Activation-Based Active Learning for In-Context Learning: Challenges and Insights
Pith reviewed 2026-06-28 06:25 UTC · model grok-4.3
The pith
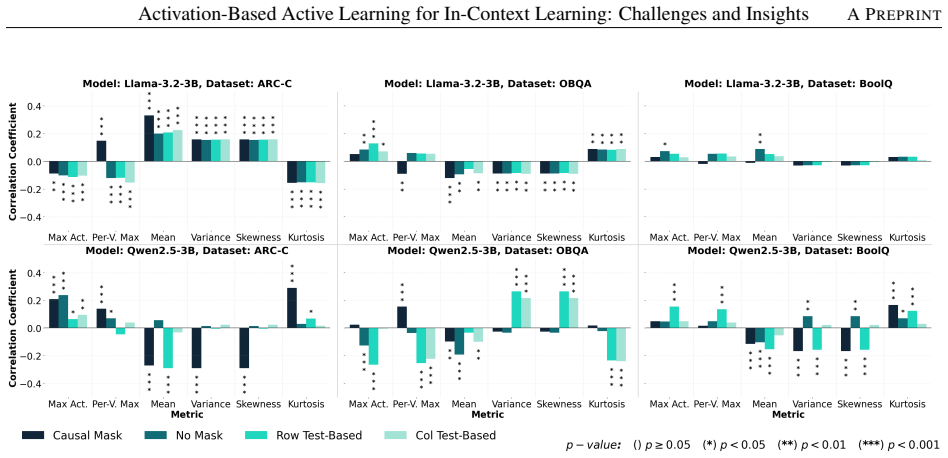
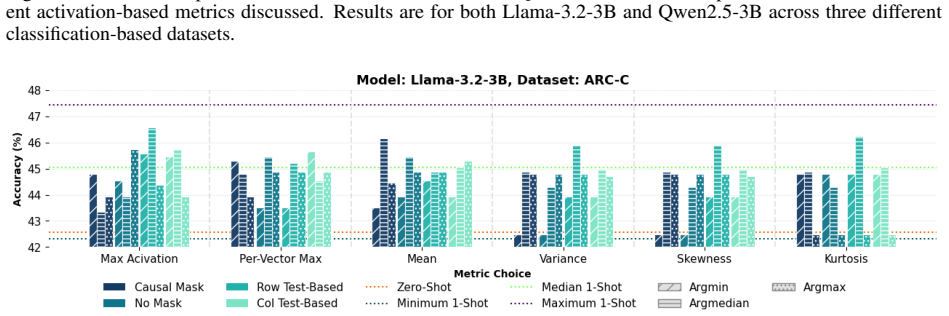
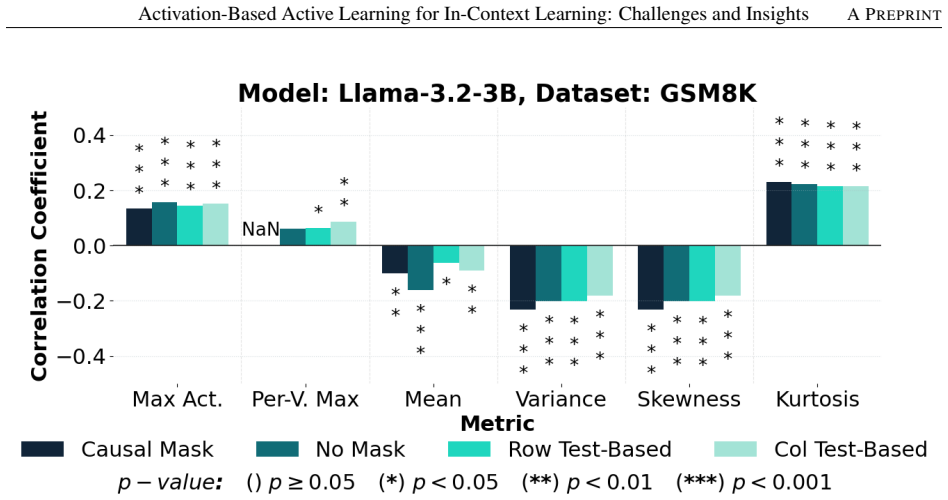
MLP activation statistics show at most 0.33 Spearman correlation with in-context example quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MLP outputs, viewed through the lenses of massive activations or the first four moments, do not correlate with example quality or task performance. Specifically, the absolute Spearman correlation coefficient is at most 0.33 for all tasks and models tested, showing that such activation-based sampling should not be used for in-context learning. The authors hypothesise that superposition may explain the absence of signal and suggest sparse autoencoders as a possible next step.
What carries the argument
Massive activations and the first four moments computed from MLP layer outputs, used as candidate scores for ranking candidate in-context examples during active learning.
