GLASS: GRPO-Trained LoRA for Acoustic Style Steering in Zero-Shot Text-to-Speech
Pith reviewed 2026-06-27 23:51 UTC · model grok-4.3
The pith
Separately trained LoRA adapters for acoustic attributes in zero-shot TTS can be linearly swapped, interpolated, and composed without retraining the backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
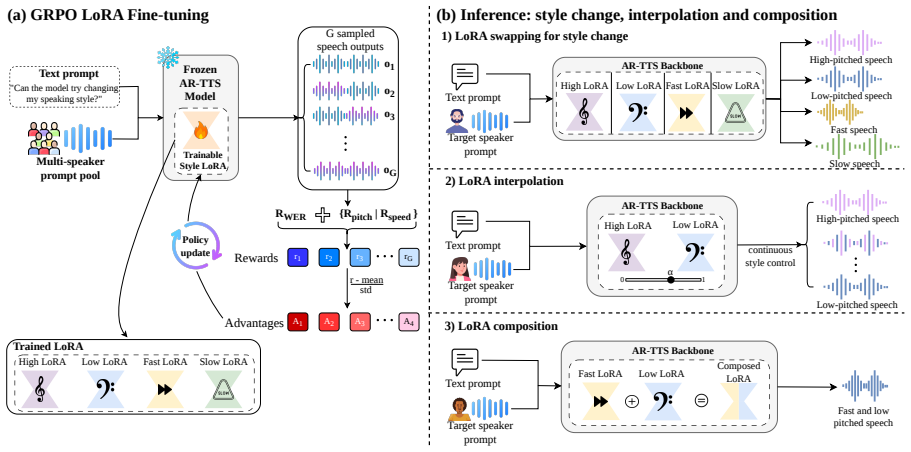
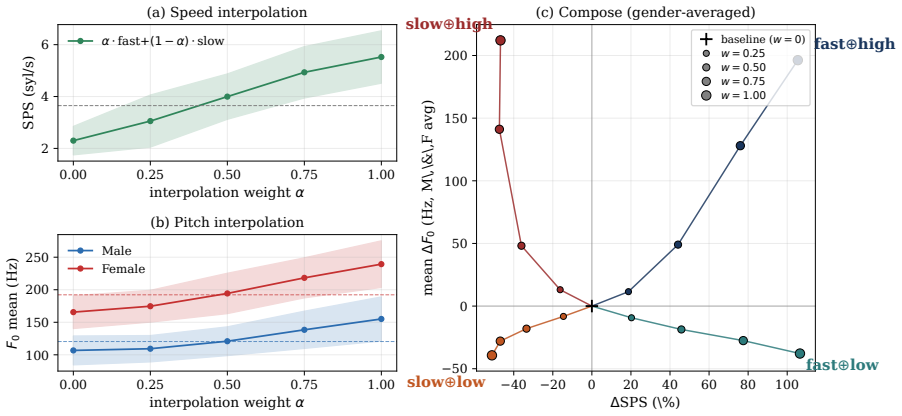
GLASS freezes the TTS backbone and trains one lightweight LoRA adapter per control axis with Group Relative Policy Optimization, using speech-token length and mean F0 as style rewards and WER as an intelligibility anchor. Because each control is represented as a LoRA weight update, independently trained adapters can be swapped, interpolated, and composed through linear LoRA arithmetic without retraining the backbone. Experiments on speaking rate and pitch control show targeted style shifts while preserving naturalness, speaker similarity, and intelligibility, and demonstrate smooth interpolation and multi-axis composition across independently trained adapters.
What carries the argument
GRPO-trained LoRA adapters that encode reward-defined control directions for individual acoustic attributes and enable their composition via linear weight arithmetic.
If this is right
- Targeted shifts in speaking rate or pitch occur while naturalness, speaker similarity, and intelligibility remain stable.
- Smooth interpolation between style levels is achieved by scaling and adding adapter weights.
