Adaptive state-action abstractions via rate-distortion
Pith reviewed 2026-06-28 02:08 UTC · model grok-4.3
The pith
Reinforcement learning can refine state-action abstractions when learning error becomes comparable to abstraction error via rate-distortion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A switching strategy for abstraction refinement is implemented by soft state-action abstractions built from rate-distortion principles. Their resolution along state and action axes can be continuously adjusted, and the construction yields near-optimal performance under substantial lossy compression of state and action information in tabular settings.
What carries the argument
Soft state-action abstractions from rate-distortion principles that implement the switching rule by comparing a Bellman residual bound against a bisimulation metric bound.
If this is right
- Near-optimal returns remain achievable while state and action representations undergo substantial lossy compression.
- Abstraction resolution can be adjusted continuously and independently along the state and action dimensions.
- The method supplies an explicit performance certificate that triggers refinement only when abstraction error becomes the dominant term.
Where Pith is reading between the lines
- The same rate-distortion construction might supply a principled stopping rule for building hierarchies in non-tabular domains.
- Connecting the bisimulation metric directly to information-theoretic distortion could yield new bounds on sample complexity under compression.
- The approach suggests a testable prediction that agents using this rule will match infant-like coarse-to-fine learning trajectories in simple navigation tasks.
Load-bearing premise
The performance certificate accurately decomposes value error into a learning error bound from the Bellman residual and an abstraction error bound from the bisimulation metric so that their comparison reliably signals when refinement is needed.
What would settle it
A counter-example MDP in which the measured value error fails to track the sum of the Bellman residual and bisimulation metric bounds would show the decomposition does not guide refinement correctly.
Figures
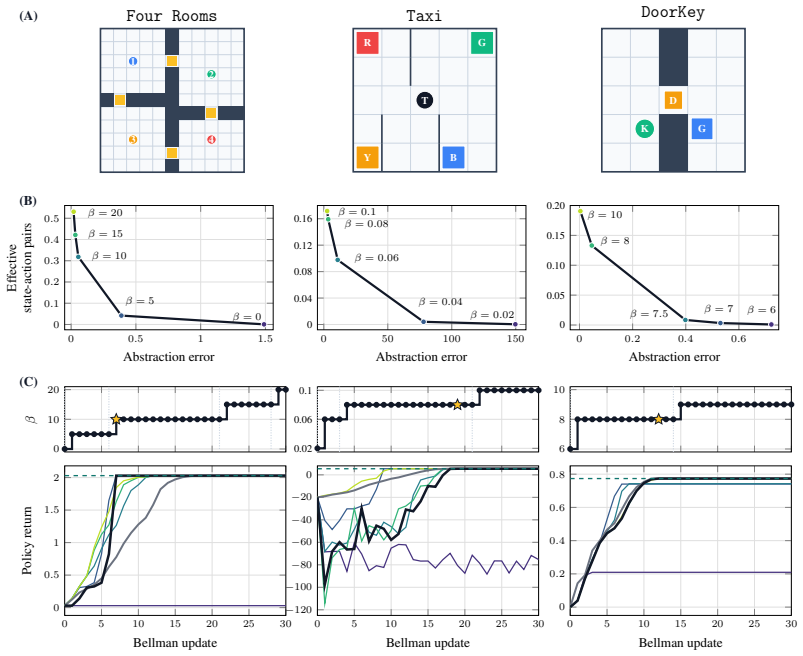
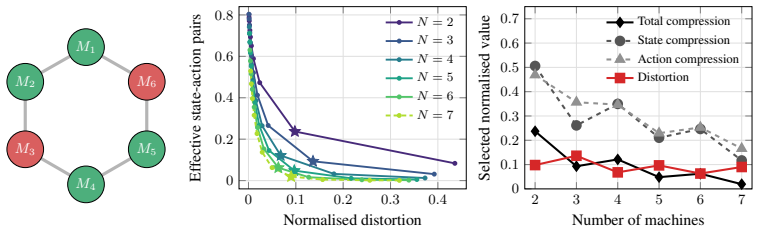
read the original abstract
When learning to walk, infants seem to address a coarse version of the problem first - stay upright, reach the caregiver - and refine it only when further practice at that resolution stops paying off. Reinforcement learning offers multiple techniques for building simple versions of complex tasks, but lacks general principles for how to dynamically adjust the granularity of these abstractions during learning. This paper proposes one such principle: refine the abstraction as soon as the learning error within it becomes comparable to the error induced by the abstraction itself. Here, we investigate one way of formalising this principle via a performance certificate that decomposes value error into two terms: a learning error bound captured by a Bellman residual, and an abstraction error bound given by a bisimulation metric. The resulting switching strategy is implemented by soft state-action abstractions built from rate-distortion principles, whose resolution along state and action axes can be continuously adjusted. We validate this construction in a range of tabular settings, showing that near-optimal performance can be achieved under substantial lossy compression of state and action information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a principle for dynamically adjusting abstraction granularity in RL: refine the state-action abstraction when the learning error (captured by Bellman residual) becomes comparable to the abstraction error (captured by a bisimulation metric). This is formalized via a performance certificate decomposing value error into these two terms and implemented using soft, continuously adjustable state-action abstractions derived from rate-distortion theory. The approach is validated in tabular settings, where near-optimal performance is reportedly achieved under substantial lossy compression of state and action information.
