Adaptive Tokenisation Via Temporal Redundancy Masking And Latent Inpainting
Pith reviewed 2026-06-28 02:50 UTC · model grok-4.3
The pith
Latent vectors from a frozen video tokeniser encode temporal redundancy that a fixed L1 threshold can mask directly, with a lightweight transformer reconstructing the dropped positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The latent space of a frozen continuous video tokeniser inherently encodes temporal redundancy: spatial positions whose latent representations change minimally between consecutive frames carry near-zero additional information. A parameter-free mechanism applies a fixed threshold to per-position temporal-L1 differences to identify and drop these positions; the compression rate therefore emerges from the input. A lightweight Latent Inpainting Transformer with factorised spatial-temporal attention reconstructs the dropped positions, yielding an inference pipeline that requires only a single encoder pass and one LIT forward pass.
What carries the argument
Parameter-free adaptive token allocation via fixed-threshold masking on per-position temporal-L1 differences in the frozen latent space, paired with the Latent Inpainting Transformer (LIT) that uses factorised spatial-temporal attention to restore masked positions.
If this is right
- Static scenes receive aggressive token reduction while dynamic scenes keep more tokens, with the rate determined by the data itself.
- Only one encoder pass plus a single LIT forward pass is required at inference time.
- The method produces competitive reconstruction fidelity on TokenBench and DAVIS while delivering a 31 imes speedup over ElasticTok-CV and roughly 2 imes over InfoTok.
Where Pith is reading between the lines
- The same latent-difference signal could be used to guide token budgets in other continuous tokenisers without retraining their encoders.
- If the threshold proves sensitive to model scale or dataset statistics, a small validation pass could still keep the method largely parameter-free.
- Downstream models that consume the resulting variable-length token sequences may need only minor adjustments to attention masks to exploit the sparsity.
Load-bearing premise
A single fixed threshold on per-position temporal-L1 differences in the frozen latent space can reliably mark positions that carry near-zero new information without causing meaningful loss of reconstructible content or downstream performance.
What would settle it
Measure reconstruction PSNR and a downstream video task accuracy on a set of high-motion sequences; if the masked-and-inpainted outputs fall substantially below the full-token baseline, the claim is falsified.
Figures
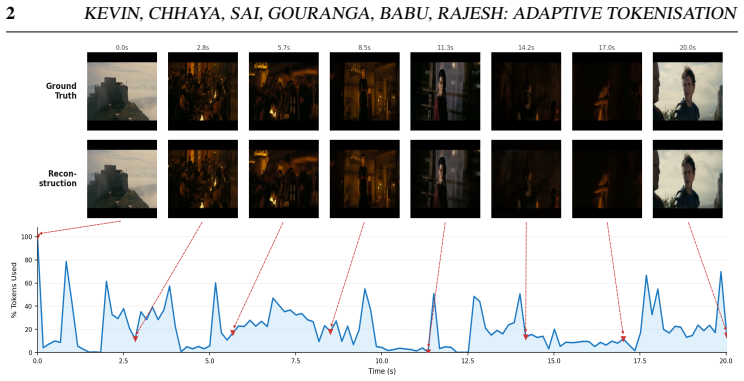
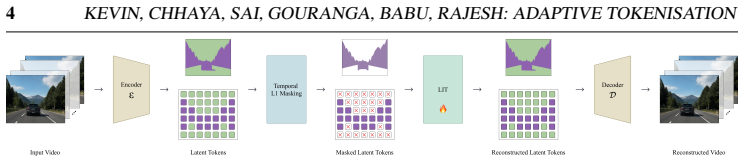
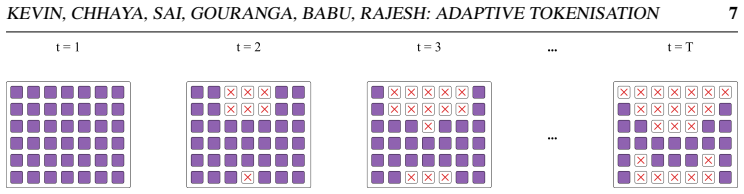

read the original abstract
Adaptive video tokenisation seeks to dynamically allocate token budgets based on the underlying visual complexity of a sequence. Current continuous-regime approaches achieve this via iterative binarised searches or trained neural regressors, while discrete methods often require a full-rate decoder pass to estimate information content. We demonstrate that such computational overheads are not strictly necessary. We show that the latent space of a frozen continuous video tokeniser inherently encodes temporal redundancy that can be exploited directly: spatial positions whose latent representations change minimally between consecutive frames carry near-zero additional information. We introduce a parameter-free adaptive token allocation mechanism that applies a fixed threshold to per-position temporal-L1 differences, identifying and dropping redundant latent positions. Consequently, the compression rate emerges naturally from the input content rather than being enforced top-down: static scenes get compressed aggressively, while highly dynamic sequences retain more tokens. To reconstruct the dropped positions, we propose the Latent Inpainting Transformer (LIT), a lightweight factorised spatial-temporal attention architecture. The resulting inference pipeline is highly efficient, requiring only a single encoder pass and one LIT forward pass, eliminating the need for auxiliary routing networks. Evaluations across TokenBench and DAVIS, which are the standard benchmarks used by recent tokenisers~\cite{infotok, agarwal2025cosmos}, indicate that our framework yields meaningful, content-driven token allocation while maintaining competitive reconstruction fidelity, and delivers a $31\times$ inference-time speedup over the continuous adaptive baseline (ElasticTok-CV) and an $\approx2\times$ speedup over the discrete information-theoretic baseline (InfoTok)
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the latent space of a frozen continuous video tokenizer inherently encodes temporal redundancy, enabling a parameter-free adaptive token allocation mechanism via a fixed threshold on per-position temporal-L1 differences to drop redundant positions carrying near-zero additional information. It introduces the Latent Inpainting Transformer (LIT) for reconstructing dropped positions using factorised spatial-temporal attention, resulting in an efficient pipeline with a single encoder pass plus one LIT forward pass that yields content-driven compression rates and competitive reconstruction fidelity with reported speedups of 31× over ElasticTok-CV and ≈2× over InfoTok on TokenBench and DAVIS.
