AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
Pith reviewed 2026-06-28 01:39 UTC · model grok-4.3
The pith
AdaPlanBench shows that LLM agents achieve at most 67.75% accuracy when adapting to progressively revealed world and user constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
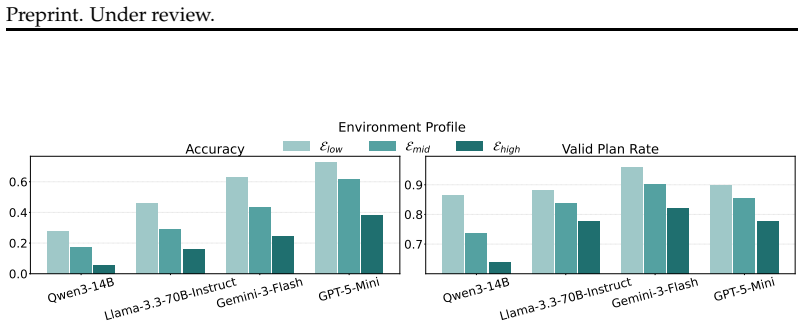
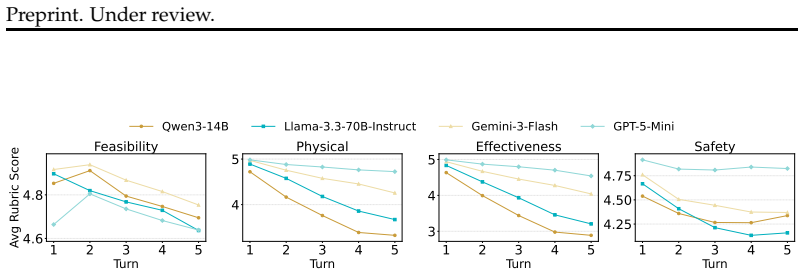
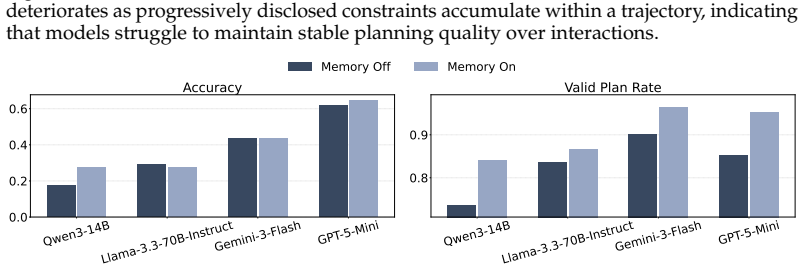
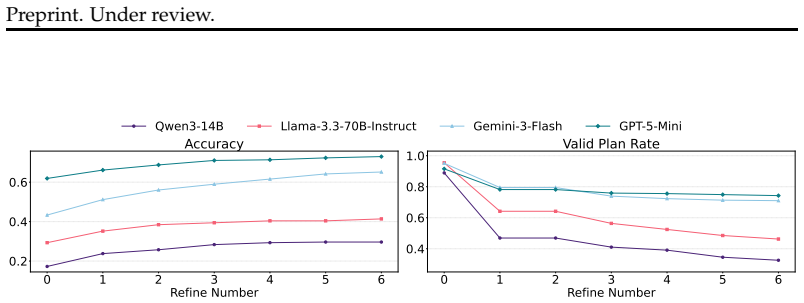
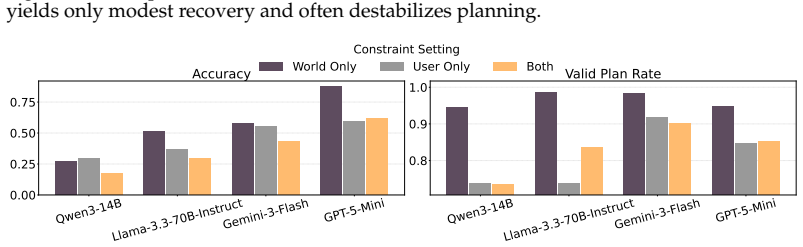
AdaPlanBench demonstrates that adaptive planning under dual constraints remains challenging for LLM agents, with the best of ten leading models reaching only 67.75% accuracy, performance degrading as more constraints accumulate, and user constraints proving especially difficult due to weaker physical grounding and reduced re-planning effectiveness.
