Many Circuits, One Mechanism: Input Variation and Evaluation Granularity in Circuit Discovery
Pith reviewed 2026-06-28 01:45 UTC · model grok-4.3
The pith
Structurally distinct circuits implement the same computation when input frequency varies but the task is fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
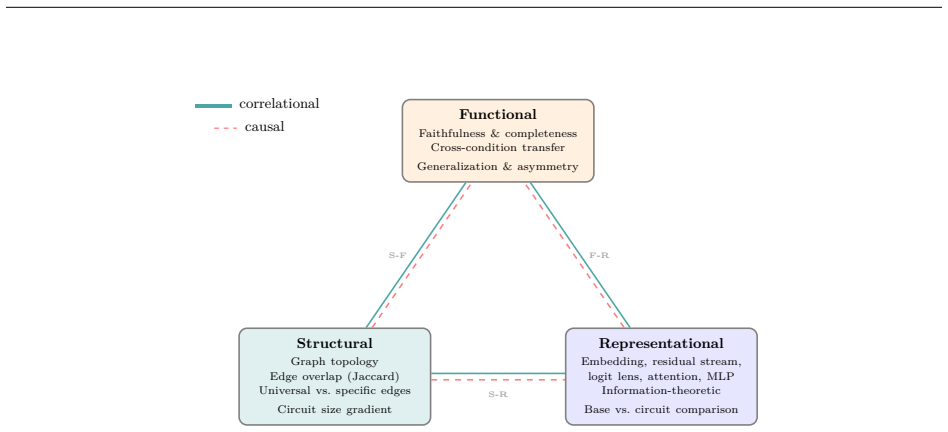
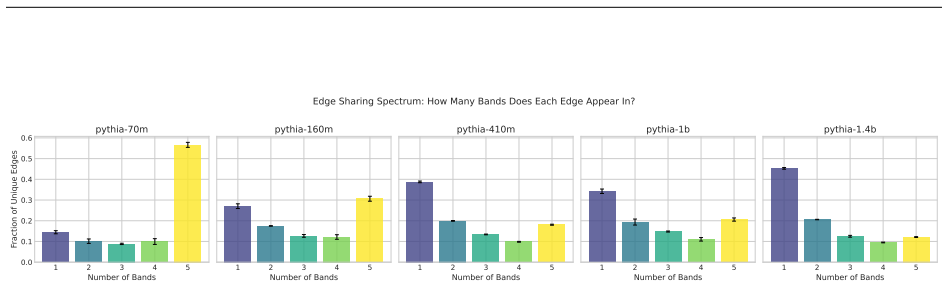
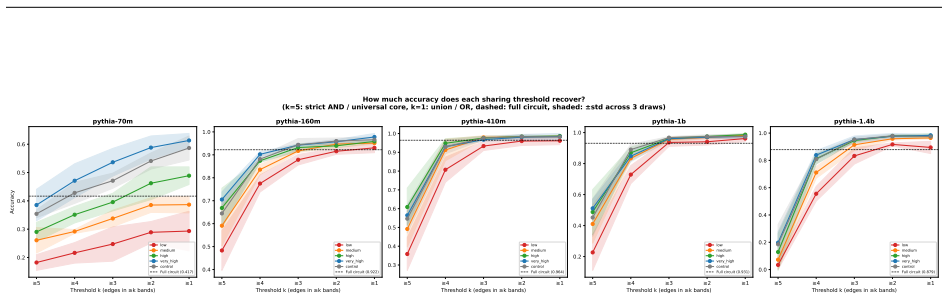
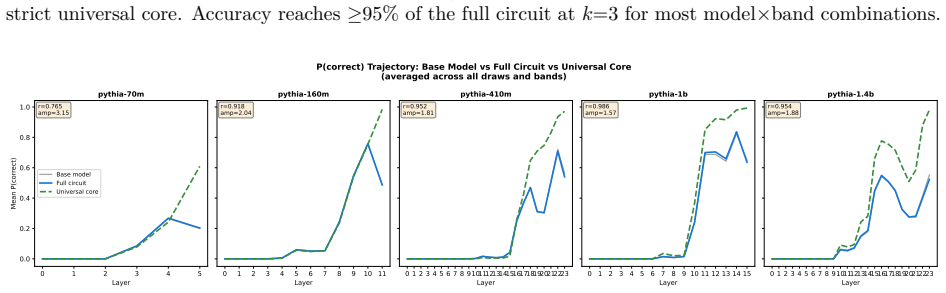