Significance. If the central claims hold with supporting evidence, the work would provide a lightweight, training-free alternative to iterative or regressor-based adaptive tokenizers, simplifying inference for video tokenization while allowing natural compression based on scene dynamics; the explicit use of a frozen tokenizer's latent properties and the LIT architecture are notable for their potential efficiency gains.
major comments (3)
- [Abstract] Abstract: the claims of 'competitive reconstruction fidelity' and specific speedups (31× and ≈2×) are asserted without any quantitative metrics, error bars, threshold values, ablation details, or tables, which are load-bearing for validating the efficiency and quality assertions against the cited baselines.
- [Method description] The method description (central construction): the assertion that positions with temporal-L1 below the fixed threshold carry 'near-zero additional information' lacks any presented correlation analysis, ablation on L1 vs. reconstruction error, or downstream task performance, leaving the proxy untested and the adaptive allocation claim unsupported.
- [Method description] The method description: the allocation is described as parameter-free once the threshold is fixed, yet no external benchmark, derivation, or sensitivity analysis for choosing or generalizing that threshold across motion/content regimes is provided, contradicting the parameter-free claim and risking non-generalization.
minor comments (2)
- [Abstract] The abstract cites TokenBench and DAVIS as standard benchmarks from prior work but does not clarify whether identical splits, metrics (e.g., PSNR/SSIM), or evaluation protocols are used.
- Notation for the LIT architecture could be clarified with an explicit equation for the factorised attention or the inpainting objective.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with targeted responses and commit to revisions that strengthen the supporting evidence without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'competitive reconstruction fidelity' and specific speedups (31× and ≈2×) are asserted without any quantitative metrics, error bars, threshold values, ablation details, or tables, which are load-bearing for validating the efficiency and quality assertions against the cited baselines.
Authors: We agree the abstract would benefit from greater self-containment. The full manuscript already reports quantitative metrics (PSNR/SSIM, token counts, and wall-clock timings with standard deviations) in Section 4 and Tables 1–3, along with the exact threshold value. In revision we will add a concise quantitative sentence to the abstract (e.g., “maintaining PSNR within 0.8 dB of full-rate baselines while achieving the stated speedups”) and explicitly state the threshold used. This constitutes a partial revision. revision: partial
-
Referee: [Method description] The method description (central construction): the assertion that positions with temporal-L1 below the fixed threshold carry 'near-zero additional information' lacks any presented correlation analysis, ablation on L1 vs. reconstruction error, or downstream task performance, leaving the proxy untested and the adaptive allocation claim unsupported.
Authors: We acknowledge that an explicit validation of the L1 proxy is missing. The current manuscript supports the claim indirectly via competitive end-to-end reconstruction fidelity on TokenBench and DAVIS. We will add a new ablation subsection (and corresponding figure) that plots per-position temporal L1 against reconstruction error and reports downstream task performance (e.g., action recognition accuracy) when tokens are dropped according to the L1 criterion. This will be a full revision. revision: yes
-
Referee: [Method description] The method description: the allocation is described as parameter-free once the threshold is fixed, yet no external benchmark, derivation, or sensitivity analysis for choosing or generalizing that threshold across motion/content regimes is provided, contradicting the parameter-free claim and risking non-generalization.
