VTI-CoT: Visual-Textual Interleaved Chain of Thought for Video Reasoning
Pith reviewed 2026-06-28 01:50 UTC · model grok-4.3
The pith
Interleaving visual frames into chain-of-thought reasoning improves video reasoning accuracy and training efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a Visual-Textual Interleaved Chain of Thought framework, which pairs each textual reasoning step with the corresponding visual frames, together with an automated pipeline that generates such multimodal supervision and an OCR compression step that collapses long CoT sequences into a single canvas, produces state-of-the-art video reasoning results among models of the same parameter count and markedly faster training convergence.
What carries the argument
The Visual-Textual Interleaved CoT that inserts matching video frames into each textual reasoning step, supported by automated multimodal annotation and OCR-based compression of supervision signals.
If this is right
- Models of fixed parameter count reach higher accuracy on temporal and causal video tasks than text-only CoT baselines.
- Long video sequences become trainable because CoT token length is reduced without discarding critical visual information.
- Training time decreases substantially while performance on complex event understanding improves.
- The same interleaving pattern applies to other long-sequence multimodal reasoning problems.
Where Pith is reading between the lines
- The compression technique could be tested on non-video sequential tasks where token length also limits training.
- If the automated pipeline generalizes, similar data-generation methods might reduce dependence on manual annotation for other interleaved reasoning formats.
- Smaller models trained this way might close the gap with much larger text-only models on video benchmarks.
Load-bearing premise
The automated annotation pipeline produces high-quality multimodal CoT data that faithfully captures visual-textual interleaved reasoning suitable for training.
What would settle it
Train two otherwise identical models, one with standard text-only CoT and one with VTI-CoT, on the same video reasoning benchmarks; if the interleaved version shows no accuracy gain or no reduction in training steps to convergence, the central benefit would be refuted.
Figures

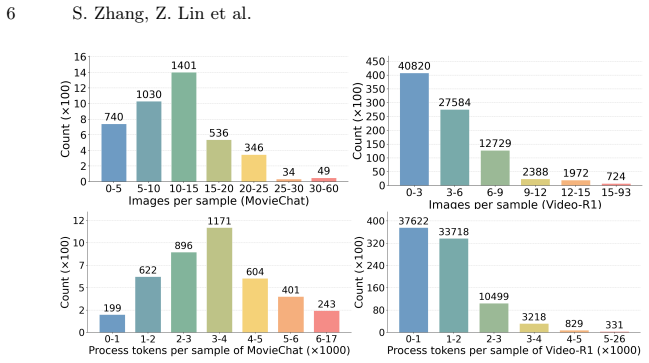
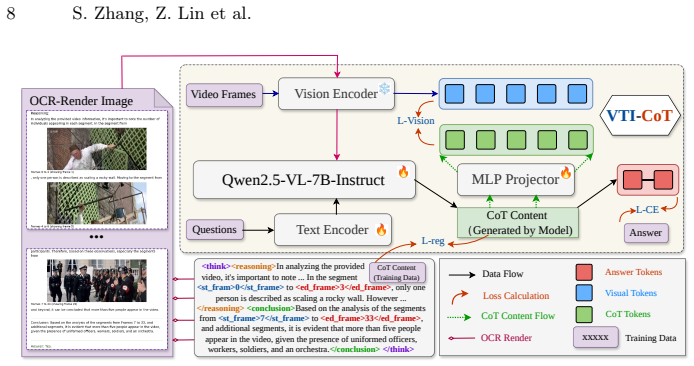
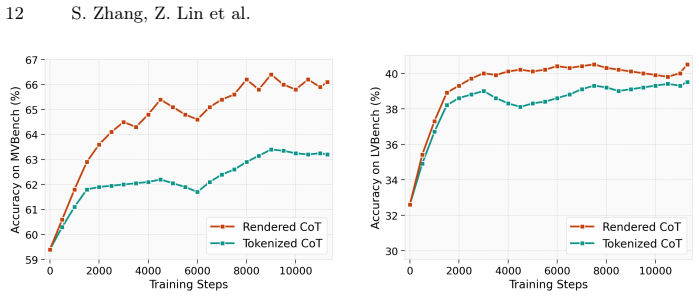




read the original abstract
Video reasoning aims to understand complex temporal events and causal relationships within videos. Recently, Chain-of-Thought (CoT) has been introduced to this field to enhance reasoning accuracy. However, existing CoT-based video reasoning methods primarily rely on text-only information for logical deduction, overlooking critical visual information during the inference process. Inspired by the human cognitive mechanism of reviewing visual segments during inference, we propose VTI-CoT, a Visual-Textual Interleaved CoT framework. VTI-CoT integrates textual reasoning steps with corresponding visual frames. Given the scarcity of visual-textual interleaved CoT in existing datasets, we develop an automated annotation pipeline to construct high-quality multimodal CoT data. Further, reasoning over long-form videos entails increasingly long CoT token sequences, which severely hinders training convergence and efficiency. To address this, we employ Optical Character Recognition (OCR)-based compression techniques to compress CoT supervision signals into a single