Representation Learning Enables Scalable Multitask Deep Reinforcement Learning
Pith reviewed 2026-06-28 02:58 UTC · model grok-4.3
The pith
Predictive representation learning with auxiliary objectives suffices for scalable multitask RL even without planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that combining predictive, model-based representations with high-capacity value function approximation is sufficient to achieve strong performance in multitask continuous control, even without planning. The authors introduce MR.Q, a simple model-free algorithm that incorporates auxiliary predictive objectives into an actor-critic architecture, and show it outperforms a recent world-model-based method as well as standard deep RL baselines while improving wall-clock efficiency and scaling with model capacity.
What carries the argument
MR.Q, a model-free actor-critic algorithm augmented with auxiliary predictive objectives that learns representations without explicit planning.
If this is right
- Performance improves consistently as model capacity increases.
- The approach reduces computational overhead compared to world-model methods.
- Predictive representation learning proves critical through targeted ablations.
- Strong results hold across a diverse suite of multitask continuous control tasks.
Where Pith is reading between the lines
- The result implies that future scaling efforts in RL could focus computational resources on representation learning rather than planning modules.
- Similar auxiliary predictive tasks might transfer to discrete action spaces or partially observable environments.
- If the pattern holds, simpler model-free pipelines could replace planning-heavy systems in resource-constrained multitask deployments.
Load-bearing premise
Auxiliary predictive objectives alone generate representations that support scalable multitask performance in the absence of planning or model-based control.
What would settle it
An ablation study in which removing the auxiliary predictive objectives produces no measurable drop in multitask performance on the same continuous control suite.
Figures
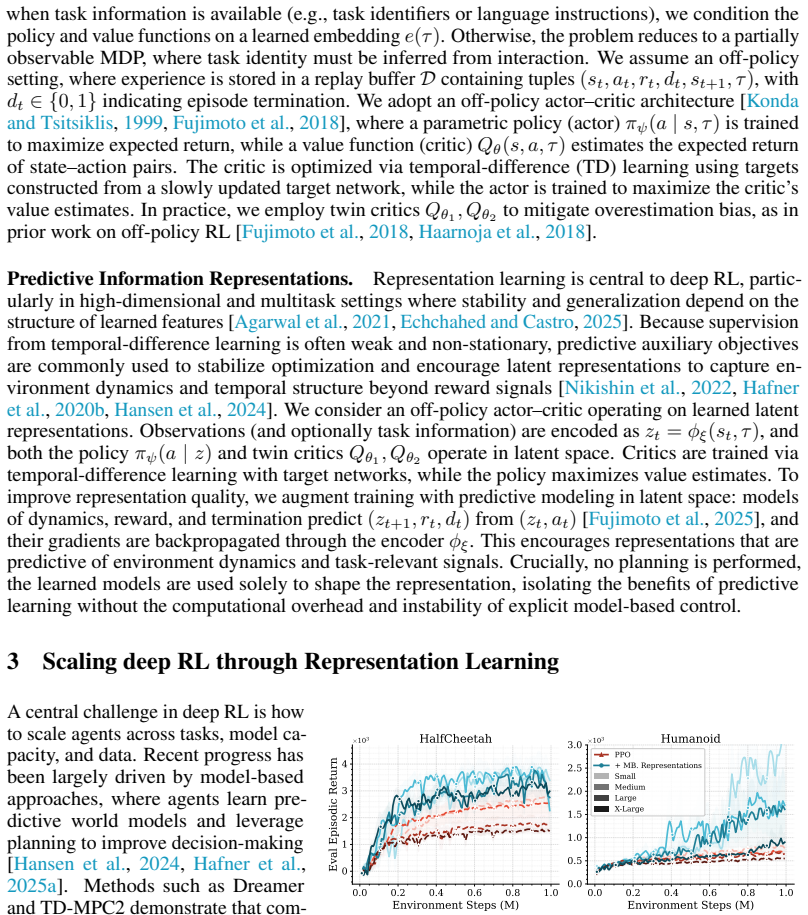
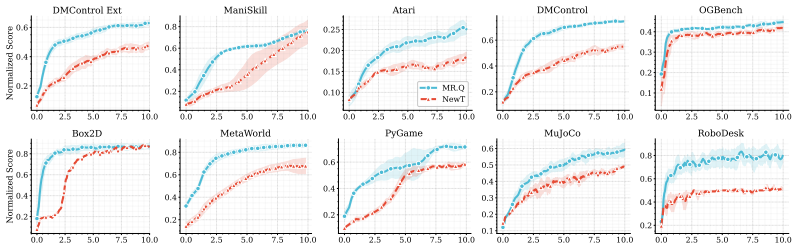


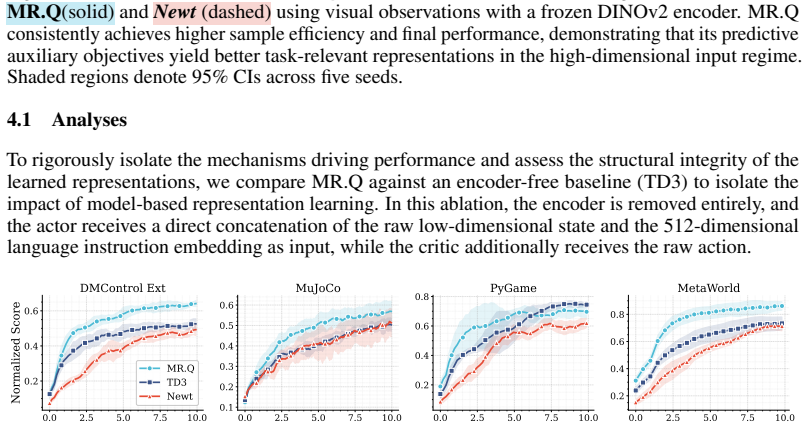
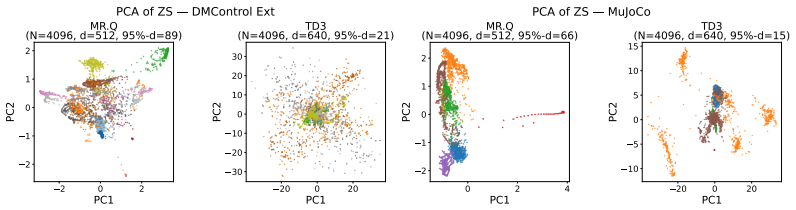
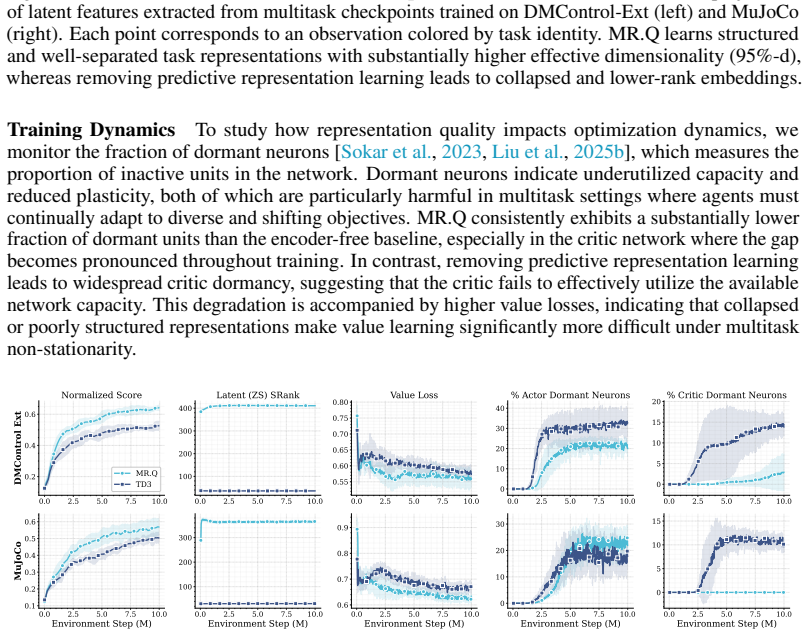

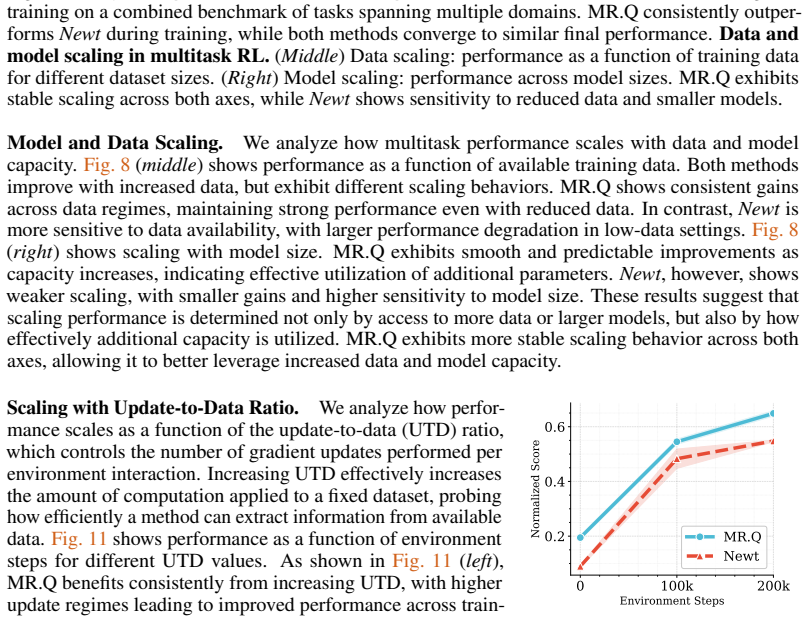
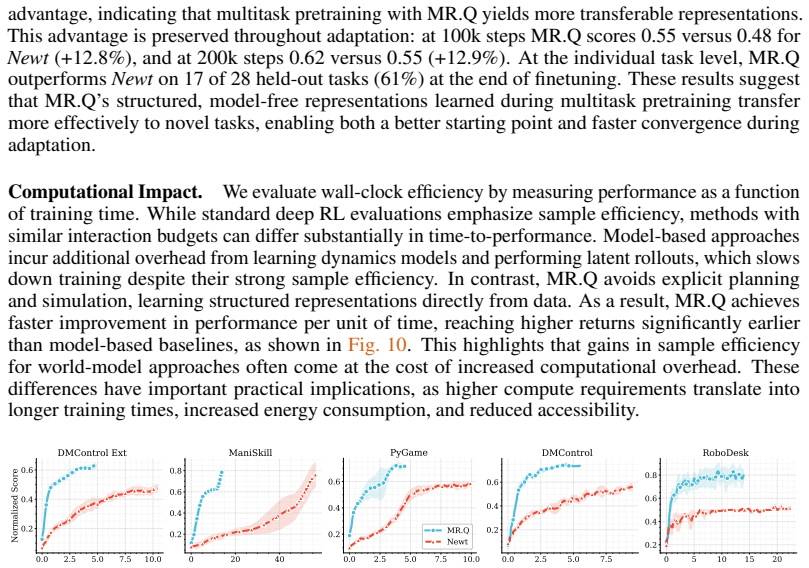
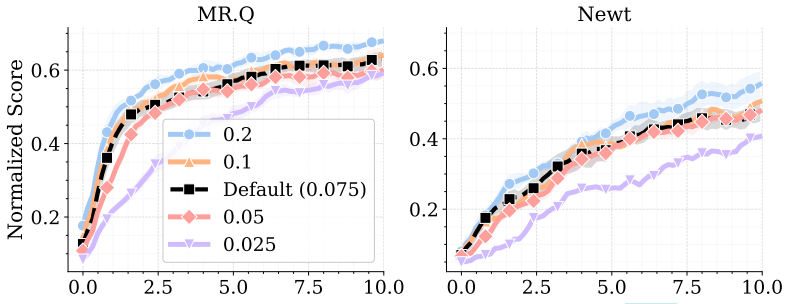
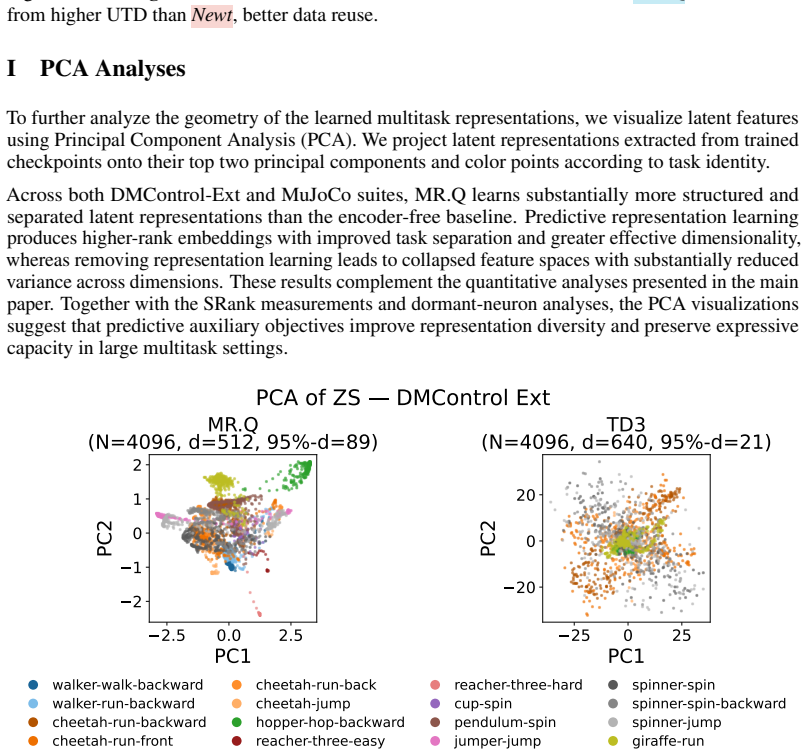
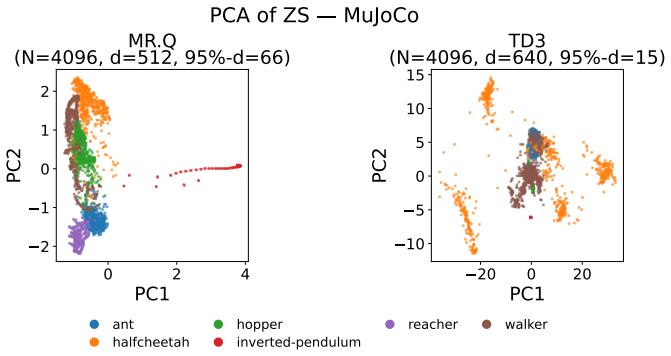
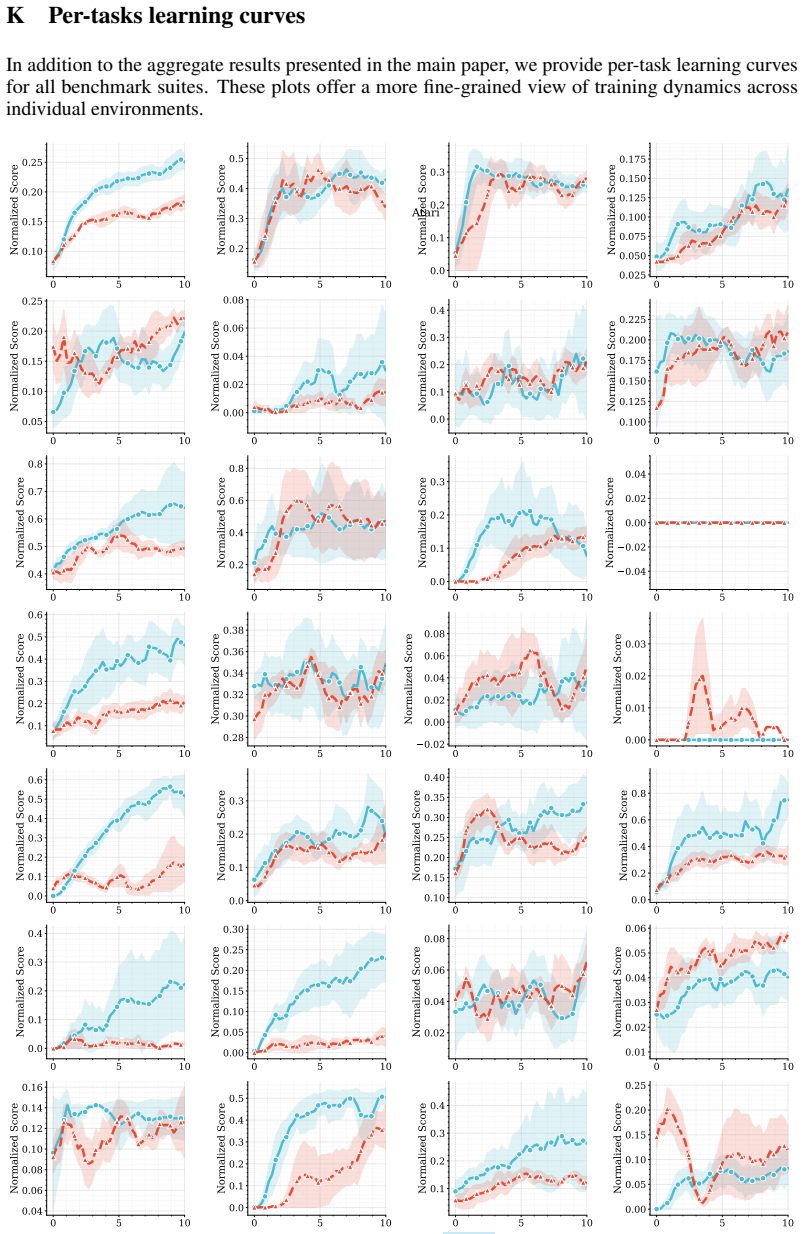
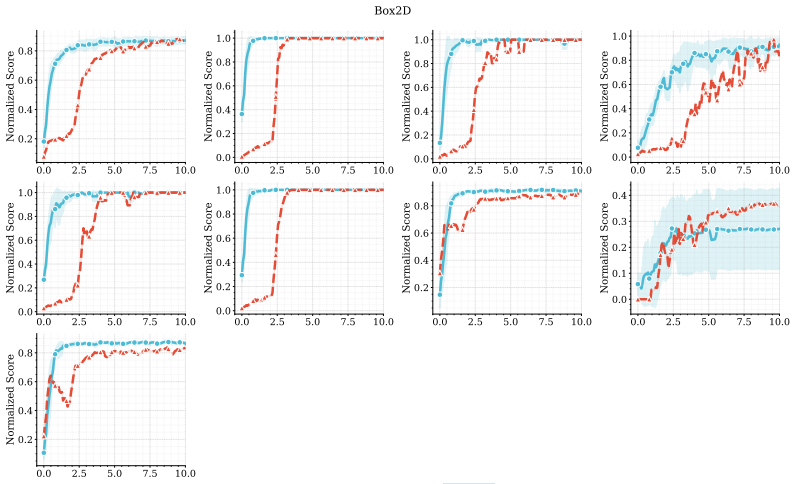
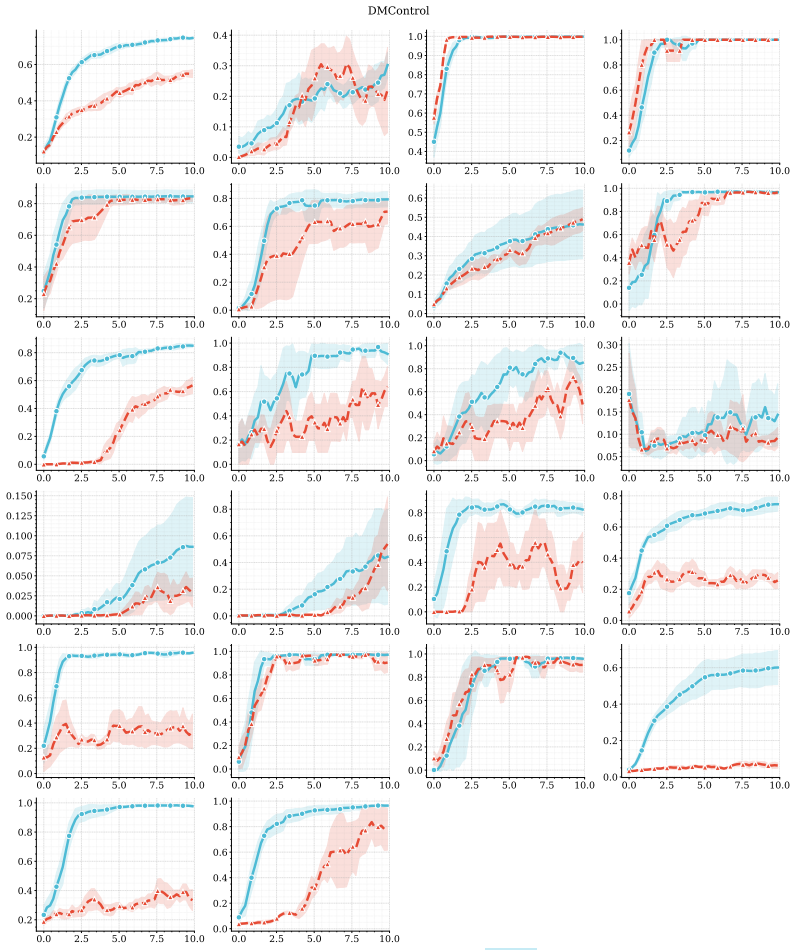
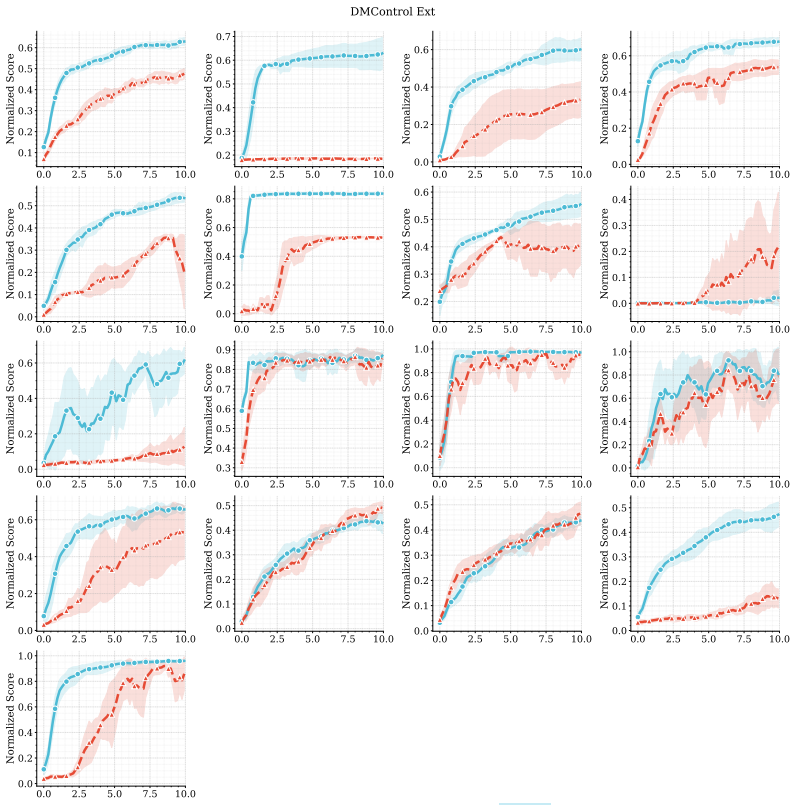
