The Tell-Tale Norm: ell₂ Magnitude as a Signal for Reasoning Dynamics in Large Language Models
Pith reviewed 2026-06-28 02:05 UTC · model grok-4.3
The pith
The l2 norm of hidden states tracks reasoning intensity inside large language models and bounds SAE feature activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
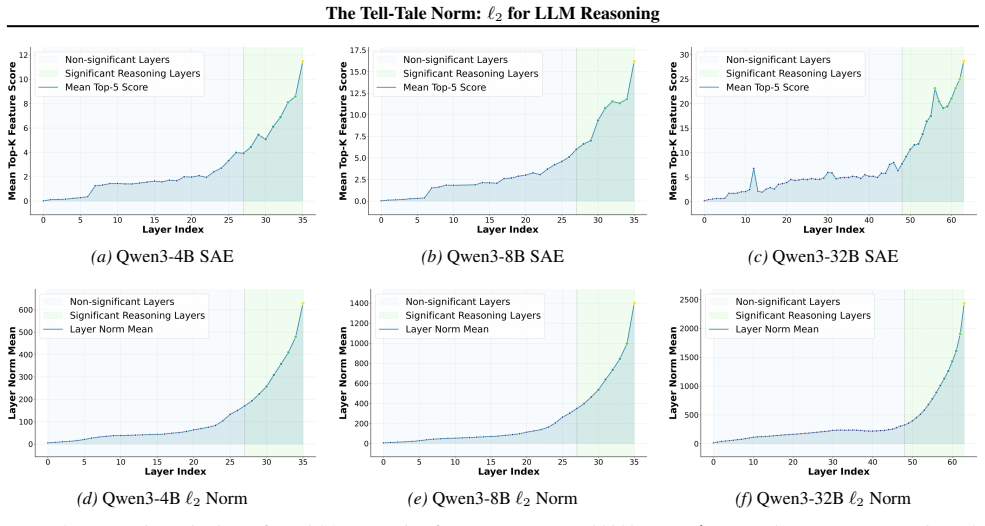
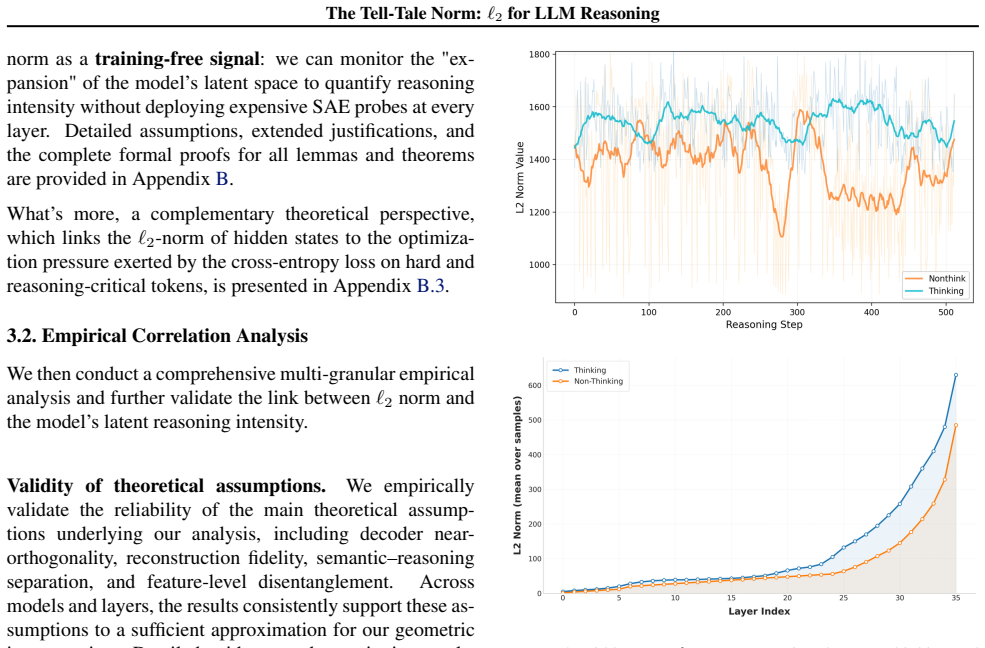
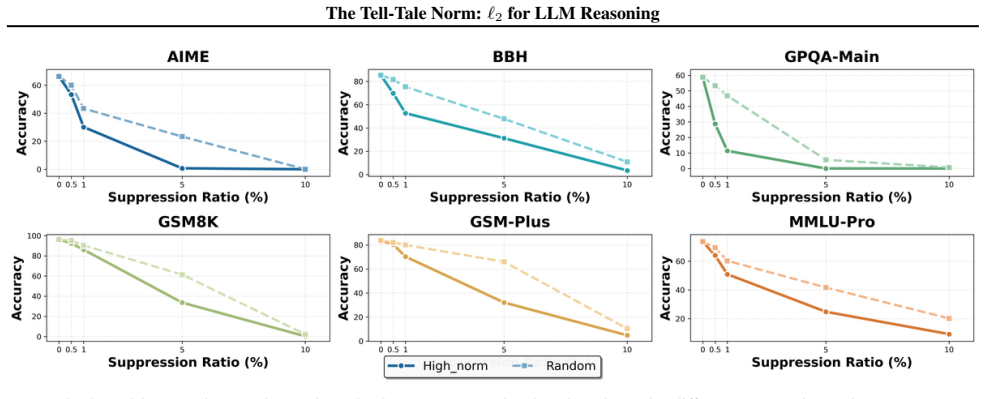
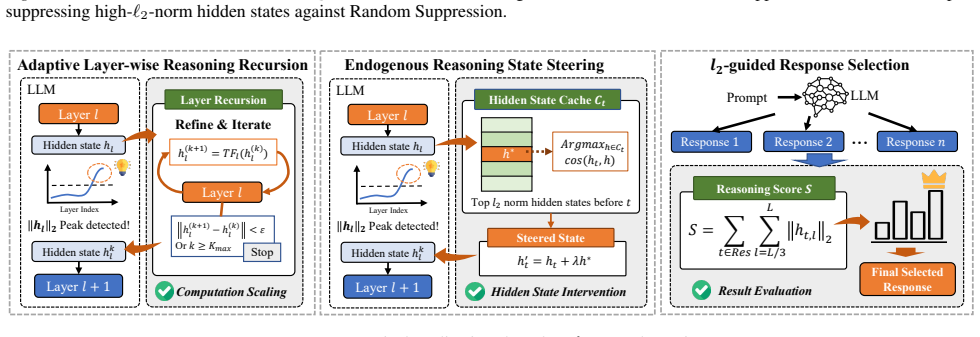
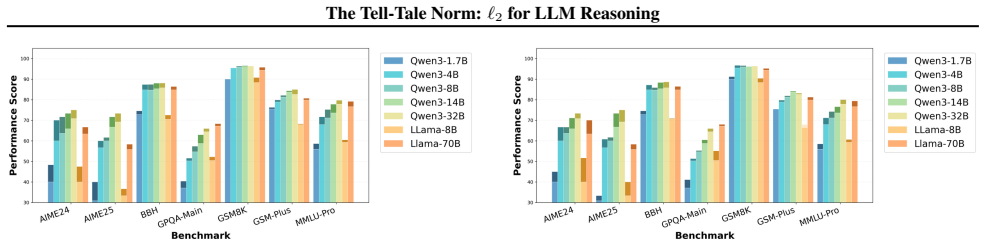
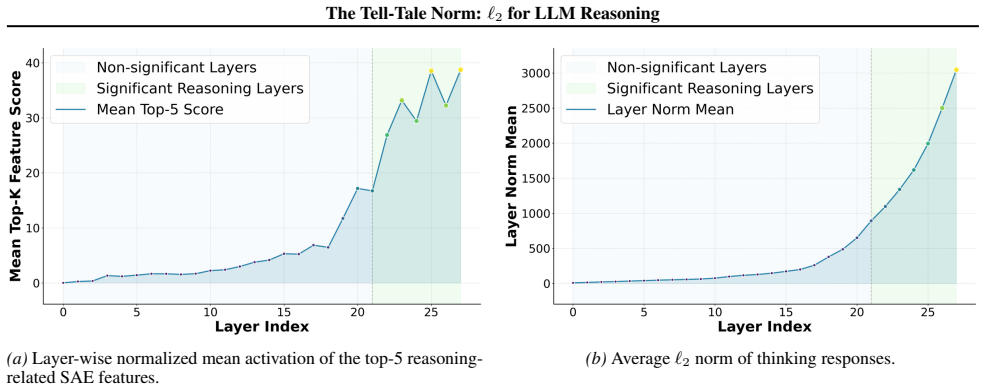
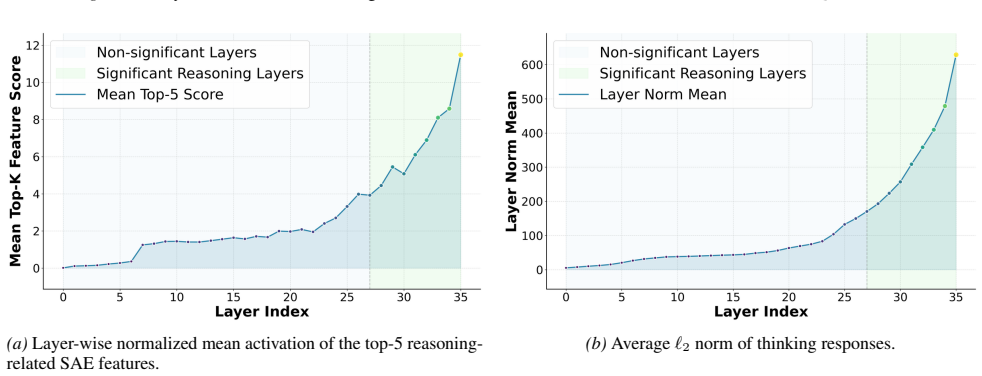
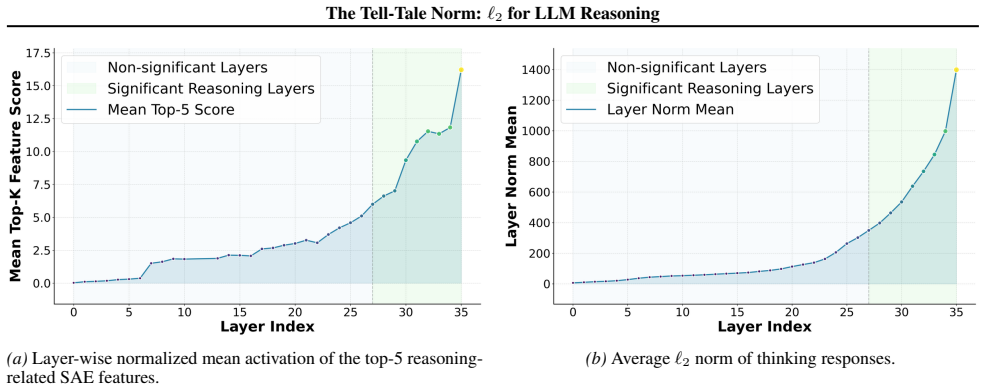
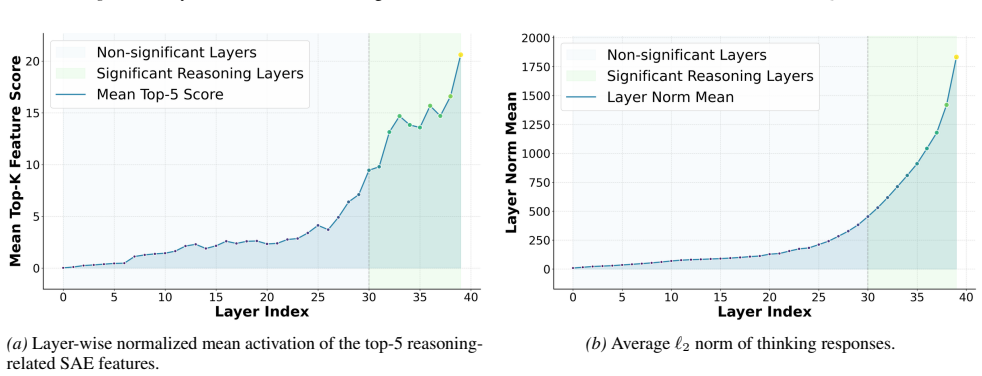
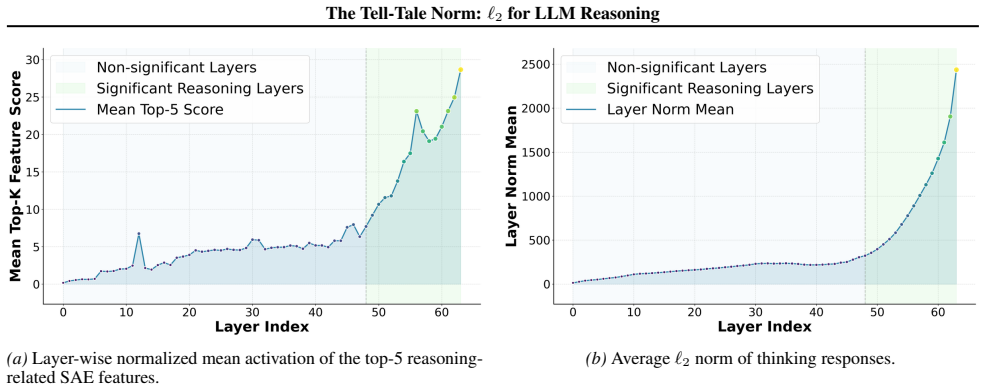
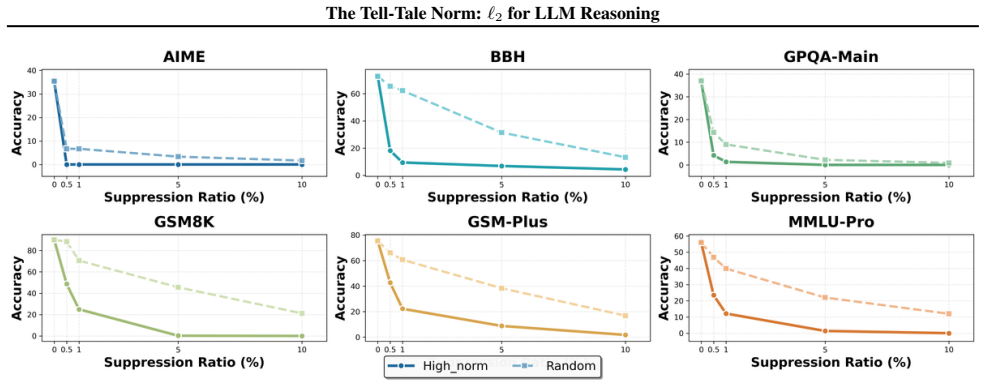
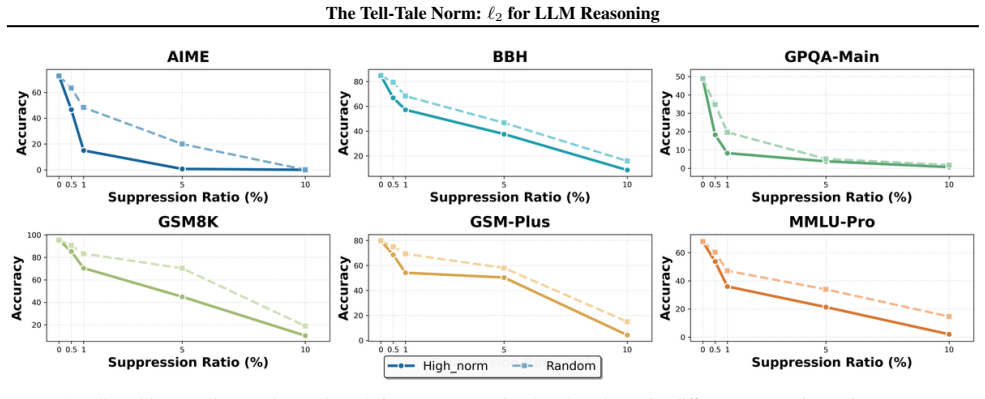
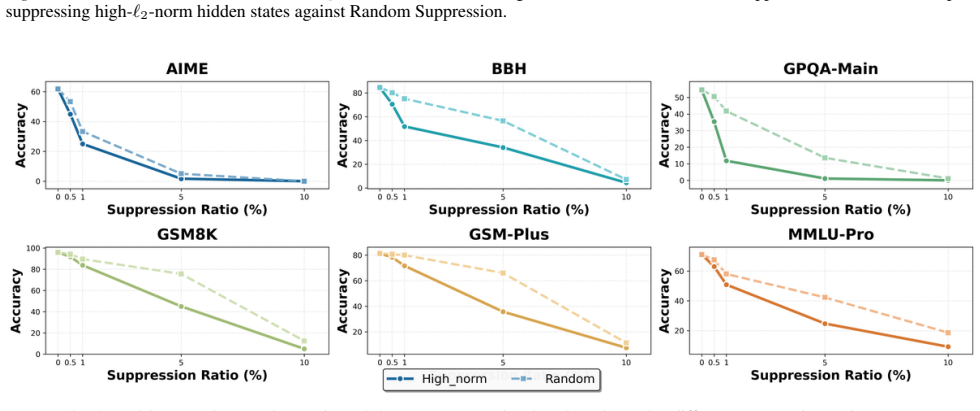
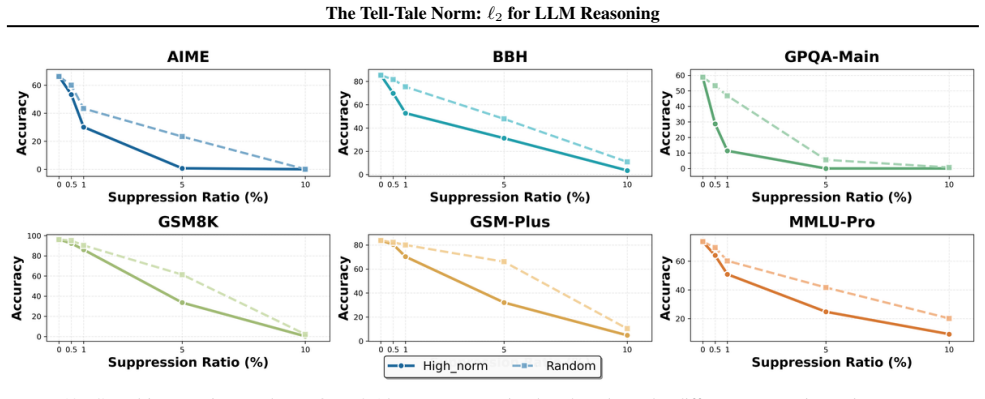
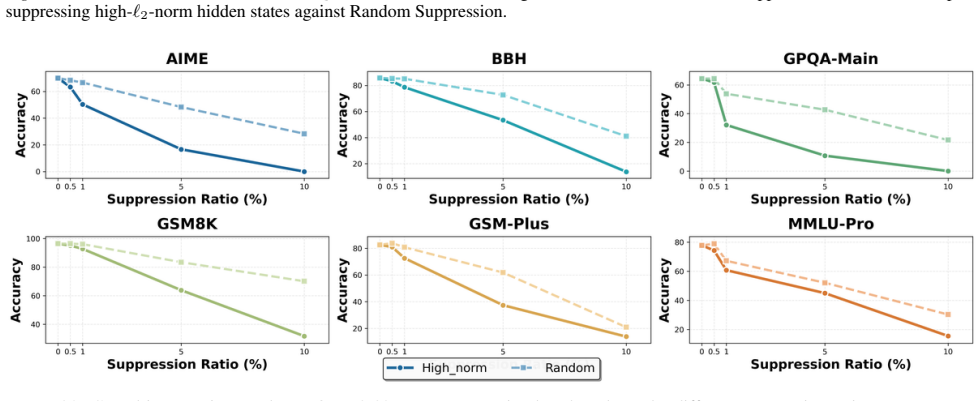
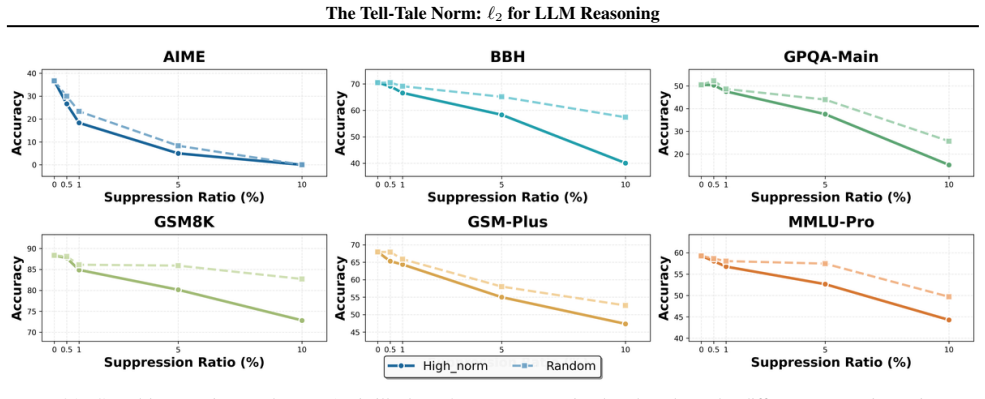
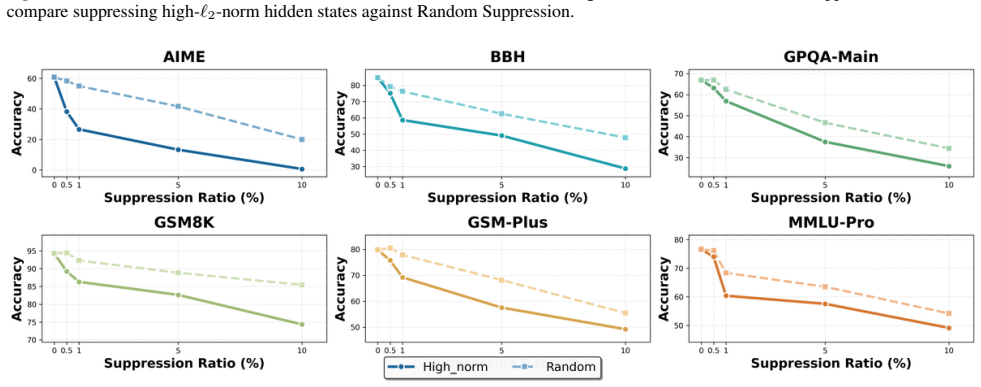