canvas. Experimental results demonstrate that VTI-CoT achieves state-of-the-art performance among models of the same parameter scale while significantly improving training efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VTI-CoT, a Visual-Textual Interleaved Chain-of-Thought framework for video reasoning that augments textual reasoning steps with corresponding visual frames. Due to the lack of such interleaved data, the authors introduce an automated annotation pipeline to generate multimodal CoT supervision and apply OCR-based compression to condense long CoT token sequences into a single canvas for improved training efficiency. The central claim is that models trained with this approach achieve state-of-the-art performance among same-parameter-scale models while significantly improving training efficiency.
Significance. If the automated pipeline produces faithful interleaved reasoning data and the reported gains are reproducible, the work would provide a concrete mechanism for incorporating visual review during inference, addressing a gap in text-only CoT video methods. The OCR compression technique offers a practical solution to long-sequence training issues. These elements could influence future multimodal reasoning systems if the data quality is independently verified.
major comments (2)
- [Automated annotation pipeline] Automated annotation pipeline section: No quantitative validation metrics (human agreement scores, error rates, or comparison to manual CoT) are supplied for the generated visual-textual interleaved data. This is load-bearing for the SOTA and efficiency claims, as performance gains could arise from systematic artifacts in the pipeline rather than the VTI-CoT framework itself.
- [Experimental results] Experimental results section: The manuscript provides no tables or figures with specific metrics, baselines, dataset details, or ablations that isolate the contribution of interleaved visual-textual CoT versus the compression step or data volume. Without these, the claim of SOTA at fixed parameter scale cannot be verified as attributable to the proposed method.
minor comments (1)
- [Method] Notation for the OCR canvas compression could be clarified with an equation or pseudocode example showing how token sequences map to the single canvas.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below.
read point-by-point responses
-
Referee: [Automated annotation pipeline] Automated annotation pipeline section: No quantitative validation metrics (human agreement scores, error rates, or comparison to manual CoT) are supplied for the generated visual-textual interleaved data. This is load-bearing for the SOTA and efficiency claims, as performance gains could arise from systematic artifacts in the pipeline rather than the VTI-CoT framework itself.
Authors: We agree that the manuscript lacks quantitative validation metrics for the automated annotation pipeline. In the revised version we will add a dedicated evaluation subsection reporting human agreement scores, error rates, and direct comparisons against manually annotated CoT examples to confirm data fidelity. revision: yes
-
Referee: [Experimental results] Experimental results section: The manuscript provides no tables or figures with specific metrics, baselines, dataset details, or ablations that isolate the contribution of interleaved visual-textual CoT versus the compression step or data volume. Without these, the claim of SOTA at fixed parameter scale cannot be verified as attributable to the proposed method.
