Ten Headache Specialists versus Artificial Intelligence for Clinical Literature Summarization: A Critical Evaluation and Comparison
Pith reviewed 2026-06-28 06:00 UTC · model grok-4.3
The pith
Headache specialists rated their own literature summaries higher than those from three leading AI models, though they often could not identify the source.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
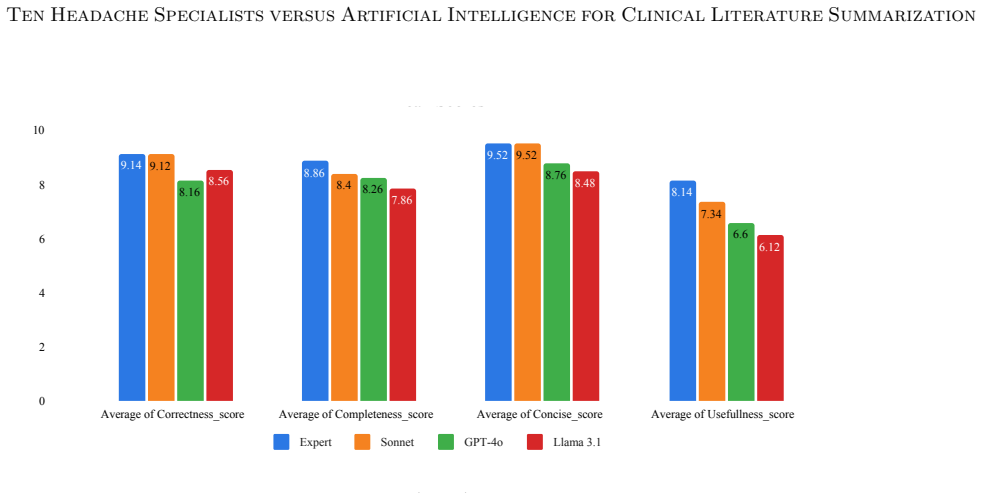
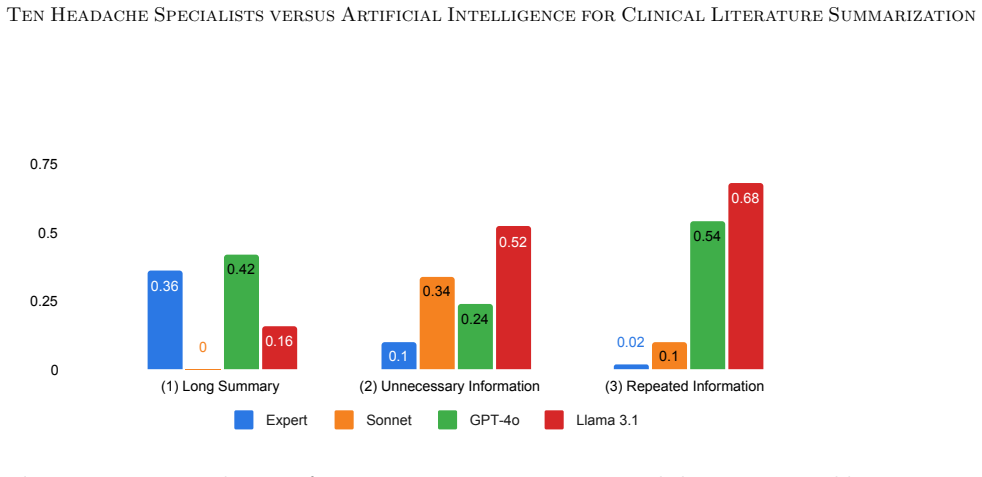
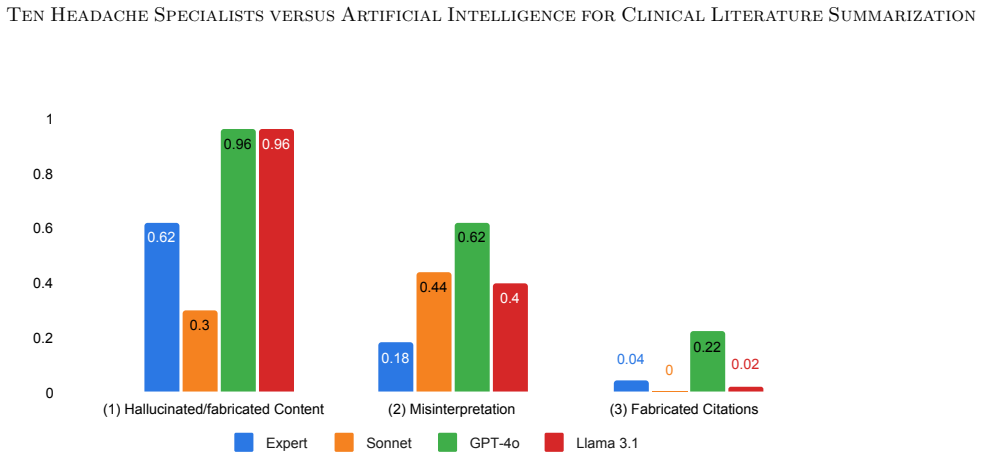
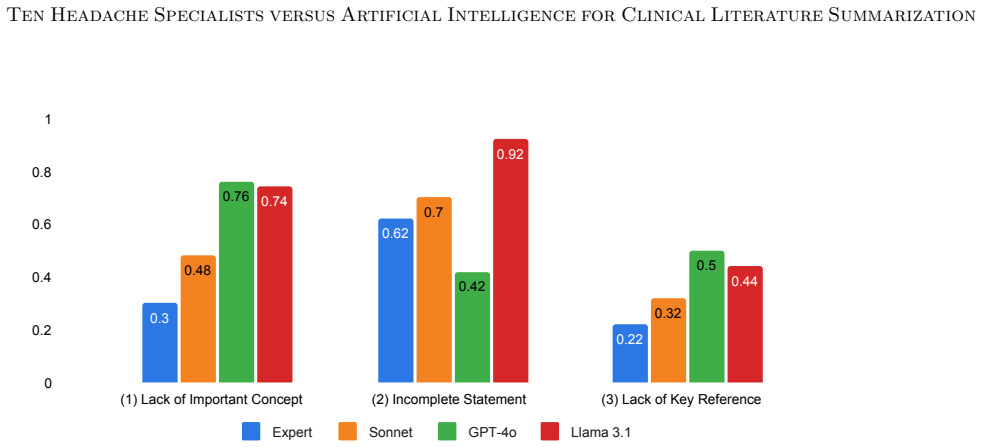
Expert-written summaries were preferred by the evaluating specialists over the three LLM outputs, although the specialists sometimes found it challenging to distinguish between human- and AI-generated summaries. The study also identified expert-valued features beyond standard metrics that can guide refinement of summarization pipelines.
What carries the argument
Blinded ranking and rubric scoring by ten headache specialists of four summaries per question (one expert-written, three from an RAG-based agentic LLM framework using Sonnet, GPT-4o, and Llama 3.1).
If this is right
- Expert summaries currently outperform the tested LLM outputs on clinical utility for headache literature.
- AI summaries can sometimes pass as expert work under blinded review.
- Features experts value, such as depth of clinical insight, can be used to improve both human and AI summarization.
- The current RAG agentic setup supplies a concrete baseline for measuring future progress in medical literature synthesis.
Where Pith is reading between the lines
- The difficulty distinguishing sources suggests AI may already capture much of the surface structure experts use.
- Extending the same blinded protocol to other medical fields could reveal whether the expert preference holds more broadly.
- Incorporating the additional expert-valued features into LLM prompts might narrow the observed gap in future tests.
