Deciphering Two Training Clocks in Grokking via Deep Linear Network Theory with Conditional ReLU Reduction
Pith reviewed 2026-06-28 02:23 UTC · model grok-4.3
The pith
Deep linear networks separate fitting from representation simplification into two distinct training clocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
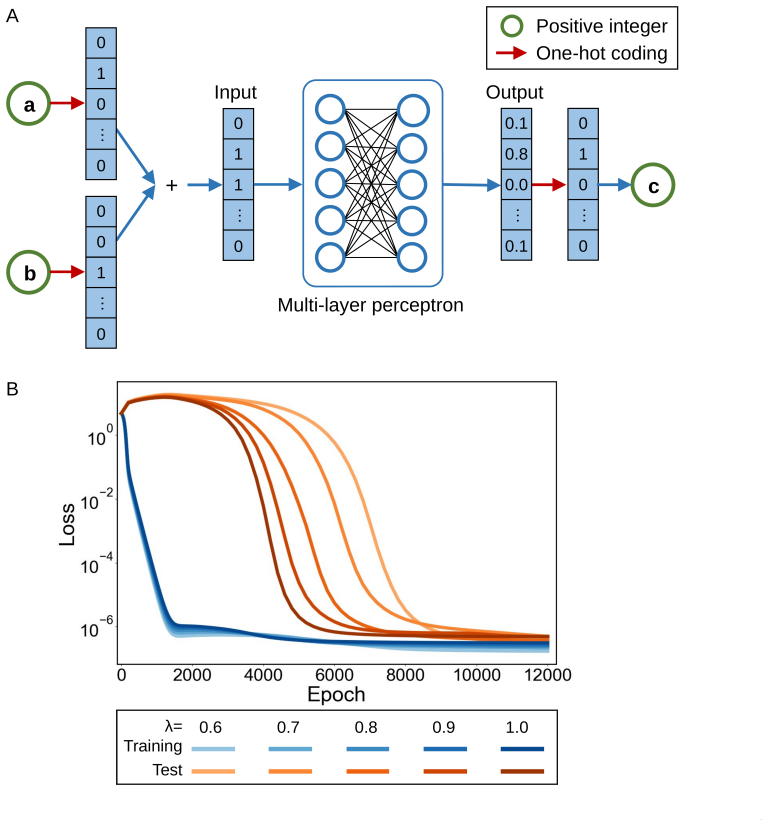
For deep linear networks, a post-margin gap-growth or one-step tail-contraction condition reduces the cross-entropy loss to level epsilon on a logarithmic time scale. In contrast, when layerwise weight decay is present, the induced regularization on the end-to-end map can be expressed as a Schatten-type penalty; under a sharp late-time Kurdyka-Lojasiewicz tail, this structural energy closes on a polynomial time scale. The two clocks therefore separate fitting from representation simplification. In regions where activation patterns on the training set remain fixed the ReLU network reduces to a linear model in the active coordinates, supporting a two-stage mechanism in which the classifier fit
What carries the argument
The pair of stopping times called two training clocks, carried by the post-margin gap-growth condition for logarithmic loss decay and the Schatten-type penalty plus Kurdyka-Lojasiewicz tail for polynomial structural-energy decay.
If this is right
- Cross-entropy loss reaches epsilon on a logarithmic time scale under the post-margin gap-growth or one-step tail-contraction condition.
- The induced Schatten-type penalty on the end-to-end map closes on a polynomial time scale when layerwise weight decay is present.
- In a two-layer ReLU embedding model the classifier head receives larger effective gradients than the embedding block, so the classifier fits first.
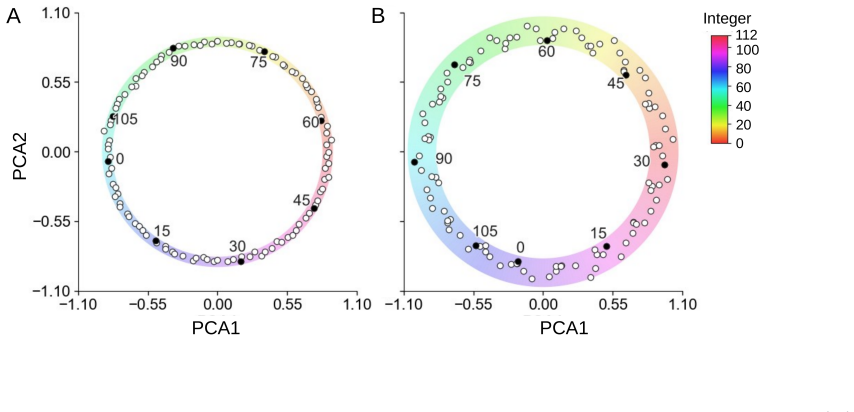
- Modular addition experiments exhibit the two-stage behavior once activation patterns stabilize.