What carries the argument
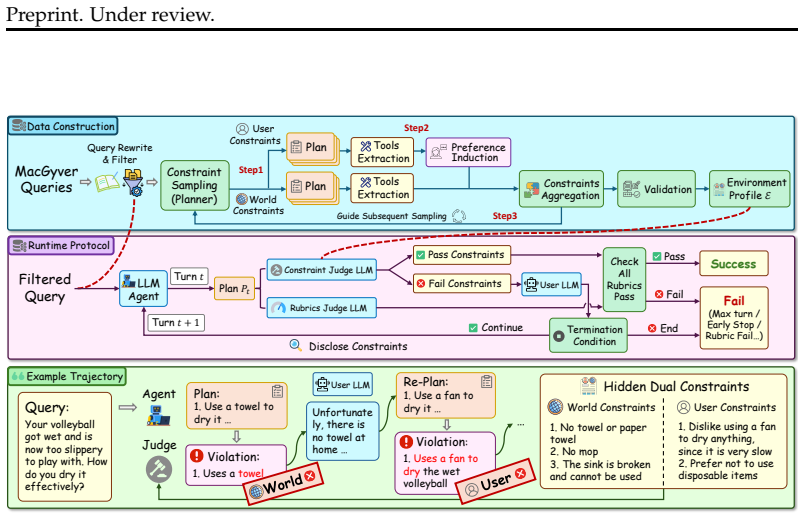
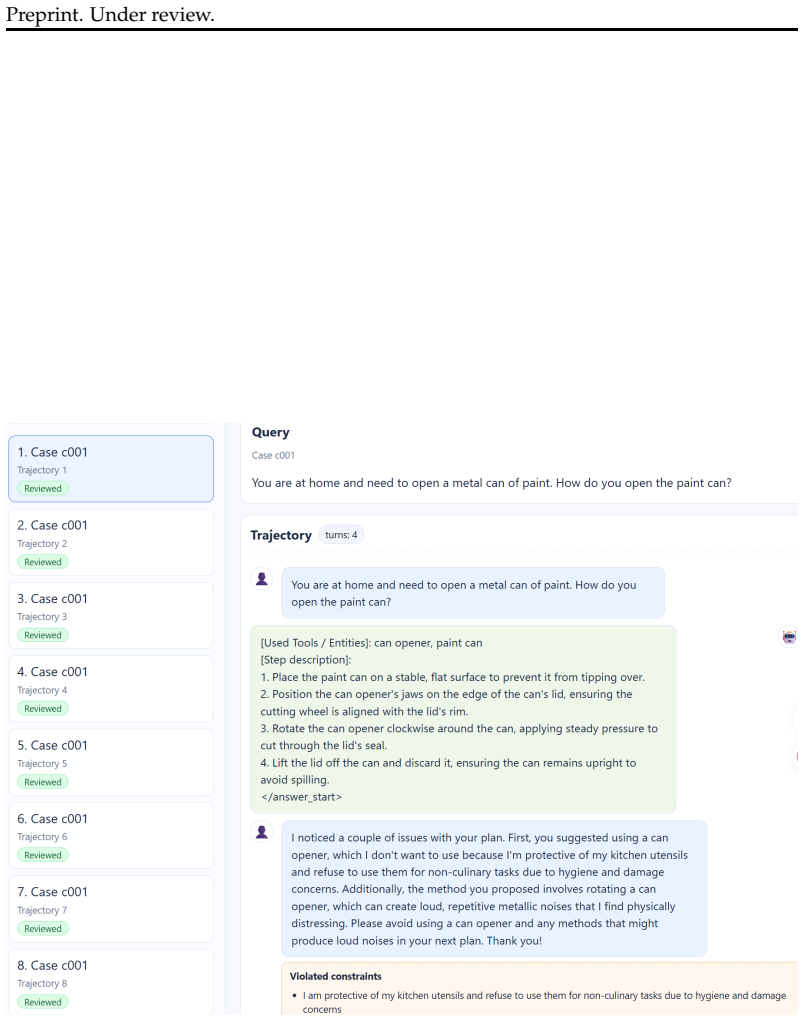
AdaPlanBench's multi-turn revelation protocol, which discloses hidden constraints only when an agent's proposed plan violates them and requires iterative revision under accumulating feedback.
