Preserving Data Privacy in Learning Causal Structure with Fully Homomorphic Encryption
Pith reviewed 2026-06-28 05:20 UTC · model grok-4.3
The pith
Causal structure learning can run on fully encrypted data with accuracy matching plaintext versions by approximating division and logarithm operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
All steps of causal structure learning can be executed directly on ciphertexts by replacing unsupported operations with Newton-Raphson reciprocal and Taylor expansions, together with circuit simplification and SIMD batching, so that the recovered structures match the plaintext versions in consistency and accuracy.
What carries the argument
Newton-Raphson reciprocal approximation for division and Taylor expansion for logarithm, applied inside a circuit-simplified, SIMD-batched FHE workflow that keeps data encrypted throughout.
If this is right
- Causal discovery becomes possible on distributed encrypted data without any party decrypting intermediates.
- The same approximation pipeline supports differential privacy as an alternative protection layer.
- Learning completes in tens of minutes even under full FHE protection.
- High consistency with plaintext results holds across the datasets examined.
Where Pith is reading between the lines
- Organizations could pool encrypted records for joint causal analysis without exposing raw values.
- The method might scale to larger graphs if the approximation error stays bounded as node count grows.
- Applying the same approximations to other graph-learning tasks that rely on division and logs could be tested directly.
Load-bearing premise
The numerical approximations for division and logarithm keep enough accuracy that downstream causal discovery still recovers the correct structure.
What would settle it
A dataset where the plaintext algorithm recovers the true causal graph but the FHE version with approximations recovers a different graph would show the accuracy claim fails.
Figures






read the original abstract
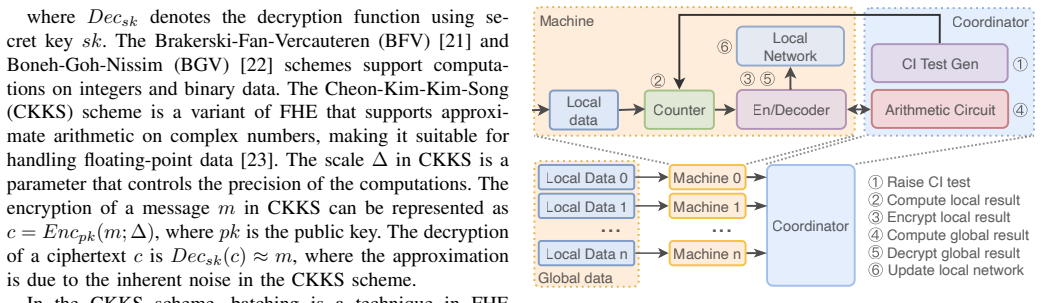
Preserving data privacy is an important topic in structural data management and data mining. However, the issue of privacy leakage in distributed causal structure learning is a persistent challenge, especially in cases where data transmission and computation are required. In this paper, we propose a method based on fully homomorphic encryption (FHE) that performs calculations on ciphertexts, keeping data encrypted in transition and computation. Nevertheless, adopting FHE to causal structure learning is challenging due to the high computation cost and limited support on division as well as logarithm operations in FHE. To tackle this challenge, we propose a series of novel techniques including (i) circuit simplification for better efficiency, (ii) approximation of division and logarithm through Newton-Raphson Reciprocal and Taylor expansion, and (iii) a batching technique with SIMD-acceleration to enhance the whole learning process. Additionally, our method can be easily extended beyond FHE by demonstration of its portability to support differential privacy. Empirical results show that our method achieves high consistency and comparable causal structure with the plaintext version in the datasets tested. Last, our method is efficient and practical to complete learning causal structures in tens of minutes even under the privacy protection of FHE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an FHE-based approach for privacy-preserving causal structure learning. It tackles FHE limitations on division and logarithm via Newton-Raphson reciprocal approximation and Taylor expansions, plus circuit simplification and SIMD batching for efficiency. The method is claimed to extend to differential privacy, and empirical results assert high consistency with plaintext causal discovery on tested datasets, with runtimes in tens of minutes.
