FiLM-Based Speaker Conditioning of a SpeechLLM for Pathological Speech Recognition
Pith reviewed 2026-06-28 01:56 UTC · model grok-4.3
The pith
FiLM speaker conditioning adapts frozen ASR models to pathological speech competitively with fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Speaker conditioning via FiLM applied to x-vector embeddings inside a frozen ASR encoder produces recognition performance on pathological speech that is competitive with established adaptation strategies while retaining the model's original performance on non-conditioned speech.
What carries the argument
FiLM layers that use x-vector speaker embeddings to modulate activations at each transformer layer of the frozen ASR encoder.
If this is right
- The base model weights remain unchanged, preserving general capabilities.
- Performance on non-pathological speech stays intact.
- The same conditioning works inside a SpeechLLM without harming question-answering behavior.
- The approach offers a parameter-efficient alternative to full or LoRA-style fine-tuning for speaker adaptation.
Where Pith is reading between the lines
- The same conditioning mechanism could be tested on other speaker variations such as strong accents or child speech.
- Combining FiLM conditioning with light fine-tuning on a small pathological set might produce additive gains.
- Evaluating the method on multilingual pathological corpora would test whether the x-vector-to-FiLM mapping generalizes across languages.
Load-bearing premise
X-vector speaker embeddings contain information that FiLM can translate into useful adjustments of the encoder's internal representations for pathological speech.
What would settle it
On a new pathological speech test set, the FiLM-conditioned frozen model produces substantially higher word error rates than a fine-tuned baseline or shows clear degradation on ordinary speech.
Figures
read the original abstract
Automatic speech recognition (ASR) has advanced remarkably for standard speech; however, pathological speech from neurological conditions remains a significant challenge. We investigate speaker conditioning via Feature-wise Linear Modulation (FiLM), injecting x-vector-derived information into each transformer layer of a frozen ASR encoder to adapt internal representations to individual pathological speakers without modifying base model weights. We benchmark this for the ASR task against standard and parameter-efficient fine-tuning baselines, complemented by post-processing, on Spanish and English pathological speech. Additionally, we evaluate if the adapted model preserves the ability to answer speech-related questions. Results show that speaker-conditioned ASR is competitive with established adaptation strategies while retaining performance on non-conditioned speech.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes injecting x-vector speaker embeddings via FiLM into each transformer layer of a frozen ASR encoder to adapt internal representations to individual pathological speakers without modifying base model weights. It benchmarks the approach against standard and parameter-efficient fine-tuning baselines (with post-processing) on Spanish and English pathological speech datasets, and additionally evaluates retention of performance on non-conditioned speech and speech-related question answering. The central claim is that speaker-conditioned ASR is competitive with established adaptation strategies while retaining performance on non-conditioned speech.
Significance. If the results hold, the method offers a parameter-efficient adaptation route for pathological ASR that avoids full model updates and preserves base-model capabilities on non-pathological inputs; this is potentially significant for clinical or low-resource settings where retraining is costly.
major comments (2)
- [Method] The central claim requires that x-vector-derived conditioning vectors remain informative under pathological distortions (dysarthria, tremor, etc.). The method description gives no indication of domain adaptation, fine-tuning, or validation of the x-vector extractor on pathological data; if the embeddings are noisy or non-separable, FiLM modulation cannot reliably adapt the frozen encoder, directly undermining both the competitiveness and retention claims.
- [Abstract] The abstract asserts that results show competitiveness with baselines, yet no quantitative metrics, tables, or experimental-setup details (e.g., WER deltas, dataset sizes, or statistical significance) are supplied in the provided description; without these the support for the central claim cannot be evaluated.
minor comments (1)
- The abstract would benefit from one or two key quantitative results to allow readers to gauge the magnitude of the reported competitiveness.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating where revisions will be made.
read point-by-point responses
-
Referee: [Method] The central claim requires that x-vector-derived conditioning vectors remain informative under pathological distortions (dysarthria, tremor, etc.). The method description gives no indication of domain adaptation, fine-tuning, or validation of the x-vector extractor on pathological data; if the embeddings are noisy or non-separable, FiLM modulation cannot reliably adapt the frozen encoder, directly undermining both the competitiveness and retention claims.