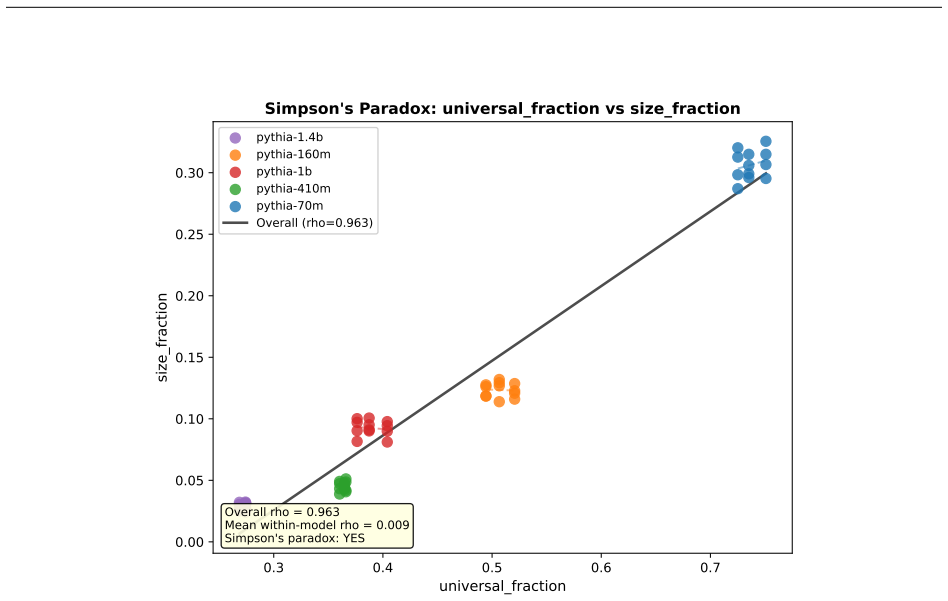
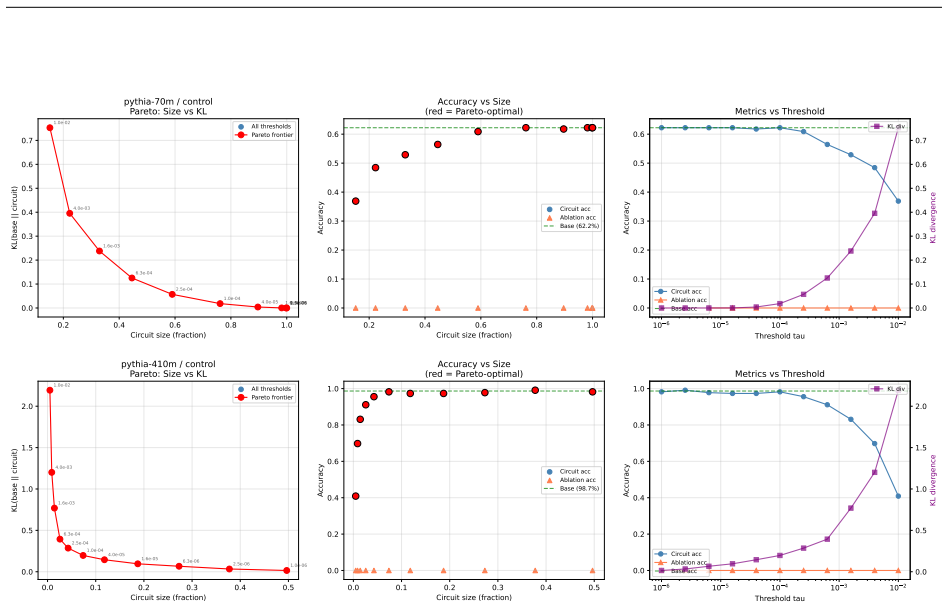
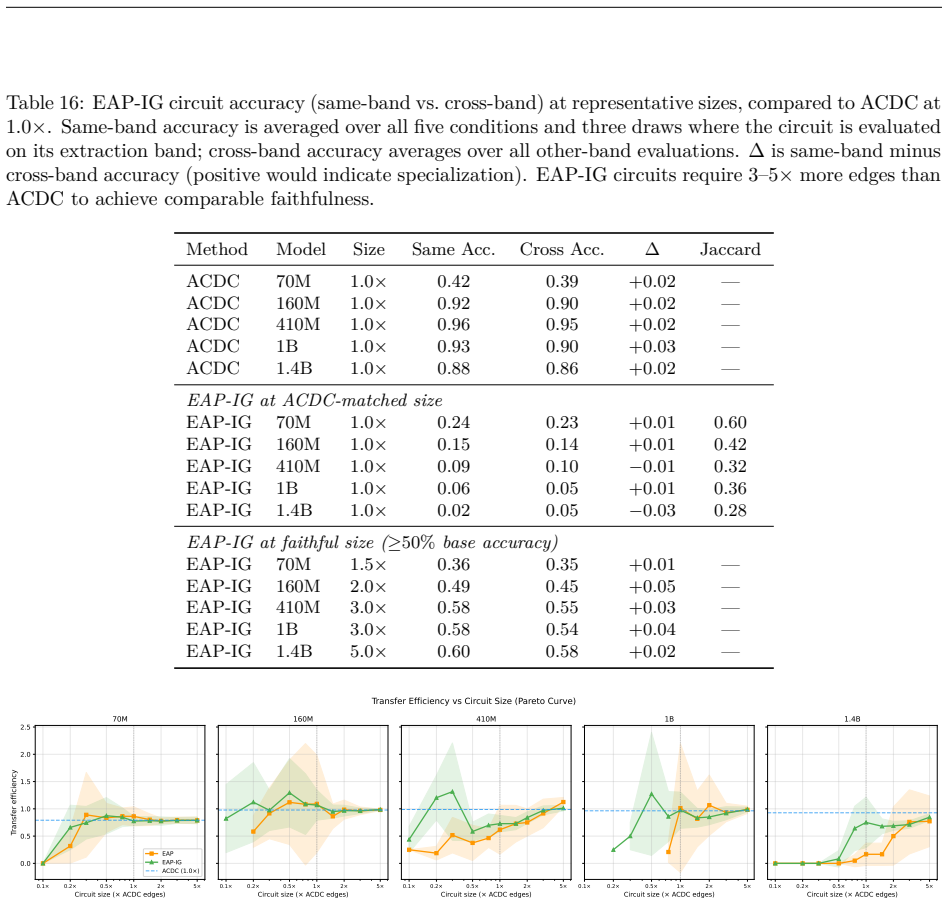
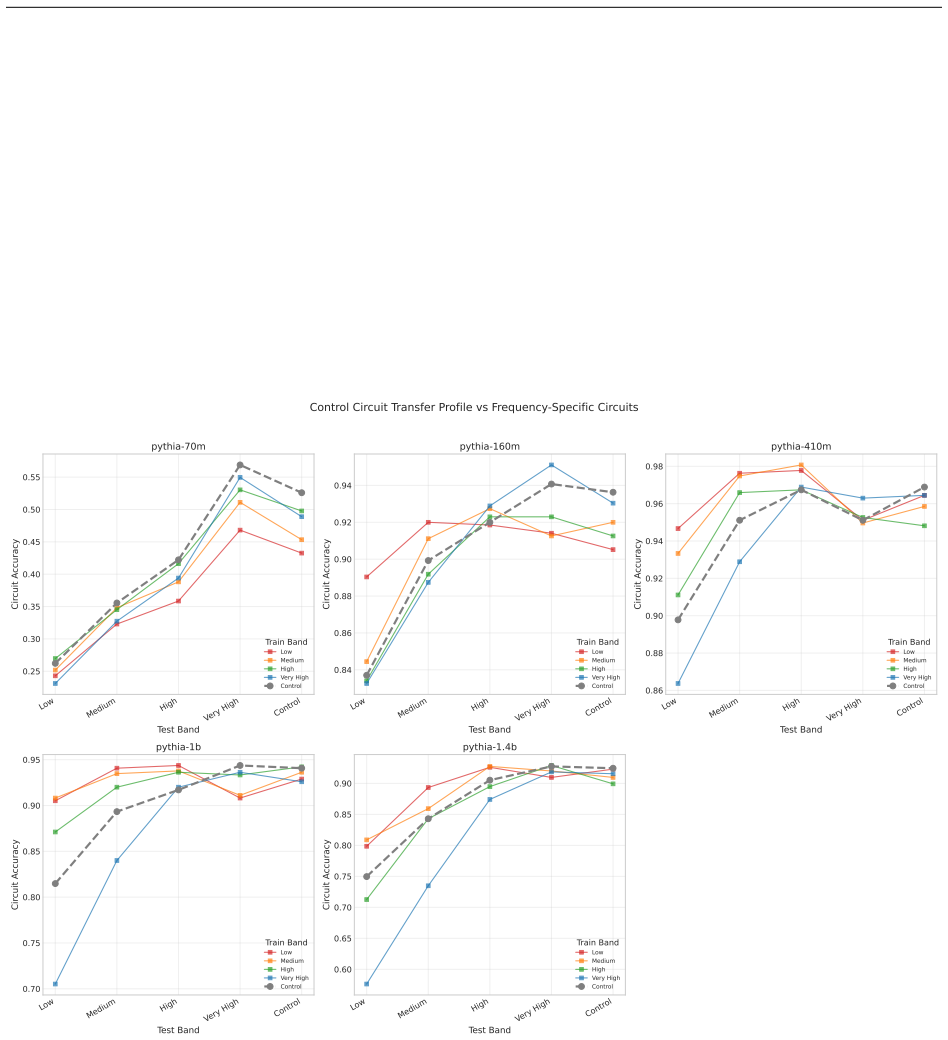
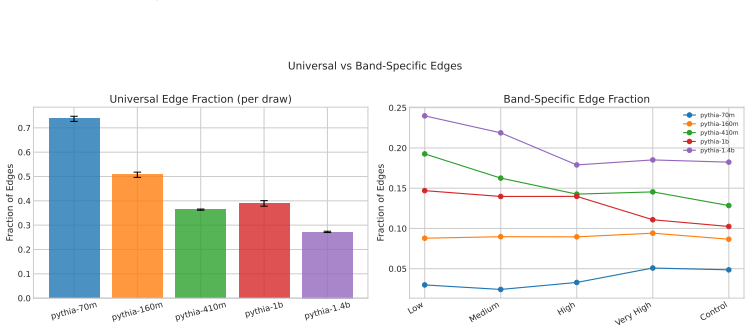
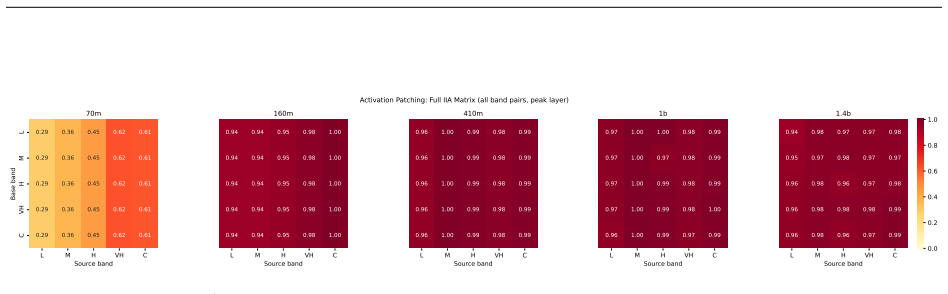
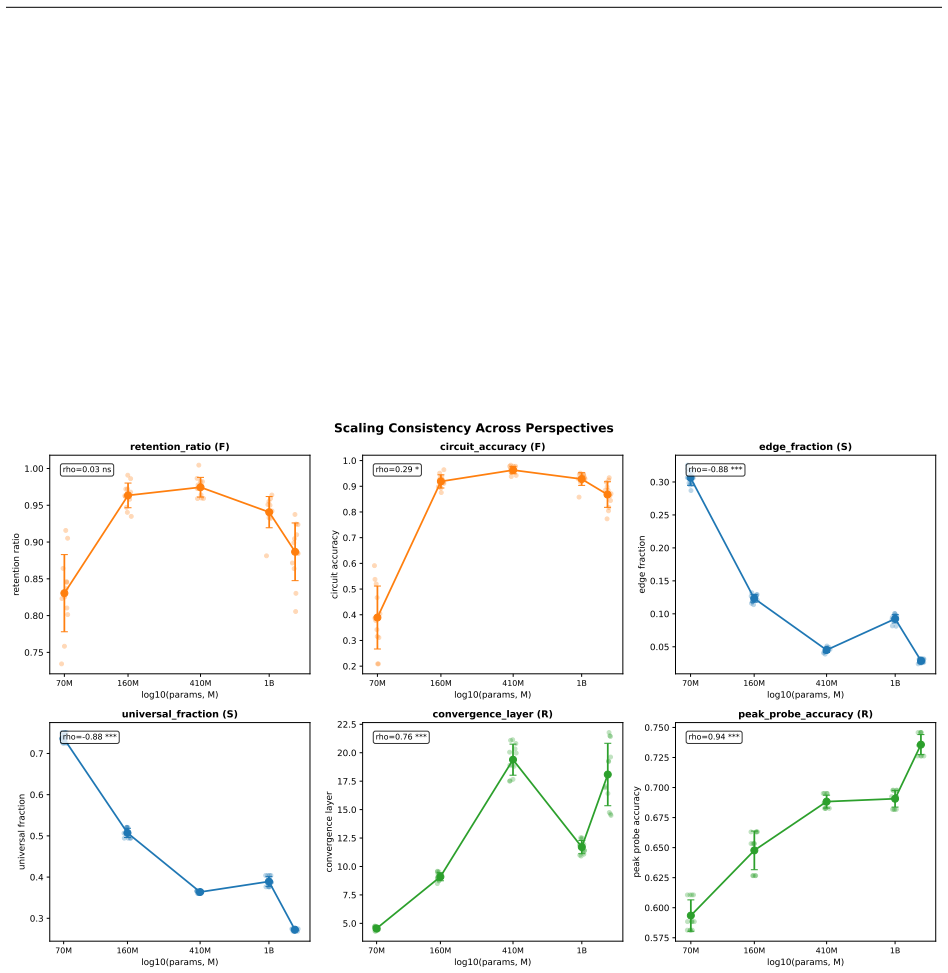
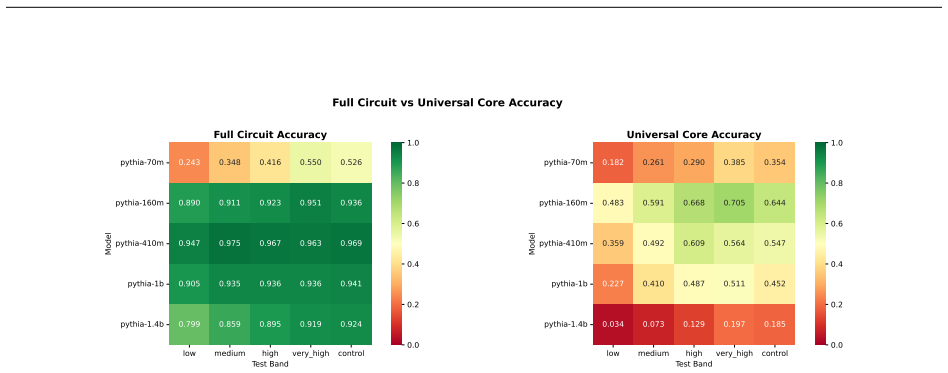
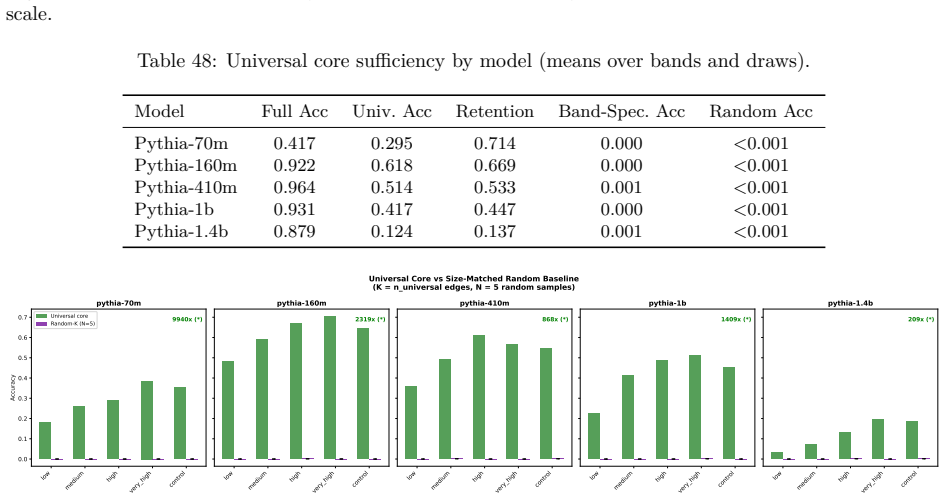
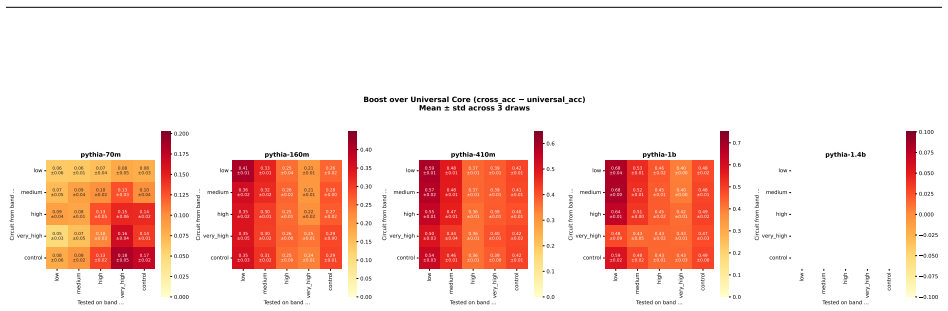
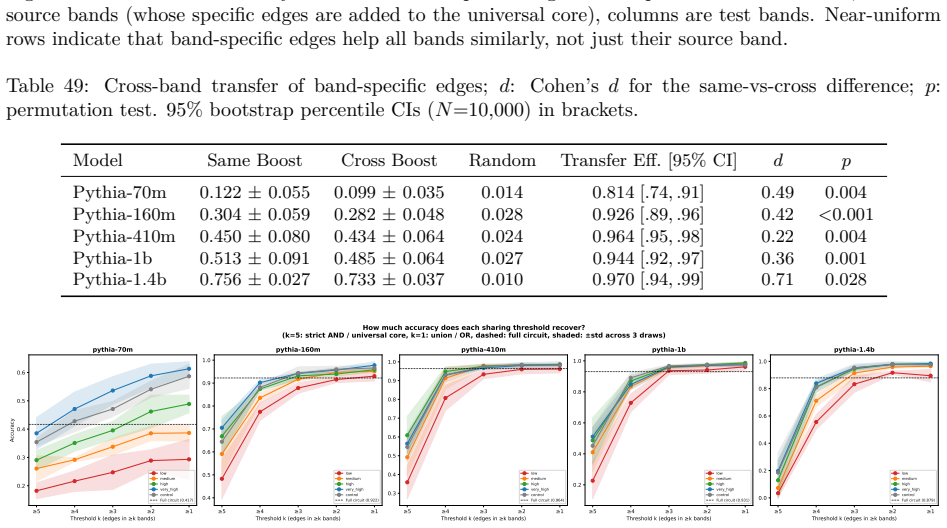
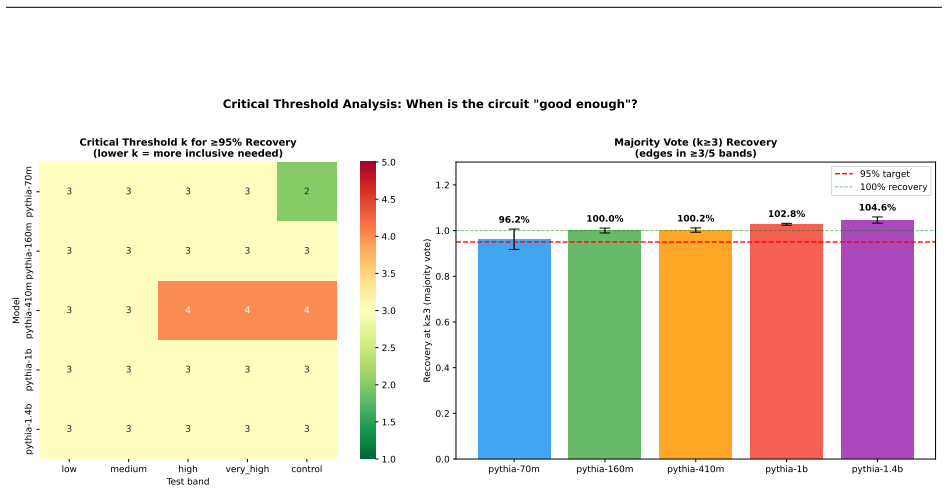