Significance. If the numerical approximations preserve sufficient fidelity for downstream causal algorithms, the work would be a practical contribution to secure distributed causal discovery. The engineering focus on circuit simplification, batching, and portability to DP is a strength, as is the direct empirical test of the core assumption that the approximations do not degrade structure recovery.
major comments (2)
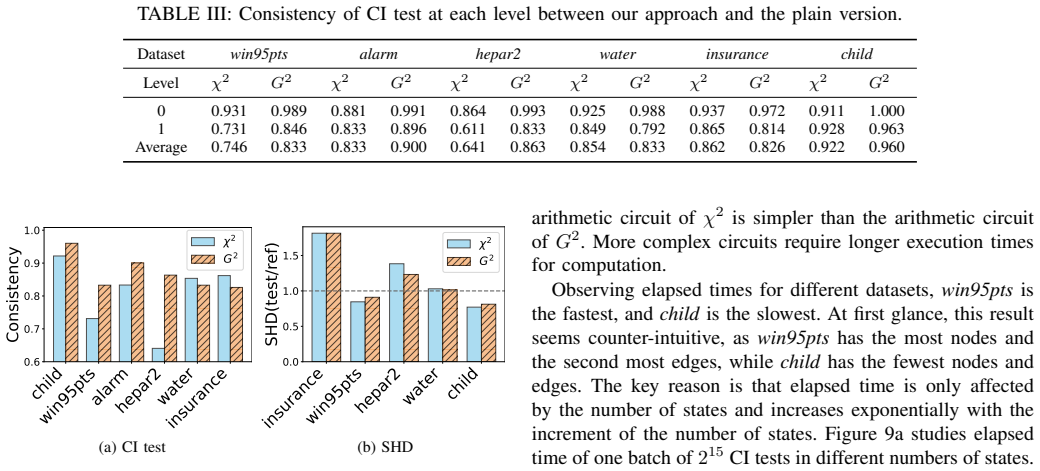
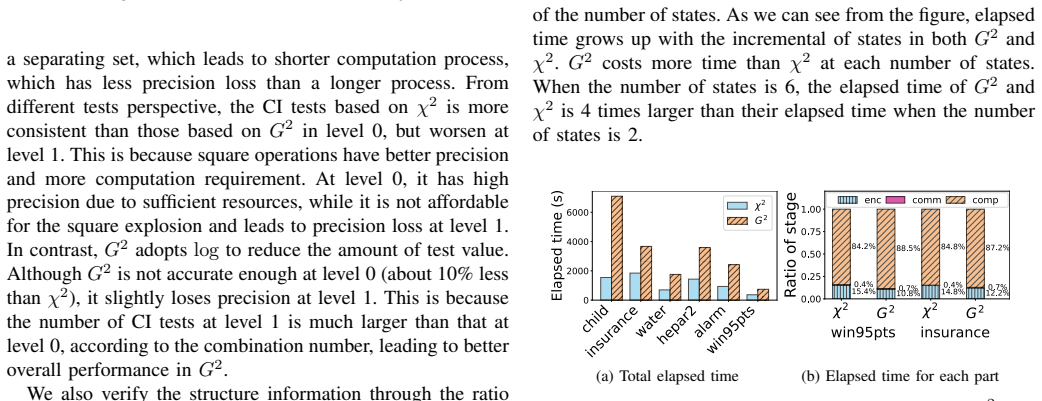
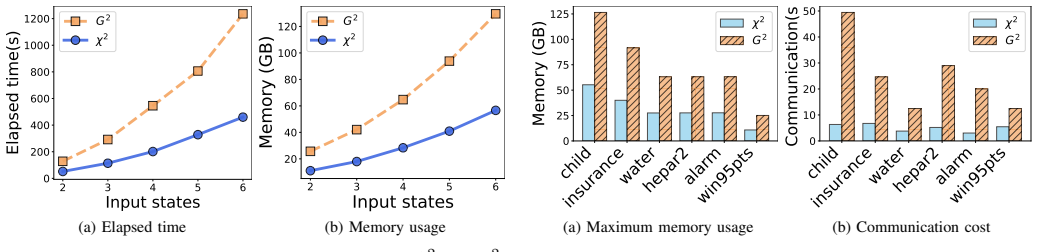
- [Abstract / Experiments] Abstract and experimental results: the central claim that the method 'achieves high consistency and comparable causal structure with the plaintext version in the datasets tested' is load-bearing, yet the provided text supplies no datasets, sample sizes, metrics (e.g., SHD, precision/recall on edges), error bars, or ablation on approximation parameters. This prevents evaluation of whether the Newton-Raphson/Taylor approximations meet the weakest-assumption threshold.