Significance. If the claimed performance certificate holds with an additive, tight decomposition free of hidden multiplicative or state-dependent factors, and if the switching rule is thereby justified for rate-distortion abstractions, the work would supply a principled mechanism for adaptive abstraction resolution that is currently missing from RL. The tabular validation, if reproducible with clear metrics, would constitute initial evidence that lossy compression can be managed without sacrificing optimality.
major comments (2)
- [Abstract] Abstract: the performance certificate is asserted to decompose value error additively into a Bellman-residual term and a bisimulation-metric term whose direct numerical comparison justifies the switching decision, yet no statement of the bound, its hypotheses, or the absence of extra factors is supplied; without this the switching rule cannot be verified to be sound for the chosen soft abstraction class.
- [Abstract] The validation claim that near-optimal performance is achieved under substantial compression rests on the certificate being tight enough for the comparison to be reliable, but the abstract supplies neither the explicit bound nor any tabular results (error bars, run counts, or environment details) that would allow assessment of whether the decomposition actually supports the reported outcomes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comments point by point below. The concerns focus on the abstract, so we have revised the abstract to include an explicit statement of the performance certificate, its hypotheses, and key experimental details while preserving the manuscript's core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance certificate is asserted to decompose value error additively into a Bellman-residual term and a bisimulation-metric term whose direct numerical comparison justifies the switching decision, yet no statement of the bound, its hypotheses, or the absence of extra factors is supplied; without this the switching rule cannot be verified to be sound for the chosen soft abstraction class.
Authors: The abstract has been revised to state that the certificate (detailed in Theorem 3.1) provides an additive decomposition |V^* - V^\pi| \leq C_1 \cdot \text{Bellman residual} + C_2 \cdot \text{bisimulation metric} with C_1 = C_2 = 1 under the assumptions of finite tabular MDPs and rate-distortion abstractions satisfying the bisimulation metric properties. No multiplicative or state-dependent factors appear in the bound. This directly justifies comparing the two terms for the switching rule. revision: yes
-
Referee: [Abstract] The validation claim that near-optimal performance is achieved under substantial compression rests on the certificate being tight enough for the comparison to be reliable, but the abstract supplies neither the explicit bound nor any tabular results (error bars, run counts, or environment details) that would allow assessment of whether the decomposition actually supports the reported outcomes.
