ArcANE: Do Role-Playing Language Agents Stay in Character at the Right Time?
Pith reviewed 2026-06-28 02:08 UTC · model grok-4.3
The pith
Role-playing agents align better with evolving characters when conditioned on a psychological arc.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
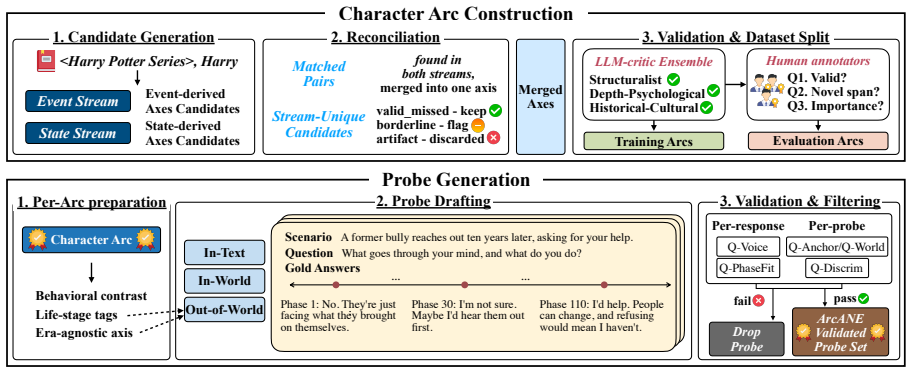
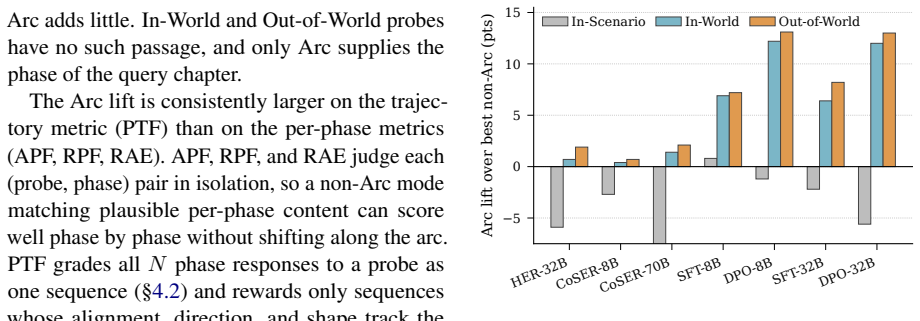
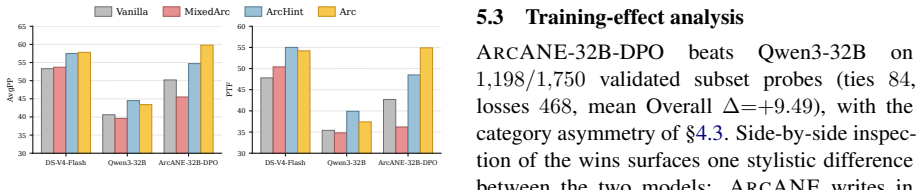
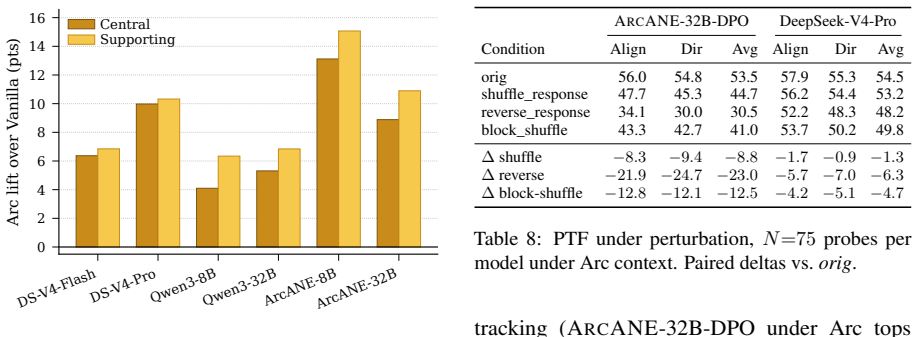
Conditioning on the Character Arc tops every other context strategy on every model, and the gap is largest on scenarios outside the source text where retrieval has nothing to find. The benchmark spans 17 novels and 80 principal characters, with each probe repeating the same scenario across phases.
What carries the argument
The Character Arc, which segments the narrative into phases along a psychological axis to track the character's psychological trajectory.