- [Method (approximations subsection)] Approximation methods: the Newton-Raphson reciprocal and Taylor expansions for division and logarithm lack any reported error bounds, convergence analysis, or propagation study showing that the induced numerical error does not alter the output of the causal discovery procedure. Because the paper's correctness rests on these approximations preserving structure, a concrete sensitivity test (e.g., graph difference under varying iteration counts or polynomial degree) is required.
minor comments (1)
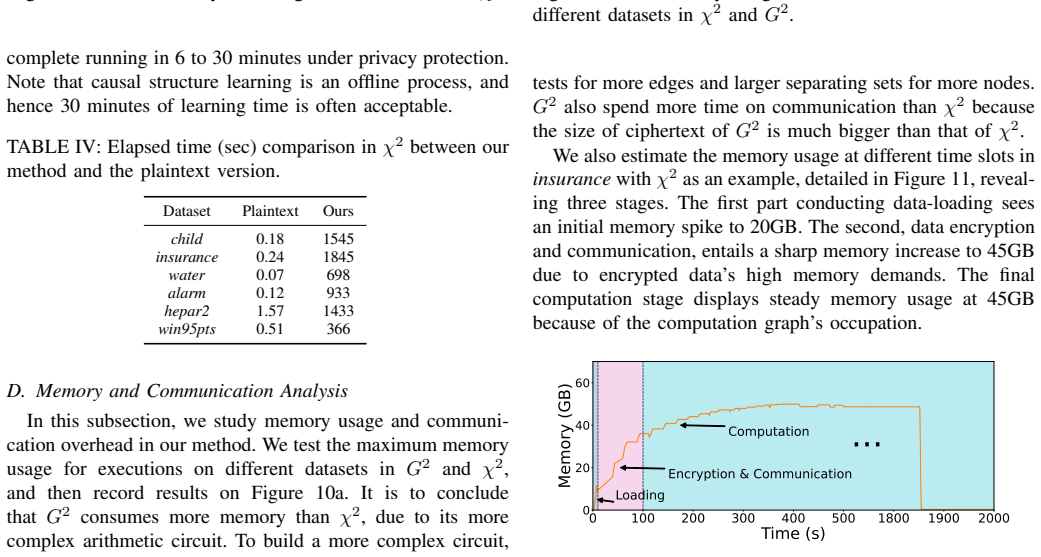
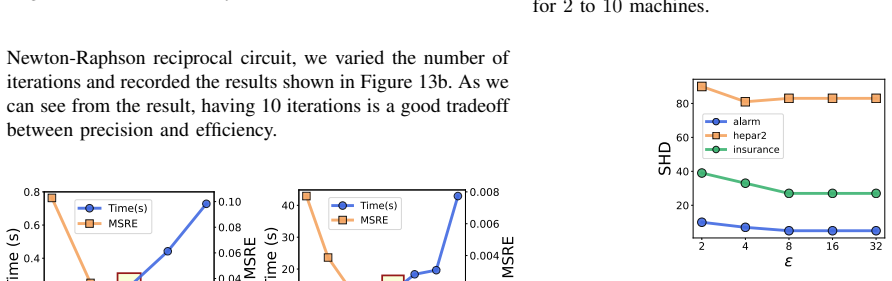
- [Implementation details] Notation for the batching and SIMD parameters could be clarified with an explicit table of ciphertext packing sizes and their effect on throughput.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where the manuscript can be strengthened with additional experimental details and analysis. We will revise accordingly and address each point below.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental results: the central claim that the method 'achieves high consistency and comparable causal structure with the plaintext version in the datasets tested' is load-bearing, yet the provided text supplies no datasets, sample sizes, metrics (e.g., SHD, precision/recall on edges), error bars, or ablation on approximation parameters. This prevents evaluation of whether the Newton-Raphson/Taylor approximations meet the weakest-assumption threshold.