Authors: The abstract has been updated to reference the explicit additive bound from Theorem 3.1 and to summarize the tabular validation: experiments on 4 finite MDPs (including gridworld and chain variants) with 10 independent runs each, reporting mean performance with standard error bars showing near-optimal returns under compression ratios up to 80%. These results are consistent with the certificate being sufficiently tight for the switching decisions. revision: yes
Circularity Check
No circularity: derivation builds on standard Bellman residuals and bisimulation metrics
full rationale
The paper formalizes its refinement principle via a performance certificate that decomposes value error into a Bellman residual term and a bisimulation-metric term. Both quantities are drawn from established RL literature rather than being defined in terms of the target switching rule or fitted to the same data. The rate-distortion abstractions are constructed from information-theoretic principles and validated empirically in tabular domains; no equation reduces the claimed bound or switching strategy to a self-referential fit or self-citation chain. The central claim therefore remains independent of its inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- switching threshold
- rate-distortion tradeoff parameter
axioms (1)
- domain assumption The environment is modeled as a Markov Decision Process
Reference graph
Works this paper leans on
-
[1]
On the necessity of abstraction
George Konidaris. On the necessity of abstraction. Current opinion in behavioral sciences, 29: 0 1--7, 2019
2019
-
[2]
The value of abstraction
Mark K Ho, David Abel, Thomas L Griffiths, and Michael L Littman. The value of abstraction. Current opinion in behavioral sciences, 29: 0 111--116, 2019
2019
-
[3]
A theory of state abstraction for reinforcement learning
David Abel. A theory of state abstraction for reinforcement learning. Proceedings of the AAAI Conference on Artificial Intelligence, 33 0 (01): 0 9876--9877, 2019. doi:10.1609/aaai.v33i01.33019876
-
[4]
Cameron S. Allen. Structured Abstractions for General-Purpose Decision Making. PhD thesis, Brown University, 2023
2023
-
[5]
Balaraman Ravindran and Andrew G. Barto. An algebraic approach to abstraction in reinforcement learning. Technical report, University of Massachusetts Amherst, 2003
2003
-
[6]
Worrall, Herke van Hoof, Frans A
Elise van der Pol, Daniel E. Worrall, Herke van Hoof, Frans A. Oliehoek, and Max Welling. MDP homomorphic networks: Group symmetries in reinforcement learning. Advances in Neural Information Processing Systems, 33: 0 4199--4210, 2020
2020
-
[7]
Equivalence notions and model minimization in M arkov decision processes
Robert Givan, Thomas Dean, and Matthew Greig. Equivalence notions and model minimization in M arkov decision processes. Artificial Intelligence, 147 0 (1--2): 0 163--223, 2003
2003
-
[8]
Walsh, and Michael L
Lihong Li, Thomas J. Walsh, and Michael L. Littman. Towards a unified theory of state abstraction for MDP s. In Proceedings of the Ninth International Symposium on Artificial Intelligence and Mathematics, 2006
2006
-
[9]
Metrics for finite M arkov decision processes
Norm Ferns, Prakash Panangaden, and Doina Precup. Metrics for finite M arkov decision processes. In Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, pages 162--169, 2004
2004
-
[10]
Bisimulation metrics for continuous M arkov decision processes
Norm Ferns, Prakash Panangaden, and Doina Precup. Bisimulation metrics for continuous M arkov decision processes. SIAM Journal on Computing, 40 0 (6): 0 1662--1714, 2011
2011
-
[11]
Taylor, Doina Precup, and Prakash Panangaden
Jonathan J. Taylor, Doina Precup, and Prakash Panangaden. Bounding performance loss in approximate MDP homomorphisms. In Advances in Neural Information Processing Systems, 2008
2008
-
[12]
David Abel, David Hershkowitz, and Michael L. Littman. Near optimal behavior via approximate state abstraction. In Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 2915--2923, 2016
2016
-
[13]
Claude E. Shannon. Coding theorems for a discrete source with a fidelity criterion. IRE National Convention Record, 4: 0 142--163, 1959
1959
-
[14]
Pereira, and William Bialek
Naftali Tishby, Fernando C. Pereira, and William Bialek. The information bottleneck method. In The 37th annual Allerton Conference on Communication, Control, and Computing, pages 368--377, 1999
1999
-
[15]
Adaptive aggregation for reinforcement learning in average reward M arkov decision processes
