Aggregating LLM-Based Weak Verifiers for Spatial Layout Generation
Pith reviewed 2026-06-28 03:06 UTC · model grok-4.3
The pith
Aggregating LLM-generated weak verifiers in a layout DSL yields a strong verifier that raises F1-scores by up to 7X over direct LLM judges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
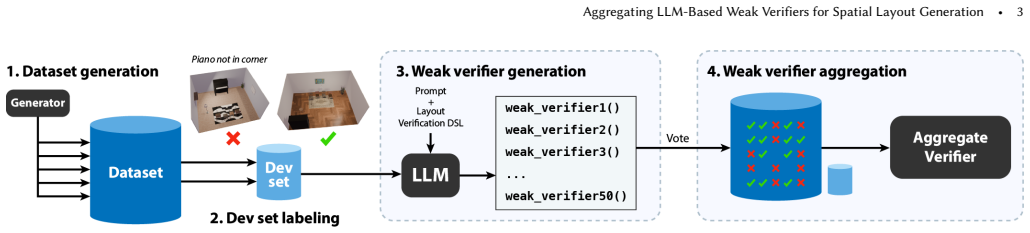
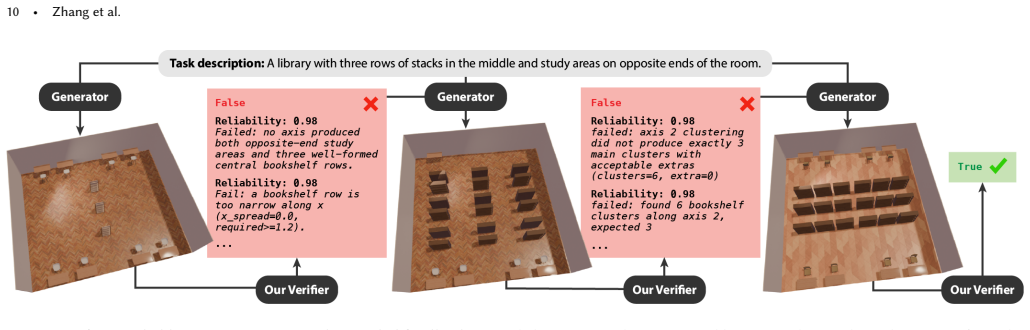
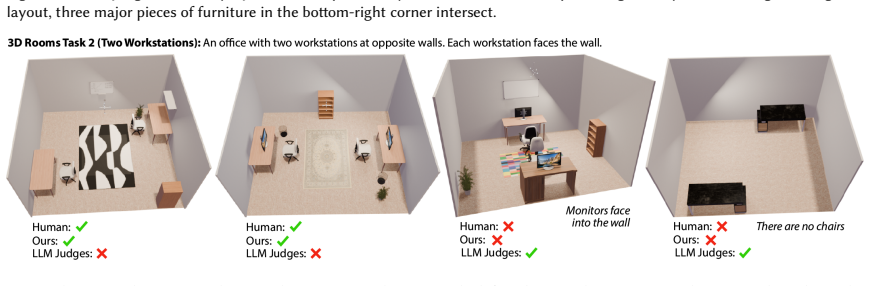
The paper establishes that synthesizing a collection of verifier programs in a layout verification DSL with an LLM, then aggregating their responses through weak learning on a small set of human examples, yields a strong verifier. This verifier outperforms direct LLM judges on matching layouts to task descriptions, as measured by higher F1 scores, and supports better layout generation via natural language feedback.
What carries the argument
The pipeline that asks an LLM to synthesize verifier programs in a layout verification DSL and learns aggregation weights via weak learning from approximately 10 labeled examples.