- Multiple acoustic attributes can be controlled at once by composing adapters trained on separate reward axes.
- Style control requires only computable post-generation rewards rather than curated style labels.
Where Pith is reading between the lines
- If additional scalar rewards can be defined without entanglement, the same adapter approach could extend to other attributes such as energy or timbre.
- Dynamic scaling of adapter weights during inference could enable real-time user interfaces for fine-grained style adjustment.
- The reliance on linear arithmetic suggests the method may reduce data and compute needs for domain-specific TTS customization compared with retraining full models.
Load-bearing premise
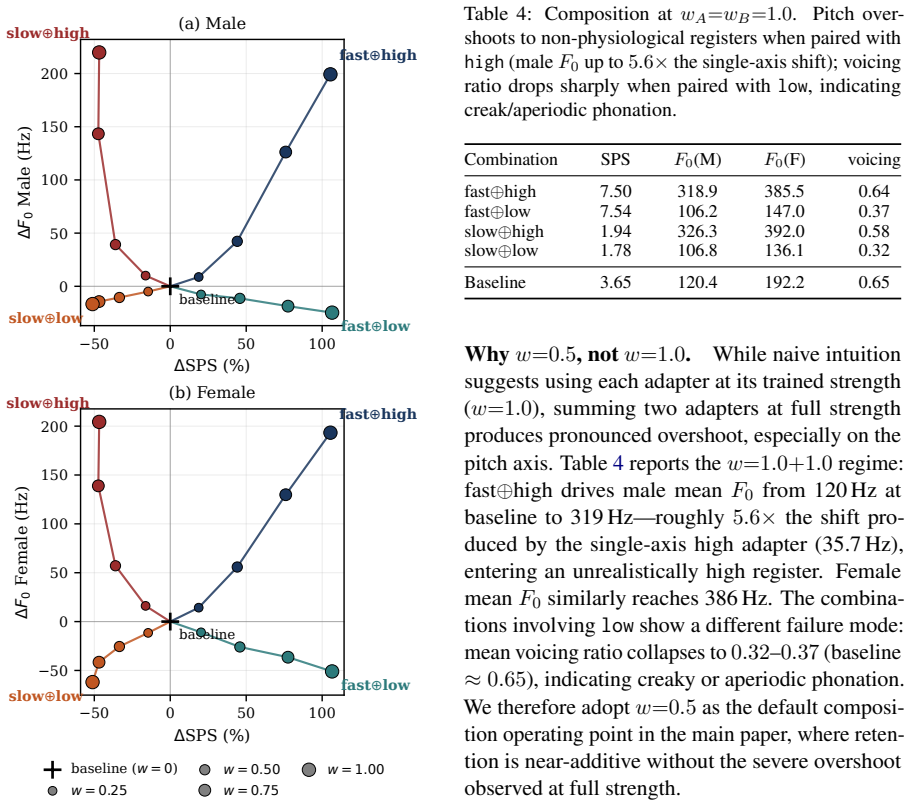
The scalar rewards based on speech-token length, mean F0, and WER supply sufficiently disentangled signals for the target attributes without creating unmeasured side effects on other dimensions of speech quality.
What would settle it
An evaluation where linearly composing two adapters produces a measurable drop in speaker similarity or an increase in artifacts not captured by the WER reward.
