EGTR-Review: Efficient Evidence-Grounded Scientific Peer Review Generation via Multi-Agent Teacher Distillation
Pith reviewed 2026-06-28 01:44 UTC · model grok-4.3
The pith
A lightweight student model distilled from a multi-agent teacher generates evidence-grounded peer reviews with better quality and lower cost than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
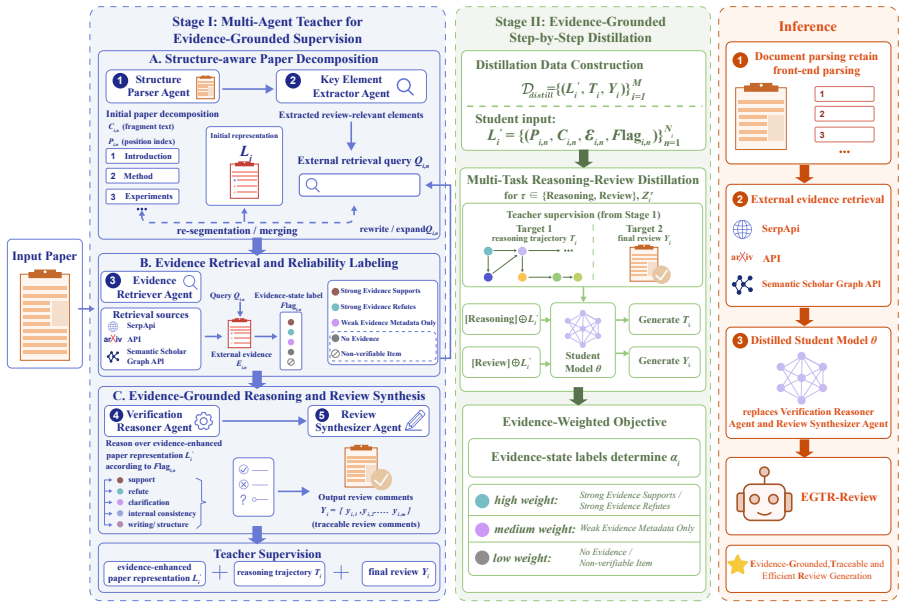
EGTR-Review builds a multi-agent teacher that executes structure-aware paper decomposition, key-element extraction, external scholarly evidence retrieval, evidence-state labeling, verification reasoning, and review synthesis. Both the teacher's intermediate trajectories and final comments are then distilled into a student model via task-prefix-driven multi-task learning, with an evidence-weighted objective that down-weights unverifiable supervision. The resulting student model surpasses prompt-based, fine-tuned, and structured agentic baselines on automatic metrics, LLM-as-judge scores, and human evaluation while preserving factual grounding, source traceability, and substantially lower toke
What carries the argument
Multi-agent teacher distillation through task-prefix-driven multi-task learning combined with an evidence-weighted training objective.
If this is right
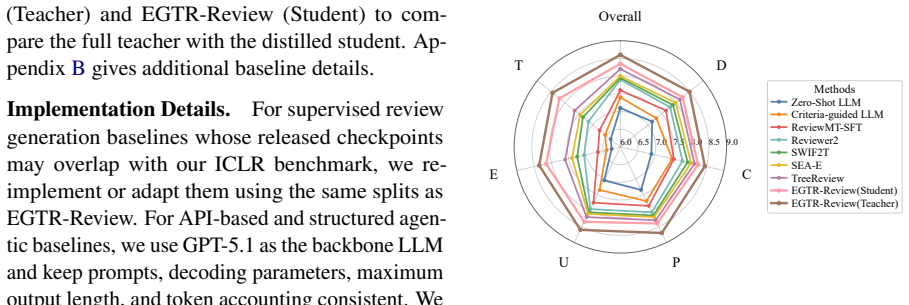
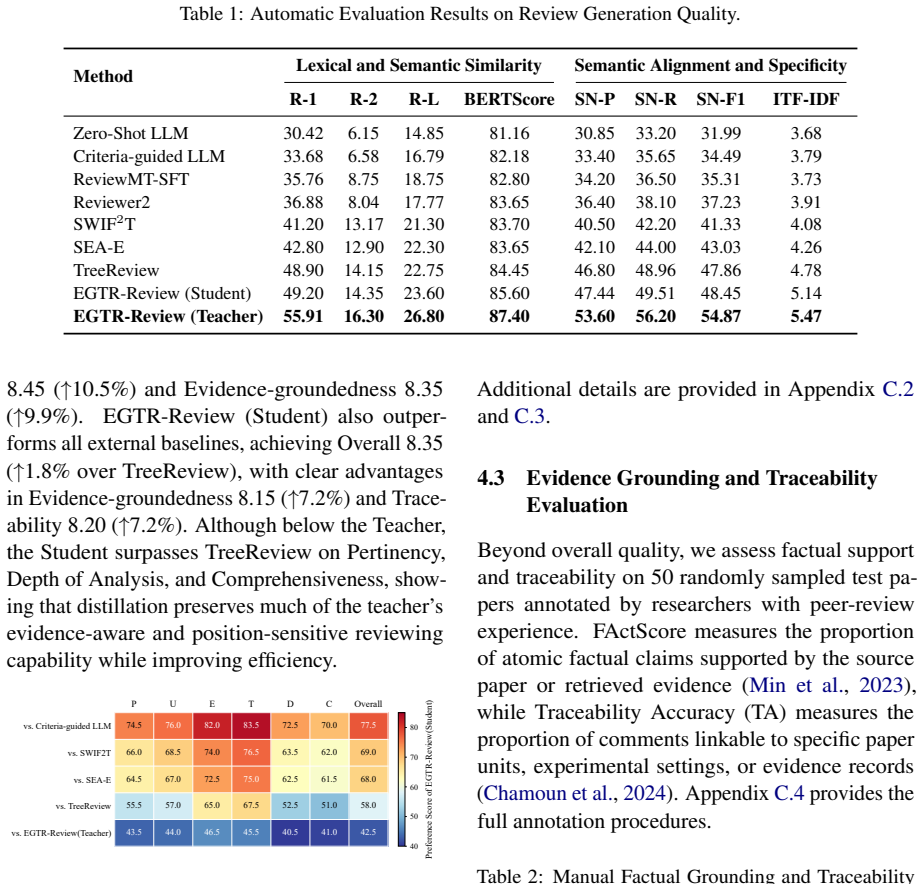
- The student model records higher automatic metric scores, LLM-as-judge ratings, and human preferences than prompt-based, fine-tuned, and agentic baselines.
- Generated reviews retain strong factual grounding and explicit source traceability.
- Token consumption and inference latency drop substantially relative to the teacher system.
Where Pith is reading between the lines
- The same teacher-to-student transfer pattern could be tested on other long-document generation tasks that require external evidence, such as grant proposal feedback or survey article drafting.
- If the evidence-retrieval step generalizes across disciplines, the approach could reduce review delays in fields with smaller reviewer pools.
- Deployment on edge hardware becomes feasible once the student size is confirmed, allowing real-time review assistance during manuscript drafting.
Load-bearing premise
The multi-agent teacher's reasoning steps and reviews supply high-quality verifiable supervision that a student model can absorb without major loss of grounding or traceability.
What would settle it