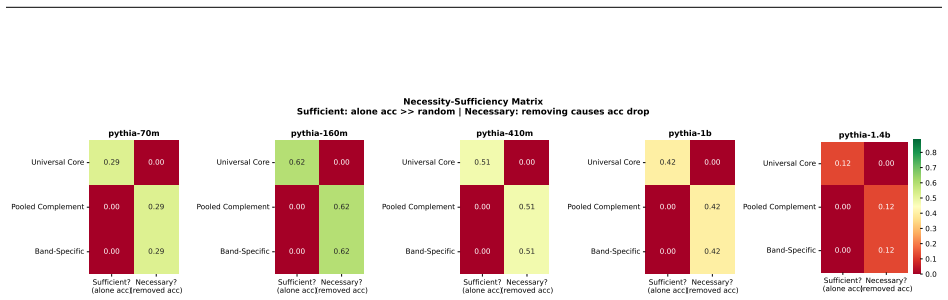
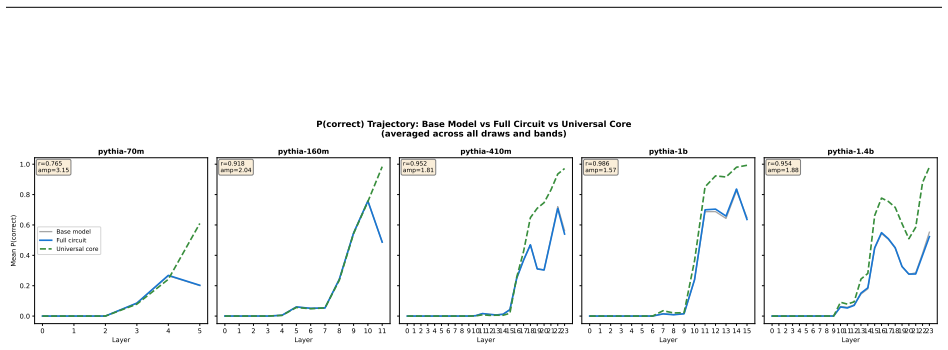
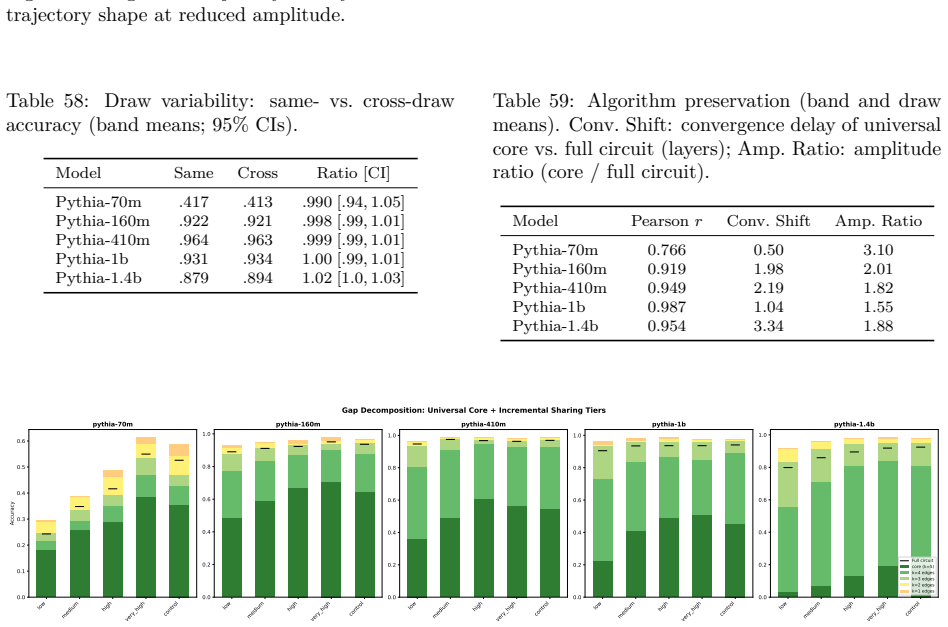
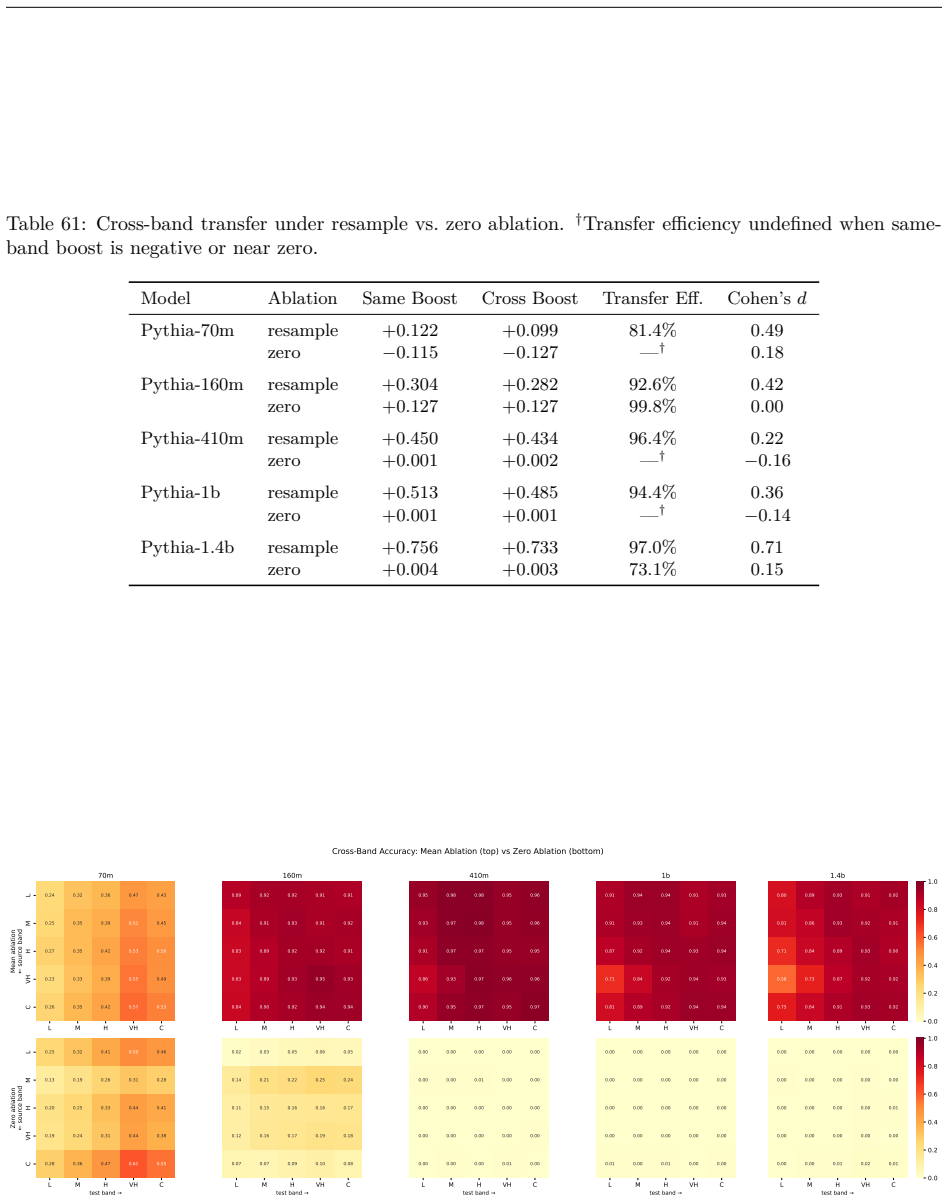
Structurally distinct circuits implement the same computation: band-specific edges transfer broadly across bands, a core shared across most bands recovers at least 99% of circuit performance, and causal interchange interventions confirm that internal representations are interchangeable across frequency bands.
