Continual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments
Pith reviewed 2026-06-28 01:43 UTC · model grok-4.3
The pith
Dedicated memory systems do not improve continual learning in LLM agents; naive in-context learning outperforms them on a new multi-domain benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
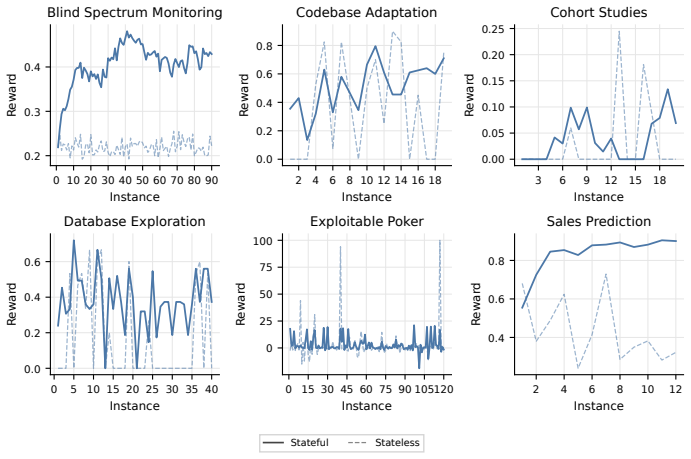
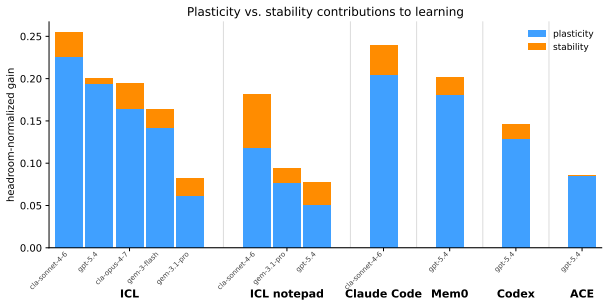
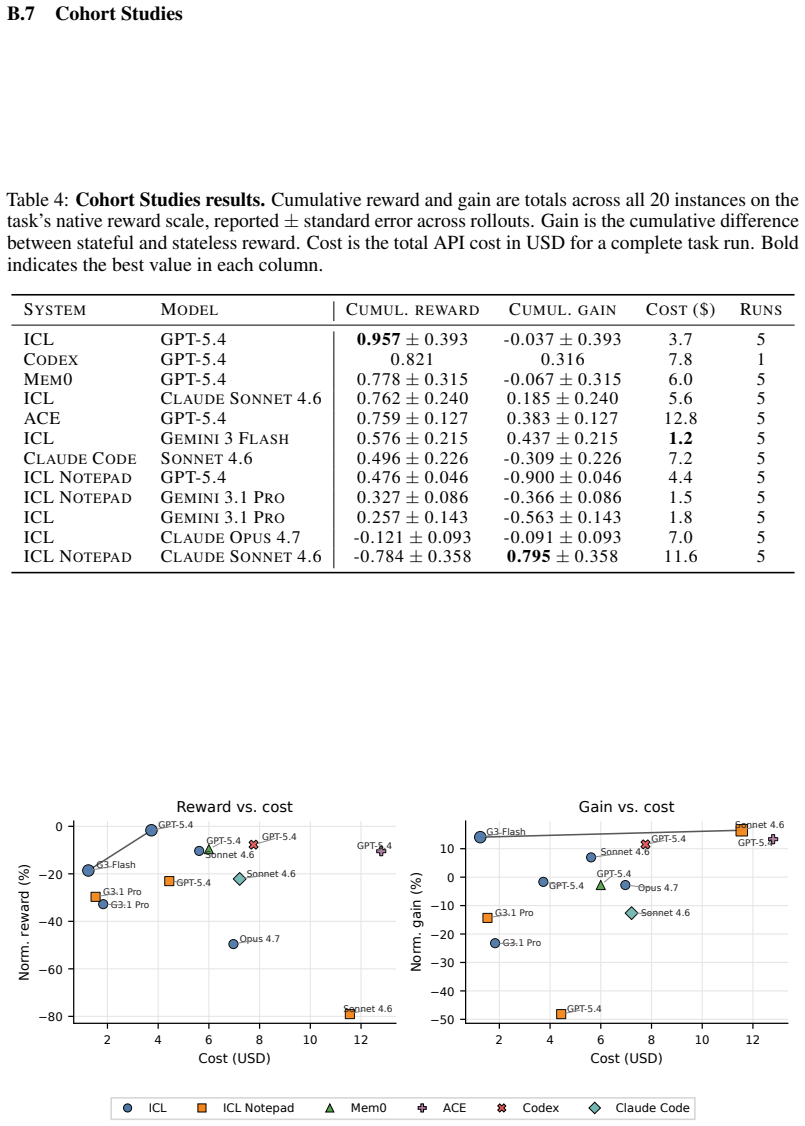
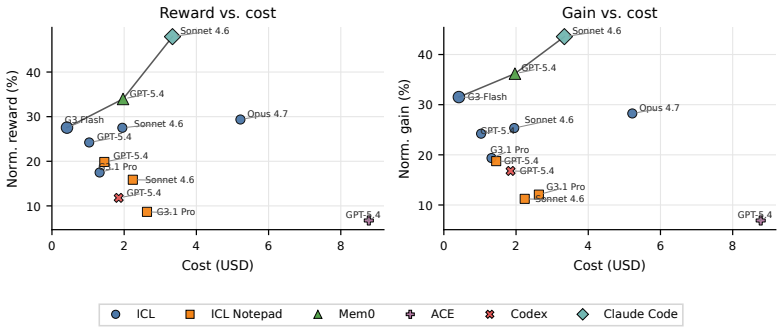
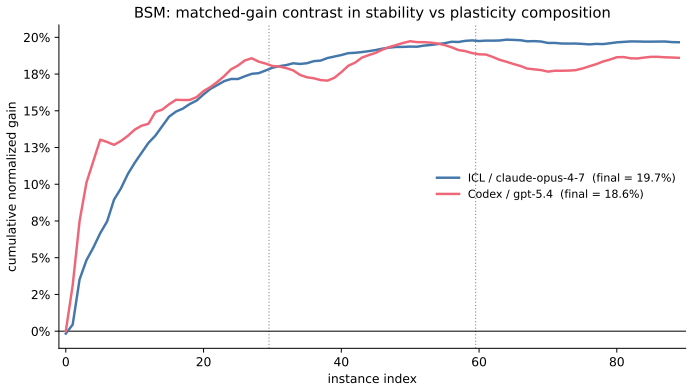
CL-Bench shows that frontier LLM-based agents do not reliably improve through sequential experience even when tasks contain shared latent structures such as codebase layouts or opponent strategies; agents overfit to immediate observations or fail to reuse prior knowledge, and dedicated memory systems do not remedy this limitation—instead, naive in-context learning yields higher gains.
What carries the argument
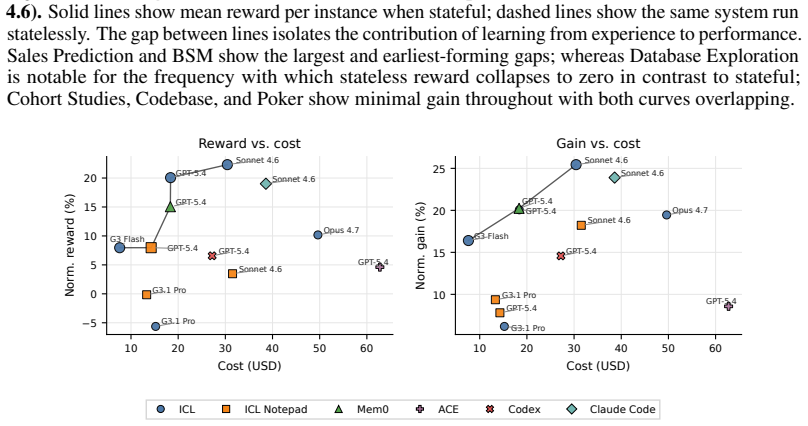
CL-Bench benchmark with its gain metric, which measures performance improvement across task instances after isolating prior model capability, applied to domains with shared learnable latent structures.
If this is right
- Current agent architectures leave measurable headroom for better continual learning.
- Adding dedicated memory modules does not address overfitting or knowledge-reuse failures.
- Naive in-context learning remains the strongest performer among the tested setups.
- Future systems need mechanisms to discover and apply latent structures across instances rather than relying on raw memory storage.
Where Pith is reading between the lines
- The results suggest that improvements may require changes in how experience is encoded during inference rather than just expanding storage capacity.
- Benchmarks of this type could be extended to measure whether models can be prompted or trained to explicitly search for cross-instance patterns.
- In practical deployments, simpler prompting strategies might currently deliver more reliable adaptation than complex memory architectures.
- The gap between naive and memory-based approaches points to a need for evaluation methods that test transfer even when surface features differ between instances.