Figures
read the original abstract
We propose GLASS, a framework for composable acoustic style control in zero-shot autoregressive text-to-speech (TTS) that learns controls from post-generation rewards rather than style labels. In zero-shot TTS, a speaker prompt often entangles speaker identity with prosodic attributes such as speaking rate and pitch, making it difficult to change style without changing the prompt itself. GLASS instead treats each acoustic attribute as a reward-defined control direction. For each control axis, GLASS freezes the TTS backbone and trains one lightweight LoRA adapter with Group Relative Policy Optimization (GRPO), using speech-token length and mean F0 as style rewards and WER as an intelligibility anchor. Because each control is represented as a LoRA weight update, independently trained adapters can be swapped, interpolated, and composed through linear LoRA arithmetic without retraining the backbone. Experiments on speaking rate and pitch control show targeted style shifts while preserving naturalness, speaker similarity, and intelligibility, and demonstrate smooth interpolation and multi-axis composition across independently trained adapters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GLASS, a framework for composable acoustic style control in zero-shot autoregressive TTS. It freezes the backbone and trains independent lightweight LoRA adapters via Group Relative Policy Optimization (GRPO) using scalar rewards (speech-token length for rate, mean F0 for pitch) anchored by WER for intelligibility. The central claim is that these adapters act as independent control vectors that can be swapped, interpolated, and linearly composed without retraining while preserving naturalness, speaker similarity, and intelligibility.
Significance. If substantiated, the result would demonstrate that external scalar rewards can yield linearly composable LoRA directions for acoustic attributes, enabling label-free style steering in zero-shot TTS. This would be a useful practical contribution for flexible control without style labels or full fine-tuning. The absence of any quantitative results, however, prevents assessment of whether the claimed disentanglement and preservation actually occur.
major comments (2)
- [Abstract] Abstract: the claim that 'experiments ... show targeted style shifts while preserving naturalness, speaker similarity, and intelligibility' is presented without any quantitative metrics, baselines, ablation studies, or statistical tests, rendering the central claim of successful linear composition unevaluable.
- [Method] Method (reward design): the chosen rewards (token length, mean F0) are known to be correlated in natural speech, yet no measurement of cross-effects on untargeted dimensions (e.g., WER drift or speaker similarity under multi-adapter inference) is reported; this directly undermines the assumption that the resulting LoRA updates remain sufficiently disentangled for reliable linear arithmetic.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate the revisions we will make to provide the requested quantitative support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments ... show targeted style shifts while preserving naturalness, speaker similarity, and intelligibility' is presented without any quantitative metrics, baselines, ablation studies, or statistical tests, rendering the central claim of successful linear composition unevaluable.
Authors: We agree that the abstract's claims require quantitative backing to be evaluable. The current manuscript version reports experimental outcomes only qualitatively. In the revision we will add concrete metrics (rate/pitch deviation, WER, speaker similarity via cosine distance, and MOS naturalness), baseline comparisons, composition ablations, and statistical significance tests to substantiate the linear-composition results. revision: yes
-
Referee: [Method] Method (reward design): the chosen rewards (token length, mean F0) are known to be correlated in natural speech, yet no measurement of cross-effects on untargeted dimensions (e.g., WER drift or speaker similarity under multi-adapter inference) is reported; this directly undermines the assumption that the resulting LoRA updates remain sufficiently disentangled for reliable linear arithmetic.
Authors: The observation that token length and mean F0 are correlated in natural speech is correct and directly relevant to the disentanglement claim. The manuscript does not presently include measurements of cross-effects on WER or speaker similarity when multiple adapters are active. We will add targeted experiments that quantify these cross-effects under multi-adapter inference to assess the practical degree of independence. revision: yes
Circularity Check
No circularity; claims rest on external rewards and standard LoRA properties
full rationale
The paper trains LoRA adapters via GRPO using external scalar rewards (token length, mean F0, WER) and asserts linear composability based on the known additive structure of LoRA updates. No equations, derivations, or self-citations reduce the claimed performance, disentanglement, or composition results to quantities defined by the adapters themselves. The approach is empirical and relies on independent reward signals rather than any self-referential fitting or renaming of results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Prompttts: Controllable text-to-speech with text descriptions , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[2]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Instructtts: Modelling expressive tts in discrete latent space with natural language style prompt , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2024 , publisher=
