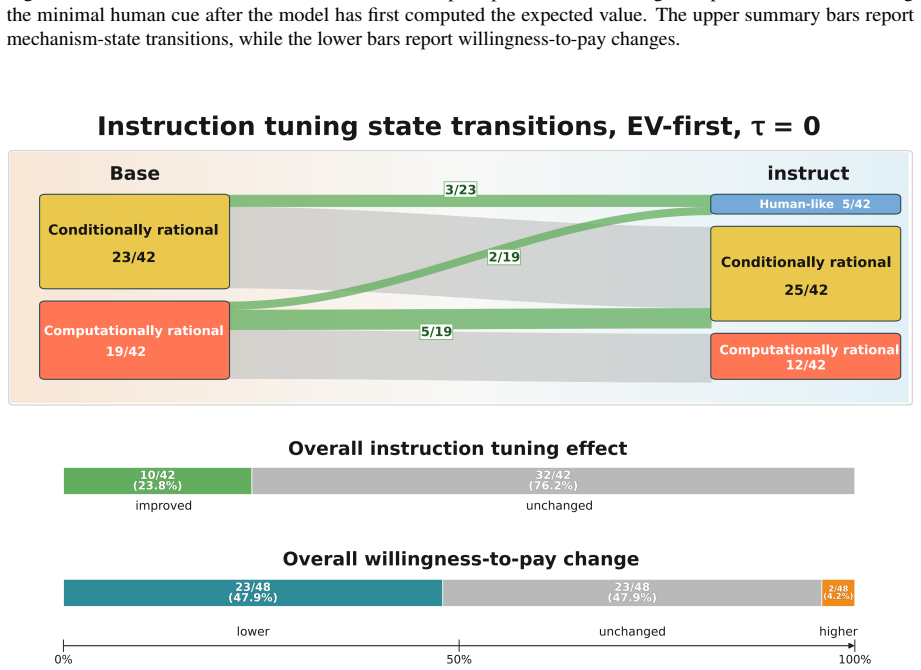
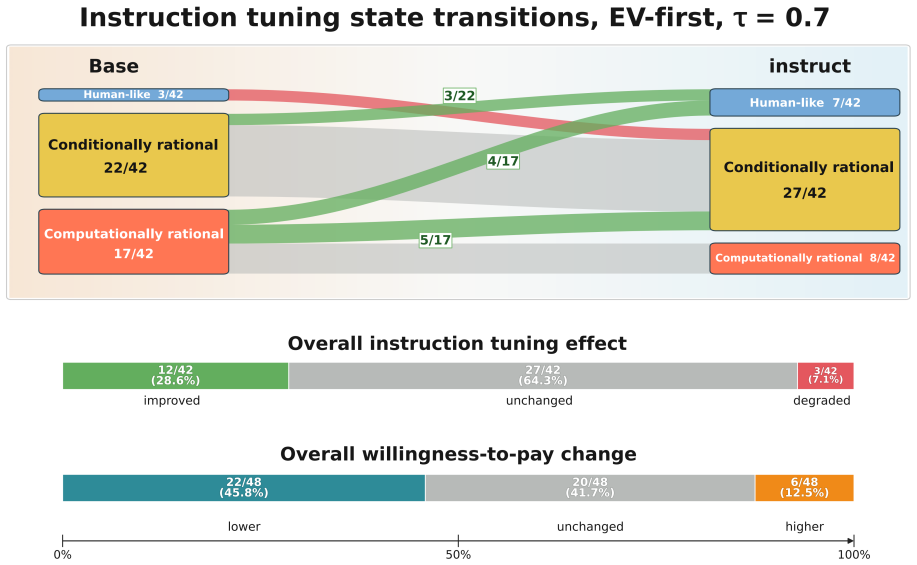
In the original St. Petersburg game most of the 28 LLMs generate finite bids that resemble human reports, yet the controlled variants reveal that models shift toward conditionally and computationally rational behavior rather than preserving human-like response patterns. Human-cue prompting and instruction tuning lower bids and reduce some visible pathologies, but most mechanism-level response patterns remain largely unchanged. These findings show that behavioral alignment in risk decision-making can be surface-level: LLMs may produce human-like risk decisions without exhibiting human-consistent mechanisms.