What carries the argument
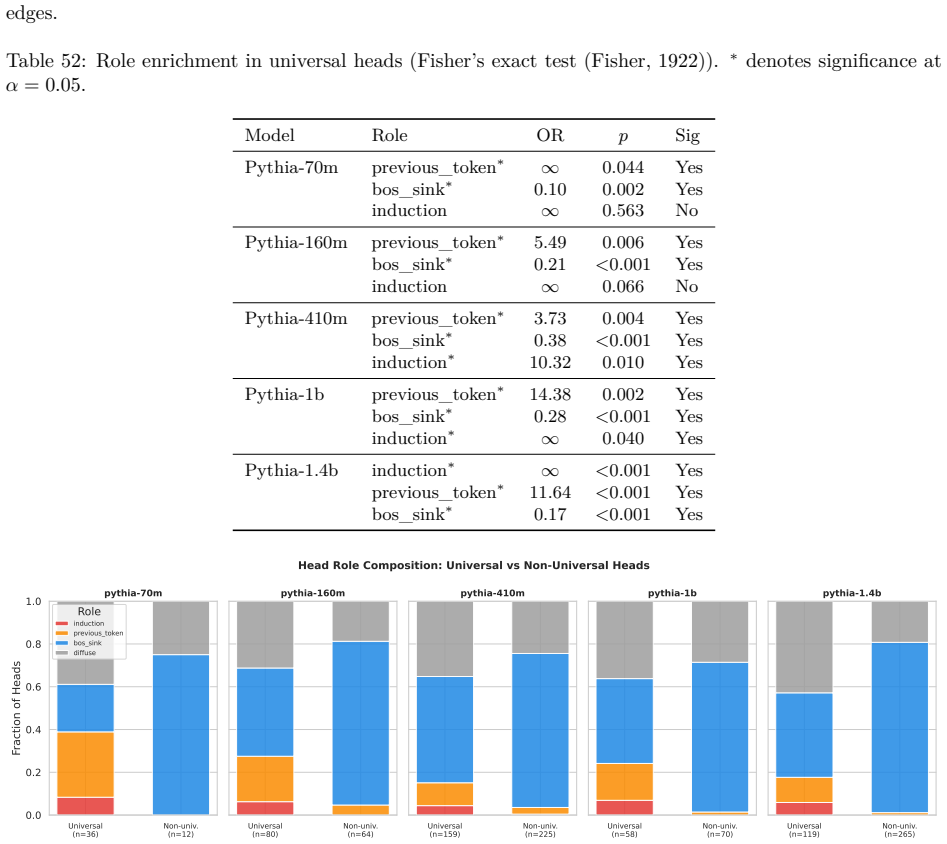
Phantom specialization: apparent structural differences between circuits that do not correspond to functional differences, exposed by cross-condition edge transfer and edge-level evaluation.
If this is right
- Band-specific edges transfer broadly across frequency bands without loss of function.
- A shared core across most bands recovers at least 99% of circuit performance.
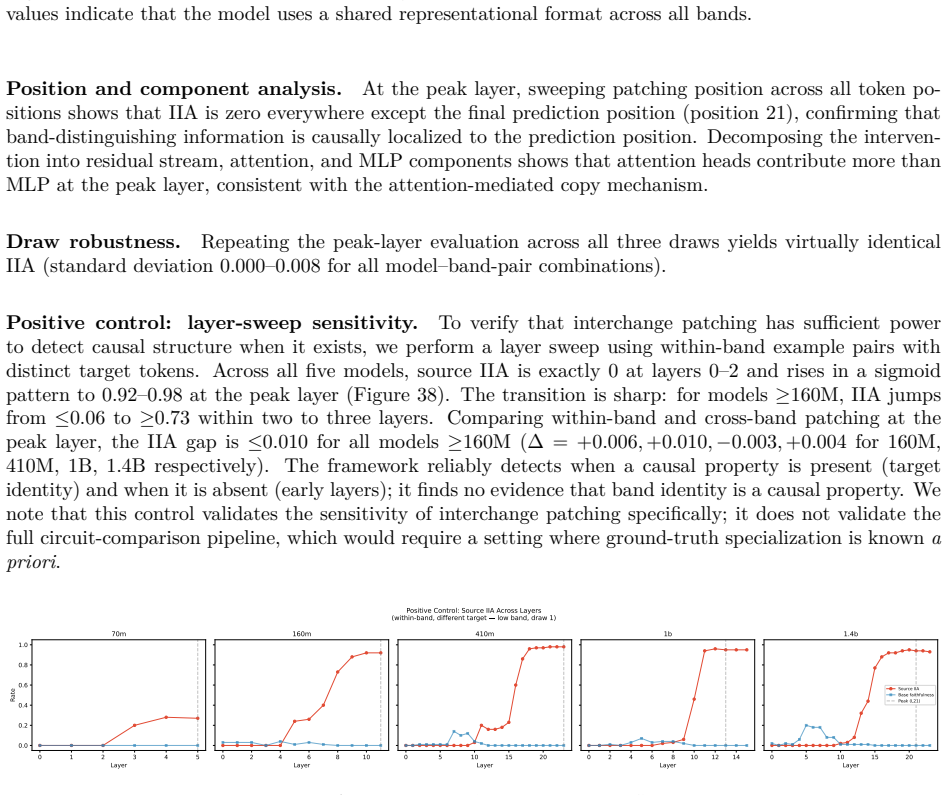
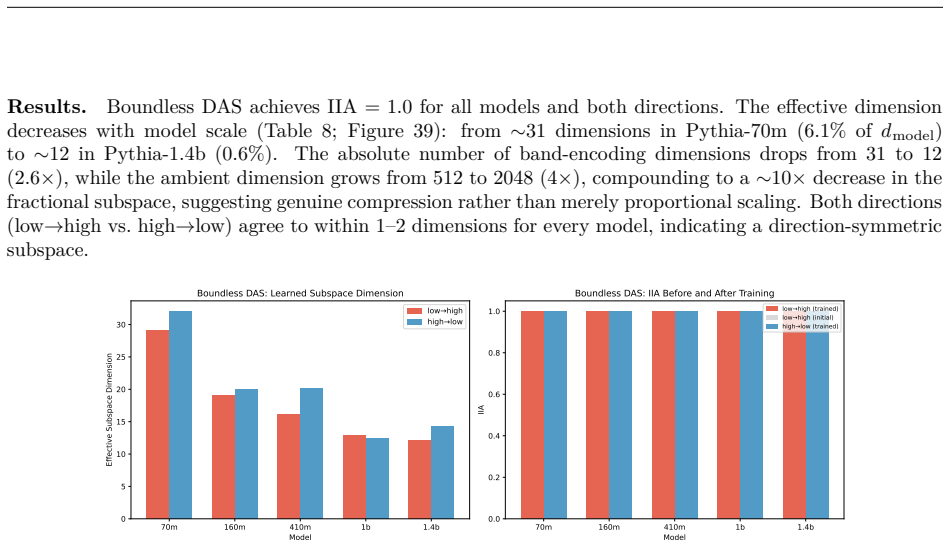
- Causal interchange interventions confirm interchangeable internal representations across bands.
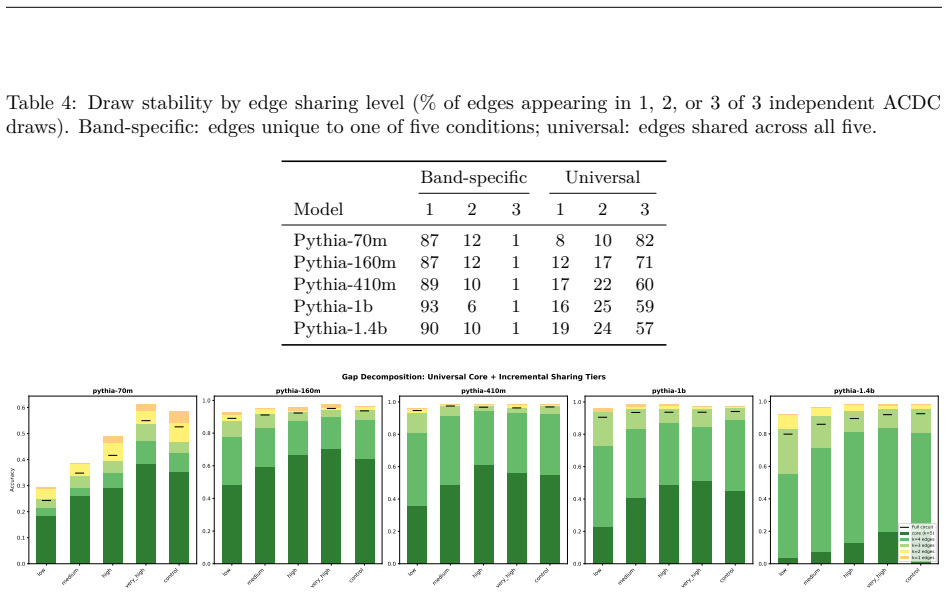
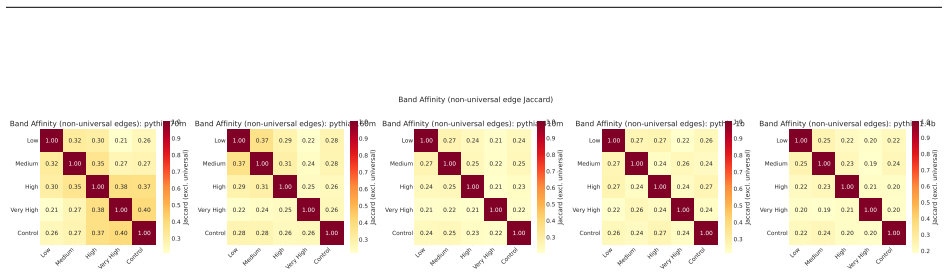
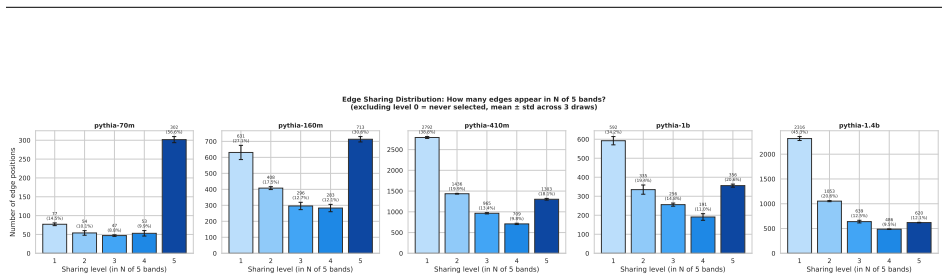
- Repeated extractions within one band sample from an equivalence class of valid subgraphs.