Authors: We agree the manuscript lacks these specifics in the abstract and experimental reporting. In revision we will expand the experiments section to list the exact datasets (standard benchmarks such as Asia and Sachs), sample sizes, quantitative metrics including SHD and edge precision/recall with error bars across runs, and ablations varying approximation parameters (iteration counts, polynomial degrees) to show that structure recovery remains comparable to plaintext. revision: yes
-
Referee: [Method (approximations subsection)] Approximation methods: the Newton-Raphson reciprocal and Taylor expansions for division and logarithm lack any reported error bounds, convergence analysis, or propagation study showing that the induced numerical error does not alter the output of the causal discovery procedure. Because the paper's correctness rests on these approximations preserving structure, a concrete sensitivity test (e.g., graph difference under varying iteration counts or polynomial degree) is required.
Authors: The current text describes the approximations but omits explicit bounds and sensitivity results. We will add a dedicated analysis subsection reporting error bounds for the Newton-Raphson reciprocal and Taylor series, convergence behavior, and propagation through the causal algorithm. This will include sensitivity experiments measuring graph differences (SHD, edge changes) under different iteration counts and polynomial degrees to confirm the approximations preserve the recovered structure. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method for causal structure learning under FHE, using circuit simplification, Newton-Raphson reciprocal, Taylor expansions for division/log, and SIMD batching. Its central claim is that the encrypted version achieves high consistency and comparable structure to the plaintext version on tested datasets. This is validated by direct external comparison rather than any internal derivation that reduces to fitted parameters, self-definitions, or self-citation chains. No load-bearing step equates a prediction to its own inputs by construction; the numerical fidelity of the approximations is treated as an empirical question tested outside the method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Probabilistic reasoning in intelligent systems: networks of plausible inference,
J. Pearl, “Probabilistic reasoning in intelligent systems: networks of plausible inference,” 1988
1988
-
[2]
Citywide traffic volume estimation using trajectory data,
X. Zhan, Y . Zheng, X. Yi, and S. V . Ukkusuri, “Citywide traffic volume estimation using trajectory data,”IEEE Transactions on Knowledge and Data Engineering, vol. 29, no. 2, pp. 272–285, 2016
2016
-
[3]
A rear-end collision risk evaluation and control scheme using a bayesian network model,
C. Chen, X. Liu, H.-H. Chen, M. Li, and L. Zhao, “A rear-end collision risk evaluation and control scheme using a bayesian network model,” IEEE Transactions on Intelligent Transportation Systems, vol. 20, no. 1, pp. 264–284, 2018
2018
-
[4]
Darpa’s explainable artificial intelligence (XAI) program,
D. Gunning and D. Aha, “Darpa’s explainable artificial intelligence (XAI) program,”AI Magazine, vol. 40, no. 2, pp. 44–58, 2019
2019
-
[5]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead,
C. Rudin, “Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead,”Nature Machine Intelligence, vol. 1, no. 5, pp. 206–215, 2019
2019
-
[6]
Order-independent constraint- based causal structure learning
D. Colombo, M. H. Maathuiset al., “Order-independent constraint- based causal structure learning.”Journal of Machine Learning Research, vol. 15, no. 1, pp. 3741–3782, 2014
2014
-
[7]
