GOTabPFN: From Feature Ordering to Compact Tokenization for Tabular Foundation Models on High-Dimensional Data
Pith reviewed 2026-06-28 06:43 UTC · model grok-4.3
The pith
GOTabPFN uses graph-guided ordering and local feature compression to make TabPFN-style models accurate on high-dimensional low-sample tabular data under tight token budgets without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
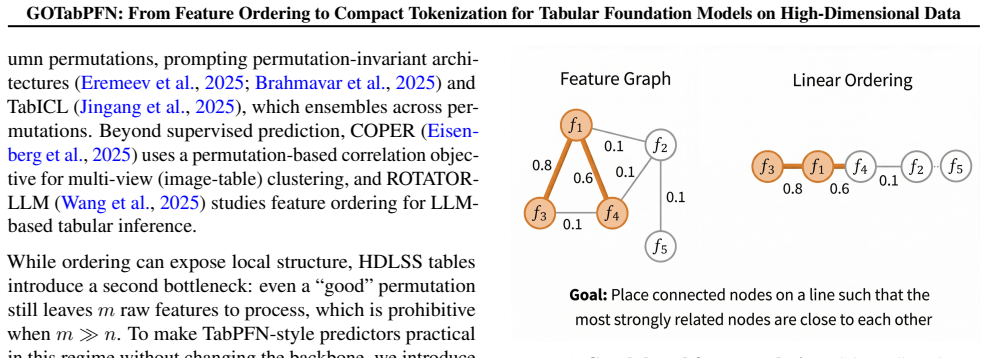
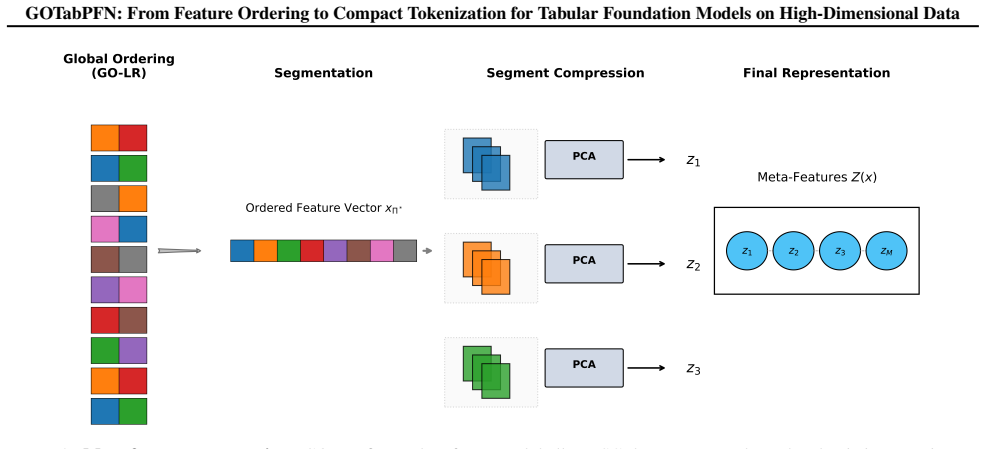
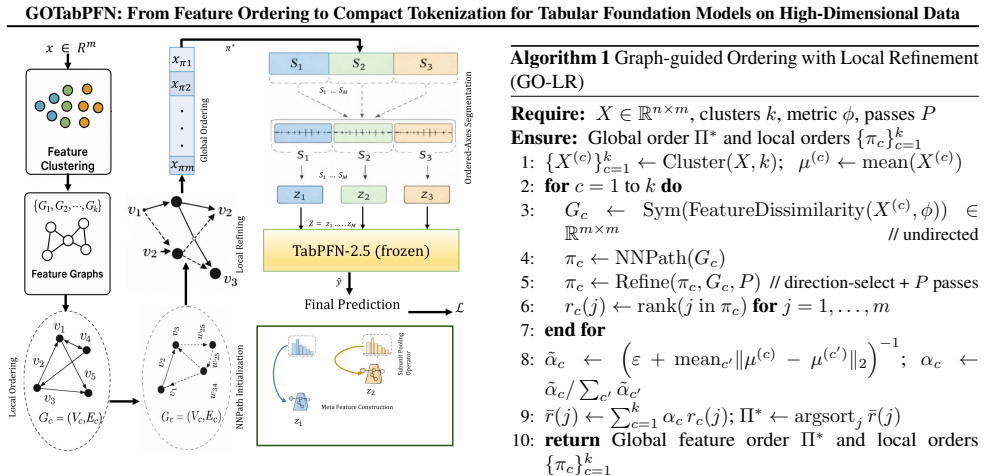
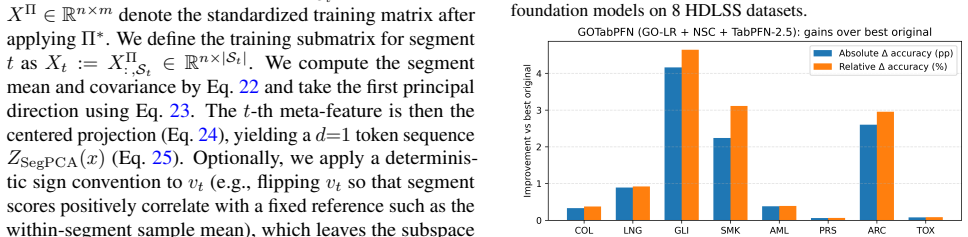
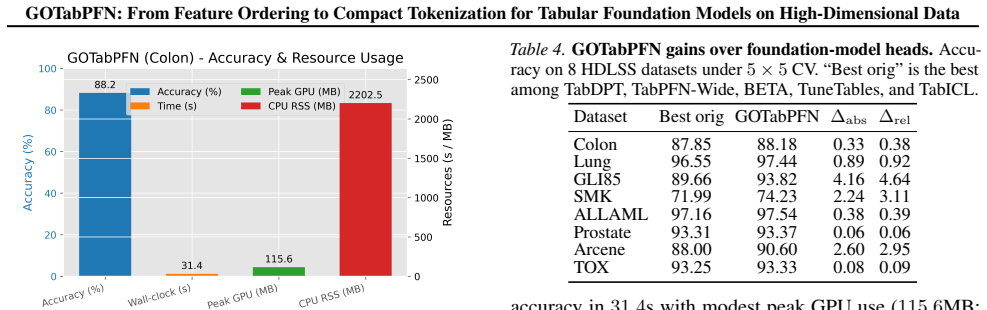
GOTabPFN builds on GO-LR, shown equivalent to weighted Minimum Linear Arrangement and solved practically as a TSP-path-style surrogate, together with Neuro-Inspired Subunit Compression (NSC) to pool locally adjacent ordered features into meta-features, yielding a compact representation that makes TabPFN-style prediction practical in HDLSS regimes and improves stability and accuracy across tabular benchmarks under tight token budgets.
What carries the argument
Graph-guided Ordering with Local Refinement (GO-LR) for feature arrangement equivalent to weighted minimum linear arrangement, paired with Neuro-Inspired Subunit Compression (NSC) to create meta-features from adjacent tokens.
If this is right
- TabPFN-style prediction becomes practical in high-dimensional low-sample-size regimes.
- Stability and accuracy improve on tabular benchmarks when token budgets are tight.
- Compact representations can be generated without retraining the underlying foundation model backbone.
- Feature relationships captured in a graph allow effective local pooling that reduces input size while retaining signal.
Where Pith is reading between the lines
- The same ordering-plus-pooling steps could be tested on other tabular foundation models to check if token efficiency gains generalize beyond TabPFN.
- Treating feature arrangement as a graph linear arrangement problem opens the door to importing solvers from combinatorial optimization for tabular preprocessing.
- If the TSP surrogate ordering proves robust, it might reduce the need for exhaustive feature selection in HDLSS settings by focusing computation on locally coherent groups.
Load-bearing premise
The ordering found by the TSP-path-style solver for GO-LR produces adjacent features whose pooling via NSC keeps enough information for the TabPFN backbone to predict accurately without retraining.
What would settle it
On a new collection of HDLSS tabular datasets, if GOTabPFN shows no gains in accuracy or stability versus direct TabPFN or other baselines when both are restricted to the same small token budget, the central claim would be falsified.
