Learning Visual Spatial Planning from Symbolic State via Modality-Gap-Aware Self-Distillation
Pith reviewed 2026-06-28 01:53 UTC · model grok-4.3
The pith
A two-stage self-distillation process transfers planning skill from symbolic states to visual inputs while keeping inference purely visual.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
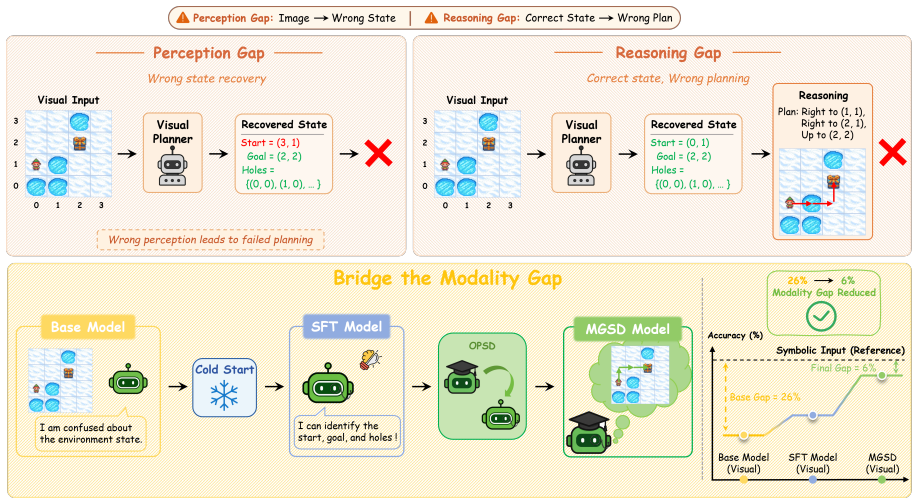
On-policy distillation from a privileged symbolic teacher, applied after a cold-start grounding stage and using the visual student's own rollout prefixes as context, equips a purely visual model with both more reliable state recovery and stronger optimal-path reasoning, narrowing the gap to symbolic-input upper bounds on visual planning tasks.
What carries the argument
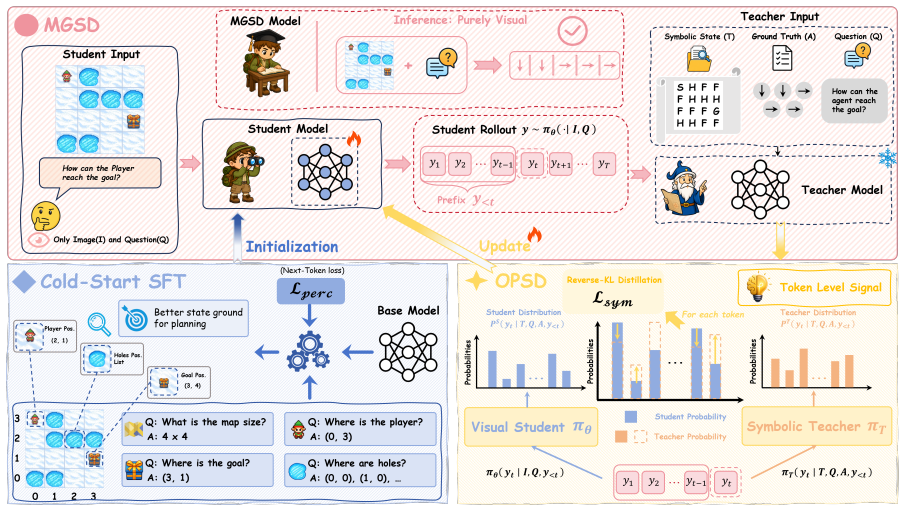
MGSD, a two-stage modality-gap-aware self-distillation framework whose second stage performs on-policy distillation from explicit symbolic states onto the student's visual rollout prefixes.
If this is right
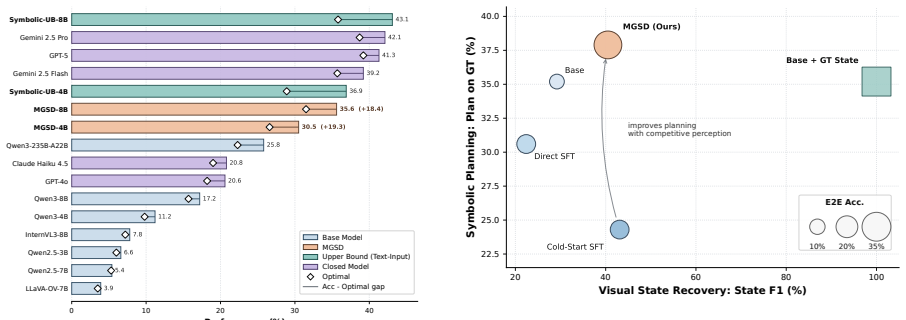
- Visual planning accuracy rises consistently across model scales, with macro-average gains of 19.3 percent for 4B and 18.4 percent for 8B backbones.