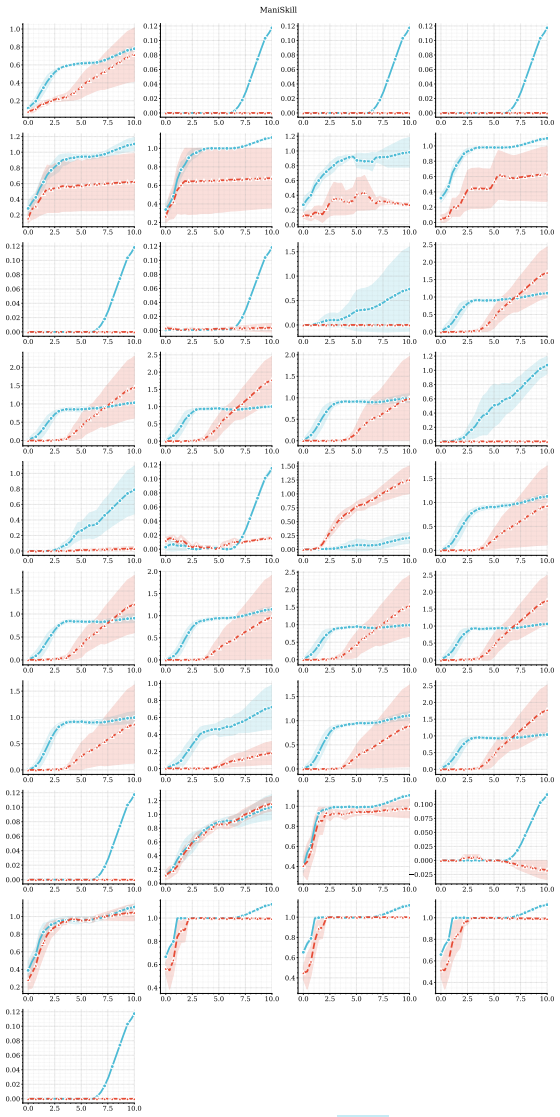
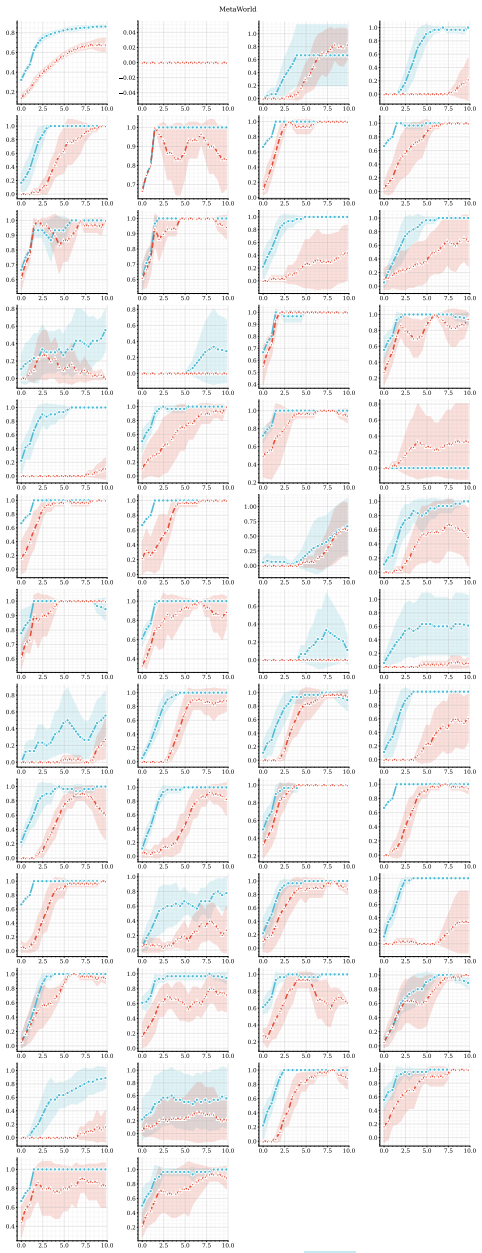
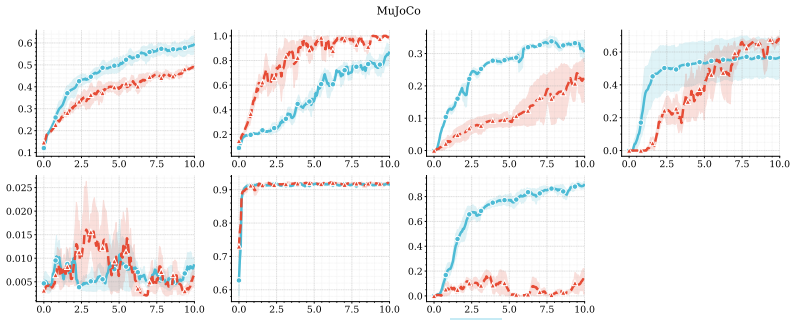
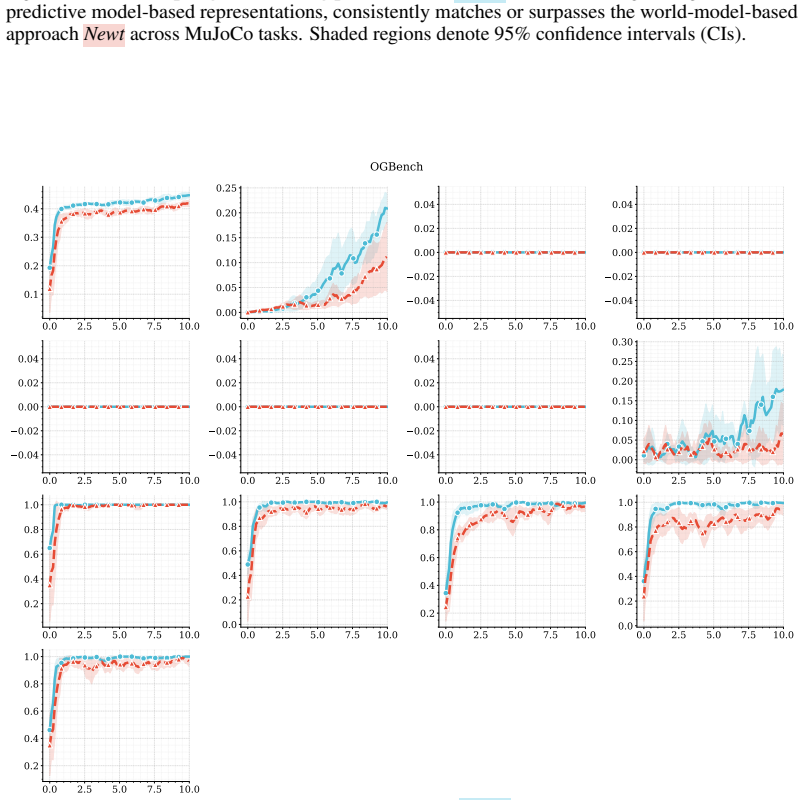
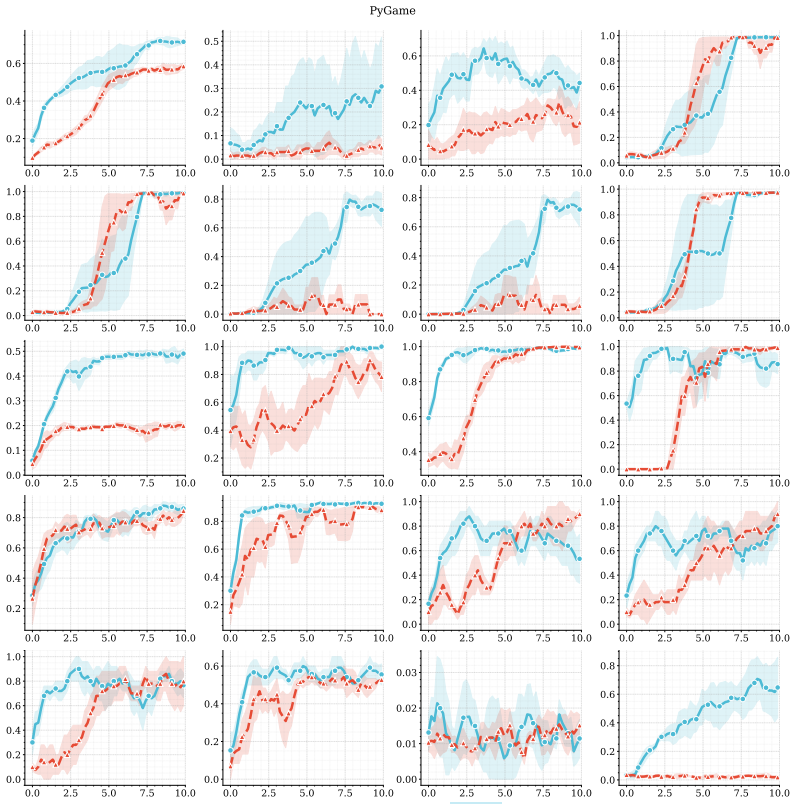
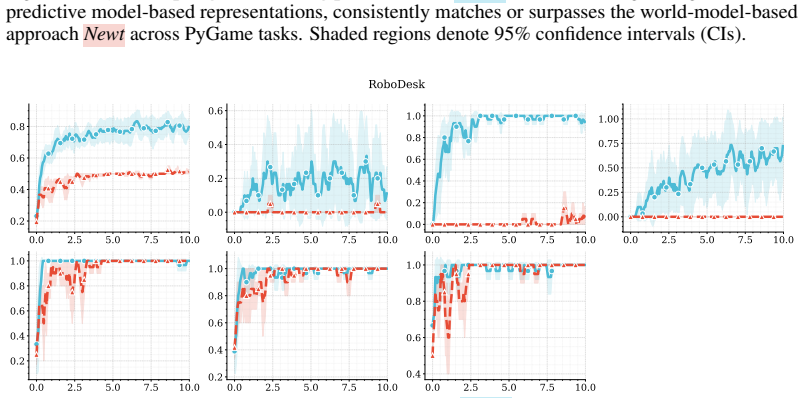
read the original abstract
Scaling reinforcement learning (RL) to diverse multitask settings remains a central challenge. While recent advances in model-based RL achieve strong performance, they rely on planning and complex training pipelines, making it unclear which components are essential for scalability. We revisit this question and argue that the primary driver of scalable multitask RL is not model-based control, but \emph{representation learning}. In particular, we show that combining predictive, model-based representations with high-capacity value function approximation is sufficient to achieve strong performance, even without planning. We evaluate a simple model-free algorithm, MR.Q, coupled with auxiliary predictive objectives into a scalable actor-critic architecture. This approach outperforms a recent world-model-based method and a range of deep RL baselines across a diverse suite of multitask continuous control tasks, while significantly reducing computational overhead and improving wall-clock efficiency. We observe consistent improvements with increased