Figures

read the original abstract
We investigate how to make small tabular foundation models effective for High-Dimensional, Low-Sample Size (HDLSS) tabular prediction without retraining large backbones. We introduce Graph-guided Ordering with Local Refinement (GO-LR), show its equivalence to weighted Minimum Linear Arrangement, and interpret the practical solver as a TSP-path-style surrogate. We propose GOTabPFN,which builds on GO-LR, and a Neuro-Inspired Subunit Compression (NSC) unit to pool locally adjacent ordered features into meta-features, yielding a compact representation that makes TabPFN-style prediction practical in HDLSS regimes. Across tabular benchmarks, GOTabPFN improves stability and accuracy under tight token budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GOTabPFN for making TabPFN-style tabular foundation models practical on high-dimensional low-sample-size (HDLSS) data without retraining. It defines Graph-guided Ordering with Local Refinement (GO-LR), claims equivalence to weighted Minimum Linear Arrangement, interprets a practical solver as a TSP-path surrogate, and combines it with Neuro-Inspired Subunit Compression (NSC) to pool locally adjacent features into meta-features, yielding compact tokenizations that improve stability and accuracy under tight token budgets on tabular benchmarks.
Significance. If the TSP-path surrogate for the claimed MLA equivalence produces orderings whose NSC meta-features retain the feature dependencies needed by the frozen TabPFN backbone, the method could extend tabular foundation models to HDLSS regimes. The equivalence claim and surrogate interpretation would be useful contributions if independently derived and if the no-retraining assumption holds empirically.
major comments (2)
- [Abstract] Abstract: the central claims of equivalence between GO-LR and weighted Minimum Linear Arrangement, the TSP-path surrogate interpretation, and the resulting accuracy/stability gains are stated without any equations, proof sketches, experimental protocols, error bars, dataset details, or baseline comparisons, so the soundness of the claims cannot be assessed from the provided information.
- [Abstract] The manuscript does not address whether the approximation gap of the TSP-path heuristic for the MLA objective can produce orderings that systematically misalign local neighborhoods with the original feature correlations, which would invalidate the assumption that NSC pooling preserves the statistical structure required by the pretrained TabPFN backbone in HDLSS settings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of equivalence between GO-LR and weighted Minimum Linear Arrangement, the TSP-path surrogate interpretation, and the resulting accuracy/stability gains are stated without any equations, proof sketches, experimental protocols, error bars, dataset details, or baseline comparisons, so the soundness of the claims cannot be assessed from the provided information.
Authors: The abstract is written to be concise and highlight the core contributions within length limits. The full manuscript contains the equivalence to weighted Minimum Linear Arrangement with a proof sketch in Section 3, the TSP-path surrogate interpretation in the same section, and all experimental protocols, error bars, dataset descriptions, and baseline comparisons in Section 5. We will revise the abstract to include a short reference to the theoretical result and experimental validation if space allows. revision: partial
-
Referee: [Abstract] The manuscript does not address whether the approximation gap of the TSP-path heuristic for the MLA objective can produce orderings that systematically misalign local neighborhoods with the original feature correlations, which would invalidate the assumption that NSC pooling preserves the statistical structure required by the pretrained TabPFN backbone in HDLSS settings.
Authors: This is a valid concern about the heuristic's approximation quality. Our empirical results across benchmarks demonstrate that the produced orderings enable effective NSC compression and yield accuracy and stability gains under tight token budgets. However, the manuscript does not include a formal analysis or bound on how the approximation gap may affect local feature correlations. We will add an explicit discussion of this limitation and its implications for the no-retraining assumption in a revised version. revision: yes
Circularity Check
No significant circularity; derivation introduces independent components
full rationale
The provided abstract and description introduce GO-LR as a new ordering method, claim an equivalence to weighted Minimum Linear Arrangement (with TSP-path surrogate interpretation), and combine it with a new NSC pooling unit to enable compact tokenization for TabPFN in HDLSS settings. No equations or definitions are given that reduce the claimed equivalence or the downstream prediction performance to a tautological fit or self-referential input by construction. The central claims rest on the practical utility of the proposed ordering and compression steps rather than any self-definitional loop, fitted-input renaming, or load-bearing self-citation chain. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M
doi: 10.1109/MIPR62202.2024.00065. Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M. Optuna: A Next-Generation Hyperparameter Opti- mization Framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Dis- covery & Data Mining, pp. 2623–2631, 2019. doi: 10.1145/3292500.3330701. Aoshima, M., Shen, D., Shen, H., Yata, K., Z...