What carries the argument
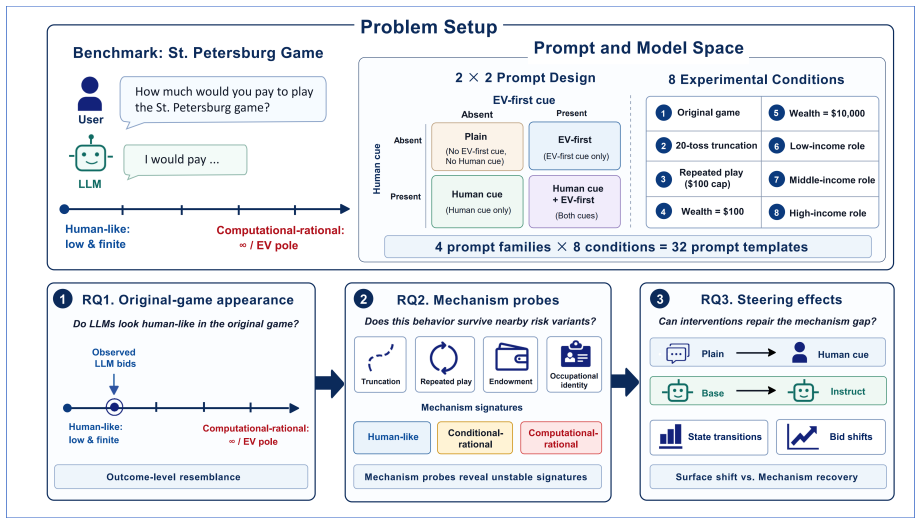
Structured prompt suite with controlled variants that perturb truncation, repeated play, numeric endowment, and occupational identity, together with a human-perspective prompt, used to separate outcome-level resemblance from mechanism-level alignment.
If this is right
- Outcome similarity in risk tasks does not imply mechanism consistency across decision variants.
- Instruction tuning and human-perspective prompts change some output values without aligning core response patterns to game changes.
- Evaluations of LLM decision-making must include mechanism probes in addition to final choice similarity.
- The St. Petersburg game with systematic perturbations serves as a testbed for detecting surface-only behavioral alignment.
- High-stakes applications should examine whether alignment rests on consistent internal rules.
Where Pith is reading between the lines
- Alignment methods that match outputs alone may leave gaps in other uncertainty-heavy tasks such as planning or ethics.
- Training objectives could add consistency checks across prompt variants to target mechanism alignment directly.
- The variant-probe approach could extend to multi-step or interactive decision settings to test deeper consistency.
- Release evaluations might incorporate mechanism metrics alongside standard benchmark scores.
Load-bearing premise
The structured prompt variants isolate genuine differences in the models' underlying decision mechanisms rather than simply changing how the models phrase their answers.
What would settle it
If models produced the same finite bid patterns and did not shift toward rational calculations when truncation is removed or the game is repeated many times, the claim of mechanism-level misalignment would not hold.
Figures






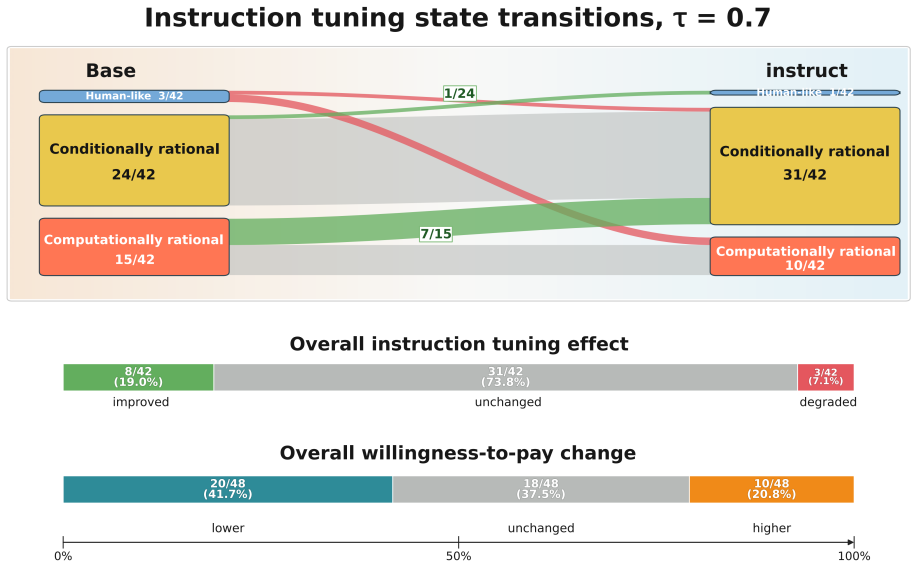
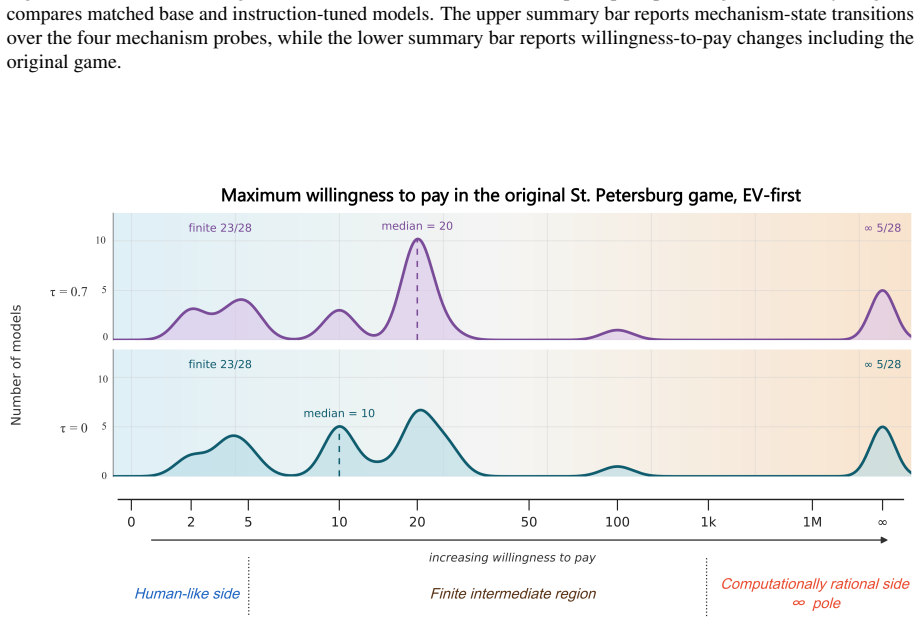
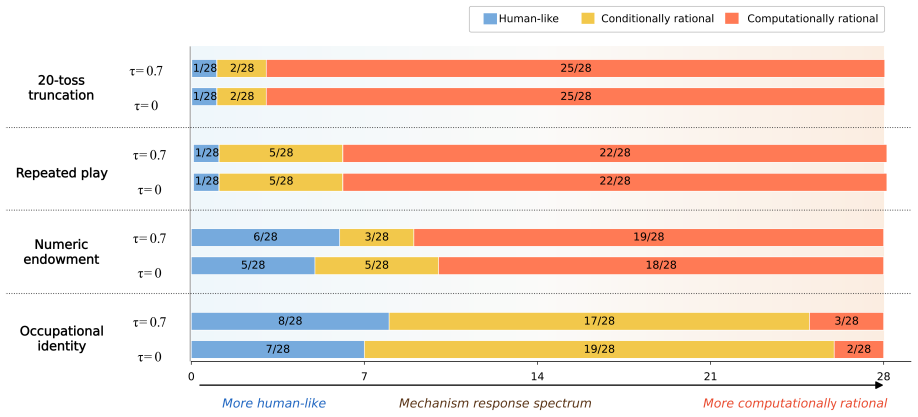
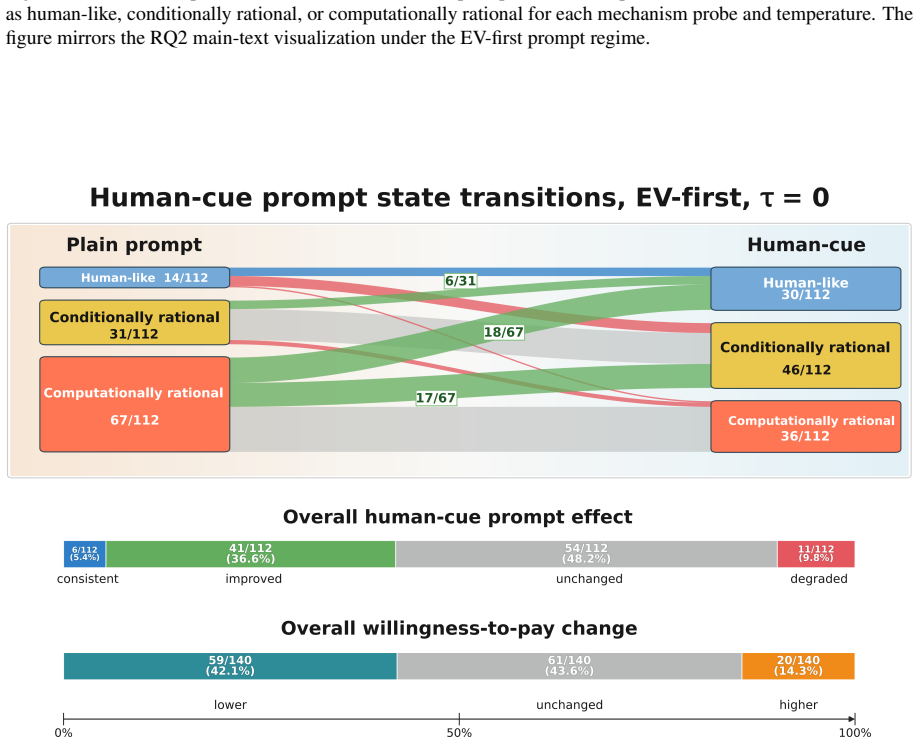
read the original abstract
