Towards Persistent Case-Based Memory for Autonomous Data Science: A CBR-Augmented R&D-Agent with a Locally Deployable Small Language Model
Pith reviewed 2026-06-28 05:16 UTC · model grok-4.3
The pith
CBR layer added to R&D agent with local SLM yields directional accuracy gains and lower variance on Kaggle tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
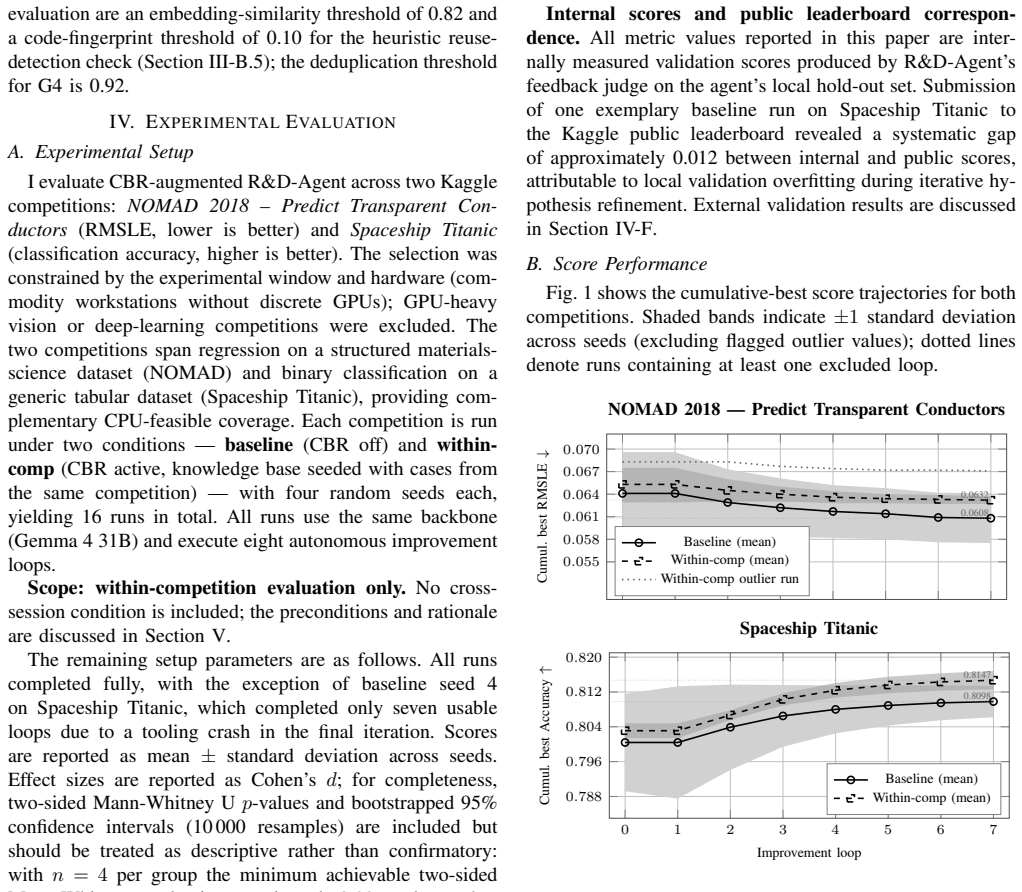
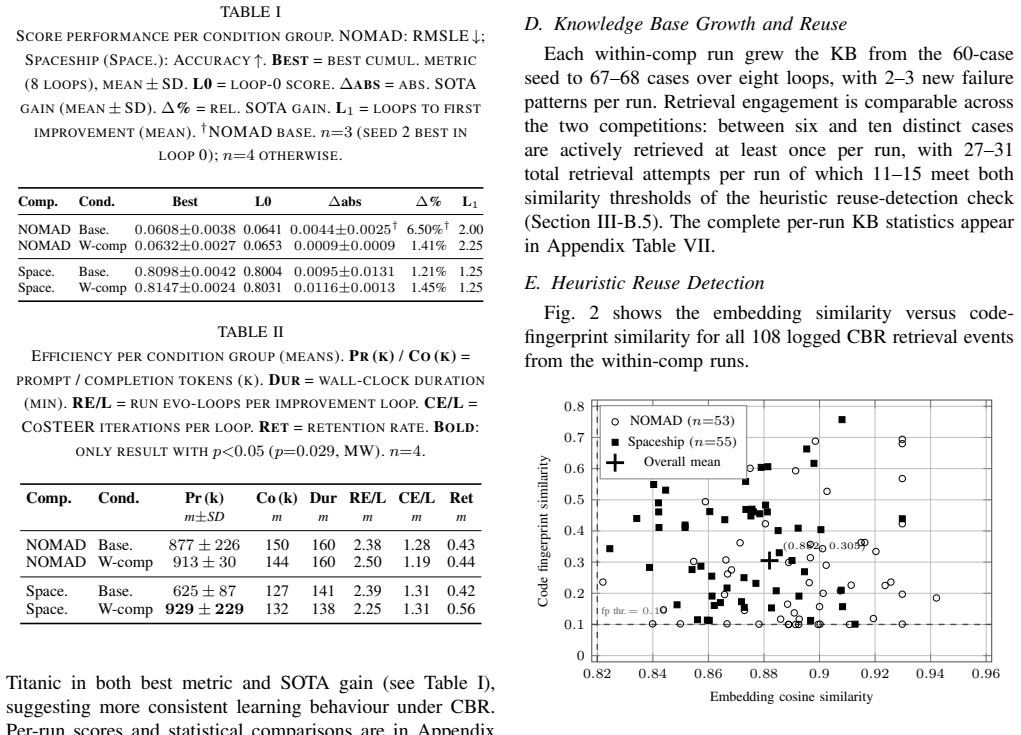
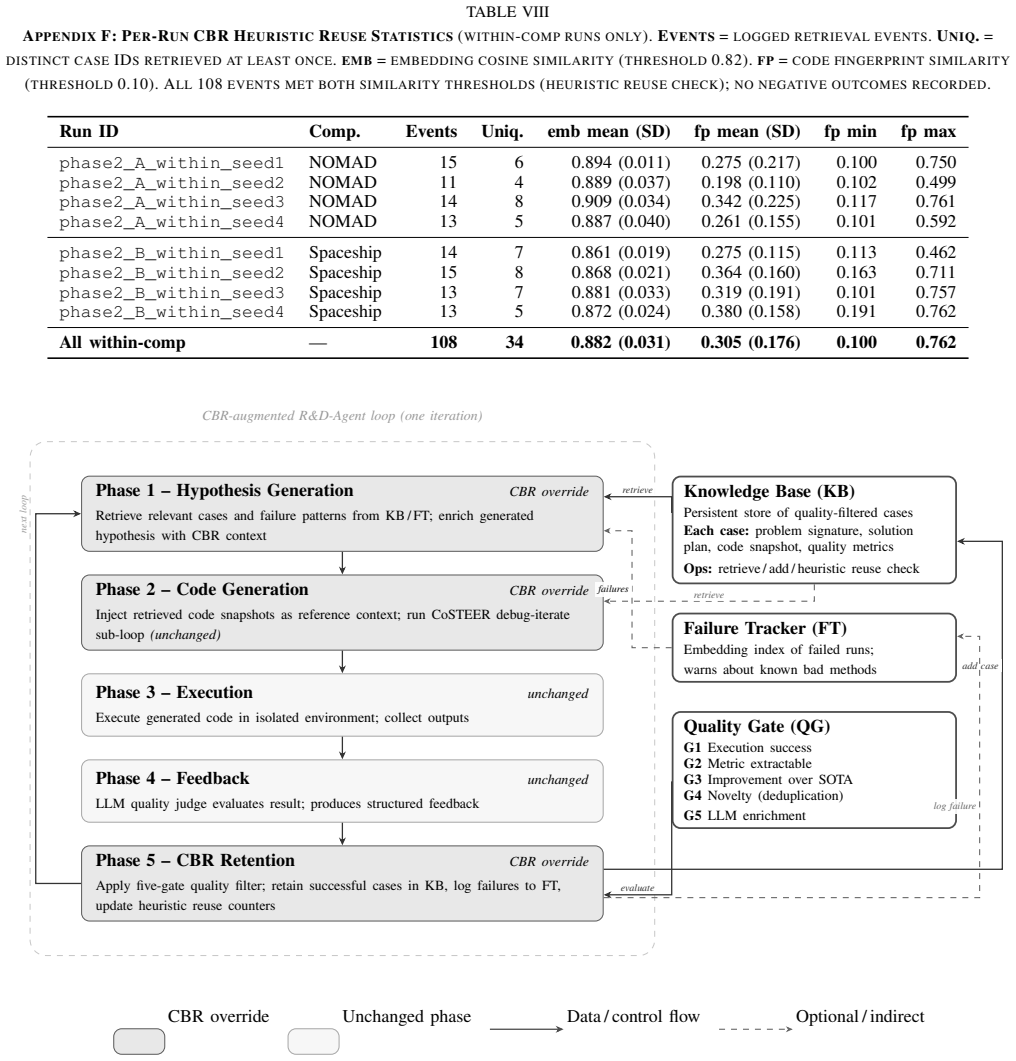
Overriding three phases of the R&D loop with a CBR layer that stores structured cases containing executable code snapshots and quality metadata, then retrieves them via a five-gate filter and reuse-detection heuristic combining embedding similarity (mean 0.882) and code-fingerprint overlap (mean 0.305), produces directionally higher accuracy and markedly lower variance than the CBR-disabled baseline on the Spaceship Titanic task.
What carries the argument
The CBR layer, implemented as a surgical subclass toggled by an environment variable, that stores cases as structured records with executable code and quality metadata and retrieves them through a five-gate quality filter and heuristic reuse detection using embedding similarity plus code-fingerprint overlap.
If this is right
- Persistent, quality-controlled case memory can be added to existing agent frameworks without replacing the core loop.
- Small language models such as Gemma 4 31B can function as locally deployable backbones for full autonomous data-science pipelines.
- Heuristic reuse detection supports conceptual guidance from prior cases rather than verbatim code reuse.
