Audio Interaction Model
Pith reviewed 2026-06-28 04:55 UTC · model grok-4.3
The pith
A unified streaming model adds real-time audio instruction following to offline task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
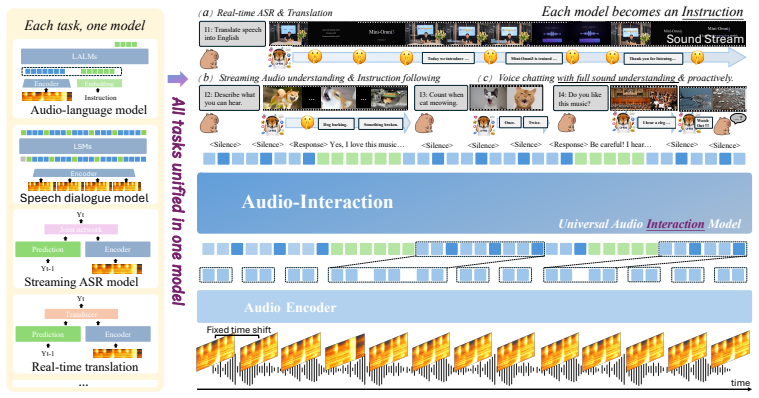
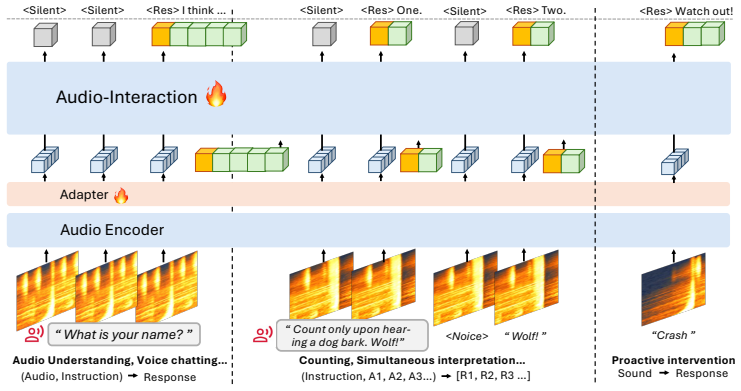
The authors formalize the regime of always-on audio interaction as the Audio Interaction Model and realize it with Audio-Interaction, a unified streaming model that retains offline task execution while adding online general audio instruction following, from dialogue to full voice chatting, deciding when to respond from the semantics of the stream.
What carries the argument
The Audio Interaction Model, implemented as a perceive-decide-respond loop in Audio-Interaction and supported end-to-end by the SoundFlow framework of streaming-native data, comprehension-aware training, and asynchronous low-latency inference.
If this is right
- The same model supports real-time ASR and streaming instruction following alongside its offline tasks.
- Response timing is determined by semantics in the audio stream rather than fixed rules.
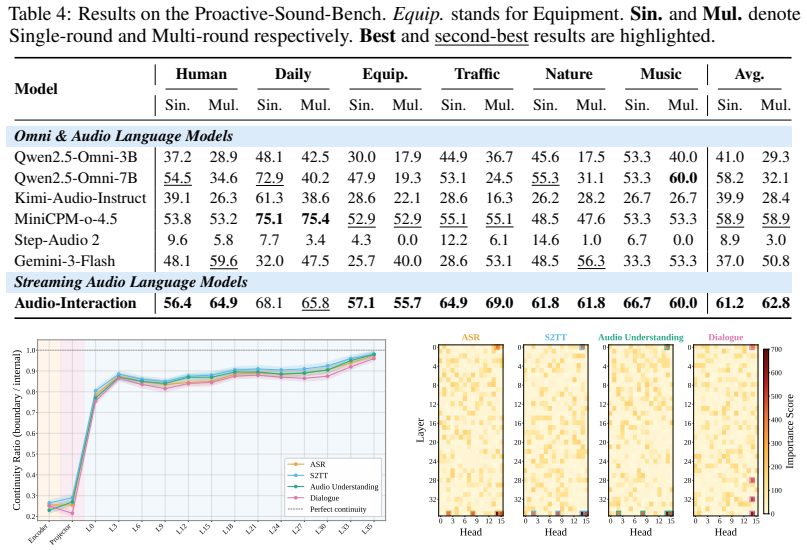