An evaluation on held-out papers where the distilled student produces measurably weaker evidence support or traceability scores than the full teacher or the best baseline while still consuming fewer tokens.
Figures









read the original abstract
Scientific peer review generation has attracted increasing attention for reducing reviewing burdens and providing timely feedback. However, existing Large Language Model (LLM)-based methods often produce generic comments with insufficient evidence support and weak source traceability, while complex multi-agent systems incur high inference costs. To address these challenges, we propose EGTR-Review, an Evidence-Grounded and Traceable Review Generation framework via Multi-Agent Teacher Distillation. EGTR-Review first constructs a multi-agent teacher that performs structure-aware paper decomposition, key-element extraction, external scholarly evidence retrieval, evidence-state labeling, verification reasoning, and review synthesis. It then distills both intermediate reasoning trajectories and final review comments into a lightweight student model through task-prefix-driven multi-task learning. An evidence-weighted objective further reduces the influence of weak, missing, or non-verifiable supervision. Experiments on public peer-review datasets show that EGTR-Review (Student) outperforms strong prompt-based, fine-tuned, and structured/agentic baselines across automatic metrics, LLM-as-Judge evaluation, and human evaluation, while maintaining strong factual grounding and source traceability with substantially lower token consumption and inference time. Our code, prompts, configurations, and sample data are available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EGTR-Review, an Evidence-Grounded and Traceable Review Generation framework via Multi-Agent Teacher Distillation. A multi-agent teacher performs structure-aware paper decomposition, key-element extraction, external scholarly evidence retrieval, evidence-state labeling, verification reasoning, and review synthesis; these trajectories and final reviews are then distilled into a lightweight student model via task-prefix-driven multi-task learning with an evidence-weighted objective to mitigate weak supervision. Experiments on public peer-review datasets claim that the student outperforms prompt-based, fine-tuned, and structured/agentic baselines on automatic metrics, LLM-as-Judge, and human evaluation while preserving factual grounding, source traceability, and substantially lower token consumption and inference time.
