Gradient Descent with Large Step Size Restores Symmetry in Deep Linear Networks with Multi-Pathway
Pith reviewed 2026-06-28 23:14 UTC · model grok-4.3
The pith
Large-step gradient descent in multi-pathway deep linear networks redistributes signals across paths after initial symmetry breaking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
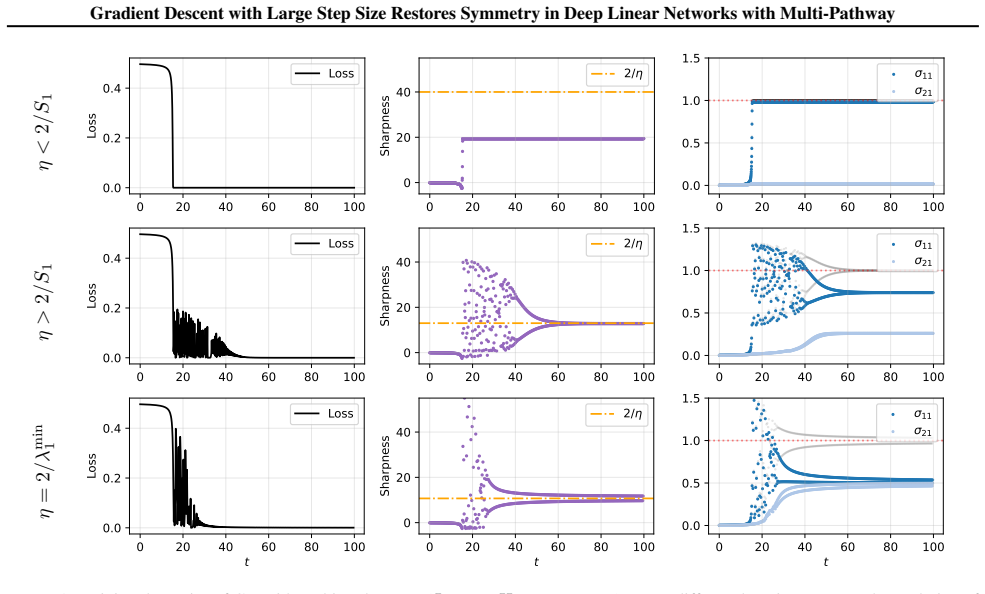
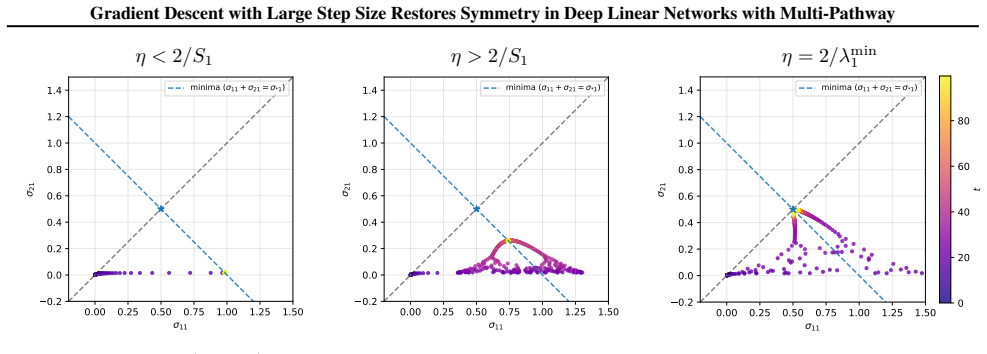
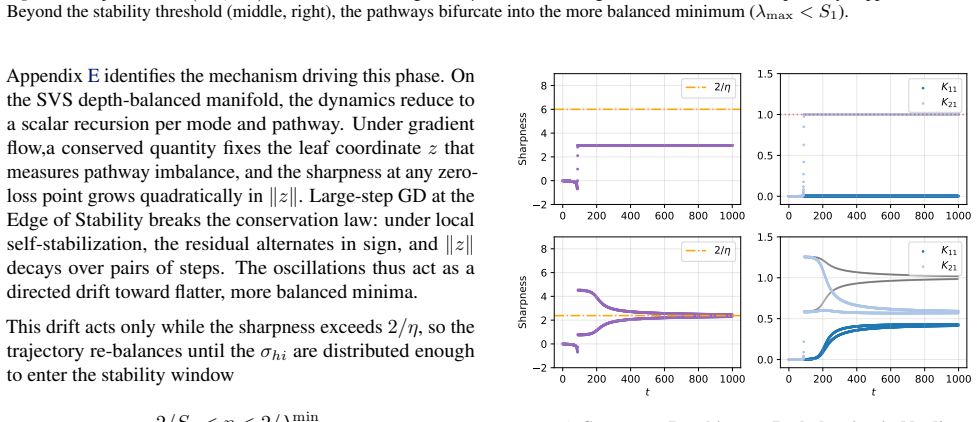
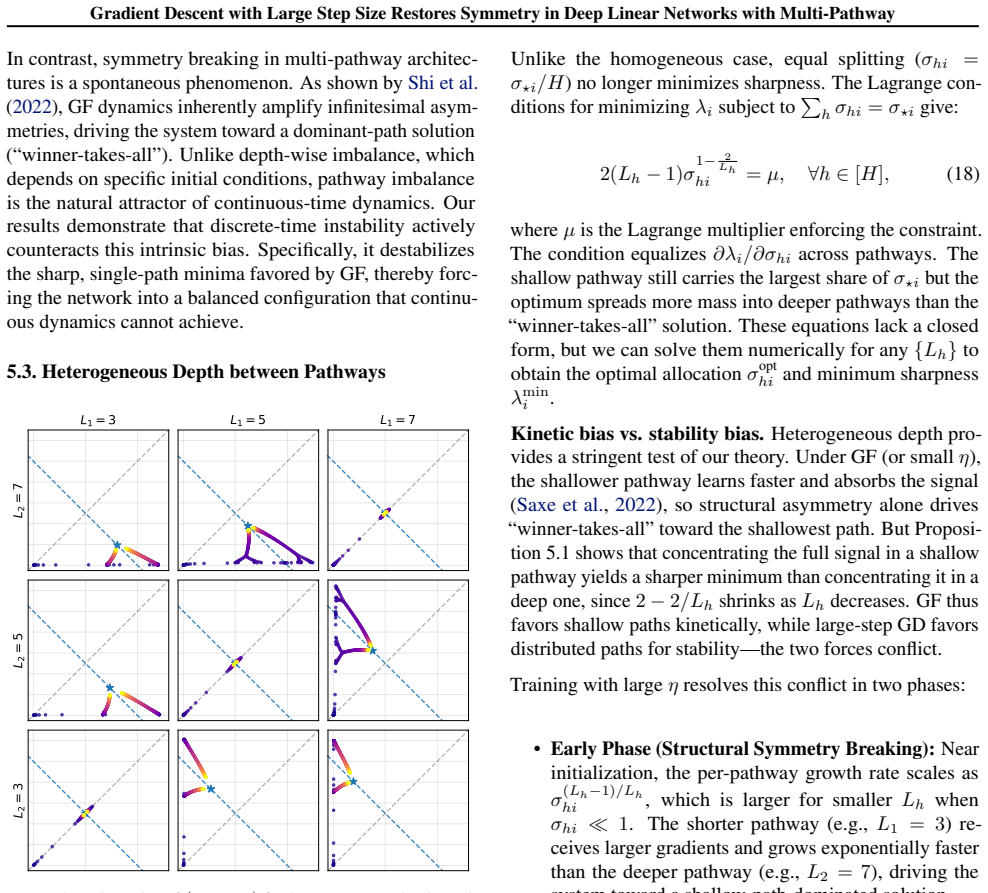