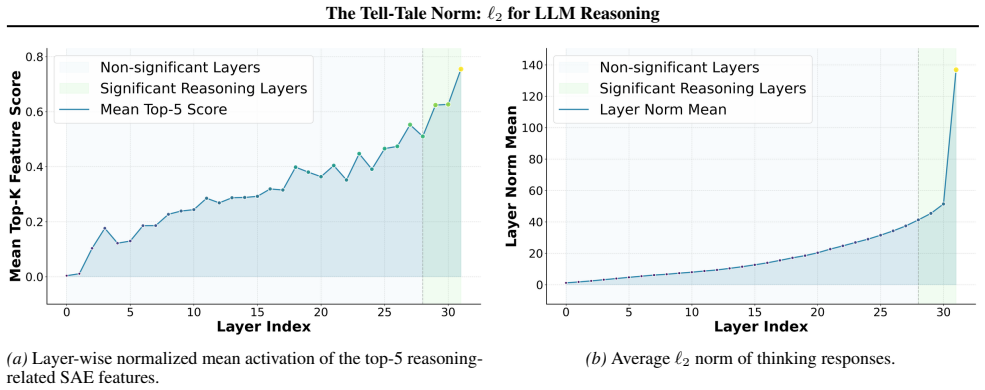
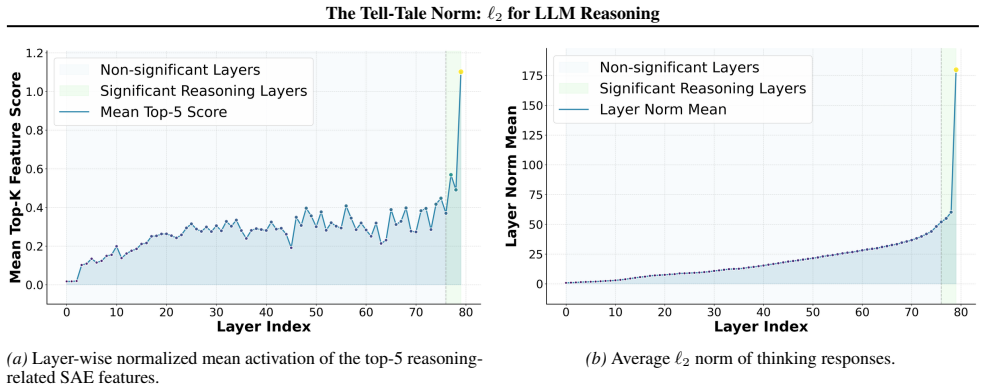
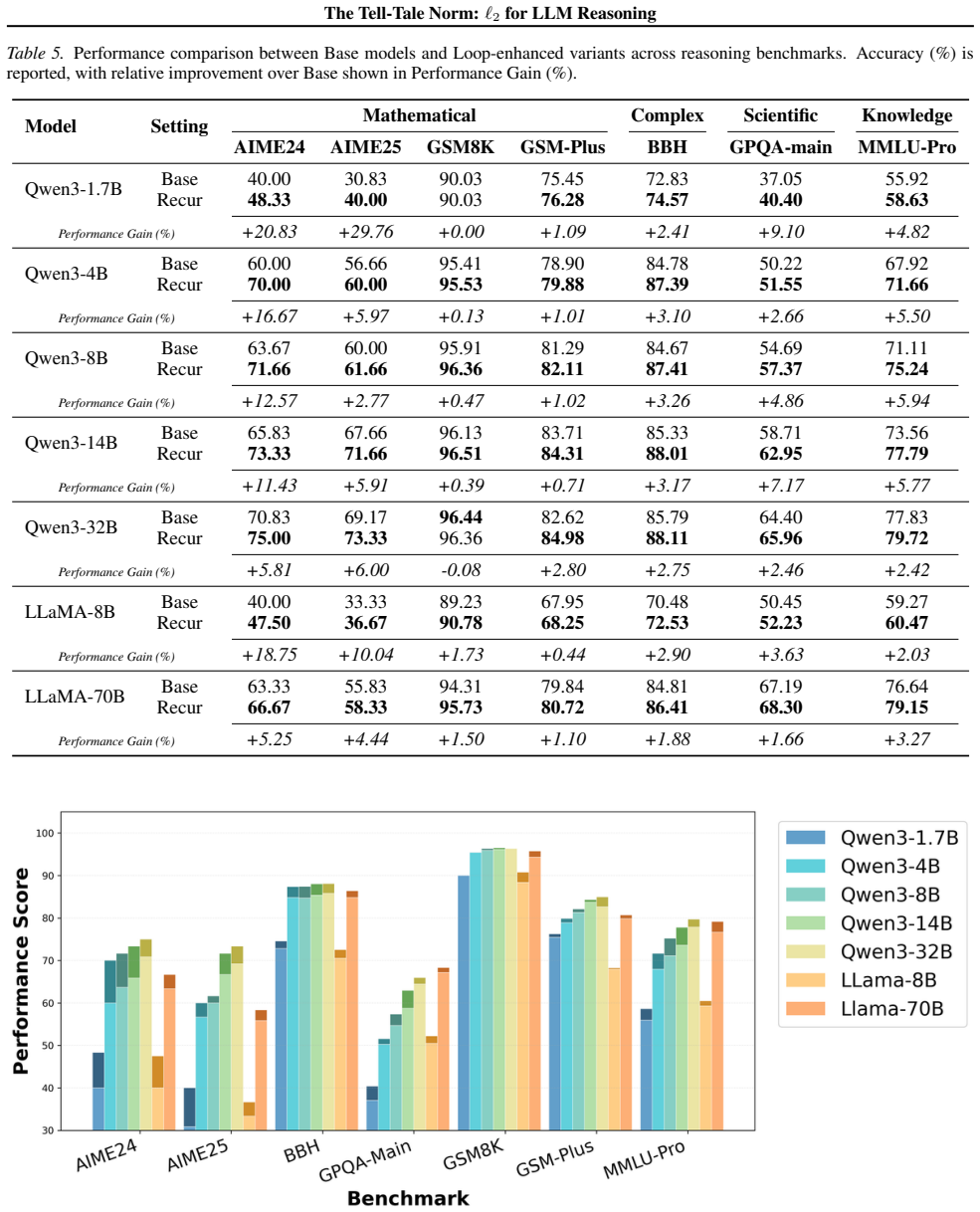
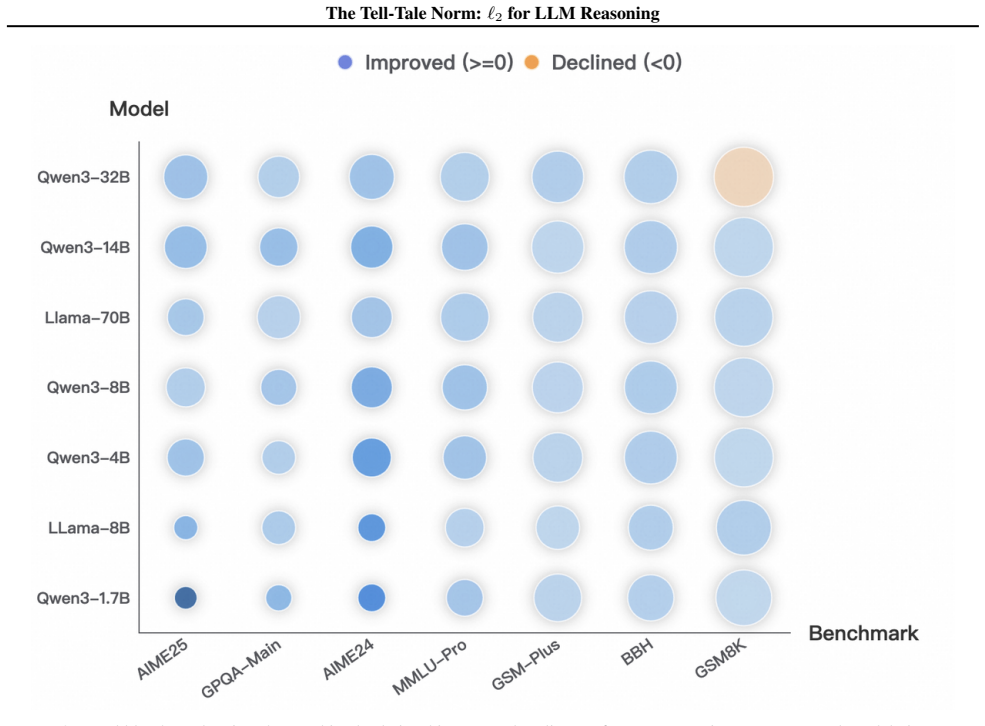
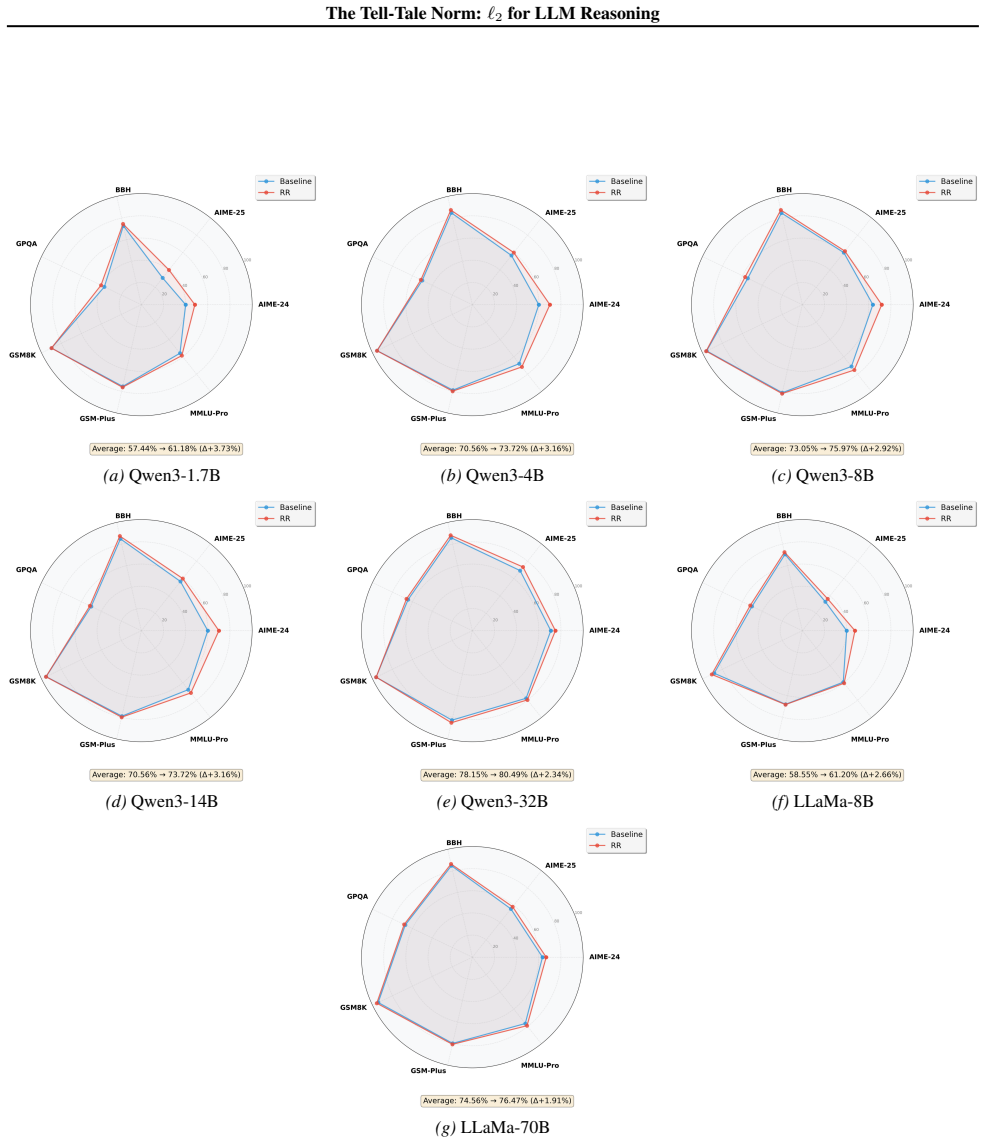
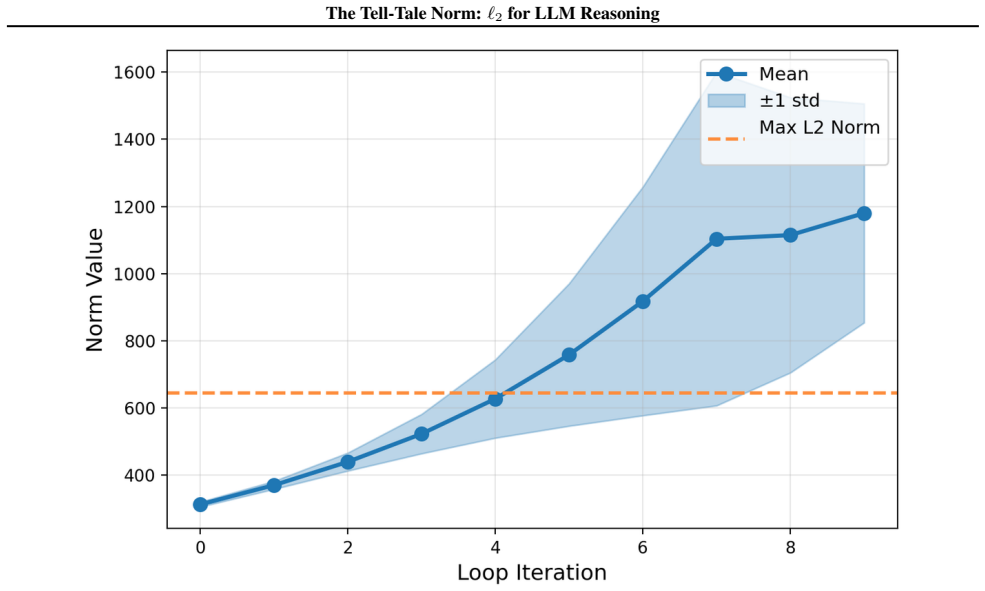
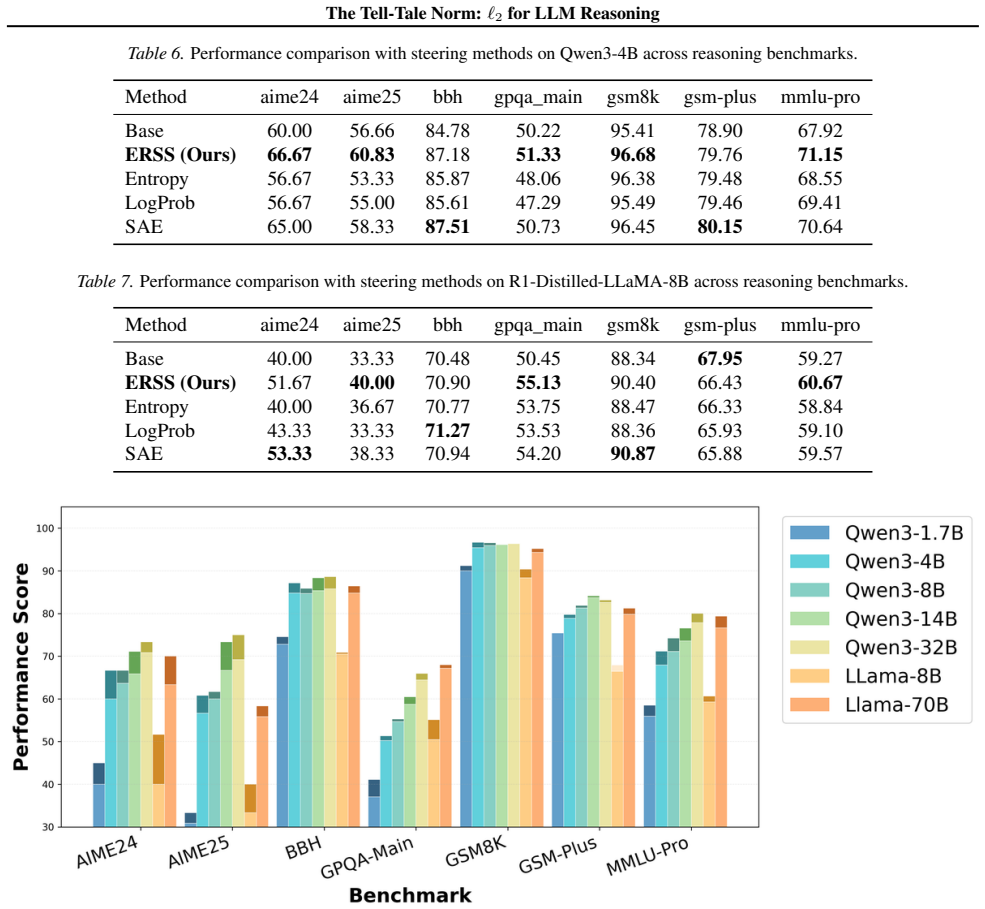
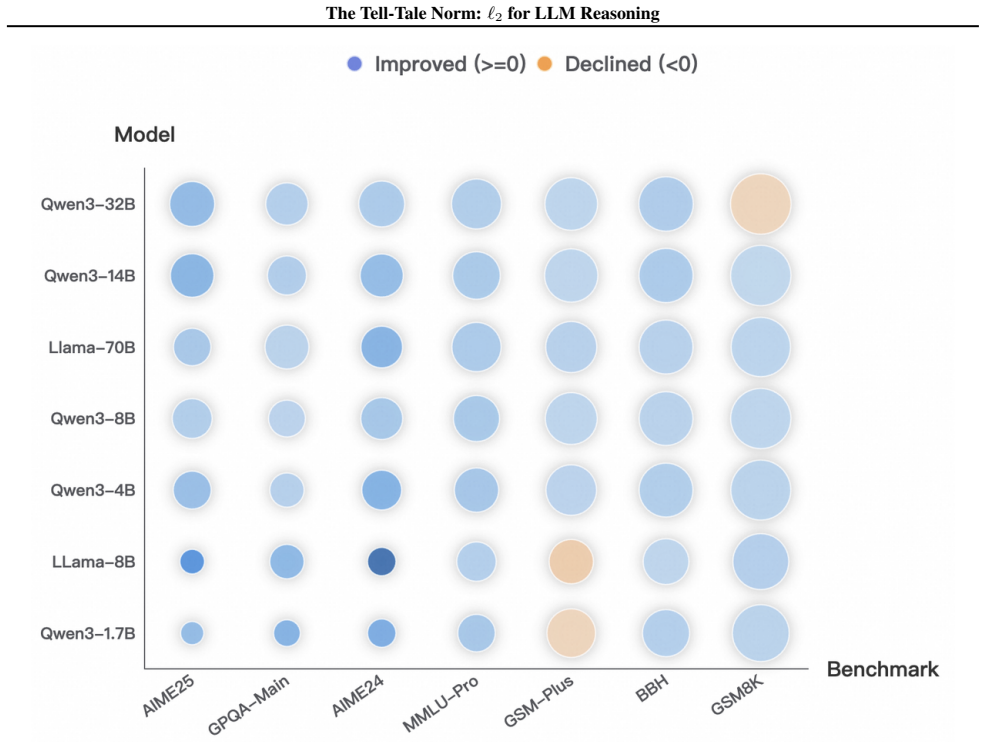
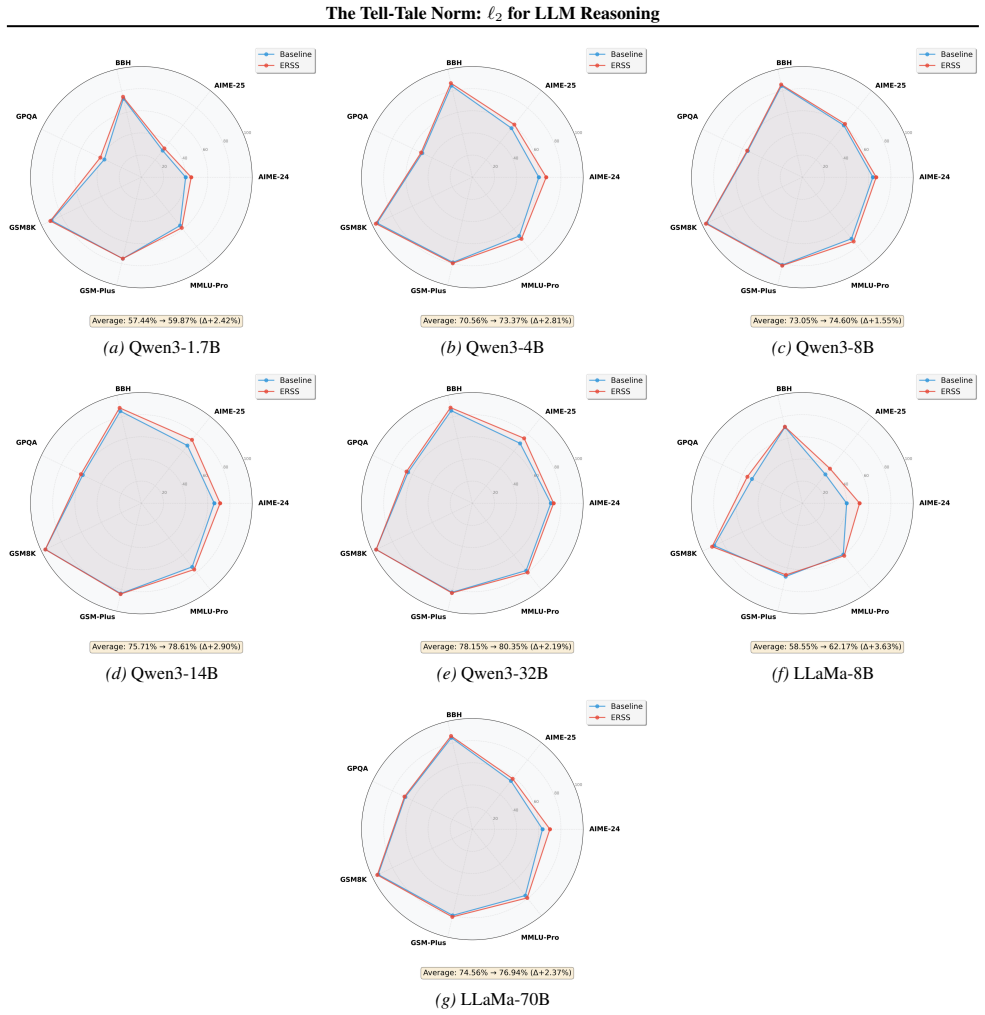
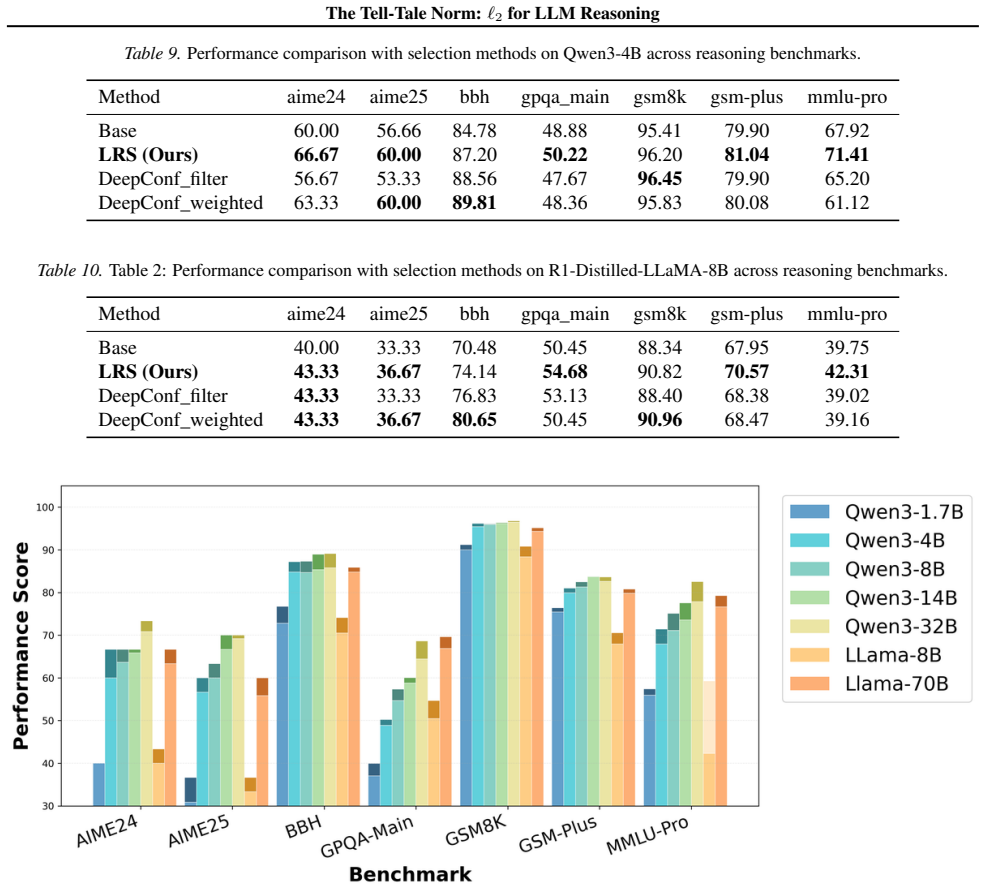
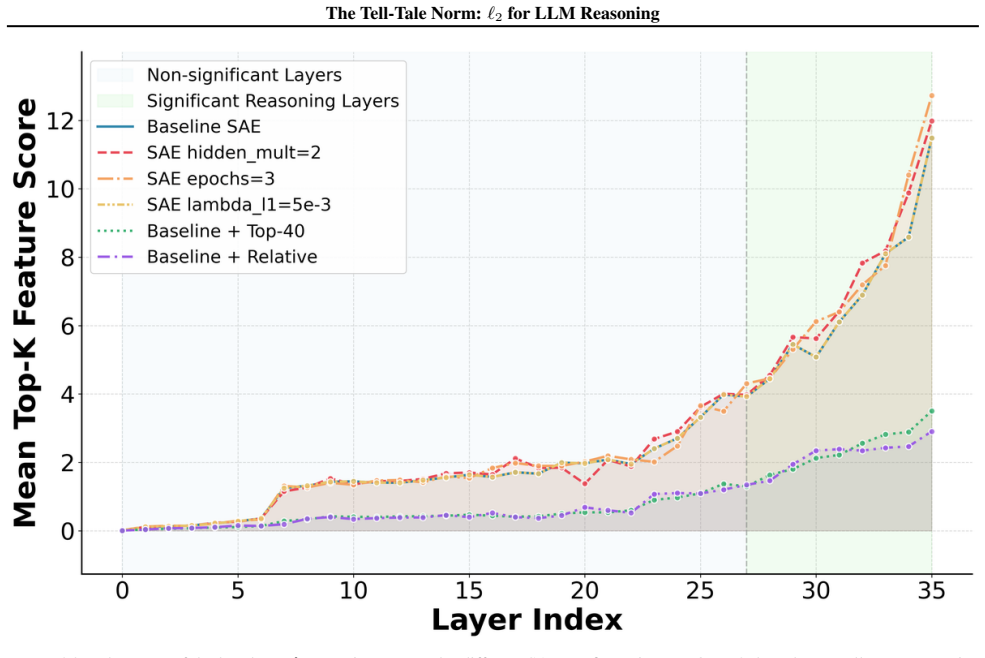
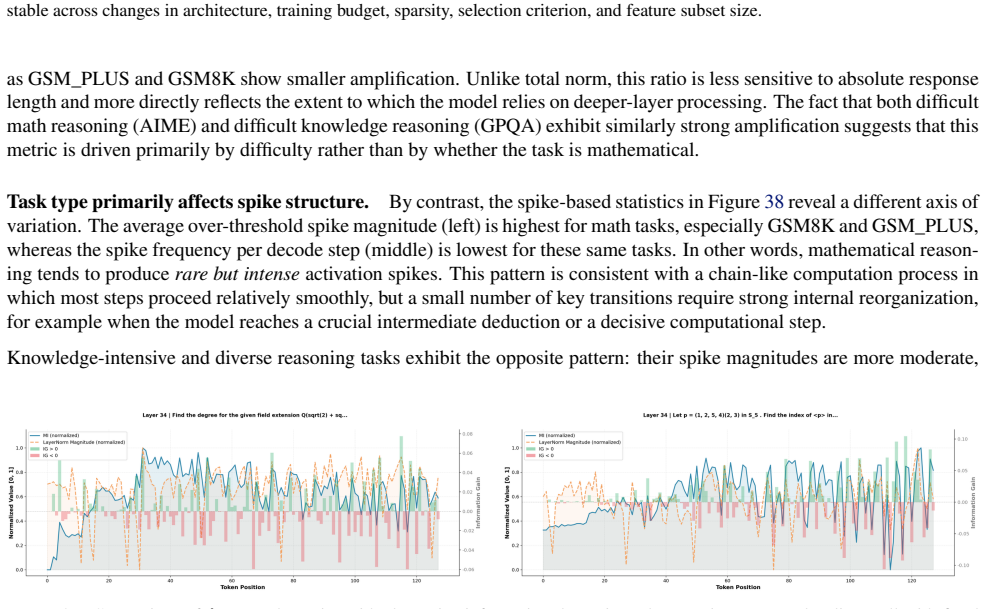
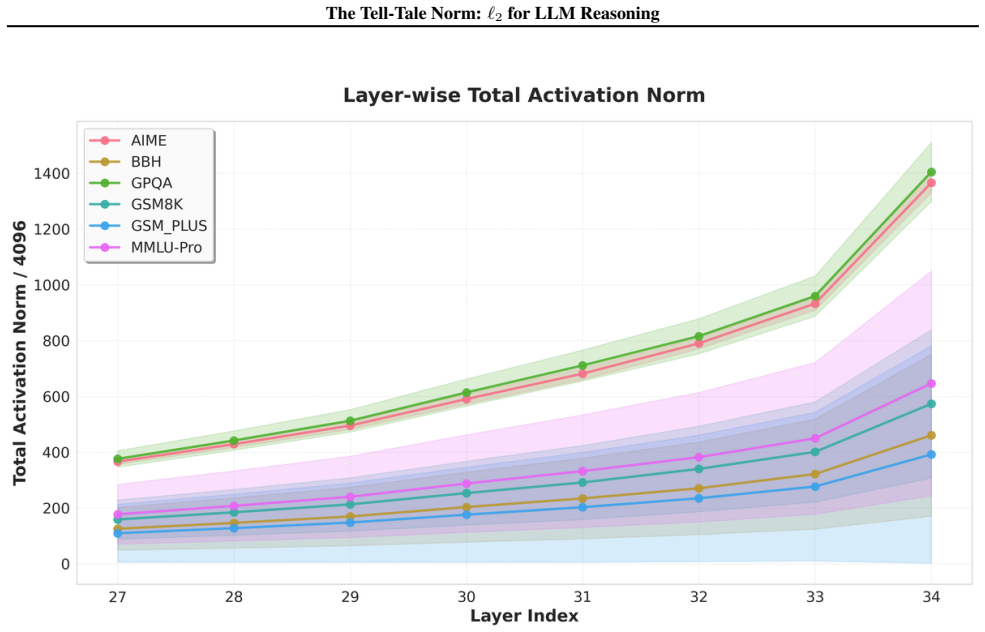
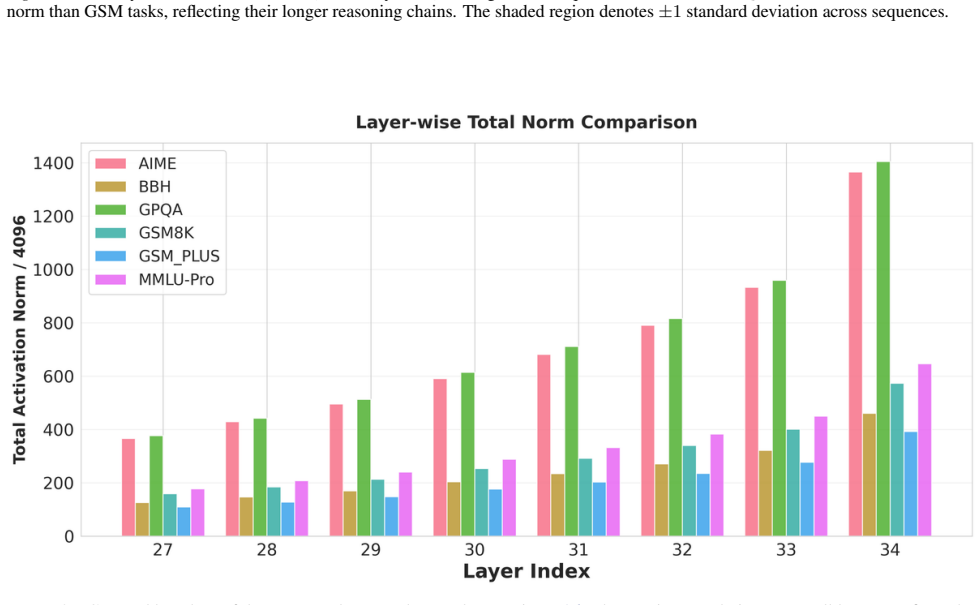
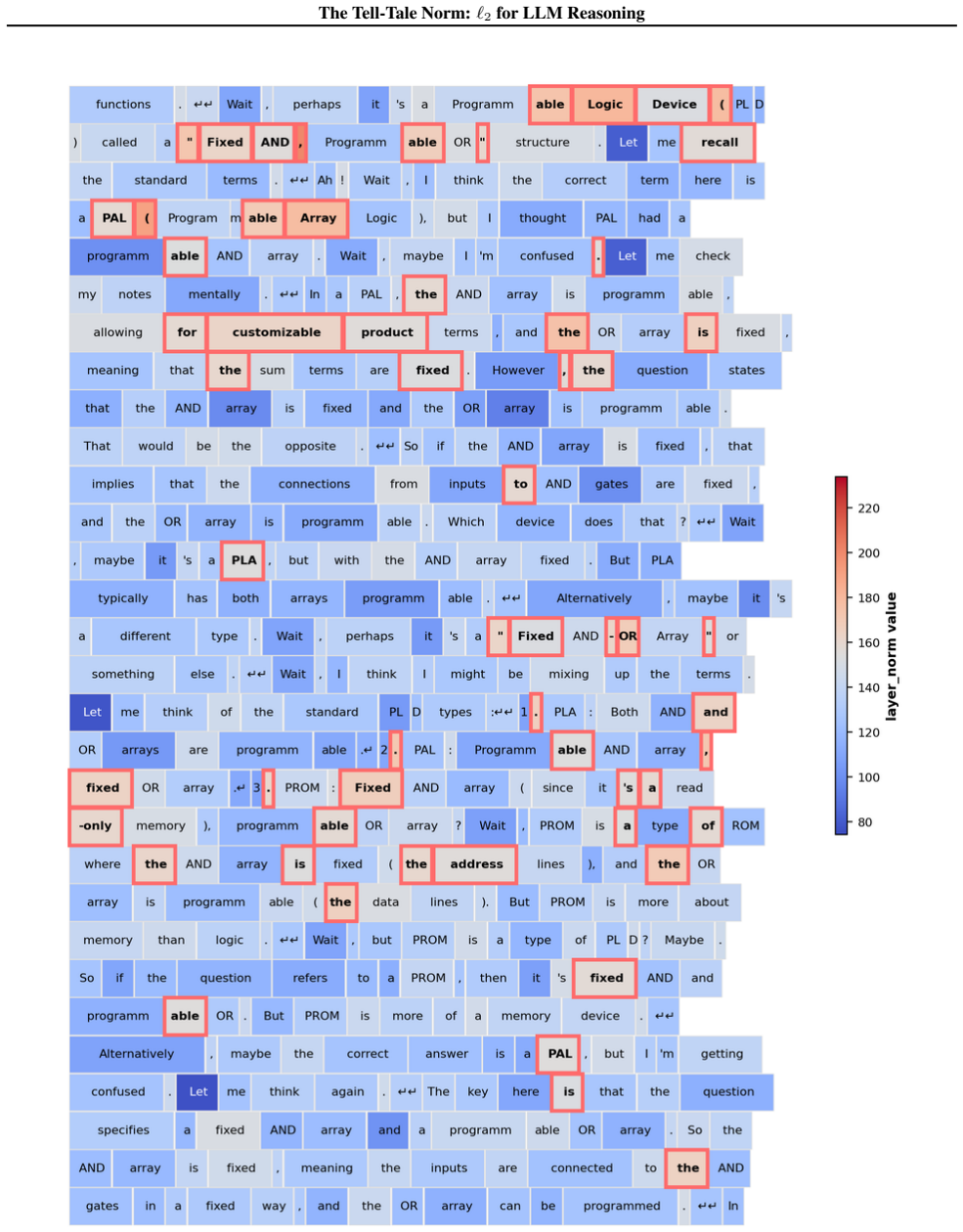
We show that the ℓ₂ norm of hidden states functions as an endogenous signal of reasoning intensity. Sparse autoencoders reveal a sharp increase in reasoning-feature activations concentrated in late layers; we prove that the l2 norm bounds the activation strength of these features. Correlation analysis and causal interventions confirm that elevated norms align with critical reasoning steps. This relation yields three test-time scaling