- Edge-level evaluation reveals the many-to-one mapping while source-level evaluation inflates apparent faithfulness.
Where Pith is reading between the lines
- Interpretability work should require functional equivalence tests rather than relying on structural comparisons alone.
- Circuit discovery methods may routinely return one of many equivalent subgraphs for a given behavior.
- The same task may admit multiple valid circuits whose differences reflect sampling rather than distinct mechanisms.
Load-bearing premise
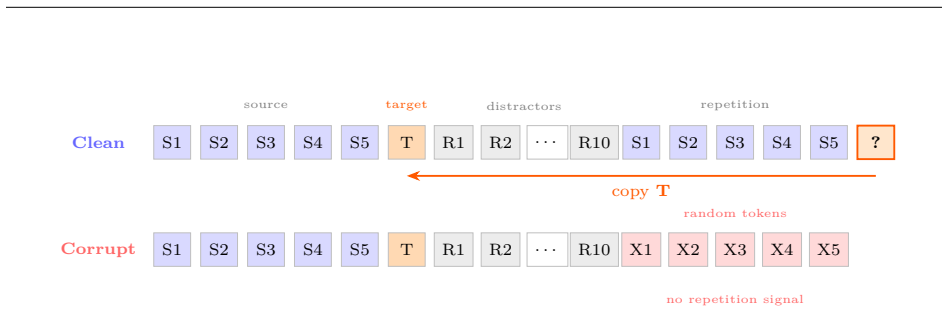
Varying token frequency while holding the literal sequence copying task fixed isolates the effect of input statistics on circuit structure.
What would settle it
An interchange intervention between circuits extracted from different frequency bands that fails to preserve task performance would falsify the claim of interchangeable representations.
Figures
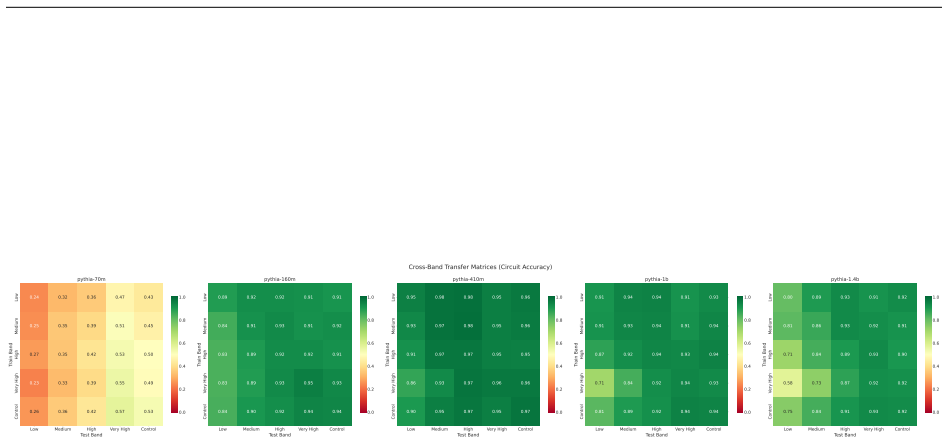
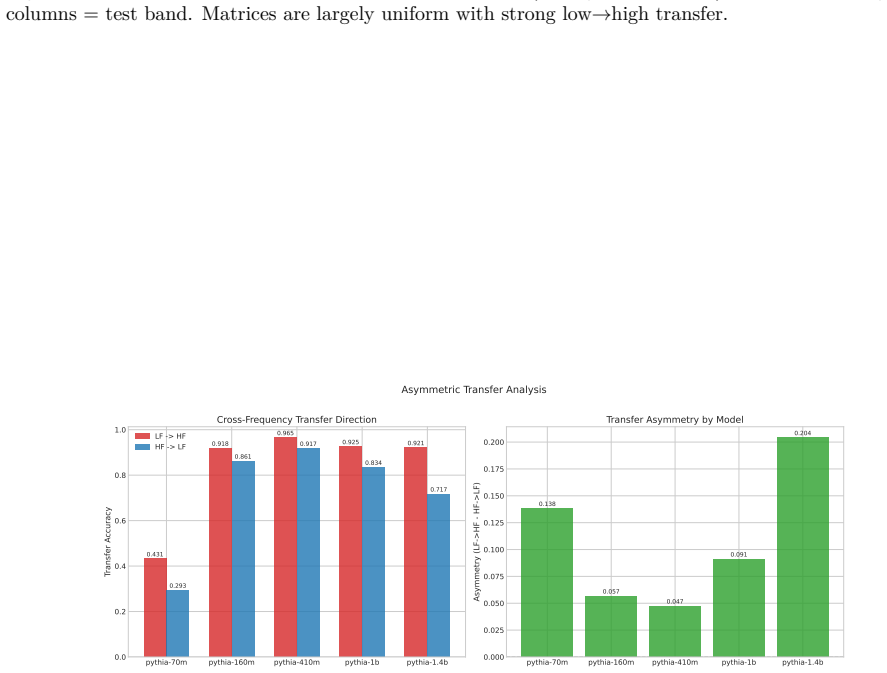
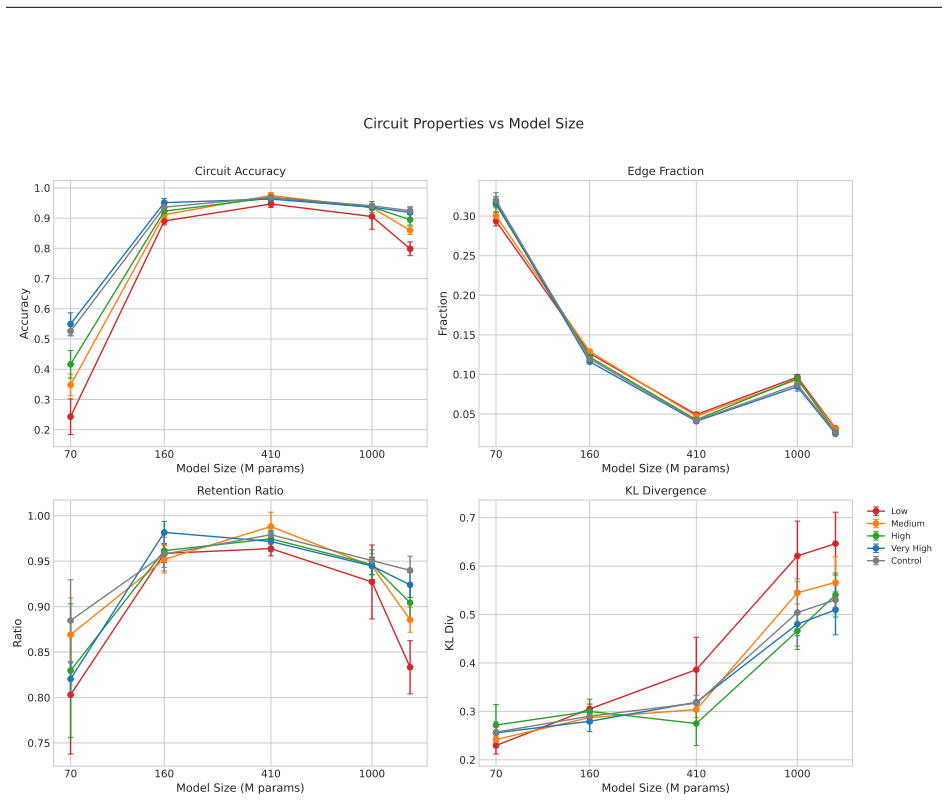
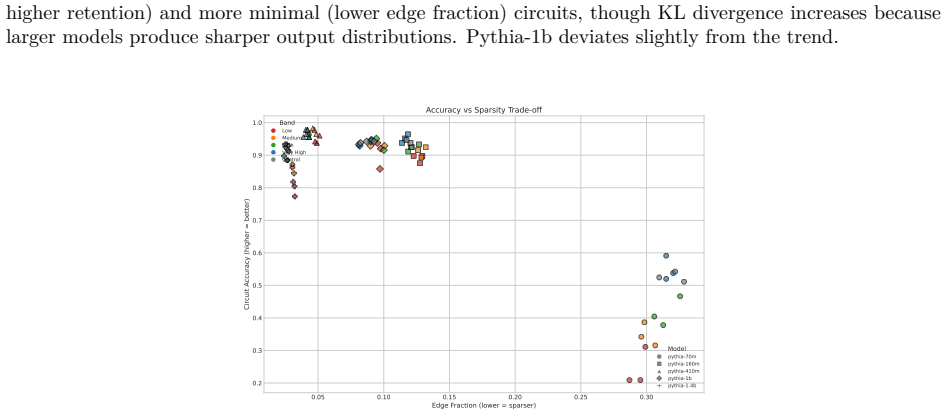
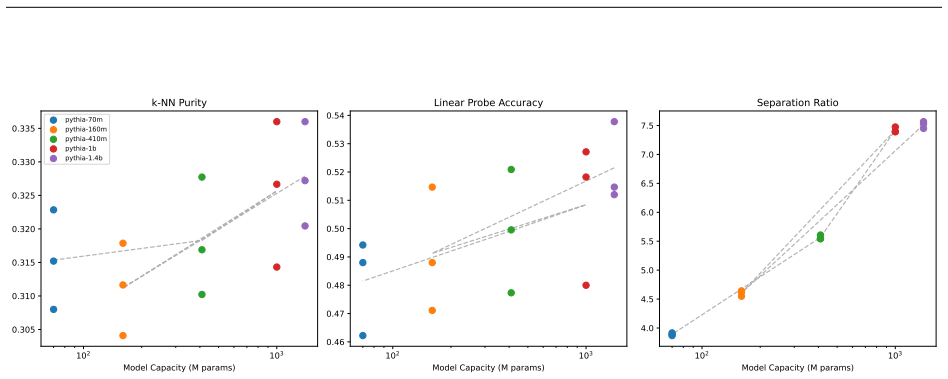
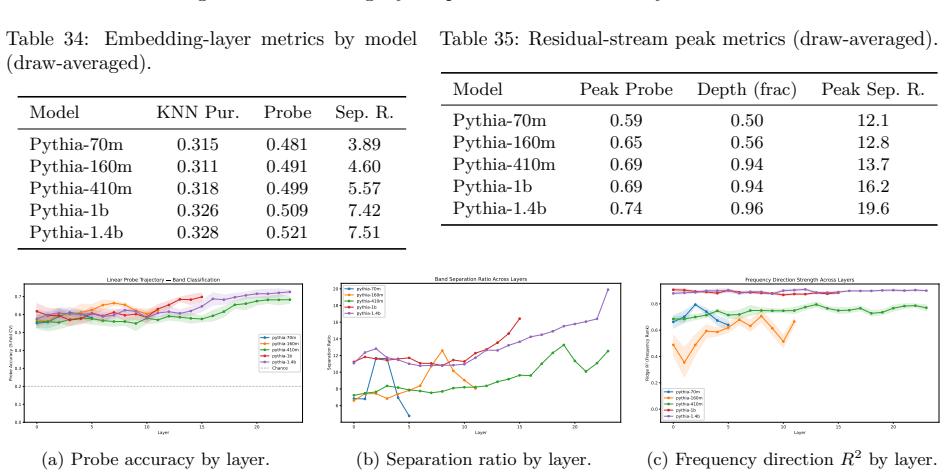
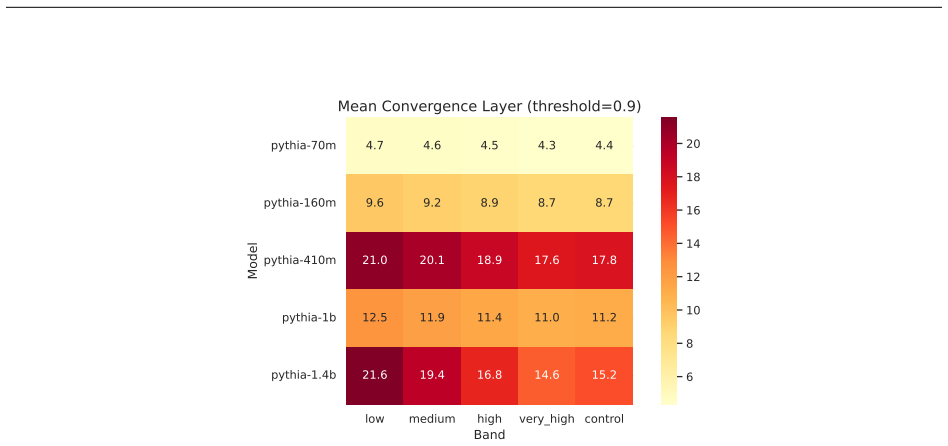
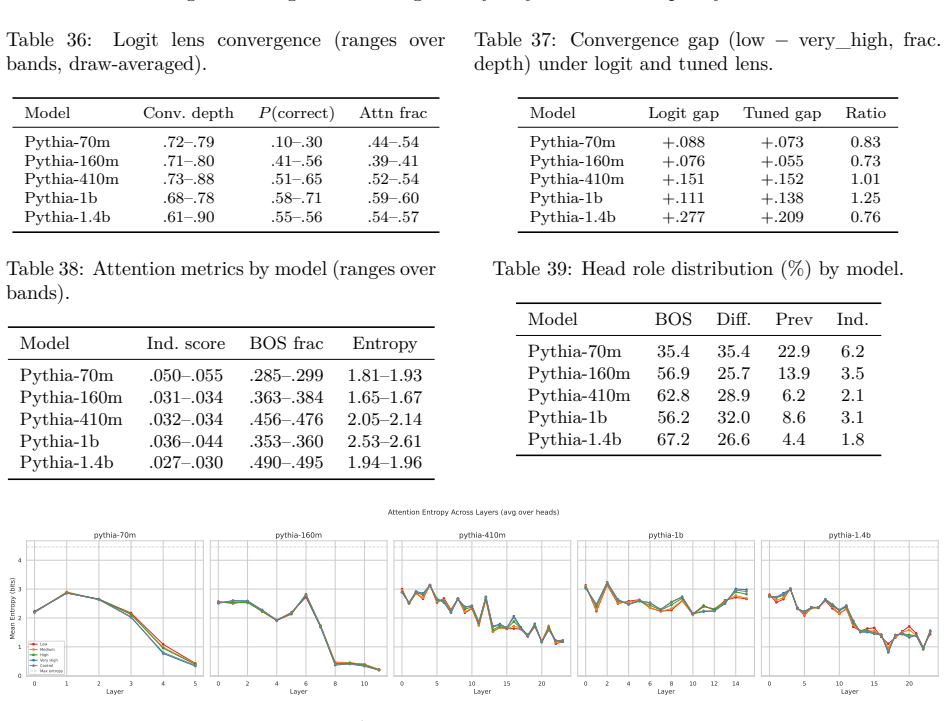

read the original abstract
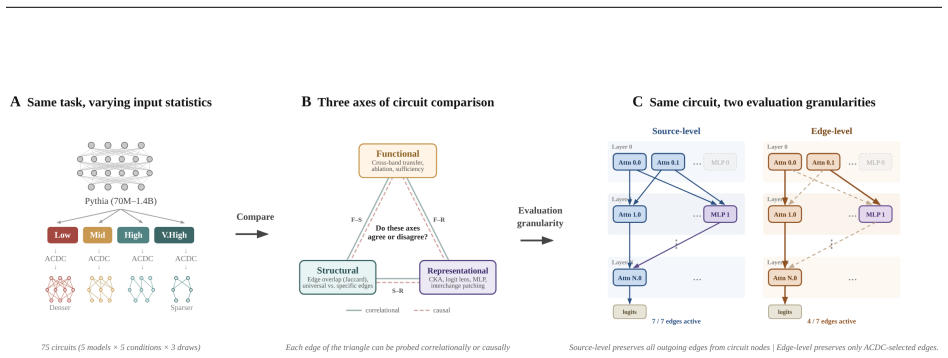
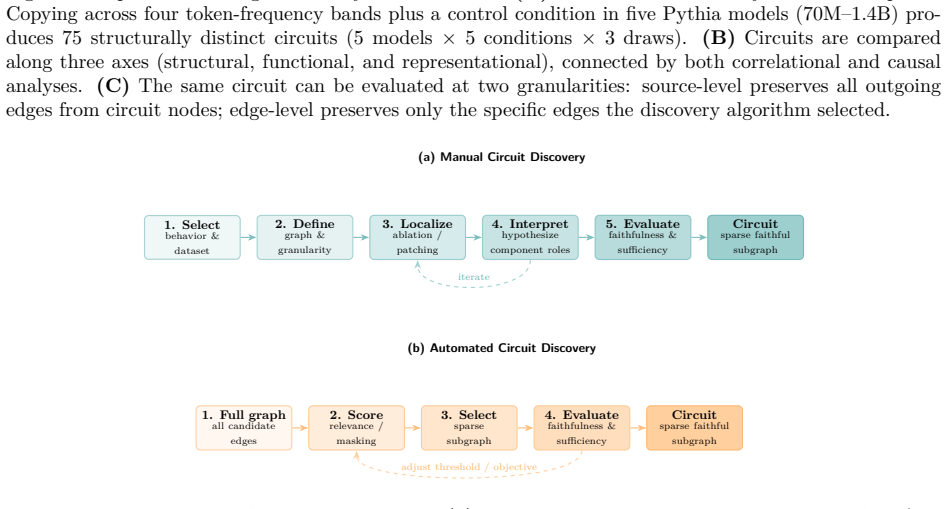
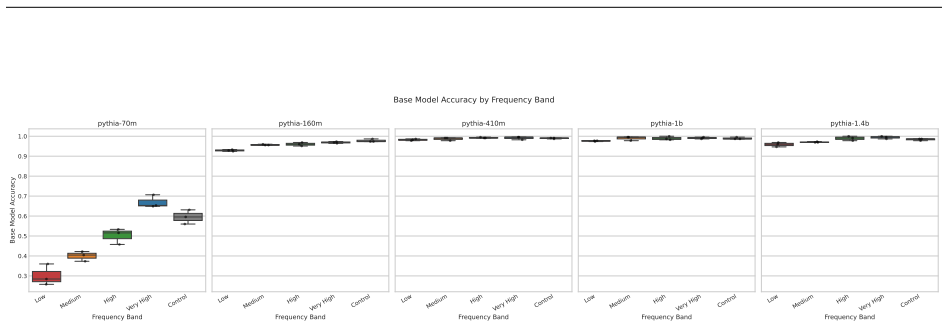
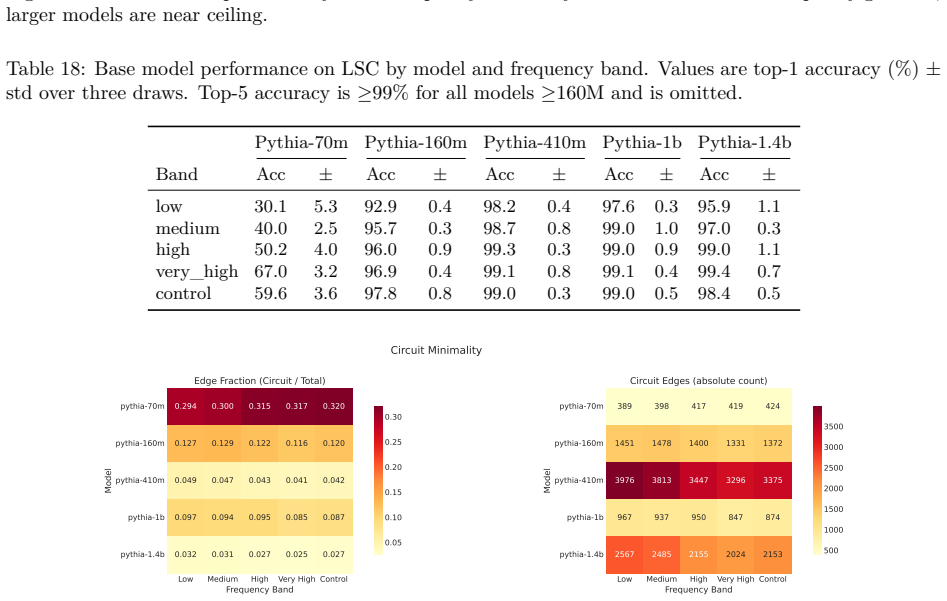
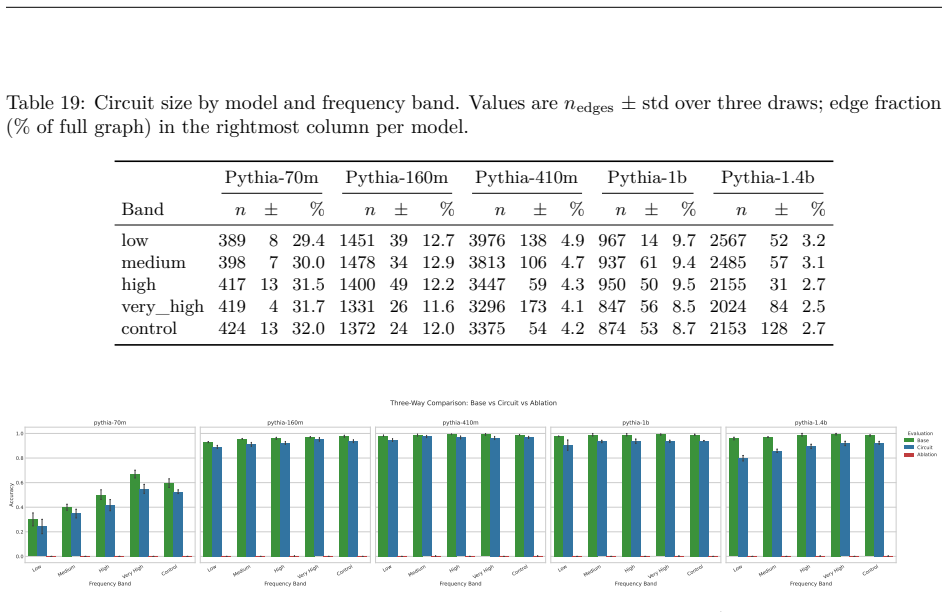
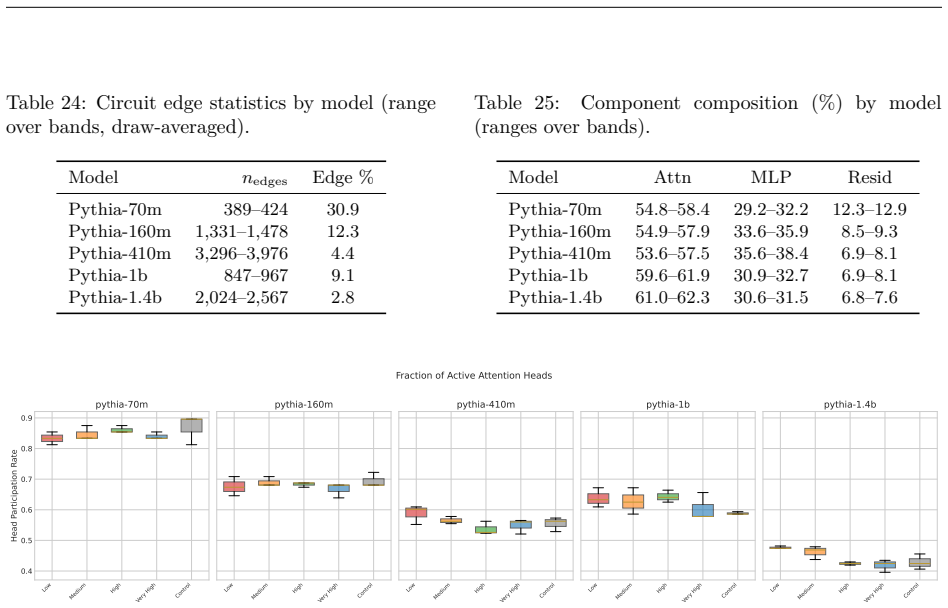