Where Pith is reading between the lines
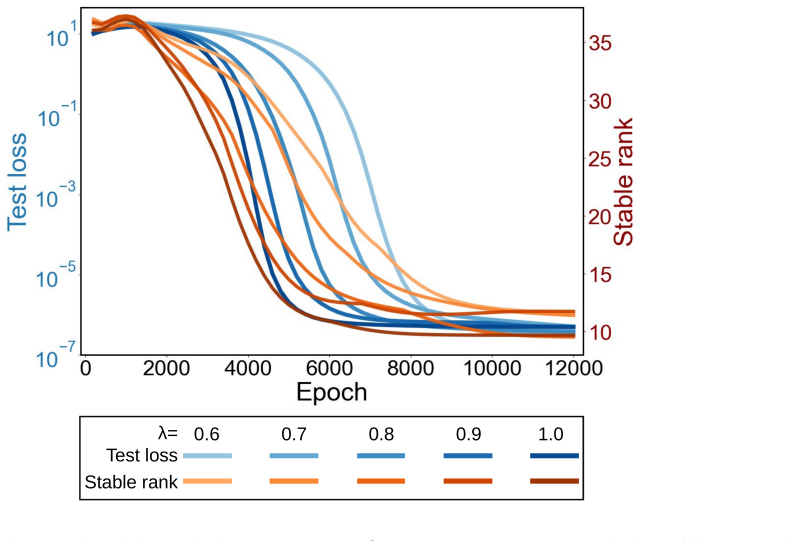
- The same separation could be tested by tracking both loss and effective rank or nuclear norm of the end-to-end map on other tasks that exhibit grokking.
- If the late-time Kurdyka-Lojasiewicz tail holds only after the loss has already saturated, the polynomial clock may be observable only in the presence of weight decay.
- Conditional reduction to linear dynamics suggests that monitoring activation stability on the training set could predict when the slow simplification phase begins in larger ReLU models.
Load-bearing premise
Activation patterns on the training set remain fixed in regions of interest so that the ReLU network reduces to a linear model on the active coordinates.
What would settle it
In a deep linear network with layerwise weight decay, measure whether the cross-entropy loss and the Schatten structural energy both reach their target levels on the same time scale; if they do, the claimed separation of the two clocks is false.
Figures
read the original abstract
Grokking suggests that fitting the training data and learning a simple underlying rule may occur on different time scales. We formalize this phenomenon by separating the fast decay of the classification loss from the slower simplification of the learned representation, and we call the resulting pair of stopping times two training clocks. For deep linear networks, we show that a post-margin gap-growth or one-step tail-contraction condition reduces the cross-entropy loss to level epsilon on a logarithmic time scale. In contrast, when layerwise weight decay is present, the induced regularization on the end-to-end map can be expressed as a Schatten-type penalty; under a sharp late-time Kurdyka-Lojasiewicz tail, this structural energy closes on a polynomial time scale. The two clocks, therefore, separate fitting from representation simplification. We then explain how the same mechanism can appear in ReLU MLPs. In regions where the activation patterns on the training set remain fixed, the network reduces to a linear model in the active coordinates. In a two-layer ReLU embedding model, chain-rule estimates further show that the classifier head can receive larger effective gradients than the embedding block under controlled downstream norms. This supports a two-stage mechanism in which the classifier fits first, while the representation continues to simplify later. We use modular addition as the main experimental setting. The deep linear theory provides the rigorous core of the analysis. But the ReLU results are formulated as conditional reductions that account for empirical behavior without claiming a global proof for nonlinear training dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that grokking arises from two distinct training clocks: a fast logarithmic-time decay of cross-entropy loss to epsilon under post-margin gap-growth or one-step tail-contraction conditions in deep linear networks, versus a slower polynomial-time closure of a Schatten-type structural energy (induced by layerwise weight decay) under a sharp late-time Kurdyka-Lojasiewicz tail. It conditionally extends this separation to ReLU MLPs by reducing to a linear model in active coordinates when activation patterns on the training set remain fixed, supported by chain-rule gradient estimates showing larger effective gradients to the classifier head, and validates the framework experimentally on modular addition.