- Lower variance across random seeds indicates more stable improvement trajectories when CBR memory is active.
Where Pith is reading between the lines
- The same CBR pattern could be ported to other agent scaffolds that lack native long-term memory.
- Variable code-fingerprint similarity alongside high embedding similarity points to a hybrid symbolic-neural memory design that may generalize beyond the current tasks.
- Testing the five-gate filter on tasks with noisier or less structured code artefacts would clarify the limits of the current reuse heuristic.
Load-bearing premise
The five-gate quality filter and heuristic reuse-detection mechanism correctly identify transferable knowledge without introducing selection bias or false positives that inflate apparent gains.
What would settle it
Re-running the eight-loop evaluation on Spaceship Titanic with the reuse-detection heuristic disabled or replaced by random retrieval and finding that the accuracy gap and variance reduction both disappear.
Figures
read the original abstract
Most top-performing autonomous data-science agents rely on frontier cloud models and lack persistent, cross-session memory. This paper addresses two open gaps: (1) the underexplored use of formally structured, quality-controlled Case-Based Reasoning (CBR) case bases coupling symbolic case records with executable code artefacts; and (2) the untested viability of Small Language Models (SLMs) as locally deployable agent backbones. We present CBR-augmented R&D-Agent, integrating a persistent CBR layer into Microsoft's R&D-Agent framework with a custom backend for Gemma 4 31B Dense -- the first published end-to-end evaluation of Gemma 4 as an autonomous data-science agent backbone. The CBR