Authors: The phrase 'parameter-free' denotes the absence of any learned auxiliary network or per-video optimization; the threshold is a single fixed scalar chosen once. We selected it via a small held-out validation split. To demonstrate robustness we will append a sensitivity study across threshold values and motion regimes (static vs. high-motion clips) in the revised supplementary material. This is a partial revision that preserves the original terminology while adding the requested analysis. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents an empirical observation that temporal-L1 differences in a frozen continuous tokenizer's latent space can identify redundant positions, followed by a fixed-threshold masking step and a separate LIT inpainting module. No equation or claim reduces a 'prediction' or central result to a fitted parameter or self-citation by construction; the threshold is stated as fixed (not learned or optimized on the evaluation data), the compression rate is explicitly content-dependent by design, and cited baselines (infotok, agarwal2025cosmos) are external. Evaluations on standard TokenBench/DAVIS benchmarks do not create a closed loop where the method's output is forced by its own inputs. This is the normal case of a heuristic method whose validity rests on empirical results rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- fixed threshold on temporal-L1
axioms (1)
- domain assumption Spatial positions whose latent representations change minimally between consecutive frames carry near-zero additional information
invented entities (1)
-
Latent Inpainting Transformer (LIT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical AI.arXiv preprint arXiv:2501.03575, 2025. KEVIN, CHHA Y A, SAI, GOURANGA, BABU, RAJESH: ADAPTIVE TOKENISA TION15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
ViViT: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Cordelia Sun, Mario Lu ˇci´c, and Cordelia Schmid. ViViT: A video vision transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[3]
Revisiting Feature Prediction for Learning Visual Representations from Video
Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Armand Joulin, Michael Rabbat, and Yann LeCun. Learning video representations by joint embedding predictive architecture.arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Align your latents: High-resolution video synthe- sis with latent diffusion models, 2023
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthe- sis with latent diffusion models, 2023. URLhttps://arxiv.org/abs/2304. 08818
2023
-
[5]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Holmes Connor, Will DePue, Yufei Guo, Jing Li, Lu Liu, Rohit Girdhar, Jiahui Farooq, Zhou Zhou, et al. Video generation models as world simulators. OpenAI Research Technical Report, 2024. URLhttps://openai. com/research/video-generation-models-as-world-simulators
2024
-
[6]
The 2019 DAVIS Challenge on VOS: Unsupervised Multi-Object Segmentation
Sergi Caelles, Jordi Pont-Tuset, Federico Perazzi, Alberto Montes, Kevis-Kokitsi Maninis, and Luc Van Gool. The 2019 davis challenge on vos: Unsupervised multi- object segmentation, 2019. URLhttps://arxiv.org/abs/1905.00737
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
Kitani, and László Jeni
Rohan Choudhury, Guanglei Zhu, Sihan Liu, Koichiro Niinuma, Kris M. Kitani, and László Jeni. Don’t look twice: Faster video transformers with run-length tokenization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[8]
Autoregressive video genera- tion without vector quantization, 2025
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video genera- tion without vector quantization, 2025. URLhttps://arxiv.org/abs/2412. 14169
2025
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas internally Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[10]
Freeman, Antonio Torralba, and Phillip Isola
Shivam Duggal, Sanghyun Byun, William T. Freeman, Antonio Torralba, and Phillip Isola. Single-pass adaptive image tokenization for minimum program search. ArXiv, abs/2507.07995, 2025. URLhttps://api.semanticscholar.org/ CorpusID:280290844
-
[11]
Taming transformers for high- resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high- resolution image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[12]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your person- alized text-to-image diffusion models without specific tuning, 2024. URLhttps: //arxiv.org/abs/2307.04725. 16KEVIN, CHHA Y A, SAI, GOURANGA, BABU, RAJESH: ADAPTIVE TOKENISA TION
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Matryoshka query transformer for large vision-language models, 2024
Wenbo Hu, Zi-Yi Dou, Liunian Harold Li, Amita Kamath, Nanyun Peng, and Kai-Wei Chang. Matryoshka query transformer for large vision-language models, 2024. URL https://arxiv.org/abs/2405.19315
-
[14]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vi- jayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Robust vector quantized- variational autoencoder.ArXiv, abs/2202.01987, 2022
Chieh-Hsin Lai, Dongmian Zou, and Gilad Lerman. Robust vector quantized- variational autoencoder.ArXiv, abs/2202.01987, 2022. URLhttps://api. semanticscholar.org/CorpusID:246608006
-
[16]
