Noise-Aware Visual Representation Learning for Medical Visual Question Answering
Pith reviewed 2026-06-28 03:08 UTC · model grok-4.3
The pith
A denoising autoencoder learns robust visual embeddings for medical visual question answering by reconstructing clean representations from corrupted inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretraining a denoising autoencoder to reconstruct clean visual embeddings from corrupted versions produces representations that remain effective when fed through an MLP into an LLM, yielding improved robustness to noisy embeddings on the SLAKE and PathVQA benchmarks while preserving competitive performance on clean inputs.
What carries the argument
Denoising autoencoder pretrained to reconstruct clean visual embeddings from corrupted inputs.
If this is right
- The model shows improved robustness to noisy input embeddings on the evaluated benchmarks.
- Clean-input performance stays competitive with existing mapping-network approaches.
- Parameter-efficient fine-tuning via LoRA allows adaptation without retraining the full vision or language components.
- The framework directly targets small irrelevant changes in visual representations that prior Med-VQA pipelines overlooked.
Where Pith is reading between the lines
- The same pretraining step could be inserted into other vision-language pipelines that rely on frozen encoders.
- Performance gains may depend on how closely the synthetic corruption matches the distribution of artifacts in actual clinical scans.
- If the noise model generalizes, it could reduce the need for extensive data cleaning in medical imaging datasets.
Load-bearing premise
The specific corruption used to train the autoencoder matches the noise and small irrelevant changes that actually appear in real medical images, and the resulting robustness survives the later MLP projection into the language model.
What would settle it
On SLAKE or PathVQA, add controlled noise to the visual embeddings and measure whether accuracy with the denoising autoencoder falls to the same level as a baseline without it.
Figures
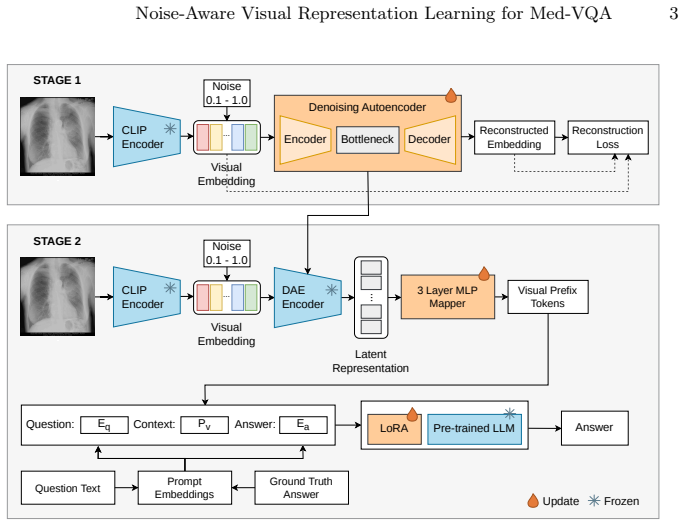
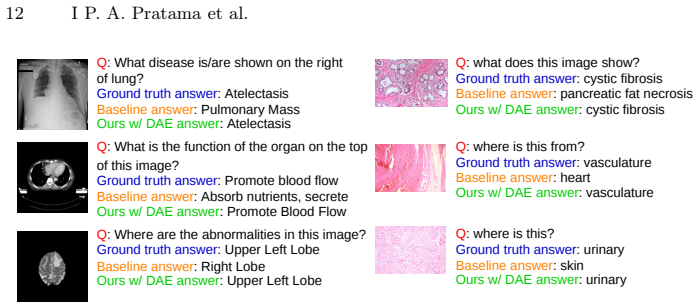
read the original abstract
Medical visual question answering (Med-VQA) has strong potential for clinical decision support by enabling AI models to interpret medical images and answer clinically relevant queries. Recent approaches typically connect off-the-shelf vision encoders with large language models (LLMs) through lightweight mapping networks to reduce computational cost. However, these methods often overlook the importance of handling noise and small irrelevant changes in visual representations. To address these challenges, we propose a noise-aware Med-VQA framework that incorporates a denoising autoencoder before visual embeddings are mapped into the input space of an LLM. The denoising autoencoder is pretrained to reconstruct clean visual embeddings from corrupted inputs, encouraging the model to learn robust visual representations that are less sensitive to noise. The resulting embeddings are then projected into the language model embedding space using a multi-layer perceptron (MLP), forming visual prefix tokens that provide image information to the LLM. To enable efficient adaptation without full retraining, we employ parameter-efficient fine-tuning using low-rank adaptation (LoRA). The proposed method is evaluated on the SLAKE and PathVQA benchmarks. Experimental results show improved robustness to noisy input embeddings while maintaining competitive clean performance across multiple evaluation criteria. These findings suggest that learning more robust visual representations can enhance Med-VQA performance and robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a noise-aware Med-VQA framework that inserts a denoising autoencoder before the MLP projection into an LLM. The autoencoder is pretrained to reconstruct clean visual embeddings from corrupted inputs, with the goal of learning representations robust to noise. The system uses LoRA for parameter-efficient fine-tuning and is evaluated on the SLAKE and PathVQA benchmarks, claiming improved robustness to noisy input embeddings while maintaining competitive clean performance.