Significance. If the central derivations hold, the work supplies a clean, optimization-based account of timescale separation between fitting and representation simplification, crediting the rigorous core in deep linear network theory (gap-growth, KL inequality, Schatten penalty) and the explicit conditional framing that avoids overclaiming a global nonlinear proof. This strengthens the theoretical toolkit for analyzing grokking without introducing free parameters or circular reductions.
major comments (1)
- [Abstract (ReLU paragraph)] Abstract (ReLU paragraph) and the conditional reduction section: the claim that the two-clock mechanism appears in ReLU MLPs rests on activation patterns remaining fixed after the fast fitting phase, allowing reduction to the linear theory; however, the manuscript provides no empirical verification, bounds, or late-time analysis confirming this invariance holds in the modular addition experiments, which is load-bearing for transferring the polynomial-time structural energy closure to the nonlinear case.
minor comments (1)
- The abstract references 'chain-rule estimates' for gradient comparison between classifier head and embedding block but does not display the explicit bounds or norm assumptions used; adding these (even as a short derivation) would improve readability of the two-stage mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the deep linear core. We address the single major comment below regarding the conditional ReLU reduction.
read point-by-point responses
-
Referee: [Abstract (ReLU paragraph)] Abstract (ReLU paragraph) and the conditional reduction section: the claim that the two-clock mechanism appears in ReLU MLPs rests on activation patterns remaining fixed after the fast fitting phase, allowing reduction to the linear theory; however, the manuscript provides no empirical verification, bounds, or late-time analysis confirming this invariance holds in the modular addition experiments, which is load-bearing for transferring the polynomial-time structural energy closure to the nonlinear case.
Authors: We agree that the transfer to ReLU MLPs is conditional on activation patterns remaining fixed after the fast phase, and that the manuscript does not supply direct empirical verification or late-time bounds for this invariance in the modular addition experiments. The paper already qualifies the ReLU results explicitly as conditional reductions (see abstract and conditional reduction section) without claiming a global nonlinear proof. To strengthen the presentation, the revised manuscript will add an empirical analysis of activation pattern stability on the training set during late-time training for the modular addition experiments, together with any supporting observations from the existing chain-rule gradient estimates on effective gradients to the classifier head versus embedding block. revision: yes
Circularity Check
No significant circularity; derivation relies on external optimization primitives and conditional reductions
full rationale
The paper's core claims for deep linear networks derive the two timescales from standard external tools (post-margin gap-growth, one-step tail-contraction, Kurdyka-Lojasiewicz inequality) applied to cross-entropy and Schatten penalties; these are not reduced to the paper's own fitted quantities or self-defined inputs. The ReLU extension is explicitly conditional on fixed activation patterns and does not claim a global proof or invoke self-citations as load-bearing uniqueness theorems. No equations or steps in the provided text reduce a prediction to a fitted parameter by construction, rename known results, or smuggle ansatzes via self-citation chains. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Kurdyka-Lojasiewicz inequality holds with a sharp late-time tail
- domain assumption Activation patterns on the training set remain fixed in the regions considered
Forward citations
Cited by 1 Pith paper
-
Beyond Neural Collapse: Task-Intrinsic Geometry Governs Neural Representations in Modular Arithmetic
Modular arithmetic induces cyclic rank-2 geometries via layerwise subspace locking and entropy-regularized phase alignment on S^1, prevailing over neural collapse simplices due to a Theta(K) advantage under weight-dec...
