PLAN-S: Bridging Planning with Latent Style Dynamics for Autonomous Driving World Models
Pith reviewed 2026-06-28 01:12 UTC · model grok-4.3
The pith
Decoding a style-conditioned four-channel semantic cost map from latent representations allows upstream fusion that reduces trajectory errors and collision rates in autonomous driving planners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
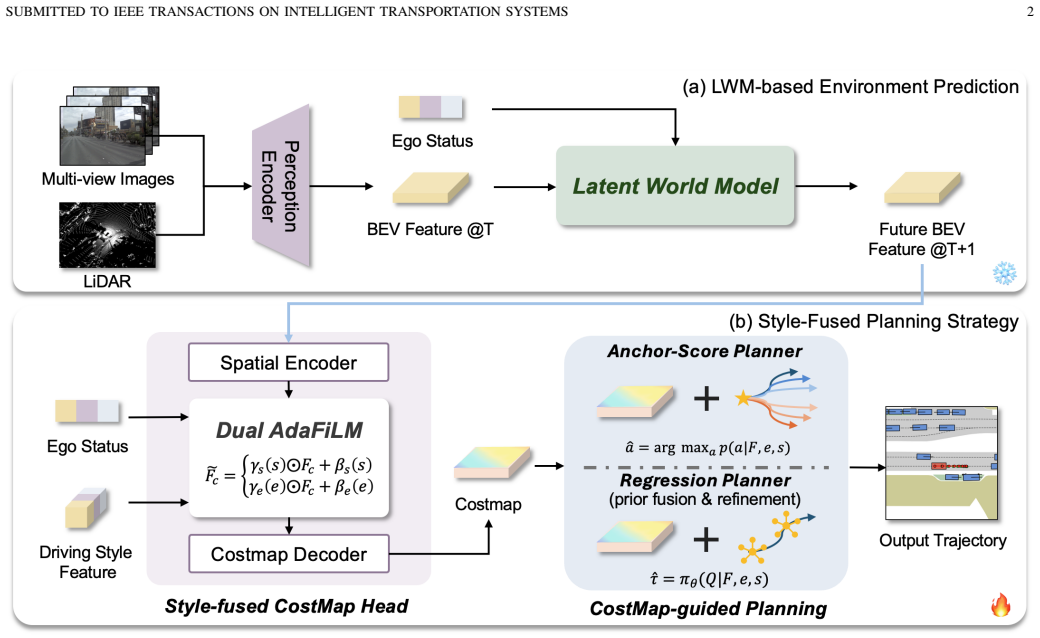
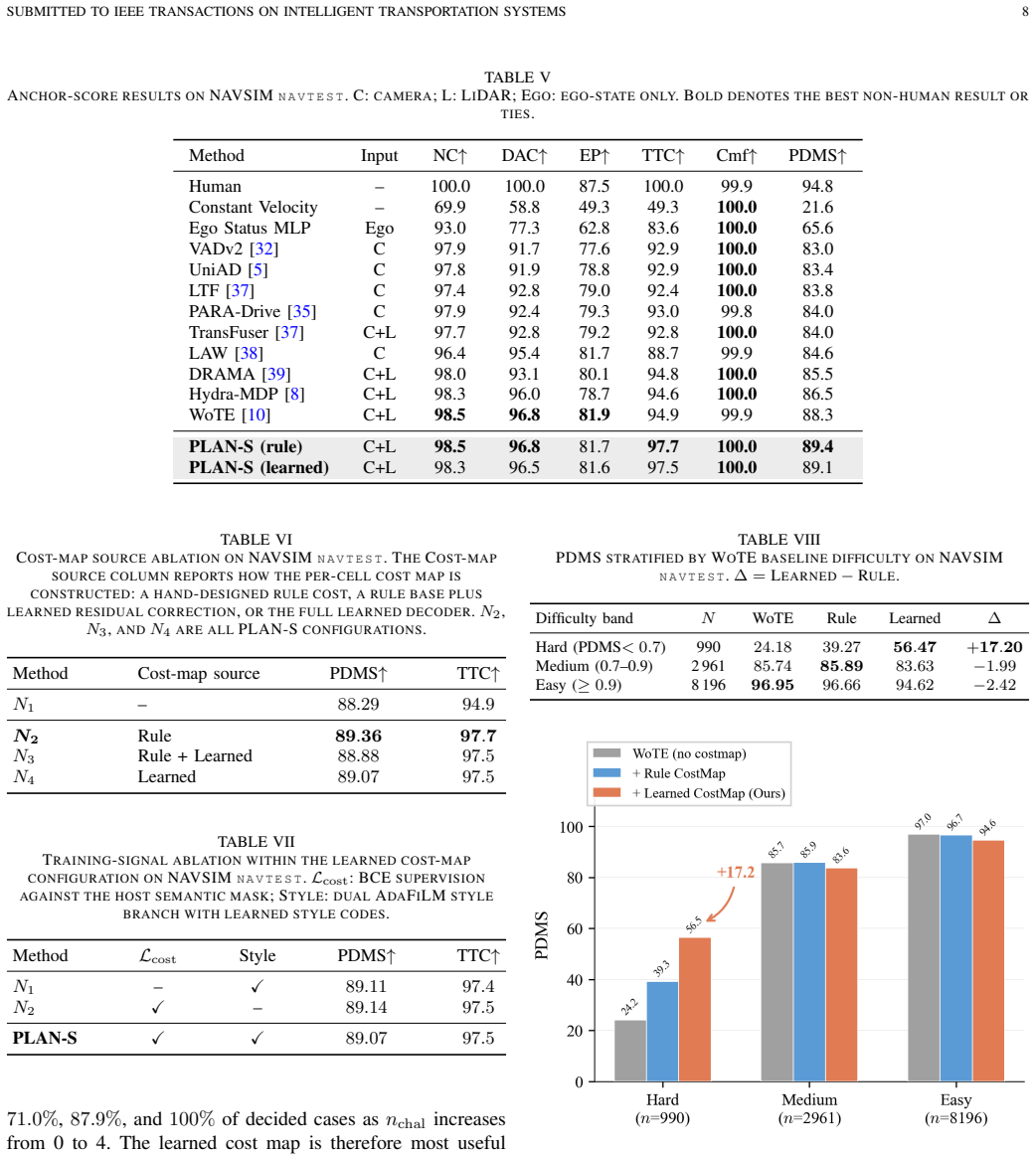
PLAN-S bridges latent world models to planning by decoding a style-conditioned, four-channel semantic cost map from the latent representation. The cost map is conditioned on ego state and driving style and is consumed upstream of the planning decision through attention-level fusion for regression planners and reward-level fusion for anchor-score planners. Validation on two frozen host architectures shows consistent metric gains: 0.55 m average L2 and 42 percent relative reduction in 3 s collision rate on nuScenes, and 89.4 PDMS on NAVSIM for the rule-cost variant, with complementary gains from the learned-cost variant on challenging scenes.
What carries the argument
The style-conditioned four-channel semantic cost map decoded from latent representations and fused upstream of planning via attention-level or reward-level interfaces.
If this is right
- L2 trajectory error decreases at every prediction horizon relative to the frozen baseline.
- 3-second collision rate drops by 42 percent on nuScenes.
- Rule-cost variant reaches 89.4 PDMS on NAVSIM while learned-cost variant adds gains on hard scenes.
