LoRi: Low-Rank Distillation for Implicit Reasoning
Pith reviewed 2026-06-28 06:18 UTC · model grok-4.3
The pith
Low-rank alignment of hidden-state trajectories transfers reasoning from teacher to student models without explicit prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
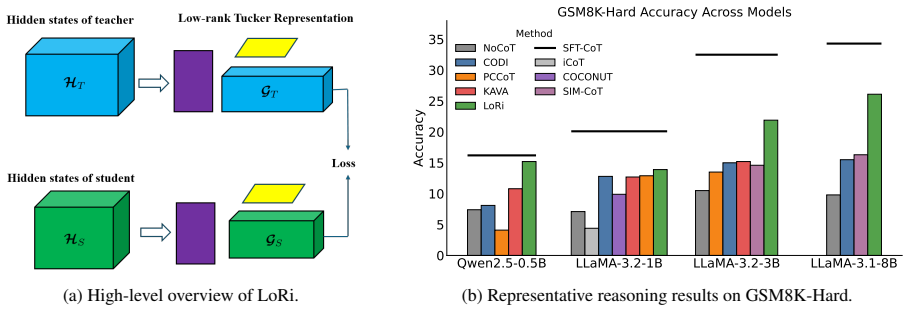
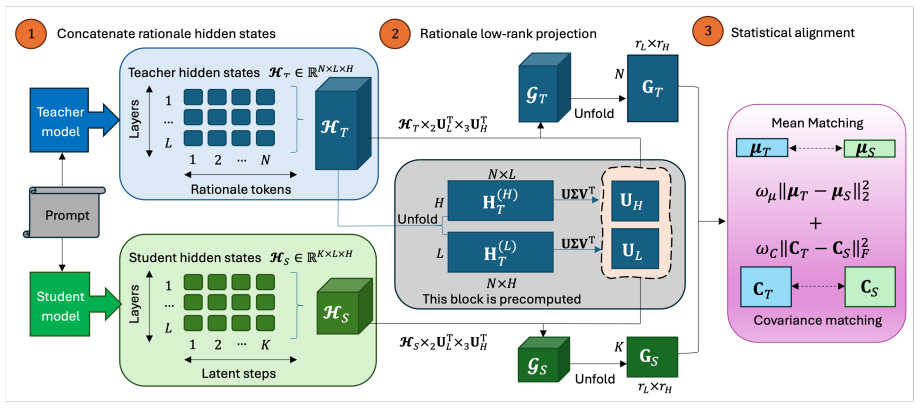
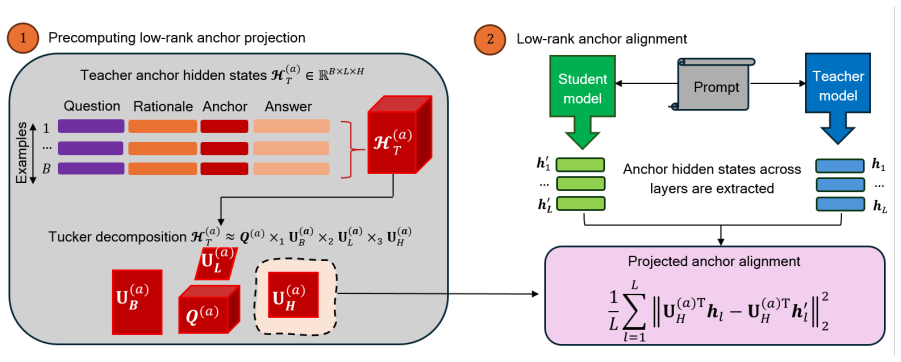
By aligning teacher and student reasoning trajectories inside a shared low-rank tensor subspace via first- and second-order statistics, the distillation process transfers implicit reasoning capability, yielding consistent gains on mathematical reasoning benchmarks that are largest on multi-step tasks and bring implicit performance near explicit CoT levels.
What carries the argument
The low-rank distillation framework that projects trajectories into a shared low-rank tensor subspace and aligns them using first- and second-order statistics.
If this is right
- Gains are larger on multi-step problems than on single-step ones.
- The student model reaches performance close to explicit chain-of-thought without emitting reasoning steps at test time.