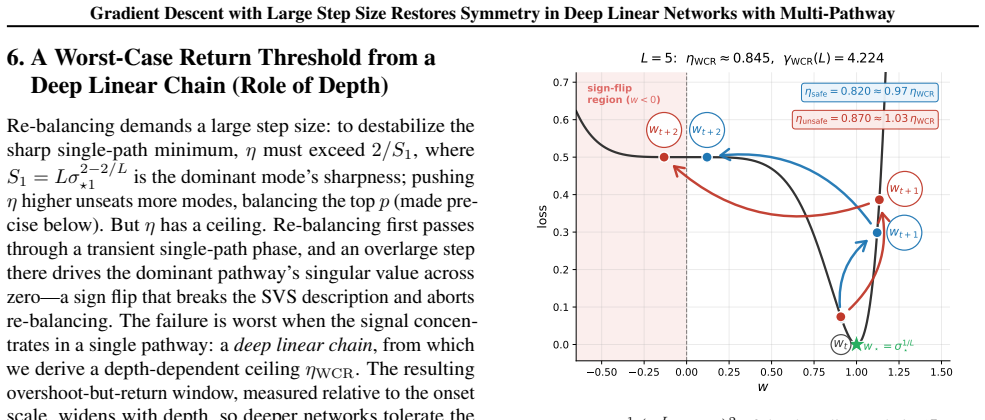
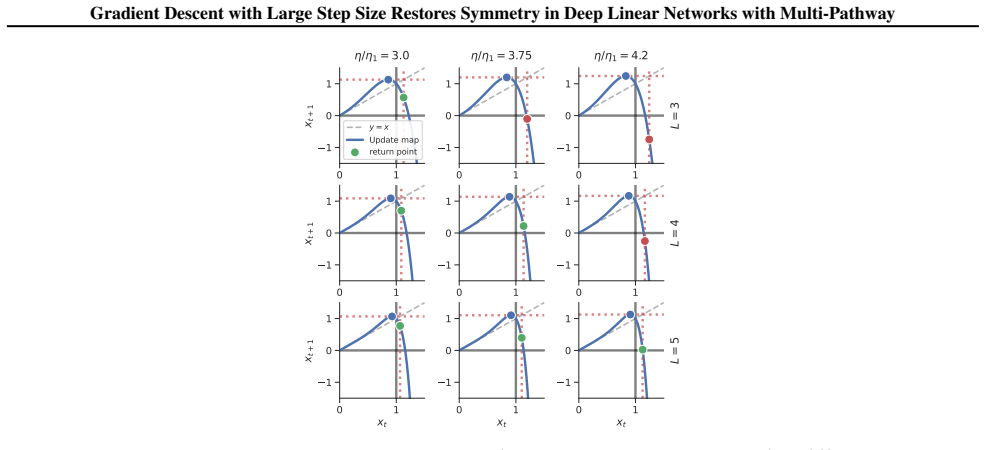
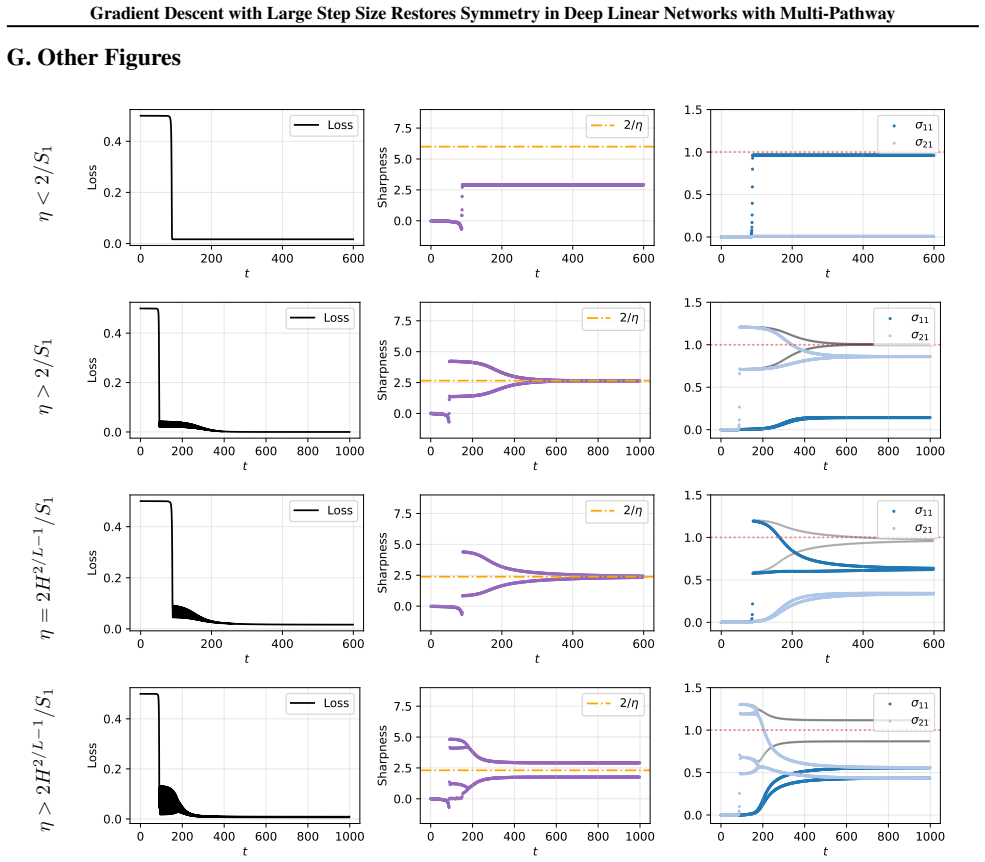
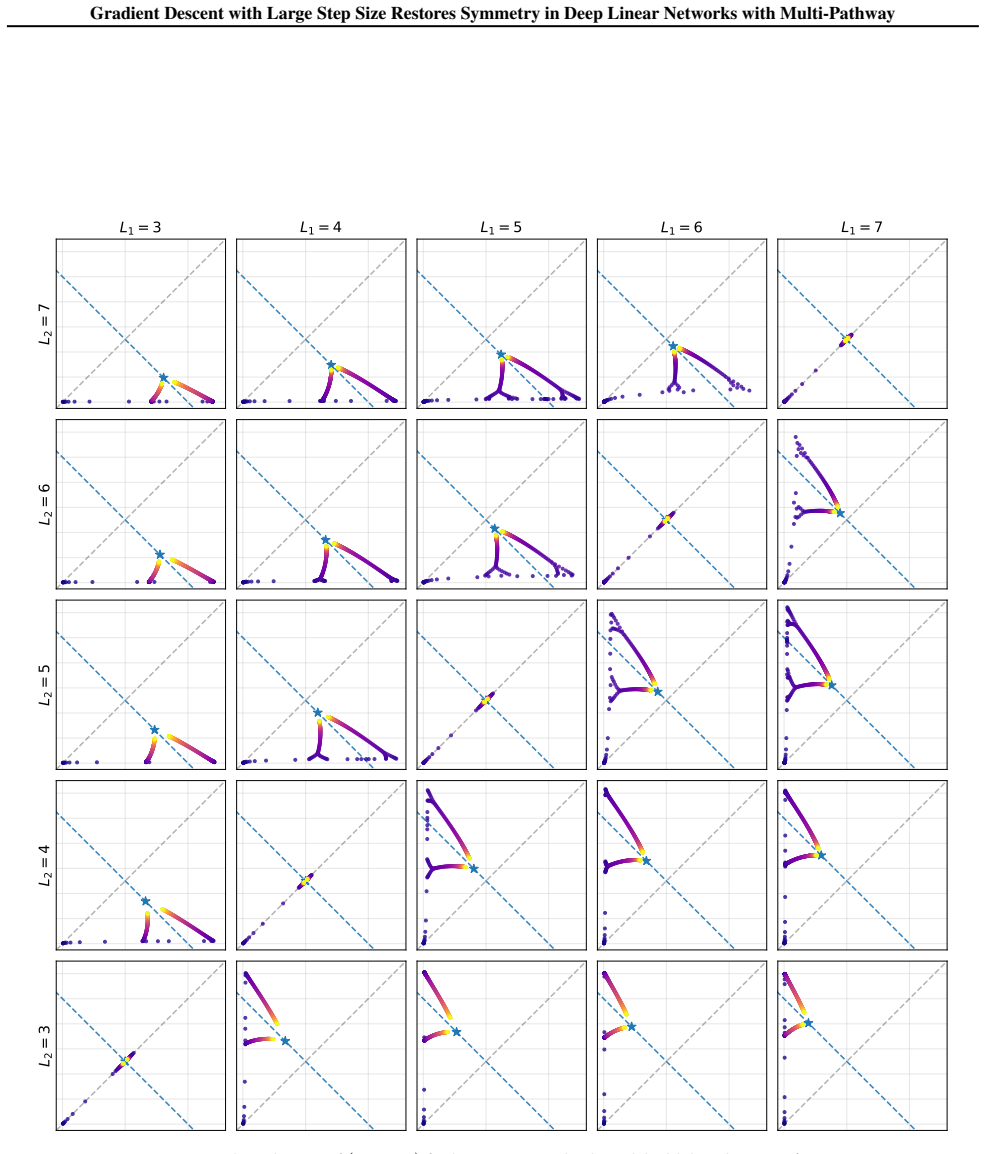
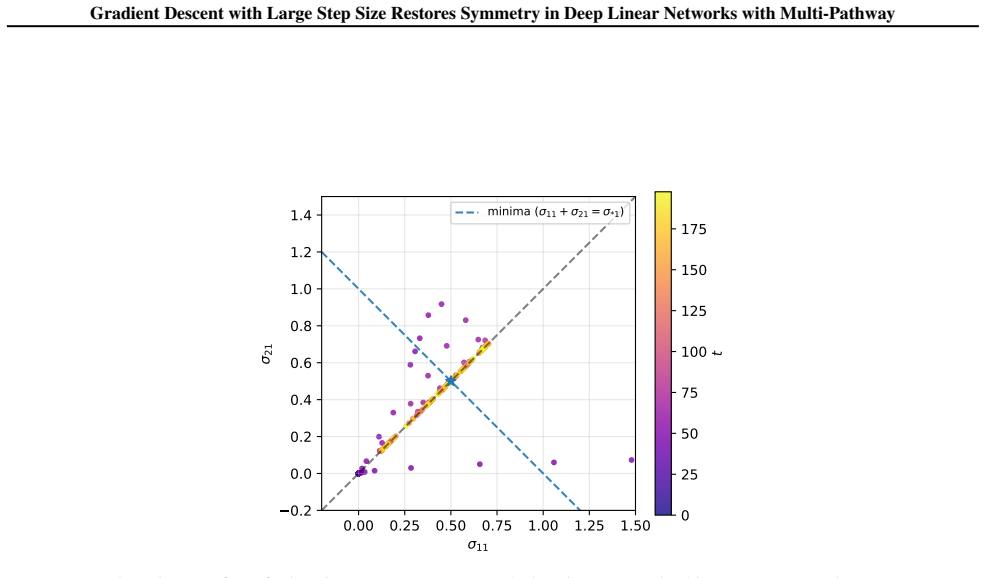
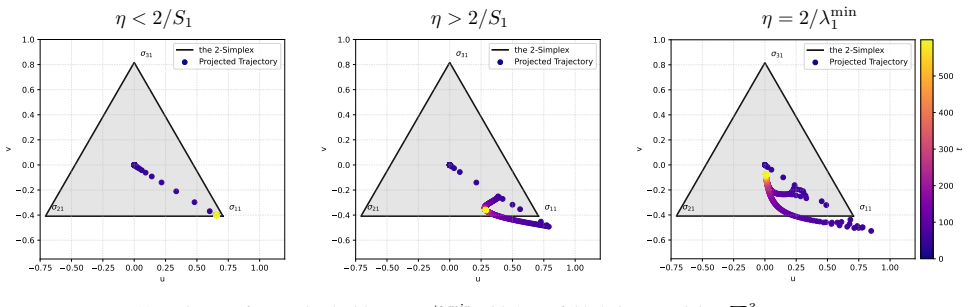
In multi-pathway deep linear networks, single-path solutions are sharp minima while distributing signals across pathways reduces sharpness by a factor that decreases with both the number of pathways and depth. Early training reproduces the depth-driven symmetry breaking predicted by gradient flow, but oscillations at the edge of stability subsequently override this tendency and drive the network into a re-balancing phase where signals redistribute across pathways.
What carries the argument
The sharpness reduction obtained by spreading signals across multiple pathways, which scales with pathway count and depth, combined with the effect of edge-of-stability oscillations on the discrete GD trajectory.
If this is right
- Early training exhibits the depth-driven symmetry breaking seen under gradient flow.
- Edge-of-stability oscillations drive a subsequent re-balancing phase that redistributes signals.
- Large-step GD favors shared representations over single-pathway dominance.
- Depth amplifies the sharpness reduction from multi-path distributions and therefore the strength of re-balancing.
Where Pith is reading between the lines
- The same re-balancing may occur in nonlinear networks that exhibit edge-of-stability behavior under large steps.
- Depth-dependent sharpness reduction offers one concrete reason deeper architectures can sustain distributed representations under practical training.
- The mechanism links sharpness-based accounts of training dynamics to the emergence of shared features rather than specialized pathways.
Load-bearing premise
The analysis assumes that edge-of-stability oscillations and the associated sharpness reduction apply directly to the discrete gradient descent trajectory and that the invoked loss landscape properties hold under standard random initialization.