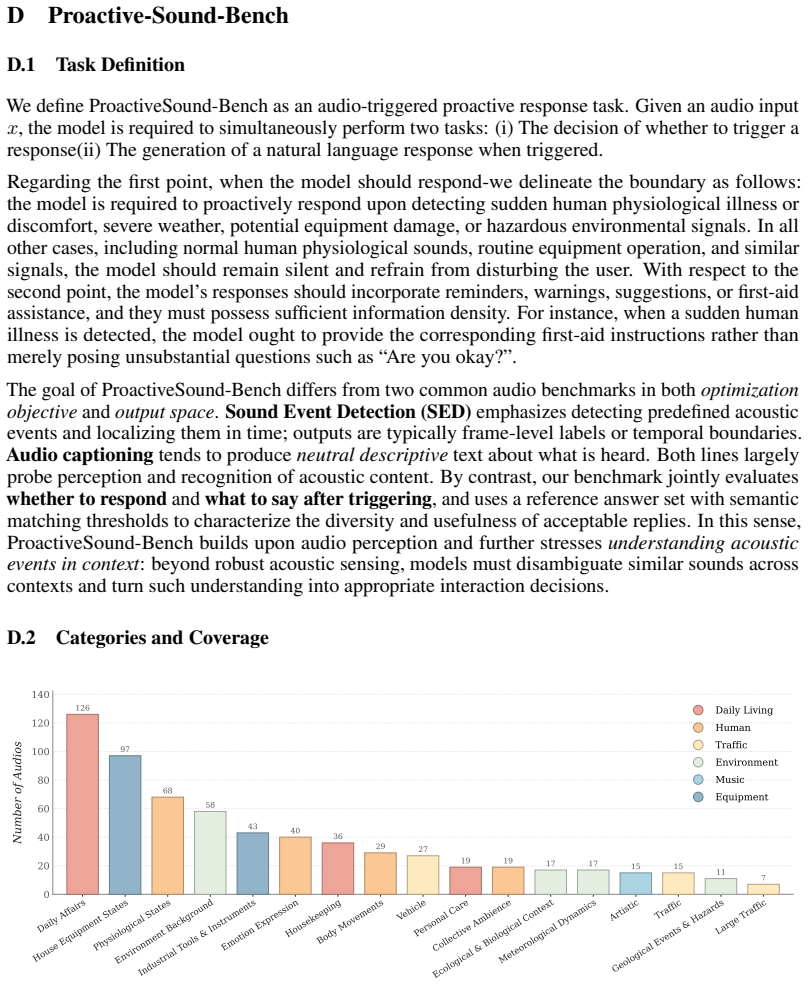
- Proactive audio intervention becomes measurable with the new Proactive-Sound-Bench.
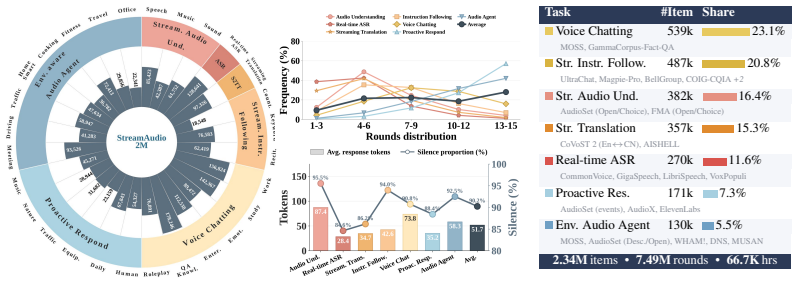
- Performance holds across 7 fundamental abilities and 28 sub-tasks in the StreamAudio-2M corpus.
Where Pith is reading between the lines
- The approach may generalize to longer multi-turn conversations where the model must maintain context across extended audio streams.
- Similar streaming loops could be tested on combined audio-visual inputs to handle environments with both sound and visual cues.
- Deployment in consumer devices would require checking whether the asynchronous inference keeps latency low enough for natural conversation.
Load-bearing premise
Streaming-native data construction, comprehension-aware training, and asynchronous low-latency inference together produce stable real-time interaction without degrading the offline capabilities the model is also required to preserve.
What would settle it
Run Audio-Interaction on the eight reported benchmarks and measure whether offline scores stay competitive while real-time ASR, instruction following, and proactive intervention succeed or fail.