If this is right
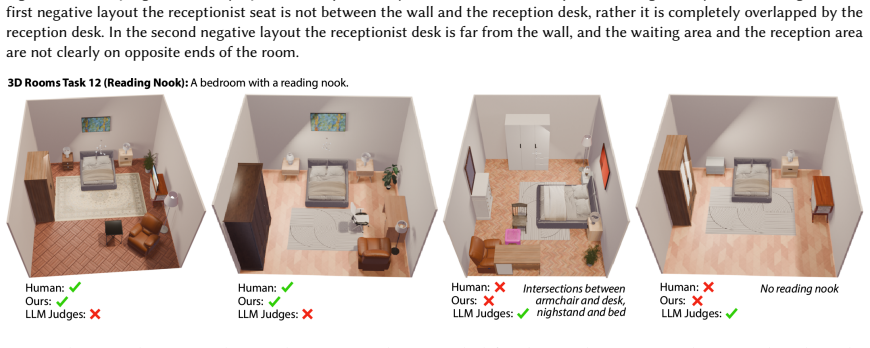
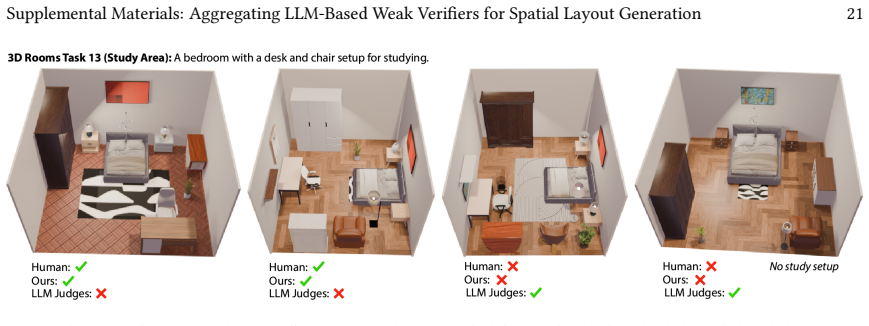
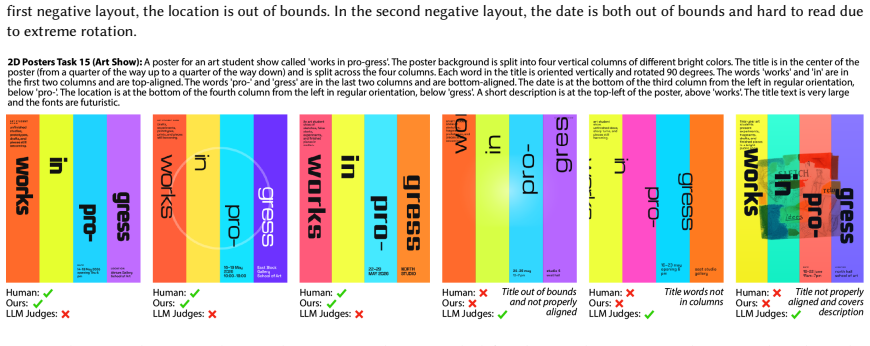
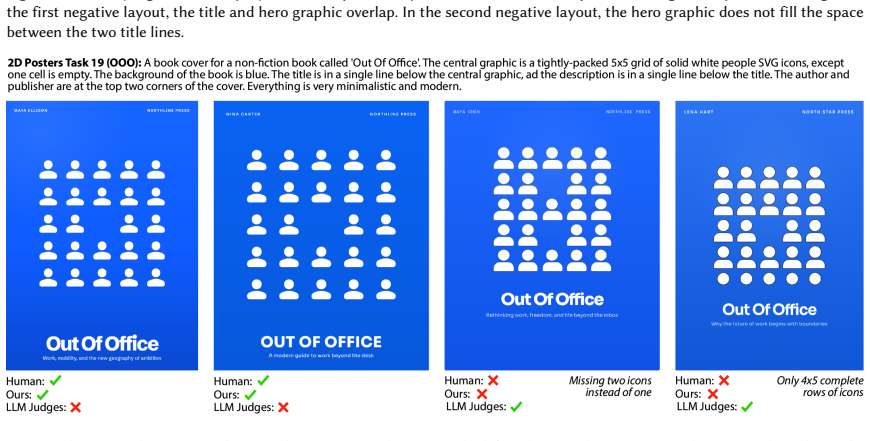
- The strong verifier improves layout generation quality by up to 66.2% when used to supply natural language feedback to a base generator.