If this is right
- Activation-based sampling that relies on massive activations or statistical moments should not be applied to in-context example selection.
- The lack of correlation persists across classification and generative tasks and across different attention masking strategies.
- The same negative outcome appears for both the Llama-3.2-3B and Qwen2.5-3B base models.
- Methods that disentangle features, such as sparse autoencoders, become a logical direction for future activation-based active learning.
Where Pith is reading between the lines
- If a different decomposition of the same MLP activations were used, a stronger correlation with example quality might appear.
- Active learning for in-context learning may need to rely on signals other than raw activation statistics, such as uncertainty or diversity measures.
- The finding raises the possibility that superposition is a general obstacle to activation-based selection across current transformer designs.
Load-bearing premise
The chosen statistics of massive activations and first four moments are sufficient to detect any useful signal about example quality that exists in the MLP activations.
What would settle it
Finding a Spearman correlation above 0.5 between these same activation statistics and task performance on a held-out model or dataset would falsify the central negative result.
Figures
read the original abstract
Deep active learning has previously been explored for LLM in-context sample selection, but not with methods that utilise recent advances in understanding of transformer activations. In this paper, we test the hypothesis that model activations could provide a fine-grained signal to optimise the selection of in-context examples. We present the most comprehensive analysis to date of MLP activation-based deep active learning methods applied to in-context learning, including how different attention masking strategies impact active learning across diverse classification and generative datasets, using both Llama-3.2-3B and Qwen2.5-3B base models. However, we find a negative result: MLP outputs, viewed through the lenses of massive activations or the first four moments, do not correlate with example quality or task performance. Specifically, the absolute Spearman correlation coefficient is at most 0.33 for all tasks and models we tested, showing that such activation-based sampling should not be used for in-context learning. We hypothesise that this may be due to superposition, whereby models represent more features than they have dimensionality, suggesting that methods like Sparse Autoencoders (SAEs) may be a promising future direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper tests whether MLP activations can serve as a fine-grained signal for active learning in LLM in-context example selection. Across Llama-3.2-3B and Qwen2.5-3B on diverse classification and generative tasks, with varying attention masking, the authors compute Spearman correlations between two views of MLP outputs (massive activations and the first four moments) and measures of example quality or downstream performance, reporting a maximum absolute correlation of 0.33. They conclude that activation-based sampling should not be used and hypothesize that superposition may explain the lack of signal, proposing SAEs as a future direction.
Significance. If the reported correlations are robust, the negative empirical result is a useful contribution to deep active learning for in-context learning: it supplies concrete evidence that simple activation statistics are unlikely to identify high-quality examples and supplies an explicit hypothesis (superposition) together with a concrete next step (SAEs). The breadth of the experimental design—two base models, multiple task types, and explicit attention-masking variants—is a clear strength that increases the reliability of the null finding.
major comments (1)
- [Abstract] Abstract: the statement that 'such activation-based sampling should not be used for in-context learning' is load-bearing for the paper's central recommendation, yet it is derived only from the two tested lenses (massive activations and first four moments). The paper's own superposition hypothesis implies that other representations of the same MLP activations could still carry usable signal; therefore the recommendation should be scoped explicitly to the statistics examined rather than to activation-based methods in general.
minor comments (2)
- [Methods] Methods: supply the precise algorithmic definitions and any hyperparameters (thresholds, normalization, masking implementation) used to extract massive activations and the four moments so that the correlation computations can be reproduced.
- [Results] Results: report p-values or confidence intervals alongside the Spearman coefficients to allow readers to judge whether the observed |ρ| ≤ 0.33 values are statistically distinguishable from zero or from a practically meaningful threshold.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the abstract's recommendation should be scoped more precisely to the activation statistics tested, and we will make this revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'such activation-based sampling should not be used for in-context learning' is load-bearing for the paper's central recommendation, yet it is derived only from the two tested lenses (massive activations and first four moments). The paper's own superposition hypothesis implies that other representations of the same MLP activations could still carry usable signal; therefore the recommendation should be scoped explicitly to the statistics examined rather than to activation-based methods in general.