layer overrides three R&D loop phases via a surgical subclass toggled by a single environment variable. Cases are stored as structured records with executable code snapshots and quality metadata; a five-gate quality filter and a heuristic reuse-detection mechanism assess knowledge transfer by combining embedding similarity, code-fingerprint overlap, and injection provenance. Evaluated on two Kaggle competitions (NOMAD 2018, Spaceship Titanic) with four seeds over eight improvement loops each, CBR achieves directionally higher accuracy than the CBR-disabled baseline on Spaceship Titanic (0.8147 vs. 0.8098, d = -1.41) with substantially lower variance. Heuristic reuse detection across 108 retrieval events shows high semantic relevance (mean embedding similarity 0.882) alongside variable structural proximity (mean code-fingerprint similarity 0.305), consistent with conceptual guidance rather than verbatim code copying.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a CBR-augmented R&D-Agent that integrates a persistent, structured Case-Based Reasoning layer (with quality-controlled case records coupling symbolic metadata and executable code) into Microsoft's R&D-Agent framework. It uses Gemma 4 31B Dense as the locally deployable SLM backbone and evaluates the system on two Kaggle competitions (NOMAD 2018 and Spaceship Titanic) across eight improvement loops with four random seeds. The central claim is that the CBR layer produces directionally higher accuracy (0.8147 vs. 0.8098) and substantially lower variance on Spaceship Titanic, with supporting analysis of 108 retrieval events showing high embedding similarity but variable code-fingerprint overlap.