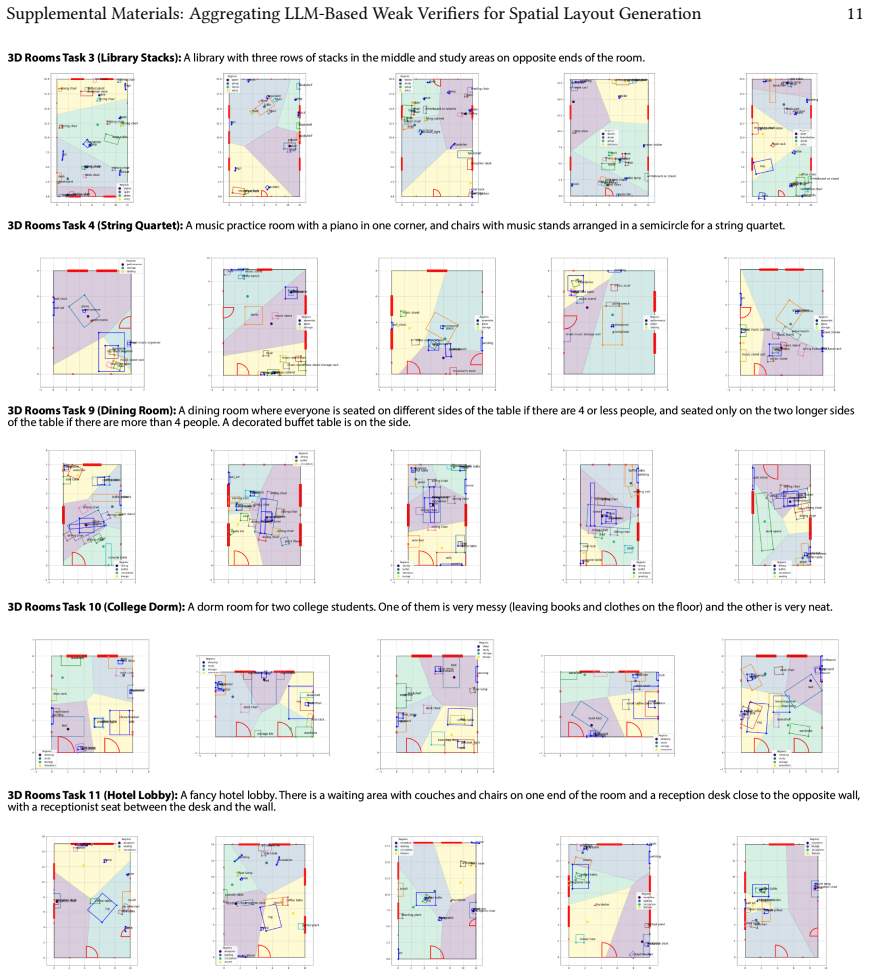
- The approach applies across both 3D room layout tasks and 2D poster design tasks.
- Aggregation weights learned from about 10 examples suffice to outperform direct LLM judges.
- F1-scores increase by up to 7 times relative to the status-quo of using LLM judges directly.
Where Pith is reading between the lines
- The method could extend to other structured generation tasks if similar domain-specific verification languages are defined.
- The reduced label requirement may make high-quality verification practical for new layout domains without large annotation efforts.
- Iterative use of the verifier feedback could be combined with optimization loops in existing layout systems.
Load-bearing premise
The LLM-generated verifiers supply sufficiently diverse checks so that weak learning can learn reliable aggregation weights from only about 10 human-labeled examples.
What would settle it
A test showing that the F1 score of the aggregated verifier does not exceed the F1 score of a set of direct LLM judges on held-out 3D room layout or 2D poster examples.
Figures















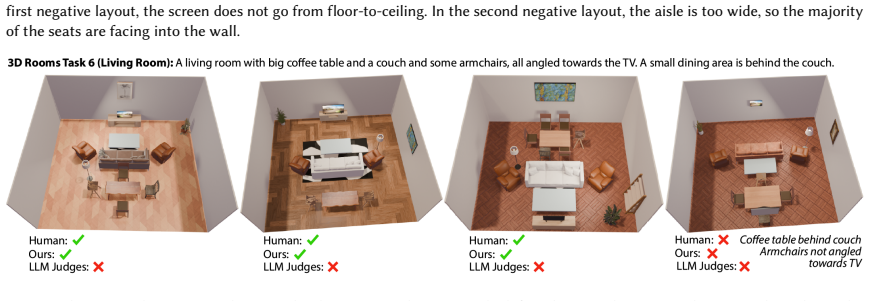
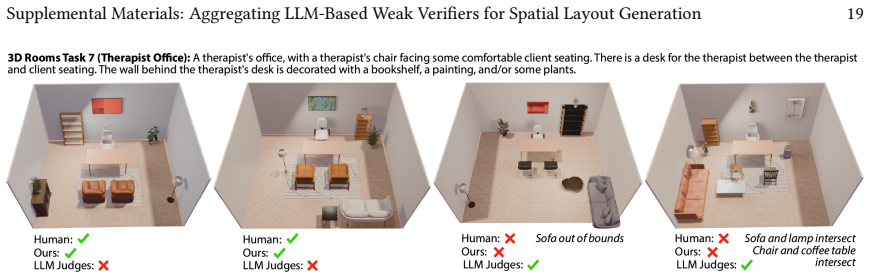


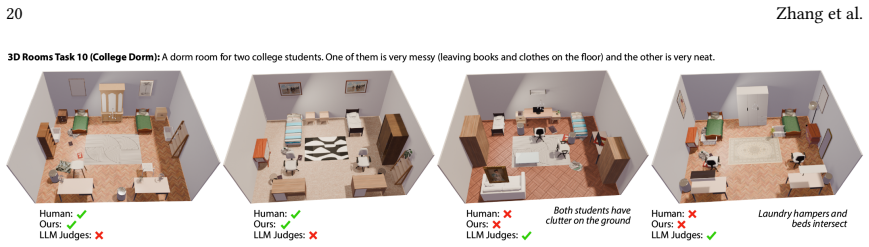
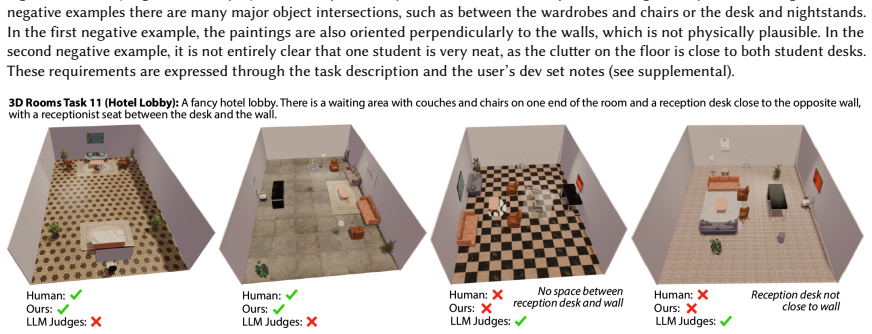




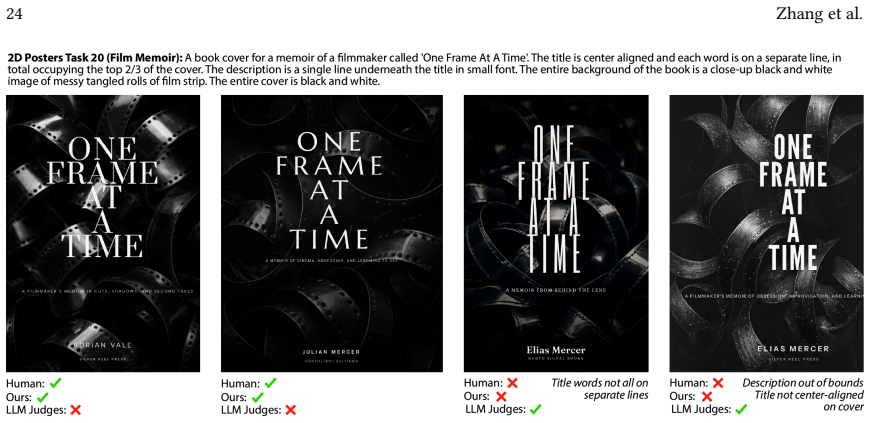






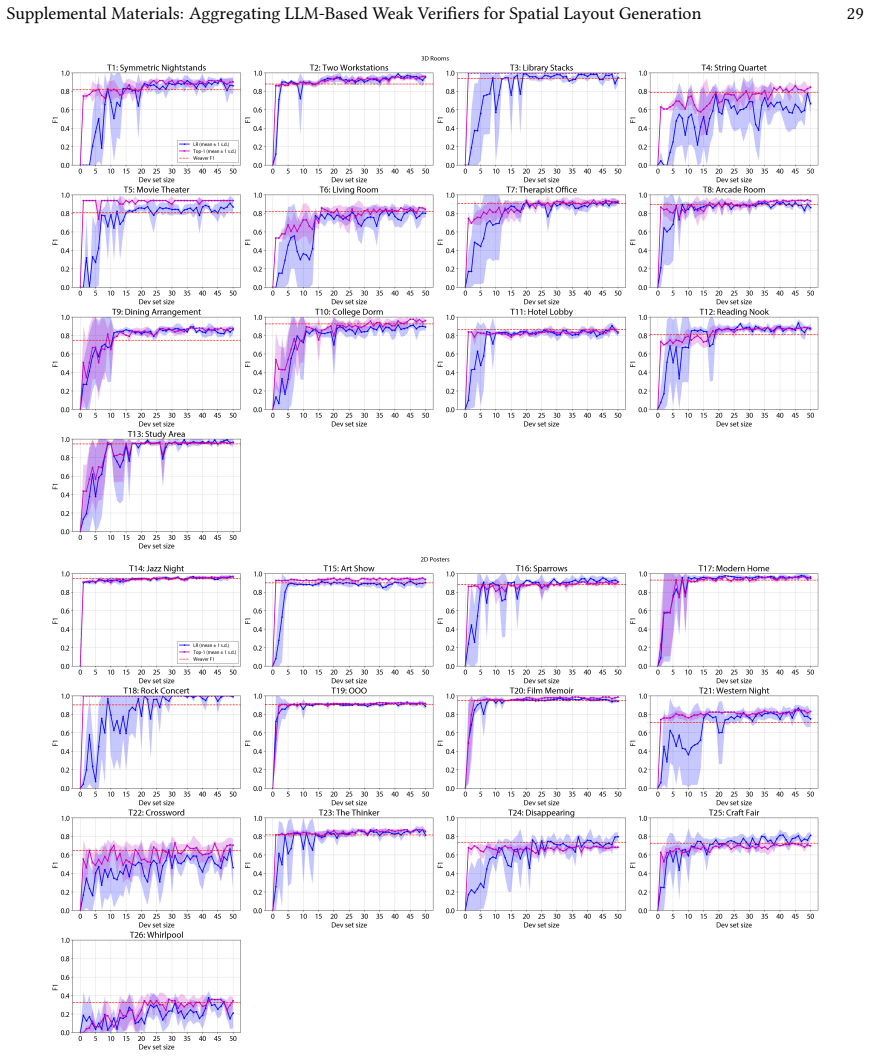
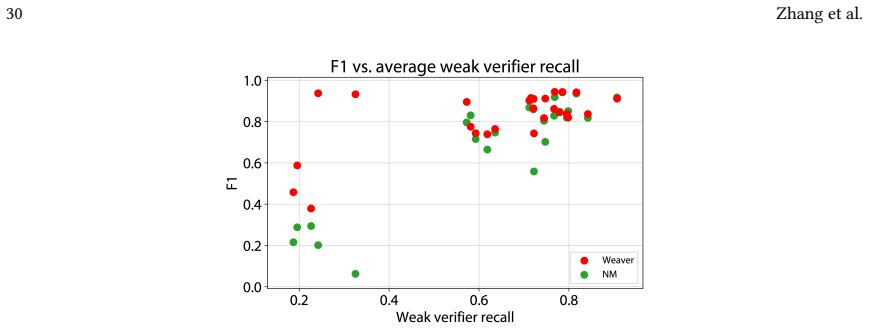

read the original abstract
