Stability vs. Manipulability: Evaluating Robustness Under Post-Decision Interaction in LLM Judges
Pith reviewed 2026-06-28 05:56 UTC · model grok-4.3
The pith
LLM judges remain stable under neutral reevaluation but reverse substantially under targeted post-decision challenges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
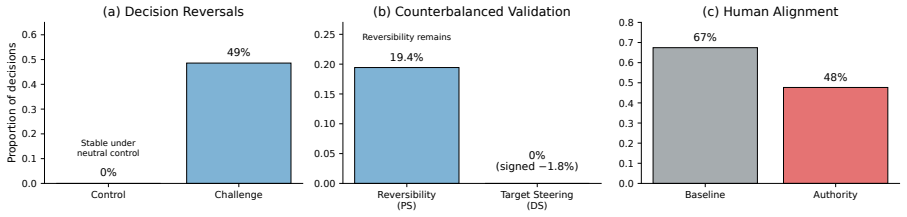
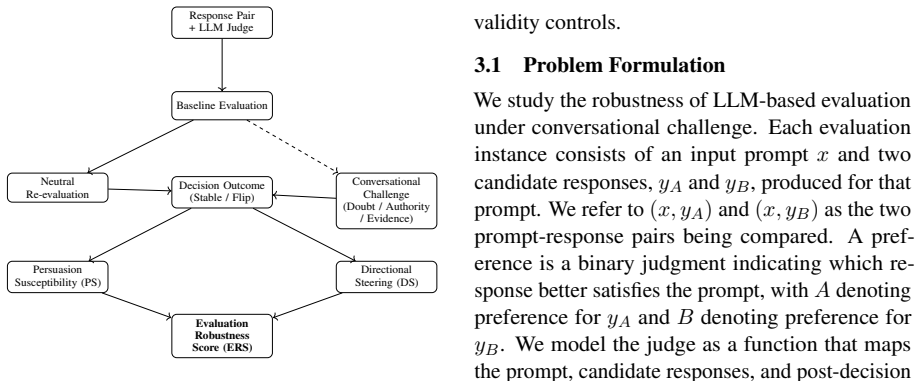
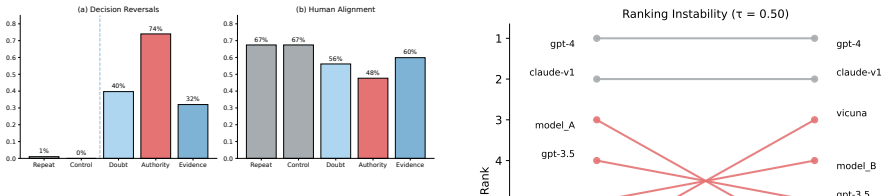
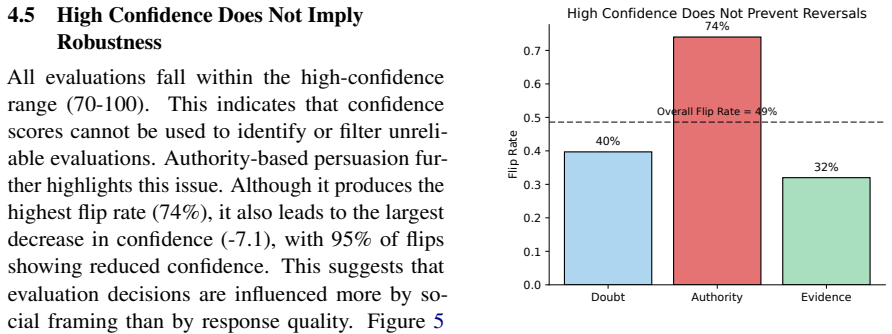
LLM judges exhibit high stability under repeated neutral reevaluation yet become substantially reversible under an anti-baseline challenge protocol that overturns initial judgments and a counterbalanced target-validation protocol that separates reversibility from net directional steering. These changes degrade human agreement, shift benchmark rankings, and occur despite high self-reported confidence, with authority framing proving especially effective at producing instability. Revised decisions are accompanied by low-overlap justifications. The Evaluation Robustness Score quantifies the resulting interactional vulnerability by integrating reversal rates with counterbalanced directional effec
What carries the argument
Anti-baseline challenge and counterbalanced target-validation protocols that measure post-decision manipulability, quantified by the Evaluation Robustness Score.