techniques—Adaptive Layer-wise Reasoning Recursion, Endogenous Reasoning State Steering, and l2-guided Response Selection—that require no additional training and raise performance across model families and benchmarks.
What carries the argument
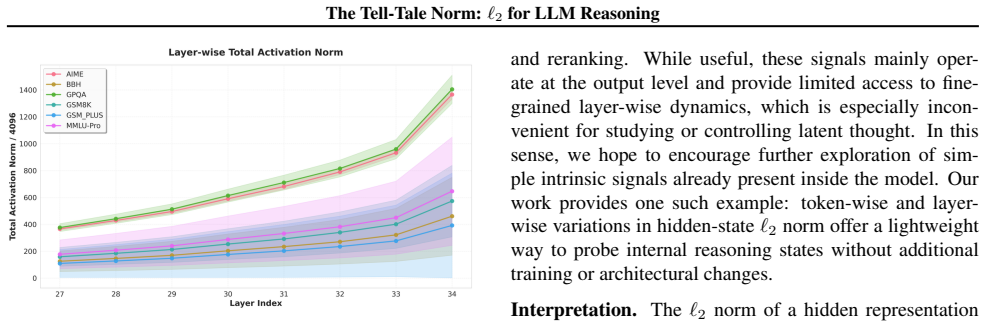
The ℓ₂ norm of hidden states, which bounds the activation strength of sparse-autoencoder reasoning features and thereby signals layer-wise reasoning intensity.
If this is right
- Adaptive Layer-wise Reasoning Recursion uses rising l2 norms to decide when to recurse on a layer, increasing effective reasoning depth only where needed.
- Endogenous Reasoning State Steering adjusts hidden states toward higher-norm regimes to strengthen reasoning features without external models.
- l2-guided Response Selection picks among candidate outputs the one whose hidden-state trajectory shows the strongest norm signature of reasoning.
- The three techniques are compatible with existing inference engines and produce measurable gains on standard reasoning benchmarks across architectures.