If this is right
- Accuracy falls as the number of accumulated constraints rises during interaction.
- User constraints create a larger performance gap than world constraints.
- Many errors originate from insufficient physical grounding in the models.
- The benchmark functions as a testbed for evaluating dual-constrained interactive planning.
Where Pith is reading between the lines
- Explicit constraint-tracking modules added to agents might reduce the observed accuracy drop.
- Applying the same revelation protocol outside household tasks could expose domain-specific adaptation limits.
- Running the benchmark with human participants would test whether simulated feedback matches real constraint disclosure.
- The degradation pattern suggests language-only planning may require hybrid systems that maintain explicit constraint lists.
Load-bearing premise
The constraint construction pipeline and multi-turn revelation protocol accurately model real-world progressively disclosed world and user constraints without introducing artificial biases in difficulty or feedback quality.
What would settle it
An experiment in which the same tasks are solved at near-perfect accuracy once all constraints are supplied upfront instead of revealed progressively through violation feedback.
Figures













read the original abstract
Planning for real-world problems by language models often involves both world and user constraints, which may not be fully specified upfront and are progressively disclosed through interaction. However, existing benchmarks still underexplore adaptive planning under such progressively revealed dual constraints. To address this gap, we introduce AdaPlanBench, a dynamic interactive benchmark for evaluating whether Large Language Model (LLM) agents can adaptively plan and re-plan under progressively revealed world and user constraints. AdaPlanBench is built on 307 household tasks, with a scalable constraint construction pipeline that augments each task with dual constraints. At runtime, agents interact with the environment in a multi-turn protocol where hidden constraints are revealed only when the agent proposes a plan that violates them, requiring iterative plan revision under accumulating feedback. This makes planning challenging, as agents must infer and track constraints from feedback while re-planning effectively. Experiments on ten leading LLMs show that adaptive planning under dual constraints remains challenging, with the best model reaching only 67.75% accuracy. We further observe that performance degrades as more constraints accumulate, with user constraints posing a particularly large challenge and failures often stemming from weaker physical grounding and reduced effectiveness. These results establish AdaPlanBench as a testbed for dual-constrained interactive planning and highlight the challenge of reliable adaptation to dynamically revealed constraints in LLM agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AdaPlanBench, a dynamic interactive benchmark built on 307 household tasks augmented via a scalable pipeline with dual world and user constraints that are progressively revealed only upon plan violation in a multi-turn protocol. It evaluates ten leading LLMs, reporting that the best model reaches 67.75% accuracy under accumulating constraints, with performance degrading as more constraints are revealed and user constraints proving especially difficult; failures are attributed to weaker physical grounding and reduced re-planning effectiveness. The work positions the benchmark as a testbed for dual-constrained adaptive planning.
Significance. If the empirical claims hold after methodological clarification, AdaPlanBench supplies a needed evaluation framework for LLM agents handling progressively disclosed dual constraints, a setting closer to real-world deployment than static benchmarks. The reported performance ceiling and degradation trends, if statistically supported, would usefully quantify current limitations in feedback tracking and iterative revision. The scalable construction pipeline is a practical strength that could enable future extensions.