Significance. If the claimed robustness transfers from synthetic embedding corruptions through the MLP to the LLM and generalizes to real medical-image variations, the approach could improve reliability of Med-VQA systems in clinical settings. The use of a lightweight mapping network plus LoRA is a practical design choice that keeps computational cost low. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the claim of 'improved robustness to noisy input embeddings' is stated without any quantitative numbers, error bars, ablation tables, or description of the noise-injection process, making it impossible to verify whether the central empirical claim is supported.
- [Method] Method description (pretraining of the denoising autoencoder): no evidence is provided that the chosen corruption distribution on visual embeddings approximates the actual perturbations that arise when a frozen vision encoder processes real medical images, nor is any analysis given showing that the subsequent MLP projection preserves the learned invariance properties.
minor comments (2)
- The paper should report the exact noise model (type, variance, etc.) used during autoencoder pretraining and include an ablation that isolates its contribution.
- Baseline comparisons and evaluation criteria on SLAKE and PathVQA should be described with explicit metrics and statistical significance tests.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and outline planned revisions to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'improved robustness to noisy input embeddings' is stated without any quantitative numbers, error bars, ablation tables, or description of the noise-injection process, making it impossible to verify whether the central empirical claim is supported.
Authors: We agree that the abstract would benefit from quantitative details to make the robustness claim verifiable. In the revised manuscript, we will expand the abstract to report specific performance improvements under noisy conditions on SLAKE and PathVQA (with references to the main-text tables), note the use of multiple runs for error bars, and provide a brief description of the noise-injection process used in pretraining. revision: yes
-
Referee: [Method] Method description (pretraining of the denoising autoencoder): no evidence is provided that the chosen corruption distribution on visual embeddings approximates the actual perturbations that arise when a frozen vision encoder processes real medical images, nor is any analysis given showing that the subsequent MLP projection preserves the learned invariance properties.
Authors: We acknowledge that the manuscript currently lacks direct evidence comparing the synthetic corruption distribution to real perturbations from medical images and does not analyze invariance preservation through the MLP. In the revision, we will add a dedicated analysis subsection that empirically compares observed embedding variations from real medical images to our corruption model and includes metrics demonstrating that the learned robustness properties are retained after MLP projection. revision: yes
Circularity Check
No circularity: empirical method with benchmark evaluation
full rationale
The paper describes a standard empirical pipeline: pretrain a denoising autoencoder on synthetically corrupted visual embeddings, project via MLP, apply LoRA, and evaluate robustness on SLAKE and PathVQA. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claim rests on experimental outcomes rather than any derivation that reduces to its own inputs by construction. This is the expected non-finding for a methods paper whose validity is tested externally via benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alain, G., Bengio, Y.: What regularized auto-encoders learn from the data- generating distribution. J. Mach. Learn. Res.15(1), 3563–3593 (Jan 2014)
2014
-
[2]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.N
Chen, J., Gui, C., Ouyang, R., Gao, A., Chen, S., Chen, G.H., Wang, X., Cai, Z., Ji, K., Wan, X., Wang, B.: Towards injecting medical visual knowledge into multimodal LLMs at scale. In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 7346–7370. Association for Comput...
-
[3]
In: Cho, M., Laptev, I., Tran, D., Yao, A., Zha, H
Chen, Q., Hong, Y.: Medblip: Bootstrapping language-image pretraining from 3d medical images and texts. In: Cho, M., Laptev, I., Tran, D., Yao, A., Zha, H. (eds.) Computer Vision – ACCV 2024. pp. 98–113. Springer Nature Singapore, Singapore (2025)
2024
-
[4]
Applied Sciences15(6) (2025).https://doi
Dong, W., Shen, S., Han, Y., Tan, T., Wu, J., Xu, H.: Generative models in medical visual question answering: A survey. Applied Sciences15(6) (2025).https://doi. org/10.3390/app15062983,https://www.mdpi.com/2076-3417/15/6/2983
-
[5]
In: 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW)
Gondara, L.: Medical image denoising using convolutional denoising autoencoders. In: 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW). pp. 241–246 (2016).https://doi.org/10.1109/ICDMW.2016.0041
-
[6]
In: Naumann, T., Ben Abacha, A., Bethard, S., Roberts, K., Bitterman, D
Ha, C., Asaadi, S., Karn, S.K., Farri, O., Heimann, T., Runkler, T.: Fusion of domain-adapted vision and language models for medical visual question answer- ing. In: Naumann, T., Ben Abacha, A., Bethard, S., Roberts, K., Bitterman, D. (eds.) Proceedings of the 6th Clinical Natural Language Processing Work- shop. pp. 246–257. Association for Computational ...
-
[7]
He, J., Li, P., Liu, G., He, G., Chen, Z., Zhong, S.: Pefomed: Parameter efficient fine-tuning of multimodal large language models for medical imaging (2025),https: //arxiv.org/abs/2401.02797
arXiv 2025
-
[8]
In: Zong, C., Xia, F., Li, W., Navigli, R
He, X., Cai, Z., Wei, W., Zhang, Y., Mou, L., Xing, E., Xie, P.: Towards visual question answering on pathology images. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)...