Reference graph
Works this paper leans on
-
[1]
, title =
Recht, Benjamin and Fazel, Maryam and Parrilo, Pablo A. , title =. SIAM Review , volume =
-
[2]
Machine Learning , volume =
Xu, Huan and Mannor, Shie , title =. Machine Learning , volume =
-
[3]
Vershynin, Roman , title =
-
[4]
and Bhojanapalli, Srinadh and Neyshabur, Behnam and Srebro, Nathan , title =
Gunasekar, Suriya and Woodworth, Blake E. and Bhojanapalli, Srinadh and Neyshabur, Behnam and Srebro, Nathan , title =. NeurIPS , year =
-
[5]
Psychometrika , volume =
Eckart, Carl and Young, Gale , title =. Psychometrika , volume =
-
[6]
Quarterly Journal of Mathematics , volume =
Mirsky, Leon , title =. Quarterly Journal of Mathematics , volume =
-
[7]
Filippov, A. F. , title =
-
[8]
Transactions on Machine Learning Research , year =
Huh, Minyoung and Mobahi, Hossein and Zhang, Richard and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip , title =. Transactions on Machine Learning Research , year =
-
[9]
NeurIPS , year =
Arora, Sanjeev and Cohen, Nadav and Hu, Wei and Luo, Yuping , title =. NeurIPS , year =
-
[10]
Mathematics , volume =
Shang, Fanhua and Liu, Yuanyuan and Shang, Fanjie and Liu, Hongying and Kong, Lin and Jiao, Licheng , title =. Mathematics , volume =
-
[11]
COLM , year =
Huang, Yufei and Hu, Shengding and Han, Xu and Liu, Zhiyuan and Sun, Maosong , title =. COLM , year =
-
[12]
and Tegmark, Max and Williams, Mike , title =
Liu, Ziming and Kitouni, Ouail and Nolte, Niklas and Michaud, Eric J. and Tegmark, Max and Williams, Mike , title =. NeurIPS , year =
-
[13]
, title =
Mohamadi, Mohamad Amin and Li, Zhiyuan and Wu, Lei and Sutherland, Danica J. , title =. ICML , year =
-
[14]
and Tegmark, Max , title =
Liu, Ziming and Michaud, Eric J. and Tegmark, Max , title =. ICLR , year =
-
[15]
ICLR , year =
Nanda, Neel and Chan, Lawrence and Lieberum, Tom and Smith, Jess and Steinhardt, Jacob , title =. ICLR , year =
-
[16]
arXiv preprint arXiv:2301.02679 , year =
Gromov, Andrey , title =. arXiv preprint arXiv:2301.02679 , year =
-
[17]
arXiv preprint arXiv:2406.03495 , year =
Doshi, Darshil and He, Tianyu and Das, Aritra and Gromov, Andrey , title =. arXiv preprint arXiv:2406.03495 , year =
-
[18]
Explaining Grokking Through Circuit Efficiency , journal =
Varma, Vikrant and Shah, Rohin and Kenton, Zachary and Kram. Explaining Grokking Through Circuit Efficiency , journal =
-
[19]
Grokking Phase Transitions in Learning Local Rules with Gradient Descent , journal =
-
[20]
ALT , year =
Timor, Nadav and Vardi, Gal and Shamir, Ohad , title =. ALT , year =
-
[21]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Power, Alethea and Burda, Yuri and Edwards, Harri and Babuschkin, Igor and Misra, Vedant , title =. arXiv preprint arXiv:2201.02177 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Journal of Machine Learning Research , volume =
Soudry, Daniel and Hoffer, Elad and Shpigel Nacson, Mor and Gunasekar, Suriya and Srebro, Nathan , title =. Journal of Machine Learning Research , volume =
-
[23]
ICLR , year =
Ji, Ziwei and Telgarsky, Matus , title =. ICLR , year =
-
[24]
ICLR , year =
Lyu, Kaifeng and Li, Jian , title =. ICLR , year =
-
[25]
Galanti, Tomer and Siegel, Zachary S. and Gupte, Aparna and Poggio, Tomaso , title =. arXiv preprint arXiv:2206.05794 , year =
-
[26]
ICLR , year =
Rieck, Bastian and Togninalli, Matteo and Bock, Christian and Moor, Michael and Horn, Max and Gumbsch, Thomas and Borgwardt, Karsten , title =. ICLR , year =
-
[27]
Journal of Machine Learning Research , volume =
Naitzat, Gregory and Zhitnikov, Andrey and Lim, Lek-Heng , title =. Journal of Machine Learning Research , volume =
-
[28]
Predicting the Generalization Gap in Neural Networks Using Topological Data Analysis , journal =
Ballester, Rub. Predicting the Generalization Gap in Neural Networks Using Topological Data Analysis , journal =
-
[29]
Papyan, Vardan and Han, X. Y. and Donoho, David L. , title =. Proceedings of the National Academy of Sciences , volume =
-
[30]
NeurIPS , year =
Zhu, Zhihui and Ding, Tianyu and Zhou, Jinxin and Li, Xiao and You, Chong and Sulam, Jeremias and Qu, Qing , title =. NeurIPS , year =
-
[31]
and Parshall, Hans and Pi, Jianzong , title =
Mixon, Dustin G. and Parshall, Hans and Pi, Jianzong , title =. Sampling Theory, Signal Processing, and Data Analysis , volume =