Authors: We agree that the method section should explicitly describe the x-vector pipeline. The extractor is a pre-trained model (standard VoxCeleb-trained x-vector) applied directly to pathological utterances without domain adaptation or fine-tuning; speaker embeddings are extracted per utterance to capture individual characteristics. Our results demonstrate that these embeddings remain sufficiently informative for FiLM to yield competitive WER on both Spanish and English pathological datasets while preserving non-conditioned performance. We will revise the method section to state this usage explicitly, add a brief discussion of x-vector robustness on dysarthric speech with supporting citations, and note the absence of domain adaptation as a design choice for parameter efficiency. revision: yes
-
Referee: [Abstract] The abstract asserts that results show competitiveness with baselines, yet no quantitative metrics, tables, or experimental-setup details (e.g., WER deltas, dataset sizes, or statistical significance) are supplied in the provided description; without these the support for the central claim cannot be evaluated.
Authors: Abstracts are intentionally concise summaries and conventionally omit specific numerical values, tables, or statistical details to remain within length limits; all quantitative results, dataset sizes, WER comparisons, and experimental setups are provided in the full manuscript (Sections 4 and 5, with accompanying tables). The central claim is therefore fully supported by the body of the paper. No revision to the abstract is required, though we can ensure the results section more prominently references key deltas if the editor prefers. revision: no
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical method for speaker conditioning of a frozen ASR encoder via FiLM layers using x-vector embeddings, benchmarked against fine-tuning baselines on pathological speech datasets. No load-bearing steps involve self-definitional equations, fitted parameters renamed as predictions, or self-citation chains that reduce claims to inputs by construction. The central claims rest on experimental results comparing conditioned ASR performance to baselines while retaining non-conditioned capability, with no derivations or uniqueness theorems invoked.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yet these sys- tems continue to struggle with speech produced by individuals with neuromotor disorders such as amyotrophic lateral sclerosis (ALS) or Parkinson’s disease (PD)
Introduction Automatic speech recognition (ASR) has improved markedly in recent years, with large pretrained models achieving low word error rates on standard benchmarks [1]. Yet these sys- tems continue to struggle with speech produced by individuals with neuromotor disorders such as amyotrophic lateral sclerosis (ALS) or Parkinson’s disease (PD). These ...
-
[2]
FiLM-Based Speaker Conditioning of a SpeechLLM for Pathological Speech Recognition
Speaker-Conditioned ASR via FiLM Modulation We condition the ASR encoder of a frozen SpeechLLM on pathological speech by injecting speaker-derived information after every transformer layer. Speaker information is obtained from FiLM layers driven by x-vector speaker embeddings. All pretrained weights of the SpeechLLM remain frozen in our ap- proach. We jus...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
What is the sex of the speaker?
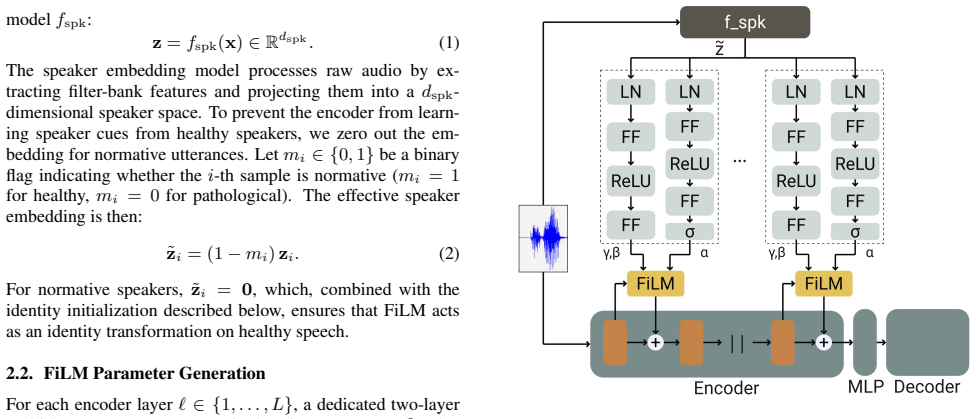
Experimental Setup We compare our method against adaptation strategies explored in the SAP challenge [4], namely standard fine-tuning and parameter-efficient fine-tuning, further complemented by a text post-processing stage. Each model is first fine-tuned on the Figure 1:Proposed FiLM conditioning architecture. The raw audio is processed by the speaker en...