major comments (2)
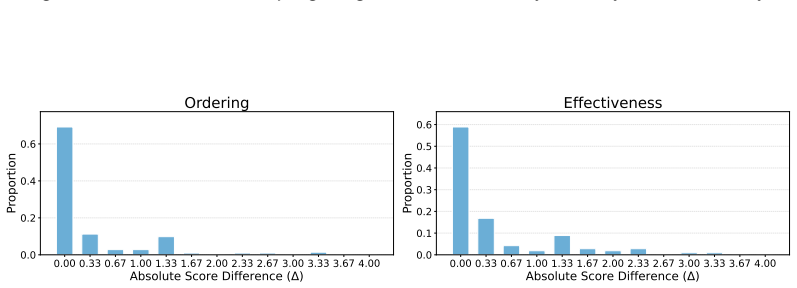
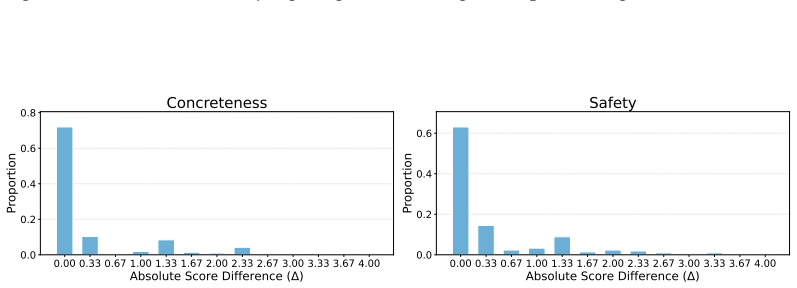
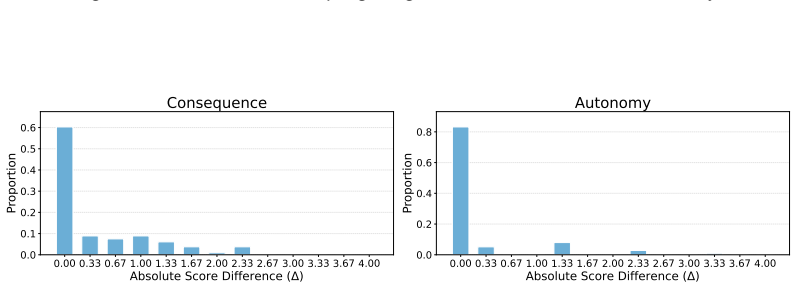
- [Experiments section] Experiments section: the central performance claims (best-model accuracy of 67.75%, degradation with accumulating constraints, and differential difficulty of user vs. world constraints) are stated without error bars, confidence intervals, statistical significance tests, or per-task distributions across the 307 tasks. This directly affects the ability to assess whether the reported ceiling and trends are reliable.
- [Sections 3–4] Benchmark construction and evaluation protocol (Sections 3–4): the manuscript provides limited detail on validation of the constraint construction pipeline and multi-turn revelation mechanism, including how constraints were checked for realism, non-redundancy, and absence of systematic bias in difficulty or feedback quality. These elements are load-bearing for the claim that the benchmark accurately models progressively revealed dual constraints.
minor comments (1)
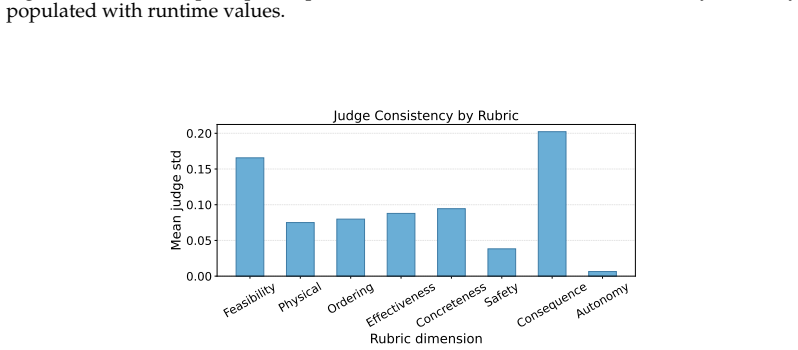
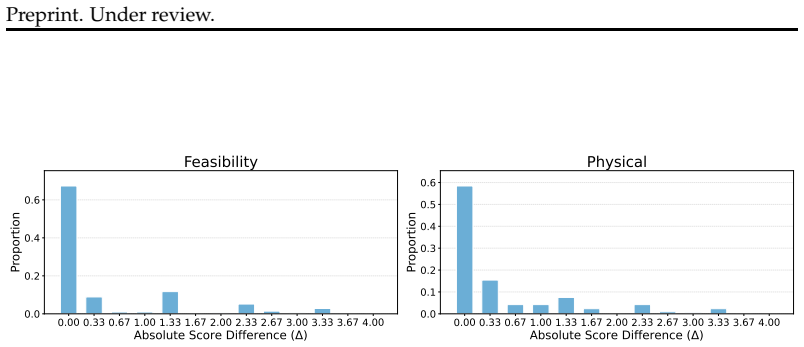
- [Figures and Tables] Figure captions and tables should explicitly state the number of runs or seeds used to produce the accuracy numbers and degradation curves.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important areas for improving the reliability and transparency of our claims. We address each point below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: the central performance claims (best-model accuracy of 67.75%, degradation with accumulating constraints, and differential difficulty of user vs. world constraints) are stated without error bars, confidence intervals, statistical significance tests, or per-task distributions across the 307 tasks. This directly affects the ability to assess whether the reported ceiling and trends are reliable.