What would settle it
Training a multi-pathway deep linear network with large-step GD and measuring whether pathway signal norms equalize after the loss begins oscillating at the edge of stability.
Figures
read the original abstract
Recent analyses of multi-pathway Deep Linear Networks use Gradient Flow to predict a "winner-takes-all" specialization in which path symmetry breaks and each feature concentrates in a single pathway. In this work, we show that discrete Gradient Descent (GD) with a large step size tells a different story. We prove that single-path solutions are sharp minima, whereas distributing signals across pathways reduces sharpness by a factor that decreases with both the number of pathways and depth. Consequently, while early training reproduces the depth-driven symmetry breaking predicted by GF, oscillations at the Edge of Stability subsequently override this tendency and drive the network into a re-balancing phase, where signals redistribute across pathways. Together, these results clarify how depth shapes pathway competition and explain why large-step GD favors shared representations rather than persistent single-pathway dominance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines multi-pathway deep linear networks and contrasts gradient flow (GF) predictions of depth-driven symmetry breaking and winner-takes-all specialization with the behavior of discrete gradient descent (GD) using large step sizes. It proves that single-path solutions are sharp minima while distributing signals across pathways reduces sharpness by a factor that decreases with pathway count and depth. Consequently, early GD training reproduces GF-style symmetry breaking, but Edge of Stability (EoS) oscillations later override this and induce a re-balancing phase in which signals redistribute across pathways.
Significance. If the central claims hold, the work clarifies how discretization and large step sizes interact with depth to shape pathway competition, offering an explanation for why practical large-step GD often favors distributed rather than single-path representations. The explicit proofs of the sharpness properties constitute a verifiable landscape analysis and are a clear strength.
major comments (1)
- [Abstract] Abstract (final sentence) and the transition from landscape analysis to dynamics: the claim that EoS oscillations 'override this tendency and drive the network into a re-balancing phase' treats the dynamical consequence as following directly from the sharpness reduction. However, sharpness is a local curvature property at critical points; the manuscript does not appear to supply a derivation or theorem establishing that the discrete large-step GD trajectory necessarily produces net signal redistribution (rather than sustained oscillation without redistribution or trapping). This link is load-bearing for the 'consequently' clause and the overall narrative that large-step GD restores symmetry.
Simulated Author's Rebuttal
We thank the referee for the constructive report on arXiv:2606.05219. The major comment concerns the transition from our landscape results to the claimed dynamical re-balancing under large-step GD. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (final sentence) and the transition from landscape analysis to dynamics: the claim that EoS oscillations 'override this tendency and drive the network into a re-balancing phase' treats the dynamical consequence as following directly from the sharpness reduction. However, sharpness is a local curvature property at critical points; the manuscript does not appear to supply a derivation or theorem establishing that the discrete large-step GD trajectory necessarily produces net signal redistribution (rather than sustained oscillation without redistribution or trapping). This link is load-bearing for the 'consequently' clause and the overall narrative that large-step GD restores symmetry.
Authors: We agree that sharpness is a local property and that a fully rigorous global trajectory theorem would strengthen the narrative. Our contribution establishes that single-path solutions are strictly sharper than multi-path solutions (by a factor that grows with depth and shrinks with pathway count). Standard analyses of the Edge of Stability show that large-step GD cannot converge to sharp minima and instead produces persistent oscillations whose time-averaged effect moves parameters toward flatter regions. Because the flatter regions are precisely the multi-pathway configurations (per our sharpness theorems), the observed re-balancing follows. We support the mechanism with both the landscape theorems and extensive simulations that document the transition from early symmetry breaking to later redistribution. We will add a short clarifying paragraph in the main text and revise the abstract wording to emphasize that the link relies on the combination of our sharpness results with established EoS behavior rather than a new global convergence theorem. revision: partial