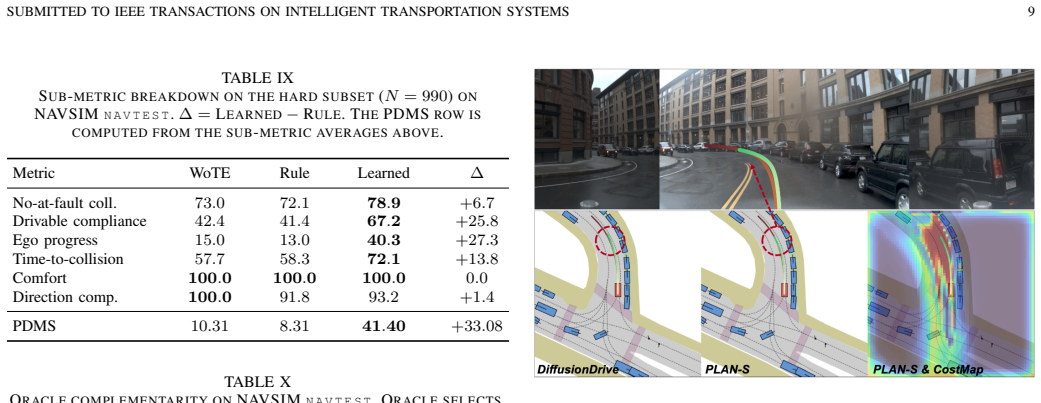
- Cost pathway contributes most directly to safer trajectory selection according to ablations.
- Diverse, spatially consistent cost maps can be generated for different driving styles.
Where Pith is reading between the lines
- The bridge architecture could be inserted into other latent planners without retraining the world model backbone.
- Changing the style conditioning input at inference time might enable online style switching without additional training.
- Hybrid systems that combine the decoded cost map with external rule sets could be tested for further safety margins.
- The approach may transfer to longer-horizon forecasting if the latent encoder preserves style information over extended sequences.
Load-bearing premise
The latent representations already encode sufficient disentangled information about risk, drivability, and style preferences that a four-channel semantic cost map can be decoded and fused upstream of planning without degrading the host planner.
What would settle it
Re-running the nuScenes and NAVSIM evaluations with the cost-map decoder removed or replaced by random maps while keeping hosts frozen, and finding no reduction in L2 or collision rate, would falsify the claim that the decoded cost map drives the observed improvements.
Figures

read the original abstract
Latent world models (LWMs) have strengthened end-to-end autonomous driving by forecasting compact scene dynamics for downstream planning. However, existing LWM-based planners usually generate trajectories directly from entangled latent representations. This compact latent-to-planner pathway lacks explicit modeling of risk, drivability, and diverse style preferences, making driving-style dynamics difficult to supervise, inspect, or modulate before a final trajectory is selected. We propose PLAN-S (PLANning with latent Style dynamics), a planner-facing bridge that addresses this compactness-controllability dilemma by decoding a style-conditioned, four-channel semantic cost map from the latent representation. The cost map is conditioned on ego state and driving style and is consumed up-stream of the planning decision through two host-side interfaces: attention-level fusion for regression planners and reward-level fusion for anchor-score planners. We validate PLAN-S on two architecturally distinct hosts, ResWorld on nuScenes and WoTE on NAVSIM, while keeping the host backbones frozen to isolate the contribution of the proposed bridge. On nuScenes, PLAN-S reduces L2 at every horizon over the baseline, with 0.55 m average L2 and a 42% relative reduction in the 3 s collision rate. On NAVSIM, the rule-cost variant reaches 89.4 Predictive Driver Model Score (PDMS), while the learned cost variant provides complementary gains on baseline-challenging scenes. Ablations show that the cost pathway contributes most directly to safer trajectory selection. Qualitative results further show that PLAN-S can produce diverse cost maps, with spatially consistent variations aligned to different driving styles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PLAN-S, a bridge module that decodes a style-conditioned four-channel semantic cost map from frozen latent world model representations. The cost map is conditioned on ego state and driving style and fused upstream of frozen host planners (ResWorld on nuScenes via attention-level fusion; WoTE on NAVSIM via reward-level fusion) to enable explicit modeling of risk, drivability, and style preferences. Reported results include 0.55 m average L2 error with 42% relative 3 s collision-rate reduction on nuScenes and 89.4 PDMS (rule-cost variant) on NAVSIM, with ablations attributing gains primarily to the cost pathway and qualitative results showing style-aligned cost-map variations.
Significance. If the experimental claims hold under full scrutiny, the work demonstrates a modular, host-agnostic way to improve controllability and safety metrics in LWM-based planners without retraining backbones. The frozen-host protocol and dual fusion interfaces are strengths that isolate the bridge contribution and support style modulation.
major comments (3)
- [Experiments] Experiments section: the reported gains (0.55 m avg L2, 42 % collision reduction on nuScenes; 89.4 PDMS on NAVSIM) are presented without error bars, run-to-run variance, or statistical significance tests, leaving open whether the improvements exceed baseline variability.