LLMs can appear cautious in risk decision-making tasks, yet cautious-looking outputs do not necessarily indicate alignment with human decision-making mechanisms. We investigate this distinction using the St. Petersburg game as a controlled testbed, a classical paradox in which the expected payoff is infinite, yet humans typically report low, finite willingness to pay. We evaluate 28 LLMs with a structured prompt suite that includes the original game; controlled decision variants that perturb truncation, repeated play, numeric endowment, and occupational identity; a human-perspective prompt that asks models to reason as human decision makers; and paired comparisons between base models and their instruction-tuned counterparts. In the original game, most models generate finite bids, creating the appearance of human-like risk behavior. However, this outcome-level resemblance masks substantial mechanism-level differences. The controlled variants reveal that rather than maintaining human-like behavior seen in the original game, models often shift to conditionally and computationally rational behavior. Human-cue prompting and instruction tuning often lower bids and reduce some visible pathologies, but most mechanism-level response patterns remain largely unchanged. These findings show that behavioral alignment in risk decision-making can be surface-level: LLMs may produce human-like risk decisions without exhibiting human-consistent mechanisms. High-stakes evaluations of LLM decision-making should therefore move beyond outcome similarity and examine whether the alignment is supported by mechanism-level consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates 28 LLMs on the St. Petersburg paradox using a structured prompt suite that includes the base game, variants perturbing truncation/repeated play/numeric endowment/occupational identity, a human-perspective instruction, and base vs. instruction-tuned model pairs. It reports that most models produce finite bids resembling humans in the original game, but shift toward conditionally rational responses under variants; human-cue prompting and instruction tuning lower bids without substantially altering most mechanism-level patterns. The central claim is that this demonstrates surface-level behavioral alignment without human-consistent mechanisms.
Significance. If the central claim holds after addressing verification gaps, the work would be significant for LLM alignment research by providing a controlled testbed (the St. Petersburg game) to separate outcome resemblance from mechanism consistency. The use of multiple controlled variants and paired base/instruction-tuned comparisons is a methodological strength that enables falsifiable distinctions. This could usefully inform high-stakes decision evaluations by shifting focus beyond surface outputs.