Figures



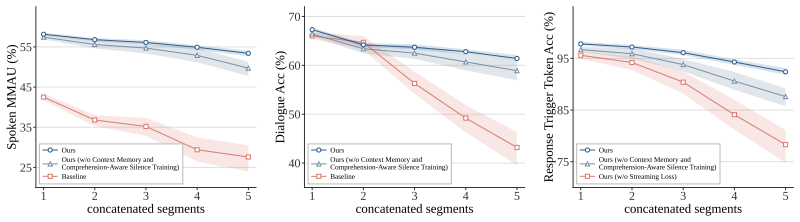
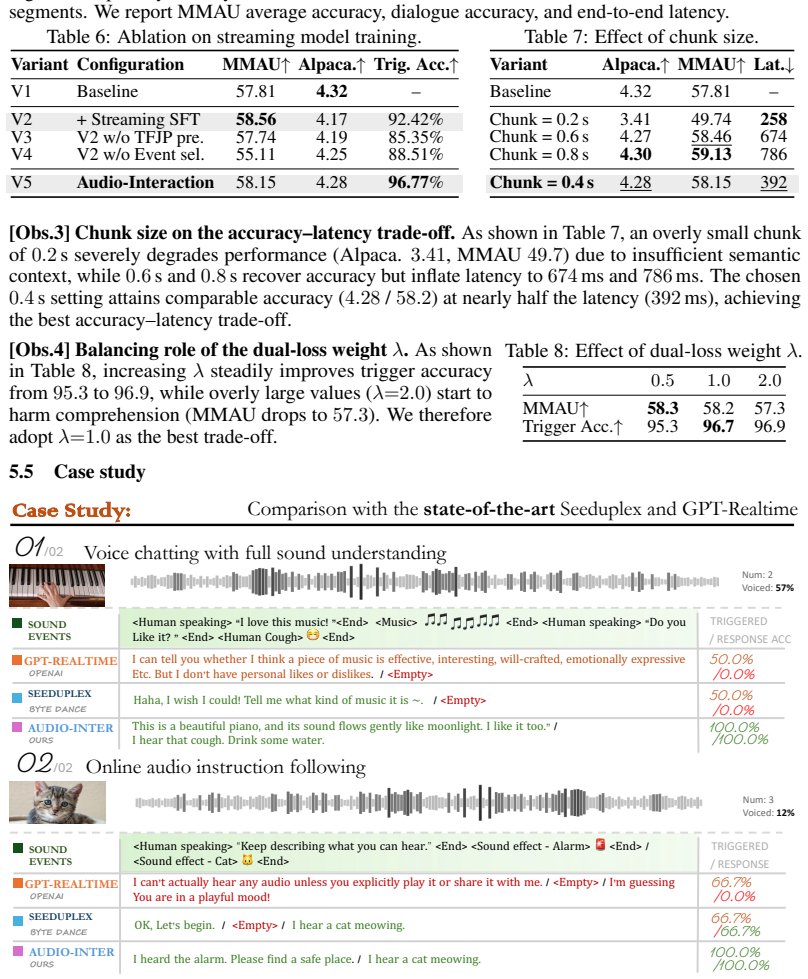
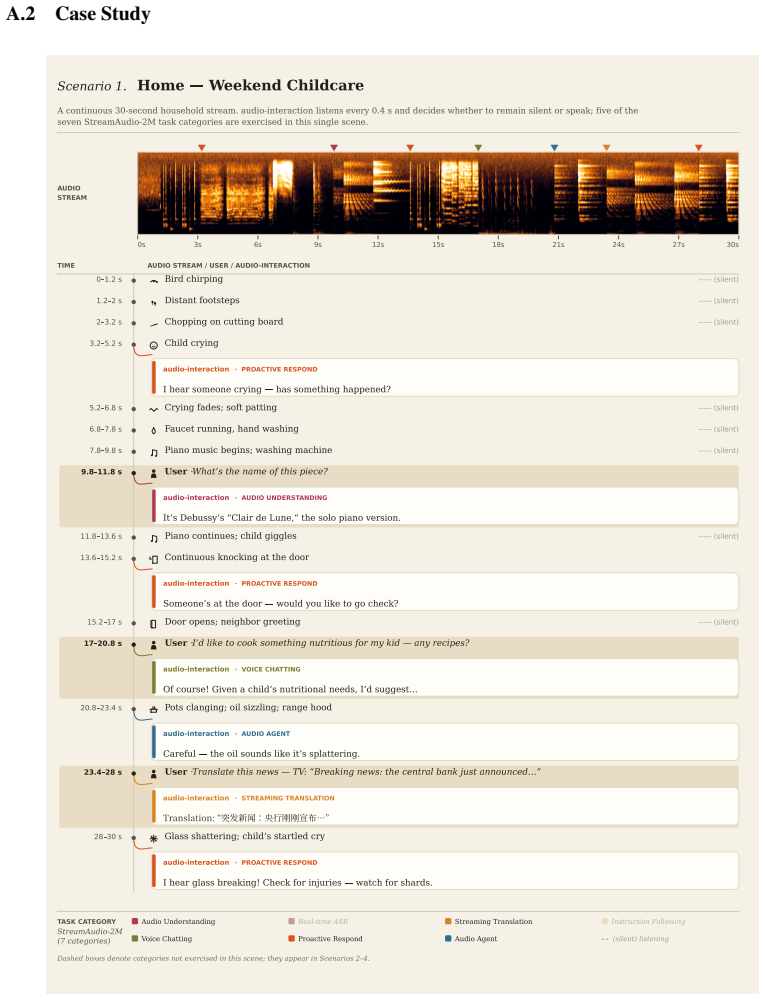
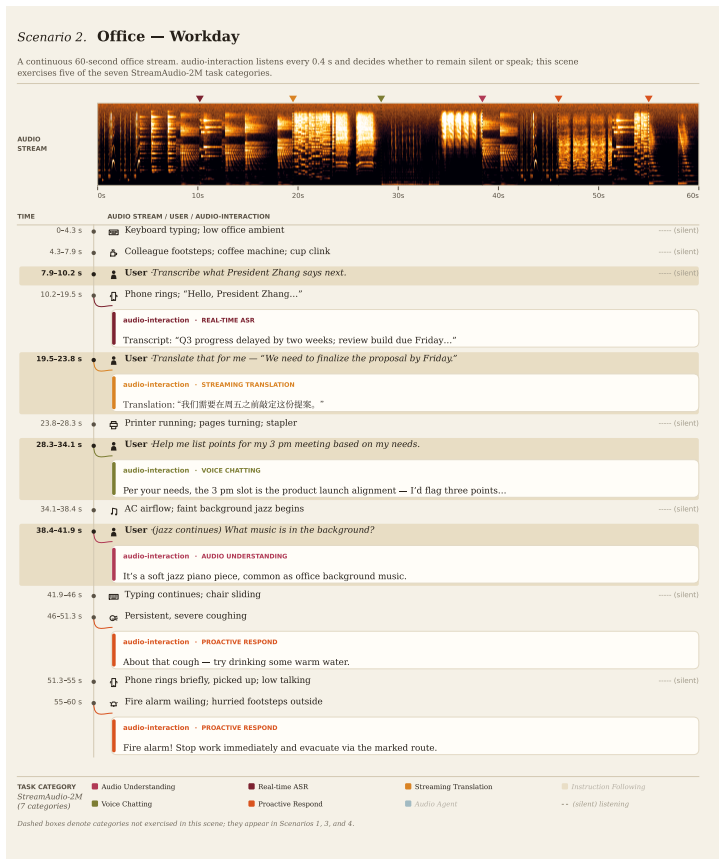




read the original abstract
Audio is an inherently interactive modality, yet today's Large Audio Language Models (LALMs) are offline, and streaming audio models each handle only a single task such as streaming ASR or voice chatting. It is time to unify them into one online LALM: a model that, through an always-on perceive-decide-respond loop, listens to sound, environment, and instructions in real time and reacts on the fly. We formalize this regime as the Audio Interaction Model, and realize it with Audio-Interaction, a unified streaming model that retains offline task execution while adding online general audio instruction following, from dialogue to full voice chatting, deciding when to respond from the semantics of the stream. To enable this, we propose SoundFlow, a framework that instantiates the perceive-decide-respond loop end to end, from data to training to deployment, through streaming-native data construction, comprehension-aware training, and asynchronous low-latency inference for stable real-time interaction. We further construct StreamAudio-2M, a 2.6M-item streaming corpus spanning 7 fundamental abilities and 28 sub-tasks, and Proactive-Sound-Bench for evaluating proactive audio intervention. Across 8 benchmarks, Audio-Interaction preserves competitive performance on mainstream audio tasks while unlocking capabilities inaccessible to offline LALMs, including real-time ASR, streaming audio instruction following, and proactive help.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the Audio Interaction Model as a unified streaming Large Audio Language Model (LALM) that performs an always-on perceive-decide-respond loop. It realizes this with Audio-Interaction, built via the SoundFlow framework (streaming-native data construction, comprehension-aware training, asynchronous low-latency inference). The work introduces StreamAudio-2M (2.6M-item corpus covering 7 abilities and 28 sub-tasks) and Proactive-Sound-Bench, claiming that the resulting model preserves competitive performance on mainstream offline audio tasks while enabling new online capabilities such as real-time ASR, streaming instruction following, and proactive intervention, as demonstrated across 8 benchmarks.