Inferring gene regulatory networks from gene expression data by path consistency algorithm based on conditional mutual information,
X. Zhang, X.-M. Zhao, K. He, L. Lu, Y . Cao, J. Liu, J.-K. Hao, Z.- P. Liu, and L. Chen, “Inferring gene regulatory networks from gene expression data by path consistency algorithm based on conditional mutual information,”Bioinformatics, vol. 28, no. 1, pp. 98–104, 2012. 12
2012
-
[8]
Predicting causal effects in large-scale systems from observational data,
M. H. Maathuis, D. Colombo, M. Kalisch, and P. B ¨uhlmann, “Predicting causal effects in large-scale systems from observational data,”Nature methods, vol. 7, no. 4, pp. 247–248, 2010
2010
-
[9]
Learning Bayesian Networks with the bnlearn R Package
M. Scutari, “Learning Bayesian networks with the bnlearn R package,” arXiv preprint arXiv:0908.3817, 2009
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[10]
Tetrad—a toolbox for causal discovery,
J. D. Ramsey, K. Zhang, M. Glymour, R. S. Romero, B. Huang, I. Ebert- Uphoff, S. Samarasinghe, E. A. Barnes, and C. Glymour, “Tetrad—a toolbox for causal discovery,” inInternational Workshop on Climate Informatics, 2018
2018
-
[11]
Fully homomorphic encryption using ideal lattices,
C. Gentry, “Fully homomorphic encryption using ideal lattices,” in Proceedings of the forty-first annual ACM symposium on Theory of computing, 2009, pp. 169–178
2009
-
[12]
A review of homomorphic encryption and software tools for encrypted statistical machine learning
L. J. Aslett, P. M. Esperanc ¸a, and C. C. Holmes, “A review of homomorphic encryption and software tools for encrypted statistical machine learning,”arXiv preprint arXiv:1508.06574, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Spirtes, C
P. Spirtes, C. N. Glymour, R. Scheines, and D. Heckerman,Causation, prediction, and search. MIT press, 2000
2000
-
[14]
Learning high-dimensional directed acyclic graphs with latent and selection variables,
D. Colombo, M. H. Maathuis, M. Kalisch, and T. S. Richardson, “Learning high-dimensional directed acyclic graphs with latent and selection variables,”The Annals of Statistics, pp. 294–321, 2012
2012
-
[15]
Causal Inference and Causal Explanation with Background Knowledge
C. Meek, “Causal inference and causal explanation with background knowledge,”arXiv preprint arXiv:1302.4972, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[16]
cupc: Cuda-based parallel PC algorithm for causal structure learning on gpu,
B. Zarebavani, F. Jafarinejad, M. Hashemi, and S. Salehkaleybar, “cupc: Cuda-based parallel PC algorithm for causal structure learning on gpu,” IEEE Transactions on Parallel and Distributed Systems, vol. 31, no. 3, pp. 530–542, 2019
2019
-
[17]
Differential privacy,
C. Dwork, “Differential privacy,” inAutomata, Languages and Program- ming: 33rd International Colloquium, ICALP 2006, Venice, Italy, July 10-14, 2006, Proceedings, Part II 33. Springer, 2006, pp. 1–12
2006
-
[18]
Privacy-preserving deep learning,
R. Shokri and V . Shmatikov, “Privacy-preserving deep learning,” in Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, 2015, pp. 1310–1321
2015
-
[19]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” in Proceedings of the 2016 ACM SIGSAC conference on computer and communications security, 2016, pp. 308–318
2016
-
[20]
The exponential mechanism for social welfare: Private, truthful, and nearly optimal,
Z. Huang and S. Kannan, “The exponential mechanism for social welfare: Private, truthful, and nearly optimal,” in2012 IEEE 53rd Annual Symposium on Foundations of Computer Science. IEEE, 2012, pp. 140– 149
2012
-
[21]
Somewhat practical fully homomorphic encryption,
J. Fan and F. Vercauteren, “Somewhat practical fully homomorphic encryption,”Cryptology ePrint Archive, 2012
2012
-
[22]