Circularity Check
No significant circularity; derivation rests on independent loss-landscape proof
full rationale
The paper's central claims consist of a mathematical proof that single-path solutions are sharp minima while multi-path distributions reduce sharpness (with the reduction factor depending on pathway count and depth), followed by the observation that early GD follows GF symmetry breaking but EoS oscillations later induce re-balancing. No quoted step reduces by construction to a fitted parameter, self-citation, or redefinition of its own inputs; the sharpness analysis is presented as an external property of the loss landscape rather than an ansatz or renamed empirical pattern. The dynamical link to discrete GD is asserted as a consequence but does not exhibit self-definitional or load-bearing self-citation patterns within the provided derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Understanding deep learning requires rethinking generalization , author=. International Conference on Learning Representations , year=
-
[2]
2017 , eprint=
Geometry of Optimization and Implicit Regularization in Deep Learning , author=. 2017 , eprint=
2017
-
[3]
Exploring Generalization in Deep Learning , volume =
Neyshabur, Behnam and Bhojanapalli, Srinadh and Mcallester, David and Srebro, Nati , booktitle =. Exploring Generalization in Deep Learning , volume =
-
[4]
Implicit Regularization in Matrix Factorization , volume =
Gunasekar, Suriya and Woodworth, Blake E and Bhojanapalli, Srinadh and Neyshabur, Behnam and Srebro, Nati , booktitle =. Implicit Regularization in Matrix Factorization , volume =
-
[5]
Journal of Machine Learning Research , year =
Daniel Soudry and Elad Hoffer and Mor Shpigel Nacson and Suriya Gunasekar and Nathan Srebro , title =. Journal of Machine Learning Research , year =
-
[6]
Second-Order Regression Models Exhibit Progressive Sharpening to the Edge of Stability , booktitle =
Agarwala, Atish and Pedregosa, Fabian and Pennington, Jeffrey , year = 2023, pages =. Second-Order Regression Models Exhibit Progressive Sharpening to the Edge of Stability , booktitle =
2023
-
[7]
International Conference on Learning Representations , year =
A Convergence Analysis of Gradient Descent for Deep Linear Neural Networks , author =. International Conference on Learning Representations , year =
-
[8]
Arora, Sanjeev and Cohen, Nadav and Hazan, Elad , year = 2018, pages =. On the. Proceedings of the 35th
2018
-
[9]
Implicit
Arora, Sanjeev and Cohen, Nadav and Hu, Wei and Luo, Yuping , year = 2019, volume =. Implicit. Advances in
2019
-
[10]
Understanding
Arora, Sanjeev and Li, Zhiyuan and Panigrahi, Abhishek , year = 2022, pages =. Understanding. Proceedings of the 39th
2022
-
[11]
Neural Networks and Principal Component Analysis:
Baldi, Pierre and Hornik, Kurt , year = 1989, journal =. Neural Networks and Principal Component Analysis:
1989
-
[12]
Information and Inference: A Journal of the IMA , volume =
Bah, Bubacarr and Rauhut, Holger and Terstiege, Ulrich and Westdickenberg, Michael , title =. Information and Inference: A Journal of the IMA , volume =. 2021 , issn =. doi:10.1093/imaiai/iaaa039 , eprint =
-
[13]
Beyond the
Chen, Lei and Bruna, Joan , year = 2023, pages =. Beyond the. Proceedings of the 40th
2023
-
[14]
Chizat, L. On. Advances in
-
[15]
Gradient Descent for Deep Matrix Factorization:
Chou, Hung-Hsu and Gieshoff, Carsten and Maly, Johannes and Rauhut, Holger , year = 2024, journal =. Gradient Descent for Deep Matrix Factorization:
2024
-
[16]
International Conference on Learning Representations , year =
Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability , author =. International Conference on Learning Representations , year =
-
[17]
The Thirteenth International Conference on Learning Representations , year =
Understanding Optimization in Deep Learning with Central Flows , author =. The Thirteenth International Conference on Learning Representations , year =
-
[18]
The Eleventh International Conference on Learning Representations , year =
Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability , author =. The Eleventh International Conference on Learning Representations , year =
-
[19]
Even, Mathieu and Pesme, Scott and Gunasekar, Suriya and Flammarion, Nicolas , year = 2023, journal =. (