Load-bearing premise
The judgments of these ten specialists using the chosen rubrics and questions provide a reliable standard for clinical summary quality.
What would settle it
A repeat of the blinded evaluation with a different set of specialists or questions in which AI summaries receive equal or higher preference rankings would undermine the claim that expert summaries are superior.
Figures
read the original abstract
Summarizing the latest medical literature to guide clinical decision-making is essential for evidence-based medicine and high-quality patient care. Yet clinicians face increasing challenges due to limited time with patients and a rapidly growing volume of published articles. Although retrieval-augmented large language models (LLMs) have shown promise in clinical summarization, human evaluations of their effectiveness in synthesizing broader scientific literature and direct comparisons to expert-written syntheses remain scarce. We constructed a RAG-based agentic AI framework using three state-of-the-art LLMs: Sonnet, GPT-4o, and Llama 3.1. A headache specialist created 13 questions, three for prompt optimization and ten for evaluation. Ten headache specialists across the United States and Canada each wrote a summary for one question, yielding four summaries per question (expert, Sonnet, GPT-4o, and Llama). The experts, blinded to authorship, critically evaluated the summaries, excluding the topic for which they wrote a summary, based on correctness, completeness, conciseness, and clinical utility, scoring each from 1 to 10 using standardized rubrics. They also ranked the summaries by preference and indicated whether they believed each summary was written by an expert or an LLM. Our study, comparing LLM- and expert-written literature summaries evaluated by headache specialists, showed that expert-written summaries were preferred, although experts sometimes found it challenging to distinguish between human- and AI-generated summaries. We also identified key expert-valued features beyond standard evaluation metrics that can guide future refinement of both human and AI literature summarization pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical comparison of literature summaries on 10 headache-related clinical questions. One specialist created the questions; each of 10 specialists authored one expert summary; a RAG-based agentic system using Claude Sonnet, GPT-4o, and Llama 3.1 generated three AI summaries per question. The same 10 specialists, blinded to authorship and excluding their own question, scored all summaries on standardized rubrics for correctness, completeness, conciseness, and clinical utility (1-10), ranked them by preference, and guessed human vs. LLM authorship. The central result is that expert summaries were preferred, although experts sometimes could not reliably distinguish authorship.
Significance. If the preference result holds under independent scrutiny, the work supplies a rare head-to-head, domain-expert evaluation of current LLM summarization against human experts in a narrow but clinically relevant field. The blinded protocol, use of four distinct rubrics, and inclusion of three frontier models constitute concrete strengths that allow direct comparison of what specialists actually value. The identification of additional expert-valued features beyond the rubrics offers actionable guidance for future RAG and agentic systems.
major comments (2)
- [Methods] Methods (study design paragraph): the same 10 specialists both authored the expert summaries and performed all rubric scoring and ranking (each evaluating the nine questions they did not author). Although authorship blinding is employed, the shared clinical perspective and internal standards for 'correctness' and 'clinical utility' are therefore present in both the reference outputs and the evaluation criteria. This design choice directly affects the strength of the claim that expert summaries are objectively preferred.
- [Results] Results (preference and rubric-score analysis): no inter-rater reliability statistics (e.g., Fleiss' kappa, ICC, or pairwise agreement) are reported for the 1-10 rubric scores or the ranking data. Given the subjective nature of clinical utility judgments and the modest number of evaluators (n=10) and questions (n=10), absence of these metrics leaves the reliability of the reported preference ordering unclear.
minor comments (2)
- [Abstract] Abstract: the sentence 'A headache specialist created 13 questions, three for prompt optimization and ten for evaluation' should explicitly note that the ten evaluation questions form the basis of all reported comparisons.
- [Discussion] The manuscript would benefit from a short limitations subsection that discusses the single-specialty focus and the modest sample of questions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond to each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Methods] Methods (study design paragraph): the same 10 specialists both authored the expert summaries and performed all rubric scoring and ranking (each evaluating the nine questions they did not author). Although authorship blinding is employed, the shared clinical perspective and internal standards for 'correctness' and 'clinical utility' are therefore present in both the reference outputs and the evaluation criteria. This design choice directly affects the strength of the claim that expert summaries are objectively preferred.
