ReverseEOL: Improving Training-free Text Embeddings via Text Reversal in Decoder-only LLMs
Pith reviewed 2026-06-28 01:41 UTC · model grok-4.3
The pith
Reversing the input text in decoder-only LLMs produces a second embedding that supplies context inaccessible in the forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
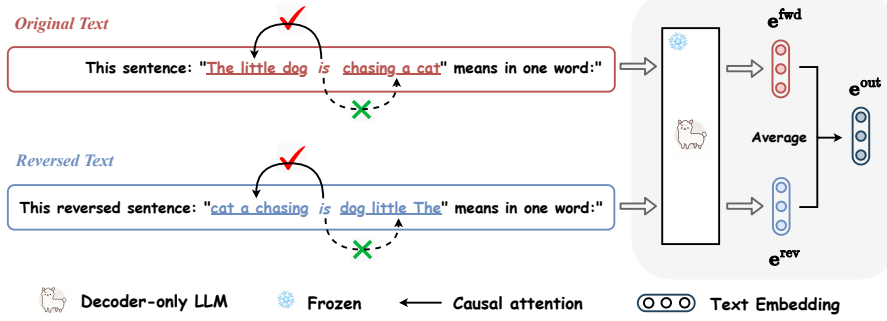
ReverseEOL augments the standard forward embedding with an additional reversed embedding derived from the reversed input text. Since reversing the input exposes each token to context inaccessible in the original order, the resulting reversed embedding effectively provides complementary information to the original one. As a result, combining the forward and reversed embeddings yields a richer final representation. Comprehensive experiments on STS and MTEB benchmarks demonstrate that ReverseEOL significantly improves the performance of existing training-free baselines across a broad range of LLMs with diverse architectures and scales.
What carries the argument
Reverse prompting with Explicit One-word Limitation (ReverseEOL), which creates a reversed embedding from the input text run backward to complement the forward embedding.
If this is right
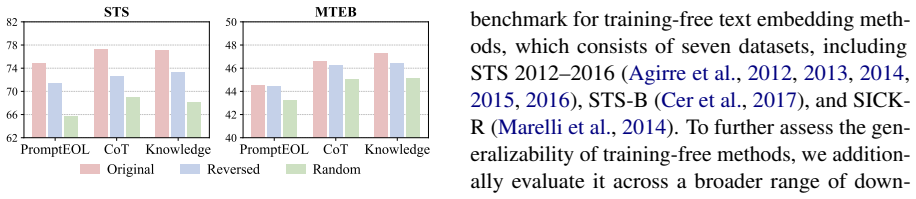
- Improves performance of training-free baselines on STS benchmarks.
- Improves performance on MTEB benchmarks.
- The gains hold across LLMs of different architectures and scales.
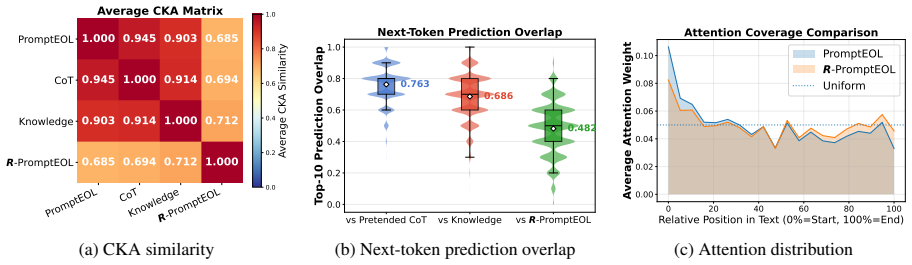
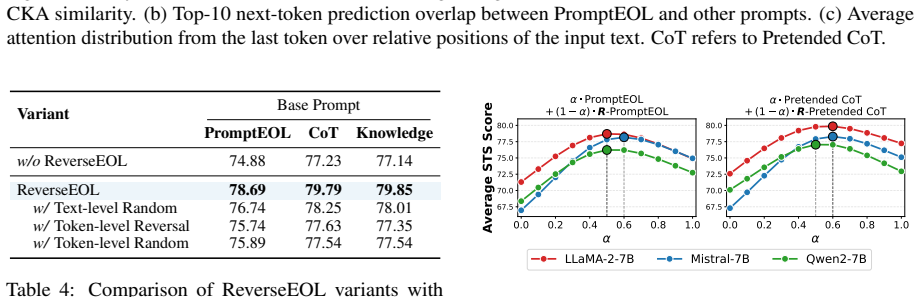
- Ablations confirm that the reversal step itself is required for the observed benefit.
Where Pith is reading between the lines
- The same reversal trick could be tested on other causal sequence models beyond language.