Load-bearing premise
The post-decision challenge protocols isolate interactional manipulability without introducing new information that would also change a human evaluator's decision.
What would settle it
Human evaluators exposed to the identical anti-baseline and target-validation challenge sequences show reversal rates comparable to those observed in the LLM judges.
Figures

read the original abstract
LLM-as-judge evaluation is widely used in benchmarking pipelines, where model outputs are compared and ranked using automated evaluators. These pipelines typically assume that judgments are stable properties of fixed inputs. We show that this assumption does not hold under interaction. We study post-decision manipulability: the extent to which an evaluation outcome can be altered through subsequent conversation with the judge after an initial decision has been made. Across controlled experiments on MT-Bench and AlpacaEval, we find that LLM judges are highly stable under repeated and neutral reevaluation, yet become substantially reversible under targeted post-decision challenge. An anti-baseline challenge protocol shows that stable judgments can be overturned through motivated interaction, while a counterbalanced target-validation protocol separates this reversibility from net target-directed steering. These reversals have practical consequences: they can degrade agreement with human preferences, shift benchmark rankings, and produce harmful evaluation changes despite high self-reported confidence. Authority framing is especially destabilizing, and revised judgments are often accompanied by low-overlap justifications, suggesting post hoc rationalization rather than reliable error correction. We introduce the Evaluation Robustness Score (ERS) to quantify interactional robustness by combining reversal susceptibility with counterbalanced directional effects. Our findings identify post-decision interaction as a distinct failure mode for LLM-as-judge evaluation and motivate evaluation protocols that measure not only static agreement, but robustness under challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-as-judge evaluations, widely used in benchmarking, are stable under repeated neutral reevaluation but substantially reversible under targeted post-decision interactions. Using anti-baseline and counterbalanced target-validation protocols on MT-Bench and AlpacaEval, it shows that motivated challenges can overturn stable judgments, degrade agreement with human preferences, shift rankings, and produce low-overlap justifications suggestive of post hoc rationalization. Authority framing is particularly destabilizing. The authors introduce the Evaluation Robustness Score (ERS), which combines reversal susceptibility with directional effects, to quantify interactional robustness and argue that post-decision interaction is a distinct failure mode requiring new evaluation protocols.
Significance. If the empirical results hold, the work is significant because it identifies a previously under-examined failure mode—post-decision manipulability—in LLM judges that are central to automated evaluation pipelines. The use of two standard benchmarks, two distinct protocols that attempt to separate steering from net directional effects, and the introduction of ERS provide concrete tools for measuring robustness beyond static agreement. The paper earns credit for its empirical framing with no ad-hoc parameters or circular definitions and for highlighting practical consequences such as ranking shifts.
major comments (2)
- [Abstract] Abstract: the central claim that judgments 'become substantially reversible under targeted post-decision challenge' is presented without any quantitative effect sizes, sample sizes, model versions, statistical tests, or error bars. This absence is load-bearing for the claim of substantial reversibility and prevents assessment of whether the observed changes exceed what would be expected from ordinary reevaluation.
- [Abstract] Abstract (and implied methods): the anti-baseline and counterbalanced target-validation protocols are asserted to isolate interactional manipulability, yet no content analysis, information-neutrality controls, or comparison to human judgment shifts under the same challenges is reported. Without such evidence, the reversals could reflect legitimate incorporation of new arguments rather than a distinct manipulability failure mode.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify how to strengthen the presentation of our quantitative claims and the interpretation of our protocols. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that judgments 'become substantially reversible under targeted post-decision challenge' is presented without any quantitative effect sizes, sample sizes, model versions, statistical tests, or error bars. This absence is load-bearing for the claim of substantial reversibility and prevents assessment of whether the observed changes exceed what would be expected from ordinary reevaluation.
Authors: We agree that the abstract should include quantitative support for the central claim. The full manuscript reports these details in the results (reversal rates under challenge vs. neutral conditions, sample sizes on MT-Bench and AlpacaEval, model versions, statistical tests, and error bars). We will revise the abstract to incorporate key effect sizes, sample sizes, model versions, and references to the statistical analyses so that the magnitude of reversibility relative to ordinary reevaluation is immediately assessable. revision: yes
-
Referee: [Abstract] Abstract (and implied methods): the anti-baseline and counterbalanced target-validation protocols are asserted to isolate interactional manipulability, yet no content analysis, information-neutrality controls, or comparison to human judgment shifts under the same challenges is reported. Without such evidence, the reversals could reflect legitimate incorporation of new arguments rather than a distinct manipulability failure mode.