Where Pith is reading between the lines
- If the norm reliably marks reasoning, similar magnitude patterns could be checked in non-reasoning tasks such as factual recall or creative generation to test generality.
- The bound suggests that simple norm clipping or boosting during generation might serve as a lightweight alternative to full SAE-based steering.
- Applying the same observational pipeline to multimodal or agentic models could reveal whether l2 dynamics generalize beyond text-only reasoning.
Load-bearing premise
Sparse autoencoders trained on LLM activations can reliably isolate features that correspond to the model's actual internal reasoning steps.
What would settle it
A direct intervention that raises or lowers the l2 norm of hidden states at specific layers without changing the model's reasoning performance or the measured SAE feature activations would falsify the claimed link.
Figures



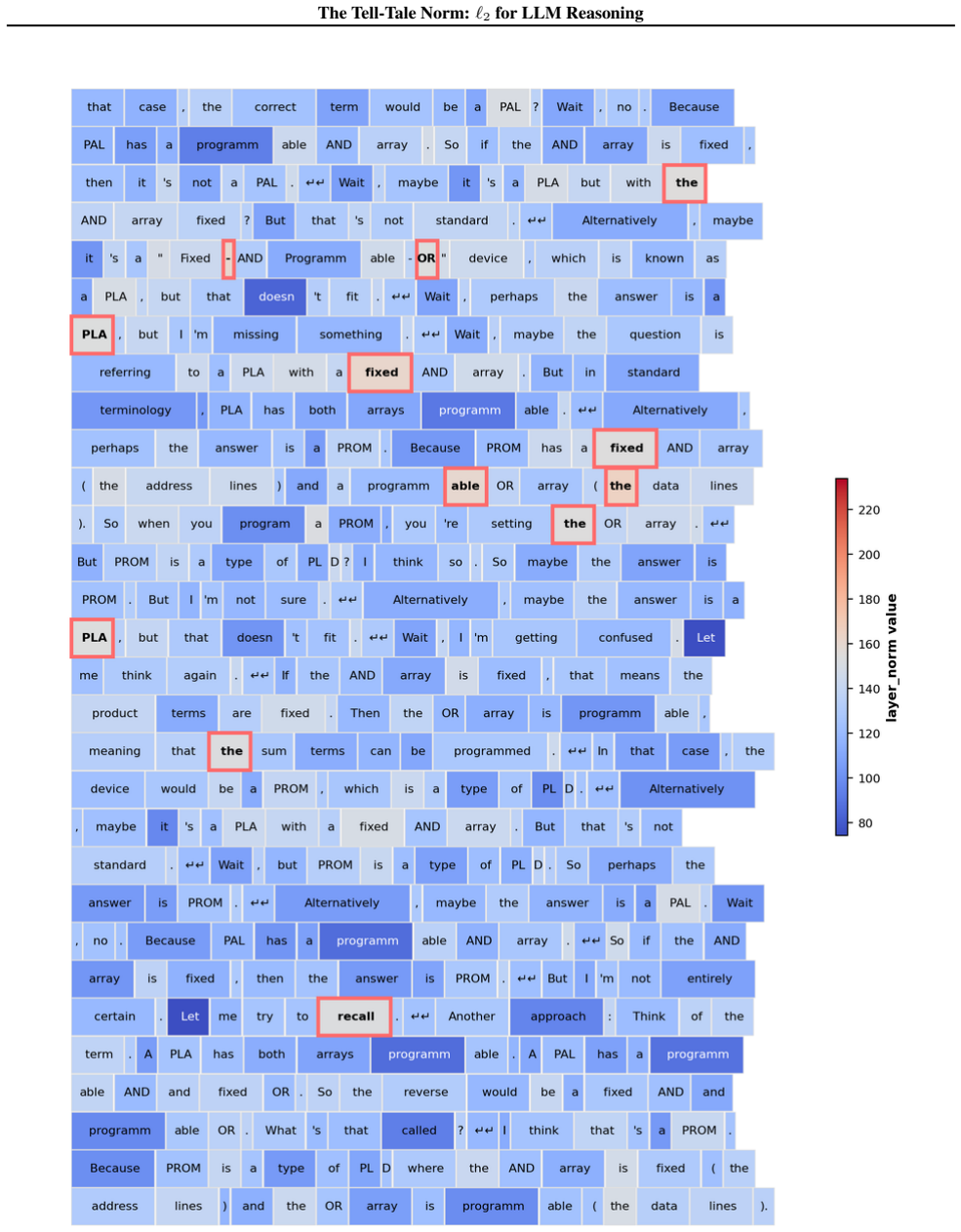
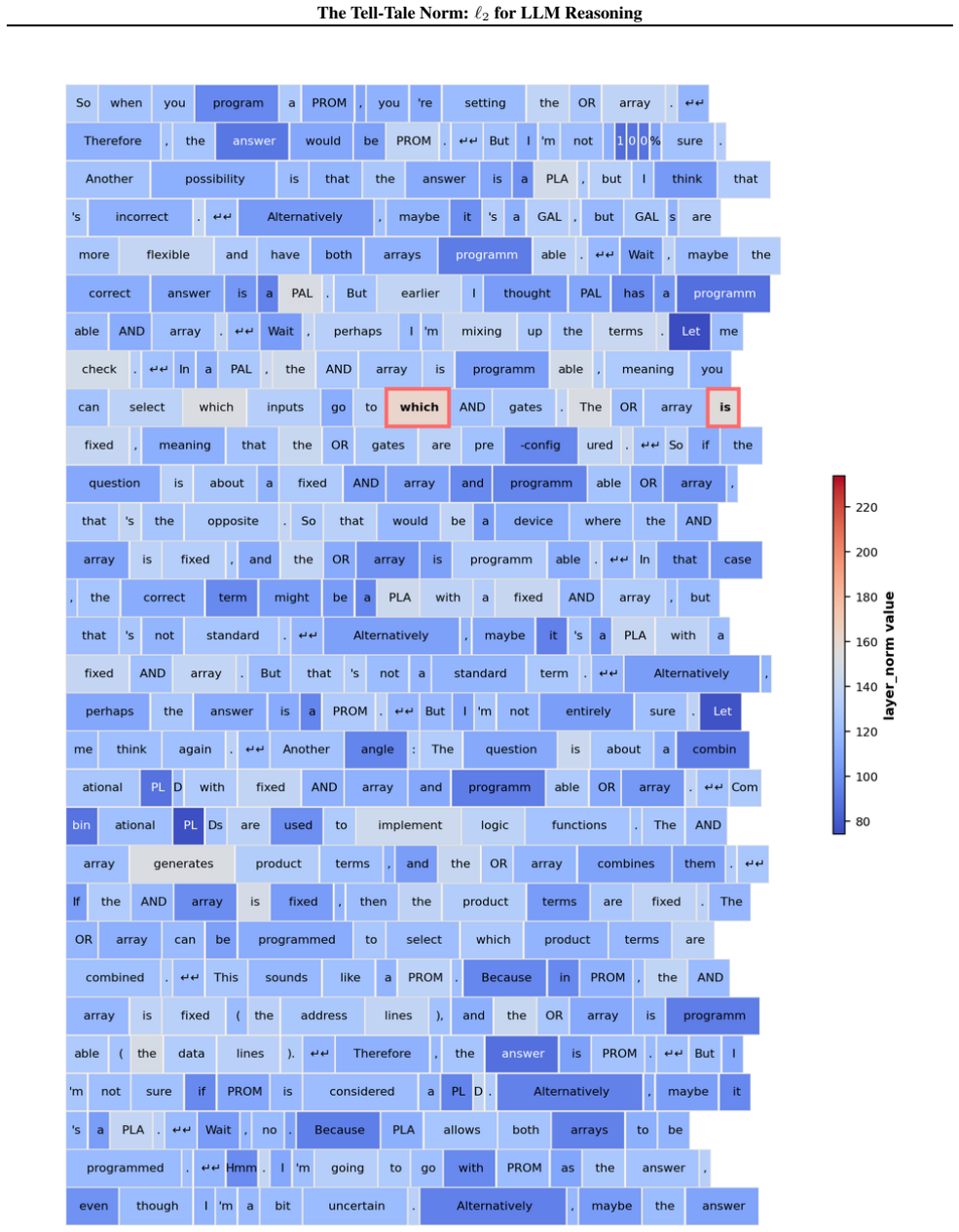
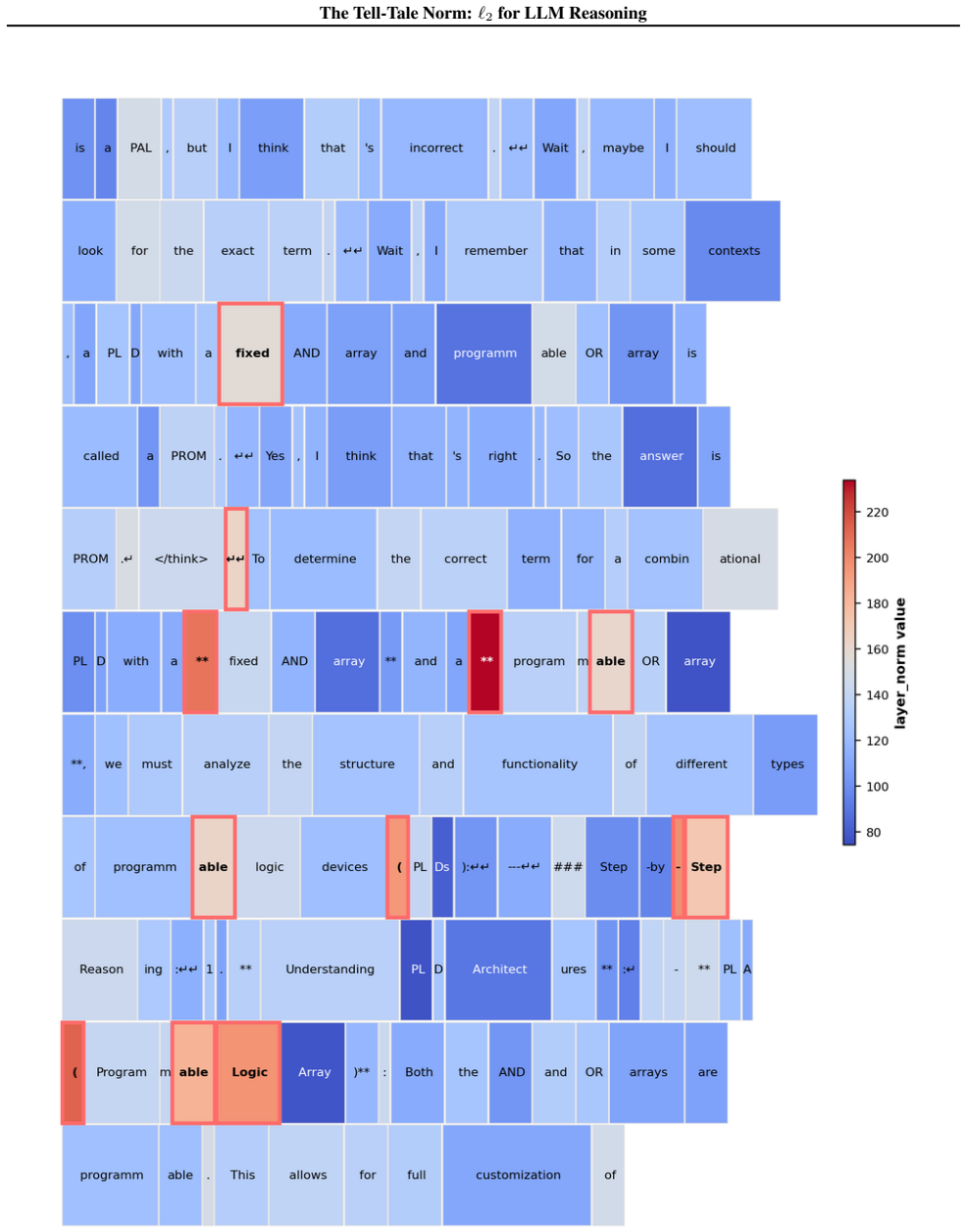