Load-bearing premise
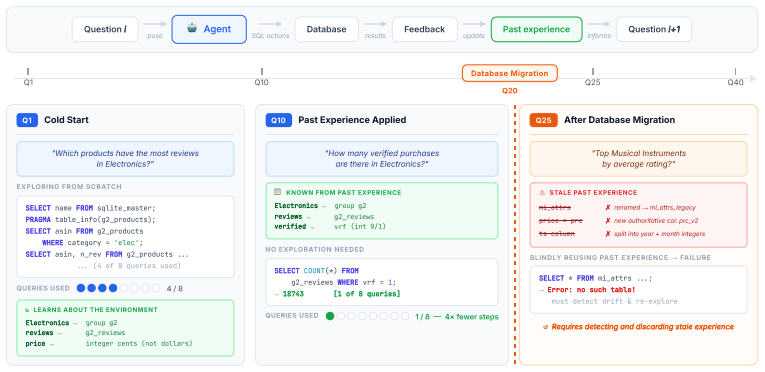
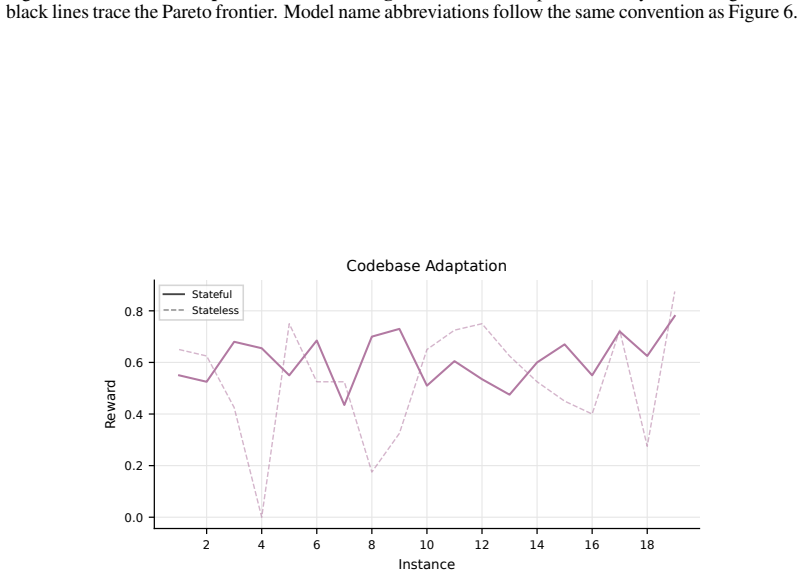
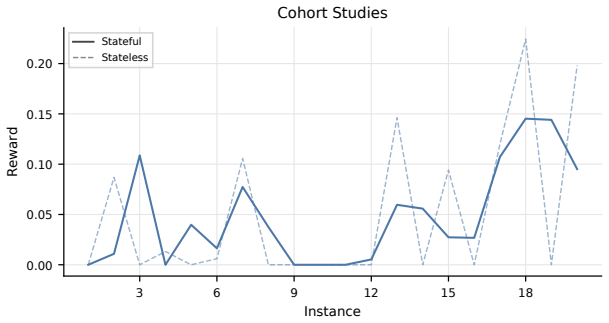
The benchmark tasks are constructed so they share a discoverable latent structure that a stateful system can learn online but a stateless one cannot.
What would settle it
If memory-augmented agents consistently produce higher gain scores than naive in-context learning across the six domains while showing clear reuse of earlier task knowledge rather than overfitting.
Figures



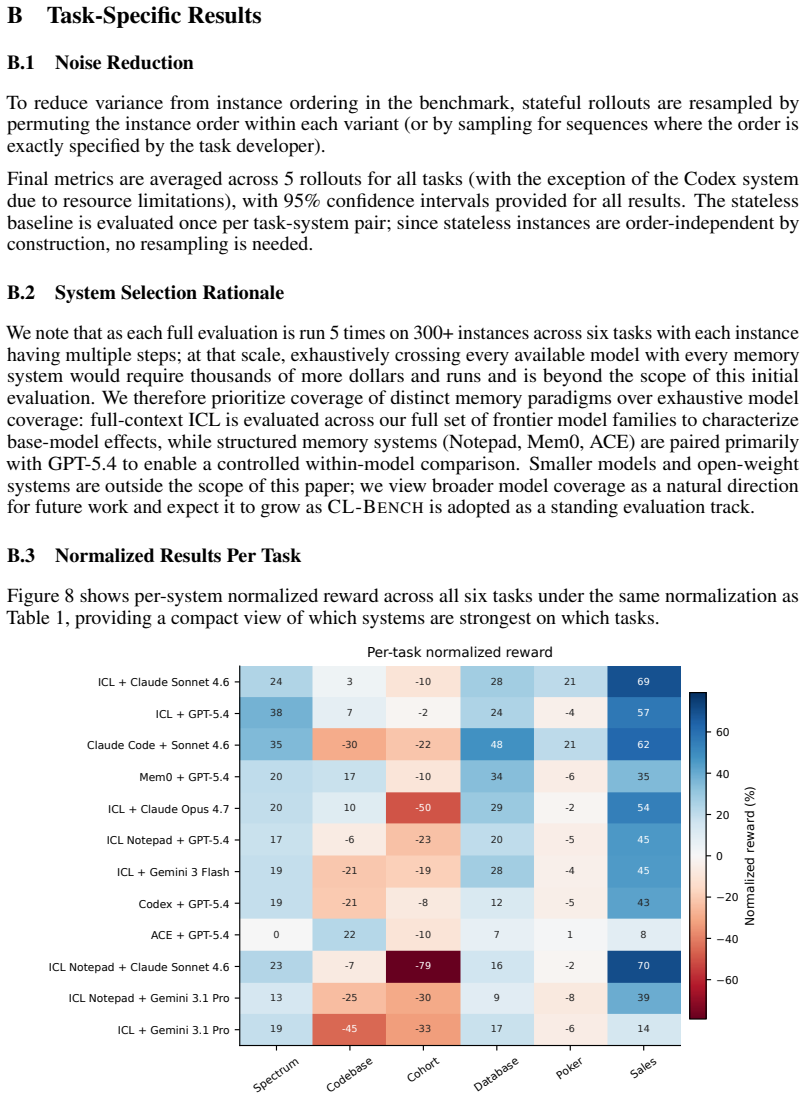
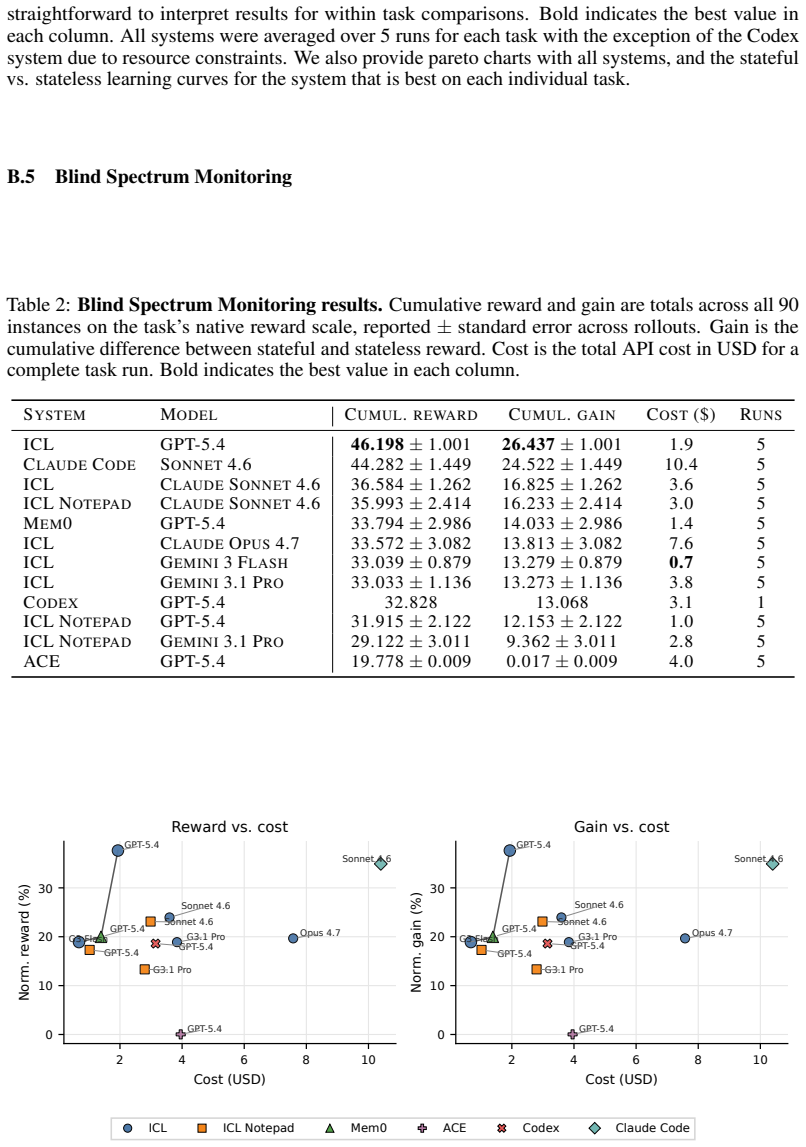
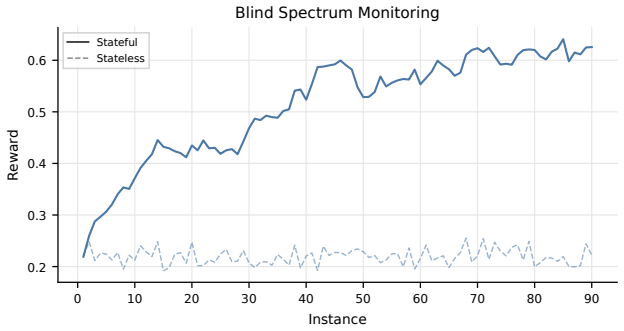
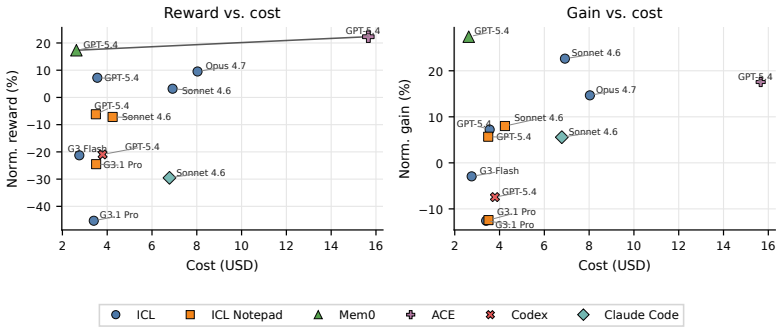
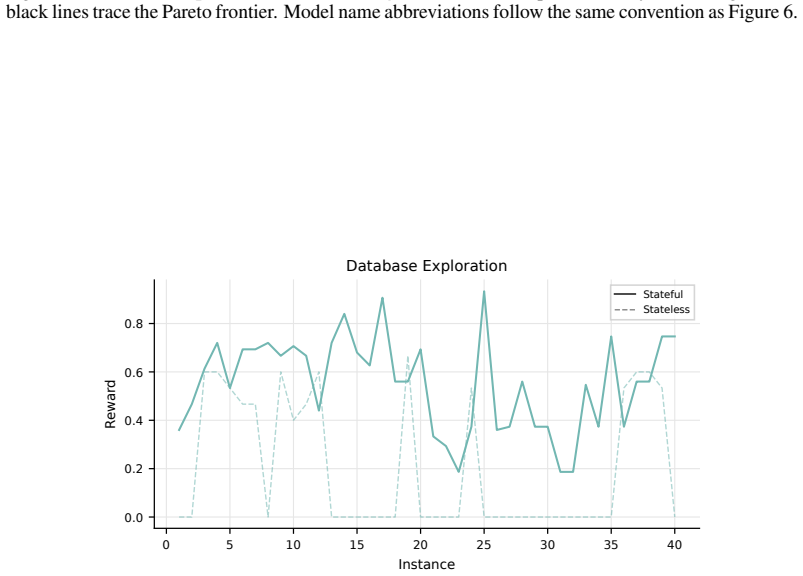
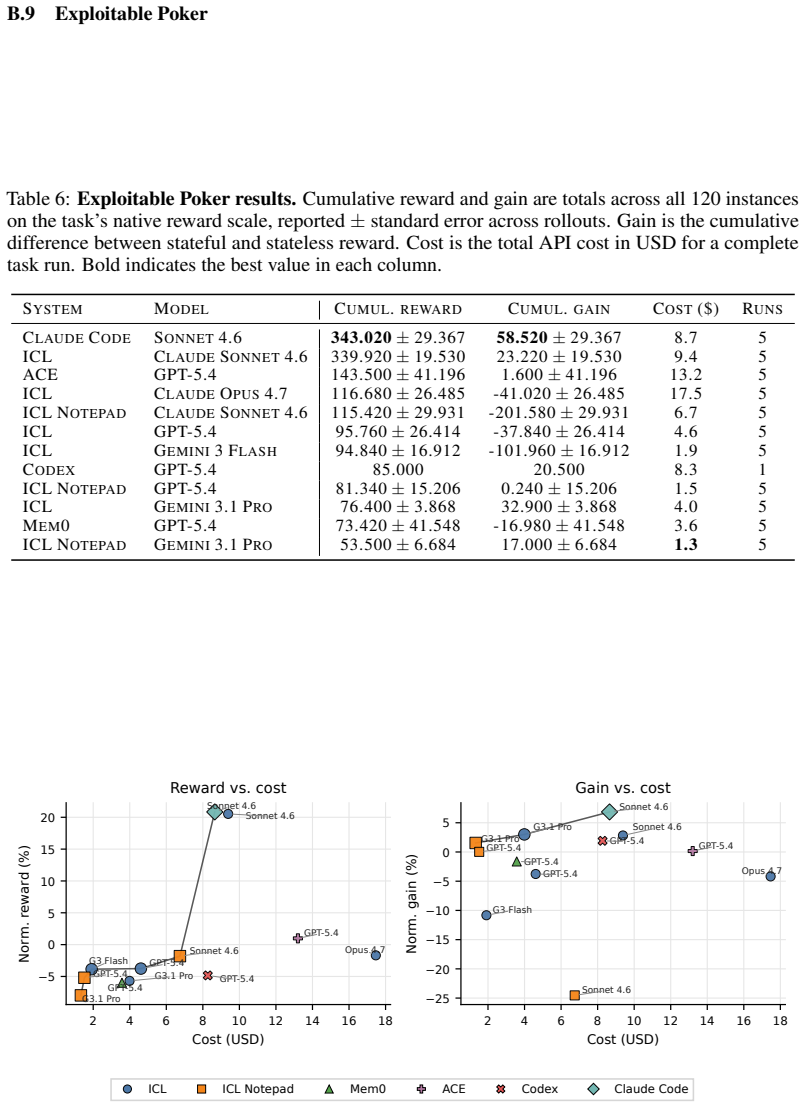

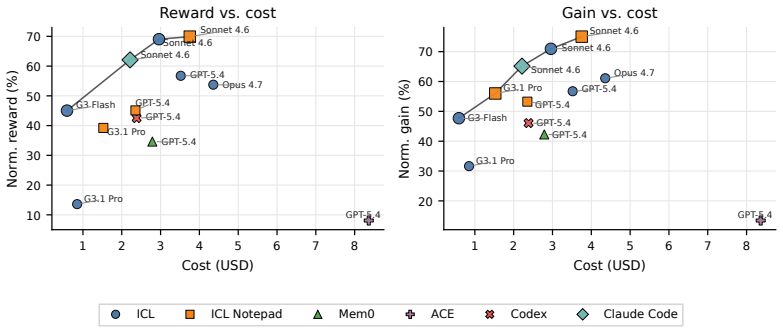
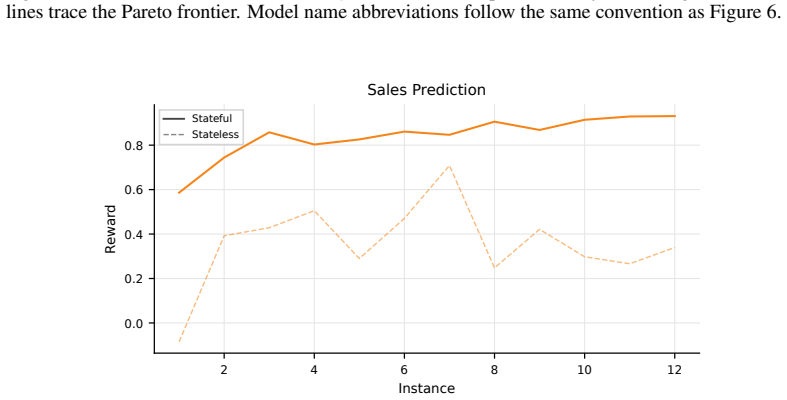
read the original abstract
Continual learning, the ability of AI systems to improve through sequential experience, has attracted substantial interest, but no high-quality benchmark exists to evaluate it. We introduce Continual Learning Bench (CL-Bench), the first difficult, expert-validated benchmark designed to measure whether LLM-based systems genuinely improve with experience. CL-Bench spans six diverse domains (software engineering, signal