Authors: We acknowledge that the use of the same specialists for both authoring and evaluating the summaries introduces a shared clinical perspective that could influence judgments of correctness and utility. This design was selected to ensure evaluations by practicing domain experts, and blinding plus exclusion of each rater's own summary were employed to reduce bias. The manuscript reports a preference among these specialists rather than claiming objective superiority; however, we agree the design warrants explicit discussion as a limitation. In revision we will add a paragraph in the Discussion section addressing this point and will adjust wording in the abstract and conclusions to avoid any implication of objectivity beyond the evaluated group. revision: partial
-
Referee: [Results] Results (preference and rubric-score analysis): no inter-rater reliability statistics (e.g., Fleiss' kappa, ICC, or pairwise agreement) are reported for the 1-10 rubric scores or the ranking data. Given the subjective nature of clinical utility judgments and the modest number of evaluators (n=10) and questions (n=10), absence of these metrics leaves the reliability of the reported preference ordering unclear.
Authors: We agree that reporting inter-rater reliability is necessary given the subjective elements of the rubrics and the sample size. In the revised manuscript we will compute and present Fleiss' kappa for the rubric scores across the four summary types and appropriate agreement metrics (e.g., Kendall's W or percentage agreement) for the preference rankings. revision: yes
Circularity Check
Empirical evaluation study with no derivation chain or fitted predictions
full rationale
This is a human-subject evaluation study comparing LLM-generated and expert-written summaries on 13 clinical questions. All quality scores, rankings, and authorship guesses derive directly from blinded ratings by the ten specialists; there are no equations, parameters fitted to data subsets, predictions of held-out quantities, self-citation chains, or ansatzes. The design contains no mathematical derivation that could reduce to its own inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ArXiv , year=
Matching patients to clinical trials with large language models , author=. ArXiv , year=
-
[2]
2020 , journal=
Intelligent Clinical Trials , author=. 2020 , journal=
2020
-
[3]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Therapeutic Innovation & Regulatory Science , volume=
Improving clinical trial participant prescreening with artificial intelligence (AI): a comparison of the results of AI-assisted vs standard methods in 3 oncology trials , author=. Therapeutic Innovation & Regulatory Science , volume=. 2020 , publisher=
2020
-
[5]
AMIA Annual Symposium Proceedings , volume=
Large language models for healthcare data augmentation: An example on patient-trial matching , author=. AMIA Annual Symposium Proceedings , volume=. 2023 , organization=
2023
-
[6]
Center for Biologics Evaluation and Research Center for Drug Evaluation and Research
Enhancing the diversity of clinical trial populations—eligibility criteria, enrollment practices, and trial designs guidance for industry , author=. Center for Biologics Evaluation and Research Center for Drug Evaluation and Research. https://www. fda. gov/regulatory-information/search-fda-guidance-documents/enhancing-diversity-clinical-trial-populations-...