-
[2]
doi: 10.1609/aaai.v35i8.16826. Atkins, J. E., Boman, E. G., and Hendrickson, B. A Spec- tral Algorithm for Seriation and the Consecutive Ones Problem.SIAM Journal on Computing, 28(1):297–310,
-
[3]
doi: 10.1137/S0097539795285771. Balın, M. F., Abid, A., and Zou, J. Concrete Autoencoders: Differentiable Feature Selection and Reconstruction. In International Conference on Machine Learning, pp. 444–
-
[4]
Barthel, K
PMLR, 2019. Barthel, K. U., Barthel, F. T., and Eisert, P. Permutation Learning with Only N Parameters: From SoftSort to Self- Organizing Gaussians. In2025 33rd European Signal Pro- cessing Conference (EUSIPCO), pp. 1892–1896. IEEE,
2019
-
[5]
Neural Drone Localization Exploiting Signal Synthesis of Real- World Audio Data
doi: 10.23919/EUSIPCO63237.2025.11226796. Behrisch, M., Bach, B., Henry Riche, N., Schreck, T., and Fekete, J.-D. Matrix Reordering Methods for Table and Network Visualization. InComputer Graphics Forum, volume 35, pp. 693–716. Wiley Online Library, 2016. doi: 10.1111/cgf.12935. Beltagy, I., Peters, M. E., and Cohan, A. Longformer: The Long-Document Trans...
-
[6]
Chen, K.-Y ., Chiang, P.-H., Chou, H.-R., Chen, T.-W., and Chang, T.-H
doi: 10.1609/aaai.v36i4.20309. Chen, K.-Y ., Chiang, P.-H., Chou, H.-R., Chen, T.-W., and Chang, T.-H. Trompt: Towards A Better Deep Neural Network for Tabular Data. InInternational Conference on Machine Learning, pp. 4392–4434. PMLR, 2023. Chen, T. and Guestrin, C. XGBoost: A Scalable Tree Boosting System. InProceedings of the 22nd ACM SIGKDD Internation...
-
[7]
Garey, M., Johnson, D., and Stockmeyer, L
doi: 10.1080/01621459.1937.10503522. Garey, M., Johnson, D., and Stockmeyer, L. Some Simpli- fied NP-Complete Graph Problems.Theoretical Com- puter Science, 1(3):237–267, 1976. doi: 10.1016/ 0304-3975(76)90059-1. Garey, M. R., Johnson, D. S., and Stockmeyer, L. Some Simplified NP-Complete Problems. InProceedings of the Sixth Annual ACM Symposium on Theory...
-
[8]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
doi: 10.48550/arXiv.2511.08667. Guo, H., Tang, R., Ye, Y ., Li, Z., and He, X. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. InProceedings of the Twenty-Sixth Interna- tional Joint Conference on Artificial Intelligence. Interna- tional Joint Conferences on Artificial Intelligence Organi- zation (IJCAI-17), 2017. doi: 10.24963/ij...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.08667 2017
-
[9]
ZAYAN: Disentangled Contrastive Transformer for Tabular Remote Sensing Data
Springer, 2024. doi: 10.1007/978-3-031-78128-5 27. Habib, A. Z. S. B., Ahamed, M. Y ., Gyawali, P. K., Doretto, G., and Adjeroh, D. A. BSTabDiff: Block-Subunit Diffu- sion Priors for High-Dimensional Tabular Data Genera- tion. InICLR 2026 2nd Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Effi- cacy, 2026a. Habib, A. Z. S. B....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-031-78128-5 2024
-
[10]
doi: 10.1023/A:1006529012972. Levina, E. and Bickel, P. Maximum Likelihood Estimation of Intrinsic Dimension.Advances in Neural Information Processing Systems, 17, 2004. Li, J., Cheng, K., Wang, S., Morstatter, F., Trevino, R. P., Tang, J., and Liu, H. Feature Selection: A Data Perspec- tive.ACM Computing Surveys (CSUR), 50(6):94, 2018. doi: 10.1145/31366...