- The distilled models close a substantial portion of the performance difference to models that receive symbolic states as input.
- Ablation results attribute the improvement to joint gains in visual state recovery and in reasoning over the recovered structure.
- Symbolic supervision is used only during training; inference remains strictly visual.
Where Pith is reading between the lines
- The same staged distillation pattern could be tested on other tasks that require recovering structure from pixels before performing sequential decisions.
- If the transfer holds, planners could be trained in simulation with privileged state access and then deployed on raw camera input.
- Longer-horizon planning benchmarks would provide a direct test of whether the recovered reasoning generalizes beyond the training distribution.
Load-bearing premise
Supervising the visual student with a symbolic teacher on the student's own visual rollout prefixes will transfer multi-step planning capability to the visual model.
What would settle it
Running the trained visual model on the same benchmark tasks and finding that its success rate remains far below the symbolic-input upper bound even after the full MGSD procedure.
Figures
read the original abstract
While vision-language models excel at general multimodal understanding, they still struggle with visual spatial planning. We attribute this to a perception-reasoning modality gap: visual planning requires models to infer latent state structures from pixels and then reason over the recovered structure to produce valid actions, whereas symbolic planning directly leverages explicit objects and constraints. This creates dual bottlenecks in visual state recovery and multi-step planning. To address this, we propose MGSD, a two-stage modality-gap-aware self-distillation framework. First, a cold-start grounding stage equips the visual student with reliable state representations, minimizing early perception noise. Second, a privileged teacher transfers planning capabilities via on-policy distillation, using explicit symbolic states to supervise the student's own visual rollout prefixes. Crucially, symbolic data is used strictly during training, leaving inference purely visual. Experiments on visual planning benchmarks show that MGSD consistently improves visual planning across both 4B and 8B backbones, raising the macro average by 19.3% and 18.4%, respectively. The resulting models narrow the gap to symbolic-input upper bounds, while ablations and diagnostics confirm that the improvement comes from both visual state recovery and optimal-path reasoning. These results suggest that modality-gap-aware self-distillation improves not only how models perceive actionable states, but also how they plan over the inferred structure. Code is available at https://github.com/Oranger-l/MGSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MGSD, a two-stage modality-gap-aware self-distillation framework to improve visual spatial planning in vision-language models. Stage 1 performs cold-start grounding to equip the visual student with reliable state representations; stage 2 performs on-policy distillation in which a privileged symbolic teacher supervises the student's own visual rollout prefixes. The abstract reports that this yields macro-average gains of 19.3% (4B) and 18.4% (8B) on visual planning benchmarks, narrows the gap to symbolic-input upper bounds, and that ablations attribute the gains to both visual state recovery and optimal-path reasoning. Symbolic data is used only at training time.
Significance. If the empirical claims hold, the work would be significant for demonstrating a practical route to transfer multi-step planning capability across the perception-reasoning modality gap without requiring symbolic input at inference. The public release of code is a clear strength that supports reproducibility.
major comments (2)
- [MGSD framework (second stage)] The central claim that stage-2 distillation teaches optimal-path reasoning (rather than merely improving perception) rests on the premise that stage-1 grounding already produces visual rollout prefixes sufficiently close to the symbolic trajectory distribution. No quantitative state-recovery metric is supplied for the actual prefixes used in distillation, nor is any description given of how rollouts are generated or filtered. This is load-bearing for the ablation claim that gains arise from both recovery and reasoning.
- [Experiments] The abstract asserts quantitative gains and ablations on visual planning benchmarks, yet supplies no details on experimental protocols, baseline implementations, statistical tests, data splits, or rollout generation. Without these, the reported 19.3% / 18.4% macro-average improvements cannot be independently verified and constitute the primary evidence for the method's effectiveness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional detail would strengthen the paper. We agree with both major points and will revise the manuscript to address them directly.
read point-by-point responses
-
Referee: [MGSD framework (second stage)] The central claim that stage-2 distillation teaches optimal-path reasoning (rather than merely improving perception) rests on the premise that stage-1 grounding already produces visual rollout prefixes sufficiently close to the symbolic trajectory distribution. No quantitative state-recovery metric is supplied for the actual prefixes used in distillation, nor is any description given of how rollouts are generated or filtered. This is load-bearing for the ablation claim that gains arise from both recovery and reasoning.