-
[7]
Journal of medical Internet research , volume=
Online patient recruitment in clinical trials: systematic review and meta-analysis , author=. Journal of medical Internet research , volume=. 2020 , publisher=
2020
-
[8]
Nature , volume=
An AI boost for clinical trials , author=. Nature , volume=. 2019 , publisher=
2019
-
[9]
International Journal of Environmental Research and Public Health , volume=
Benefits of Participation in Clinical Trials: An Umbrella Review , author=. International Journal of Environmental Research and Public Health , volume=. 2022 , publisher=
2022
-
[10]
Clinical Trials , volume =
Louise Locock and Lorraine Smith , title =. Clinical Trials , volume =. 2011 , doi =
2011
-
[11]
Nature , volume=
Evaluating eligibility criteria of oncology trials using real-world data and AI , author=. Nature , volume=. 2021 , publisher=
2021
-
[12]
medRxiv , pages=
Assessing the Potential of USMLE-Like Exam Questions Generated by GPT-4 , author=. medRxiv , pages=. 2023 , publisher=
2023
-
[13]
NEJM AI , pages=
Using ChatGPT to Facilitate Truly Informed Medical Consent , author=. NEJM AI , pages=. 2024 , publisher=
2024
-
[14]
arXiv preprint arXiv:2401.05654 , year=
Towards Conversational Diagnostic AI , author=. arXiv preprint arXiv:2401.05654 , year=
-
[15]
Machine Learning for Health (ML4H) , pages=
LLMs Accelerate Annotation for Medical Information Extraction , author=. Machine Learning for Health (ML4H) , pages=. 2023 , organization=
2023
-
[16]
arXiv preprint arXiv:1703.08705 , year=
Comparing rule-based and deep learning models for patient phenotyping , author=. arXiv preprint arXiv:1703.08705 , year=
-
[17]
Journal of the American Medical Informatics Association , volume=
Evaluating shallow and deep learning strategies for the 2018 n2c2 shared task on clinical text classification , author=. Journal of the American Medical Informatics Association , volume=. 2019 , publisher=
2018
-
[18]
arXiv preprint arXiv:2401.04088 , year=
Mixtral of Experts , author=. arXiv preprint arXiv:2401.04088 , year=
-
[19]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[20]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[21]
IEEE transactions on pattern analysis and machine intelligence , volume=
Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2018 , publisher=
2018
-
[22]
arXiv preprint arXiv:2311.01301 , year=
TRIALSCOPE A Unifying Causal Framework for Scaling Real-World Evidence Generation with Biomedical Language Models , author=. arXiv preprint arXiv:2311.01301 , year=
-
[23]
Journal of biomedical informatics , volume=
Creation of a new longitudinal corpus of clinical narratives , author=. Journal of biomedical informatics , volume=. 2015 , publisher=
2015
-
[24]
Journal of biomedical informatics , volume=
Annotating longitudinal clinical narratives for de-identification: The 2014 i2b2/UTHealth corpus , author=. Journal of biomedical informatics , volume=. 2015 , publisher=
2014
-
[25]
arXiv preprint arXiv:2001.08361 , year=
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
Pith/arXiv arXiv 2001
-
[26]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[27]
arXiv preprint arXiv:1801.06146 , year=
Universal language model fine-tuning for text classification , author=. arXiv preprint arXiv:1801.06146 , year=
-
[28]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[29]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Large language models are few-shot clinical information extractors , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[30]
arXiv preprint arXiv:2312.09958 , year=
Distilling Large Language Models for Matching Patients to Clinical Trials , author=. arXiv preprint arXiv:2312.09958 , year=
-
[31]
arXiv preprint arXiv:2308.02180 , year=
Scaling Clinical Trial Matching Using Large Language Models: A Case Study in Oncology , author=. arXiv preprint arXiv:2308.02180 , year=
-
[32]
2023 , eprint=
C-Pack: Packaged Resources To Advance General Chinese Embedding , author=. 2023 , eprint=
2023
-
[33]
Pharmafile URL http://www
