AsyncWebRL: Efficient Multi-Step RL for Visual Web Agents
Pith reviewed 2026-06-28 02:41 UTC · model grok-4.3
The pith
Async design overlapping rollouts with updates plus constant normalizer in GRPO speeds web RL training 2.9x and contracts verbose trajectories while preserving success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
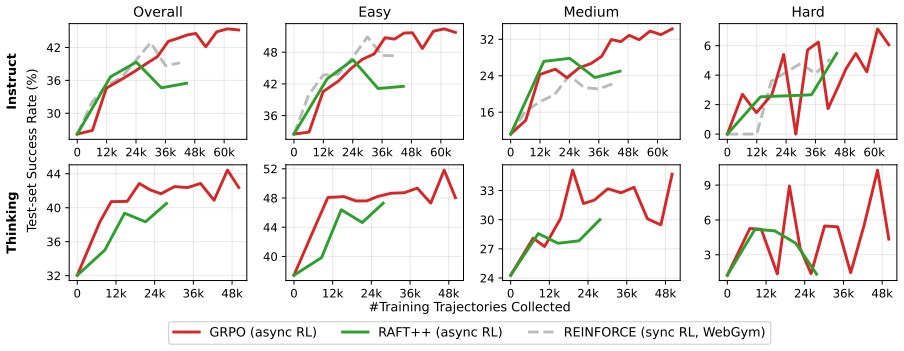
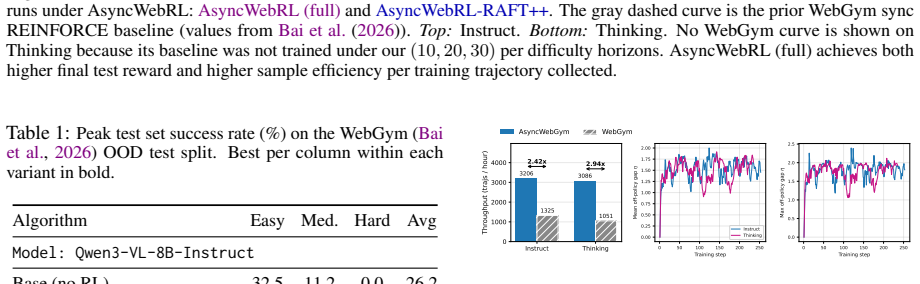
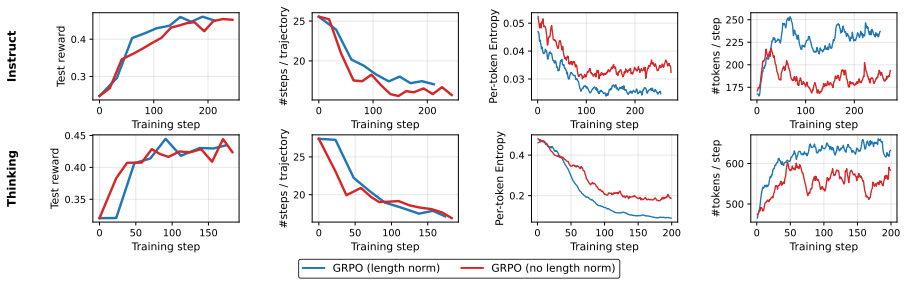
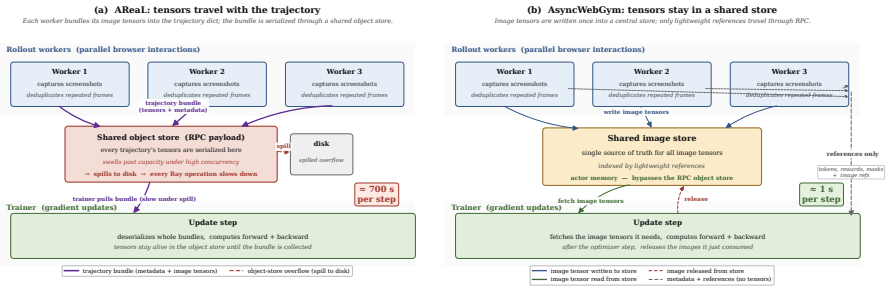
AsyncWebRL overlaps rollout, gradient update, and policy refresh across iterations using an asynchronous design with an everlasting rollout pool and lightweight screenshot handling, delivering up to 2.9 times higher end-to-end training throughput than the prior fastest open synchronous pipeline. It also identifies the per-trajectory normalizer 1/|τ_i| in multi-step GRPO as the source of token-level inefficiency, because failures are longer than successes and therefore receive weaker negative gradients; replacing it with a constant 1/k contracts trajectories while keeping aggregate success intact. The combined changes produce a new open-source state of the art on the WebGym out-of-distributio
What carries the argument
The constant normalizer 1/k in multi-step GRPO that decouples trajectory length from per-token gradient weight, together with asynchronous overlap of rollout and update steps.