major comments (3)
- [Methods, prompt suite] Methods section (prompt suite description): The claim that variants and the human-perspective prompt successfully isolate mechanism-level differences (rather than inducing surface output shifts via in-context imitation) is load-bearing for the surface-vs-mechanism conclusion, yet the manuscript provides no independent verification such as logit inspection, attention analysis, or consistency metrics across prompt phrasings.
- [Results] Results section: The assertion that 'most mechanism-level response patterns remain largely unchanged' under human-cue prompting and instruction tuning lacks quantitative support (e.g., percentage of models exhibiting change, statistical tests, or effect sizes), making it difficult to evaluate whether the patterns are truly stable or merely described qualitatively.
- [Results and discussion] Results and discussion: No human participant data are collected on the variant prompts (truncation, repeated play, endowment, identity), so the reference point for 'human-consistent mechanisms' is limited to the original game; this weakens the interpretation that model shifts indicate divergence from human mechanisms under the same conditions.
minor comments (2)
- [Methods] The abstract states that 28 models were evaluated but the methods should explicitly list the models (open vs. closed source) and any exclusion criteria to support reproducibility.
- [Results] Figure or table presenting per-model bids or pattern classifications would benefit from error bars or confidence intervals given the stochastic nature of LLM outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential significance of the work for LLM alignment research. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Methods, prompt suite] Methods section (prompt suite description): The claim that variants and the human-perspective prompt successfully isolate mechanism-level differences (rather than inducing surface output shifts via in-context imitation) is load-bearing for the surface-vs-mechanism conclusion, yet the manuscript provides no independent verification such as logit inspection, attention analysis, or consistency metrics across prompt phrasings.