processing, disease outbreak forecasting, database querying, strategic game-playing, and demand forecasting), each validated by domain experts and designed so that tasks share a learnable latent structure (codebase layout, disease outbreak dynamics, opponent strategies) that a stateful system can discover online but a stateless one cannot. We evaluate frontier models across several agent architectures, from naive in-context learning (ICL) to dedicated memory systems, introducing a gain metric to isolate learning from prior capabilities. We find that these systems leave headroom for improved continual learning: agents frequently overfit to immediate observations or fail to reuse knowledge across instances, and dedicated memory systems do not fix this -- in fact, naive ICL outperforms systems dedicated to memory management. CL-Bench is the first benchmark to evaluate continual learning across diverse real-world domains with expert-validated tasks and isolate online learning from underlying model capability, showing a need for better continual learning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Continual Learning Bench (CL-Bench), the first expert-validated benchmark spanning six real-world domains (software engineering, signal processing, disease outbreak forecasting, database querying, strategic game-playing, demand forecasting) designed to test whether LLM-based agents improve via sequential experience on tasks sharing discoverable latent structures. It compares agent architectures from naive in-context learning (ICL) to dedicated memory systems, introduces a gain metric to separate online learning from base capabilities, and reports that current systems overfit or fail to reuse knowledge, with dedicated memory systems underperforming naive ICL.
Significance. If the experimental controls and task constructions hold, the benchmark would provide a valuable, reproducible tool for measuring genuine continual learning progress in stateful settings, and the counterintuitive result that ICL outperforms specialized memory architectures would usefully redirect research attention toward architectures that better exploit latent structure across episodes.
minor comments (2)
- Clarify the exact formula and statistical controls for the gain metric (mentioned in the abstract) so readers can verify it isolates improvement from base model capability.
- Add an appendix or table listing the specific latent structures per domain and the expert validation protocol to support reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the paper and for recommending minor revision. The referee's description accurately reflects the benchmark design, the gain metric, and the main empirical finding that naive ICL outperforms dedicated memory systems on CL-Bench. No major comments were enumerated in the report, so we have no point-by-point rebuttals to provide. We remain available to address any minor suggestions or clarifications the editor may request.
Circularity Check
No significant circularity in benchmark design or empirical claims
full rationale
The paper introduces CL-Bench as a new empirical benchmark across six domains with expert-validated tasks sharing latent structures. It evaluates agent architectures (including naive ICL vs. dedicated memory) using a gain metric to isolate improvement. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central findings (ICL outperforming memory systems, overfitting issues) follow directly from the task constructions and comparisons under identical backbones, without reducing to self-definition or prior author results by construction. This is a standard benchmark paper whose claims rest on new data collection and measurement rather than internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks in each domain share a learnable latent structure that stateful systems can discover online but stateless ones cannot.