read the original abstract
Recent work has sought to understand Large Language Models (LLMs) reasoning, yet a principled, model-intrinsic signal that captures its layer-wise reasoning dynamics remains underexplored. We bridge this gap by demonstrating that the l2 norm of hidden states serves as an endogenous signal of the model's reasoning intensity. Using Sparse Autoencoders (SAEs) as a diagnostic probe, we observe that LLMs' internal reasoning is marked by a sharp increase in reasoning feature activations concentrated in late layers. Motivated by this pattern, we establish a formal link between reasoning intensity and the model's latent geometry and theoretically prove that the l2 norm of hidden states bounds the activation strength of SAE reasoning features. Empirical correlation analysis and causal interventions further validate the l2 norm as a faithful indicator, where heightened norms consistently correspond to critical reasoning steps. We then introduce three test-time scaling techniques guided by l2 norms: (i) Adaptive Layer-wise Reasoning Recursion, (ii) Endogenous Reasoning State Steering, and (iii) l2-guided Response Selection, which requires no additional training or data and is compatible with advanced inference engines. Experiments across model architectures and benchmarks show that l2-norm-based techniques significantly improve reasoning performance, offering a principled yet simple lens to perceive and control LLM latent reasoning dynamics. Our code is available at https://github.com/zjy1298/The-Tell-Tale-Norm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the ℓ₂ norm of hidden states provides an endogenous, model-intrinsic signal of reasoning intensity in LLMs. Using SAEs as probes, it reports sharp increases in 'reasoning feature' activations in late layers, asserts a theoretical proof that ||h||₂ bounds the activation strength of these SAE features, validates the link via correlations and causal interventions, and introduces three norm-guided test-time scaling methods (Adaptive Layer-wise Reasoning Recursion, Endogenous Reasoning State Steering, and ℓ₂-guided Response Selection) that improve performance on reasoning benchmarks without training.