Authors: We agree with this observation. Our negative result applies specifically to the two views of MLP activations examined (massive activations and the first four moments), and the superposition hypothesis we advance does leave open the possibility that alternative representations of the same activations could yield usable signal. We will revise the abstract to state that the tested activation statistics should not be used for in-context learning, rather than activation-based sampling in general. The revised wording will be: 'showing that the activation statistics examined in this work should not be used for in-context learning.' This change will also be reflected in the conclusion section for consistency. revision: yes
Circularity Check
No circularity: direct empirical correlations reported without reduction to fitted inputs or self-citations
full rationale
The paper's central claim rests on computing Spearman rank correlations between two specific views of MLP activations (massive activations and first four moments) and task performance/example quality across models and datasets. These are straightforward statistical measurements on held-out data with no equations, fitted parameters, or self-citations that reduce the reported |ρ| ≤ 0.33 result to the inputs by construction. The superposition hypothesis is explicitly labeled as speculation for future work (SAEs) rather than a load-bearing premise. No self-definitional, fitted-input, or uniqueness patterns appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spearman rank correlation is a valid measure of association between activation-derived scalars and downstream task performance
Reference graph
Works this paper leans on
-
[1]
2024 , url=
Parishad BehnamGhader and Vaibhav Adlakha and Marius Mosbach and Dzmitry Bahdanau and Nicolas Chapados and Siva Reddy , booktitle=. 2024 , url=
2024
-
[2]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[3]
Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers , url =
Chen, Shijie and Jimenez Gutierrez, Bernal and Su, Yu , booktitle =. Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers , url =
-
[4]
First Conference on Language Modeling , year=
Massive Activations in Large Language Models , author=. First Conference on Language Modeling , year=
-
[5]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[6]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[7]
doi:10.5281/zenodo.10256836 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[8]
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems , url =
Wang, Alex and Pruksachatkun, Yada and Nangia, Nikita and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel , booktitle =. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems , url =
-
[9]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[10]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[11]
The Thirteenth International Conference on Learning Representations , year=
Repetition Improves Language Model Embeddings , author=. The Thirteenth International Conference on Learning Representations , year=
-
[12]
arXiv preprint arXiv:2512.14982 , year=
Prompt Repetition Improves Non-Reasoning LLMs , author=. arXiv preprint arXiv:2512.14982 , year=
-
[13]
arXiv preprint arXiv:2505.20195 , year=
Monocle: Hybrid Local-Global In-Context Evaluation for Long-Text Generation with Uncertainty-Based Active Learning , author=. arXiv preprint arXiv:2505.20195 , year=
-
[14]
Man Luo and Xin Xu and Zhuyun Dai and Panupong Pasupat and Mehran Kazemi and Chitta Baral and Vaiva Imbrasaite and Vincent Y Zhao , booktitle=. Dr. 2023 , url=
2023
-
[15]
arXiv preprint arXiv:2310.20046 , year=
Which examples to annotate for in-context learning? towards effective and efficient selection , author=. arXiv preprint arXiv:2310.20046 , year=
-
[16]
arXiv preprint arXiv:2603.27385 , year=
Active In-Context Learning for Tabular Foundation Models , author=. arXiv preprint arXiv:2603.27385 , year=
-
[17]
Workshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025 , year=
Contrastive In-Context Learning with Active Memory for Task Planning , author=. Workshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025 , year=
2025
-
[18]
Malik, Vijit and Pande, Atul and Majumder, Anirban , title =. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages =. 2025 , isbn =. doi:10.1145/3746252.3761536 , abstract =
-
[19]
LTP: A New Active Learning Strategy for CRF-Based Named Entity Recognition , volume =
Mingyi Liu and Zhiying Tu and Tong Zhang and Tonghua Su and Xiaofei Xu and Zhongjie Wang , doi =. LTP: A New Active Learning Strategy for CRF-Based Named Entity Recognition , volume =. Neural Processing Letters , month =
-
[20]
Zhang, Leihan and Zhang, Le , title =. Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence , pages =. 2020 , isbn =. doi:10.1145/3374587.3374611 , abstract =
-
[21]
Shelmanov, Artem and Liventsev, Vadim and Kireev, Danil and Khromov, Nikita and Panchenko, Alexander and Fedulova, Irina and Dylov, Dmitry V. , booktitle=. Active Learning with Deep Pre-trained Models for Sequence Tagging of Clinical and Biomedical Texts , year=. doi:10.1109/BIBM47256.2019.8983157 , ISSN=
-
[22]
Active Learning Literature Survey , Type =
Burr Settles , Institution =. Active Learning Literature Survey , Type =
-
[23]
2001 , booktitle =
Tong, Simon , pages =. 2001 , booktitle =
2001
-
[24]
Active Learning with Statistical Models , url =
Cohn, David and Ghahramani, Zoubin and Jordan, Michael , booktitle =. Active Learning with Statistical Models , url =
-
[25]
Proceedings of the 40th International Conference on Machine Learning , pages =
Compositional Exemplars for In-context Learning , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[26]
arXiv preprint arXiv:2506.01115 , year=
Is Random Attention Sufficient for Sequence Modeling? Disentangling Trainable Components in the Transformer , author=. arXiv preprint arXiv:2506.01115 , year=
-
[27]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[28]
Alignment Forum , volume=
Fact finding: Attempting to reverse-engineer factual recall on the neuron level , author=. Alignment Forum , volume=
-
[29]
and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
-
[30]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[31]
arXiv preprint arXiv:2407.10671 , year=
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
-
[32]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[33]
arXiv preprint arXiv:2508.09199 , year=
-AttnMask: Attention-Guided Masked Hidden States for Efficient Data Selection and Augmentation , author=. arXiv preprint arXiv:2508.09199 , year=
-
[34]
On the Role of Attention Masks and LayerNorm in Transformers , url =
Wu, Xinyi and Ajorlou, Amir and Wang, Yifei and Jegelka, Stefanie and Jadbabaie, Ali , booktitle =. On the Role of Attention Masks and LayerNorm in Transformers , url =. doi:10.52202/079017-0472 , editor =
-
[35]
Swietojanski, Pawel and Braun, Stefan and Can, Dogan and Da Silva, Thiago Fraga and Ghoshal, Arnab and Hori, Takaaki and Hsiao, Roger and Mason, Henry and McDermott, Erik and Silovsky, Honza and Travadi, Ruchir and Zhuang, Xiaodan , booktitle=. Variable Attention Masking for Configurable Transformer Transducer Speech Recognition , year=. doi:10.1109/ICASS...
