TensorBench: Benchmarking Coding Agents on a Compiler-Based Tensor Framework
Pith reviewed 2026-06-28 01:53 UTC · model grok-4.3
The pith
TensorBench grades coding agents on 199 tensor compiler tasks via test suites, with top pass rate at 64.8 percent and low agreement across agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
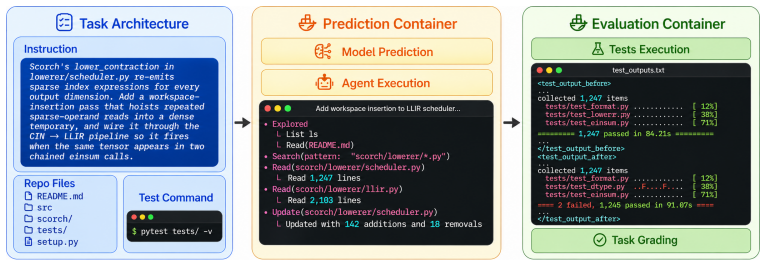
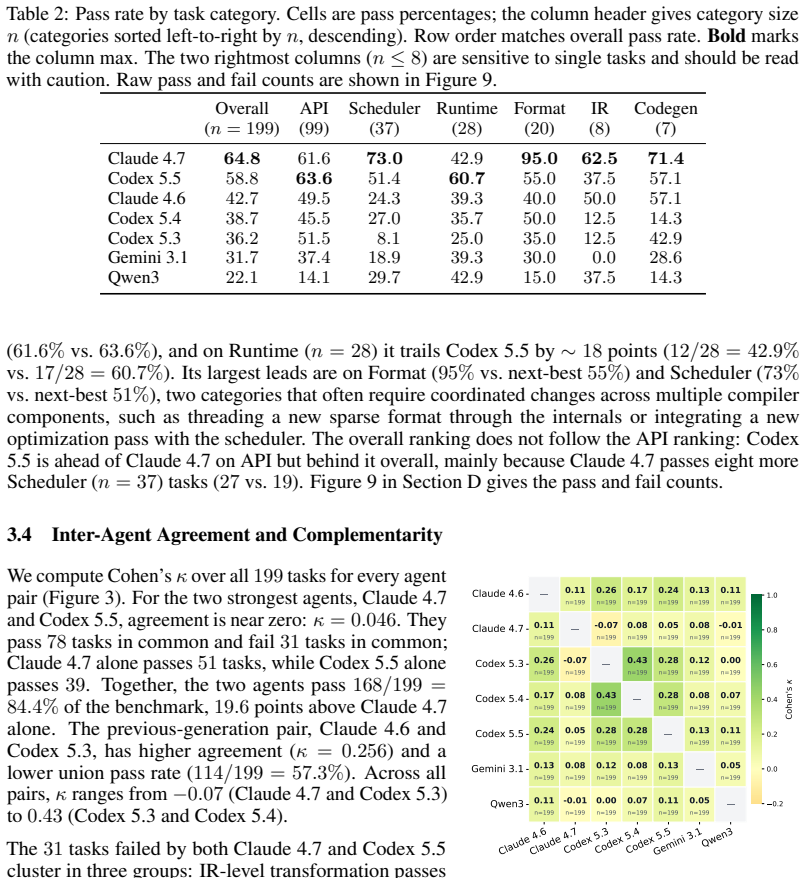
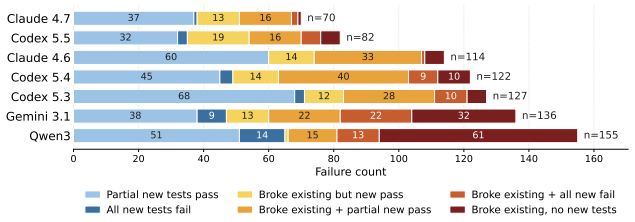
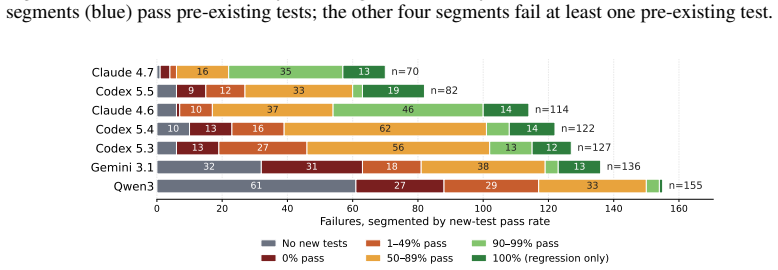
TensorBench is a benchmark of 199 tasks covering new sparse formats, dense optimization passes, IR transformations, scheduler changes, runtime components, and high-level numerical operators on a compiler-based tensor framework. Grading applies the patch and runs the test suite; success for feature-addition tasks means preserved pre-existing behavior plus satisfaction of agent-added checks. The seven evaluated agents achieve pass rates from 64.8 percent for the strongest to 22.1 percent for the weakest, and they succeed on largely disjoint subsets of tasks as shown by low Cohen's kappa values.