(leveled) fully ho- momorphic encryption without bootstrapping,
Z. Brakerski, C. Gentry, and V . Vaikuntanathan, “(leveled) fully ho- momorphic encryption without bootstrapping,”ACM Transactions on Computation Theory (TOCT), vol. 6, no. 3, pp. 1–36, 2014
2014
-
[23]
Homomorphic encryption for arithmetic of approximate numbers,
J. H. Cheon, A. Kim, M. Kim, and Y . Song, “Homomorphic encryption for arithmetic of approximate numbers,” inAdvances in Cryptology– ASIACRYPT 2017: 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, December 3-7, 2017, Proceedings, Part I 23. Springer, 2017, pp. 409– 437
2017
-
[24]
Fully homomorphic encryption over the integers,
M. Van Dijk, C. Gentry, S. Halevi, and V . Vaikuntanathan, “Fully homomorphic encryption over the integers,” inAdvances in Cryptology– EUROCRYPT 2010: 29th Annual International Conference on the The- ory and Applications of Cryptographic Techniques, French Riviera, May 30–June 3, 2010. Proceedings 29. Springer, 2010, pp. 24–43
2010
-
[25]
Choosing starting values for newton- raphson computation of reciprocals, square-roots and square-root recip- rocals,
P. Kornerup and J.-M. Muller, “Choosing starting values for newton- raphson computation of reciprocals, square-roots and square-root recip- rocals,” Ph.D. dissertation, INRIA, LIP, 2003
2003
-
[26]
Microsoft SEAL (release 4.1),
“Microsoft SEAL (release 4.1),” https://github.com/Microsoft/SEAL, Jan. 2023, microsoft Research, Redmond, W A
2023
-
[27]
Eva: An encrypted vector arithmetic language and compiler for efficient homomorphic computation,
R. Dathathri, B. Kostova, O. Saarikivi, W. Dai, K. Laine, and M. Musuvathi, “Eva: An encrypted vector arithmetic language and compiler for efficient homomorphic computation,” inProceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI 2020. New York, NY , USA: Association for Computing Machinery, 2020, p. ...
-
[28]
M. Scutari, “Bayesian network constraint-based structure learning al- gorithms: Parallel and optimised implementations in the bnlearn R package,”arXiv preprint arXiv:1406.7648, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[29]
Generalized hamming distance,
A. Bookstein, V . A. Kulyukin, and T. Raita, “Generalized hamming distance,”Information Retrieval, vol. 5, pp. 353–375, 2002
2002
-
[30]
Fast parallel bayesian network structure learning,
J. Jiang, Z. Wen, and A. Mian, “Fast parallel bayesian network structure learning,” in2022 IEEE International Parallel and Distributed Process- ing Symposium (IPDPS), 2022, pp. 617–627
2022
-
[31]
Searching for Bayesian network structures in the space of restricted acyclic partially directed graphs,
S. Acid and L. M. de Campos, “Searching for Bayesian network structures in the space of restricted acyclic partially directed graphs,” Journal of Artificial Intelligence Research, vol. 18, pp. 445–490, 2003
2003
-
[32]
A Branch-and-Bound Algorithm for MDL Learning Bayesian Networks
J. Tian, “A branch-and-bound algorithm for mdl learning Bayesian networks,”arXiv preprint arXiv:1301.3897, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[33]
Learning Bayesian Networks from Incomplete Data with Stochastic Search Algorithms
J. W. Myers, K. B. Laskey, and T. S. Levitt, “Learning Bayesian networks from incomplete data with stochastic search algorithms,”arXiv preprint arXiv:1301.6726, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[34]
Efficient and scalable structure learning for bayesian net- works: Algorithms and applications,
R. Zhu, A. Pfadler, Z. Wu, Y . Han, X. Yang, F. Ye, Z. Qian, J. Zhou, and B. Cui, “Efficient and scalable structure learning for bayesian net- works: Algorithms and applications,” in2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 2021, pp. 2613–2624
2021
-
[35]