- Different combination rules for the two embeddings, such as learned weights, might yield further gains.
- The method highlights a general way to reduce causal bias through input reordering rather than model changes.
Load-bearing premise
The reversed embedding supplies genuinely complementary information that improves downstream similarity judgments when simply combined with the forward embedding.
What would settle it
Running the combined embedding versus the forward-only embedding on a standard STS benchmark and finding no consistent improvement or outright degradation would falsify the claim.
Figures
read the original abstract
Recent advances in Large Language Models (LLMs) have opened new avenues for generating training-free text embeddings. However, the causal attention in decoder-only LLMs prevents earlier tokens from attending to future context, leading to biased contextualized representations. In this work, we propose Reverse prompting with Explicit One-word Limitation (ReverseEOL), a simple yet effective method for enhancing the representational capability of frozen LLMs. ReverseEOL augments the standard forward embedding with an additional reversed embedding derived from the reversed input text. Since reversing the input exposes each token to context inaccessible in the original order, the resulting reversed embedding effectively provides complementary information to the original one. As a result, combining the forward and reversed embeddings yields a richer final representation. Comprehensive experiments on STS and MTEB benchmarks demonstrate that ReverseEOL significantly improves the performance of existing training-free baselines across a broad range of LLMs with diverse architectures and scales. Extensive ablations and analyses further confirm the necessity of our reversal mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReverseEOL, which augments forward-pass embeddings from decoder-only LLMs with embeddings computed on reversed input text. The reversal is claimed to expose each token to context inaccessible under causal attention, so that simple combination of the two embeddings produces a richer representation. Experiments on STS and MTEB benchmarks report consistent gains over existing training-free baselines across model scales and architectures; ablations are said to confirm that the reversal step is necessary.
Significance. If the reversal supplies genuinely complementary information rather than generic ensembling effects, the method offers a parameter-free, training-free augmentation that directly leverages existing forward passes. This is a clear practical strength. The significance hinges on whether the reported gains survive controls that isolate reversal-specific context exposure from any second embedding.
major comments (2)
- [Ablations] Abstract and ablation section: the statement that 'extensive ablations and analyses further confirm the necessity of our reversal mechanism' does not indicate whether non-reversal perturbations (word shuffling, synonym substitution, or random reordering) were tested. Without such controls the central claim that reversal supplies information 'inaccessible in the original order' cannot be distinguished from the weaker claim that any second embedding improves the result via ensembling.
- [Method / Experiments] Method and experimental sections: the precise combination rule (concatenation, averaging, weighted sum, etc.) used to merge forward and reversed embeddings is not stated, nor is any statistical testing or variance reporting for the benchmark deltas. Both are load-bearing for reproducing and assessing the claim that the combined representation is 'richer'.
minor comments (1)
- Clarify whether the 'Explicit One-word Limitation' component of the acronym is used in the reported experiments or is an optional variant.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the clarity and rigor of our claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [Ablations] Abstract and ablation section: the statement that 'extensive ablations and analyses further confirm the necessity of our reversal mechanism' does not indicate whether non-reversal perturbations (word shuffling, synonym substitution, or random reordering) were tested. Without such controls the central claim that reversal supplies information 'inaccessible in the original order' cannot be distinguished from the weaker claim that any second embedding improves the result via ensembling.
Authors: We acknowledge that the ablations presented in the manuscript focus on variants of the reversal approach and comparisons against forward-only baselines rather than non-reversal perturbations such as shuffling or synonym substitution. While the theoretical motivation rests on causal attention exposing complementary context, the referee is correct that this does not yet fully isolate reversal-specific effects from generic ensembling. We will add the suggested control experiments in the revised manuscript to directly address this distinction. revision: yes
-
Referee: [Method / Experiments] Method and experimental sections: the precise combination rule (concatenation, averaging, weighted sum, etc.) used to merge forward and reversed embeddings is not stated, nor is any statistical testing or variance reporting for the benchmark deltas. Both are load-bearing for reproducing and assessing the claim that the combined representation is 'richer'.