model capacity and show through ablations that predictive representation learning is critical for performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that scalable multitask deep RL is primarily driven by representation learning via auxiliary predictive objectives rather than model-based planning. It introduces the model-free actor-critic MR.Q, which combines these predictive representations with high-capacity value function approximation to achieve strong performance without planning, outperforming a recent world-model method and other baselines on multitask continuous control tasks while reducing compute; ablations are cited to show that predictive representation learning is critical and that performance improves with model capacity.
Significance. If the result holds after addressing isolation concerns, this would indicate that predictive auxiliary objectives suffice to learn useful representations for multitask RL, challenging the necessity of planning and complex world models. It would simplify training pipelines and highlight efficiency gains. The paper explicitly provides ablations on predictive objectives and capacity scaling experiments as supporting evidence.
major comments (2)
- [Abstract and §4] Abstract and §4 (MR.Q description): the claim that auxiliary predictive objectives produce representations enabling scalable multitask performance (without planning) is load-bearing, yet MR.Q jointly optimizes the encoder, value head, and policy; the ablations do not isolate semantic representation quality from extra gradient flow through shared parameters (e.g., no frozen pretrained encoder or linear-probe accuracy on task quantities is described).
- [§5] §5 (Experiments and ablations): the reported outperformance over the world-model baseline lacks quantitative details, error bars, or task/dataset descriptions in the abstract, and the ablation tables do not control for whether predictive objectives merely regularize training versus genuinely improving downstream value approximation.
minor comments (2)
- [Abstract] Abstract: states consistent improvements with model capacity but provides no specific metrics or scaling curves to quantify the effect.
- [§4] Notation: the integration of auxiliary predictive losses into the actor-critic objective could be clarified with an explicit combined loss equation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (MR.Q description): the claim that auxiliary predictive objectives produce representations enabling scalable multitask performance (without planning) is load-bearing, yet MR.Q jointly optimizes the encoder, value head, and policy; the ablations do not isolate semantic representation quality from extra gradient flow through shared parameters (e.g., no frozen pretrained encoder or linear-probe accuracy on task quantities is described).
Authors: We acknowledge that the current ablations compare runs with and without the auxiliary predictive objectives but do not include a frozen-encoder control or linear-probe evaluation on downstream task quantities. These additional controls would more cleanly separate representation quality from the extra gradient flow through shared parameters. The existing results show that removing the predictive objectives consistently degrades multitask performance, which we interpret as evidence for their role in representation learning; however, we agree this does not fully isolate the semantic quality of the representations. In revision we will add an explicit discussion of this limitation in §4 and, space permitting, include a linear-probe analysis on a subset of tasks to provide stronger supporting evidence. revision: partial
-
Referee: [§5] §5 (Experiments and ablations): the reported outperformance over the world-model baseline lacks quantitative details, error bars, or task/dataset descriptions in the abstract, and the ablation tables do not control for whether predictive objectives merely regularize training versus genuinely improving downstream value approximation.