2023
-
[20]
International Conference on Learning Representations , year=
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks , author=. International Conference on Learning Representations , year=
-
[21]
The Thirteenth International Conference on Learning Representations , year =
Learning Dynamics of Deep Matrix Factorization Beyond the Edge of Stability , author =. The Thirteenth International Conference on Learning Representations , year =
-
[22]
Implicit
Gidel, Gauthier and Bach, Francis and. Implicit. Advances in
-
[23]
Exact Learning Dynamics of Deep Linear Networks with Prior Knowledge
J Domin. Exact Learning Dynamics of Deep Linear Networks with Prior Knowledge. Journal of Statistical Mechanics: Theory and Experiment , volume =
-
[24]
Efficient
Kwon, Soo Min and Zhang, Zekai and Song, Dogyoon and Balzano, Laura and Qu, Qing , year = 2024, pages =. Efficient. Proceedings of
2024
-
[25]
Lampinen and Surya Ganguli , title =
Andrew K. Lampinen and Surya Ganguli , title =. 7th International Conference on Learning Representations,. 2019 , url =
2019
-
[26]
arXiv preprint arXiv:2003.02218 , year=
Lewkowycz, Aitor and Bahri, Yasaman and Dyer, Ethan and. The Large Learning Rate Phase of Deep Learning: The Catapult Mechanism , shorttitle =. doi:10.48550/arXiv.2003.02218 , archiveprefix =. 2003.02218 , primaryclass =
-
[27]
Understanding the
Lyu, Kaifeng and Li, Zhiyuan and Arora, Sanjeev , year = 2022, journal =. Understanding the
2022
-
[28]
Abide by the Law and Follow the Flow: Conservation Laws for Gradient Flows , shorttitle =
Marcotte, Sibylle and Gribonval, Remi and Peyr. Abide by the Law and Follow the Flow: Conservation Laws for Gradient Flows , shorttitle =. Advances in Neural Information Processing Systems , volume =
-
[29]
Advances in Neural Information Processing Systems , volume =
Deep Linear Networks for Regression Are Implicitly Regularized towards Flat Minima , author =. Advances in Neural Information Processing Systems , volume =
-
[30]
Position:
Nam, Yoonsoo and Lee, Seok Hyeong and Domin. Position:. Proceedings of the 42nd
-
[31]
Advances in Neural Information Processing Systems , author =
Algorithmic Regularization in Learning Deep Homogeneous Models:. Advances in Neural Information Processing Systems , author =
-
[32]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks , author =. doi:10.48550/arXiv.1312.6120 , archiveprefix =. 1312.6120 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1312.6120
-
[33]
Proceedings of the National Academy of Sciences , volume =
A Mathematical Theory of Semantic Development in Deep Neural Networks , author =. Proceedings of the National Academy of Sciences , volume =
-
[34]
The Neural Race Reduction: Dynamics of Abstraction in Gated Networks , shorttitle =
Saxe, Andrew and Sodhani, Shagun and Lewallen, Sam Jay , year = 2022, pages =. The Neural Race Reduction: Dynamics of Abstraction in Gated Networks , shorttitle =. Proceedings of the 39th
2022
-
[35]
Learning dynamics of deep linear networks with multiple pathways , volume =
Shi, Jianghong and Shea-Brown, Eric and Buice, Michael , booktitle =. Learning dynamics of deep linear networks with multiple pathways , volume =
-
[36]
Advances in Neural Information Processing Systems , volume =
On the Spectral Bias of Two-Layer Linear Networks , author =. Advances in Neural Information Processing Systems , volume =
-
[37]
Analyzing
Wang, Zixuan and Li, Zhouzi and Li, Jian , year = 2022, journal =. Analyzing
2022
-
[38]
Wu, Lei and Ma, Chao and E, Weinan , year = 2018, volume =. How. Advances in
2018
-
[39]
Xing, Chen and Arpit, Devansh and Tsirigotis, Christos and Bengio, Yoshua , year = 2018, number =. A. doi:10.48550/arXiv.1802.08770 , archiveprefix =. 1802.08770 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.08770 2018
-
[40]
Yoo, Geonhui and Song, Minhak and Yun, Chulhee , year = 2025, number =. Understanding. doi:10.48550/arXiv.2506.06940 , archiveprefix =. 2506.06940 , primaryclass =
-
[41]
Zhang, Yedi and Singh, Aaditya K. and Latham, Peter E. and Saxe, Andrew , year = 2025, number =. Training. doi:10.48550/arXiv.2501.16265 , archiveprefix =. 2501.16265 , primaryclass =
-
[42]
The Eleventh International Conference on Learning Representations , year =
Understanding Edge-of-Stability Training Dynamics with a Minimalist Example , author =. The Eleventh International Conference on Learning Representations , year =
-
[43]
Catapults in
Zhu, Libin and Liu, Chaoyue and Radhakrishnan, Adityanarayanan and Belkin, Mikhail , year = 2024, pages =. Catapults in. Proceedings of the 41st
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.