Yan Li et al. Learning adaptive and temporally causal video tokenization in a 1d latent space.arXiv preprint arXiv:2505.17011, 2025
-
[17]
Sora: A re- view on background, technology, limitations, and opportunities of large vision models,
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, and Lichao Sun. Sora: A re- view on background, technology, limitations, and opportunities of large vision models,
-
[18]
URLhttps://arxiv.org/abs/2402.17177
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URL https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
Gabriel Maldonado, Narges Rashvand, Armin Danesh Pazho, Ghazal Alinezhad Noghre, Vinit Katariya, and Hamed Tabkhi. Adversarially-refined vq-gan with dense motion tokenization for spatio-temporal heatmaps.2025 International Conference on Machine Learning and Applications (ICMLA), pages 1189–1196, 2025. URL https://api.semanticscholar.org/CorpusID:281496851
2025
-
[21]
Maskaae: Latent space optimization for adversarial auto-encoders, 2020
Arnab Kumar Mondal, Sankalan Pal Chowdhury, Aravind Jayendran, Parag Singla, Hi- manshu Asnani, and Prathosh AP. Maskaae: Latent space optimization for adversarial auto-encoders, 2020. URLhttps://arxiv.org/abs/1912.04564
-
[22]
Cosmos tokenizer: High-fidelity video and image compression for world models
NVIDIA Cosmos Tokenizer Team. Cosmos tokenizer: High-fidelity video and image compression for world models. GitHub Repository, 2024. URLhttps://github. com/NVIDIA/Cosmos-Tokenizer
2024
-
[23]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild, 2012. URLhttps://arxiv.org/ abs/1212.0402
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[24]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Ro- former: Enhanced transformer with rotary position embedding, 2023. URLhttps: //arxiv.org/abs/2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges, 2019. URLhttps://arxiv.org/abs/1812.01717
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
Attention is all you need
Ashish Kakwani Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS), 2017. KEVIN, CHHA Y A, SAI, GOURANGA, BABU, RAJESH: ADAPTIVE TOKENISA TION17
2017
-
[27]
Larp: Tokenizing videos with a learned autoregressive generative prior
Hanyu Wang, Saksham Suri, Yixuan Ren, Hao Chen, and Abhinav Shrivas- tava. Larp: Tokenizing videos with a learned autoregressive generative prior. ArXiv, abs/2410.21264, 2024. URLhttps://api.semanticscholar.org/ CorpusID:273654612
-
[28]
Omnitokenizer: A joint image-video tokenizer for visual generation
Junke Wang, Yi Jiang, Zehuan Yuan, Binyue Peng, Zuxuan Wu, and Yu-Gang Jiang. Omnitokenizer: A joint image-video tokenizer for visual generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[29]
ElasticTok: Adaptive tokenization for image and video
Content Yan et al. ElasticTok: Adaptive tokenization for image and video. InInterna- tional Conference on Learning Representations (ICLR) Under Review, 2024
2024
-
[30]
VideoGPT: Video generation using VQ-V AE and transformers.arXiv preprint arXiv:2104.10540, 2021
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. VideoGPT: Video generation using VQ-V AE and transformers.arXiv preprint arXiv:2104.10540, 2021
-
[31]
arXiv preprint arXiv:2410.08368 , year=
Wilson Yan, Matei Zaharia, V olodymyr Mnih, Pieter Abbeel, Aleksandra Faust, and Hao Liu. Elastictok: Adaptive tokenization for image and video.arXiv preprint arXiv:2410.08368, 2024
-
[32]
Infotok: Adaptive discrete video tokenizer via information-theoretic compression
Haotian Ye et al. Infotok: Adaptive discrete video tokenizer via information-theoretic compression. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[33]
Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G
Lijun Yu, José Lezama, Nitesh Bharadwaj Gundavarapu, Luca Versari, Kihyuk Sohn, David C. Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G. Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A. Ross, and Lu Jiang. Language model beats diffusion – tokenizer is key to visual generation. 2023. URLhttps: //api.semanticscholar.org/CorpusID:263830733
2023
-
[34]
Language model beats diffusion – tokenizer is key to visual generation
Lijun Yu, José Lezama, Yu Cheng, Huiwen Chang, Han Zhang, Jianchao Yuan, Jiahui Gu, Lu Jiang, Yong Li, Liangliang Jiang, et al. Language model beats diffusion – tokenizer is key to visual generation. InInternational Conference on Learning Repre- sentations (ICLR), 2024
2024
-
[35]
Magvit: Masked generative video transformer.CVPR, 2023
Lijun Yu et al. Magvit: Masked generative video transformer.CVPR, 2023
2023
-
[36]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric, 2018. URLhttps: //arxiv.org/abs/1801.03924
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Cv-vae: A compatible video vae for latent generative video models,
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, and Ying Shan. Cv-vae: A compatible video vae for latent generative video models,
-
[38]
URLhttps://arxiv.org/abs/2405.20279. 18KEVIN, CHHA Y A, SAI, GOURANGA, BABU, RAJESH: ADAPTIVE TOKENISA TION Supplementary Material: Adaptive Tokenisation Via Temporal Redundancy Masking And Latent Inpainting A Empirical Threshold Calibration Our mechanism relies on a fixed scalar threshold,τ, which dictates whether the temporal L1 difference∆(t ′,y,x)betw...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.