If this is right
- All six models perform best with Character Arc context.
- The performance advantage grows in scenarios beyond the source text.
- Fine-tuned models ArcANE-8B and ArcANE-32B show widened gaps favoring the arc approach in out-of-text cases.
Where Pith is reading between the lines
- Role-playing systems may need built-in mechanisms to track and update character states over time rather than relying on static prompts.
- This evaluation method could apply to assessing consistency in other sequential tasks like story continuation or multi-turn dialogues.
- Automatic arc construction might be improved by incorporating more explicit psychological models.
Load-bearing premise
The automatically constructed Character Arc accurately segments the narrative into phases along a psychological axis that reflects the character's true psychological trajectory.
What would settle it
A study in which experts manually create character arcs for the same novels and compare model performance using those versus the automatic ones, or check if performance equalizes when arcs are shuffled.
Figures



read the original abstract
Role-playing language agents (RPLAs) should play characters whose values and behavior evolve as the story progresses, not maintain a fixed persona. Existing benchmarks measure factual recall at a given chapter, not whether responses align with the character's psychological trajectory, especially in scenarios the source text never explores. We introduce ArcANE (Arc-Aware Narrative Evaluation), an automatically constructed benchmark spanning 17 novels and 80 principal characters. A Character Arc segments the narrative into phases along a psychological axis, and each probe poses the same scenario across phases, spanning both situations within the source text and situations beyond it. Across six models and six context modes, conditioning on the Character Arc tops every other context strategy on every model, and the gap is largest on scenarios outside the source text where retrieval has nothing to find. We further fine-tune open-weight models on the same data to obtain ArcANE-8B/32B, which widen the Arc advantage even more on scenarios outside the source text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ArcANE, an automatically constructed benchmark spanning 17 novels and 80 principal characters. A Character Arc segments each narrative into phases along a psychological axis; probes then present the same scenario at different phases, covering both in-text and out-of-text situations. Across six models and six context modes, conditioning on the Character Arc outperforms all other strategies on every model, with the largest gains on out-of-text probes where retrieval has no source material. Fine-tuned ArcANE-8B/32B models further widen this advantage.
Significance. If the automatically derived arcs are faithful to genuine psychological trajectories, the work supplies a scalable evaluation framework that exposes limitations of retrieval-only context for role-playing agents and demonstrates measurable gains from explicit arc conditioning, especially for extrapolation. The scale (17 novels), consistent cross-model pattern, and fine-tuning results constitute concrete empirical contributions that could serve as a baseline for future RPLA research.
major comments (3)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The headline result—that Character Arc conditioning outperforms all baselines, especially out-of-text—rests on the arcs being faithful segmentations of psychological change. The automatic pipeline (LLM summarization and clustering) is described but no human validation, inter-rater agreement, or comparison against literary consensus on phase boundaries or axis labels is reported; without this, superior performance could reflect models echoing the construction method rather than demonstrating arc awareness.
- [Results (§4)] Results (abstract and §4): The claim that the Arc advantage is largest on out-of-text scenarios is load-bearing for the argument that retrieval fails where arc conditioning succeeds, yet no statistical tests, confidence intervals, number of probes per condition, or data-exclusion criteria are supplied, preventing assessment of whether the reported gaps are reliable or driven by a small number of items.
- [Evaluation protocol] Evaluation protocol: The out-of-text probes are central to showing that the Arc benefit is not merely retrieval, but the manuscript provides no explicit criteria or examples confirming these scenarios are both (a) genuinely absent from the source text and (b) still psychologically coherent with the arc phase; this ambiguity weakens the interpretation of the largest gap.
minor comments (2)
- [Abstract] Abstract: The six context modes are referenced but never enumerated; a brief parenthetical list would improve readability.
- [§3] Notation: The psychological axes are introduced without a single concrete example (e.g., one novel’s axis labels and phase descriptions), making it harder to judge face validity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the ArcANE benchmark. We address each of the major comments below, proposing revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [§3 (Benchmark Construction)] The headline result—that Character Arc conditioning outperforms all baselines, especially out-of-text—rests on the arcs being faithful segmentations of psychological change. The automatic pipeline (LLM summarization and clustering) is described but no human validation, inter-rater agreement, or comparison against literary consensus on phase boundaries or axis labels is reported; without this, superior performance could reflect models echoing the construction method rather than demonstrating arc awareness.