Authors: We agree that the current manuscript lacks quantitative state-recovery metrics on the specific visual rollout prefixes used during stage-2 distillation and does not describe rollout generation or filtering procedures. These details are necessary to support the claim that improvements stem from both state recovery and optimal-path reasoning. In the revision we will add (1) state-recovery accuracy metrics computed on the actual prefixes fed to the teacher, (2) a precise description of how rollouts are generated (including policy, horizon, and sampling), and (3) any filtering criteria applied. This will allow readers to evaluate the premise of the ablation analysis. revision: yes
-
Referee: [Experiments] The abstract asserts quantitative gains and ablations on visual planning benchmarks, yet supplies no details on experimental protocols, baseline implementations, statistical tests, data splits, or rollout generation. Without these, the reported 19.3% / 18.4% macro-average improvements cannot be independently verified and constitute the primary evidence for the method's effectiveness.
Authors: We concur that the manuscript currently omits the experimental details required for reproducibility and verification of the reported gains. In the revised version we will expand the Experiments section to include: full experimental protocols, exact baseline implementations and hyper-parameters, statistical tests performed, data splits, and the complete procedure for rollout generation (including any filtering). These additions will make the 19.3% / 18.4% macro-average results independently verifiable. revision: yes
Circularity Check
No circularity; empirical benchmark gains rest on external evaluation, not self-referential fitting or derivation.
full rationale
The paper presents a two-stage training procedure (cold-start grounding followed by on-policy distillation from a symbolic teacher) and reports performance lifts on visual planning benchmarks. No equations, uniqueness theorems, or fitted parameters are defined in terms of the target metrics; the central claims are validated by held-out benchmark scores and ablations rather than by construction. Self-citations, if present, are not load-bearing for the reported improvements. This is the standard non-circular case for an empirical ML methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Symbolic planners provide optimal or near-optimal planning signals that can be transferred to visual models via distillation
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.23497
VOLD: Reasoning transfer from LLMs to vision-language models via on-policy distillation. arXiv preprint arXiv:2510.23497. Ethan Chern, Zhulin Hu, Steffi Chern, Siqi Kou, Jiadi Su, Yan Ma, Zhijie Deng, and Pengfei Liu. 2025. Thinking with generated images.arXiv preprint arXiv:2505.22525. Gheorghe Comanici, E. Bieber, Mike Schaekermann, Ice Pasupat, Noveen ...
Pith/arXiv arXiv 2025
-
[2]
Revisiting on-policy distillation: Empiri- cal failure modes and simple fixes.arXiv preprint arXiv:2603.25562. Google DeepMind. 2025. Gemini 3 Flash model card. https://storage.googleapis. com/deepmind-media/Model-Cards/ Gemini-3-Flash-Model-Card.pdf . Accessed: 2026-05-26. Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang
Pith/arXiv arXiv 2025
-
[3]
InProceedings of the International Conference on Learning Representations
MiniLLM: Knowledge distillation of large language models. InProceedings of the International Conference on Learning Representations. Haowei Guo, Baolong Bi, Ruicheng Zhang, Bingqian Sun, and Wentao Zhang. 2026. When should the teacher move? temporal coupling and stability in self on-policy distillation.Preprint, arXiv:2606.03532. Yuhang He, Haodong Wu, Si...
Pith/arXiv arXiv 2026
-
[4]
Emily Jin, Jiaheng Hu, Zhuoyi Huang, Ruohan Zhang, Jiajun Wu, Li Fei-Fei, and Roberto Martín-Martín
Openvlthinker: Complex vision-language reasoning via iterative sft-rl cycles.arXiv preprint arXiv:2503.17352. Emily Jin, Jiaheng Hu, Zhuoyi Huang, Ruohan Zhang, Jiajun Wu, Li Fei-Fei, and Roberto Martín-Martín
-
[5]
Jiachun Jin, Zetong Zhou, Xiao Yang, Hao Zhang, Pengfei Liu, Jun Zhu, and Zhijie Deng
Mini-BEHA VIOR: A procedurally generated benchmark for long-horizon decision-making in em- bodied ai.arXiv preprint arXiv:2310.01824. Jiachun Jin, Zetong Zhou, Xiao Yang, Hao Zhang, Pengfei Liu, Jun Zhu, and Zhijie Deng. 2026. Laten- tUM: Unleashing the potential of interleaved cross- modal reasoning via a latent-space unified model. arXiv preprint arXiv:...