Significance. If the reported accuracy and variance improvements can be substantiated with adequate statistical controls and larger sample sizes, the work would demonstrate a practical route to persistent, cross-session memory in autonomous data-science agents while using only locally deployable small models. The five-gate quality filter and combined embedding-plus-fingerprint reuse heuristic constitute a concrete, inspectable mechanism for controlled knowledge transfer that could be adopted or extended by other agent frameworks.
major comments (2)
- [Abstract] Abstract: The central empirical claim of directional superiority plus lower variance rests on only four random seeds. No per-seed accuracy values, standard deviations, p-values, bootstrap confidence intervals, or hypothesis tests are reported, so it is impossible to determine whether the 0.49 pp difference (or the cited d = -1.41) exceeds what would be expected from seed-to-seed fluctuation under an otherwise identical agent.
- [Abstract] Abstract: The effect size d = -1.41 is stated without definition, formula, or reference to the underlying per-seed data; this prevents verification of the sign, magnitude, or appropriateness of the statistic for the variance comparison.
minor comments (1)
- [Abstract] Abstract: The phrase 'Gemma 4 31B Dense' should be clarified with the exact model identifier or citation, as it is not a standard public release name.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying gaps in the statistical reporting of the abstract. We address each major comment below and will revise the manuscript to improve transparency and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of directional superiority plus lower variance rests on only four random seeds. No per-seed accuracy values, standard deviations, p-values, bootstrap confidence intervals, or hypothesis tests are reported, so it is impossible to determine whether the 0.49 pp difference (or the cited d = -1.41) exceeds what would be expected from seed-to-seed fluctuation under an otherwise identical agent.
Authors: We agree that four seeds constitute a small sample and that aggregate means alone do not permit readers to judge whether the 0.49 pp difference exceeds typical seed-to-seed fluctuation. In the revised manuscript we will add a table or explicit listing of the four per-seed accuracies for both the CBR-augmented and baseline conditions on Spaceship Titanic, report the standard deviation across seeds, and include the result of an appropriate paired test (e.g., Wilcoxon signed-rank) together with its p-value and a bootstrap confidence interval. These additions will be placed in both the abstract and a new short results subsection. revision: yes
-
Referee: [Abstract] Abstract: The effect size d = -1.41 is stated without definition, formula, or reference to the underlying per-seed data; this prevents verification of the sign, magnitude, or appropriateness of the statistic for the variance comparison.