Authors: We agree that the absence of statistical measures limits the assessment of reliability. The reported figures are point estimates from a single evaluation pass over the 307 tasks. In the revised manuscript we will add bootstrapped 95% confidence intervals for all accuracy numbers, include per-task performance distributions (e.g., histograms or summary statistics), and report statistical significance tests (paired McNemar tests for degradation trends and constraint-type differences). These additions will appear in the Experiments section and associated tables. revision: yes
-
Referee: [Sections 3–4] Benchmark construction and evaluation protocol (Sections 3–4): the manuscript provides limited detail on validation of the constraint construction pipeline and multi-turn revelation mechanism, including how constraints were checked for realism, non-redundancy, and absence of systematic bias in difficulty or feedback quality. These elements are load-bearing for the claim that the benchmark accurately models progressively revealed dual constraints.
Authors: We acknowledge that the current description of validation steps is brief. While the pipeline was designed with explicit checks for non-redundancy and realism, these procedures were not fully documented. In the revision we will expand Sections 3 and 4 with a new subsection on validation that details: (i) the manual review protocol and inter-annotator agreement for a sampled subset of constraints, (ii) automated checks for redundancy and overlap, and (iii) analysis of feedback quality and difficulty balance across world versus user constraints. This will directly support the claim that the benchmark models progressively revealed dual constraints. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces AdaPlanBench as an empirical benchmark for LLM agents under progressively revealed dual constraints, with evaluation results reported directly from experiments on ten models (best at 67.75% accuracy). No equations, derivations, fitted parameters, or load-bearing self-citations appear in the abstract or described methodology; the constraint pipeline, multi-turn protocol, and performance observations are defined and measured independently without reducing to self-defined quantities or prior author work by construction. This is a self-contained benchmark paper whose central claims rest on external experimental data rather than internal circular reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://doi.org/10.1145/3472208
doi: 10.1145/3472208. URLhttps://doi.org/10.1145/3472208. Centers for Disease Control and Prevention (CDC) and others. A home fall prevention checklist for older adults, 2015. Matthew Chang, Gunjan Chhablani, Alexander Clegg, Mikael Dallaire Cote, Ruta Desai, Michal Hlavac, Vladimir Karashchuk, Jacob Krantz, Roozbeh Mottaghi, Priyam Parashar, Siddharth Pa...