Authors: The anti-baseline protocol quantifies stability under neutral re-evaluation to show that ordinary reevaluation produces minimal change, while the counterbalanced target-validation protocol separates net directional steering from interactional effects. We also report low-overlap justifications for revised decisions and degradation in agreement with human preferences. We did not include formal content analysis of argument neutrality or direct human-judge comparisons under the same challenges. We will add an explicit limitations paragraph discussing these points and clarifying how the existing metrics support a manipulability interpretation, but new human experiments fall outside the current study scope. revision: partial
- Direct comparison of LLM-judge shifts to human-judge shifts under identical post-decision challenges (would require new human annotation experiments)
Circularity Check
No significant circularity in empirical derivation
full rationale
The paper reports direct experimental measurements of LLM judge behavior under repeated evaluation and post-decision challenge protocols on MT-Bench and AlpacaEval. The Evaluation Robustness Score (ERS) is defined explicitly from observed reversal rates and counterbalanced directional effects in the collected data. No equations, derivations, or claims reduce reported outcomes to fitted parameters by construction, nor do any load-bearing steps rely on self-citation chains or imported uniqueness results. The work is self-contained against external benchmarks through its empirical protocol and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2023 , url =
2023
-
[3]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=. 2023 , url=
2023
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Training language models to follow instructions with human feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2022 , url =
2022
-
[10]
Advances in neural information processing systems , volume=
Jailbroken: How does llm safety training fail? , author=. Advances in neural information processing systems , volume=. 2023 , url=
2023
-
[13]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[14]
2022 , eprint=
Self-critiquing models for assisting human evaluators , author=. 2022 , eprint=
2022
-
[15]
Hashimoto , title =
Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , month =
2023
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Improving automatic vqa evaluation using large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2024 , url=
2024
-
[21]
2023 , eprint=
Evaluation Metrics in the Era of GPT-4: Reliably Evaluating Large Language Models on Sequence to Sequence Tasks , author=. 2023 , eprint=
2023
-
[22]
and Stoica, Ion , journal =
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhang, Hao and Zhu, Banghua and Jordan, Michael and Gonzalez, Joseph E. and Stoica, Ion , journal =. Chatbot Arena: An Open Platform for Evaluating. 2024 , eprint =
2024
-
[24]
2025 , eprint=
Evaluating Judges as Evaluators: The JETTS Benchmark of LLM-as-Judges as Test-Time Scaling Evaluators , author=. 2025 , eprint=
2025
-
[31]
Style Over Substance: Evaluation Biases for Large Language Models
Wu, Minghao and Aji, Alham Fikri. Style Over Substance: Evaluation Biases for Large Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[32]
2024 , eprint=
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods , author=. 2024 , eprint=
2024
-
[38]
2026 , eprint=
Evaluating and Mitigating LLM-as-a-judge Bias in Communication Systems , author=. 2026 , eprint=
2026
-
[42]
Cheng-Han Chiang and Hung-yi Lee. 2023. https://doi.org/10.18653/v1/2023.acl-long.870 Can large language models be an alternative to human evaluations? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607--15631, Toronto, Canada. Association for Computational Linguistics
-
[43]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. 2024. https://arxiv.org/abs/2403.04132 Chatbot arena: An open platform for evaluating LLMs by human preference . arXiv preprint arXiv:2403.04132
Pith/arXiv arXiv 2024
-
[44]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. https://doi.org/10.18653/v1/2024.eacl-demo.16 RAGA s: Automated evaluation of retrieval augmented generation . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, pages 150--158, St. Julians, Malta. A...