Authors: We will insert an explicit definition of the reported effect size, the formula employed, and the per-seed values used in its calculation. The revised text will also clarify whether the statistic is intended to quantify the accuracy difference or the variance reduction and will cite the standard reference for the chosen effect-size measure. revision: yes
Circularity Check
No circularity; empirical ablation is direct and self-contained
full rationale
The paper reports a straightforward empirical comparison of CBR-enabled versus CBR-disabled runs of the same R&D-Agent on identical Kaggle tasks (NOMAD 2018, Spaceship Titanic) across four seeds. No equations, derivations, or predictions are presented that reduce reported accuracies (0.8147 vs 0.8098) to fitted parameters defined by the authors. The five-gate filter and reuse-detection mechanism are described as implementation details whose correctness is evaluated externally via observed similarities, not assumed by construction. No self-citation chains or uniqueness theorems are invoked to justify the central claim. The evaluation is therefore independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Small language models such as Gemma 4 31B can serve as viable backbones for autonomous data-science agents
- domain assumption Structured case records with executable code and quality metadata can be reused across sessions via embedding and fingerprint similarity
Reference graph
Works this paper leans on
-
[1]
AIDE: AI-Driven Exploration in the Space of Code
Z. Jiang, D. Schmidt, D. Srikanth, D. Xu, I. Kaplan, D. Jacenko, and Y . Wu, “AIDE: AI-driven exploration in the space of code,”arXiv preprint arXiv:2502.13138, 2025. [Online]. Available: https://arxiv.org/abs/2502.13138
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
MARS: Modular Agent with Reflective Search for Automated AI Research
J. Chen, B. Dalvi Mishra, J. Nam, R. Meng, T. Pfister, and J. Yoon, “MARS: Modular agent with reflective search for automated AI research,” inProceedings of the 43rd International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research. PMLR, 2026, to appear; proceedings not yet published at time of writing. [Online]. Availabl...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Large language models orchestrating structured reasoning achieve kaggle grandmaster level
A. Grosnit, A. Maraval, Refinath S N, Z. Zhao, J. Doran, G. Paolo, A. Thomas, J. Gonzalez, A. Kumar, K. Khandelwal, A. Benechehab, H. Cherkaoui, Y . Attia El-Hili, K. Shao, J. Hao, J. Yao, B. Kégl, H. Bou-Ammar, and J. Wang, “Kolb-based experiential learning for generalist agents with human-level Kaggle data science performance,”arXiv preprint arXiv:2411....
-
[4]
R&D-Agent: An LLM-Agent Framework Towards Autonomous Data Science
X. Yang, X. Yang, S. Fang, B. Xian, Y . Li, J. Wang, M. Xu, H. Pan, X. Hong, W. Liu, Y . Shen, W. Chen, and J. Bian, “R&D-Agent: Automating data-driven AI solution building through LLM-powered automated research, development, and evolution,” arXiv preprint arXiv:2505.14738, 2025. [Online]. Available: https: //arxiv.org/abs/2505.14738
-
[5]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
J. S. Chan, N. Chowdhury, O. Jaffe, J. Aung, D. Sherburn, E. Mays, G. Starace, K. Liu, L. Maksin, T. Patwardhan, L. Weng, and A. M ˛ adry, “MLE-Bench: Evaluating machine learning agents on machine learning engineering,” inProceedings of the 13th International Conference on Learning Representations (ICLR), 2025. [Online]. Available: https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Ds-agent: Automated data science by empowering large language models with case-based reasoning
S. Guo, C. Deng, Y . Wen, H. Chen, Y . Chang, and J. Wang, “DS- Agent: Automated data science by empowering large language models with case-based reasoning,” inProceedings of the 41st International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 16 813– 16 848. [Online]. Available: https://ar...
-
[7]
Gemma 4 model card,
Google DeepMind, “Gemma 4 model card,” https://ai.google.dev/ gemma/docs/core/model_card_4, 2026, last updated 17 April 2026, accessed 13 May 2026
2026
-
[8]
Case-based reasoning: Foundational issues, methodological variations, and system approaches,
A. Aamodt and E. Plaza, “Case-based reasoning: Foundational issues, methodological variations, and system approaches,”AI Communications, vol. 7, no. 1, pp. 39–59, 1994. [Online]. Available: https://www.researchgate.net/publication/225070522_Case- Based_Reasoning_Foundational_Issues_Methodological_Variations_ and_System_Approaches
-
[9]
Remembering to forget: A competence- preserving case deletion policy for case-based reasoning systems,
B. Smyth and M. T. Keane, “Remembering to forget: A competence- preserving case deletion policy for case-based reasoning systems,” in Proceedings of the 14th International Joint Conference on Artificial Intelligence (IJCAI-95), 1995, pp. 377–382. [Online]. Available: https://www.ijcai.org/Proceedings/95-1/Papers/050.pdf
1995
-
[10]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 9459–9474. [Online]. Available: https://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
N. Wiratunga, R. Abeyratne, L. Jayawardena, K. Martin, S. Massie, I. Nkisi-Orji, R. Weerasinghe, A. Liret, and B. Fleisch, “CBR-RAG: Case-based reasoning for retrieval augmented generation in LLMs for legal question answering,” inProceedings of the 32nd International Conference on Case-Based Reasoning (ICCBR 2024), ser. Lecture Notes in Computer Science, ...