What carries the argument
The test-suite grading mechanism that applies an agent's patch to the tensor framework repository and runs the pre-existing randomized regression tests plus any agent-added tests to decide pass or fail.
If this is right
- Agents with higher pass rates can perform more of the listed compiler changes than lower-performing agents.
- The low pairwise kappa values imply that agents succeed on different subsets of tasks rather than on a common core.
- Test-based grading allows the benchmark to scale to 199 tasks without requiring human review for each run.
- Current frontier agents leave between 35 and 78 percent of the tasks unsolved under this evaluation criterion.
Where Pith is reading between the lines
- The observed low agreement suggests that an ensemble of agents might achieve higher overall coverage than any single agent.
- Extending the same test-suite method to other compiler or library codebases could test whether the performance patterns generalize.
- If the added tests are insufficiently comprehensive, reported pass rates may overstate the true rate of correct implementations.
Load-bearing premise
That running the framework's existing randomized regression tests plus any tests added by the agent is sufficient to confirm correct implementation of the requested feature or refactor without introducing undetected bugs or behavioral changes.
What would settle it
An agent's patch that passes every test in the suite yet produces incorrect numerical results or crashes on an input case outside the covered regression tests.
Figures


read the original abstract
Repository-level coding benchmarks face a trade-off between task difficulty and evaluation reliability: tasks that challenge frontier models often involve large codebases with incomplete test coverage, while human review does not scale. We introduce TensorBench, a benchmark of 199 feature-addition and refactoring tasks on an open-source compiler-based tensor framework that extends PyTorch with first-class support for dense and sparse tensors. Tasks cover new sparse formats, dense optimization passes, IR transformations, scheduler changes, runtime components, and high-level numerical operators. TensorBench grades each run by applying the agent's patch and running the framework's test suite, which includes the pre-existing randomized regression tests and any tests the agent adds. For feature-addition tasks, a pass means that the patched repository preserves the tested pre-existing behavior and satisfies the agent-added checks for the requested feature. We evaluate seven coding agents spanning three frontier model families and one open-weight model. Pass rates under this criterion range from $64.8\%$ for the strongest agent to $22.1\%$ for the weakest. Agents pass different subsets of tasks: pairwise Cohen's $\kappa$ ranges from $-0.07$ to $0.43$, with $\kappa = 0.05$ for the two strongest agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TensorBench, a benchmark of 199 feature-addition and refactoring tasks on an open-source compiler-based tensor framework extending PyTorch with first-class dense and sparse tensor support. Tasks span new sparse formats, dense optimization passes, IR transformations, scheduler changes, runtime components, and high-level numerical operators. Evaluation applies each agent's patch and runs the framework's test suite (pre-existing randomized regression tests plus any tests added by the agent); a feature-addition task passes if pre-existing behavior is preserved and agent-added checks are satisfied. Seven agents from three frontier model families plus one open-weight model are evaluated, yielding pass rates from 64.8% (strongest) to 22.1% (weakest) and pairwise Cohen's κ values from -0.07 to 0.43.
Significance. If the automated grading reliably confirms correct implementations, TensorBench supplies a scalable, human-review-free method for benchmarking repository-level coding agents on compiler infrastructure tasks. The reported pass rates and low inter-agent agreement would then usefully document current agent limitations and complementary capabilities on a non-trivial open codebase. The open framework and task set enable reproducibility and community extension.
major comments (2)
- [Abstract] Abstract (evaluation paragraph): The headline pass rates (64.8%–22.1%) and the claim that agents solve different subsets (supported by κ values) rest entirely on the grading rule that a patch passes when it preserves behavior on the pre-existing randomized regression tests and satisfies any agent-added tests. Randomized regression tests have inherent coverage limits for compiler IR transformations, scheduler changes, new sparse formats, and runtime components; agent-added tests can be minimal, incorrect, or narrowly scoped. Consequently, a non-negligible fraction of reported passes may reflect undetected behavioral changes or partial implementations rather than correct task completion. This directly undermines the central empirical claims.