Significance. If the empirical results hold, the unification of offline and online audio capabilities in a single model would be a notable contribution to audio-language modeling, moving beyond task-specific streaming systems. The new streaming corpus and proactive benchmark are concrete additions that could support further research in real-time audio interaction.
major comments (1)
- [Abstract] Abstract: The central empirical claim—that SoundFlow enables preservation of offline performance while adding stable online instruction following—is asserted without any quantitative results, tables, ablation studies, or error analysis. This leaves the weakest assumption (that the three SoundFlow components produce the claimed outcome without degradation) unverified from the provided text.
minor comments (2)
- The abstract references '8 benchmarks' and 'competitive performance' but does not name the benchmarks or report specific metrics, limiting immediate assessment of the results.
- Terminology such as 'comprehension-aware training' and 'asynchronous low-latency inference' is introduced at a high level without definitions or pseudocode in the visible text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and the opportunity to clarify the presentation of our results. We address the comment on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim—that SoundFlow enables preservation of offline performance while adding stable online instruction following—is asserted without any quantitative results, tables, ablation studies, or error analysis. This leaves the weakest assumption (that the three SoundFlow components produce the claimed outcome without degradation) unverified from the provided text.
Authors: The abstract serves as a high-level summary of the paper's contributions and findings. The quantitative results, including performance tables, ablation studies on the SoundFlow components, and error analyses, are provided in the main body of the manuscript, specifically in the Experiments section across 8 benchmarks. These demonstrate that Audio-Interaction maintains competitive offline performance while enabling online capabilities. However, we acknowledge that including key quantitative highlights directly in the abstract would make the central claim more immediately verifiable. We will revise the abstract to incorporate representative metrics, such as accuracy on offline tasks and latency/success rates for online instruction following. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical framework (SoundFlow) for a streaming audio model, including dataset construction (StreamAudio-2M), training procedures, inference methods, and evaluation across benchmarks. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. The central assertions rest on experimental outcomes rather than reductions to inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras.arXiv preprint arXiv:2503.01743,
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
-
[3]
Ye Bai, Jingping Chen, Jitong Chen, Wei Chen, Zhuo Chen, Chuang Ding, Linhao Dong, Qianqian Dong, Yujiao Du, Kepan Gao, et al. Seed-asr: Understanding diverse speech and contexts with llm-based speech recognition.arXiv preprint arXiv:2407.04675,
-
[4]
Seamless: Multilingual expressive and streaming speech translation.arXiv preprint arXiv:2312.05187,
Loïc Barrault, Yu-An Chung, Mariano Coria Meglioli, David Dale, Ning Dong, Mark Duppenthaler, Paul-Ambroise Duquenne, Brian Ellis, Hady Elsahar, Justin Haaheim, et al. Seamless: Multilingual expressive and streaming speech translation.arXiv preprint arXiv:2312.05187,
-
[5]
Semantic parsing on freebase from question-answer pairs
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on freebase from question-answer pairs. InProceedings of the 2013 conference on empirical methods in natural language processing, pages 1533–1544,
2013
-
[6]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[7]
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models.arXiv preprint arXiv:2311.07919,
-
[8]
Qwen2-audio technical report.arXiv preprint arXiv:2407.10759,
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759,
-
[9]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037,
-
[10]
Sd-qa: Spoken dialectal question answering for the real world
Fahim Faisal, Sharlina Keshava, Md Mahfuz Ibn Alam, and Antonios Anastasopoulos. Sd-qa: Spoken dialectal question answering for the real world. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 3296–3315,
2021
-
[11]
Llama-omni: Seamless speech interaction with large language models.arXiv preprint arXiv:2409.06666,
Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, and Yang Feng. Llama-omni: Seamless speech interaction with large language models.arXiv preprint arXiv:2409.06666,
-
[12]
Llama-omni 2: Llm-based real-time spoken chatbot with autoregressive streaming speech synthesis
Qingkai Fang, Yan Zhou, Shoutao Guo, Shaolei Zhang, and Yang Feng. Llama-omni 2: Llm-based real-time spoken chatbot with autoregressive streaming speech synthesis. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18617–18629, 2025a. 12 Qingkai Fang, Yan Zhou, Shoutao Guo, Shaolei Zhan...