Circuit discovery methods identify subgraphs that explain specific model behaviors, and structural differences between discovered circuits are commonly interpreted as evidence of distinct mechanisms. We test this assumption by varying input statistics while holding the task fixed, and show that the resulting structural differences exhibit apparent specialization but do not correspond to functional differences, a pattern we term phantom specialization. Using Literal Sequence Copying across four token-frequency bands plus a control condition in five Pythia models (70M-1.4B), we extract 75 circuits and find that structurally distinct circuits implement the same computation: band-specific edges transfer broadly across bands, a core shared across most bands recovers at least 99% of circuit performance, and causal interchange interventions confirm that internal representations are interchangeable across frequency bands. Repeated extractions within the same frequency band further suggest that discovery algorithms sample from an equivalence class of valid subgraphs rather than recovering a unique mechanism. Standard evaluation practice obscures this pattern: source-level evaluation inflates apparent faithfulness, while edge-level evaluation reveals the many-to-one mapping from structure to function. Our results show that structural differences between circuits are not sufficient evidence for distinct mechanisms, and that exposing this requires edge-level evaluation and cross-condition transfer tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that circuit discovery methods yield structurally distinct subgraphs for the same task (literal sequence copying) when input token-frequency statistics are varied across four bands plus control, but these differences reflect 'phantom specialization' rather than distinct mechanisms. Using 75 circuits extracted from