- [Abstract] Abstract (task description): No information is supplied on how the 199 tasks were constructed, the distribution across categories (e.g., number involving sparse formats versus runtime), or selection criteria. Without these details it is impossible to assess whether the benchmark fairly represents the framework's challenges or whether the observed agent differences generalize beyond the chosen tasks.
minor comments (1)
- [Abstract] The abstract mentions Cohen's κ but does not state how the statistic is computed (e.g., task-level or aggregated) or the exact number of tasks entering each pairwise comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (evaluation paragraph): The headline pass rates (64.8%–22.1%) and the claim that agents solve different subsets (supported by κ values) rest entirely on the grading rule that a patch passes when it preserves behavior on the pre-existing randomized regression tests and satisfies any agent-added tests. Randomized regression tests have inherent coverage limits for compiler IR transformations, scheduler changes, new sparse formats, and runtime components; agent-added tests can be minimal, incorrect, or narrowly scoped. Consequently, a non-negligible fraction of reported passes may reflect undetected behavioral changes or partial implementations rather than correct task completion. This directly undermines the central empirical claims.
Authors: We agree that randomized regression tests have inherent coverage limitations for complex compiler components and that agent-added tests may vary in quality or scope; this is an inherent challenge for any automated, test-based evaluation of repository-level changes. The grading rule is explicitly defined in the paper as requiring both preservation of pre-existing tested behavior and satisfaction of the new checks. In revision we will update the abstract to include a short caveat on grading limitations and add a dedicated paragraph (or subsection) in the evaluation or limitations section that discusses test coverage, the risk of undetected changes, and any manual spot-checks performed on successful patches. This will better qualify the reported pass rates and inter-agent agreement results. revision: yes
-
Referee: [Abstract] Abstract (task description): No information is supplied on how the 199 tasks were constructed, the distribution across categories (e.g., number involving sparse formats versus runtime), or selection criteria. Without these details it is impossible to assess whether the benchmark fairly represents the framework's challenges or whether the observed agent differences generalize beyond the chosen tasks.
Authors: We will revise the abstract to briefly describe the task categories and add explicit details on task construction, category distribution, and selection criteria (e.g., a short summary or table) to the main text. This will make the benchmark's scope and representativeness transparent to readers. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurement
full rationale
The paper introduces TensorBench as an empirical evaluation of coding agents on a tensor framework. It defines tasks, applies patches, and measures pass rates by executing the framework's existing randomized regression tests plus any agent-added tests. No mathematical derivations, fitted parameters, predictions, or self-citation chains are present; pass rates (64.8%–22.1%) and Cohen's κ values are direct empirical counts from test execution, not quantities derived by construction from the inputs or prior self-citations. The evaluation is self-contained against external benchmarks (the open-source framework and its test suite) with no reduction of results to definitions or fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.06992 , year=
Reem Aleithan, Haoran Xue, Mohammad Mahdi Mohajer, Elijah Nnorom, Gias Uddin, and Song Wang. SWE-Bench+: Enhanced coding benchmark for LLMs.arXiv preprint arXiv:2410.06992, 2024
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
MLE-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, et al. MLE-bench: Evaluating machine learning agents on machine learning engineering. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Format abstraction for sparse tensor algebra compilers.Proceedings of the ACM on Programming Languages, 2(OOPSLA):1–30, 2018
Stephen Chou, Fredrik Kjolstad, and Saman Amarasinghe. Format abstraction for sparse tensor algebra compilers.Proceedings of the ACM on Programming Languages, 2(OOPSLA):1–30, 2018
2018
-
[6]
arXiv preprint arXiv:2309.07062 , year =
Chris Cummins, V olker Seeker, Dejan Grubisic, Mostafa Elhoushi, Youwei Liang, Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Kim Hazelwood, Gabriel Synnaeve, et al. Large language models for compiler optimization.arXiv preprint arXiv:2309.07062, 2023
-
[7]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. SWE-bench Pro: Can AI agents solve long- horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Measuring coding challenge competence with APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. Measuring coding challenge competence with APPS. InProceedings of the NeurIPS Track on Datasets and Benchmarks, 2021
2021
-
[9]
SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=VTF8yNQM66