-
[12]
K. Hatalis, D. Christou, and V . Kondapalli, “Review of case-based reasoning for LLM agents: Theoretical foundations, architectural components, and cognitive integration,”arXiv preprint arXiv:2504.06943, 2025. [Online]. Available: https: //arxiv.org/abs/2504.06943
-
[13]
Case-based reasoning meets large language models: A research manifesto for open challenges and research directions,
K. Bach, R. Bergmann, F. Brand, M. Caro-Martínez, V . Eisenstadt, M. W. Floyd, L. Jayawardena, D. Leake, M. Lenz, L. Malburg, D. H. Ménager, M. Minor, B. Schack, I. Watson, K. Wilkerson, and N. Wiratunga, “Case-based reasoning meets large language models: A research manifesto for open challenges and research directions,” HAL Science, Tech. Rep. hal-050067...
2025
-
[14]
Levels of AI memory — and case-based ways for LLMs to ascend them,
M. W. Floyd, D. Leake, D. H. Ménager, I. Watson, and K. Wilkerson, “Levels of AI memory — and case-based ways for LLMs to ascend them,” inCBR-LLM Workshop @ ICCBR 2025, ser. CEUR Workshop Proceedings, vol. 3993, 2025, pp. 2–14. [Online]. Available: https://ceur-ws.org/V ol-3993/paper1.pdf
2025
-
[15]
EXAR: A unified experience-grounded agentic reasoning architecture,
R. Bergmann, F. Brand, M. Lenz, and L. Malburg, “EXAR: A unified experience-grounded agentic reasoning architecture,” inProceedings of the 33rd International Conference on Case-Based Reasoning (ICCBR 2025), ser. Lecture Notes in Computer Science, vol. 15662. Springer, 2025, pp. 3–17. [Online]. Available: https://www.wi2.uni- trier.de/shared/publications/2...
2025
-
[16]
A case-based reasoning approach to dynamic few-shot prompting for code generation,
D. Dannenhauer, Z. Dannenhauer, D. Christou, and K. Hatalis, “A case-based reasoning approach to dynamic few-shot prompting for code generation,” inICML 2024 Workshop on LLMs and Cognition, 2024. [Online]. Available: https://openreview.net/pdf?id= Kt9bM32oDY
2024
-
[17]
Large language models as knowledge engineers,
F. Brand, L. Malburg, and R. Bergmann, “Large language models as knowledge engineers,” inCBR-LLM Workshop @ ICCBR 2024, ser. CEUR Workshop Proceedings, vol. 3708, 2024, pp. 3–18. [Online]. Available: https://ceur-ws.org/V ol-3708/paper_01.pdf
2024
-
[18]
Retrieval augmented generation with LLMs for explaining business process models,
M. Minor and E. Kaucher, “Retrieval augmented generation with LLMs for explaining business process models,” inProceedings of the 32nd International Conference on Case-Based Reasoning (ICCBR 2024), ser. Lecture Notes in Computer Science, vol. 14775. Springer, 2024, pp. 175–190. [Online]. Available: http://wi.cs.uni- frankfurt.de/webdav/publications/2024_IC...
2024
-
[19]
Explainable classification system for hip fractures: A hybrid CBR+LLM surrogate approach,
E. Queipo-de Llano, M. Ciurcau, A. Paz-Olalla, B. Díaz-Agudo, and J. A. Recio-García, “Explainable classification system for hip fractures: A hybrid CBR+LLM surrogate approach,” inXCBR Workshop on CBR for the Explanation of Intelligent Systems @ ICCBR 2024, ser. CEUR Workshop Proceedings, vol. 3708, 2024, pp. 65–80. [Online]. Available: https://ceur-ws.or...