arXiv 2026
-
[6]
InProceedings of the Inter- national Conference on Machine Learning
Imagine while reasoning in space: Multimodal visualization-of-thought. InProceedings of the Inter- national Conference on Machine Learning. Gongye Liu, Bo Yang, Yida Zhi, Zhizhou Zhong, Lei Ke, Didan Deng, Han Gao, Yongxiang Huang, Kai- hao Zhang, Hongbo Fu, and 1 others. 2026. Beyond vlm-based rewards: Diffusion-native latent reward modeling.arXiv prepri...
Pith/arXiv arXiv 2026
-
[7]
Reproducibility:All environment instances are Table 4:OPSD training hyperparameters. Setting Value Backbone Qwen3-VL-4B Initialization SFT-merged model Training tasks 3 tasks Training samples 18K Validation samples 1.2K Tuning method On-policy distillation Teacher frozen text-only teacher Precision bfloat16 Epochs 3 Max prompt length 5,120 Max response le...
-
[8]
Solu- tions are computed via exact shortest-path algo- rithms; any candidate lacking a complete, legal solution is discarded
Guaranteed Solvability:Candidate states un- dergo rigorous graph-based validation. Solu- tions are computed via exact shortest-path algo- rithms; any candidate lacking a complete, legal solution is discarded
-
[9]
Move actions must be locally valid, interactions must satisfy explicit state precon- ditions, and terminal states must strictly align with task success criteria
Action Feasibility:Generated trajectories are strictly verified against environment transition dynamics. Move actions must be locally valid, interactions must satisfy explicit state precon- ditions, and terminal states must strictly align with task success criteria
-
[10]
perfect maze
Balanced Complexity:To prevent distribution skew toward trivial or overly complex paths, we apply rejection sampling across predefined diffi- culty buckets. Intra-level deduplication (via spa- tial layout and key-state hashing) further maxi- mizes dataset diversity. B.2 Environment-Specific Construction • FrozenLake:Formulated as an N×N grid navigation ta...
-
[11]
Next, give exactly one short sentence that states the planned route at a high level and simulate mentally and verify reaches Goal without hitting any hole. 3. Do not narrate the solution step by step. Do not list repeated moves, repeated coordi- nates, or intermediate states outside <an- swer>. 4. End with exactly one <an- swer>...</answer> block containi...
-
[12]
Next, give exactly one short sentence that states the planned route at a high level and simulate mentally and verify reaches Goal without hitting any hole. 3. Do not narrate the solution step by step. Do not list repeated moves, repeated coordi- nates, or intermediate states outside <an- swer>. 4. End with exactly one <an- swer>...</answer> block containi...
-
[13]
A move is legal only when the current cell lists that direction as open. 4. The route should finish at the target without crossing any wall. Output requirements: 1. First, briefly state the map size, the positions of the Player and Goal, and an open-direction table for every cell. 2. Next, give exactly one short sen- tence that states the planned route at...
-
[14]
The blue dot is the Goal. 3. White re- gions are traversable corridors. 4. Black boundaries are walls and cannot be crossed. Rules: 1. Valid actions are L (Left), D (Down), R (Right), and U (Up). 2. The player moves one grid cell per action. 3. Keep the reasoning brief and necessary only
-
[15]
Output requirements: 1
When mentioning positions, use 0-based (row, column) coordinates only. Output requirements: 1. First, briefly state the map size, the positions of the Player and Goal, and an open-direction table for every cell. 2. Next, give exactly one short sen- tence that states the planned route at a high level and mentally verifies that it reaches the Goal without c...
-
[16]
PICK is legal only when the agent is adjacent to the printer. 5. DROP is legal only after PICK, when the agent is adjacent to the table. 6. The plan must perform PICK before DROP and finish immediately after a legal DROP. Output requirements: 1. First, briefly state the grid size and the positions of the Agent, Printer, and Table. 2. Next, give exactly on...
-
[17]
The white marker is the Printer. 3. The tan block is the Table. 4. Black cells are free floor cells. Rules: 1. Valid move actions are L (Left), D (Down), R (Right), and U (Up). 2. Valid interaction actions are PICK and DROP. 3. The agent moves one grid cell per move ac- tion. 4. The agent cannot enter table cells. The printer cell is blocked before PICK, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.