-
[11]
Popov, S., Morozov, S., and Babenko, A
doi: 10.1016/S0896-6273(03)00149-1. Popov, S., Morozov, S., and Babenko, A. Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data. InInternational Conference on Learning Representations, 2020. Prokhorenkova, L., Gusev, G., V orobev, A., Dorogush, A. V ., and Gulin, A. CatBoost: Unbiased Boosting with Categor- ical Features.Advances in Neur...
-
[12]
doi: 10.1137/0206041. Rousseeuw, P. J. Silhouettes: A Graphical Aid to the In- terpretation and Validation of Cluster Analysis.Journal of Computational and Applied Mathematics, 20:53–65,
-
[13]
doi: 10.1016/0377-0427(87)90125-7. Roy, O. and Vetterli, M. The Effective Rank: A Measure of Effective Dimensionality. In2007 15th European Signal Processing Conference, pp. 606–610. IEEE, 2007. Rubachev, I., Kartashev, N., Gorishniy, Y ., and Babenko, A. TabReD: Analyzing Pitfalls and Filling the Gaps in Tabular Deep Learning Benchmarks. InInternational ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/0377-0427(87)90125-7 2007
-
[14]
doi: 10.1007/BF01919177. Thielmann, A. F. and Samiee, S. On the Efficiency of NLP- Inspired Methods for Tabular Deep Learning. InNeurIPS Efficient Natural Language and Speech Processing Work- shop, pp. 532–539. PMLR, 2024. Thielmann, A. F., Kumar, M., Weisser, C., Reuter, A., S¨afken, B., and Samiee, S. Mambular: A Sequen- tial Model for Tabular Deep Lear...
-
[15]
doi: 10.1109/ICCIS.2015.7274557
IEEE, 2015c. doi: 10.1109/ICCIS.2015.7274557. Wang, Y ., Huang, H., Rudin, C., and Shaposhnik, Y . Under- standing How Dimension Reduction Tools Work: An Em- pirical Approach to Deciphering t-SNE, UMAP, TriMAP, and PaCMAP for Data Visualization.Journal of Machine Learning Research, 22(201):1–73, 2021. Wen, X., Zhang, H., Zheng, S., Xu, W., and Bian, J. Fr...
-
[16]
Wu, X., Liu, X., Li, W., and Wu, Q
doi: 10.1145/3637528.3671975. Wu, X., Liu, X., Li, W., and Wu, Q. Improved Expressivity through Dendritic Neural Networks.Advances in Neural Information Processing Systems, 31, 2018. Yamada, Y ., Lindenbaum, O., Negahban, S., and Kluger, Y . Feature Selection Using Stochastic Gates. InInter- national Conference on Machine Learning, pp. 10648– 10659. PMLR,...
-
[17]
start at arg mini P j dij and repeatedly append the nearest unvisited node
extended this direction by studying feature ordering for LLM-based tabular inference. DynaTab (Habib et al., 2026b) systematically studied when feature ordering matters in high-dimensional tabular learning, introducing an Intrinsic Dimensionality Factor (IDF) and feature-to-sample ratio ρ=m/n based categorization of dataset regimes. It proposed a neurosci...