2024
-
[3]
ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Learning latent representations for style control and transfer in end-to-end speech synthesis , author=. ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2019 , organization=
2019
-
[4]
International Conference on Learning Representations , year=
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech , author=. International Conference on Learning Representations , year=
-
[5]
ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Fastpitch: Parallel text-to-speech with pitch prediction , author=. ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2021 , organization=
2021
-
[6]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[7]
arXiv preprint arXiv:2408.14713 , year=
StyleSpeech: Parameter-efficient Fine Tuning for Pre-trained Controllable Text-to-Speech , author=. arXiv preprint arXiv:2408.14713 , year=
-
[8]
International conference on machine learning , pages=
Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[9]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Neural codec language models are zero-shot text to speech synthesizers , author=. arXiv preprint arXiv:2301.02111 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Cosyvoice 2: Scalable streaming speech synthesis with large language models , author=. arXiv preprint arXiv:2412.10117 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models , author=. arXiv preprint arXiv:2406.02430 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching , author=. arXiv preprint arXiv:2410.06885 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
International Conference on Learning Representations , year=
Editing Models with Task Arithmetic , author=. International Conference on Learning Representations , year=
-
[16]
arXiv preprint arXiv:2307.13269 , year=
LoRAHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition , author=. arXiv preprint arXiv:2307.13269 , year=
-
[17]
arXiv preprint arXiv:2311.13600 , year=
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs , author=. arXiv preprint arXiv:2311.13600 , year=
-
[18]
arXiv preprint arXiv:2504.02407 , year=
F5R-TTS: Improving Flow-Matching based Text-to-Speech with Group Relative Policy Optimization , author=. arXiv preprint arXiv:2504.02407 , year=
-
[19]
arXiv preprint arXiv:2511.21270 , year=
Multi-Reward GRPO for Stable and Prosodic Single-Codebook TTS LLMs at Scale , author=. arXiv preprint arXiv:2511.21270 , year=
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DMOSpeech 2: Reinforcement Learning for Duration Prediction in Metric-Optimized Speech Synthesis , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
arXiv preprint arXiv:2305.18802 , year=
Libritts-r: A restored multi-speaker text-to-speech corpus , author=. arXiv preprint arXiv:2305.18802 , year=
-
[22]
International conference on machine learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[23]
arXiv preprint arXiv:2204.02152 , year=
Utmos: Utokyo-sarulab system for voicemos challenge 2022 , author=. arXiv preprint arXiv:2204.02152 , year=
-
[24]
Advances in Neural Information Processing Systems , volume=
Mix-of-show: Decentralized low-rank adaptation for multi-concept customization of diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Orthogonal Adaptation for Modular Customization of Diffusion Models , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2024 , organization=
2024
-
[26]
European Conference on Computer Vision , pages=
Concept sliders: Lora adaptors for precise control in diffusion models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[27]
arXiv preprint arXiv:2402.01912 , year=
Natural language guidance of high-fidelity text-to-speech with synthetic annotations , author=. arXiv preprint arXiv:2402.01912 , year=
-
[28]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Spark-tts: An efficient llm-based text-to-speech model with single-stream decoupled speech tokens , author=. arXiv preprint arXiv:2503.01710 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
No Verifiable Reward for Prosody: Toward Preference-Guided Prosody Learning in TTS , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[30]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Emo-dpo: Controllable emotional speech synthesis through direct preference optimization , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[31]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Group relative policy optimization for text-to-speech with large language models , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[32]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[33]
IEEE Journal of Selected Topics in Signal Processing , volume=
Wavlm: Large-scale self-supervised pre-training for full stack speech processing , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
2022
-
[34]
2026 International Conference on Electronics, Information, and Communication (ICEIC) , pages=
Encoder-Free Style-Controllable Text-to-Speech with Voice Attribute Vectors , author=. 2026 International Conference on Electronics, Information, and Communication (ICEIC) , pages=. 2026 , organization=
2026
-
[35]
Unlocking Fine-Grained and Within-Utterance Speaking Style Control in Prompt-Based Text-to-Speech Models , author=. arXiv preprint arXiv:2605.27376 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.