Authors: We acknowledge that the current manuscript does not present the requested level of experimental detail. The revision will include expanded tables and figures with concrete metrics, baseline comparisons, dataset specifications, and ablation studies that separately measure the contributions of the interleaved visual-textual CoT and the OCR compression step. revision: yes
Circularity Check
No circularity: empirical method and experiments, no derivations or self-referential reductions
full rationale
The paper introduces VTI-CoT as a proposed framework that interleaves visual frames with textual CoT steps, constructs data via an automated annotation pipeline, and applies OCR compression for long sequences. All performance claims (SOTA at fixed scale, efficiency gains) are presented as outcomes of experiments on the resulting trained models. No equations, uniqueness theorems, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the derivation chain is absent and the work is self-contained as a methodological proposal validated externally by reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24185–24198 (2024)
2024
-
[4]
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., Zhu, Y., Zhang, W., Luo, Z., Zhao, D., Bing, L.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms (2024),https://arxiv.org/abs/2406.07476
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H.W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prab- hakaran, V., Reif, E., Du, N., Hutchinson, B., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur-Ari, G., Yin, P., Duke, T., Levsk...
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [6]
- [7]
-
[8]
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y., Peng, T., Wu, J., Zhang, X., Wang, B., Yue, X.: Video-r1: Reinforcing video reasoning in mllms (2025),https: //arxiv.org/abs/2503.21776
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [9]
-
[10]
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., Chen, P., Li, Y., Lin, S., Zhao, S., Li, K., Xu, T., Zheng, X., Chen, E., Shan, C., He, R., Sun, X.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis (2025),https://arxiv.org/abs/ 2405.21075
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Ghazanfari, S., Croce, F., Flammarion, N., Krishnamurthy, P., Khorrami, F., Garg, S.: Chain-of-frames: Advancing video understanding in multimodal llms via frame- aware reasoning (2025),https://arxiv.org/abs/2506.00318
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
In: The Fourteenth International Conference on Learning Representations (2025)
Gu, J., Hao, Y., Wang, H.W., Li, L., Shieh, M.Q., Choi, Y., Krishna, R., Cheng, Y.: Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought rea- soning. In: The Fourteenth International Conference on Learning Representations (2025)
2025
-
[14]
Hosseini, A., Yuan, X., Malkin, N., Courville, A., Sordoni, A., Agarwal, R.: V-star: Training verifiers for self-taught reasoners (2024),https://arxiv.org/abs/2402. 06457
2024
- [15]
- [16]
-
[17]
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models (2023),https: //arxiv.org/abs/2301.12597
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., Wang, L., Qiao, Y.: Mvbench: A comprehensive multi-modal video understanding benchmark (2024),https://arxiv.org/abs/2311.17005
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Liang, C., Wang, W., Zhou, T., Miao, J., Luo, Y., Yang, Y.: Local-global context aware transformer for language-guided video segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence45(8), 10055–10069 (Aug 2023).https: //doi.org/10.1109/tpami.2023.3262578,http://dx.doi.org/10.1109/TPAMI. 2023.3262578
-
[20]
TempCompass: Do Video LLMs Really Understand Videos?