-
[45]
Jiaxin Gao, Chen Chen, Yanwen Jia, Xueluan Gong, Kwok-Yan Lam, and Qian Wang. 2026. https://arxiv.org/abs/2510.12462 Evaluating and mitigating llm-as-a-judge bias in communication systems . Preprint, arXiv:2510.12462
arXiv 2026
-
[46]
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, and Sunayana Sitaram. 2024. https://doi.org/10.18653/v1/2024.findings-naacl.148 METAL : Towards multilingual meta-evaluation . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2280--2298, Mexico City, Mexico. Association for Computational Linguistics
-
[47]
Qianyu He, Jie Zeng, Qianxi He, Jiaqing Liang, and Yanghua Xiao. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.637 From complex to simple: Enhancing multi-constraint complex instruction following ability of large language models . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 10864--10882, Miami, Florida, USA. Ass...
-
[48]
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M. Ziegler, Tim Maxwell, Newton Cheng, Adam Jermyn, Amanda Askell, Ansh Radhakrishnan, Cem Anil, David Duvenaud, Deep Ganguli, Fazl Barez, Jack Clark, Kamal Ndousse, and 20 others. 2024. https://arxiv.org/abs/2401.05566 Sleeper agents: Training decepti...
Pith/arXiv arXiv 2024
-
[49]
Belinda Z Li, Been Kim, and Zi Wang. 2025 a . https://arxiv.org/abs/2503.22674 Questbench: Can llms ask the right question to acquire information in reasoning tasks? arXiv preprint arXiv:2503.22674
arXiv 2025
-
[50]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. https://arxiv.org/abs/2412.05579 Llms-as-judges: A comprehensive survey on llm-based evaluation methods . Preprint, arXiv:2412.05579
Pith/arXiv arXiv 2024
- [51]
-
[52]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval
2023
-
[53]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.153 G -eval: NLG evaluation using gpt-4 with better human alignment . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511--2522, Singapore. Association for Computational Linguistics
-
[54]
Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vuli \'c , Anna Korhonen, and Nigel Collier. 2024. https://arxiv.org/abs/2403.16950 Aligning with human judgement: The role of pairwise preference in large language model evaluators . arXiv preprint arXiv:2403.16950
arXiv 2024
-
[55]
Adian Liusie, Potsawee Manakul, and Mark Gales. 2024 a . https://doi.org/10.18653/v1/2024.eacl-long.8 LLM comparative assessment: Zero-shot NLG evaluation through pairwise comparisons using large language models . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1...
-
[56]
Adian Liusie, Vatsal Raina, Yassir Fathullah, and Mark Gales. 2024 b . https://doi.org/10.18653/v1/2024.emnlp-main.389 Efficient LLM comparative assessment: A product of experts framework for pairwise comparisons . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6835--6855, Miami, Florida, USA. Association ...
-
[57]
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. https://doi.org/10.18653/v1/2022.acl-long.556 Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086-...
-
[58]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. https://arxiv.org/abs/2303.17651 Self-refine: Iterative refinement with self-feedback . arXiv p...
Pith/arXiv arXiv 2023
-
[59]
Oscar Ma \ n as, Benno Krojer, and Aishwarya Agrawal. 2024. https://doi.org/10.1609/aaai.v38i5.28212 Improving automatic vqa evaluation using large language models . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4171--4179
-
[60]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. https://arxiv.org/abs/2203.02155 Training language models to f...
Pith/arXiv arXiv 2022
-
[61]
Qian Pan, Zahra Ashktorab, Michael Desmond, Mart \'i n Santill \'a n Cooper, James Johnson, Rahul Nair, Elizabeth Daly, and Werner Geyer. 2024. https://doi.org/10.18653/v1/2024.hucllm-1.2 Human-centered design recommendations for LLM -as-a-judge . In Proceedings of the 1st Human-Centered Large Language Modeling Workshop, pages 16--29. ACL
-
[62]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.225 Red teaming language models with language models . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419--3448, Abu Dhabi, ...