-
[4]
Table 1:WER (%) of Voxtral-Mini and adapted variants on the NeuroVoz and TORGO test sets
Results Table 1 presents the ASR results, while Table 2 reports MCQA accuracy for paralinguistic questions. Table 1:WER (%) of Voxtral-Mini and adapted variants on the NeuroVoz and TORGO test sets. PP = post-processing. Model Trained blocks NeuroV oz TORGO Raw +PP Overall Single-word Multi-word Raw +PP Raw +PP Raw +PP Base None 6.75 6.87 25.15 22.09 46.83...
-
[5]
However, this requires prior knowl- edge of whether the input speech is pathological, which may not always be available in practice
Limitations In our approach, setting the speaker embeddings to a zero vec- tor causes FiLM to act as an identity function, preserving the base model’s performance. However, this requires prior knowl- edge of whether the input speech is pathological, which may not always be available in practice. Furthermore, we assess the model’s ability to answer paralin...
-
[6]
It is a lightweight approach to pathological speech adaptation that maintains the base model untouched
Conclusion We proposed FiLM conditioning of a frozen SpeechLLM en- coder via derived information form speaker x-vectors. It is a lightweight approach to pathological speech adaptation that maintains the base model untouched. Results on TORGO and NeuroV oz show that the method reduces WER on pathological speech, though with a higher dependence on post-proc...
-
[7]
101135916)
Acknowledgments This project has been partially funded by the European Union’s Horizon 2020 RIA ELOQUENCE project (Grant Agreement No. 101135916). Views and opinions expressed are, however, those of the author(s) only and do not necessarily reflect those of the European Union or European Commission-EU. Neither the European Union nor the granting authority...
2020
-
[8]
Automatic speech recognition: A survey of deep learning techniques and ap- proaches,
H. Ahlawat, N. Aggarwal, and D. Gupta, “Automatic speech recognition: A survey of deep learning techniques and ap- proaches,”International Journal of Cognitive Computing in En- gineering, 2025
2025
-
[9]
The torgo database of acoustic and articulatory speech from speakers with dysarthria,
F. Rudzicz, A. K. Namasivayam, and T. Wolff, “The torgo database of acoustic and articulatory speech from speakers with dysarthria,”Language resources and evaluation, vol. 46, no. 4, pp. 523–541, 2012
2012
-
[10]
Dysarthric speech database for universal access research
H. Kim, M. Hasegawa-Johnson, A. Perlman, J. R. Gunderson, T. S. Huang, K. L. Watkin, S. Frameet al., “Dysarthric speech database for universal access research.” inInterspeech, vol. 2008, 2008, pp. 1741–1744
2008
-
[11]
The interspeech 2025 speech accessibility project challenge,
X. Zheng, B. Phukon, J. Na, E. Cutrell, K. Han, M. Hasegawa- Johnson, P.-P. Jiang, A. Kuila, C. Lea, B. MacDonaldet al., “The interspeech 2025 speech accessibility project challenge,” inProc. Interspeech 2025, 2025
2025
-
[12]
New spanish speech cor- pus database for the analysis of people suffering from parkinson’s disease
J. R. Orozco-Arroyave, J. D. Arias-Londo ˜no, J. F. Vargas-Bonilla, M. C. Gonzalez-R ´ativa, and E. N ¨oth, “New spanish speech cor- pus database for the analysis of people suffering from parkinson’s disease.” inLrec, 2014, pp. 342–347
2014
-
[13]
Neurovoz: a castillian spanish corpus of parkinsonian speech,