-
[36]
Transformers need glasses! Information over-squashing in language tasks , url =
Barbero, Federico and Banino, Andrea and Kapturowski, Steven and Kumaran, Dharshan and Ara\'. Transformers need glasses! Information over-squashing in language tasks , url =. Advances in Neural Information Processing Systems , doi =
-
[37]
Federico Barbero and Alvaro Arroyo and Xiangming Gu and Christos Perivolaropoulos and Petar Veli. Why do. Second Conference on Language Modeling , year=
-
[38]
Look Both Ways and No Sink: Converting LLM s into Text Encoders without Training
Lin, Ziyong and Wu, Haoyi and Wang, Shu and Tu, Kewei and Zheng, Zilong and Jia, Zixia. Look Both Ways and No Sink: Converting LLM s into Text Encoders without Training. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1113
-
[39]
Active Learning Principles for In-Context Learning with Large Language Models
Margatina, Katerina and Schick, Timo and Aletras, Nikolaos and Dwivedi-Yu, Jane. Active Learning Principles for In-Context Learning with Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.334
-
[40]
What Makes Good In-Context Examples for GPT -3?
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu. What Makes Good In-Context Examples for GPT -3?. Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures. 2022. doi:10.18653/v1/2022.deelio-1.10
-
[41]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina. B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[42]
Mihaylov, Todor and Clark, Peter and Khot, Tushar and Sabharwal, Ashish. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1260
-
[43]
M onte C arlo Sampling for Analyzing In-Context Examples
Schoch, Stephanie and Ji, Yangfeng. M onte C arlo Sampling for Analyzing In-Context Examples. The Sixth Workshop on Insights from Negative Results in NLP. 2025. doi:10.18653/v1/2025.insights-1.7
-
[44]
Active Example Selection for In-Context Learning
Zhang, Yiming and Feng, Shi and Tan, Chenhao. Active Example Selection for In-Context Learning. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.622
-
[45]
Finding Support Examples for In-Context Learning
Li, Xiaonan and Qiu, Xipeng. Finding Support Examples for In-Context Learning. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.411
-
[46]
A ctive L earning for BERT : A n E mpirical S tudy
Ein-Dor, Liat and Halfon, Alon and Gera, Ariel and Shnarch, Eyal and Dankin, Lena and Choshen, Leshem and Danilevsky, Marina and Aharonov, Ranit and Katz, Yoav and Slonim, Noam. A ctive L earning for BERT : A n E mpirical S tudy. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnl...
-
[47]
A ctive LLM : Large Language Model-Based Active Learning for Textual Few-Shot Scenarios
Bayer, Markus and Lutz, Justin and Reuter, Christian. A ctive LLM : Large Language Model-Based Active Learning for Textual Few-Shot Scenarios. Transactions of the Association for Computational Linguistics. 2026. doi:10.1162/tacl.a.63
-
[48]
Learning To Retrieve Prompts for In-Context Learning
Rubin, Ohad and Herzig, Jonathan and Berant, Jonathan. Learning To Retrieve Prompts for In-Context Learning. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.191
-
[49]
Wu, Zhiyong and Wang, Yaoxiang and Ye, Jiacheng and Kong, Lingpeng. Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.79
-
[50]
Yao, Bingsheng and Chen, Guiming and Zou, Ruishi and Lu, Yuxuan and Li, Jiachen and Zhang, Shao and Sang, Yisi and Liu, Sijia and Hendler, James and Wang, Dakuo. More Samples or More Prompts? Exploring Effective Few-Shot In-Context Learning for LLM s with In-Context Sampling. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi...
-
[51]
In-Context Learning with Iterative Demonstration Selection
Qin, Chengwei and Zhang, Aston and Chen, Chen and Dagar, Anirudh and Ye, Wenming. In-Context Learning with Iterative Demonstration Selection. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.438
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.