If this is right
- End-to-end training throughput rises by up to 2.9 times over prior synchronous web RL pipelines.
- Agent trajectories shorten in length while aggregate task success is preserved.
- Relative performance gains reach +42 percent on medium tasks and +48 percent on hard tasks.
- New state-of-the-art open-source results on the WebGym out-of-distribution test split.
Where Pith is reading between the lines
- The same length-bias problem in GRPO normalizers is likely to appear in other multi-step RL domains where failure trajectories differ in length from successes.
- Asynchronous overlapping of rollout and update could transfer to other vision-language RL settings that currently use synchronous pipelines.
- Lower per-trajectory token counts may reduce inference-time compute when the trained agents are deployed on real web tasks.
- The approach could be combined with experience replay or other memory mechanisms to further stabilize training on long-horizon web navigation.
Load-bearing premise
Failures are systematically longer than successes, so that swapping the per-trajectory normalizer for a constant will shorten trajectories without lowering success rates or harming training stability.
What would settle it
Train the same web-agent policy with the constant 1/k normalizer and measure whether average trajectory length falls while success rate on the WebGym test split stays the same or rises.
Figures



read the original abstract
Training vision-language web agents with multi-step RL is compute-intensive, with two dominant forms of inefficiency: idle GPUs in synchronous RL, and trajectories that use more steps and tokens than necessary. We present AsyncWebRL, which addresses both. On the system side, an asynchronous design overlaps rollout, gradient update, and policy refresh across iterations, paired with two web-agent-specific adaptations, namely an everlasting rollout pool and lightweight screenshot handling, that together deliver up to a $2.9\times$ end-to-end training-throughput speedup over the previously fastest open synchronous pipeline (WebGym). On the algorithmic side, we identify the per-trajectory normalizer $1/|\tau_i|$ in multi-step GRPO as the root cause of trajectory-level and token-level inefficiency: because failures are systematically longer than successes, it down-weights the negative gradient on failed tokens, so the policy keeps producing verbose memory schemas. Replacing $1/|\tau_i|$ with a constant $1/k$ breaks this coupling, contracting trajectories while preserving aggregate success. Together, these contributions set a new open-source state of the art on the WebGym out-of-distribution test split (+5.8% relative over the 42.9% prior best), with the largest gains on the harder slices (+42% relative on Medium, +48% relative on Hard).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AsyncWebRL, an asynchronous multi-step RL framework for vision-language web agents. It claims two main contributions: (1) a system design with asynchronous rollouts, an everlasting rollout pool, and lightweight screenshot handling that yields up to 2.9× end-to-end training throughput over prior synchronous pipelines; (2) replacement of the per-trajectory normalizer 1/|τ_i| in multi-step GRPO with a constant 1/k, motivated by the observation that failures are longer than successes, which is asserted to contract trajectory lengths while preserving aggregate success rate. These changes are reported to establish a new open-source SOTA on the WebGym out-of-distribution test split (+5.8% relative over 42.9%), with larger relative gains on Medium (+42%) and Hard (+48%) slices.