Authors: We agree that explicit description of the combination rule and supporting statistical details are necessary for reproducibility. We will revise the method section to state the combination rule precisely and will add variance reporting together with any applicable statistical tests for the reported deltas. revision: yes
Circularity Check
No significant circularity; method is a direct, non-reductive augmentation
full rationale
The paper's central claim is an empirical augmentation: forward embeddings are combined with embeddings from reversed text to exploit causal attention's one-way context limitation. This rests on a standard architectural property of decoder-only LLMs rather than any self-definition, fitted parameter renamed as prediction, or self-citation chain. No equations appear in the provided text, no parameters are fitted to data subsets, and no uniqueness theorems or ansatzes are imported. Ablations are described only at a high level without reducing the reversal benefit to the input by construction. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reversing input text exposes each token to context inaccessible in the original causal order
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.01046 , year=
KV-Embedding: Training-free Text Embedding via Internal KV Re-routing in Decoder-only LLMs , author=. arXiv preprint arXiv:2601.01046 , year=
-
[2]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Contrastive prompting enhances sentence embeddings in llms through inference-time steering , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Token prepending: A training-free approach for eliciting better sentence embeddings from llms , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[4]
Findings of the association for computational linguistics: EMNLP 2024 , pages=
Scaling sentence embeddings with large language models , author=. Findings of the association for computational linguistics: EMNLP 2024 , pages=
2024
-
[5]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Meta-task prompting elicits embeddings from large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
arXiv preprint arXiv:2402.15449 , year=
Repetition improves language model embeddings , author=. arXiv preprint arXiv:2402.15449 , year=
-
[7]
International Conference on Intelligent Computing , pages=
Simple techniques for enhancing sentence embeddings in generative language models , author=. International Conference on Intelligent Computing , pages=. 2024 , organization=
2024
-
[8]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 embedding: Advancing text embedding and reranking through foundation models , author=. arXiv preprint arXiv:2506.05176 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gemini Embedding: Generalizable Embeddings from Gemini
Gemini embedding: Generalizable embeddings from gemini , author=. arXiv preprint arXiv:2503.07891 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2506.20923 , year=
Kalm-embedding-v2: Superior training techniques and data inspire A versatile embedding model , author=. arXiv preprint arXiv:2506.20923 , year=
-
[11]
arXiv preprint arXiv:2412.09165 , year=
When text embedding meets large language model: a comprehensive survey , author=. arXiv preprint arXiv:2412.09165 , year=
-
[12]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
Mteb: Massive text embedding benchmark , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[13]
S em E val-2012 Task 6: A Pilot on Semantic Textual Similarity
Agirre, Eneko and Cer, Daniel and Diab, Mona and Gonzalez-Agirre, Aitor. S em E val-2012 Task 6: A Pilot on Semantic Textual Similarity. * SEM 2012: The First Joint Conference on Lexical and Computational Semantics -- Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic...
2012
-
[14]
* SEM 2013 shared task: Semantic Textual Similarity
Agirre, Eneko and Cer, Daniel and Diab, Mona and Gonzalez-Agirre, Aitor and Guo, Weiwei. * SEM 2013 shared task: Semantic Textual Similarity. Second Joint Conference on Lexical and Computational Semantics (* SEM ), Volume 1: Proceedings of the Main Conference and the Shared Task: Semantic Textual Similarity. 2013
2013
-
[15]
S em E val-2014 Task 10: Multilingual Semantic Textual Similarity
Agirre, Eneko and Banea, Carmen and Cardie, Claire and Cer, Daniel and Diab, Mona and Gonzalez-Agirre, Aitor and Guo, Weiwei and Mihalcea, Rada and Rigau, German and Wiebe, Janyce. S em E val-2014 Task 10: Multilingual Semantic Textual Similarity. Proceedings of the 8th International Workshop on Semantic Evaluation ( S em E val 2014). 2014
2014
-
[16]
S em E val-2015 Task 2: Semantic Textual Similarity, E nglish, S panish and Pilot on Interpretability
Agirre, Eneko and Banea, Carmen and Cardie, Claire and Cer, Daniel and Diab, Mona and Gonzalez-Agirre, Aitor and Guo, Weiwei and Lopez-Gazpio, I \ n igo and Maritxalar, Montse and Mihalcea, Rada and Rigau, German and Uria, Larraitz and Wiebe, Janyce. S em E val-2015 Task 2: Semantic Textual Similarity, E nglish, S panish and Pilot on Interpretability. Pro...