five Pythia models (70M–1.4B), the authors show that band-specific edges transfer broadly, a shared core across most bands recovers ≥99% of per-band circuit performance, and causal interchange interventions demonstrate that internal representations are interchangeable across bands. Repeated within-band extractions suggest discovery algorithms sample from an equivalence class of valid subgraphs. The work argues that source-level evaluation inflates faithfulness while edge-level evaluation reveals the many-to-one structure-to-function mapping, implying structural differences alone are insufficient evidence for distinct mechanisms.
Significance. If the empirical results hold, the paper makes a substantive contribution to mechanistic interpretability by providing converging evidence (cross-band transfer, shared-core recovery, and interchange interventions) that challenges the common assumption that structural variation in discovered circuits implies functional specialization. The clean isolation of input statistics while holding the task fixed, combined with the emphasis on evaluation granularity, offers a practical methodological caution and supports the view that circuits may belong to equivalence classes rather than unique mechanisms.
major comments (2)
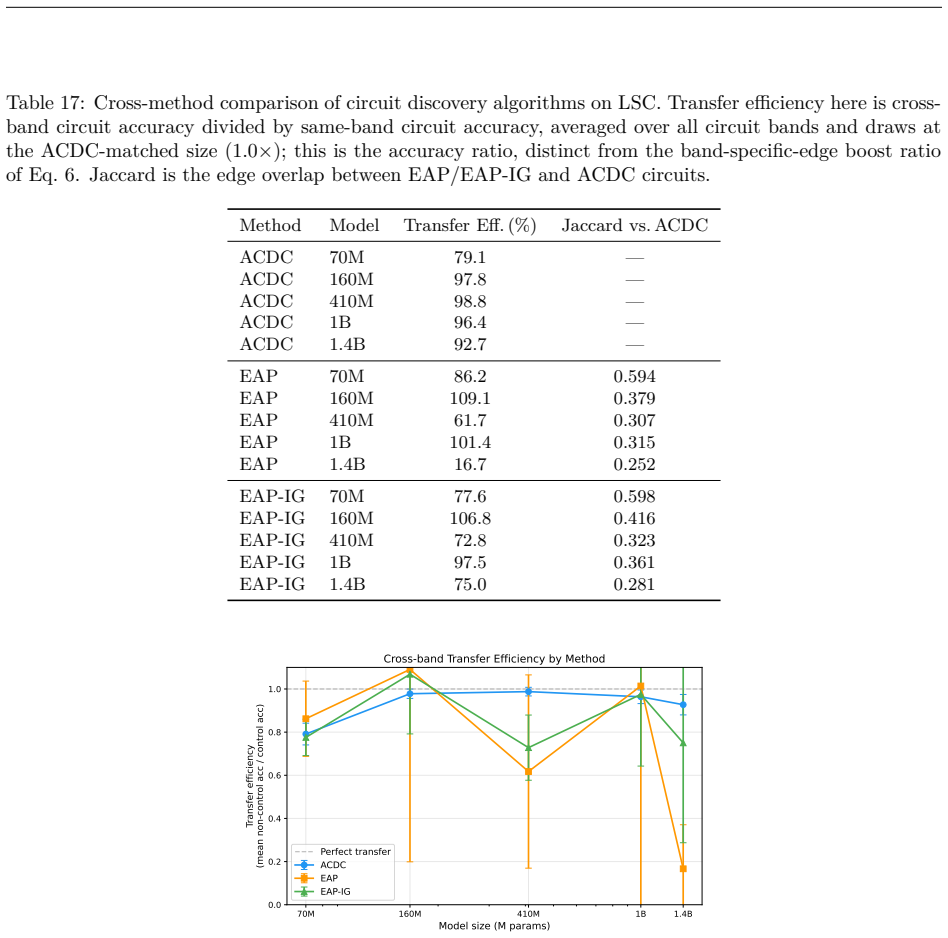
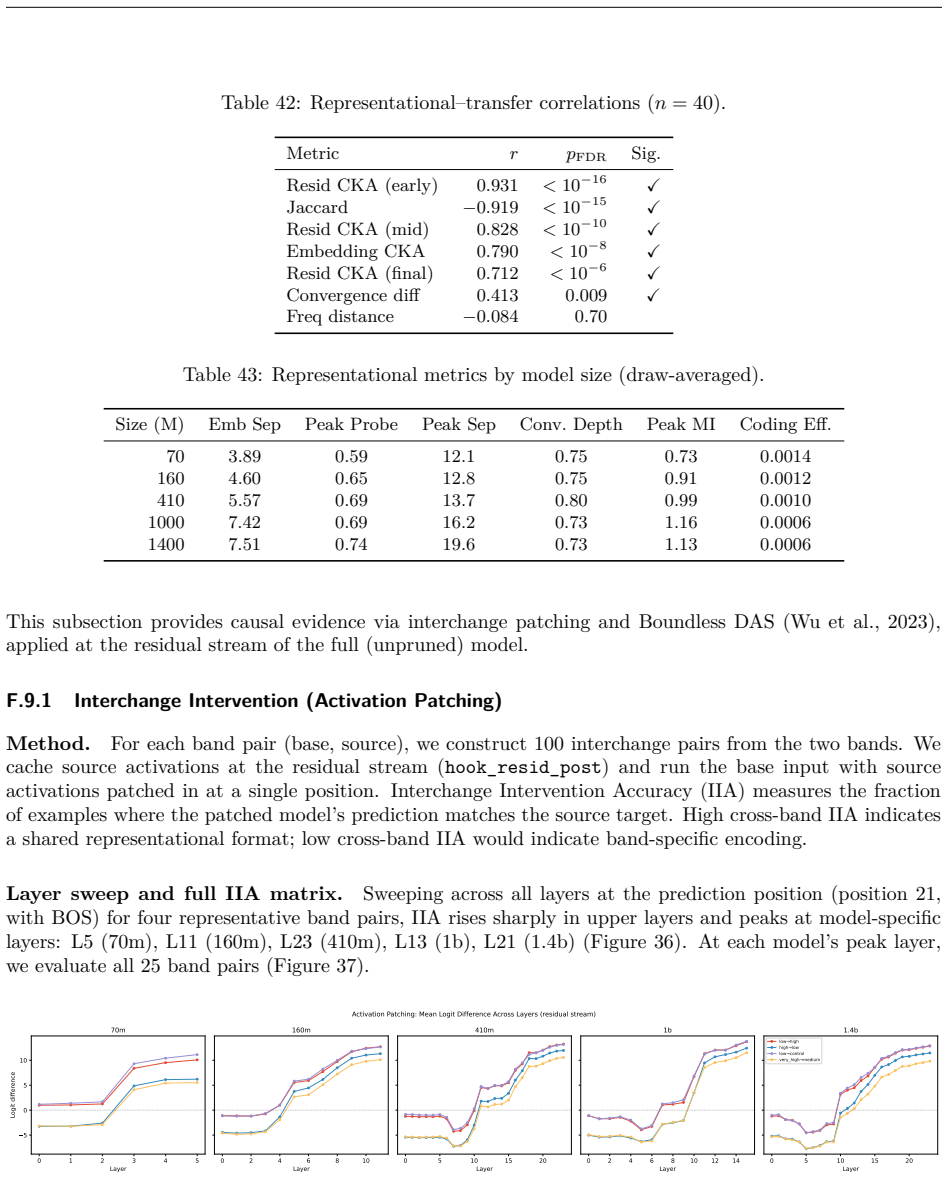
- [§4.2] §4.2 (cross-band transfer results): the reported broad transfer of band-specific edges is central to the phantom-specialization claim, yet the manuscript does not report the exact threshold used to classify an edge as 'transferring' or the statistical test for whether transfer rates differ significantly from within-band baselines.