Authors: Quantitative results with error bars, statistical significance, and full task/dataset descriptions appear in §5 and the appendix; the abstract summarizes the high-level outcome. We will revise the abstract to include a concise quantitative statement of the performance gains. On the regularization concern, the predictive objectives are forward-dynamics prediction losses that supply structured, task-relevant features rather than generic regularization; the ablation tables show that these objectives improve value-function approximation across a diverse multitask suite, with gains that scale with model capacity. We will add a short paragraph in §5 clarifying this distinction and referencing the capacity-scaling results. revision: yes
Circularity Check
Empirical method comparison with no derivation chain or self-referential reductions
full rationale
The manuscript is an empirical RL paper that introduces the MR.Q algorithm, trains it end-to-end on multitask continuous-control benchmarks, and reports performance gains plus ablations. No mathematical derivation, uniqueness theorem, or first-principles result is asserted; the central claim is supported solely by experimental outcomes rather than by any equation that reduces to its own inputs by construction. No self-citations appear as load-bearing premises, no parameters are fitted on a subset and then relabeled as predictions, and no ansatz is smuggled via prior work. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 38th International Conference on Machine Learning , year =
Revisiting Rainbow: Promoting more insightful and inclusive deep reinforcement learning research , author=. Proceedings of the 38th International Conference on Machine Learning , year =
-
[2]
International Conference on Learning Representations , year=
What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study , author=. International Conference on Learning Representations , year=
-
[3]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Hadamax Encoding: Elevating Performance in Model-Free Atari , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[4]
Proceedings of the 40th International Conference on Machine Learning , pages =
Simplified Temporal Consistency Reinforcement Learning , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[5]
Simplifying Model-based
Raj Ghugare and Homanga Bharadhwaj and Benjamin Eysenbach and Sergey Levine and Russ Salakhutdinov , booktitle=. Simplifying Model-based. 2023 , url=
2023
-
[6]
Proceedings of the aaai conference on artificial intelligence , volume=
Improving sample efficiency in model-free reinforcement learning from images , author=. Proceedings of the aaai conference on artificial intelligence , volume=
-
[7]
1000 Layer Networks for Self-Supervised
Kevin Wang and Ishaan Javali and Micha. 1000 Layer Networks for Self-Supervised. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[8]
The Eleventh International Conference on Learning Representations , year=
Proto-Value Networks: Scaling Representation Learning with Auxiliary Tasks , author=. The Eleventh International Conference on Learning Representations , year=
-
[9]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[10]
arXiv preprint arXiv:2505.22642 , year=
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control , author=. arXiv preprint arXiv:2505.22642 , year=
-
[11]
2024 , url=
Nicklas Hansen and Hao Su and Xiaolong Wang , booktitle=. 2024 , url=
2024
-
[12]
Deep Reinforcement Learning Workshop NeurIPS 2022 , year=
Sample-efficient reinforcement learning by breaking the replay ratio barrier , author=. Deep Reinforcement Learning Workshop NeurIPS 2022 , year=
2022
-
[13]
Advances in neural information processing systems , volume=
For sale: State-action representation learning for deep reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[14]
International Conference on Machine Learning , pages=
Parallel Q -Learning: Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[15]
International Conference on Machine Learning , pages=
Bigger, better, faster: Human-level atari with human-level efficiency , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[16]
International conference on machine learning , pages=
Addressing function approximation error in actor-critic methods , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[17]
International conference on machine learning , pages=
A distributional perspective on reinforcement learning , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[18]
Advances in neural information processing systems , volume=
Mastering atari games with limited data , author=. Advances in neural information processing systems , volume=
-
[19]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Towards General-Purpose Model-Free Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[20]
International conference on machine learning , pages=
The primacy bias in deep reinforcement learning , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[21]
Jianlan Luo and Charles Xu and Jeffrey Wu and Sergey Levine , title =. Science Robotics , volume =. 2025 , doi =. https://www.science.org/doi/pdf/10.1126/scirobotics.ads5033 , abstract =
-
[22]
7th Annual Conference on Robot Learning , year=
Robot Parkour Learning , author=. 7th Annual Conference on Robot Learning , year=
-
[23]
The International Journal of Robotics Research , volume=
Rapid locomotion via reinforcement learning , author=. The International Journal of Robotics Research , volume=. 2024 , publisher=
2024
-
[24]
2022 , eprint=
A Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning , author=. 2022 , eprint=
2022
-
[25]
2017 , eprint=
Data-efficient Deep Reinforcement Learning for Dexterous Manipulation , author=. 2017 , eprint=
2017
-
[26]
arXiv preprint arXiv:1910.07113 , year=
Solving rubik's cube with a robot hand , author=. arXiv preprint arXiv:1910.07113 , year=
Pith/arXiv arXiv 1910
-
[27]
arXiv preprint arXiv:2507.23172 , year=
Benchmarking Massively Parallelized Multi-Task Reinforcement Learning for Robotics Tasks , author=. arXiv preprint arXiv:2507.23172 , year=
-
[28]
Advances in neural information processing systems , volume=
Bigger, regularized, optimistic: scaling for compute and sample efficient continuous control , author=. Advances in neural information processing systems , volume=
-
[29]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Learning better with less: Effective augmentation for sample-efficient visual reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
International Conference on Machine Learning , pages=
EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[32]
Forty-second International Conference on Machine Learning , year=
The Impact of On-Policy Parallelized Data Collection on Deep Reinforcement Learning Networks , author=. Forty-second International Conference on Machine Learning , year=
-
[33]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
MICo: Improved representations via sampling-based state similarity for Markov decision processes , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
The Nineth International Conference on Learning Representations (ICLR) , year=
Data-Efficient Reinforcement Learning with Self-Predictive Representations , author=. The Nineth International Conference on Learning Representations (ICLR) , year=
-
[36]
International conference on machine learning , pages=
Curl: Contrastive unsupervised representations for reinforcement learning , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[37]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Isaac Gym: High Performance GPU Based Physics Simulation For Robot Learning , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[38]