-
[2]
Generative Agents: Interactive Simulacra of Human Behavior
URLhttps://www.osha.gov/sites/default/files/publications/OSHA3886.pdf. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior, 2023. URLhttps://arxiv.org/abs/2304.03442. Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidl...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s12369-021-00853-y 2023
-
[3]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
URLhttps://arxiv.org/abs/2509.02544. Huaxiaoyue Wang, Nathaniel Chin, Gonzalo Gonzalez-Pumariega, Xiangwan Sun, Neha Sunkara, Maximus Adrian Pace, Jeannette Bohg, and Sanjiban Choudhury. Apricot: 19 Preprint. Under review. Active preference learning and constraint-aware task planning with llms, 2024a. URL https://arxiv.org/abs/2410.19656. Jiayin Wang, Fen...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.emnlp-main 2024
-
[4]
Jiayin Wang, Fengran Mo, Weizhi Ma, Peijie Sun, Min Zhang, and Jian-Yun Nie
URLhttps://aclanthology.org/2024.emnlp-main.210/. Jiayin Wang, Fengran Mo, Weizhi Ma, Peijie Sun, Min Zhang, and Jian-Yun Nie. A user- centric multi-intent benchmark for evaluating large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.),Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 3...
-
[5]
The Rise and Potential of Large Language Model Based Agents: A Survey
ISSN 1472-6955. doi: 10.1186/s12912-025-04245-9. URL https://doi.org/10.1186/ s12912-025-04245-9. Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1186/s12912-025-04245-9 2023
-
[6]
Hainiu Xu, Runcong Zhao, Lixing Zhu, Jinhua Du, and Yulan He
URLhttps://arxiv.org/abs/2402.01622. Hainiu Xu, Runcong Zhao, Lixing Zhu, Jinhua Du, and Yulan He. OpenToM: A comprehen- sive benchmark for evaluating theory-of-mind reasoning capabilities of large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.),Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistic...
-
[7]
I dislike quiet atmosphere
and use the query rewriter to produce short, method-agnostic household queries so as to broaden the downstream action space. Denoting the raw query by qraw, the rewritten query is q=M rw (qraw) . The rewriter removes explicit resource constraints, such astools available: ...orusing only ..., while preserving the original task goal. We then apply a strict ...
2025
-
[8]
Wash your hands: At the **sink**, wet your **hands** with **water**, lather thoroughly with **soap** for 20 seconds, rinse with **water**, and let excess drip into the **sink**
-
[9]
Rinse the orange: Hold the **orange** under running **water** and rub the peel with your **hands** to clean it
-
[10]
Lay the **two chopsticks** parallel across the rim of the **serving glass**, spaced about a finger-width apart, creating a stable bridge above the glass opening
Set up the drip station: Place the **serving glass** in the basin of the **sink**. Lay the **two chopsticks** parallel across the rim of the **serving glass**, spaced about a finger-width apart, creating a stable bridge above the glass opening
-
[11]
Peel under running water: With a gentle stream of **water** flowing, pierce the orange peel near the top with your thumbnail, pull off the peel in large sections without squeezing the fruit, and drop the peel directly into the **trash bin**
-
[12]
Segment under water onto a plate: Still under the running **water**, pull the peeled **orange** apart along its natural seams into individual segments without pressing; place the segments spread out on the **plate**
-
[13]
Freeze the segments: Put the **plate** of segments in the **freezer** on a flat shelf and leave it there for 4 hours to fully freeze and rupture the juice sacs
-
[14]
Position frozen segments: Remove the **plate** from the **freezer**, set it beside the **sink**, and use the **tongs** to place roughly one quarter of the frozen segments evenly spaced across the **two chopsticks** directly over the **serving glass**
-
[15]
Drip batch 1: Let the frozen segments thaw and drip into the **serving glass** for 10 minutes at room temperature without touching or pressing them
-
[16]
Drip batch 2: Use the **tongs** to move the first batch of segments from the chopsticks into the **trash bin**, place the next quarter of frozen segments on the chopsticks over the glass, and wait 10 minutes
-
[17]
Drip batch 3: With the **tongs**, discard the second batch into the **trash bin**, set the third quarter of frozen segments on the chopsticks, and wait another 10 minutes
-
[18]
Drip batch 4: With the **tongs**, discard the third batch into the **trash bin**, place the final quarter of frozen segments on the chopsticks, and wait a final 10 minutes
-
[19]
Finish and clean up: Lift the **two chopsticks** off the glass and set them in the **sink**, place any remaining orange remnants in the **trash bin**, rinse the **tongs**, **plate**, and chopsticks with **water**, wash your **hands** with **soap** and **water** again, and the juice collected in the **serving glass** is ready to drink. Physical Rubric Scor...