We present a pipeline for building and aggregating task-specific, LLM-generated weak (imperfect) verifiers into a strong verifier for spatial layout domains. Given a task description, our pipeline asks an LLM to synthesize a collection of verifier programs using a layout verification DSL. Each individual LLM-generated verifier usually provides an imperfect check for a match between the layout and the corresponding task description. We show that by aggregating the responses of many such verifiers we can produce a stronger verifier. Moreover, by applying techniques from weak learning, our pipeline can learn how to aggregate the weak verifiers from a very sparse set of human labeled example layouts (about 10). We find that the strong verifiers produced by our pipeline outperform the status-quo approach of using a set of LLM judges to directly check whether a layout matches a task description, raising F1-scores by up to 7X across a variety of 3D room layout and 2D poster design tasks. We also demonstrate that verifier-guided layout generation using natural language feedback from our strong verifiers improves layout quality of a base layout generator by up to 66.2% according to a human evaluator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a pipeline that prompts an LLM to synthesize multiple weak verifiers as programs in a layout verification DSL for spatial tasks (3D room layouts, 2D poster design). These verifiers are aggregated via weak-learning techniques trained on roughly 10 human-labeled examples to produce a strong verifier. The resulting verifier is claimed to outperform direct LLM judges (F1 gains up to 7X) and, when used for natural-language feedback, to improve base layout generators by up to 66.2% per human evaluation.
Significance. If the empirical claims hold under scrutiny, the work offers a practical route to task-specific verification with minimal labeled data by exploiting LLM-generated DSL programs and weak learning. The multi-task evaluation and the use of a DSL for verifiable checks are positive elements; reproducible code or explicit aggregation procedures would further strengthen it.
major comments (2)
- [Abstract / §3] Abstract and §3 (method): The central claim that aggregation weights can be learned reliably from ~10 human-labeled layouts rests on the unstated assumptions that the LLM-generated verifiers are sufficiently diverse and that their errors are not highly correlated. No count of verifiers, no description of the weak-learning procedure (boosting, weighted voting, etc.), and no cross-validation or stability results for the 10-example regime are supplied; with more than a handful of verifiers this sample size supplies too few degrees of freedom for stable estimation.
- [Abstract / Experiments] Abstract and experimental section: The reported F1 gains of up to 7X and the 66.2% human-evaluated improvement lack any mention of baseline implementations, statistical significance tests, prompt-sensitivity controls, or data-split details. These omissions make it impossible to verify whether the gains are robust or sensitive to unstated experimental choices.
minor comments (2)
- [§2] The DSL definition and the exact syntax of the generated verifier programs should be presented with at least one concrete example to allow replication.