Significance. If the empirical results hold after validation of the teacher trajectories, the work demonstrates a viable path to efficient, evidence-grounded review generation that avoids the generic outputs of single-prompt LLMs and the high inference costs of full multi-agent systems. The evidence-weighted distillation objective is a potentially reusable technique for transferring complex reasoning supervision.
major comments (2)
- [Abstract] The central claim that the distilled student maintains strong factual grounding and source traceability rests on the assumption that the multi-agent teacher's structure-aware decomposition, evidence-state labeling, and verification reasoning produce high-quality, verifiable trajectories. No quantitative validation of teacher output quality (e.g., error rates on labeling or verification steps, or inter-annotator agreement) is reported.
- [Experiments] The abstract states that the student outperforms baselines across automatic metrics, LLM-as-Judge, and human evaluation, yet provides no details on dataset splits, exact baseline implementations, metric definitions, or ablations (particularly the contribution of the evidence-weighted term). Without these, the load-bearing outperformance and grounding claims cannot be assessed.
minor comments (1)
- The availability of code, prompts, configurations, and sample data on GitHub is noted and supports reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating planned revisions where appropriate. Our responses focus on clarifying the manuscript's content and strengthening the presentation of results.
read point-by-point responses
-
Referee: [Abstract] The central claim that the distilled student maintains strong factual grounding and source traceability rests on the assumption that the multi-agent teacher's structure-aware decomposition, evidence-state labeling, and verification reasoning produce high-quality, verifiable trajectories. No quantitative validation of teacher output quality (e.g., error rates on labeling or verification steps, or inter-annotator agreement) is reported.
Authors: We agree that direct quantitative validation of the teacher trajectories would provide stronger support for the grounding claims. The current manuscript relies on the student's downstream performance as an indirect measure of trajectory quality. In revision, we will add a dedicated subsection reporting error rates on evidence-state labeling and verification reasoning steps (computed via automated consistency checks against source papers where possible) and any available agreement metrics from the multi-agent process. revision: yes
-
Referee: [Experiments] The abstract states that the student outperforms baselines across automatic metrics, LLM-as-Judge, and human evaluation, yet provides no details on dataset splits, exact baseline implementations, metric definitions, or ablations (particularly the contribution of the evidence-weighted term). Without these, the load-bearing outperformance and grounding claims cannot be assessed.
Authors: The full manuscript contains dataset split information, baseline descriptions, and metric definitions in Section 4. However, we acknowledge that more explicit reporting and ablations are needed for full reproducibility and to isolate the evidence-weighted objective. In the revision we will expand the Experiments section with precise split ratios, implementation details for all baselines, formal metric definitions, and additional ablation results specifically measuring the contribution of the evidence-weighted loss term. revision: yes
Circularity Check
No circularity; empirical claims on public data with no derivations or self-referential reductions
full rationale
The manuscript presents an engineering framework (multi-agent teacher construction followed by distillation into a student model) evaluated on public peer-review datasets against external baselines. No equations, parameter fits, or derivations appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The performance claims rest on standard automatic metrics, LLM-as-judge, and human evaluation rather than any internal reduction to fitted inputs or prior author work. This is the normal case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Surv., 52(6)
Academic plagiarism detection: A systematic literature review.ACM Comput. Surv., 52(6). Zhaolin Gao, Kianté Brantley, and Thorsten Joachims
-
[2]
Palash Goyal, Mihir Parmar, Yiwen Song, Hamid Palangi, Tomas Pfister, and Jinsung Yoon
Reviewer2: Optimizing review gen- eration through prompt generation.Preprint, arXiv:2402.10886. Palash Goyal, Mihir Parmar, Yiwen Song, Hamid Palangi, Tomas Pfister, and Jinsung Yoon. 2026. Scholarpeer: A context-aware multi-agent frame- work for automated peer review.Preprint, arXiv:2601.22638. Cheng-Yu Hsieh, Chun-Liang Li, Chih-kuan Yeh, Hootan Nakhost...