- The same approach works across LLaMA and Qwen families at different scales.
- It surpasses earlier implicit CoT distillation baselines on the same benchmarks.
Where Pith is reading between the lines
- Reasoning patterns may be compressible into far fewer dimensions than the full hidden state, opening routes to cheaper inference.
- If the low-rank property appears in non-math domains, the same alignment could transfer planning or code-generation skills.
- The subspace view suggests that future students could be initialized directly in the teacher's low-rank basis rather than distilled after full training.
Load-bearing premise
The empirical finding that hidden-state reasoning trajectories exhibit low-rank structure is enough for alignment in that subspace alone to transfer reasoning ability.
What would settle it
Running the low-rank alignment on a new model family and finding no accuracy lift on multi-step math problems compared with ordinary distillation, or measuring that the trajectories do not in fact occupy a low-rank subspace.
Figures
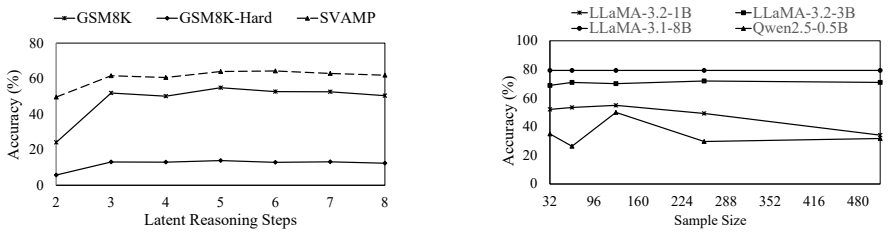
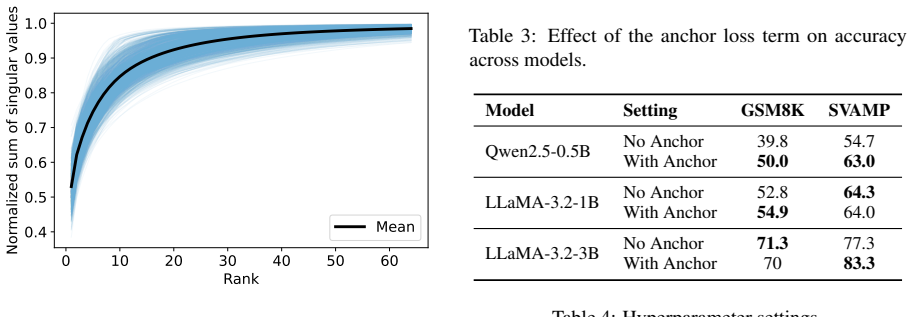
read the original abstract
Implicit chain-of-thought (iCoT) methods aim to internalize reasoning in large language models, but often underperform explicit CoT prompting. We empirically find that hidden-state reasoning trajectories exhibit low-rank structure. Motivated by this observation, we propose a low-rank distillation framework that transfers reasoning by aligning teacher and student trajectories in a shared low-rank tensor subspace using first- and second-order statistics. The resulting formulation captures the global structure of reasoning while supporting a compact latent reasoning process. We evaluate the method across multiple model families, including LLaMA and Qwen, at different scales on mathematical reasoning benchmarks. Our approach consistently improves performance, especially on challenging multi-step tasks, approaching explicit CoT accuracy and outperforming prior iCoT distillation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoRi, a low-rank distillation framework for implicit chain-of-thought (iCoT) reasoning in LLMs. Motivated by the empirical observation that hidden-state reasoning trajectories exhibit low-rank structure, it aligns teacher and student trajectories in a shared low-rank tensor subspace using first- and second-order statistics. This is claimed to capture global reasoning structure while enabling compact latent reasoning. Evaluations across LLaMA and Qwen model families on mathematical reasoning benchmarks show consistent improvements, especially on multi-step tasks, approaching explicit CoT accuracy and outperforming prior iCoT distillation methods.