2024
-
[20]
LLM-driven case-base populating for structuring and integrating restoration experiences,
F. Ghazouani, F. Giustozzi, and F. Le Ber, “LLM-driven case-base populating for structuring and integrating restoration experiences,” inProceedings of the 33rd International Conference on Case- Based Reasoning (ICCBR 2025), ser. Lecture Notes in Computer Science, vol. 15662. Springer, 2025, pp. 67–80. [Online]. Available: https://hal.science/hal-05058570v...
2025
-
[21]
Agentic CBR in action: Empowering loan approvals through interactive, counterfactual explanations,
P. Salimi, N. Wiratunga, and D. Corsar, “Agentic CBR in action: Empowering loan approvals through interactive, counterfactual explanations,” inCBR-LLM Workshop @ ICCBR 2025, ser. CEUR Workshop Proceedings, vol. 3993, 2025, pp. 27–42. [Online]. Available: https://ceur-ws.org/V ol-3993/paper3.pdf
2025
-
[22]
A human-LLM note-taking system with case-based reasoning as framework for scientific discovery,
D. B. Craig, “A human-LLM note-taking system with case-based reasoning as framework for scientific discovery,” inProceedings of the 1st Workshop on AI and Scientific Discovery: Directions and Opportunities (AISD @ NAACL 2025), 2025, pp. 22–30. [Online]. Available: https://aclanthology.org/2025.aisd-main.3
2025
-
[23]
Decision making in LLMs: A first step,
R. O. Weber, C. B. Rauch, and S. Amin, “Decision making in LLMs: A first step,” inCBR-LLM Workshop @ ICCBR 2025, ser. CEUR Workshop Proceedings, vol. 3993, 2025, pp. 15–26. [Online]. Available: https://ceur-ws.org/V ol-3993/paper2.pdf
2025
-
[24]
Memento: Fine-tuning llm agents without fine-tuning llms.arXiv preprint arXiv:2508.16153, 2025
H. Zhou, Y . Chen, S. Guo, X. Yan, K. H. Lee, Z. Wang, K. Y . Lee, G. Zhang, K. Shao, L. Yang, and J. Wang, “Memento: Fine-tuning LLM agents without fine-tuning LLMs,” arXiv preprint arXiv:2508.16153, 2025. [Online]. Available: https: //arxiv.org/abs/2508.16153
-
[25]
C. Thornton, F. Hutter, H. H. Hoos, and K. Leyton-Brown, “Auto-WEKA: Combined selection and hyperparameter optimization of classification algorithms,” inProceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2013, pp. 847–855. [Online]. Available: https://dl.acm.org/doi/10.1145/2487575.2487629
-
[26]
Auto-sklearn: Automated machine learning,
M. Feurer, A. Klein, K. Eggensperger, J. Springenberg, M. Blum, and F. Hutter, “Auto-sklearn: Automated machine learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 28, 2015, pp. 2962–2970. [Online]. Available: https://www.researchgate.net/publication/333181102_Auto- sklearn_Efficient_and_Robust_Automated_Machine_Learning
-
[27]
Evaluation of a tree-based pipeline optimization tool for automating data science,
R. S. Olson, N. Bartley, R. J. Urbanowicz, and J. H. Moore, “Evaluation of a tree-based pipeline optimization tool for automating data science,” inProceedings of the Genetic and Evolutionary Computation Conference (GECCO), 2016, pp. 485–492. [Online]. Available: https://dl.acm.org/doi/10.1145/2908812.2908918
-
[29]
Available: https://arxiv.org/abs/2402.18679
[Online]. Available: https://arxiv.org/abs/2402.18679
-
[30]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, C. Zhang, J. Wang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “MetaGPT: Meta programming for a multi-agent collaborative framework,” inProceedings of the 12th International Conference on Learning Representations (ICLR), 2024. [Online]. Available: https://arxiv.org/ab...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Q. Huang, J. V ora, P. Liang, and J. Leskovec, “MLAgentBench: Evaluating language agents on machine learning experimentation,” inProceedings of the 41st International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 20 271–20 309. [Online]. Available: https://arxiv.org/abs/2310.03302
-
[32]
Z. Li, Q. Zang, D. Ma, J. Guo, T. Zheng, M. Liu, X. Niu, Y . Wang, J. Yang, J. Liu, W. Zhong, W. Zhou, W. Huang, and G. Zhang, “AutoKaggle: A multi-agent framework for autonomous data science competitions,”arXiv preprint arXiv:2410.20424, 2024. [Online]. Available: https://arxiv.org/abs/2410.20424
-
[33]
MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement
J. Nam, J. Yoon, J. Chen, J. Shin, S. Ö. Arık, and T. Pfister, “MLE-STAR: Machine learning engineering agent via search and targeted refinement,”arXiv preprint arXiv:2506.15692, 2025. [Online]. Available: https://arxiv.org/abs/2506.15692
-
[34]
OpenHands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “OpenHands: An open platform for AI software developers as generalist agents,” inProceedings of the 13th International Confere...