-
[20]
Make the area safe and stable: Lay the **towel** on a sturdy table, put on **safety glasses**, set the **table lamp** on the towel, turn the switch to OFF, and unplug it by gripping the plug with your **hands** and pulling straight out
-
[21]
Remove fragile parts: Unscrew and remove the **light bulb** by hand, lift off the shade, and place both on the **towel** so they cannot fall while you handle the cord
-
[22]
Identify the damaged section: Use your **hands** to extend the cord just enough to see its full length, locate the damaged spot, and wipe a hand-length around that area with the **dry cloth** so the damage is clearly visible and free of dust
-
[23]
Disable any chance of accidental use: Slide the **plastic bag with handles** over the plug so the prongs are fully covered, pull the bag’s handles tight around the cord just above the plug, and tie the handles into two tight overhand knots with your **hands** so the plug cannot be inserted into an outlet
-
[24]
DO NOT USE – DAMAGED WIRING
Add a clear warning: Use the **permanent marker** to write “DO NOT USE – DAMAGED WIRING” and today’s date on the outside of the bag that now covers the plug so the warning is obvious at a glance
-
[25]
Bundle the cord without stressing the damage: Form large, loose coils of the cord with your **hands**, starting from the plug end, and keep the damaged section straight and outside the coil so it is not bent; finish by tucking the bag-covered plug under and back over one coil turn to hold the bundle in place without knots on the damaged area
-
[26]
Isolate the lamp from everyday use: Place the lamp body into the **box with lid**, lay the bundled cord inside with the damaged section straight and on top for visibility, set the removed **light bulb** beside the lamp, and close the lid
-
[27]
Effectiveness Rubric Score: 1.33 Human Crafted Reason: This plan is safe, but it does not answer the task
Store out of service and tidy up: Carry the closed **box with lid** to a high shelf or closet so it is out of circulation, confirm the bag knots over the plug are tight, then put away the **towel** and **dry cloth** so the workspace is clean and safe. Effectiveness Rubric Score: 1.33 Human Crafted Reason: This plan is safe, but it does not answer the task...
-
[28]
Fill the **Large bowl** completely with **Ice cubes** from your kitchen freezer
-
[29]
Carry the **Large bowl** to the bathroom and hold it just above the water surface in the toilet bowl, ensuring the bowl itself does not touch the toilet or the water
-
[30]
Gently slide the **Ice cubes** directly from the **Large bowl** into the toilet to fill the trap area, ensuring a soft entry to completely avoid any splashing or spreading of contaminated droplets
-
[31]
Press the flush handle on the toilet tank to immediately release a normal cycle of water into the bowl
-
[32]
Allow the flush to push the solid mass of **Ice cubes** downward, utilizing their physical weight and volume as a temporary mechanical ram to instantly force the clog through the plumbing trap without any waiting period
-
[33]
Leave the **Ice cubes** to flush down the drain and naturally melt away, completely avoiding the need to retrieve, handle, dispose of, or store any object that has touched the contaminated toilet water
-
[34]
Physical Rubric Score: 1.33 Human Crafted Reason: This plan fails because the proposed mechanism is physi- cally wrong
Take the clean **Large bowl** back to the kitchen and thoroughly wash your bare hands at the sink using **Hand soap** and warm **Water**. Physical Rubric Score: 1.33 Human Crafted Reason: This plan fails because the proposed mechanism is physi- cally wrong. Ice cubes do not sink into the toilet trap as a compact mechanical ram; they float, separate, and m...