Reference graph
Works this paper leans on
-
[1]
Lisa Adams, Felix Busch, Tianyu Han, Jean-Baptiste Excoffier, Matthieu Ortala, Alexander Löser, Hugo JWL Aerts, Jakob Nikolas Kather, Daniel Truhn, and Keno Bressem. Longhealth: A question answering benchmark with long clinical documents.arXiv preprint arXiv:2401.14490, 2024
arXiv 2024
-
[2]
Memorybench: A benchmark for memory and continual learning in llm systems, 2026
Qingyao Ai, Yichen Tang, Changyue Wang, Jianming Long, Weihang Su, and Yiqun Liu. Memorybench: A benchmark for memory and continual learning in llm systems, 2026. URL https://arxiv.org/abs/2510.17281
Pith/arXiv arXiv 2026
-
[3]
Claude code.https://www.anthropic.com/product/claude-code, 2025
Anthropic. Claude code.https://www.anthropic.com/product/claude-code, 2025
2025
-
[4]
Introducing Claude Opus 4.7
Anthropic. Introducing Claude Opus 4.7. https://www.anthropic.com/news/ claude-opus-4-7, April 2026
2026
-
[5]
Introducing Claude Sonnet 4.6
Anthropic. Introducing Claude Sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6, February 2026
2026
-
[6]
Parth Asawa, Alexandros G. Dimakis, and Matei Zaharia. Sieve: Sample-efficient parametric learning from natural language, 2026. URLhttps://arxiv.org/abs/2604.02339
Pith/arXiv arXiv 2026
-
[7]
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance agent benchmark: Benchmarking llms on real-world financial research tasks.arXiv preprint arXiv:2508.00828, 2025
arXiv 2025
-
[8]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
Pith/arXiv arXiv 2025
-
[9]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022. URL https://arxiv.org/abs/1909.08383. Comprehensive survey with stability-plasticity fram...
arXiv 2022
-
[10]
van de Ven, and Tinne Tuytelaars
Matthias De Lange, Gido M. van de Ven, and Tinne Tuytelaars. Continual evaluation for lifelong learning: Identifying the stability gap. InInternational Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id=Zy350cRstc6. Per-iteration evaluation reveals transient forgetting invisible to task-boundary-only metrics
2023
-
[11]
Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?, 2025
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. Swe-bench pro: Can ai agents solve long-ho...
Pith/arXiv arXiv 2025
-
[12]
Cartridges: Lightweight and general-purpose long context representations via self-study, 2025
Sabri Eyuboglu, Ryan Ehrlich, Simran Arora, Neel Guha, Dylan Zinsley, Emily Liu, Will Tennien, Atri Rudra, James Zou, Azalia Mirhoseini, and Christopher Re. Cartridges: Lightweight and general-purpose long context representations via self-study, 2025. URL https://arxiv.org/abs/2506.06266
arXiv 2025
-
[13]
Arc-agi-3: A new challenge for frontier agentic intelligence, 2026
ARC Prize Foundation. Arc-agi-3: A new challenge for frontier agentic intelligence, 2026. URLhttps://arxiv.org/abs/2603.24621
Pith/arXiv arXiv 2026
-
[14]
Introducing Gemini 3 Flash: Frontier intelligence built for speed
Google DeepMind. Introducing Gemini 3 Flash: Frontier intelligence built for speed. https: //blog.google/products/gemini/gemini-3-flash/, December 2025
2025
-
[15]
Gemini 3.1 Pro: A smarter model for your most com- plex tasks
Google DeepMind. Gemini 3.1 Pro: A smarter model for your most com- plex tasks. https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/, March 2026
2026
-
[16]
Richard Hake. Interactive-engagement versus traditional methods: A six-thousand-student survey of mechanics test data for introductory physics courses.American Journal of Physics - AMER J PHYS, 66, 01 1998. doi: 10.1119/1.18809
-
[17]
Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
Pith/arXiv arXiv 2024
-
[18]
Reinforcement learning via self-distillation, 2026
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation, 2026. URL https://arxiv.org/abs/ 2601.20802
Pith/arXiv arXiv 2026
-
[19]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024. URLhttps://arxiv.org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[20]
Swe-bench-cl: Continual learning for coding agents.arXiv preprint arXiv:2507.00014, 2025
Thomas Joshi, Shayan Chowdhury, and Fatih Uysal. Swe-bench-cl: Continual learning for coding agents.arXiv preprint arXiv:2507.00014, 2025
arXiv 2025
-
[21]
Continual learning via sparse memory finetuning, 2025
Jessy Lin, Luke Zettlemoyer, Gargi Ghosh, Wen-Tau Yih, Aram Markosyan, Vincent-Pierre Berges, and Barlas O ˘guz. Continual learning via sparse memory finetuning, 2025. URL https://arxiv.org/abs/2510.15103
arXiv 2025
-
[22]
Evaluating very long-term conversational memory of llm agents, 2024
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents, 2024. URL https://arxiv.org/abs/2402.17753
Pith/arXiv arXiv 2024
-