Significance. If the low-rank subspace alignment via moment matching preserves the essential reasoning computation, the method could offer an efficient, inference-cost-free way to internalize multi-step reasoning in smaller models. This would advance iCoT techniques by providing a theoretically motivated distillation objective grounded in an observed structural property of trajectories.
major comments (2)
- [Abstract / Method description] The central claim that first- and second-order alignment in the low-rank tensor subspace suffices to transfer multi-step reasoning rests on the untested assumption that higher-order or path-dependent statistics are irrelevant once the subspace is matched. The abstract provides no analysis showing that the orthogonal complement or non-Gaussian structure of trajectories does not contain critical sequential dependencies required for the observed gains on challenging tasks.
- [Experiments / Evaluation] The reported improvements are described only qualitatively ('consistently improves', 'approaching explicit CoT accuracy'). Without access to exact performance deltas, ablation results isolating the low-rank component, or statistical significance tests, it is impossible to determine whether the gains are load-bearing evidence for the subspace-alignment hypothesis or could arise from other implementation choices.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific mathematical reasoning benchmarks and model scales used in the evaluation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We respond to each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Method description] The central claim that first- and second-order alignment in the low-rank tensor subspace suffices to transfer multi-step reasoning rests on the untested assumption that higher-order or path-dependent statistics are irrelevant once the subspace is matched. The abstract provides no analysis showing that the orthogonal complement or non-Gaussian structure of trajectories does not contain critical sequential dependencies required for the observed gains on challenging tasks.
Authors: The framework is directly motivated by our empirical observation that reasoning trajectories in hidden states exhibit low-rank structure; the first- and second-order moment matching is intended to align the dominant global structure within the shared subspace. We acknowledge that the manuscript does not contain an explicit analysis of higher-order statistics, path-dependent properties, or the information content of the orthogonal complement. The performance gains on multi-step tasks provide supporting evidence, yet we agree this leaves an assumption untested. We will revise the method and discussion sections to state this limitation more explicitly and outline directions for future analysis of non-Gaussian or sequential dependencies. revision: partial
-
Referee: [Experiments / Evaluation] The reported improvements are described only qualitatively ('consistently improves', 'approaching explicit CoT accuracy'). Without access to exact performance deltas, ablation results isolating the low-rank component, or statistical significance tests, it is impossible to determine whether the gains are load-bearing evidence for the subspace-alignment hypothesis or could arise from other implementation choices.
Authors: The full manuscript contains tables reporting exact accuracy deltas for LLaMA and Qwen models across the mathematical reasoning benchmarks, together with ablation studies that isolate the low-rank subspace alignment from other implementation choices. To strengthen the evidence, we will add statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) in the revised version and ensure the quantitative results are presented with greater prominence. revision: yes
Circularity Check
No circularity; method is empirically motivated and evaluated
full rationale
The paper states an empirical observation that hidden-state trajectories exhibit low-rank structure, then proposes an alignment method in that subspace using first- and second-order statistics. This is presented as a motivated framework whose effectiveness is assessed via benchmark evaluations across model families, with no derivation chain, self-citations, fitted parameters renamed as predictions, or self-definitional steps visible in the provided text. The central performance claims rest on external experimental results rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NeurIPS , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. NeurIPS , year=
-
[2]
International Conference on Learning Representations , month=
Towards Robust Neural Networks via Close-loop Control , author=. International Conference on Learning Representations , month=
-
[3]
Journal of machine learning research , volume=
Self-healing robust neural networks via closed-loop control , author=. Journal of machine learning research , volume=
-
[4]
2024 , publisher=
Chen, Zhuotong and Wang, Zihu and Yang, Yifan and Li, Qianxiao and Zhang, Zheng , journal=. 2024 , publisher=