Significance. If the central claims are substantiated with full experimental details, the work would offer a practical advance in scaling RL for web agents by jointly tackling compute inefficiency and trajectory verbosity. The combination of async system optimizations and the targeted normalizer change could influence training pipelines for long-horizon agents; the reported gains on harder task slices are particularly noteworthy if reproducible.
major comments (3)
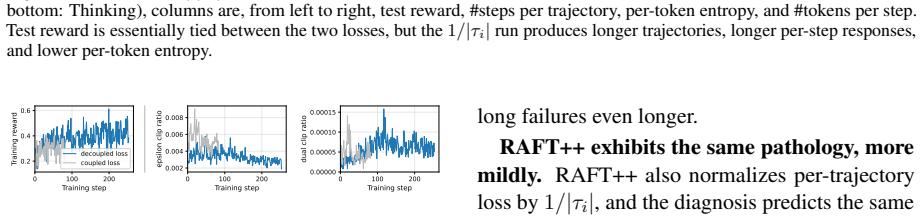
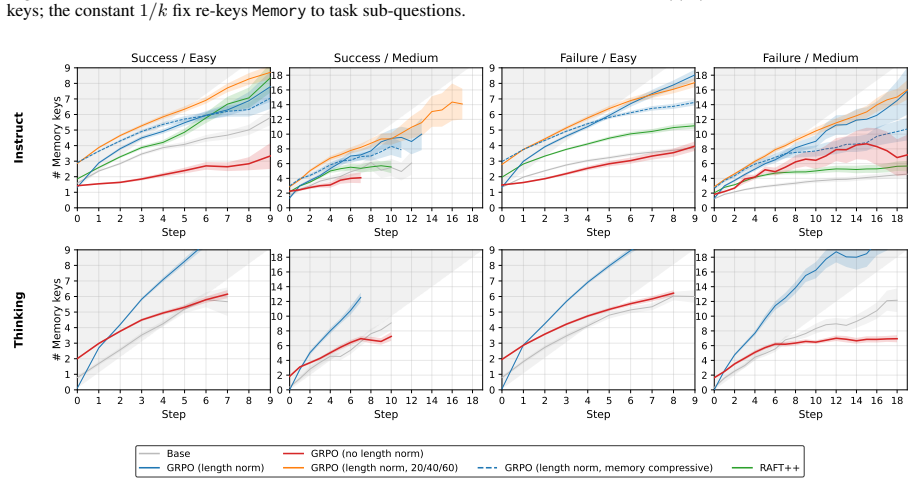
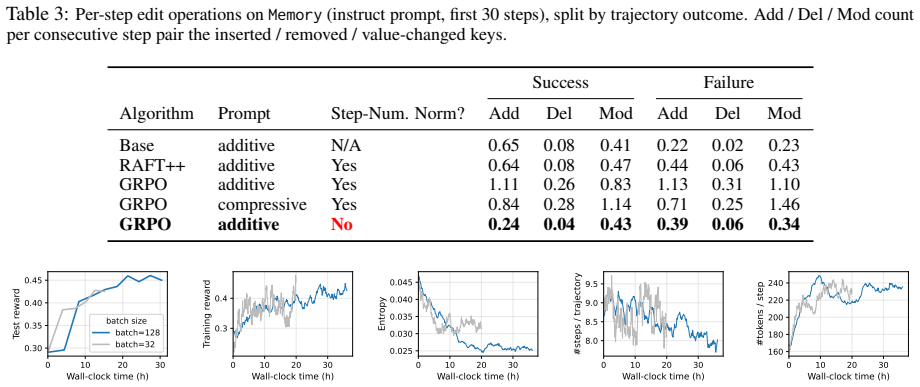
- [Abstract and §3] Abstract and §3 (algorithmic contribution): the assertion that replacing 1/|τ_i| with constant 1/k 'contracts trajectories while preserving aggregate success' without side effects on other metrics or training stability is load-bearing for the SOTA attribution, yet the provided text supplies no length histograms, per-slice success deltas, stability curves, or ablations confirming that success is unchanged rather than traded for length on some tasks.
- [§4] §4 (experiments): the headline +5.8% overall and larger gains on Medium/Hard slices are presented without error bars, ablation tables isolating the normalizer change from the async system, or verification that the constant 1/k does not introduce instability or degrade other metrics; this absence prevents assessment of whether the reported improvements are robust.
- [§2.2] §2.2 (GRPO formulation): the claim that 1/|τ_i| down-weights negative gradients on failed tokens because failures are systematically longer requires explicit quantitative support (e.g., mean length statistics for success vs. failure trajectories) to justify the normalizer swap as the root cause rather than a correlated symptom.
minor comments (2)
- The definition and value of the constant k (free parameter) should be stated explicitly with sensitivity analysis, as it appears in the free_parameters list but is not detailed in the abstract.