arXiv 2026
-
[3]
Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wen- wen Gong, Shu Zhao, Peng Zhang, and Jie Tang
Peer review as a multi-turn and long-context dialogue with role-based interactions.Preprint, arXiv:2406.05688. Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wen- wen Gong, Shu Zhao, Peng Zhang, and Jie Tang
-
[4]
GKD: A general knowledge distillation frame- work for large-scale pre-trained language model. In Proceedings of the 61st Annual Meeting of the As- sociation for Computational Linguistics (V olume 5: Industry Track), pages 134–148, Toronto, Canada. Association for Computational Linguistics. Wei Wang, Zhaowei Li, Qi Xu, YiQing Cai, Hang Song, Qi Qi, Ran Zho...
Pith/arXiv arXiv 2025
-
[5]
Paper Information Title: [paper title] Abstract: [paper abstract] Main text: [paper content or selected full-paper text]
-
[6]
Review A [anonymized review generated by one system]
-
[7]
Review B [anonymized review generated by the other system]
-
[8]
For each dimension, choose one of the following options: (a) Review A is better; (b) Review B is better; (c) Tie
Instruction Please compare Review A and Review B based on the paper content. For each dimension, choose one of the following options: (a) Review A is better; (b) Review B is better; (c) Tie
-
[9]
Pertinency