- [Related Work] Standard weak-learning references (e.g., boosting literature) are missing; adding them would clarify the aggregation technique.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional clarity on assumptions, procedures, and experimental rigor would strengthen the manuscript. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method): The central claim that aggregation weights can be learned reliably from ~10 human-labeled layouts rests on the unstated assumptions that the LLM-generated verifiers are sufficiently diverse and that their errors are not highly correlated. No count of verifiers, no description of the weak-learning procedure (boosting, weighted voting, etc.), and no cross-validation or stability results for the 10-example regime are supplied; with more than a handful of verifiers this sample size supplies too few degrees of freedom for stable estimation.
Authors: We agree the assumptions should be stated explicitly and the procedure detailed. The revised manuscript will report the number of verifiers synthesized per task, describe the aggregation method (weighted combination of verifier outputs learned via regularized logistic regression on the sparse labels), and include leave-one-out cross-validation results demonstrating weight stability in the 10-example setting. We will also discuss the diversity of LLM-generated verifiers and note the risk of correlated errors as a limitation. revision: yes
-
Referee: [Abstract / Experiments] Abstract and experimental section: The reported F1 gains of up to 7X and the 66.2% human-evaluated improvement lack any mention of baseline implementations, statistical significance tests, prompt-sensitivity controls, or data-split details. These omissions make it impossible to verify whether the gains are robust or sensitive to unstated experimental choices.
Authors: We will expand the experimental section to specify the LLM judge baselines (same model with varied prompts), report statistical significance via bootstrap resampling or paired tests on the F1 scores, include prompt-sensitivity analysis with variance across prompt variants, and detail the train/test splits (10 labeled examples for aggregation learning, separate held-out sets for evaluation). These additions will allow readers to assess robustness. revision: yes
Circularity Check
No circularity; purely empirical pipeline with no derivations or self-referential fits
full rationale
The paper describes an empirical method for synthesizing LLM-generated verifiers in a DSL, then aggregating them via weak learning on ~10 human labels to produce a stronger verifier. No equations, first-principles derivations, or fitted quantities are presented that reduce to their own inputs by construction. Results rest on F1-score comparisons and human evaluations against baselines, with no self-citation chains, uniqueness theorems, or ansatzes invoked as load-bearing. The weak-learning step is a standard application of existing techniques and does not redefine its own aggregation weights as predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shrinking the generation-verification gap with weak verifiers.arXiv preprint arXiv:2506.18203,
Weaver: Shrinking the Generation-Verification Gap with Weak Verifiers , author =. Conference on Neural Information Processing Systems , year =. doi:10.48550/arXiv.2506.18203 , url =
-
[2]
3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics , year=
Fu, Huan and Cai, Bowen and Gao, Lin and Zhang, Ling-Xiao and Wang, Jiaming and Li, Cao and Zeng, Qixun and Sun, Chengyue and Jia, Rongfei and Zhao, Binqiang and Zhang, Hao , booktitle=. 3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics , year=
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Despoina Paschalidou and Amlan Kar and Maria Shugrina and Karsten Kreis and Andreas Geiger and Sanja Fidler , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[4]
Training complex models with multi-task weak supervision
Ratner, Alexander and Hancock, Braden and Dunnmon, Jared and Sala, Frederic and Pandey, Shreyash and R \'e , Christopher. Training complex models with multi-task weak supervision. Proc. Conf. AAAI Artif. Intell
-
[5]
and Ehrenberg, Henry and Fries, Jason and Wu, Sen and R\'
Ratner, Alexander and Bach, Stephen H. and Ehrenberg, Henry and Fries, Jason and Wu, Sen and R\'. Snorkel: rapid training data creation with weak supervision , year =. Proc. VLDB Endow. , month = nov, pages =. doi:10.14778/3157794.3157797 , abstract =
-
[6]
Training complex models with multi-task weak supervision , year =
Ratner, Alexander and Hancock, Braden and Dunnmon, Jared and Sala, Frederic and Pandey, Shreyash and R\'. Training complex models with multi-task weak supervision , year =. Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Ed...
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yang, Yue and Sun, Fan-Yun and Weihs, Luca and VanderBilt, Eli and Herrasti, Alvaro and Han, Winson and Wu, Jiajun and Haber, Nick and Krishna, Ranjay and Liu, Lingjie and Callison-Burch, Chris and Yatskar, Mark and Kembhavi, Aniruddha and Clark, Christopher , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR...