Clinical trials and their patients: the rising costs and how to stem the loss , author=. Pharmafile URL http://www. pharmafile. com/news/511225/clinical-trials-and-their-patients-rising-costs-and-how-stem-loss , year=
-
[34]
arXiv preprint arXiv:2307.09702 , year=
Efficient Guided Generation for LLMs , author=. arXiv preprint arXiv:2307.09702 , year=
-
[35]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[36]
Clinical Leader Newsletter , year=
Considerations for improving patient recruitment into clinical trials , author=. Clinical Leader Newsletter , year=
-
[37]
Journal of Oncology Practice , volume=
Effort required in eligibility screening for clinical trials , author=. Journal of Oncology Practice , volume=. 2012 , publisher=
2012
-
[38]
arXiv preprint arXiv:2309.00071 , year=
Yarn: Efficient context window extension of large language models , author=. arXiv preprint arXiv:2309.00071 , year=
-
[39]
Clinical Trials Market , journal=
GVR , year=. Clinical Trials Market , journal=
-
[40]
Healthcare informatics research , volume=
Managing unstructured big data in healthcare system , author=. Healthcare informatics research , volume=. 2019 , publisher=
2019
-
[41]
BMC Medical Informatics and Decision Making , author =
Increasing the efficiency of trial-patient matching: automated clinical trial eligibility. BMC Medical Informatics and Decision Making , author =. 2015 , keywords =. doi:10.1186/s12911-015-0149-3 , language =
-
[42]
and Sun, Jimeng , month = aug, year =
Gao, Junyi and Xiao, Cao and Glass, Lucas M. and Sun, Jimeng , month = aug, year =. Proceedings of the 26th. doi:10.1145/3394486.3403123 , urldate =
-
[43]
and Sun, Jimeng , month = apr, year =
Zhang, Xingyao and Xiao, Cao and Glass, Lucas M. and Sun, Jimeng , month = apr, year =. Proceedings of. doi:10.1145/3366423.3380181 , urldate =
-
[44]
Contemporary Clinical Trials Communications , author =
Assessing an. Contemporary Clinical Trials Communications , author =. 2021 , keywords =. doi:10.1016/j.conctc.2020.100692 , language =
-
[45]
Journal of biomedical informatics , volume=
Challenges in clinical natural language processing for automated disorder normalization , author=. Journal of biomedical informatics , volume=. 2015 , publisher=
2015
-
[46]
Journal of the American Medical Informatics Association , author =. 2019 , pages =. doi:10.1093/jamia/ocy178 , language =
-
[47]
2021 , url=
The Office of the National Coordinator for Health Information Technology , title=. 2021 , url=
2021
-
[48]
gov web site
US National Institutes of Health launches ClinicalTrials. gov web site. , author=. Immunotherapy Weekly , pages=. 2000 , publisher=
2000
-
[49]
Corpus-based
Luo, Zhihui , pages =. Corpus-based
-
[50]
Journal of the American Medical Informatics Association , author =. 2011 , pages =. doi:10.1136/amiajnl-2011-000321 , language =
-
[51]
Tseo, Yitong and Salkola, M. I. and Mohamed, Ahmed and Kumar, Anuj and Abnousi, Freddy , month = jul, year =. Information Extraction of Clinical Trial Eligibility Criteria , url =
-
[52]
Journal of the American Medical Informatics Association , author =. 2017 , pages =. doi:10.1093/jamia/ocx019 , language =
-
[53]
BMC Medical Research Methodology , volume=
Piloting an automated clinical trial eligibility surveillance and provider alert system based on artificial intelligence and standard data models , author=. BMC Medical Research Methodology , volume=. 2023 , publisher=
2023
-
[54]
Journal of biomedical informatics , volume=
Matching patients to clinical trials using semantically enriched document representation , author=. Journal of biomedical informatics , volume=. 2020 , publisher=
2020
-
[55]
Pradeep, Ronak and Li, Yilin and Wang, Yuetong and Lin, Jimmy , title =. 2022 , isbn =. doi:10.1145/3477495.3531853 , booktitle =
-
[56]
Nature Communications , volume=
Deciphering clinical abbreviations with a privacy protecting machine learning system , author=. Nature Communications , volume=. 2022 , publisher=
2022
-
[57]
ArXiv , year=
Rethinking with Retrieval: Faithful Large Language Model Inference , author=. ArXiv , year=