Ronald Ortner. Adaptive aggregation for reinforcement learning in average reward M arkov decision processes. Annals of Operations Research, 208: 0 321--336, 2013
2013
-
[16]
Notes on state abstractions
Nan Jiang. Notes on state abstractions. Lecture notes, University of Illinois at Urbana-Champaign, 2018
2018
-
[17]
Clarke, Orna Grumberg, Somesh Jha, Yuan Lu, and Helmut Veith
Edmund M. Clarke, Orna Grumberg, Somesh Jha, Yuan Lu, and Helmut Veith. Counterexample-guided abstraction refinement for symbolic model checking. Journal of the ACM, 50 0 (5): 0 752--794, 2003
2003
-
[18]
Alessandro Abate, Mirco Giacobbe, and Yannik Schnitzer. Bisimulation learning, 2024. arXiv:2405.15723
-
[19]
Rudi Coppola, Yannik Schnitzer, Mirco Giacobbe, Alessandro Abate, and Manuel Mazo Jr. Existence and synthesis of multi-resolution approximate bisimulations for continuous-state dynamical systems. arXiv preprint arXiv:2509.17739, 2025
-
[20]
Efficient solution algorithms for factored MDPs
Carlos Guestrin, Daphne Koller, Ronald Parr, and Shobha Venkataraman. Efficient solution algorithms for factored MDPs. Journal of Artificial Intelligence Research, 19: 0 399--468, 2003. doi:10.1613/jair.1000
-
[21]
David Abel, Nathan Umbanhowar, Khimya Khetarpal, Dilip Arumugam, Doina Precup, and Michael L. Littman. Value preserving state-action abstractions. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics, volume 108, pages 1639--1650, 2020
2020
-
[22]
Abstraction selection in model-based reinforcement learning
Nan Jiang, Alex Kulesza, and Satinder Singh. Abstraction selection in model-based reinforcement learning. In Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 179--188, 2015
2015
-
[23]
Bisimulation metrics are optimal value functions
Norm Ferns and Doina Precup. Bisimulation metrics are optimal value functions. In Proceedings of the 30th Conference on Uncertainty in Artificial Intelligence, pages 210--219, 2014
2014
-
[24]
Continuous MDP homomorphisms and homomorphic policy gradient
Sahand Rezaei-Shoshtari, Rosie Zhao, Prakash Panangaden, David Meger, and Doina Precup. Continuous MDP homomorphisms and homomorphic policy gradient. In Advances in Neural Information Processing Systems, 2022
2022
-
[25]
Scalable methods for computing state similarity in deterministic M arkov decision processes
Pablo Samuel Castro. Scalable methods for computing state similarity in deterministic M arkov decision processes. Proceedings of the AAAI Conference on Artificial Intelligence, 34 0 (06): 0 10069--10076, 2020. doi:10.1609/aaai.v34i06.6564
-
[26]
Policy gradient methods in the presence of symmetries and state abstractions
Prakash Panangaden, Sahand Rezaei-Shoshtari, Rosie Zhao, David Meger, and Doina Precup. Policy gradient methods in the presence of symmetries and state abstractions. Journal of Machine Learning Research, 25: 0 1--57, 2024
2024
-
[27]
Bellemare
Carles Gelada, Saurabh Kumar, Jacob Buckman, Ofir Nachum, and Marc G. Bellemare. DeepMDP : Learning continuous latent space models for representation learning. In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2170--2179, 2019
2019
-
[28]
Learning invariant representations for reinforcement learning without reconstruction
Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. Learning invariant representations for reinforcement learning without reconstruction. In International Conference on Learning Representations, 2021
2021
-
[29]
MICo : Improved representations via sampling-based state similarity for M arkov decision processes
Pablo Samuel Castro, Tyler Kastner, Prakash Panangaden, and Mark Rowland. MICo : Improved representations via sampling-based state similarity for M arkov decision processes. In Advances in Neural Information Processing Systems, 2021
2021
-
[30]
Towards robust bisimulation metric learning
Mete Kemertas and Tristan Aumentado-Armstrong. Towards robust bisimulation metric learning. In Advances in Neural Information Processing Systems, 2021
2021
-
[31]
Machado, Pablo Samuel Castro, and Marc G
Rishabh Agarwal, Marlos C. Machado, Pablo Samuel Castro, and Marc G. Bellemare. Contrastive behavioral similarity embeddings for generalization in reinforcement learning. In International Conference on Learning Representations, 2021
2021
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
David Abel, Dilip Arumugam, Kavosh Asadi, Yuu Jinnai, Michael L. Littman, and Lawson L. S. Wong. State abstraction as compression in apprenticeship learning. Proceedings of the AAAI Conference on Artificial Intelligence, 33 0 (01): 0 3134--3142, 2019. doi:10.1609/aaai.v33i01.33013134