Evaluation Dimensions Q1. Pertinency. Which review is more focused on the specific problems of the target paper, rather than providing generic comments? Q2. Usefulness. Which review provides more actionable and helpful suggestions for improving the paper? Q3. Evidence-groundedness. Which review is better supported by the paper content, experimental result...
-
[10]
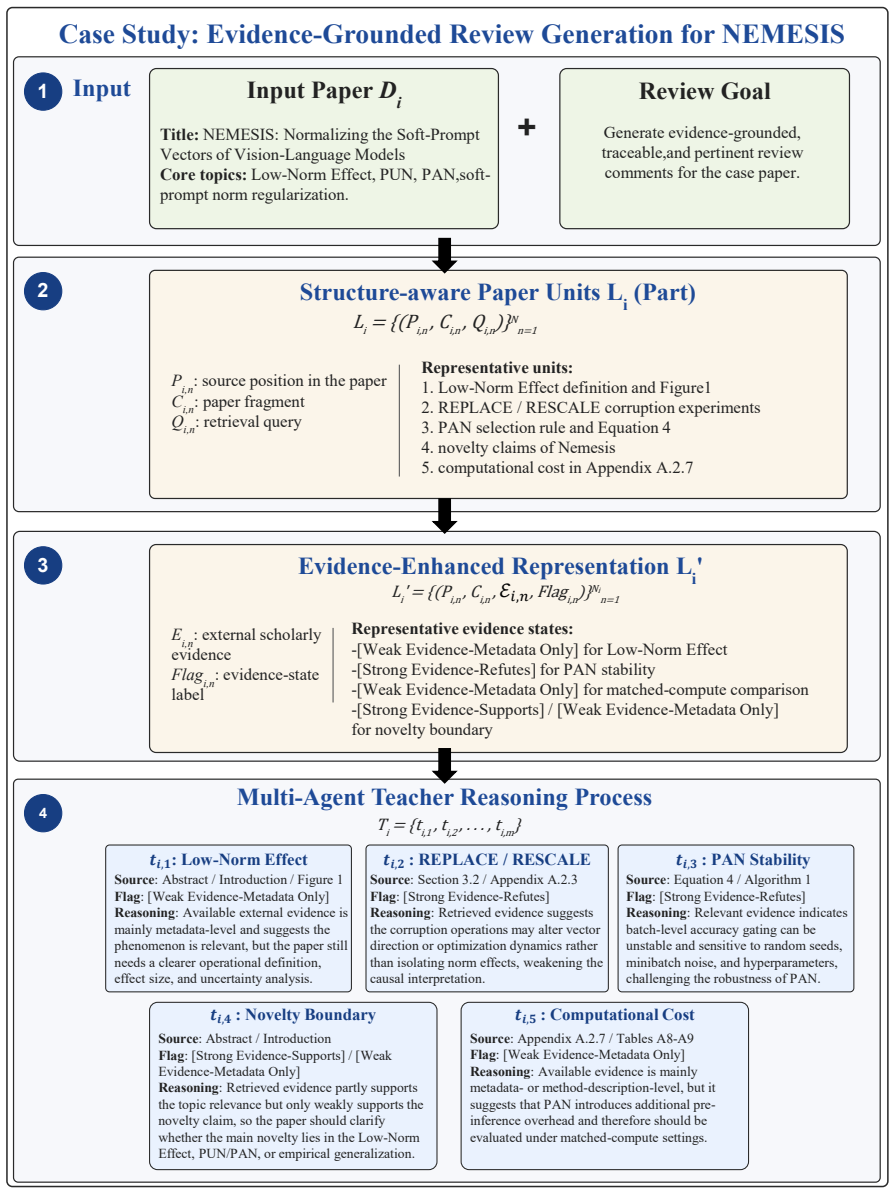
Low-Norm Effect definition and Figure1
-
[11]
REPLACE / RESCALE corruption experiments
-
[12]
PAN selection rule and Equation 4
-
[13]
novelty claims of Nemesis
-
[14]
Low-Norm Effect
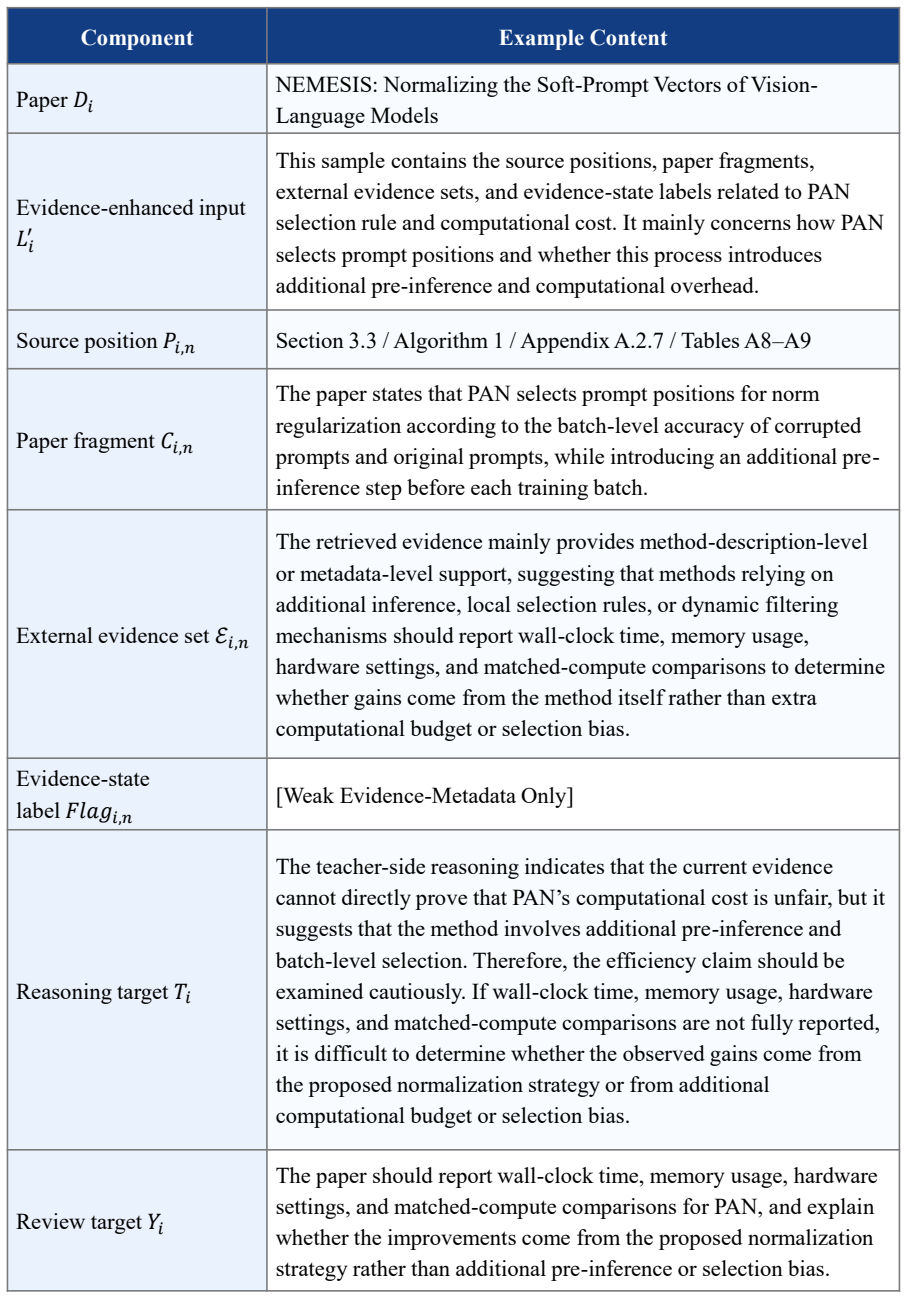
computational cost in Appendix A.2.7 3 Evidence-Enhanced Representation Li' Li' = {(Pi,n , Ci,n , ℰ𝑖,𝑛, Flagi,n)}Ni n=1 Ei,n: external scholarly evidence Flagi,n: evidence-state label Representative evidence states: -[Weak Evidence-Metadata Only] for Low-Norm Effect -[Strong Evidence-Refutes] for PAN stability -[Weak Evidence-Metadata Only] for matched-co...
-
[15]
Identify the hierarchical structure of 𝐷𝑖, including but not limited to Abstract, Introduction, Related Work, Method, Approach, Experiments, Results, Analysis, Ablation Study, Discussion, Limitations, Conclusion, Appendix, figures, tables, formulas, algorithms, and captions
-
[16]
Each fragment should be semantically coherent, relatively self-contained, and suitable for downstream key-element extraction, evidence retrieval, and verification reasoning
Segment 𝐷𝑖 into paper fragments 𝐶𝑖,𝑛. Each fragment should be semantically coherent, relatively self-contained, and suitable for downstream key-element extraction, evidence retrieval, and verification reasoning. Avoid fragments that are too long to support precise localization or too short to preserve necessary context
-
[17]
Assign a precise position index 𝑃𝑖,𝑛 to each fragment 𝐶𝑖,𝑛. The position index should record where the fragment appears in the original paper, such as section title, subsection title, paragraph number, figure number, table number, formula number, algorithm number, caption, or appendix location
-
[18]
Preserve all information that may be relevant to scientific peer review, including research problems, motivations, methodological descriptions, assumptions, experimental settings, datasets, evaluation metrics, baselines, result claims, ablation studies, error analysis, limitations, citations, formulas, tables, figures, and captions
-
[19]
Do not remove fragments simply because they appear descriptive. Descriptive fragments may still be useful for downstream reasoning, especially when they contain assumptions, experimental settings, claims, implementation details, or methodological explanations
-
[20]
Need further splitting
If a fragment contains multiple independent claims, mark it as “Need further splitting” and provide a suggested split. If a fragment is too short or lacks semantic completeness, mark it as “Need merging” and identify the neighboring fragment with which it should be merged. Otherwise, mark it as “Keep”. Your output should contain the following fields for e...