[23]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
Pith/arXiv arXiv 2026
-
[24]
Codex: A cloud-based software engineering agent
OpenAI. Codex: A cloud-based software engineering agent. https://openai.com/index/ introducing-codex/, 2025
2025
-
[25]
Introducing GPT-5.4
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026
2026
-
[26]
Gabriel Orlanski, Devjeet Roy, Alexander Yun, Changho Shin, Alex Gu, Albert Ge, Dyah Adila, Nicholas Roberts, Frederic Sala, and Aws Albarghouthi. Slopcodebench: Benchmarking how coding agents degrade over long-horizon iterative tasks.arXiv preprint arXiv:2603.24755, 2026
Pith/arXiv arXiv 2026
-
[27]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024. URL https: //arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2024
-
[28]
Posttrainbench: Can llm agents automate llm post-training? arXiv preprint arXiv:2603.08640, 2026
Ben Rank, Hardik Bhatnagar, Ameya Prabhu, Shira Eisenberg, Karina Nguyen, Matthias Bethge, and Maksym Andriushchenko. Posttrainbench: Can llm agents automate llm post-training? arXiv preprint arXiv:2603.08640, 2026
arXiv 2026
-
[29]
Self-distillation enables continual learning, 2026
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning, 2026. URLhttps://arxiv.org/abs/2601.19897
Pith/arXiv arXiv 2026
-
[30]
Learning to (learn at test time): Rnns with expressive hidden states, 2025
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): Rnns with expressive hidden states, 2025. URL https: //arxiv.org/abs/2407.04620
Pith/arXiv arXiv 2025
-
[31]
End-to-end test-time training for long context, 2025
Arnuv Tandon, Karan Dalal, Xinhao Li, Daniel Koceja, Marcel Rød, Sam Buchanan, Xiaolong Wang, Jure Leskovec, Sanmi Koyejo, Tatsunori Hashimoto, Carlos Guestrin, Jed McCaleb, Yejin Choi, and Yu Sun. End-to-end test-time training for long context, 2025. URL https: //arxiv.org/abs/2512.23675
arXiv 2025
-
[32]
van de Ven, Tinne Tuytelaars, and Andreas S
Gido M. van de Ven, Tinne Tuytelaars, and Andreas S. Tolias. Three types of incremental learning.Nature Machine Intelligence, 2022. URL https://www.nature.com/articles/ s42256-022-00568-3 . Canonical taxonomy: task-incremental, domain-incremental, class- incremental
2022
-
[33]
Gido M. van de Ven, Nicholas Soures, and Dhireesha Kudithipudi.Continual learn- ing and catastrophic forgetting, page 153–168. Elsevier, 2025. ISBN 9780443157554. doi: 10.1016/b978-0-443-15754-7.00073-0. URL http://dx.doi.org/10.1016/ B978-0-443-15754-7.00073-0
-
[34]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025
Pith/arXiv arXiv 2025
-
[35]
Continual world: A robotic benchmark for continual reinforcement learning, 2021
Maciej Wołczyk, Michał Zaj ˛ ac, Razvan Pascanu, Łukasz Kuci´nski, and Piotr Miło´s. Continual world: A robotic benchmark for continual reinforcement learning, 2021. URL https://arxiv. org/abs/2105.10919
arXiv 2021
-
[36]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024. URL https: //arxiv.org/abs/2...
Pith/arXiv arXiv 2024
-
[37]
Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. Theagentcompany: Benchmarking llm agents on consequential real world tasks, 2025....
Pith/arXiv arXiv 2025
-
[38]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.ArXiv, abs/2406.12045, 2024. URL https://api.semanticscholar.org/CorpusID:270562578
Pith/arXiv arXiv 2024
-
[39]
Agentic context engineering: Evolving contexts for self-improving language models, 2026
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models, 2026. URLhttps://arxiv.org/abs/2510.04618
Pith/arXiv arXiv 2026
-
[40]
Lifelongagentbench: Evaluating llm agents as lifelong learners, 2025
Junhao Zheng, Xidi Cai, Qiuke Li, Duzhen Zhang, ZhongZhi Li, Yingying Zhang, Le Song, and Qianli Ma. Lifelongagentbench: Evaluating llm agents as lifelong learners, 2025. URL https://arxiv.org/abs/2505.11942
arXiv 2025
-
[41]
Shanshan Zhong, Yi Lu, Jingjie Ning, Yibing Wan, Lihan Feng, Yuyi Ao, Leonardo F. R. Ribeiro, Markus Dreyer, Sean Ammirati, and Chenyan Xiong. Skilllearnbench: Benchmarking continual learning methods for agent skill generation on real-world tasks, 2026. URL https: //arxiv.org/abs/2604.20087
Pith/arXiv arXiv 2026
-
[42]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024. URL https://arxiv.org/abs/ 2307.13854
Pith/arXiv arXiv 2024
-
[43]
Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, and Pulkit Agrawal. Self- adapting language models, 2025. URLhttps://arxiv.org/abs/2506.10943. A Task Details This appendix describes each CL-BENCHtask in detail: its continual-learning framing, the informa- tion available to the agent each instance, an illustrative prompt–response exchange, th...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.