-
[58]
ArXiv , year=
Zero-Shot Listwise Document Reranking with a Large Language Model , author=. ArXiv , year=
-
[59]
ArXiv , year=
LLM for Patient-Trial Matching: Privacy-Aware Data Augmentation Towards Better Performance and Generalizability , author=. ArXiv , year=
-
[60]
arXiv preprint arXiv:1904.05342 , year=
Clinicalbert: Modeling clinical notes and predicting hospital readmission , author=. arXiv preprint arXiv:1904.05342 , year=
Pith/arXiv arXiv 1904
-
[61]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[62]
Online preprint , volume=
From doc2query to docTTTTTquery , author=. Online preprint , volume=
-
[63]
2022 , booktitle =
Michihiro Yasunaga and Jure Leskovec and Percy Liang , title =. 2022 , booktitle =
2022
-
[64]
Journal of the American Medical Informatics Association , volume=
Cohort selection for clinical trials: n2c2 2018 shared task track 1 , author=. Journal of the American Medical Informatics Association , volume=. 2019 , publisher=
2018
-
[65]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[66]
arXiv preprint arXiv:1301.3781 , year=
Efficient estimation of word representations in vector space , author=. arXiv preprint arXiv:1301.3781 , year=
-
[67]
Journal of the American Medical Informatics Association , volume=
Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): architecture, component evaluation and applications , author=. Journal of the American Medical Informatics Association , volume=. 2010 , publisher=
2010
-
[68]
Journal of the American Medical Informatics Association , volume=
An overview of MetaMap: historical perspective and recent advances , author=. Journal of the American Medical Informatics Association , volume=. 2010 , publisher=
2010
-
[69]
Journal of the American Medical Informatics Association , volume=
CLAMP--a toolkit for efficiently building customized clinical natural language processing pipelines , author=. Journal of the American Medical Informatics Association , volume=. 2018 , publisher=
2018
-
[70]
arXiv preprint arXiv:2303.12712 , year=
Sparks of artificial general intelligence: Early experiments with gpt-4 , author=. arXiv preprint arXiv:2303.12712 , year=
-
[71]
arXiv preprint arXiv:2311.16079 , year=
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models , author=. arXiv preprint arXiv:2311.16079 , year=
-
[72]
Nature , pages=
Health system-scale language models are all-purpose prediction engines , author=. Nature , pages=. 2023 , publisher=
2023
-
[73]
arXiv preprint arXiv:2307.15343 , year=
Med-halt: Medical domain hallucination test for large language models , author=. arXiv preprint arXiv:2307.15343 , year=
-
[74]
Proceedings of the thirtieth text retrieval conference (TREC 2021) , year=
Overview of the TREC 2021 clinical trials track , author=. Proceedings of the thirtieth text retrieval conference (TREC 2021) , year=
2021
-
[75]
Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval , pages=
A test collection for matching patients to clinical trials , author=. Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval , pages=
-
[76]
2018 , url=
Double-blind, Double-dummy, Phase 2 Randomized, Multicenter, Proof-of-Concept, Safety and Efficacy Trial to Evaluate Different Oral Benznidazole Monotherapy and Benznidazole/E1224 Combination Regimens for the Treatment of Adult Patients with Chronic Indeterminate Chagas Disease , author=. 2018 , url=
2018
-
[77]
2017 , url=
A Phase II, Randomized, Double-blind, Placebo-controlled Study to Evaluate the Safety and Efficacy of TJ301 (FE 999301) Administered Intravenously in Patients with Active Ulcerative Colitis , author=. 2017 , url=
2017
-
[78]
Large Language Models are Few-Shot Health Learners , author=
-
[79]
arXiv preprint arXiv:2207.08143 , year=
Can large language models reason about medical questions? , author=. arXiv preprint arXiv:2207.08143 , year=
-
[80]
arXiv preprint arXiv:2303.11032 , year=
Deid-gpt: Zero-shot medical text de-identification by gpt-4 , author=. arXiv preprint arXiv:2303.11032 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.