- Notation for trajectory length |τ_i| and the new normalizer should be introduced with a clear equation reference in the main text for readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below with clarifications and commitments to revisions that strengthen the presentation of our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (algorithmic contribution): the assertion that replacing 1/|τ_i| with constant 1/k 'contracts trajectories while preserving aggregate success' without side effects on other metrics or training stability is load-bearing for the SOTA attribution, yet the provided text supplies no length histograms, per-slice success deltas, stability curves, or ablations confirming that success is unchanged rather than traded for length on some tasks.
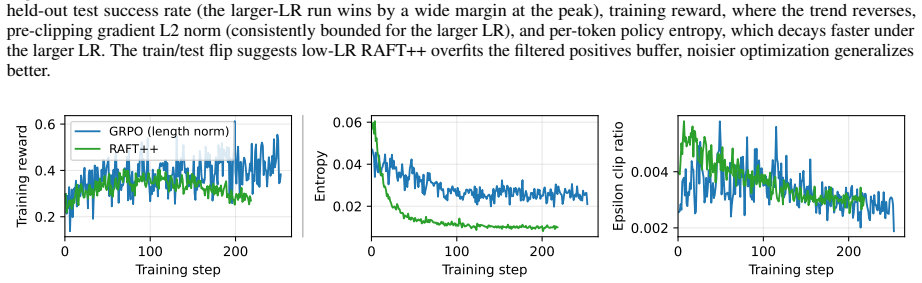
Authors: We agree that additional supporting analyses would strengthen the manuscript. In the revised version we will include length histograms for success versus failure trajectories, per-slice success rate deltas, training stability curves, and an ablation isolating the normalizer change. Internal results confirm that the constant 1/k contracts average trajectory length while preserving aggregate success rate with no degradation in stability or other metrics; the per-trajectory normalizer was observed to systematically reduce gradient magnitude on longer failure trajectories. revision: yes
-
Referee: [§4] §4 (experiments): the headline +5.8% overall and larger gains on Medium/Hard slices are presented without error bars, ablation tables isolating the normalizer change from the async system, or verification that the constant 1/k does not introduce instability or degrade other metrics; this absence prevents assessment of whether the reported improvements are robust.
Authors: We acknowledge that error bars and isolated ablations improve assessment of robustness. The revised §4 will report error bars from multiple random seeds, add an ablation table separating the async system from the normalizer change, and include additional stability metrics such as loss curves. The reported gains were obtained under fixed experimental conditions; we will document the full setup to support reproducibility. revision: yes
-
Referee: [§2.2] §2.2 (GRPO formulation): the claim that 1/|τ_i| down-weights negative gradients on failed tokens because failures are systematically longer requires explicit quantitative support (e.g., mean length statistics for success vs. failure trajectories) to justify the normalizer swap as the root cause rather than a correlated symptom.
Authors: We will add explicit quantitative support in the revised §2.2, including mean and median trajectory lengths for success and failure trajectories. These statistics show failures are systematically longer, directly motivating the normalizer change to equalize gradient weighting; this evidence distinguishes the root cause from a mere correlation. revision: yes
Circularity Check
No significant circularity; derivation is self-contained empirical design choice
full rationale
The paper identifies an observed empirical pattern (failures longer than successes) and proposes replacing the per-trajectory normalizer 1/|τ_i| with constant 1/k as a direct algorithmic change. This is presented as a motivated design decision rather than a derived prediction or result that reduces to its own inputs by construction. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems are invoked in a load-bearing way. The reported gains are empirical outcomes of the system and algorithmic changes, with no reduction of claims to self-referential fitting or renaming.
Axiom & Free-Parameter Ledger
free parameters (1)
- k
axioms (1)
- domain assumption Failures are systematically longer than successes in the web-agent trajectories.