- [Methods] Methods / latent-representation analysis: the central claim that the latent already encodes sufficient disentangled risk/drivability/style information for a four-channel cost map to be decoded and fused upstream is load-bearing, yet no probing, mutual-information analysis, or controlled visualization of the latent factors is described to substantiate disentanglement versus post-hoc mapping.
- [Ablations] Ablation studies: while the text states that ablations show the cost pathway contributes most to safer selection, no table or quantitative deltas are supplied for the individual components (style conditioning, four-channel decoding, fusion type), preventing verification that the bridge—not ancillary changes—drives the reported metrics.
minor comments (1)
- [Abstract] Abstract: the phrase 'spatially consistent variations aligned to different driving styles' is used without defining a quantitative measure of consistency or diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental reporting, latent analysis, and ablation details. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: Experiments section: the reported gains (0.55 m avg L2, 42 % collision reduction on nuScenes; 89.4 PDMS on NAVSIM) are presented without error bars, run-to-run variance, or statistical significance tests, leaving open whether the improvements exceed baseline variability.
Authors: We agree that the absence of error bars, variance across runs, and statistical tests limits the strength of the claims. In the revised manuscript we will report results from multiple independent training and evaluation runs, include standard deviations, and add statistical significance tests (e.g., paired t-tests) to confirm that the observed improvements exceed baseline variability. revision: yes
-
Referee: Methods / latent-representation analysis: the central claim that the latent already encodes sufficient disentangled risk/drivability/style information for a four-channel cost map to be decoded and fused upstream is load-bearing, yet no probing, mutual-information analysis, or controlled visualization of the latent factors is described to substantiate disentanglement versus post-hoc mapping.
Authors: We acknowledge that additional analysis is needed to substantiate the claim of sufficient disentangled information in the latent space. While the downstream performance and qualitative cost-map variations provide supporting evidence, we will add probing experiments, including controlled visualizations of latent factors and mutual-information estimates between latent dimensions and risk/drivability/style attributes, in the revised version. revision: yes
-
Referee: Ablation studies: while the text states that ablations show the cost pathway contributes most to safer selection, no table or quantitative deltas are supplied for the individual components (style conditioning, four-channel decoding, fusion type), preventing verification that the bridge—not ancillary changes—drives the reported metrics.
Authors: We agree that a quantitative ablation table with explicit deltas for each component is necessary for verification. We will expand the ablation section in the revised manuscript to include a detailed table reporting metrics for ablations of style conditioning, channel count, and fusion type, with clear quantitative comparisons to the full model. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript describes PLAN-S as an auxiliary decoding bridge that produces a style-conditioned four-channel cost map from a frozen latent world model and fuses it upstream of two distinct host planners (ResWorld, WoTE) whose backbones remain frozen. No equations, parameter-fitting steps, or self-citation chains are supplied that would reduce the reported L2, collision-rate, or PDMS gains to quantities defined by the same fitted values. The isolation claim rests on external benchmark numbers rather than internal redefinition, satisfying the criteria for a self-contained empirical addition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latent representations produced by existing world models already contain sufficient information about driving style, risk, and drivability to be decoded into a useful four-channel semantic cost map.