2024
-
[5]
Liu, Ziyue and Zhang, Ruijie and Wang, Zhengyang and Yan, Mingsong and Yang, Zi and Hovland, Paul D and Nicolae, Bogdan and Cappello, Franck and Tang, Sui and Zhang, Zheng , booktitle=
-
[6]
arXiv preprint arXiv:2502.21074 , year =
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation , author =. arXiv preprint arXiv:2502.21074 , year =
-
[7]
arXiv preprint arXiv:2510.02312 , year =
KaVa: Latent Reasoning via Compressed KV-Cache Distillation , author =. arXiv preprint arXiv:2510.02312 , year =
-
[8]
arXiv preprint arXiv:2509.20317 , year =
SIM-CoT: Supervised Implicit Chain-of-Thought , author =. arXiv preprint arXiv:2509.20317 , year =
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Compressing Transformers: Features Are Low-Rank, but Weights Are Not! , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2023 , doi =
2023
-
[10]
arXiv preprint arXiv:2510.24966 , year =
Sequences of Logits Reveal the Low Rank Structure of Language Models , author =. arXiv preprint arXiv:2510.24966 , year =
-
[11]
Proceedings of the 41st International Conference on Machine Learning (ICML) , series =
The Linear Representation Hypothesis and the Geometry of Large Language Models , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , series =. 2024 , publisher =
2024
-
[12]
arXiv preprint arXiv:2604.05655 , year=
LLM Reasoning as Trajectories: Step-Specific Representation Geometry and Correctness Signals , author=. arXiv preprint arXiv:2604.05655 , year=
-
[13]
arXiv preprint arXiv:2505.18235 , year=
The Origins of Representation Manifolds in Large Language Models , author=. arXiv preprint arXiv:2505.18235 , year=
-
[14]
Journal of the American Mathematical Society , volume=
Testing the Manifold Hypothesis , author=. Journal of the American Mathematical Society , volume=
-
[15]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Representation Learning: A Review and New Perspectives , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2013 , doi=
2013
-
[16]
arXiv preprint arXiv:2509.22518 , year=
REMA: A Unified Reasoning Manifold Framework for Interpreting Large Language Models , author=. arXiv preprint arXiv:2509.22518 , year=
-
[17]
International Conference on Learning Representations (ICLR) , year=
The Geometry of Reasoning: Flowing Logics in Representation Space , author=. International Conference on Learning Representations (ICLR) , year=
-
[18]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
2022
-
[19]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems , author =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[20]
Advances in Neural Information Processing Systems , year =
STaR: Bootstrapping Reasoning With Reasoning , author =. Advances in Neural Information Processing Systems , year =
-
[21]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM’s Reasoning Capability , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[22]
arXiv preprint arXiv:2203.11171 , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. arXiv preprint arXiv:2203.11171 , year =
-
[23]
arXiv preprint arXiv:2601.08058 , year =
Reasoning Beyond Chain-of-Thought: A Latent Computational Mode in Large Language Models , author =. arXiv preprint arXiv:2601.08058 , year =
-
[24]
Advances in Neural Information Processing Systems , year =
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[25]
arXiv preprint arXiv:2509.02350 , year =
Implicit Reasoning in Large Language Models: A Comprehensive Survey , author =. arXiv preprint arXiv:2509.02350 , year =
-
[26]
arXiv preprint arXiv:2405.14838 , year =
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step , author =. arXiv preprint arXiv:2405.14838 , year =
-
[27]
arXiv preprint arXiv:2412.06769 , year =
Training Large Language Models to Reason in a Continuous Latent Space , author =. arXiv preprint arXiv:2412.06769 , year =
-
[28]
arXiv preprint arXiv:2506.18582 , year =
Parallel Continuous Chain-of-Thought with Jacobi Iteration , author =. arXiv preprint arXiv:2506.18582 , year =
-
[29]
arXiv preprint arXiv:2409.12183 , year=
To CoT or Not to CoT? Chain-of-Thought Helps Mainly on Math and Symbolic Reasoning , author=. arXiv preprint arXiv:2409.12183 , year=
-
[30]
The Llama 3 Herd of Models , author=. arXiv:2407.21783 , year=
-
[31]
Qwen Technical Report , author=. arXiv:2309.16609 , eprint=
-
[32]
arXiv preprint at arXiv:2311.01460 , year=
Implicit Chain-of-Thought Reasoning via Knowledge Distillation , author=. arXiv preprint at arXiv:2311.01460 , year=
-
[33]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[34]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , year=
SVAMP: A Dataset of Verbally Perturbed Math Word Problems , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , year=
2021
-
[35]
arXiv , eprint=
PAL: Program-Aided Language Models , author=. arXiv , eprint=
-
[36]
SIAM Journal on Matrix Analysis and Applications , volume=
A Multilinear Singular Value Decomposition , author=. SIAM Journal on Matrix Analysis and Applications , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.