2024
-
[8]
arXiv preprint arXiv:2501.04648 , year=
FlairGPT: Repurposing LLMs for Interior Designs , author=. arXiv preprint arXiv:2501.04648 , year=
-
[9]
arXiv preprint arXiv:2307.05663 , year=
Objaverse-XL: A Universe of 10M+ 3D Objects , author=. arXiv preprint arXiv:2307.05663 , year=
-
[10]
and Scholkopf, B
Chapelle, O. and Scholkopf, B. and Zien, Eds., A. , journal=. Semi-Supervised Learning (Chapelle, O. et al., Eds.; 2006) [Book reviews] , year=
2006
-
[11]
Data programming: creating large training sets, quickly , year =
Ratner, Alexander and Sa, Christopher De and Wu, Sen and Selsam, Daniel and R\'. Data programming: creating large training sets, quickly , year =. Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =
-
[12]
and Chen, Mayee F
Fu, Daniel Y. and Chen, Mayee F. and Sala, Frederic and Hooper, Sarah M. and Fatahalian, Kayvon and R\'. Fast and three-rious: speeding up weak supervision with triplet methods , year =. Proceedings of the 37th International Conference on Machine Learning , articleno =
-
[13]
2023 , eprint=
JudgeLM: Fine-tuned Large Language Models are Scalable Judges , author=. 2023 , eprint=
2023
-
[14]
arXiv preprint arXiv:2309.01219 , year=
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. arXiv preprint arXiv:2309.01219 , year=
-
[15]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. CoRR, abs/2312.08935 , year=
-
[16]
The Thirty-Eighth Annual Conference on Neural Information Processing Systems , year=
Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models , author=. The Thirty-Eighth Annual Conference on Neural Information Processing Systems , year=
-
[17]
2024 , archivePrefix=
JudgeBench: A Benchmark for Evaluating LLM-Based Judges , author=. 2024 , archivePrefix=
2024
-
[18]
2023 , eprint=
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[19]
2024 , eprint=
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models , author=. 2024 , eprint=
2024
-
[20]
2026 , eprint=
Towards Acyclic Preference Evaluation of Language Models via Multiple Evaluators , author=. 2026 , eprint=
2026
-
[21]
2025 , eprint=
iVISPAR -- An Interactive Visual-Spatial Reasoning Benchmark for VLMs , author=. 2025 , eprint=
2025
-
[22]
arXiv preprint arXiv:2305.15393 , year=
LayoutGPT: Compositional Visual Planning and Generation with Large Language Models , author=. arXiv preprint arXiv:2305.15393 , year=
-
[23]
arXiv preprint arXiv: 2506.00742 , year =
ArtiScene: Language-Driven Artistic 3D Scene Generation Through Image Intermediary , author =. arXiv preprint arXiv: 2506.00742 , year =
-
[24]
2025 , eprint=
Scenethesis: A Language and Vision Agentic Framework for 3D Scene Generation , author=. 2025 , eprint=
2025
-
[25]
arXiv preprint arXiv:2410.12844 , year=
TextLap: Customizing Language Models for Text-to-Layout Planning , author=. arXiv preprint arXiv:2410.12844 , year=
-
[26]
Zhang, Xilin and Wang, Hao and Dai, Jianbiao and Zhu, Pinpin , title =. Document Analysis and Recognition – ICDAR 2025: 19th International Conference, Wuhan, China, September 16–21, 2025, Proceedings, Part I , pages =. 2025 , isbn =. doi:10.1007/978-3-032-04614-7_12 , abstract =
-
[27]
Jones, B. T. and Zhang, Z. and H. A Solver-Aided Hierarchical Language for LLM-Driven CAD Design , url =. Computer Graphics Forum , keywords =. 2025 , bdsk-url-1 =. doi:https://doi.org/10.1111/cgf.70250 , eprint =
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wu, Ronghuan and Su, Wanchao and Liao, Jing , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[29]
2024 , eprint=
BlenderLLM: Training Large Language Models for Computer-Aided Design with Self-improvement , author=. 2024 , eprint=
2024
-
[30]
CAD-Llama: Leveraging Large Language Models for Computer-Aided Design Parametric 3D Model Generation , year=
Li, Jiahao and Ma, Weijian and Li, Xueyang and Lou, Yunzhong and Zhou, Guichun and Zhou, Xiangdong , booktitle=. CAD-Llama: Leveraging Large Language Models for Computer-Aided Design Parametric 3D Model Generation , year=
-
[31]
Ma, Jiaju and Agrawala, Maneesh , title =. 2025 , issue_date =. doi:10.1145/3731209 , journal =
-
[32]
D ream S ync: Aligning Text-to-Image Generation with Image Understanding Feedback
Sun, Jiao and Fu, Deqing and Hu, Yushi and Wang, Su and Rassin, Royi and Juan, Da-Cheng and Alon, Dana and Herrmann, Charles and Steenkiste, Sjoerd Van and Krishna, Ranjay and Rashtchian, Cyrus. D ream S ync: Aligning Text-to-Image Generation with Image Understanding Feedback. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of th...