invented entities (1)
-
PLAN-S bridge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Occworld: Learning a 3d occupancy world model for autonomous driving,
W. Zheng, W. Chen, Y . Huang, B. Zhang, Y . Duan, and J. Lu, “Occworld: Learning a 3d occupancy world model for autonomous driving,” in European conference on computer vision. Springer, 2024, pp. 55–72
2024
-
[2]
Driveworld: 4d pre-trained scene understanding via world models for autonomous driving,
C. Min, D. Zhao, L. Xiao, J. Zhao, X. Xu, Z. Zhu, L. Jin, J. Li, Y . Guo, J. Xinget al., “Driveworld: 4d pre-trained scene understanding via world models for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 15 522–15 533
2024
-
[3]
Bevworld: A multimodal world model for autonomous driving via unified bev latent space,
Y . Zhang, S. Gong, K. Xiong, X. Ye, X. Tan, F. Wang, J. Huang, H. Wu, and H. Wang, “Bevworld: A multimodal world model for autonomous driving via unified bev latent space,”arXiv preprint arXiv:2407.05679, 2024
-
[4]
Resworld: Temporal residual world model for end-to-end autonomous driving,
J. Zhang, Z. Fu, Q. Liu, Y . Wanget al., “Resworld: Temporal residual world model for end-to-end autonomous driving,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[6]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8340–8350
2023
-
[7]
Genad: Generative end-to-end autonomous driving,
W. Zheng, R. Song, X. Guo, C. Zhang, and L. Chen, “Genad: Generative end-to-end autonomous driving,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 87–104
2024
-
[8]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu et al., “Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation,”arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhanget al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 037–12 047
2025
-
[10]
End-to-end driving with online trajectory evaluation via bev world model,
Y . Li, Y . Wang, Y . Liu, J. He, L. Fan, and Z. Zhang, “End-to-end driving with online trajectory evaluation via bev world model,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 27 137–27 146. SUBMITTED TO IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS 11
2025
-
[11]
Styledrive: Towards driving-style aware benchmarking of end-to-end autonomous driving,
R. Hao, B. Jing, H. Yu, and Z. Nie, “Styledrive: Towards driving-style aware benchmarking of end-to-end autonomous driving,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 6, 2026, pp. 4627–4635
2026
-
[12]
X. Dong, R. Li, X. Han, Z. Wu, J. Wang, J. Chen, Q. Jiang, S. Yiu, X. Zhu, and Y . Ma, “Driving with a thousand faces: A benchmark for closed-loop personalized end-to-end autonomous driving,”arXiv preprint arXiv:2602.18757, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Drive my way: Preference alignment of vision-language-action model for personalized driving,
Z. Wang, H. Jiang, S. Dong, Y . Wang, H. Qiu, and J. Li, “Drive my way: Preference alignment of vision-language-action model for personalized driving,”arXiv preprint arXiv:2603.25740, 2026
-
[14]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI Conference on Artificial Intelligence, 2018
2018
-
[15]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[16]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavoneet al., “Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 28 706– 28 719, 2024
2024
-
[17]
Model-based imitation learning for urban driving,
A. Hu, G. Corrado, N. Griffiths, Z. Murez, C. Gurau, H. Yeo, A. Kendall, R. Cipolla, and J. Shotton, “Model-based imitation learning for urban driving,”Advances in Neural Information Processing Systems, vol. 35, pp. 20 703–20 716, 2022
2022
-
[18]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4195–4205
2023
-
[19]
GAIA-1: A Generative World Model for Autonomous Driving
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado, “Gaia-1: A generative world model for autonomous driving,”arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving,
Y . Wang, J. He, L. Fan, H. Li, Y . Chen, and Z. Zhang, “Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 14 749–14 759
2024
-
[21]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inEuropean conference on computer vision. Springer, 2020, pp. 194–210
2020
-
[22]
Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2020–2036, 2024
2020
-
[23]
Bevdepth: Acquisition of reliable depth for multi-view 3d object de- tection,
Y . Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y . Shi, J. Sun, and Z. Li, “Bevdepth: Acquisition of reliable depth for multi-view 3d object de- tection,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 2, 2023, pp. 1477–1485
2023
-
[24]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline,
P. Wu, X. Jia, L. Chen, J. Yan, H. Li, and Y . Qiao, “Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[25]