Counting unlabeled acyclic digraphs,
R. W. Robinson, “Counting unlabeled acyclic digraphs,” inCombinato- rial Mathematics V. Springer, 1977, pp. 28–43
1977
-
[36]
Who learns better Bayesian network structures: Accuracy and speed of structure learning algorithms,
M. Scutari, C. E. Graafland, and J. M. Guti ´errez, “Who learns better Bayesian network structures: Accuracy and speed of structure learning algorithms,”International Journal of Approximate Reasoning, vol. 115, pp. 235–253, 2019
2019
-
[37]
Secure multi-party computation,
O. Goldreich, “Secure multi-party computation,”Manuscript. Prelimi- nary version, vol. 78, no. 110, 1998
1998
-
[38]
Practical secure aggregation for privacy-preserving machine learning,
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” inproceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 1175–1191
2017
-
[39]
A survey of homomorphic encryption for nonspecialists,
C. Fontaine and F. Galand, “A survey of homomorphic encryption for nonspecialists,”EURASIP Journal on Information Security, vol. 2007, pp. 1–10, 2007
2007
-
[40]
Multiparty differential privacy via ag- gregation of locally trained classifiers,
M. Pathak, S. Rane, and B. Raj, “Multiparty differential privacy via ag- gregation of locally trained classifiers,”Advances in neural information processing systems, vol. 23, 2010
2010
-
[41]
Privacy-preserving deep learning via additively homomorphic encryption,
Y . Aono, T. Hayashi, L. Wang, S. Moriaiet al., “Privacy-preserving deep learning via additively homomorphic encryption,”IEEE Transactions on Information Forensics and Security, vol. 13, no. 5, pp. 1333–1345, 2017
2017
-
[42]
Privlava: synthesizing relational data with foreign keys under differential privacy,
K. Cai, X. Xiao, and G. Cormode, “Privlava: synthesizing relational data with foreign keys under differential privacy,”Proceedings of the ACM on Management of Data, vol. 1, no. 2, pp. 1–25, 2023
2023
-
[43]
Better than composition: How to answer multiple relational queries under differential privacy,
W. Dong, D. Sun, and K. Yi, “Better than composition: How to answer multiple relational queries under differential privacy,”Proceedings of the ACM on Management of Data, vol. 1, no. 2, pp. 1–26, 2023
2023
-
[44]
Heda: Multi-attribute unbounded aggregation over homo- morphically encrypted database,
X. Ren, L. Su, Z. Gu, S. Wang, F. Li, Y . Xie, S. Bian, C. Li, and F. Zhang, “Heda: Multi-attribute unbounded aggregation over homo- morphically encrypted database,”Proceedings of the VLDB Endowment, vol. 16, no. 4, pp. 601–614, 2022
2022
-
[45]
Toward efficient homo- morphic encryption for outsourced databases through parallel caching,
O. T. Tawose, J. Dai, L. Yang, and D. Zhao, “Toward efficient homo- morphic encryption for outsourced databases through parallel caching,” Proceedings of the ACM on Management of Data, vol. 1, no. 1, pp. 1–23, 2023
2023
-
[46]
Batchcrypt: Efficient homomorphic encryption for cross-silo federated learning,
C. Zhang, S. Li, J. Xia, W. Wang, F. Yan, and Y . Liu, “Batchcrypt: Efficient homomorphic encryption for cross-silo federated learning,” inProceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC 2020), 2020
2020
-
[47]
Towards federated bayesian network structure learning with continuous optimization,
I. Ng and K. Zhang, “Towards federated bayesian network structure learning with continuous optimization,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2022, pp. 8095–8111
2022
-
[48]
Towards privacy- aware causal structure learning in federated setting,
J. Huang, K. Yu, X. Guo, F. Cao, and J. Liang, “Towards privacy- aware causal structure learning in federated setting,”arXiv preprint arXiv:2211.06919, 2022. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.