J. Mendes-Laureano, J. A. G ´omez-Garc´ıa, A. Guerrero-L ´opez, E. Luque-Buzo, J. D. Arias-Londo ˜no, F. J. Grandas-P ´erez, and J. I. Godino-Llorente, “Neurovoz: a castillian spanish corpus of parkinsonian speech,”Scientific Data, vol. 11, no. 1, p. 1367, 2024
2024
-
[14]
Neurovoz: a castillian spanish corpus of parkinsonian speech,
J. Mendes-Laureano, J. A. G ´omez-Garc´ıa, A. Guerrero-L ´opez, E. Luque-Buzo, J. D. Arias-Londo ˜no, F. J. Grandas-P ´erez, and J. I. Godino Llorente, “Neurovoz: a castillian spanish corpus of parkinsonian speech,” Mar. 2024. [Online]. Available: https://doi.org/10.5281/zenodo.10777657
-
[15]
Speaker adaptation for wav2vec2 based dysarthric asr,
M. K. Baskar, T. Herzig, D. Nguyen, M. Diez, T. Polzehl, L. Bur- get, J. ˇCernock`yet al., “Speaker adaptation for wav2vec2 based dysarthric asr,”arXiv preprint arXiv:2204.00770, 2022
-
[16]
Use of speech impairment severity for dysarthric speech recognition,
M. Geng, Z. Jin, T. Wang, S. Hu, J. Deng, M. Cui, G. Li, J. Yu, X. Xie, and X. Liu, “Use of speech impairment severity for dysarthric speech recognition,” inProc. Interspeech 2023, 2023, pp. 2328–2332
2023
-
[17]
Personalized fine-tuning with controllable synthetic speech from llm-generated transcripts for dysarthric speech recognition,
D. Wagner, I. Baumann, N. Engert, S. Lee, E. N ¨oth, K. Riedham- mer, and T. Bocklet, “Personalized fine-tuning with controllable synthetic speech from llm-generated transcripts for dysarthric speech recognition,” inProc. Interspeech 2025, 2025, pp. 3294– 3298
2025
-
[18]
X. Shi, X. Wang, Z. Guo, Y . Wang, P. Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Yanget al., “Qwen3-asr technical report,”arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,” arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
S. Ghosh, A. Goel, J. Kim, S. Kumar, Z. Kong, S. gil Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[21]
Available: https://openreview.net/forum?id= FjByDpDVIO
[Online]. Available: https://openreview.net/forum?id= FjByDpDVIO
- [22]
-
[23]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” in Proceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
2018
-
[24]
A. H. Liu, K. Khandelwal, S. Subramanian, V . Jouault, A. Rastogiet al., “Ministral 3,” 2026. [Online]. Available: https://arxiv.org/abs/2601.08584
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
V oxblink2: A 100k+ speaker recognition corpus and the open- set speaker-identification benchmark,
Y . Lin, M. Cheng, F. Zhang, Y . Gao, S. Zhang, and M. Li, “V oxblink2: A 100k+ speaker recognition corpus and the open- set speaker-identification benchmark,” inProc. Interspeech 2024, 2024, pp. 4263–4267
2024
-
[26]
V oxceleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition,”Interspeech 2018, 2018
2018
-
[27]
Com- mon voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Hen- retty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Com- mon voice: A massively-multilingual speech corpus,” inProceed- ings of the twelfth language resources and evaluation conference, 2020, pp. 4218–4222
2020
-
[28]
Cba-whisper: Curriculum learning-based adalora fine-tuning on whisper for low-resource dysarthric speech recognition,
T. Tan, X. Chen, X. Le, W. Fan, X. Xia, C. Huang, and J. Lu, “Cba-whisper: Curriculum learning-based adalora fine-tuning on whisper for low-resource dysarthric speech recognition,” inProc. Interspeech 2025, 2025, pp. 3309–3313
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.