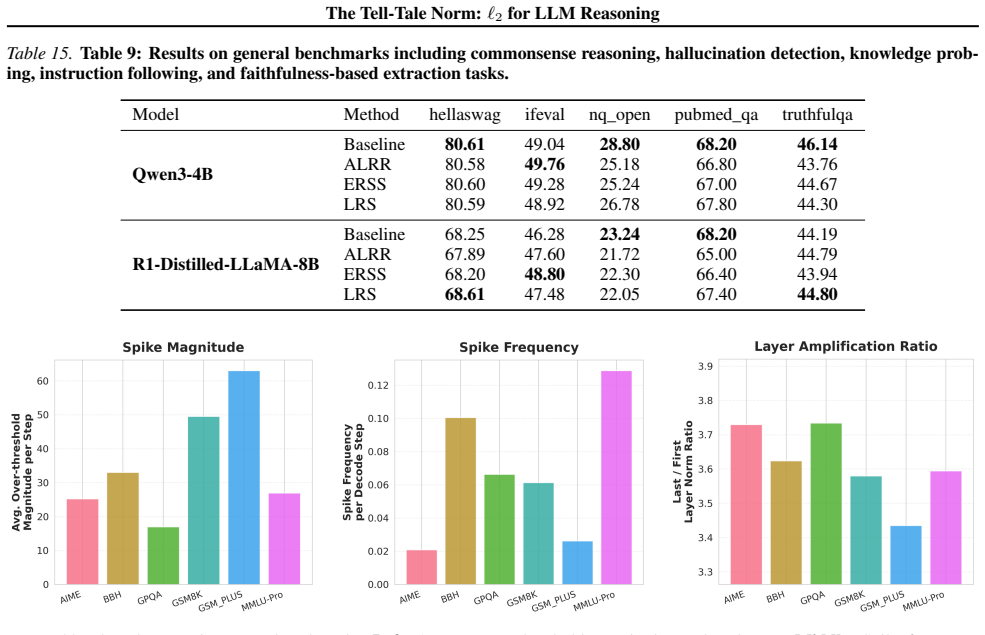
Significance. If the claimed theoretical bound holds and the SAE features veridically isolate reasoning computations, the work would supply a simple, training-free mechanism for monitoring and steering internal reasoning dynamics across architectures. The open-source code strengthens reproducibility. However, the absence of the derivation and limited validation of the feature labeling limit the immediate impact.
major comments (3)
- [Abstract / theoretical proof] Abstract and theoretical proof section: the manuscript asserts a 'theoretical proof' that the ℓ₂ norm of hidden states bounds SAE reasoning-feature activations, yet provides no derivation steps, stated assumptions, or bounding equation. This is load-bearing for the central formal-link claim and prevents verification of whether the bound is non-trivial or follows from SAE properties.