2015
-
[17]
S em E val-2016 Task 1: Semantic Textual Similarity, Monolingual and Cross-Lingual Evaluation
Agirre, Eneko and Banea, Carmen and Cer, Daniel and Diab, Mona and Gonzalez-Agirre, Aitor and Mihalcea, Rada and Rigau, German and Wiebe, Janyce. S em E val-2016 Task 1: Semantic Textual Similarity, Monolingual and Cross-Lingual Evaluation. Proceedings of the 10th International Workshop on Semantic Evaluation ( S em E val-2016). 2016
2016
-
[18]
S em E val-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation
Cer, Daniel and Diab, Mona and Agirre, Eneko and Lopez-Gazpio, I \ n igo and Specia, Lucia. S em E val-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. Proceedings of the 11th International Workshop on Semantic Evaluation ( S em E val-2017). 2017
2017
-
[19]
A SICK cure for the evaluation of compositional distributional semantic models
Marelli, Marco and Menini, Stefano and Baroni, Marco and Bentivogli, Luisa and Bernardi, Raffaella and Zamparelli, Roberto. A SICK cure for the evaluation of compositional distributional semantic models. Proceedings of the Ninth International Conference on Language Resources and Evaluation ( LREC '14). 2014
2014
-
[20]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[21]
Parishad BehnamGhader and Vaibhav Adlakha and Marius Mosbach and Dzmitry Bahdanau and Nicolas Chapados and Siva Reddy , booktitle=
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Training llms to be better text embedders through bidirectional reconstruction , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[23]
Causal2Vec: Improving Decoder-only LLMs as Embedding Models through a Contextual Token
Causal2Vec: Improving Decoder-only LLMs as Versatile Embedding Models , author=. arXiv preprint arXiv:2507.23386 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Improving Text Embeddings with Large Language Models
Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu. Improving Text Embeddings with Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 2024
2024
-
[25]
Negative Matters: Multi-Granularity Hard-Negative Synthesis and Anchor-Token-Aware Pooling for Enhanced Text Embeddings
Pan, Tengyu and Duan, Zhichao and Li, Zhenyu and Dong, Bowen and Liu, Ning and Li, Xiuxing and Wang, Jianyong. Negative Matters: Multi-Granularity Hard-Negative Synthesis and Anchor-Token-Aware Pooling for Enhanced Text Embeddings. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[26]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[27]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Qwen2 Technical Report , author =. arXiv preprint arXiv:2407.10671 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
OLMoE: Open Mixture-of-Experts Language Models
Olmoe: Open mixture-of-experts language models , author=. arXiv preprint arXiv:2409.02060 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Minicpm4: Ultra-efficient llms on end devices
Minicpm4: Ultra-efficient llms on end devices , author=. arXiv preprint arXiv:2506.07900 , year=
-
[36]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters" , url =
Qwen Team , month =. Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters" , url =
-
[38]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2309.12871 , year=
Angle-optimized text embeddings , author=. arXiv preprint arXiv:2309.12871 , year=
-
[40]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Bellm: Backward dependency enhanced large language model for sentence embeddings , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[41]
Fantastic Semantics and Where to Find Them: Investigating Which Layers of Generative LLM s Reflect Lexical Semantics
Liu, Zhu and Kong, Cunliang and Liu, Ying and Sun, Maosong. Fantastic Semantics and Where to Find Them: Investigating Which Layers of Generative LLM s Reflect Lexical Semantics. Findings of the Association for Computational Linguistics: ACL 2024. 2024
2024
-
[42]
Exploring Concept Depth: How Large Language Models Acquire Knowledge and Concept at Different Layers?
Jin, Mingyu and Yu, Qinkai and Huang, Jingyuan and Zeng, Qingcheng and Wang, Zhenting and Hua, Wenyue and Zhao, Haiyan and Mei, Kai and Meng, Yanda and Ding, Kaize and Yang, Fan and Du, Mengnan and Zhang, Yongfeng. Exploring Concept Depth: How Large Language Models Acquire Knowledge and Concept at Different Layers?. Proceedings of the 31st International C...
2025
-
[43]
Social Bias Evaluation for Large Language Models Requires Prompt Variations
Hida, Rem and Kaneko, Masahiro and Okazaki, Naoaki. Social Bias Evaluation for Large Language Models Requires Prompt Variations. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025
2025
-
[44]
H allu L ens: LLM Hallucination Benchmark
Bang, Yejin and Ji, Ziwei and Schelten, Alan and Hartshorn, Anthony and Fowler, Tara and Zhang, Cheng and Cancedda, Nicola and Fung, Pascale. H allu L ens: LLM Hallucination Benchmark. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[45]
arXiv preprint arXiv:2202.08904 , year=
Sgpt: Gpt sentence embeddings for semantic search , author=. arXiv preprint arXiv:2202.08904 , year=
-
[46]
Ask LLM s Directly, ``What shapes your bias?'': Measuring Social Bias in Large Language Models
Shin, Jisu and Song, Hoyun and Lee, Huije and Jeong, Soyeong and Park, Jong. Ask LLM s Directly, ``What shapes your bias?'': Measuring Social Bias in Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024
2024
-
[47]
HAL o GEN : Fantastic LLM Hallucinations and Where to Find Them
Ravichander, Abhilasha and Ghela, Shrusti and Wadden, David and Choi, Yejin. HAL o GEN : Fantastic LLM Hallucinations and Where to Find Them. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.