-
[33]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Hu, Ziniu and Iscen, Ahmet and Jain, Aashi and Kipf, Thomas and Yue, Yisong and Ross, David A and Schmid, Cordelia and Fathi, Alireza , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[34]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[35]
The 4th Workshop on Mathematical Reasoning and AI at NeurIPS'24 , year=
Generative Verifiers: Reward Modeling as Next-Token Prediction , author=. The 4th Workshop on Mathematical Reasoning and AI at NeurIPS'24 , year=
-
[36]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[37]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Agent-as-a-Judge: Evaluate Agents with Agents , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[38]
2024 , eprint=
TICKing All the Boxes: Generated Checklists Improve LLM Evaluation and Generation , author=. 2024 , eprint=
2024
-
[39]
2024 , eprint=
Robust Planning with Compound LLM Architectures: An LLM-Modulo Approach , author=. 2024 , eprint=
2024
-
[40]
Weak supervision from high-level abstractions , author=
-
[41]
LiveBench: A Challenging, Contamination-Free
Colin White and Samuel Dooley and Manley Roberts and Arka Pal and Benjamin Feuer and Siddhartha Jain and Ravid Shwartz-Ziv and Neel Jain and Khalid Saifullah and Sreemanti Dey and Shubh-Agrawal and Sandeep Singh Sandha and Siddartha Venkat Naidu and Chinmay Hegde and Yann LeCun and Tom Goldstein and Willie Neiswanger and Micah Goldblum , booktitle=. LiveB...
-
[42]
arXiv preprint arXiv:2404.01291 , year=
Evaluating Text-to-Visual Generation with Image-to-Text Generation , author=. arXiv preprint arXiv:2404.01291 , year=
-
[43]
arXiv preprint arXiv:2402.07207 , year=
Gala3d: Towards text-to-3d complex scene generation via layout-guided generative gaussian splatting , author=. arXiv preprint arXiv:2402.07207 , year=
-
[44]
ACM SIGGRAPH 2023 Conference Proceedings , articleno =
Para, Wamiq Reyaz and Guerrero, Paul and Mitra, Niloy and Wonka, Peter , title =. ACM SIGGRAPH 2023 Conference Proceedings , articleno =. 2023 , isbn =. doi:10.1145/3588432.3591561 , abstract =
-
[45]
Kenny and Fu, Kailiang and Aguina-Kang, Rio and Morris, Stewart and Ritchie, Daniel , title =
Gumin, Maxim and Han, Do Heon and Yoo, Seung Jean and Ganeshan, Aditya and Jones, R. Kenny and Fu, Kailiang and Aguina-Kang, Rio and Morris, Stewart and Ritchie, Daniel , title =. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , articleno =. 2025 , isbn =. doi:10.1145/3757377.3763930 , abstract =
-
[46]
arXiv , year =
Qihang Zhang and Chaoyang Wang and Aliaksandr Siarohin and Peiye Zhuang and Yinghao Xu and Ceyuan Yang and Dahua Lin and Bo Dai and Bolei Zhou and Sergey Tulyakov and Hsin-Ying Lee , title =. arXiv , year =
-
[47]
Wang, Kai and Savva, Manolis and Chang, Angel X. and Ritchie, Daniel , title =. ACM Trans. Graph. , month = jul, articleno =. 2018 , issue_date =. doi:10.1145/3197517.3201362 , abstract =
-
[48]
2021 International Conference on 3D Vision (3DV) , year=
SceneFormer: Indoor Scene Generation with Transformers , author=. 2021 International Conference on 3D Vision (3DV) , year=
2021
-
[49]
The Fourteenth International Conference on Learning Representations , year=
Do 3D Large Language Models Really Understand 3D Spatial Relationships? , author=. The Fourteenth International Conference on Learning Representations , year=
-
[50]
2026 , note=
LLM-as-a-Verifier: A General-Purpose Verification Framework , author=. 2026 , note=
2026
-
[51]
2026 , eprint=
Maillard, L. 2026 , eprint=
2026
-
[52]
and Chang, Angel X
Tam, Hou In Ivan and Pun, Hou In Derek and Wang, Austin T. and Chang, Angel X. and Savva, Manolis , year =
-
[53]
CVPR , year =
Tong Wu and Guandao Yang and Zhibing Li and Kai Zhang and Ziwei Liu and Leonidas Guibas and Dahua Lin and Gordon Wetzstein , title =. CVPR , year =
-
[54]
2026 , eprint=
SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes , author=. 2026 , eprint=
2026
-
[55]
2026 , eprint=
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.