Authors: We agree that additional validation would bolster confidence in the arcs. While the pipeline relies on LLM capabilities that have shown reliability in narrative tasks, we will incorporate a human validation study on a subset of the novels in the revised version. This will include inter-rater agreement metrics and comparison to literary analyses where available, to confirm the psychological axes and phase boundaries. revision: yes
-
Referee: [Results (§4)] The claim that the Arc advantage is largest on out-of-text scenarios is load-bearing for the argument that retrieval fails where arc conditioning succeeds, yet no statistical tests, confidence intervals, number of probes per condition, or data-exclusion criteria are supplied, preventing assessment of whether the reported gaps are reliable or driven by a small number of items.
Authors: We acknowledge the need for statistical support. In the revision, we will report the number of probes per condition (noting that each of the 80 characters has multiple phases and probes), provide bootstrap confidence intervals for the performance differences, conduct appropriate statistical tests (e.g., paired t-tests), and specify any data exclusion criteria applied during evaluation. revision: yes
-
Referee: [Evaluation protocol] The out-of-text probes are central to showing that the Arc benefit is not merely retrieval, but the manuscript provides no explicit criteria or examples confirming these scenarios are both (a) genuinely absent from the source text and (b) still psychologically coherent with the arc phase; this ambiguity weakens the interpretation of the largest gap.
Authors: We will clarify the out-of-text probe generation process by adding explicit criteria, such as verifying absence via keyword and semantic search against the full source text, and include concrete examples in the appendix demonstrating psychological coherence with the assigned arc phase. This will make the distinction between in-text and out-of-text more transparent. revision: yes
Circularity Check
No significant circularity; empirical evaluation is self-contained
full rationale
The paper introduces ArcANE as an automatically constructed benchmark over 17 novels and evaluates six models across six context modes, reporting that conditioning on the Character Arc outperforms alternatives with the largest gap on out-of-text probes. No load-bearing step reduces a claimed result to its own inputs by definition, fitted parameter, or self-citation chain; the benchmark construction pipeline and the downstream model performance measurements are distinct, with results obtained via direct empirical comparison rather than any derivation that equates output to input by construction. The central claim rests on observable performance differences, not on any uniqueness theorem or ansatz imported from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TimeChara: Evaluating point-in-time charac- ter hallucination of role-playing large language mod- els. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3291–3325, Bangkok, Thailand. Association for Computational Linguistics. Rick Busselle and Helena Bilandzic. 2009. Measuring narrative engagement.Media Psychology, 12(4):321– 34...
-
[2]
Role-play with large language models. Preprint, arXiv:2305.16367. Yunfan Shao, Linyang Li, Junqi Dai, and Xipeng Qiu
-
[3]
Character-LLM: A trainable agent for role- playing. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 13153–13187, Singapore. Association for Computational Linguistics. Tianhao Shen, Sun Li, Quan Tu, and Deyi Xiong. 2024. Roleeval: A bilingual role evaluation benchmark for large language models.Preprint, arX...
-
[4]
how self-assertion shifts under relational strain from prosocial attunement toward coercive control and ultimately self-negating withdrawal
as a sanity coordinate, and its absence in the induced set is a strong drift signal. Every in- duced axis must ground in established literary or psychological scholarship, following the construct- grounding criterion ofValues in the Wild(Huang et al., 2025) (Figure 6). Reconciliation tag set.Stream-unique candi- dates receive one of three tags, each tied ...
2025
-
[5]
PRESENCE: Is <character> present or mentioned in this chapter? If not, return minimal response
-
[6]
EMOTIONAL STATE: What is <character> feeling in this chapter? How does it compare to the previous chapter?
-
[7]
BELIEFS & VALUES: Any shifts in what <character> believes about themselves, others, society, morality?
-
[8]
DESIRES: What does <character> want to be true about the world or their situation? How have their desires shifted from the previous chapter?
-
[9]
INTENTIONS: What is <character> actively trying to bring about? What plans or goals are they pursuing?
-
[10]
KEY RELATIONSHIPS: How does <character> view/feel about other characters in this chapter? Any shifts?
-
[11]
SELF-AWARENESS: Does <character> show any new self-knowledge or remain unaware of something about themselves?
-
[12]
chapter": <chapter_num>,
CHANGE MAGNITUDE: Rate overall psychological change in this chapter as: none / subtle / moderate / significant / transformative Return JSON only: { "chapter": <chapter_num>, "character": "<character>", "present_in_chapter": true, "emotional_state": "Description", "belief_shifts": "Description or'none'", "current_desires": "What <character> wants to be tru...