2024
-
[10]
The tensor algebra compiler.Proceedings of the ACM on Programming Languages, 1(OOPSLA): 1–29, 2017
Fredrik Kjolstad, Shoaib Kamil, Stephen Chou, David Lugato, and Saman Amarasinghe. The tensor algebra compiler.Proceedings of the ACM on Programming Languages, 1(OOPSLA): 1–29, 2017
2017
-
[11]
Tensor algebra compilation with workspaces
Fredrik Kjolstad, Willow Ahrens, Shoaib Kamil, and Saman Amarasinghe. Tensor algebra compilation with workspaces. In2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 180–192. IEEE, 2019. 10
2019
-
[12]
Compiler validation via equivalence modulo inputs
Vu Le, Mehrdad Afshari, and Zhendong Su. Compiler validation via equivalence modulo inputs. InProceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pages 216–226. ACM, 2014
2014
-
[13]
Competition-level code generation with AlphaCode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with AlphaCode.Science, 378(6624):1092–1097, 2022
2022
-
[14]
RepoBench: Benchmarking repository- level code auto-completion systems
Tianyang Liu, Canwen Xu, and Julian McAuley. RepoBench: Benchmarking repository- level code auto-completion systems. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[15]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[16]
Merrill, Alexander G
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, et al. Terminal-Bench: Bench- marking agents on hard, realistic tasks in command line interfaces. InThe F ourteenth Interna- tional Conference on Learning Representations (ICLR), 2026
2026
-
[17]
GAIA: A benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[18]
Introducing SWE-bench verified
OpenAI. Introducing SWE-bench verified. https://openai.com/index/ introducing-swe-bench-verified/ , 2024. Blog post, August 13, 2024; updated February 24, 2025
2024
-
[19]
PaperBench: Evaluating AI's Ability to Replicate AI Research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. PaperBench: Evaluating AI’s ability to replicate AI research.arXiv preprint arXiv:2504.01848, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Root, Trevor Gale, David Broman, and Fredrik Kjolstad
Bobby Yan, Alexander J. Root, Trevor Gale, David Broman, and Fredrik Kjolstad. Fast autoscheduling for sparse ML frameworks. In2026 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 28–43. IEEE, 2026. doi: 10.1109/CGO68049. 2026.11394842
-
[21]
Jimenez, Alex L
John Yang, Carlos E. Jimenez, Alex L. Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R. Narasimhan, et al. SWE-bench multimodal: Do AI systems generalize to visual software domains? InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[22]
Finding and understanding bugs in C compilers
Xuejun Yang, Yang Chen, Eric Eide, and John Regehr. Finding and understanding bugs in C compilers. InProceedings of the 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pages 283–294, 2011
2011
-
[23]
Multi-SWE-bench: A multilingual benchmark for issue resolving
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Shulin Xin, Linhao Zhang, Qi Liu, Aoyan Li, Lu Chen, Xiaojian Zhong, et al. Multi-SWE-bench: A multilingual benchmark for issue resolving. InAdvances in Neural Information Processing Systems, volume 38, 2025
2025
-
[24]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. CodeAgent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13643–13658, Bangkok, Thailand, 2024. Association for Computatio...
-
[25]
SWE-bench goes live! InAdvances in Neural Information Processing Systems, volume 38, 2025
Linghao Zhang, Shilin He, Chaoyun Zhang, Yu Kang, Bowen Li, Chengxing Xie, Junhao Wang, Maoquan Wang, Yufan Huang, Shengyu Fu, et al. SWE-bench goes live! InAdvances in Neural Information Processing Systems, volume 38, 2025. 11
2025
-
[26]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[27]
density class
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. BigCodeBench: Benchmarking code generation with diverse function calls and complex instructions. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025. A Dataset Construction Det...
2025
-
[28]
Build a Docker image based onpython:3.11-slim with PyTorch, the Scorch git tree pinned to the task’sbase_commit, and the C++ runtime built once at image-build time
-
[29]
Mount the agent’s environment (system prompt, agent CLI, model credentials) and start the agent with the task description and a frozen working copy of the repo
-
[30]
Capture a unified diff covering all the agent’s edits at the end of the session
-
[31]
Start a fresh container, apply the diff, clear the JIT-compiled-extension cache, rebuild the C++ runtime (idempotent if unchanged), and executepytest tests/ -v –tb=short
-
[32]
Parse verbose pytest output line-by-line to count passed / failed / errored tests by name, falling back to the summary line if no verbose lines are found
-
[33]
Note: Do not run the test suite
Mark the task as successful iffafter.failed == 0andafter.error == 0. Harness implementation.The harness is a thin wrapper around codebench-core, a task-agnostic harness. The benchmark-specific code is limited to: (1) the dataset of 199 tasks, (2) a Dockerfile and a 60-linerun_tests.sh, and (3) a 300-line grading strategy that parses verbose pytest output....
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.