-
[13]
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro. Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities.arXiv preprint arXiv:2503.03983,
-
[14]
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang-gil Lee, Chao- Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, et al. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models.arXiv preprint arXiv:2507.08128,
-
[15]
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. Audio Flamingo: A novel audio language model with few-shot learning and dialogue abilities.arXiv preprint arXiv:2402.01831,
-
[16]
Zhifeng Kong, Arushi Goel, Joao Felipe Santos, Sreyan Ghosh, Rafael Valle, Wei Ping, and Bryan Catanzaro. Audio flamingo sound-cot technical report: Improving chain-of-thought reasoning in sound understanding.arXiv preprint arXiv:2508.11818,
-
[17]
Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025a
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025a. Longhao Li, Hongjie Chen, Zehan Li, Qihan Hu, Jian Kang, Jie Li, Lei Xie, and Yongxiang Li. Audio-cogito: Towards deep audio reasoning in large audio lan...
-
[18]
Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025b
Yadong Li, Jun Liu, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Gu- osheng Dong, Da Pan, et al. Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025b. Alexander H Liu, Andy Ehrenberg, Andy Lo, Clément Denoix, Corentin Barreau, Guillaume Lample, Jean-Malo Delignon, Khyathi Raghavi Chandu, Patrick von Platen, ...
-
[19]
Xiaoze Liu, Ruowang Zhang, Amir H Abdi, Michel Galley, Zhikai Chen, Siheng Xiong, Xiaoqian Wang, and Jing Gao. Do proactive agents really need an llm to decide when to wake and what to anchor?arXiv preprint arXiv:2605.30152,
-
[20]
Eliya Nachmani, Alon Levkovitch, Roy Hirsch, Julian Salazar, Chulayuth Asawaroengchai, Soroosh Mariooryad, Ehud Rivlin, RJ Skerry-Ryan, and Michelle Tadmor Ramanovich. Spoken question an- swering and speech continuation using spectrogram-powered llm.arXiv preprint arXiv:2305.15255,
-
[21]
Deepak Nathani, Cheng Zhang, Chang Huan, Jiaming Shan, Yinfei Yang, Alkesh Patel, Zhe Gan, William Yang Wang, Michael Saxon, and Xin Eric Wang. Proactive agent research environment: Simulating active users to evaluate proactive assistants.arXiv preprint arXiv:2604.00842,
-
[22]
Qwen2.5-Omni technical report.arXiv preprint arXiv:2503.20215,
Qwen Team. Qwen2.5-Omni technical report.arXiv preprint arXiv:2503.20215,
-
[23]
Sakshi Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark.arXiv preprint arXiv:2410.19168,
-
[24]
Monica Sekoyan, Nithin Rao Koluguri, Nune Tadevosyan, Piotr Zelasko, Travis Bartley, Nikolay Karpov, Jagadeesh Balam, and Boris Ginsburg. Canary-1b-v2 & parakeet-tdt-0.6 b-v3: Efficient and high-performance models for multilingual asr and ast.arXiv preprint arXiv:2509.14128,
-
[25]
Qwen3-asr technical report.arXiv preprint arXiv:2601.21337,
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, et al. Qwen3-asr technical report.arXiv preprint arXiv:2601.21337,
-
[26]
Musan: A music, speech, and noise corpus.arXiv preprint arXiv:1510.08484,
David Snyder, Guoguo Chen, and Daniel Povey. Musan: A music, speech, and noise corpus.arXiv preprint arXiv:1510.08484,
-
[27]
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models.arXiv preprint arXiv:2310.13289,
-
[28]
Audiox: Diffusion transformer for anything-to-audio generation.arXiv preprint arXiv:2503.10522,
Zeyue Tian, Yizhu Jin, Zhaoyang Liu, Ruibin Yuan, Xu Tan, Qifeng Chen, Wei Xue, and Yike Guo. Audiox: Diffusion transformer for anything-to-audio generation.arXiv preprint arXiv:2503.10522,
-
[29]
Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
-
[30]