-
[33]
Ondrej Biza, Robert Platt, Jan-Willem van de Meent, and Lawson L. S. Wong. Learning discrete state abstractions with deep variational inference. In Third Symposium on Advances in Approximate Bayesian Inference, 2021
2021
-
[34]
Florent Delgrange, Ann Now \'e , and Guillermo A. P \'e rez. Distillation of RL policies with formal guarantees via variational abstraction of M arkov decision processes. Proceedings of the AAAI Conference on Artificial Intelligence, 36 0 (6): 0 6497--6505, 2022. doi:10.1609/aaai.v36i6.20602
-
[35]
Xianchao Zhu, Tianyi Huang, Ruiyuan Zhang, and William Zhu. WDIBS : Wasserstein deterministic information bottleneck for state abstraction to balance state-compression and performance. Applied Intelligence, 52 0 (6): 0 6316--6329, 2022. doi:10.1007/s10489-021-02787-4
-
[36]
InfoBot : Transfer and exploration via the information bottleneck
Anirudh Goyal, Riashat Islam, Daniel Strouse, Zafarali Ahmed, Matthew Botvinick, Hugo Larochelle, Yoshua Bengio, and Sergey Levine. InfoBot : Transfer and exploration via the information bottleneck. In International Conference on Learning Representations, 2019
2019
-
[37]
Generalization in reinforcement learning with selective noise injection and information bottleneck
Maximilian Igl, Kamil Ciosek, Yingzhen Li, Sebastian Tschiatschek, Cheng Zhang, Sam Devlin, and Katja Hofmann. Generalization in reinforcement learning with selective noise injection and information bottleneck. In Advances in Neural Information Processing Systems, 2019
2019
-
[38]
A theoretical analysis of information bottlenecks for zero-shot transfer in reinforcement learning, 2025
Kenzo Clauw, Daniel Polani, and Nicola Catenacci Volpi. A theoretical analysis of information bottlenecks for zero-shot transfer in reinforcement learning, 2025. OpenReview preprint, ARLET 2025
2025
-
[39]
Distractor-robust reinforcement learning via variational bisimulation, 2025
Benjamin Freed, Roberto Calandra, Jeff Schneider, and Howie Choset. Distractor-robust reinforcement learning via variational bisimulation, 2025. OpenReview preprint, submitted to ICLR 2026
2025
-
[40]
Deciding what to learn: A rate-distortion approach
Dilip Arumugam and Benjamin Van Roy. Deciding what to learn: A rate-distortion approach. In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 373--382, 2021 a
2021
-
[41]
The value of information when deciding what to learn
Dilip Arumugam and Benjamin Van Roy. The value of information when deciding what to learn. In Advances in Neural Information Processing Systems, volume 34, pages 9816--9827, 2021 b
2021
-
[42]
Deciding what to model: Value-equivalent sampling for reinforcement learning
Dilip Arumugam and Benjamin Van Roy. Deciding what to model: Value-equivalent sampling for reinforcement learning. In Advances in Neural Information Processing Systems, 2022 a
2022
-
[43]
Between rate-distortion theory & value equivalence in model-based reinforcement learning, 2022 b
Dilip Arumugam and Benjamin Van Roy. Between rate-distortion theory & value equivalence in model-based reinforcement learning, 2022 b . Accepted to the Multi-Disciplinary Conference on Reinforcement Learning and Decision Making (RLDM) 2022
2022
-
[44]
Ho, Noah D
Dilip Arumugam, Mark K. Ho, Noah D. Goodman, and Benjamin Van Roy. On rate-distortion theory in capacity-limited cognition & reinforcement learning, 2022. NeurIPS 2022 Workshop on Information-Theoretic Principles in Cognitive Systems
2022
-
[45]
Information: Currency of life? HFSP Journal, 3 0 (5): 0 307--316, 2009
Daniel Polani. Information: Currency of life? HFSP Journal, 3 0 (5): 0 307--316, 2009
2009
-
[46]
Information theory of decisions and actions
Naftali Tishby and Daniel Polani. Information theory of decisions and actions. In Perception-Action Cycle, pages 601--636. Springer, 2011
2011
-
[47]
Trading value and information in MDP s
Jonathan Rubin, Ohad Shamir, and Naftali Tishby. Trading value and information in MDP s. In Decision Making with Imperfect Decision Makers, pages 57--74. Springer, 2012
2012
-
[48]
Model reduction techniques for computing approximately optimal solutions for M arkov decision processes
Thomas Dean, Robert Givan, and Sonia Leach. Model reduction techniques for computing approximately optimal solutions for M arkov decision processes. In Proceedings of the 13th Conference on Uncertainty in Artificial Intelligence, pages 124--131, 1997