2008
-
[18]
50) has class-conditional mean difference E[zNSC |Y= 1]−E[z NSC |Y= 0] = ∆ and varianceVar(z NSC |Y) =σ 2/s, hence we get Eq
The NSC block mean (Eq. 50) has class-conditional mean difference E[zNSC |Y= 1]−E[z NSC |Y= 0] = ∆ and varianceVar(z NSC |Y) =σ 2/s, hence we get Eq. 50 and 51 zNSC = 1 s X j∈S Xj (50) SNRNSC := E[zNSC |Y= 1]−E[z NSC |Y= 0] 2 Var(zNSC |Y) = ∆2s σ2 (51)
-
[19]
Let u= (u j)j∈S be a random projection direction withP j∈S u2 j = 1 and entries of order 1/√s, and define Eq. 52. Then we get Eq. 52 and Eq. 53. For typical random u, E (P j uj)2 = 1, so the typical SNR of zRP is defined by Eq. 54. zRP = X j∈S ujXj (52) E[zRP |Y= 1]−E[z RP |Y= 0] = ∆ X j∈S uj,Var(z RP |Y) =σ 2 (53) SNRRP := E[zRP |Y= 1]−E[z RP |Y= 0] 2 Va...
2009
-
[20]
2.Intrinsic dimension.Estimate ˆdvia effective rank (Eqs
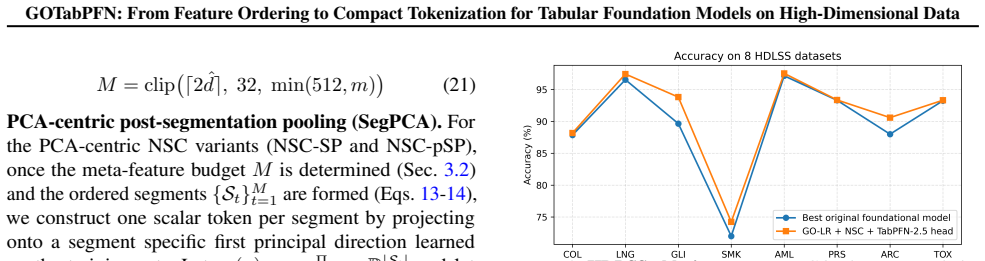
GO-LR ordering.Compute the GO-LR global feature permutation Π∗ on the training set using a chosen metric (e.g., correlation, cosine, euclidean, manhattan, or KL divergence), with local refinement passes as in Algorithm 1. 2.Intrinsic dimension.Estimate ˆdvia effective rank (Eqs. 27-29), and compute IDF= ˆd/m(Eq. 30). 3.NSC configuration.Configure NSC with...
-
[21]
This measures how well each DR method preserves label-relevant structure inMdimensions
Linear-probe accuracy.Train a logistic regression classifier on each latent space XNSC, XPCA, XRP, XAE, XUMAP, XPaCMAP using the same stratified cross-validation protocol. This measures how well each DR method preserves label-relevant structure inMdimensions. 2.k NN classification in latent space.Evaluate kNN accuracy using the compressed embeddings under...
-
[22]
Label-based separability metrics.Compute silhouette and Davies-Bouldin scores on each latent representation using ground-truth class labels as the partition
-
[23]
Sequential
Statistical comparison across datasets.Aggregate per-dataset metrics and apply nonparametric tests, using a Friedman test (Friedman, 1937) across methods followed by one-sided Wilcoxon signed-rank comparisons with NSC-pSP as the reference (see Tables D.1, D.2, D.3). Evaluation protocol.We report only quantitative DR-style evaluations under a fixed aggress...
1937
-
[24]
break contiguity
and controlled perturbations that partially preserve locality (block-shuffle) or explicitly destroy contiguity while keeping the same global order statistics (round-robin “break contiguity”). Figure E.2 (top) and Table E.1 show that ordering yields non-trivial AUC changes for the local-window Transformer, and GO-LR produces the strongest gains among the t...
2017
-
[25]
confident
(Fig. I.1), and (ii) pairwise Wilcoxon signed-rank tests (Demˇsar, 2006) comparing GOTabPFN to each baseline across the same 8 datasets, with Holm correction to control family-wise error (Table I.1). The Friedman test indicates a significant overall effect across methods, and the CD diagram visualizes the separation in average ranks, where GOTabPFN attain...
2006
-
[26]
high-risk
evaluates on 7 biomedical HDLSS datasets against 16 baselines and reports average rank as a primary aggregate measure, while LSPIN/LLSPIN (Yang et al., 2022a) evaluates on 6 real-world high-dimensional datasets, including 3 text and 3 biomedical datasets, and summarizes performance using median rank. Following this established practice, we report average ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.