Covost 2 and massively multilingual speech translation
Changhan Wang, Anne Wu, Jiatao Gu, and Juan Pino. Covost 2 and massively multilingual speech translation. InInterspeech, volume 2021, pages 2247–2251,
2021
-
[31]
Mmsu: A massive multi-task spoken language understanding and reasoning benchmark
Dingdong Wang, Junan Li, Jincenzi Wu, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark. arXiv preprint arXiv:2506.04779,
-
[32]
Dingdong Wang, Shujie Liu, Tianhua Zhang, Youjun Chen, Jinyu Li, and Helen Meng. Emotion- thinker: Prosody-aware reinforcement learning for explainable speech emotion reasoning.arXiv preprint arXiv:2601.15668,
-
[33]
14 Xiong Wang, Yangze Li, Chaoyou Fu, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long Ma. Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen llm.arXiv preprint arXiv:2411.00774,
-
[34]
Wham!: Extending speech separation to noisy environments.arXiv preprint arXiv:1907.01160,
Gordon Wichern, Joe Antognini, Michael Flynn, Licheng Richard Zhu, Emmett McQuinn, Dwight Crow, Ethan Manilow, and Jonathan Le Roux. Wham!: Extending speech separation to noisy environments.arXiv preprint arXiv:1907.01160,
Pith/arXiv arXiv 1907
-
[35]
Step-audio 2 technical report.arXiv preprint arXiv:2507.16632, 2025a
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. Step-audio 2 technical report.arXiv preprint arXiv:2507.16632, 2025a. Donghang Wu, Haoyang Zhang, Chen Chen, Tianyu Zhang, Fei Tian, Xuerui Yang, Gang Yu, Hexin Liu, Nana Hou, Yuchen Hu, et al. Chronological thinking in full-duplex spoken...
-
[36]
Zhifei Xie and Changqiao Wu. Mini-omni2: Towards open-source gpt-4o with vision, speech and duplex capabilities.arXiv preprint arXiv:2410.11190, 2024a. Zhifei Xie and Changqiao Wu. Mini-omni: Language models can hear, talk while thinking in streaming.arXiv preprint arXiv:2408.16725, 2024b. Zhifei Xie, Zongzheng Hu, Fangda Ye, Xin Zhang, Haobo Chai, Zihang...
-
[37]
Kai-Tuo Xu, Feng-Long Xie, Xu Tang, and Yao Hu. Fireredasr: Open-source industrial-grade mandarin speech recognition models from encoder-decoder to llm integration.arXiv preprint arXiv:2501.14350,
-
[38]
Bufang Yang, Lilin Xu, Liekang Zeng, Yunqi Guo, Siyang Jiang, Wenrui Lu, Kaiwei Liu, Hancheng Xiang, Xiaofan Jiang, Guoliang Xing, et al. Proagent: Harnessing on-demand sensory contexts for proactive llm agent systems.arXiv preprint arXiv:2512.06721,
-
[39]
React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
-
[40]
Haoyang Zhang, Jun Chen, Donghang Wu, Yuxin Li, Yuxin Zhang, Xiangyu Tony Zhang, Che Liu, Qingjian Lin, Yizhou Peng, Hexin Liu, et al. Duplexsla: A full-duplex spoken language model with synchronized speech, language, and action.arXiv preprint arXiv:2605.20755,
-
[41]
Audio- reasoner: Improving reasoning capability in large audio language models
Xie Zhifei, Mingbao Lin, Zihang Liu, Pengcheng Wu, Shuicheng Yan, and Chunyan Miao. Audio- reasoner: Improving reasoning capability in large audio language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 23840–23862,
2025
-
[42]
Jiaming Zhou, Xuxin Cheng, Shiwan Zhao, Yuhang Jia, Cao Liu, Ke Zeng, Xunliang Cai, and Yong Qin. Diffa-2: A practical diffusion large language model for general audio understanding.arXiv preprint arXiv:2601.23161,
-
[43]
door slam
Stage 3 — Clip Grounding Verification System:You are an audio quality verifier. Given a candidate audio clip and its target sub-event, decide whether the clip can be inserted into the surrounding scenario without breaking acoustic consistency. The same prompt is applied identically to retrieved clips and to clips synthesized by AudioX or ElevenLabs — veri...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.