-
[35]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
[Online]. Available: https://arxiv.org/abs/2407.16741
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Collaborative evolving strategy for automatic data-centric development,
X. Yang, H. Chen, W. Feng, H. Wang, Z. Ye, X. Shen, X. Yang, S. Sun, W. Liu, and J. Bian, “Collaborative evolving strategy for automatic data-centric development,”arXiv preprint arXiv:2407.18690, 2024. [Online]. Available: https://arxiv.org/abs/2407.18690
-
[37]
Toward ultra-long-horizon agentic science: Cognitive accumulation for machine learning engineering
X. Zhu, Y . Cai, Z. Liu, B. Zheng, C. Wang, R. Ye, Y . Zhang, L. Zhang, W. E, S. Chen, and Y . Wang, “Toward ultra-long- horizon agentic science: Cognitive accumulation for machine learning engineering,”arXiv preprint arXiv:2601.10402, 2026. [Online]. Available: https://arxiv.org/abs/2601.10402
-
[38]
AutoMind: Adaptive Knowledgeable Agent for Automated Data Science
Y . Ou, Y . Luo, J. Zheng, L. Wei, Z. Yu, S. Qiao, J. Zhang, D. Zheng, Y . Mao, Y . Gao, H. Chen, and N. Zhang, “AutoMind: Adaptive knowledgeable agent for automated data science,”arXiv preprint arXiv:2506.10974, 2025. [Online]. Available: https://arxiv. org/abs/2506.10974
-
[40]
ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
[Online]. Available: https://arxiv.org/abs/2505.23723
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023. [Online]. Available: https://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. Le Scao, T. Lavril, T. Wang, T. Lacroix, and W. El Sayed, “Mistral 7b,”arXiv preprint arXiv:2310.06825, 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . K. Li, F. Luo, Y . Xiong, and W. Liang, “DeepSeek-Coder: When the large language model meets programming — the rise of code intelligence,”arXiv preprint arXiv:2401.14196, 2024. [Online]. Available: https://arxiv.org/abs/2401.14196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Position: LLMs can’t plan, but can help planning in LLM-modulo frameworks,
S. Kambhampati, K. Valmeekam, L. Guan, M. Verma, K. Stechly, S. Bhambri, L. Saldyt, and A. Murthy, “Position: LLMs can’t plan, but can help planning in LLM-modulo frameworks,” in Proceedings of the 41st International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 22 895–22 907. [Online]. Ava...
-
[45]
Lost in the Middle: How Language Models Use Long Contexts
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024. [Online]. Available: https://arxiv.org/abs/2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Welcome Gemma 4: Frontier multimodal intelligence on device,
Hugging Face, “Welcome Gemma 4: Frontier multimodal intelligence on device,” https://huggingface.co/blog/gemma4, 2026, published 2 April 2026, accessed 13 May 2026. APPENDIX TABLE III APPENDIXA: PER-RUNPERFORMANCEMETRICS. COMP.=COMPETITION.COND.=CONDITION.S=SEED.N=LOOPS COMPLETED.BEST= BEST CUMULATIVE METRIC.L0=LOOP-0METRIC.∆SOTA=ABSOLUTESOTAGAIN(DIRECTIO...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.