-
[9]
In: International Conference on Learning Representations (ICLR) (2022), published as a conference paper
Hu, E., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: International Conference on Learning Representations (ICLR) (2022), published as a conference paper
2022
-
[10]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Jiang, S., Zheng, T., Zhang, Y., Jin, Y., Yuan, L., Liu, Z.: Med-moe: Mixture of domain-specific experts for lightweight medical vision-language models. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 3843–3860. Association for Computational Linguistics (2024)
2024
-
[11]
The Journal of Supercom- puting75(2), 704–718 (2019)
Jifara, W., Jiang, F., Rho, S., Cheng, M., Liu, S.: Medical image denoising using con- volutional neural network: a residual learning approach. The Journal of Supercom- puting75(2), 704–718 (2019). https://doi.org/10.1007/s11227-017-2080-0, https://doi.org/10.1007/s11227-017-2080-0
-
[12]
Medical Image Analysis90, 102963 (2023)
Kascenas, A., Sanchez, P., Schrempf, P., Wang, C., Clackett, W., Mikhael, S.S., Voisey, J.P., Goatman, K., Weir, A., Pugeault, N., Tsaftaris, S.A., O’Neil, A.Q.: The role of noise in denoising models for anomaly detection in medical images. Medical Image Analysis90, 102963 (2023). https://doi.org/https://doi.org/10.1016/ j.media.2023.102963, https://www.s...
arXiv 2023
-
[13]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023),https://aka.ms/llava-med, track on Datasets and Benchmarks
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. In: Advances in Neural Information Processing Systems (NeurIPS) (2023),https://aka.ms/llava-med, track on Datasets and Benchmarks
2023
-
[14]
Liu, B., Zhan, L.M., Xu, L., Ma, L., Yang, Y., Wu, X.M.: Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In: 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI). pp. 1650–1654 (2021).https://doi.org/10.1109/ISBI48211.2021.9434010
-
[15]
CoRRabs/2201.03898(2022), https://arxiv.org/abs/2201.03898
Michelucci, U.: An introduction to autoencoders. CoRRabs/2201.03898(2022), https://arxiv.org/abs/2201.03898
arXiv 2022
-
[16]
JMIR Medical Informatics12, e56627 (Aug 2024).https://doi
Naseem, U., Thapa, S., Masood, A.: Advancing accuracy in multimodal medical tasks through bootstrapped language-image pretraining (biomedblip): Performance evaluation study. JMIR Medical Informatics12, e56627 (Aug 2024).https://doi. org/10.2196/56627
-
[17]
In: Meila, M., Zhang, T
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Resea...
2021
-
[18]
Proceedings of SPIE– the International Society for Optical Engineering12467, 1246719 (Feb 2023)
Rahman, M.A., Yu, Z., Siegel, B.A., Jha, A.K.: A task-specific deep-learning- based denoising approach for myocardial perfusion spect. Proceedings of SPIE– the International Society for Optical Engineering12467, 1246719 (Feb 2023). https://doi.org/10.1117/12.2655629
-
[19]
Rezaei, Z., Samghabadi, S.S., Banad, Y.M.: Optimizing multimodal models for med- ical visual question answering: A comparative study of lora and adalora on vqa-rad and slake-vqa. Computers in Biology and Medicine200, 111397 (2026).https:// doi.org/https://doi.org/10.1016/j.compbiomed.2025.111397, https://www. sciencedirect.com/science/article/pii/S0010482...
-
[20]
In: Greenspan, H., Madabhushi, A., Mousavi, P., Salcudean, S., Duncan, J., Syeda-Mahmood, T., Taylor, R
van Sonsbeek, T., Derakhshani, M.M., Najdenkoska, I., Snoek, C.G.M., Worring, M.: Open-ended medical visual question answering through prefix tuning of language models. In: Greenspan, H., Madabhushi, A., Mousavi, P., Salcudean, S., Duncan, J., Syeda-Mahmood, T., Taylor, R. (eds.) Medical Image Computing and Computer Noise-Aware Visual Representation Learn...
2023
-
[21]
Vincent, P., Larochelle, H., Bengio, Y., Manzagol, P.A.: Extracting and composing robust features with denoising autoencoders. In: Proceedings of the 25th Interna- tional Conference on Machine Learning. p. 1096–1103. ICML ’08, Association for Computing Machinery, New York, NY, USA (2008).https://doi.org/10.1145/ 1390156.1390294,https://doi.org/10.1145/139...
-
[22]
Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., Manzagol, P.A.: Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res.11, 3371–3408 (Dec 2010)
2010
-
[23]
Communications Medicine 4(1), 277 (2024)
Zhang, X., Wu, C., Zhao, Z., Lin, W., Zhang, Y., Wang, Y., Xie, W.: Development of a large-scale medical visual question-answering dataset. Communications Medicine 4(1), 277 (2024). https://doi.org/10.1038/s43856-024-00709-2, https://doi. org/10.1038/s43856-024-00709-2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.