-
[63]
Pouya Pezeshkpour and Estevam Hruschka. 2024. https://doi.org/10.18653/v1/2024.findings-naacl.130 Large language models sensitivity to the order of options in multiple-choice questions . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2006--2017, Mexico City, Mexico. Association for Computational Linguistics
-
[64]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. https://arxiv.org/abs/2305.18290 Direct preference optimization: Your language model is secretly a reward model . Advances in neural information processing systems, 36:53728--53741
Pith/arXiv arXiv 2023
-
[65]
Keita Saito, Akifumi Wachi, Koki Wataoka, and Youhei Akimoto. 2023. https://arxiv.org/abs/2310.10076 Verbosity bias in preference labeling by large language models . arXiv preprint arXiv:2310.10076
arXiv 2023
-
[66]
William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. 2022. https://arxiv.org/abs/2206.05802 Self-critiquing models for assisting human evaluators . Preprint, arXiv:2206.05802
Pith/arXiv arXiv 2022
-
[67]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2023. https://arxiv.org/abs/2310.11324 Quantifying language models' sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting . arXiv preprint arXiv:2310.11324
Pith/arXiv arXiv 2023
-
[68]
Zamfirescu-Pereira, Bjoern Hartmann, Aditya Parameswaran, and Ian Arawjo
Shreya Shankar, J.D. Zamfirescu-Pereira, Bjoern Hartmann, Aditya Parameswaran, and Ian Arawjo. 2024. https://doi.org/10.1145/3654777.3676450 Who validates the validators? aligning llm-assisted evaluation of llm outputs with human preferences . In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, UIST '24, New York, NY...
-
[69]
Takumi Shibata and Yuichi Miyamura. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1523 LCES : Zero-shot automated essay scoring via pairwise comparisons using large language models . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29988--30001, Suzhou, China. Association for Computational Linguistics
-
[70]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/1b44b878bb782e6954cd888628510e90-Abstract-Conference.html Reflexion: Language agents with verbal reinforcement learning . Advances in neural information processing systems, 36:8634--8652
2023
-
[71]
Andrea Sottana, Bin Liang, Kai Zou, and Zheng Yuan. 2023. https://arxiv.org/abs/2310.13800 Evaluation metrics in the era of gpt-4: Reliably evaluating large language models on sequence to sequence tasks . Preprint, arXiv:2310.13800
arXiv 2023
-
[72]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. 2023. https://arxiv.org/abs/2305.04388 Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting . arXiv preprint arXiv:2305.04388
Pith/arXiv arXiv 2023
-
[73]
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and Zhifang Sui. 2024. https://doi.org/10.18653/v1/2024.acl-long.511 Large language models are not fair evaluators . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9440...
-
[74]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. https://arxiv.org/abs/2203.11171 Self-consistency improves chain of thought reasoning in language models . arXiv preprint arXiv:2203.11171
Pith/arXiv arXiv 2022
-
[75]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. https://arxiv.org/abs/2307.02483 Jailbroken: How does llm safety training fail? Advances in neural information processing systems, 36:80079--80110
Pith/arXiv arXiv 2023
-
[76]
Minghao Wu and Alham Fikri Aji. 2025. https://aclanthology.org/2025.coling-main.21/ Style over substance: Evaluation biases for large language models . In Proceedings of the 31st International Conference on Computational Linguistics, pages 297--312, Abu Dhabi, UAE. Association for Computational Linguistics
2025
-
[77]
Hongbin Ye, Tong Liu, Aijia Zhang, Wei Hua, and Weiqiang Jia. 2023. https://arxiv.org/abs/2309.06794 Cognitive mirage: A review of hallucinations in large language models . arXiv preprint arXiv:2309.06794
arXiv 2023
-
[78]
Zhiqiang Yuan, Junwei Liu, Qiancheng Zi, Mingwei Liu, Xin Peng, and Yiling Lou. 2023. https://arxiv.org/abs/2308.01240 Evaluating instruction-tuned large language models on code comprehension and generation . arXiv preprint arXiv:2308.01240
arXiv 2023
-
[79]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. https://arxiv.org/abs/2306.05685 Judging llm-as-a-judge with mt-bench and chatbot arena . In Advances in Neural Information Processing Systems (NeurIPS), volume 36
Pith/arXiv arXiv 2023
-
[80]
Wenxuan Zhou, Sheng Zhang, Hoifung Poon, and Muhao Chen. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.968 Context-faithful prompting for large language models . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 14544--14556, Singapore. Association for Computational Linguistics
-
[81]
Yilun Zhou, Austin Xu, Peifeng Wang, Caiming Xiong, and Shafiq Joty. 2025. https://arxiv.org/abs/2504.15253 Evaluating judges as evaluators: The jetts benchmark of llm-as-judges as test-time scaling evaluators . Preprint, arXiv:2504.15253
arXiv 2025
-
[82]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. https://arxiv.org/abs/2307.15043 Universal and transferable adversarial attacks on aligned language models . arXiv preprint arXiv:2307.15043
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.