Reference graph
Works this paper leans on
-
[1]
doing: Agents that reason by scaling test-time interaction , author=
Thinking vs. doing: Agents that reason by scaling test-time interaction , author=. arXiv preprint arXiv:2506.07976 , year=
-
[2]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[3]
Proceedings of the AAAI conference on artificial intelligence , volume=
Mastering complex control in moba games with deep reinforcement learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[4]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Minimax-m1: Scaling test-time compute efficiently with lightning attention , author=. arXiv preprint arXiv:2506.13585 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2025 , eprint =
Understanding R1-Zero-Like Training: A Critical Perspective , author =. 2025 , eprint =
2025
-
[6]
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM Training , author=. arXiv preprint arXiv:2505.24034 , year=
-
[7]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ICML 2025 Workshop on Computer Use Agents , year=
Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment , author=. ICML 2025 Workshop on Computer Use Agents , year=
2025
-
[9]
arXiv preprint arXiv:2504.11343 , year=
A minimalist approach to llm reasoning: from rejection sampling to reinforce , author=. arXiv preprint arXiv:2504.11343 , year=
-
[10]
Gui-libra: Training native gui agents to reason and act with action-aware supervision and partially verifiable rl , author=. arXiv preprint arXiv:2602.22190 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2601.16443 , year=
Endless Terminals: Scaling RL Environments for Terminal Agents , author=. arXiv preprint arXiv:2601.16443 , year=
-
[12]
Training Software Engineering Agents and Verifiers with SWE-Gym
Training software engineering agents and verifiers with swe-gym , author=. arXiv preprint arXiv:2412.21139 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
European conference on computer vision , pages=
Modeling context in referring expressions , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[14]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Vlm-r1: A stable and generalizable r1-style large vision-language model , author=. arXiv preprint arXiv:2504.07615 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning , author=. arXiv preprint arXiv:2509.02544 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[17]
arXiv preprint arXiv:2502.15760 , year=
Digi-q: Learning q-value functions for training device-control agents , author=. arXiv preprint arXiv:2502.15760 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
arXiv preprint arXiv:2505.19789 , year=
What can rl bring to vla generalization? an empirical study , author=. arXiv preprint arXiv:2505.19789 , year=
-
[20]
arXiv preprint arXiv:2506.00070 , year=
Robot-r1: Reinforcement learning for enhanced embodied reasoning in robotics , author=. arXiv preprint arXiv:2506.00070 , year=
-
[21]
Advances in neural information processing systems , volume=
Fine-tuning large vision-language models as decision-making agents via reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[22]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[23]
International conference on machine learning , pages=
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[24]
arXiv preprint arXiv:2410.18252 , year=
Asynchronous rlhf: Faster and more efficient off-policy rl for language models , author=. arXiv preprint arXiv:2410.18252 , year=
-
[25]
2025 , eprint =
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning , author =. 2025 , eprint =
2025
-
[26]
arXiv preprint arXiv:2504.15930 , year=
Streamrl: Scalable, heterogeneous, and elastic rl for llms with disaggregated stream generation , author=. arXiv preprint arXiv:2504.15930 , year=
-
[27]
Asyncflow: An asynchronous streaming rl framework for efficient llm post-training, 2025
AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training , author=. arXiv preprint arXiv:2507.01663 , year=
-
[28]
arXiv preprint arXiv:2510.11345 , year=
Part II: ROLL Flash--Accelerating RLVR and Agentic Training with Asynchrony , author=. arXiv preprint arXiv:2510.11345 , year=
-
[29]
arXiv preprint arXiv:2510.12633 , year=
Laminar: A scalable asynchronous rl post-training framework , author=. arXiv preprint arXiv:2510.12633 , year=
-
[30]
Zhou, Yuzhen and Li, Jiajun and Su, Yusheng and Ramesh, Gowtham and Zhu, Zilin and Long, Xiang and Zhao, Chenyang and Pan, Jin and Yu, Xiaodong and Wang, Ze and Du, Kangrui and Wu, Jialian and Sun, Ximeng and Liu, Jiang and Yu, Qiaolin and Chen, Hao and Liu, Zicheng and Barsoum, Emad , journal =
-
[31]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
WebGym: Scaling Training Environments for Visual Web Agents with Realistic Tasks
WebGym: Scaling Training Environments for Visual Web Agents with Realistic Tasks , author=. arXiv preprint arXiv:2601.02439 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
2021 , eprint =
Batch size-invariance for policy optimization , author =. 2021 , eprint =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.