-
[21]
Read the fragment 𝐶𝑖,𝑛 together with its position index 𝑃𝑖,𝑛
-
[22]
Identify review-relevant key elements in 𝐶𝑖,𝑛 including research questions, task settings, methodological designs, model architectures, algorithms, assumptions, datasets, evaluation metrics, baselines, experimental settings, result claims, ablation claims, comparative claims, citation evidence, and stated limitations
-
[23]
Distinguish between the following types of information:Factual Claim;Methodological Claim;Experimental Claim;Result Claim;Com parative Claim;Citation Claim;Presentation-related Statement;Non-verifiable Statement
-
[24]
Generate an external retrieval query 𝑄𝑖,𝑛 for the paper unit. The query should be concise but informative, and should contain key meth od names, dataset names, task scenarios, evaluation metrics, cited works, technical terms, and central claim terms when available
-
[25]
Ensure that 𝑄𝑖,𝑛 is directly grounded in 𝐶𝑖,𝑛 Do not add concepts, methods, datasets, citations, or claims that do not appear in the curre nt fragment
-
[26]
If 𝐶𝑖,𝑛 contains multiple independent claims that cannot be verified together, provide feedback to the Structure Parser Agent and reque st re-segmentation
-
[27]
unit_id":
If 𝐶𝑖,𝑛 is too short, lacks complete semantic boundaries, or cannot support meaningful key-element extraction and evidence retrieval, p rovide feedback to the Structure Parser Agent and request merging with a neighboring fragment. Your output should contain the following fields for each paper unit: ·Paper Unit ID: 𝑛 · Position Index:𝑃𝑖,𝑛 · Fragment Text:𝐶...
-
[28]
•[ Strong Evidence–Supports]: check whether ℰ𝑖,𝑛supports the claim in 𝐶𝑖,𝑛
-
[29]
•[ Strong Evidence–Refutes]: identify the conflict between 𝐶𝑖,𝑛and ℰ𝑖,𝑛
-
[30]
unit_id":
•[ Weak Evidence–Metadata Only]: conduct cautious weak-evidence probing. 6.• [No Evidence]: rely on paper-internal grounding from 𝐶𝑖,𝑛and surrounding context. 7.• [Non-verifiable Item]: assess writing, structure, readability, clarity, or presentation quality. 8.Generate preliminary review points only when they are grounded in at least one of the following...
-
[31]
Please carefully read the paper and the generated review
One generated review for this paper. Please carefully read the paper and the generated review. Then evaluate the generated review along the following seven dimensions. Use a score from 1 to 10 for each dimension, where 1 means very poor and 10 means excellent. Evaluation Dimensions:
-
[32]
Pertinency Assess whether the review focuses on the specific issues of the target paper rather than giving generic comments. A high score means that the review discusses concrete aspects of the paper, such as the research problem, method design, experimental setting, results, claims, limitations, or argumentation weaknesses
-
[33]
A high score means that the review not only identifies problems, but also explains why they matter and gives concrete suggestions for revision or improvement
Usefulness Assess whether the review provides helpful and actionable feedback for the authors. A high score means that the review not only identifies problems, but also explains why they matter and gives concrete suggestions for revision or improvement
-
[34]
A high score means that the review avoids unsupported subjective claims and makes judgments that can be linked to identifiable evidence
Evidence-groundedness Assess whether the review is grounded in the paper content, experimental results, methodological details, or external scholarly evidence when available. A high score means that the review avoids unsupported subjective claims and makes judgments that can be linked to identifiable evidence
-
[35]
A high score means that the authors can clearly locate the source of the issue mentioned in the review
Traceability Assess whether the review comments can be traced back to specific parts of the paper, such as sections, paragraphs, figures, tables, formulas, experimental settings, datasets, metrics, results, or technical details. A high score means that the authors can clearly locate the source of the issue mentioned in the review
-
[36]
A high score means that the review identifies substantive technical issues rather than only surface-level writing or formatting problems
Depth of Analysis Assess whether the review shows a deep understanding of the paper’s technical content, methodological design, experimental logic, and related research context. A high score means that the review identifies substantive technical issues rather than only surface-level writing or formatting problems
-
[37]
A high score means that the review provides a balanced and sufficiently complete evaluation
Comprehensiveness Assess whether the review covers the main aspects expected in a scientific peer review, including summary, strengths, weaknesses, methodological soundness, experimental adequacy, clarity, limitations, and possible improvements. A high score means that the review provides a balanced and sufficiently complete evaluation
-
[38]
A high score means that the review is paper-specific, useful, evidence-grounded, traceable, technically deep, and comprehensive
Overall Assess the overall quality of the generated review by considering all the above dimensions together. A high score means that the review is paper-specific, useful, evidence-grounded, traceable, technically deep, and comprehensive. Important Requirements: • Do not judge the paper itself; judge only the quality of the generated review. • Do not rewar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.