-
[32]
, title =
Anthony, Martin and Bartlett, Peter L. , title =
-
[33]
and Mendelson, Shahar , title =
Bartlett, Peter L. and Mendelson, Shahar , title =. Journal of Machine Learning Research , volume =
-
[34]
Ledoux, Michel and Talagrand, Michel , title =
-
[35]
IEEE Transactions on Neural Networks and Learning Systems , volume =
Wang, Sicong and Gai, Kuo and Zhang, Shihua , title =. IEEE Transactions on Neural Networks and Learning Systems , volume =
-
[36]
ICLR , year =
Aubry, Murdock and Meng, Haoming and Sugolov, Anton and Papyan, Vardan , title =. ICLR , year =
-
[37]
arXiv preprint arXiv:2408.08944 , year =
Clauw, Kenzo and Stramaglia, Sebastiano and Marinazzo, Daniele , title =. arXiv preprint arXiv:2408.08944 , year =
-
[38]
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , booktitle =
Jacot, Arthur and Gabriel, Franck and Hongler, Cl. Neural Tangent Kernel: Convergence and Generalization in Neural Networks , booktitle =
-
[39]
and Bahri, Yasaman and Novak, Roman and Sohl-Dickstein, Jascha and Pennington, Jeffrey , title =
Lee, Jaehoon and Xiao, Lechao and Schoenholz, Samuel S. and Bahri, Yasaman and Novak, Roman and Sohl-Dickstein, Jascha and Pennington, Jeffrey , title =. NeurIPS , year =
-
[40]
On Lazy Training in Differentiable Programming , booktitle =
Chizat, L. On Lazy Training in Differentiable Programming , booktitle =
-
[41]
and McClelland, James L
Saxe, Andrew M. and McClelland, James L. and Ganguli, Surya , title =. ICLR , year =
-
[42]
and Foster, Dylan J
Bartlett, Peter L. and Foster, Dylan J. and Telgarsky, Matus , title =. NeurIPS , year =
-
[43]
Convergence of Descent Methods for Semi-Algebraic and Tame Problems: Proximal Algorithms, Forward--Backward Splitting, and Regularized Gauss--Seidel Methods , journal =
Attouch, Hedy and Bolte, J. Convergence of Descent Methods for Semi-Algebraic and Tame Problems: Proximal Algorithms, Forward--Backward Splitting, and Regularized Gauss--Seidel Methods , journal =
-
[44]
Proximal Alternating Linearized Minimization for Nonconvex and Nonsmooth Problems , journal =
Bolte, J. Proximal Alternating Linearized Minimization for Nonconvex and Nonsmooth Problems , journal =
-
[45]
Annales de l'Institut Fourier , volume =
Kurdyka, Krzysztof , title =. Annales de l'Institut Fourier , volume =
-
[46]
Tyrrell and Wets, Roger J.-B
Rockafellar, R. Tyrrell and Wets, Roger J.-B. , title =
-
[47]
Exact Matrix Completion via Convex Optimization , journal =
Cand. Exact Matrix Completion via Convex Optimization , journal =
-
[48]
NeurIPS , year =
Rahimi, Ali and Recht, Benjamin , title =. NeurIPS , year =
-
[49]
, title =
Yang, Greg and Hu, Edward J. , title =. ICML , year =
-
[50]
and Moroshko, Edward and Savarese, Pedro and Golan, Itay and Soudry, Daniel and Srebro, Nathan , title =
Woodworth, Blake and Gunasekar, Suriya and Lee, Jason D. and Moroshko, Edward and Savarese, Pedro and Golan, Itay and Soudry, Daniel and Srebro, Nathan , title =. COLT , year =
-
[51]
Neural Networks , volume =
Baldi, Pierre and Hornik, Kurt , title =. Neural Networks , volume =
-
[52]
NeurIPS , year =
Kawaguchi, Kenji , title =. NeurIPS , year =
-
[53]
, title =
Laurent, Thomas and von Brecht, James H. , title =. ICML , year =
-
[54]
and Pehlevan, Cengiz , title =
Kumar, Tanishq and Bordelon, Blake and Gershman, Samuel J. and Pehlevan, Cengiz , title =. ICLR , year =
-
[55]
Clustering and Alignment: Understanding the Training Dynamics in Modular Addition , journal =
Mu. Clustering and Alignment: Understanding the Training Dynamics in Modular Addition , journal =
-
[56]
ICLR , year =
Xu, Zhiwei and Ni, Zhiyu and Wang, Yixin and Hu, Wei , title =. ICLR , year =
- [57]
-
[58]
NeurIPS , year =
Kou, Yiwen and Chen, Zixiang and Gu, Quanquan , title =. NeurIPS , year =
-
[59]
Early Neuron Alignment in Two-Layer
Min, Hancheng and Mallada, Enrique and Vidal, Ren. Early Neuron Alignment in Two-Layer. ICLR , year =
-
[60]
arXiv preprint arXiv:2502.17340 , year =
Kuzborskij, Ilja and Abbasi-Yadkori, Yasin , title =. arXiv preprint arXiv:2502.17340 , year =
-
[61]
arXiv preprint arXiv:2410.02176 , year =
Chen, Ke and Yi, Chugang and Yang, Haizhao , title =. arXiv preprint arXiv:2410.02176 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.