Advances in neural information processing systems , volume=
Unsupervised state representation learning in atari , author=. Advances in neural information processing systems , volume=
-
[39]
5th Annual Conference on Robot Learning , year=
Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning , author=. 5th Annual Conference on Robot Learning , year=
-
[40]
Communications of the ACM , volume=
Green ai , author=. Communications of the ACM , volume=. 2020 , publisher=
2020
-
[41]
Journal of Machine Learning Research , volume=
Towards the systematic reporting of the energy and carbon footprints of machine learning , author=. Journal of Machine Learning Research , volume=
-
[42]
2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=
Domain randomization for transferring deep neural networks from simulation to the real world , author=. 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=. 2017 , organization=
2017
-
[43]
International conference on machine learning , pages=
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[44]
and Naddaf, Yavar and Veness, Joel and Bowling, Michael , title =
Bellemare, Marc G. and Naddaf, Yavar and Veness, Joel and Bowling, Michael , title =. J. Artif. Int. Res. , month = may, pages =. 2013 , issue_date =
2013
-
[45]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[46]
International Conference on Machine Learning , pages=
The dormant neuron phenomenon in deep reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[47]
International Conference on Learning Representations , year=
Implicit Under-Parameterization Inhibits Data-Efficient Deep Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[48]
Nature , volume=
Loss of plasticity in deep continual learning , author=. Nature , volume=. 2024 , publisher=
2024
-
[49]
The Fourteenth International Conference on Learning Representations , year=
Learning Massively Multitask World Models for Continuous Control , author=. The Fourteenth International Conference on Learning Representations , year=
-
[50]
Simplicial Embeddings Improve Sample Efficiency in Actor
Johan Obando-Ceron and Walter Mayor and Samuel Lavoie and Scott Fujimoto and Aaron Courville and Pablo Samuel Castro , booktitle=. Simplicial Embeddings Improve Sample Efficiency in Actor. 2026 , url=
2026
-
[51]
2025 , url=
Ignat Georgiev and Varun Giridhar and Nicklas Hansen and Animesh Garg , booktitle=. 2025 , url=
2025
-
[52]
, journal=
Oliphant, Travis E. , journal=. Python for Scientific Computing , year=
-
[53]
arXiv preprint arXiv:2602.19373 , year=
Stable Deep Reinforcement Learning via Isotropic Gaussian Representations , author=. arXiv preprint arXiv:2602.19373 , year=
-
[54]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Picor: Multi-task deep reinforcement learning with policy correction , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[55]
International conference on machine learning , pages=
Multi-task reinforcement learning with context-based representations , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[56]
Proceedings of the 39th International Conference on Machine Learning , pages =
Temporal Difference Learning for Model Predictive Control , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[57]
Proceedings of the 36th International Conference on Machine Learning , pages =
Learning Latent Dynamics for Planning from Pixels , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[58]
International Conference on Learning Representations , year=
Learning Invariant Representations for Reinforcement Learning without Reconstruction , author=. International Conference on Learning Representations , year=
-
[59]
International Conference on Learning Representations , year=
Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels , author=. International Conference on Learning Representations , year=
-
[60]
International Conference on Learning Representations , year=
Mastering Visual Continuous Control: Improved Data-Augmented Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[61]
Proceedings of the 41st International Conference on Machine Learning , pages=
Overestimation, overfitting, and plasticity in actor-critic: the bitter lesson of reinforcement learning , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[62]
International Conference on Machine Learning , pages=
Mixtures of Experts Unlock Parameter Scaling for Deep RL , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[63]
International Conference on Machine Learning , pages=
In value-based deep reinforcement learning, a pruned network is a good network , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[64]
Journal of Machine Learning Research , volume=
Cleanrl: High-quality single-file implementations of deep reinforcement learning algorithms , author=. Journal of Machine Learning Research , volume=
-
[65]
The Thirteenth International Conference on Learning Representations , year=
Studying the Interplay Between the Actor and Critic Representations in Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[66]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
A Study of Plasticity Loss in On-Policy Deep Reinforcement Learning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[67]
arXiv preprint arXiv:1509.02971 , year=
Continuous control with deep reinforcement learning , author=. arXiv preprint arXiv:1509.02971 , year=
-
[68]
International Conference on Learning Representations , year=
Mastering Atari with Discrete World Models , author=. International Conference on Learning Representations , year=
-
[69]
Nature , pages=
Mastering diverse control tasks through world models , author=. Nature , pages=. 2025 , publisher=
2025
-
[70]
Forty-second International Conference on Machine Learning , year=
Network Sparsity Unlocks the Scaling Potential of Deep Reinforcement Learning , author=. Forty-second International Conference on Machine Learning , year=
-
[71]
International Conference on Machine Learning , pages=
Off-Policy Deep Reinforcement Learning without Exploration , author=. International Conference on Machine Learning , pages=
-
[72]
Qingmao Yao and Zhichao Lei and Tianyuan Chen and Ziyue Yuan and Xuefan Chen and Jianxiang Liu and Faguo Wu and Xiao Zhang , booktitle=. Offline. 2025 , url=
2025
-
[73]
1995 , publisher=
Python reference manual , author=. 1995 , publisher=
1995
-
[74]
Nature , volume=
Array programming with NumPy , author=. Nature , volume=. 2020 , publisher=
2020
-
[75]
Computing in science & engineering , volume=
Matplotlib: A 2D graphics environment , author=. Computing in science & engineering , volume=. 2007 , publisher=
2007
-
[76]
JAX: composable transformations of Python+ NumPy programs , author=
-
[77]
IOS Press , year = 2016, pages =
Jupyter Notebooks a publishing format for reproducible computational workflows. IOS Press , year = 2016, pages =. doi:10.3233/978-1-61499-649-1-87 , adsurl =
-
[78]
Python for Data Analysis: Data Wrangling with Pandas,
McKinney, Wes , biburl =. Python for Data Analysis: Data Wrangling with Pandas,
-
[79]
2025 , url=
Claas A Voelcker and Marcel Hussing and Eric Eaton and Amir-massoud Farahmand and Igor Gilitschenski , booktitle=. 2025 , url=
2025
-
[80]
Mixture of Experts in a Mixture of
Timon Willi and Johan Samir Obando Ceron and Jakob Nicolaus Foerster and Gintare Karolina Dziugaite and Pablo Samuel Castro , booktitle=. Mixture of Experts in a Mixture of. 2024 , url=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.