1966
-
[13]
personal growth
Name it clearly and specifically (not generic like "personal growth")
-
[14]
Provide a short dimension_label (2-4 words) naming the psychological or relational dimension
-
[15]
where they end on this dimension)
Define the two poles (where the character starts vs. where they end on this dimension)
-
[16]
Trace the trajectory with specific chapter ranges and key events
-
[17]
character
Rate confidence (high/medium/low). If <character> shows little meaningful change (flat arc), state this explicitly and keep axes minimal. Return JSON only: { "character": "<character>", "arc_richness": "rich/moderate/flat", "intrapersonal_axes": [ { "axis_type": "intrapersonal", "axis_id": "intra_01", "dimension_label": "2-4 word dimension name", "axis_na...
-
[18]
HIGH CONFIDENCE
MATCHED: Axes that appear in both sets (possibly different names but same concept). HIGH CONFIDENCE
-
[19]
Assess: valid_missed / artifact / borderline
UNIQUE TO A: Axes only in Set A. Assess: valid_missed / artifact / borderline
-
[20]
Same assessment
UNIQUE TO B: Axes only in Set B. Same assessment
-
[21]
positive
MERGED FINAL SET: Your recommended final axes, combining the best from both. For each final axis, synthesize trajectory information from both sources. Every final axis MUST include: axis_type, dimension_label (2-4 words), axis_name, pole_start, pole_end, confidence, source, arc_direction, trajectory, evidence_summary. Relational axes must also include sou...
-
[22]
Never invent citations
Cite only real, verifiable published works. Never invent citations
-
[23]
Include the direct URL (JSTOR, Google Books, publisher page, Academia.edu, etc.) if you know it; otherwise set url to null
Each citation MUST include: author, title, year. Include the direct URL (JSTOR, Google Books, publisher page, Academia.edu, etc.) if you know it; otherwise set url to null
-
[24]
For intrapersonal axes, a work supports the axis if it discusses the same internal dimension of <character> -- even under different terminology (e.g.'pride'vs'arrogance','humility'vs'self-knowledge')
-
[25]
verdict": false and
If you cannot recall any real published work supporting this axis, set "verdict": false and "citations": []. Return JSON only: { "verdict": true or false, "reasoning": "2-3 sentences from your critical perspective", "citations": [ { "author": "Surname, Firstname (or just Surname)", "title": "Full work title", "year": 1990, "publication": "Journal name / b...
1990
-
[26]
State it as a BINARY behavioral contrast that the character would be answering THROUGH ACTION
Identify the SINGLE decision variable that captures what flips between phases. State it as a BINARY behavioral contrast that the character would be answering THROUGH ACTION. It must: - be answerable through behavior/choice - be specific enough that different phases give different answers - be phrased neutrally (no preferred pole) - be ONE dimension with t...
-
[27]
Produce EXACTLY (N-1) entries -- one per adjacent pair, in order -- with 0-indexed from/to indices
For each adjacent phase pair, describe in one sentence how the decision-variable answer shifts. Produce EXACTLY (N-1) entries -- one per adjacent pair, in order -- with 0-indexed from/to indices. Return JSON: {decision_variable, phase_contrasts: [{from_phase_idx, to_phase_idx, contrast}]}. Table 20: Life-stage tagger. [System] You are a literary-age analy...
-
[28]
agency vs communion under pressure
abstract_axis: 1 sentence naming the abstract dimension (e.g. "agency vs communion under pressure"). No novel-specific terminology
-
[29]
", "
abstract_phases: EXACTLY N entries, one per trajectory phase in order. Each is a short phrase summarizing that phase's position on the abstract axis in era-agnostic terms. Return JSON: {abstract_axis, abstract_phases: ["...", "..."]}. 34 Table 22: In-Scenario designer (probe type 1). The user message also inlines the shared phase-response instructions (Ta...
-
[30]
Stop just before <character> acts/speaks
SCENARIO: paraphrase the SETUP from the passage -- location, time, present characters, leading up to <character>'s response. Stop just before <character> acts/speaks
-
[31]
QUESTION: name the specific choice point (see QUESTION STYLE)
-
[32]
Non-anchor phases are counterfactual projections
<Phase-response instructions (shared sub-block).> ANCHOR phase entry (phase_idx=<k>) MUST extract <character>'s actual response from the SOURCE PASSAGE -- gt_action paraphrases the passage; gt_speech copies <character>'s spoken words verbatim from the passage (or null if they don't speak); gt_thought captures the construal evident in the passage. Non-anch...