Authors: We agree that internal analyses such as logit inspection or attention maps would provide stronger direct evidence for mechanism isolation. Our design instead relies on observable behavioral shifts under controlled prompt perturbations to distinguish surface resemblance from deeper alignment. We will revise the methods and discussion to explicitly acknowledge the absence of internal verification as a limitation and to elaborate on how the multi-variant design reduces the likelihood of simple in-context imitation. This constitutes a partial revision, as we cannot add new internal-model experiments without substantial additional work. revision: partial
-
Referee: [Results] Results section: The assertion that 'most mechanism-level response patterns remain largely unchanged' under human-cue prompting and instruction tuning lacks quantitative support (e.g., percentage of models exhibiting change, statistical tests, or effect sizes), making it difficult to evaluate whether the patterns are truly stable or merely described qualitatively.
Authors: The referee correctly identifies that the stability claim is currently qualitative. In the revised manuscript we will add quantitative support by reporting, for each mechanism-level pattern, the percentage of models that exhibit change versus stability under the human-cue and instruction-tuning conditions, together with any applicable statistical comparisons or effect-size measures permitted by the data. revision: yes
-
Referee: [Results and discussion] Results and discussion: No human participant data are collected on the variant prompts (truncation, repeated play, endowment, identity), so the reference point for 'human-consistent mechanisms' is limited to the original game; this weakens the interpretation that model shifts indicate divergence from human mechanisms under the same conditions.
Authors: This is a fair observation. Human benchmarks for the original game rest on a large existing literature, while the variants are motivated by theoretical predictions from decision theory. We will revise the results and discussion sections to clarify that mechanism-level comparisons for the variants are grounded in theoretical human expectations rather than newly collected empirical data, and we will note this boundary condition explicitly. New human data collection on the variants would strengthen the claims but lies beyond the scope of the present study. revision: partial
Circularity Check
No circularity: empirical prompt study with direct observations
full rationale
The paper is a purely empirical investigation that evaluates 28 LLMs on St. Petersburg game variants via structured prompts and reports observed output patterns. No equations, derivations, fitted parameters, or self-citation chains are present that reduce any claimed result to its own inputs by construction. All findings are presented as direct measurements from prompt responses, with no load-bearing theoretical steps that invoke uniqueness theorems, ansatzes, or renamed known results. The central claim rests on the experimental design itself rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Econometrica , volume =
Bernoulli, Daniel , title =. Econometrica , volume =. 1954 , doi =
1954
-
[2]
Econometrica , volume =
Tversky, Amos and Kahneman, Daniel , title =. Econometrica , volume =. 1979 , doi =
1979
-
[3]
and Johnson, Eric J
Thaler, Richard H. and Johnson, Eric J. , title =. Management Science , volume =. 1990 , doi =
1990
-
[4]
Journal of Risk and Uncertainty , volume =
Seidl, Christian , title =. Journal of Risk and Uncertainty , volume =. 2013 , doi =
2013
-
[5]
and Kroll, Eike B
Cox, James C. and Kroll, Eike B. and Lichters, Marcel and Sadiraj, Vjollca and Vogt, Bodo , title =. Business Research , volume =. 2019 , doi =
2019
-
[6]
Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =
Peters, Ole , title =. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =. 2011 , doi =
2011
-
[7]
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F. and Leike, Jan and L...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155
-
[8]
Nature Computational Science , volume =
Hagendorff, Thilo and Fabi, Sarah and Kosinski, Michal , title =. Nature Computational Science , volume =. 2023 , doi =
2023
-
[9]
Cognitive Bias in Decision-Making with
Echterhoff, Jessica Maria and Liu, Yao and Alessa, Abeer and McAuley, Julian and He, Zexue , booktitle =. Cognitive Bias in Decision-Making with. 2024 , month = nov, address =. doi:10.18653/v1/2024.findings-emnlp.739 , pages =
-
[10]
Hartley, John and Hamill, Conor Brian and Seddon, Dale and Batra, Devesh and Okhrati, Ramin and Khraishi, Raad , editor =. How Personality Traits Shape. Findings of the Association for Computational Linguistics: ACL 2025 , month = jul, year =. doi:10.18653/v1/2025.findings-acl.1085 , pages =
-
[11]
May 2024 State Occupational Employment and Wage Estimates , year =
2024
-
[12]
and Kroll, Eike B
Cox, James C. and Kroll, Eike B. and Lichters, Marcel and Sadiraj, Vjollca and Vogt, Bodo , journal =. The. 2019 , doi =
2019
-
[13]
Econometrica , volume =
Prospect Theory: An Analysis of Decision under Risk , author =. Econometrica , volume =. 1979 , doi =
1979
-
[14]
Science , volume =
The Framing of Decisions and the Psychology of Choice , author =. Science , volume =. 1981 , doi =
1981
-
[15]
Management Science , volume =
Gambling with the House Money and Trying to Break Even: The Effects of Prior Outcomes on Risky Choice , author =. Management Science , volume =. 1990 , doi =
1990
-
[16]
2022 , eprint =
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author =. 2022 , eprint =
2022
-
[17]
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dawn and Ganguli, Deep and Li, Dustin and Tran-Johnson, Eli and Perez, Ethan an...