Liu, Y., Li, S., Liu, Y., Wang, Y., Ren, S., Li, L., Chen, S., Sun, X., Hou, L.: Tempcompass: Do video llms really understand videos? (2024),https://arxiv. org/abs/2403.00476
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
- [22]
- [23]
-
[24]
OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., Bello, I., Berdine, J., Bernadett-Shapiro, G., Berner, C., Bogdonoff, L., Boiko, O., Boyd, M., Brakman, A.L., Brockman, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [25]
- [26]
-
[27]
Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
- [29]
- [30]
- [31]
- [32]
-
[33]
Wang, W., He, Z., Hong, W., Cheng, Y., Zhang, X., Qi, J., Gu, X., Huang, S., Xu, B., Dong, Y., Ding, M., Tang, J.: Lvbench: An extreme long video understanding benchmark (2025),https://arxiv.org/abs/2406.08035
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [34]
-
[35]
Wang, Y., He, Y., Li, Y., Li, K., Yu, J., Ma, X., Li, X., Chen, G., Chen, X., Wang, Y., He, C., Luo, P., Liu, Z., Wang, Y., Wang, L., Qiao, Y.: Internvid: A large-scale video-text dataset for multimodal understanding and generation (2024), https://arxiv.org/abs/2307.06942
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Wang, Y., Li, S., Li, P., Yang, X., Tang, Y., Wei, Z.: Render-of-thought: Rendering textual chain-of-thought as images for visual latent reasoning (2026),https:// arxiv.org/abs/2601.14750
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [37]
-
[38]
Wei,H.,Sun,Y.,Li,Y.:Deepseek-ocr:Contextsopticalcompression(2025),https: //arxiv.org/abs/2510.18234
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Wei,H.,Sun, Y.,Li,Y.:Deepseek-ocr2:Visualcausal flow(2026),https://arxiv. org/abs/2601.20552
-
[40]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models (2023),https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context interleaved video-language understanding (2024),https://arxiv.org/abs/2407. 15754
2024
-
[42]
Wu, Z., Chen, X., Pan, Z., Liu, X., Liu, W., Dai, D., Gao, H., Ma, Y., Wu, C., Wang, B., Xie, Z., Wu, Y., Hu, K., Wang, J., Sun, Y., Li, Y., Piao, Y., Guan, K., Liu, A., Xie, X., You, Y., Dong, K., Yu, X., Zhang, H., Zhao, L., Wang, Y., Ruan, C.: Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding (2024),https://a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Xiang, V., Snell, C., Gandhi, K., Albalak, A., Singh, A., Blagden, C., Phung, D., Rafailov, R., Lile, N., Mahan, D., Castricato, L., Franken, J.P., Haber, N., Finn, C.: Towards system 2 reasoning in llms: Learning how to think with meta chain- of-thought (2025),https://arxiv.org/abs/2501.04682
-
[44]
arXiv preprint arXiv:2503.07334 (2025)
Xie, X., Liu, J., Lin, Z., Fan, H., Han, Z., Tang, Y., Qu, L.: Unleashing the poten- tial of large language models for text-to-image generation through autoregressive representation alignment. arXiv preprint arXiv:2503.07334 (2025)
-
[45]
Xie, Y., Chen, T., Ge, Z., Ni, L.: Video-mtr: Reinforced multi-turn reasoning for long video understanding (2025),https://arxiv.org/abs/2508.20478
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T.L., Cao, Y., Narasimhan, K.: Tree of thoughts: Deliberate problem solving with large language models (2023), https://arxiv.org/abs/2305.10601 20 S. Zhang, Z. Lin et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [47]
- [48]
-
[49]
Zhao, Y., Xie, L., Zhang, H., Gan, G., Long, Y., Hu, Z., Hu, T., Chen, W., Li, C., Song, J., Xu, Z., Wang, C., Pan, W., Shangguan, Z., Tang, X., Liang, Z., Liu, Y., Zhao, C., Cohan, A.: Mmvu: Measuring expert-level multi-discipline video understanding (2025),https://arxiv.org/abs/2501.12380
-
[50]
Zheng, W., Lin, Z., Guo, P., Zhou, Y., Wang, F., Qu, L.: Fedvlmbench: Bench- marking federated fine-tuning of vision-language models (2025),https://arxiv. org/abs/2506.09638
-
[51]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., Le, Q., Chi, E.: Least-to-most prompting enables complex reasoning in large language models (2023),https://arxiv.org/abs/2205.10625 VTI-CoT 21 A Appendix A.1 Dataset Details We provide the prompts used for interval-level visual description generation and ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.