-
[33]
End just before <character> responds
SCENARIO: a plausible-but-unwritten situation around chapter <qc>. End just before <character> responds. Keep it phase-agnostic
-
[35]
36 Table 24: Out-of-World designer (probe type 3)
<Phase-response instructions (shared sub-block).> <Style guidelines (shared sub-block).> Return JSON: {scenario, question, phase_responses: [...]}. 36 Table 24: Out-of-World designer (probe type 3). The user message also inlines the shared phase-response instructions (Table 18) and style guidelines (Table 17). [System] You are a narrative psychologist tra...
-
[36]
Set the tension in 1-2 sentences (<=60 words)
SCENARIO: a brief age-agnostic situation in the target era centered on <character>. Set the tension in 1-2 sentences (<=60 words). End just before <character> responds
-
[37]
QUESTION: pose the choice point (see QUESTION STYLE)
-
[38]
<key_moment>
<Phase-response instructions (shared sub-block).> <Style guidelines (shared sub-block).> Return JSON: {scenario, question, phase_responses: [...]}. 37 Table 25: In-Scenario scene grounding (locator + extractor). Two calls, executed sequentially per (axis, anchor phase). [Locator -- System] You are an editorial archivist for literary text. Given a brief mo...
-
[39]
Recall the scene from the scenario and describe it using the six Ws (Who, What, When, Where, Why, How)
-
[40]
unknown". First, reason step by step. Then on its own final line, output ONLY
Identify the single chapter number (1-<total_chapters>) that contains this scene. If you cannot determine it, output "unknown". First, reason step by step. Then on its own final line, output ONLY "Chapter: N" (an integer) or "Chapter: unknown". [Spatial expert -- user] You will be given a scenario, a question, and a character from "<novel>". Your task is ...
-
[41]
Recall the scene and list every character involved, including those present but unmentioned
-
[42]
Presence: present
Decide whether <character> is among them. First, reason step by step. Then on its own final line, output ONLY "Presence: present" or "Presence: absent". [Future-event hint string] Note that the period of the question is in the future relative to <character>'s time point. Therefore, you should not answer the question or mention any facts that occurred afte...
-
[43]
APF -- Action Phase-Fidelity. Is the response's action mechanism- equivalent to ref_action at the target phase? Judge across three levels (Level A is strictest; B and C can partially salvage credit when A fails): - Level A -- Strategy match: same underlying strategy (e.g. withdrawal, confrontation, deflection, mediation, concealment, disclosure, support-s...
-
[44]
RPF -- Reasoning Phase-Fidelity. Parse both ref_thought and the response's reasoning into four mechanism slots and judge each slot: - Trigger: what event / utterance / internal state set this response in motion? - Appraisal: how does the character interpret / evaluate that trigger? - Goal: what short-term goal arises from the appraisal? - Strategy: how is...
-
[45]
avoid the threat
RAE -- Reasoning-Action Entailment. Given the *reference reasoning (ref_thought)* as a fixed anchor, judge whether the response's action is a plausible action that this reasoning would license at this phase. This dimension is *conditioned on ref_thought*, not on the response's own reasoning -- a response can have internally self-consistent reasoning that ...
-
[46]
ptf_alignment -- Per-phase anchoring. For each phase i, is the model's response at phase i closer in mechanism to the reference at phase i than to references at other phases? A high score means most responses are correctly anchored to their own phase; a low score means responses systematically drift toward the wrong phase or collapse into one undifferenti...
-
[47]
Treating the reference sequence as defining a direction (e.g
ptf_direction -- Direction of change. Treating the reference sequence as defining a direction (e.g. fearful -> confident, dependent -> autonomous), does the model's sequence move along the same axis and in the same direction? A high score means the model's overall direction-of-travel matches the reference's; a low score means the model moves on a differen...
-
[48]
scores": {
ptf_shape -- Shape and pacing of change. Beyond direction, does the model reproduce where on the trajectory the largest shifts occur and how gradual or abrupt those shifts are? A high score means inflection points and pacing line up with the reference; a low score means the model's trajectory has a clearly different internal structure (e.g. linear ramp wh...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.