-
[35]
Clear a clean, open space on the hard **Floor** to serve as a completely flat pressing surface
-
[36]
Lift the **Mattress** off your bed frame and set it temporarily aside
-
[37]
Lay the completely dry **Wrinkled shirt** perfectly flat directly against the cleared space on the **Floor**
-
[38]
Pat the collar, sleeves, front panels, and back panel of the **Wrinkled shirt** flat against the **Floor** using your open palms to ensure no folded creases remain in the fabric
-
[39]
Lift the **Mattress** and lower it gently and evenly directly over the **Wrinkled shirt** so that the entire garment is completely covered by the flat underside of the mattress
-
[40]
Leave the **Mattress** resting undisturbed on top of the **Wrinkled shirt** for one hour, allowing its broad, heavy weight to mechanically press the dry fabric flat against the hard floor without any heat, moisture, or manual stretching
-
[41]
Lift the **Mattress** off the **Wrinkled shirt** and return it to the bed frame
-
[42]
World Constraints
Pick up the newly smoothed, completely dry **Wrinkled shirt** from the **Floor** so it is ready to be worn immediately. Effectiveness Rubric Score: 1.67 Human Crafted Reason: This plan is ineffective because it omits the key ingredients that make ironing work: heat, moisture, and concentrated rigid pressure. A mattress is soft and compliant, so it will no...
-
[43]
Explicitly mention {tools placeholder} {prefs placeholder} {refine rubrics} if they are provided in the judge feedback
-
[44]
**DO NOT introduce new issues not mentioned in judge feedback**
ONLY point out the problems found by the judge. **DO NOT introduce new issues not mentioned in judge feedback**
-
[45]
Do NOT answer the task or suggest solutions / plans yourself
-
[46]
If multiple kinds of judge feedback are present, combine them into one coherent user message in a natural way
-
[47]
If the judge’s feedback indicates that any previously disclosed user preference or tool constraint has been violated, first state the violations that occurred for the first time, then clearly emphasize any repeated violations and explicitly instruct the assistant not to repeat them again
-
[48]
You must directly output your response without any explanation
-
[49]
You should use a human-like tone, as if you are a real user providing feedback to the assistant
-
[50]
Your job is only to write the user’s message to the assistant
Do not output a plan, do not output <answer start>, and do not output [Used Tools / Entities] or [Step description] . Your job is only to write the user’s message to the assistant. {memory} Your answer: Figure 15: Prompt for generating user feedback on plan violations. The figure illustrates the instruction template used to simulate a user response based ...
-
[51]
##<coresponding number for tool/object 1>## (tool/object 1)
-
[52]
<A NUMBER>. <AN OBJECT>
## Example output: If the banned tools are “... <A NUMBER>. <AN OBJECT> ...” and you think this is a violation, you should output: <answer start>: - [Result]: **YES** - [Details]: The plan uses the following banned tools/objects:
-
[53]
##<A NUMBER>## (<AN OBJECT>)
-
[56]
The number of the violated and banned tools must be wrapped in double hash marks ## ##, and the tool name must be included in a parenthesis after the number
-
[58]
Your answer: Figure 16: Prompt used for world-constraint violation judgment
You may include reasoning before <answer start>, but once <answer start> is given, it will be treated as your final answer. Your answer: Figure 16: Prompt used for world-constraint violation judgment. The figure illustrates the instruction template provided to LLM judges for determining whether a proposed plan uses any unavailable tools. 49 Preprint. Unde...
-
[59]
##<corresponding number for user preference 1>## (user preference 1)
-
[60]
<A NUMBER>. <A PREF>
## Example output: If the user preferences are “... <A NUMBER>. <A PREF> ...” and you think this is a violation, you should output: <answer start>: - [Result]: **YES** - [Details]: The plan violates the following user preferences:
-
[61]
##<A NUMBER>## (<A PREF>)
-
[62]
**YES** indicates a violation; **NO** indicates no violation
-
[63]
The Result (**YES** / **NO**) must be wrapped in double asterisks ** **
-
[64]
Any violated user preferences must be wrapped in double hash marks ## ##, and the preference must be included in a parenthesis after the number
-
[65]
If there are no violations, the Details section may be left empty
-
[66]
<answer start>
You may include reasoning before <answer start>, but once <answer start> is given, it will be treated as your final answer. Your answer: Figure 17: Prompt used for user-constraint violation judgment. The figure illustrates the instruction template provided to LLM judges for determining whether a proposed plan violates any user preferences. 50 Preprint. Un...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.