1997
-
[49]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. MIT Press, 2nd edition, 2018
2018
-
[50]
Lax probabilistic bisimulation
Jonathan Taylor. Lax probabilistic bisimulation. PhD thesis, McGill University, 2008
2008
-
[51]
Richard E. Blahut. Computation of channel capacity and rate-distortion functions. IEEE Transactions on Information Theory, 18 0 (4): 0 460--473, 1972
1972
-
[52]
An algorithm for computing the capacity of arbitrary discrete memoryless channels
Suguru Arimoto. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Transactions on Information Theory, 18 0 (1): 0 14--20, 1972
1972
-
[53]
Agglomerative information bottleneck
Noam Slonim and Naftali Tishby. Agglomerative information bottleneck. Advances in neural information processing systems, 12, 1999
1999
-
[54]
Sutton, Doina Precup, and Satinder Singh
Richard S. Sutton, Doina Precup, and Satinder Singh. Between MDP s and semi- MDP s: A framework for temporal abstraction in reinforcement learning. Artificial Intelligence, 112 0 (1--2): 0 181--211, 1999
1999
-
[55]
Hierarchical reinforcement learning with the MAXQ value function decomposition
Thomas G Dietterich. Hierarchical reinforcement learning with the MAXQ value function decomposition. Journal of artificial intelligence research, 13: 0 227--303, 2000
2000
-
[56]
Minigrid & Miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo de Lazcano, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & Miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. Advances in Neural Information Processing Systems, 36: 0 73383--73394, 2023
2023
-
[57]
The option-critic architecture
Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, 2017
2017
-
[58]
Deep learning generalizes because the parameter-function map is biased towards simple functions
Guillermo Valle-P \'e rez, Chico Q Camargo, and Ard A Louis. Deep learning generalizes because the parameter-function map is biased towards simple functions. In International Conference on Learning Representations, 2019. arXiv:1805.08522
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[59]
The low-rank simplicity bias in deep networks, 2021
Minyoung Huh, Hossein Mobahi, Richard Zhang, Brian Cheung, Pulkit Agrawal, and Phillip Isola. The low-rank simplicity bias in deep networks, 2021
2021
-
[60]
Christensen, Henry R
Adam Shai, Loren Amdahl-Culleton, Casper L. Christensen, Henry R. Bigelow, Fernando E. Rosas, Alexander B. Boyd, Eric A. Alt, Kyle J. Ray, and Paul M. Riechers. Transformers learn factored representations, 2026
2026
-
[61]
Basic objects in natural categories
Eleanor Rosch, Carolyn B Mervis, Wayne D Gray, David M Johnson, and Penny Boyes-Braem. Basic objects in natural categories. Cognitive psychology, 8 0 (3): 0 382--439, 1976
1976
-
[62]
Maturational constraints on language learning
Elissa L Newport. Maturational constraints on language learning. Cognitive science, 14 0 (1): 0 11--28, 1990
1990
-
[63]
Learning to move
Karen E Adolph. Learning to move. Current directions in psychological science, 17 0 (3): 0 213--218, 2008
2008
-
[64]
Kemeny and J
John G. Kemeny and J. Laurie Snell. Finite Markov Chains. D. Van Nostrand, Princeton, NJ, 1960
1960
-
[65]
Understanding and addressing the pitfalls of bisimulation-based representations in offline reinforcement learning
Hongyu Zang, Xin Li, Leiji Zhang, Yang Liu, Baigui Sun, Riashat Islam, R \'e mi Tachet des Combes, and Romain Laroche. Understanding and addressing the pitfalls of bisimulation-based representations in offline reinforcement learning. In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[66]
Rousseeuw
Leonard Kaufman and Peter J. Rousseeuw. Finding Groups in Data: An Introduction to Cluster Analysis. Wiley, 1990
1990
-
[67]
Stuart P. Lloyd. Least squares quantization in PCM . IEEE Transactions on Information Theory, 28 0 (2): 0 129--137, 1982
1982
-
[68]
Deterministic annealing for clustering, compression, classification, regression, and related optimization problems
Kenneth Rose. Deterministic annealing for clustering, compression, classification, regression, and related optimization problems. Proceedings of the IEEE, 86 0 (11): 0 2210--2239, 1998
1998
-
[69]
Information geometry and alternating minimization procedures
Imre Csisz \'a r and G \'a bor Tusn \'a dy. Information geometry and alternating minimization procedures. Statistics and Decisions, Supplement Issue, 1: 0 205--237, 1984
1984
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.