-
[18]
Minds and Machines , volume =
Artificial Intelligence, Values, and Alignment , author =. Minds and Machines , volume =. 2020 , doi =
2020
-
[19]
2024 , eprint =
A Roadmap to Pluralistic Alignment , author =. 2024 , eprint =
2024
-
[20]
Ren, Yuanyi and Ye, Haoran and Fang, Hanjun and Zhang, Xin and Song, Guojie. V alue B ench: Towards Comprehensively Evaluating Value Orientations and Understanding of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.111
-
[21]
Nature Machine Intelligence , volume=
The benefits, risks and bounds of personalizing the alignment of large language models to individuals , author=. Nature Machine Intelligence , volume=. 2024 , publisher=
2024
-
[22]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages =
Lyu, Hanjia and Luo, Jiebo and Kang, Jian and Koenecke, Allison , title =. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2025 , isbn =. doi:10.1145/3715275.3732182 , abstract =
-
[23]
Le comportement de l'homme rationnel devant le risque: critique des postulats et axiomes de l'
Allais, Maurice , journal=. Le comportement de l'homme rationnel devant le risque: critique des postulats et axiomes de l'. 1953 , publisher=
1953
-
[24]
The quarterly journal of economics , volume=
Risk, ambiguity, and the Savage axioms , author=. The quarterly journal of economics , volume=. 1961 , publisher=
1961
-
[25]
arXiv preprint arXiv:2404.09690 , year=
Harnessing gpt-4v (ision) for insurance: A preliminary exploration , author=. arXiv preprint arXiv:2404.09690 , year=
-
[26]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
INS-MMBench: A Comprehensive Benchmark for Evaluating LVLMs' Performance in Insurance , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[27]
Available at SSRN 5574261 , year=
Fairness, Value Alignment, and Governance in LLMs: The Case of Insurance Pricing , author=. Available at SSRN 5574261 , year=
-
[28]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Investorbench: A benchmark for financial decision-making tasks with llm-based agent , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
arXiv preprint arXiv:2510.02209 , year=
Stockbench: Can llm agents trade stocks profitably in real-world markets? , author=. arXiv preprint arXiv:2510.02209 , year=
-
[30]
Nejm Ai , volume=
MedAgentBench: a virtual EHR environment to benchmark medical LLM agents , author=. Nejm Ai , volume=. 2025 , publisher=
2025
-
[31]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
CliMedBench: a large-scale Chinese benchmark for evaluating medical large language models in clinical scenarios , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[32]
and Platt, Michael L
Hayden, Benjamin Y. and Platt, Michael L. , journal =. The Mean, the Median, and the. 2009 , doi =
2009
-
[33]
LLM -Rec: Personalized Recommendation via Prompting Large Language Models
Lyu, Hanjia and Jiang, Song and Zeng, Hanqing and Xia, Yinglong and Wang, Qifan and Zhang, Si and Chen, Ren and Leung, Chris and Tang, Jiajie and Luo, Jiebo. LLM -Rec: Personalized Recommendation via Prompting Large Language Models. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.39
-
[34]
Journal of Business and Psychology , volume =
Financial Risk Tolerance and Additional Factors That Affect Risk Taking in Everyday Money Matters , author =. Journal of Business and Psychology , volume =. 2000 , doi =
2000
-
[35]
Companion Proceedings of the ACM on Web Conference 2025 , pages =
Qi, Weihong and Lyu, Hanjia and Luo, Jiebo , title =. Companion Proceedings of the ACM on Web Conference 2025 , pages =. 2025 , isbn =. doi:10.1145/3701716.3715591 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.