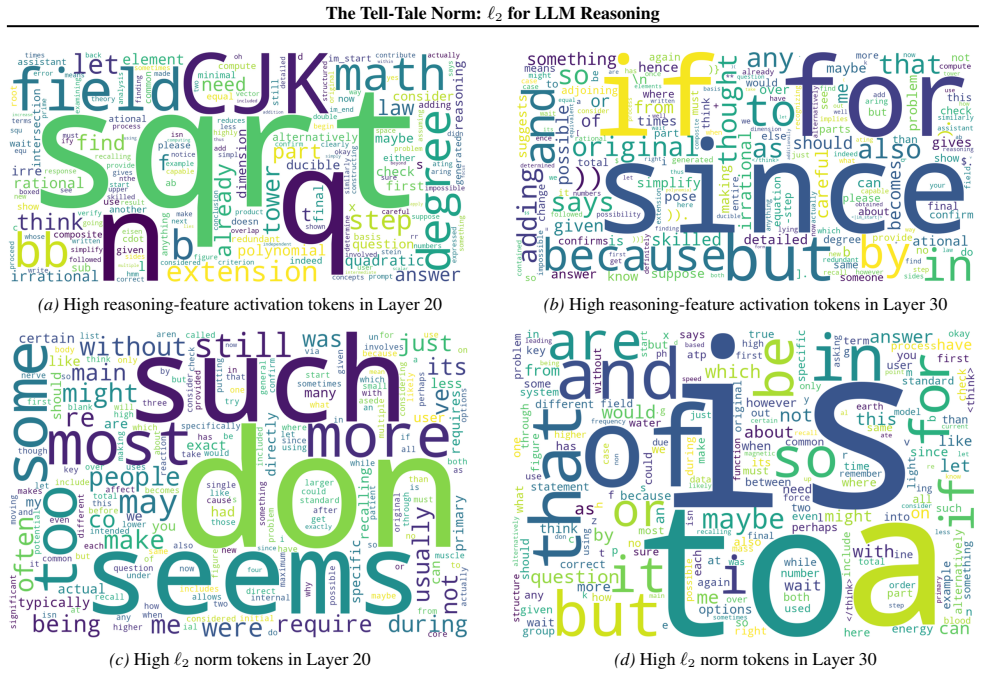
- [SAE diagnostic and causal intervention sections] SAE feature identification (observational and causal sections): features are labeled 'reasoning' on the basis of late-layer activation spikes, but no independent verification (e.g., targeted ablation that impairs multi-step reasoning while preserving other capabilities, or comparison against lexical/control features) is described. This assumption is required for interpreting both the observational pattern and the subsequent bound as relating to reasoning intensity rather than correlated downstream effects.
- [Empirical correlation and causal sections] Empirical validation sections: correlation analysis and causal interventions are reported to 'further validate' the norm as a faithful indicator, but the manuscript supplies no dataset details, error bars, control conditions, or statistical tests, making it impossible to assess whether the reported improvements are robust or confounded.
minor comments (2)
- Notation for hidden states and SAE activations should be defined explicitly at first use (e.g., h_l for layer l) to improve readability.
- The three proposed test-time methods would benefit from a short pseudocode or algorithmic box to clarify how the ℓ₂ norm is computed and applied at inference time.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity, completeness, and verifiability.
read point-by-point responses
-
Referee: [Abstract / theoretical proof] Abstract and theoretical proof section: the manuscript asserts a 'theoretical proof' that the ℓ₂ norm of hidden states bounds SAE reasoning-feature activations, yet provides no derivation steps, stated assumptions, or bounding equation. This is load-bearing for the central formal-link claim and prevents verification of whether the bound is non-trivial or follows from SAE properties.
Authors: We agree the submitted manuscript omitted the explicit derivation steps, assumptions, and bounding equation in the main text. The bound follows directly from the linear decoder of the SAE and the definition of the ℓ₂ norm (specifically, each feature activation a_i satisfies |a_i| ≤ ||h||₂ ⋅ ||d_i||₂ where d_i is the decoder vector). We will add a dedicated subsection with the full step-by-step derivation, stated assumptions (e.g., unit-norm decoder columns after normalization), and the resulting inequality in the revised version. revision: yes
-
Referee: [SAE diagnostic and causal intervention sections] SAE feature identification (observational and causal sections): features are labeled 'reasoning' on the basis of late-layer activation spikes, but no independent verification (e.g., targeted ablation that impairs multi-step reasoning while preserving other capabilities, or comparison against lexical/control features) is described. This assumption is required for interpreting both the observational pattern and the subsequent bound as relating to reasoning intensity rather than correlated downstream effects.
Authors: Feature labeling relies on the observed late-layer activation pattern together with the causal interventions already reported. We acknowledge that additional independent checks (targeted ablations on multi-step reasoning or explicit lexical/control feature comparisons) would strengthen the interpretation. We will add these analyses and comparisons in the revised manuscript. revision: yes
-
Referee: [Empirical correlation and causal sections] Empirical validation sections: correlation analysis and causal interventions are reported to 'further validate' the norm as a faithful indicator, but the manuscript supplies no dataset details, error bars, control conditions, or statistical tests, making it impossible to assess whether the reported improvements are robust or confounded.
Authors: We will expand the empirical sections to include full dataset specifications, error bars across runs, explicit control conditions, and statistical significance tests. These additions will allow readers to evaluate robustness directly. revision: yes
Circularity Check
No significant circularity; derivation chain remains independent of inputs
full rationale
The paper observes an empirical pattern via SAEs (late-layer reasoning feature spikes), then presents a separate theoretical proof that ||h||_2 bounds SAE feature activations, followed by distinct empirical correlations and interventions. No step reduces the central bound or claim to a fitted parameter, self-definition, or self-citation chain by construction. The SAE labeling step is an input assumption rather than a definitional loop, and the proof is framed as a mathematical link motivated by but not equivalent to the observation. This matches the default case of a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse Autoencoders (SAEs) trained on LLM hidden states can isolate features whose activations correspond to the model's internal reasoning process.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[2]
arXiv preprint arXiv:2411.19943 , year=
Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability , author=. arXiv preprint arXiv:2411.19943 , year=
-
[3]
arXiv preprint arXiv:2506.18167 , year=
Understanding reasoning in thinking language models via steering vectors , author=. arXiv preprint arXiv:2506.18167 , year=
-
[4]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[5]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[6]
Advances in Neural Information Processing Systems , volume=
Towards revealing the mystery behind chain of thought: a theoretical perspective , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2503.11314 , year=
Unlocking General Long Chain-of-Thought Reasoning Capabilities of Large Language Models via Representation Engineering , author=. arXiv preprint arXiv:2503.11314 , year=
-
[8]
arXiv preprint arXiv:2503.18878 , year=
I Have Covered All the Bases Here: Interpreting Reasoning Features in Large Language Models via Sparse Autoencoders , author=. arXiv preprint arXiv:2503.18878 , year=
-
[9]
arXiv preprint arXiv:2506.01939 , year=
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. arXiv preprint arXiv:2506.01939 , year=
-
[10]
arXiv preprint arXiv:2503.05613 , year=
A survey on sparse autoencoders: Interpreting the internal mechanisms of large language models , author=. arXiv preprint arXiv:2503.05613 , year=
-
[11]
arXiv preprint arXiv:2507.22928 , year=
How does chain of thought think? mechanistic interpretability of chain-of-thought reasoning with sparse autoencoding , author=. arXiv preprint arXiv:2507.22928 , year=
-
[12]
arXiv preprint arXiv:2505.17697 , year=
Activation Control for Efficiently Eliciting Long Chain-of-thought Ability of Language Models , author=. arXiv preprint arXiv:2505.17697 , year=
-
[13]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
s1: Simple test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[14]
arXiv preprint arXiv:2503.09567 , year=
Towards reasoning era: A survey of long chain-of-thought for reasoning large language models , author=. arXiv preprint arXiv:2503.09567 , year=
-
[15]
arXiv preprint arXiv:2505.15634 , year=
Feature Extraction and Steering for Enhanced Chain-of-Thought Reasoning in Language Models , author=. arXiv preprint arXiv:2505.15634 , year=
-
[16]
arXiv preprint arXiv:2601.03595 , year=
Controllable LLM Reasoning via Sparse Autoencoder-Based Steering , author=. arXiv preprint arXiv:2601.03595 , year=
-
[17]
arXiv preprint arXiv:2512.23988 , year=
Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process , author=. arXiv preprint arXiv:2512.23988 , year=
-
[18]
2023 , howpublished =
Towards Monosemanticity: Decomposing Language Models with Dictionary Learning , author =. 2023 , howpublished =
2023
-
[19]
, author=
The proof and measurement of association between two things. , author=. 1961 , publisher=
1961
-
[20]
Proceedings of the National Academy of Sciences , volume=
Origins of the brain networks for advanced mathematics in expert mathematicians , author=. Proceedings of the National Academy of Sciences , volume=. 2016 , publisher=
2016
-
[21]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[22]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[23]
Reading/Addison-Wesley , year=
Exploratory data analysis , author=. Reading/Addison-Wesley , year=
-
[24]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[25]
arXiv preprint arXiv:2503.01307 , year=
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars , author=. arXiv preprint arXiv:2503.01307 , year=
-
[26]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[27]
arXiv preprint arXiv:2502.07374 , year=
LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters! , author=. arXiv preprint arXiv:2502.07374 , year=
-
[28]
Proceedings of the National Academy of Sciences , year=
Origins of the brain networks for advanced mathematics in expert mathematicians , author=. Proceedings of the National Academy of Sciences , year=
-
[29]
arXiv preprint arXiv:2309.08600 , year=
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
-
[30]
arXiv preprint arXiv:2506.02867 , year=
Demystifying reasoning dynamics with mutual information: Thinking tokens are information peaks in llm reasoning , author=. arXiv preprint arXiv:2506.02867 , year=
-
[31]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[32]
arXiv preprint arXiv:2508.15260 , year=
Deep think with confidence , author=. arXiv preprint arXiv:2508.15260 , year=
-
[33]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Attention Is All You Need , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[34]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
GSM-Plus: A Comprehensive Benchmark for Evaluating the Robustness of LLMs as Mathematical Problem Solvers , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Action Inference by Maximising Evidence: Zero-Shot Imitation from Observation with World Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[37]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Challenging big-bench tasks and whether chain-of-thought can solve them , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[38]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Understanding the feature norm for out-of-distribution detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[40]
2025 , eprint=
Phi-4-reasoning Technical Report , author=. 2025 , eprint=
2025
-
[41]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[42]
2024 , eprint=
Phi-4 Technical Report , author=. 2024 , eprint=
2024
-
[43]
arXiv preprint arXiv:2510.10071 , year=
ADEPT: Continual Pretraining via Adaptive Expansion and Dynamic Decoupled Tuning , author=. arXiv preprint arXiv:2510.10071 , year=
-
[44]
arXiv preprint arXiv:2508.13514 , year=
Promed: Shapley information gain guided reinforcement learning for proactive medical llms , author=. arXiv preprint arXiv:2508.13514 , year=
-
[45]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
3DS: Medical Domain Adaptation of LLMs via Decomposed Difficulty-based Data Selection , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Toward better EHR reasoning in llms: Reinforcement learning with expert attention guidance , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
Advances in Neural Information Processing Systems , volume=
Magical: Medical lay language generation via semantic invariance and layperson-tailored adaptation , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
arXiv preprint arXiv:2504.02327 , year=
Learnat: Learning nl2sql with ast-guided task decomposition for large language models , author=. arXiv preprint arXiv:2504.02327 , year=
-
[49]
arXiv preprint arXiv:2604.06684 , year=
GraphWalker: Graph-Guided In-Context Learning for Clinical Reasoning on Electronic Health Records , author=. arXiv preprint arXiv:2604.06684 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.