Goalflow: Goal-driven flow matching for multimodal trajec- tories generation in end-to-end autonomous driving,
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin, “Goalflow: Goal-driven flow matching for multimodal trajec- tories generation in end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1602–1611
2025
-
[26]
Sparsedrive: End-to-end autonomous driving via sparse scene representation,
W. Sun, X. Lin, Y . Shi, C. Zhang, H. Wu, and S. Zheng, “Sparsedrive: End-to-end autonomous driving via sparse scene representation,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 8795–8801
2025
-
[27]
Parting with misconceptions about learning-based vehicle motion planning,
D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta, “Parting with misconceptions about learning-based vehicle motion planning,” inCon- ference on Robot Learning. PMLR, 2023, pp. 1268–1281
2023
-
[28]
Mp3: A unified model to map, perceive, predict and plan,
S. Casas, A. Sadat, and R. Urtasun, “Mp3: A unified model to map, perceive, predict and plan,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 403–14 412
2021
-
[29]
End-to-end interpretable neural motion planner,
W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Urtasun, “End-to-end interpretable neural motion planner,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8660–8669
2019
-
[30]
St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning,
S. Hu, L. Chen, P. Wu, H. Li, J. Yan, and D. Tao, “St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 533– 549
2022
-
[31]
Learning to navigate intersections with unsupervised driver trait infer- ence,
S. Liu, P. Chang, H. Chen, N. Chakraborty, and K. Driggs-Campbell, “Learning to navigate intersections with unsupervised driver trait infer- ence,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 3576–3582
2022
-
[32]
V ADv2: End-to-end vectorized autonomous driving via probabilistic planning,
B. Jiang, S. Chen, H. Gao, B. Liao, Q. Zhang, W. Liu, and X. Wang, “V ADv2: End-to-end vectorized autonomous driving via probabilistic planning,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[33]
Is ego status all you need for open-loop end-to-end autonomous driving?
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez, “Is ego status all you need for open-loop end-to-end autonomous driving?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 864–14 873
2024
-
[34]
Scene as occupancy,
W. Tong, C. Sima, T. Wang, L. Chen, S. Wu, H. Deng, Y . Gu, L. Lu, P. Luo, D. Linet al., “Scene as occupancy,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8406–8415
2023
-
[35]
Para- drive: Parallelized architecture for real-time autonomous driving,
X. Weng, B. Ivanovic, Y . Wang, Y . Wang, and M. Pavone, “Para- drive: Parallelized architecture for real-time autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 449–15 458
2024
-
[36]
Navigation-guided sparse scene representation for end-to-end autonomous driving,
P. Li and D. Cui, “Navigation-guided sparse scene representation for end-to-end autonomous driving,”arXiv preprint arXiv:2409.18341, 2024
-
[37]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022
2022
-
[38]
Enhancing end-to-end autonomous driving with latent world model,
Y . Li, L. Fan, J. He, Y . Wang, Y . Chen, Z. Zhang, and T. Tan, “Enhancing end-to-end autonomous driving with latent world model,” in The Thirteenth International Conference on Learning Representations, 2025
2025
-
[39]
Drama: An efficient end-to-end motion planner for autonomous driving with mamba,
C. Yuan, Z. Zhang, J. Sun, S. Sun, Z. Huang, C. D. W. Lee, D. Li, Y . Han, A. Wong, K. P. Teeet al., “Drama: An efficient end-to-end motion planner for autonomous driving with mamba,”arXiv preprint arXiv:2408.03601, 2024
-
[40]
Geobev: Learn- ing geometric bev representation for multi-view 3d object detection,
J. Zhang, Y . Zhang, Y . Qi, Z. Fu, Q. Liu, and Y . Wang, “Geobev: Learn- ing geometric bev representation for multi-view 3d object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9960–9968
2025
-
[41]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019. Xiaoyun Qiureceived the B.S. and M.S. degrees in transportation engineering from Harbin Institute of Technology, Harbin, China, in 2019 and 2021, respectively. She is currently working toward the Ph.D. degree in intelligent t...
2019
-
[42]
degree in Intelligent Trans- portation from the Hong Kong University of Science and Technology (Guangzhou) in 2024, where he is currently pursuing the Ph.D
He received M.S. degree in Intelligent Trans- portation from the Hong Kong University of Science and Technology (Guangzhou) in 2024, where he is currently pursuing the Ph.D. degree with the Intel- ligent Transportation Thrust. His current research interests include autonomous driving, cooperative perception and prediction, and intelligent transporta- tion...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.