- [§5] §5 (interchange intervention protocol): the claim that representations are interchangeable rests on the interchange tests recovering performance; however, the description does not specify how the source and target activations are aligned when the circuits differ in edge sets, which is load-bearing for interpreting the results as evidence of functional equivalence.
minor comments (3)
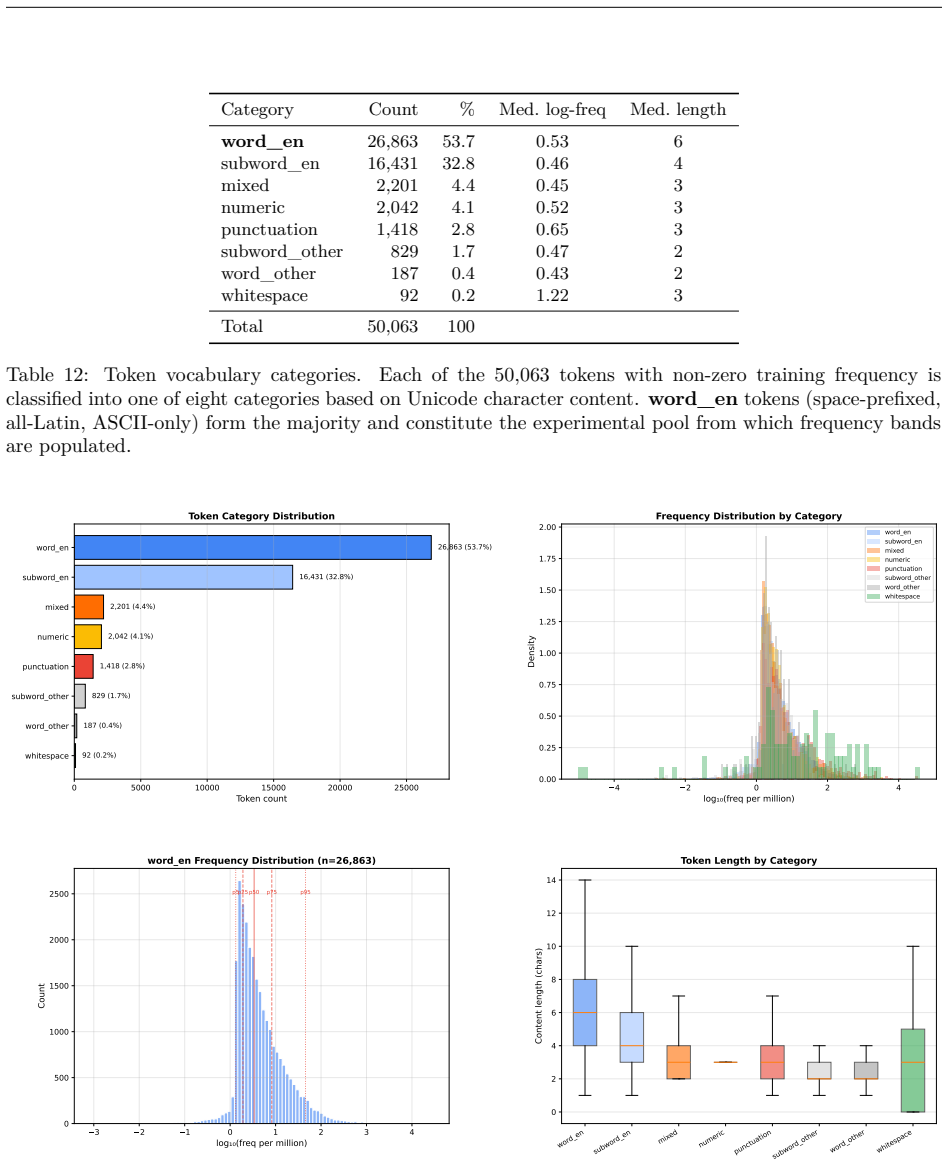
- [§3.1] The abstract and §3.1 refer to '75 circuits' but do not state how many independent extractions were performed per band-model pair; this detail would clarify the within-band variability analysis.
- [Figure 3] Figure 3 (edge-level vs. source-level faithfulness) would benefit from error bars or per-model scatter to show consistency of the inflation effect across the five model sizes.
- [§3] Notation for the four frequency bands is introduced in §3 but the exact token-frequency cutoffs are only given in an appendix; moving the definition to the main text would improve readability.
Simulated Author's Rebuttal
Thank you for the positive assessment and constructive comments. We address each major comment below and will incorporate the requested clarifications into the revised manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (cross-band transfer results): the reported broad transfer of band-specific edges is central to the phantom-specialization claim, yet the manuscript does not report the exact threshold used to classify an edge as 'transferring' or the statistical test for whether transfer rates differ significantly from within-band baselines.
Authors: We agree that these details are necessary for reproducibility. We will revise §4.2 to explicitly report the threshold used to classify an edge as transferring and to include the statistical test (with results) comparing cross-band transfer rates to within-band baselines. revision: yes
-
Referee: [§5] §5 (interchange intervention protocol): the claim that representations are interchangeable rests on the interchange tests recovering performance; however, the description does not specify how the source and target activations are aligned when the circuits differ in edge sets, which is load-bearing for interpreting the results as evidence of functional equivalence.
Authors: We thank the referee for highlighting this omission. We will revise §5 to specify the alignment procedure for activations (mapping by layer and component indices in the computational graph) when source and target circuits have differing edge sets. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical study that extracts circuits via standard methods, measures cross-band transfer, shared-core performance, and interchange interventions on fixed-task inputs with varied statistics. No derivation, equation, or first-principles claim is present that could reduce to fitted parameters, self-definitions, or self-citation chains. All load-bearing evidence consists of direct experimental measurements (edge transfer rates, faithfulness scores >=99%, interchange success) that are falsifiable outside any internal fit. The design isolates input distribution while holding task fixed, and results are reported via standard evaluation metrics without renaming or smuggling ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Circuit discovery methods identify subgraphs that explain specific model behaviors
invented entities (1)
-
phantom specialization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
II. An argument for divine providence, taken from the constant regularity observ'd in the births of both sexes. By Dr. John Arbuthnott, Physitian in Ordinary to Her Majesty, and Fellow of the College of Physitians and the Royal Society , author =. 1710 , journal =. doi:10.1098/rstl.1710.0011 , url =
-
[2]
2025 , booktitle =
On Mechanistic Circuits for Extractive Question-Answering , author =. 2025 , booktitle =
2025
-
[3]
Eliciting Latent Predictions from Transformers with the Tuned Lens , author =. 2023 , url =. 2303.08112 , archiveprefix =
Pith/arXiv arXiv 2023
-
[4]
1995 , journal =
Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing , author =. 1995 , journal =
1995
-
[5]
Finding Transformer Circuits With Edge Pruning , author =. 2024 , booktitle =. doi:10.52202/079017-0587 , url =
-
[6]
Stella Biderman and Hailey Schoelkopf and Quentin Gregory Anthony and Herbie Bradley and Kyle O'Brien and Eric Hallahan and Mohammad Aflah Khan and Shivanshu Purohit and USVSN Sai Prashanth and Edward Raff and Aviya Skowron and Lintang Sutawika and Oskar van der Wal , year =. Pythia:. International Conference on Machine Learning,
-
[7]
Tolga Bolukbasi and Adam Pearce and Ann Yuan and Andy Coenen and Emily Reif and Fernanda B. Vi. An Interpretability Illusion for. 2021 , journal =. 2104.07143 , timestamp =
arXiv 2021
-
[8]
2024 , booktitle =
Using Degeneracy in the Loss Landscape for Mechanistic Interpretability , author =. 2024 , booktitle =
2024
-
[9]
2022 , journal =
Causal scrubbing, a method for rigorously testing interpretability hypotheses , author =. 2022 , journal =
2022
-
[10]
2023 , booktitle =
A Toy Model of Universality: Reverse Engineering how Networks Learn Group Operations , author =. 2023 , booktitle =
2023
-
[11]
2013 , publisher =
Statistical Power Analysis for the Behavioral Sciences , author =. 2013 , publisher =
2013
-
[12]
Induction Heads as an Essential Mechanism for Pattern Matching in In-context Learning , author =. 2025 , booktitle =. doi:10.18653/v1/2025.findings-naacl.283 , url =
-
[13]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , year =. Proceedings of the 2019 Conference of the North. doi:10.18653/v1/N19-1423 , url =
-
[14]
Transcoders find interpretable
Dunefsky, Jacob and Chlenski, Philippe and Nanda, Neel , year =. Transcoders find interpretable. Advances in Neural Information Processing Systems , volume =. doi:10.52202/079017-0768 , url =
-
[15]
2024 , journal =
How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning , author =. 2024 , journal =
2024
-
[16]
Degeneracy and complexity in biological systems , author =. 2001 , journal =. doi:10.1073/pnas.231499798 , url =. https://www.pnas.org/doi/pdf/10.1073/pnas.231499798 , abstract =
-
[17]
2024 , booktitle =
The Evolution of Statistical Induction Heads: In-Context Learning Markov Chains , author =. 2024 , booktitle =
2024
-
[18]
1987 , journal =
Better Bootstrap Confidence Intervals , author =. 1987 , journal =
1987
-
[19]
2021 , journal =
A Mathematical Framework for Transformer Circuits , author =. 2021 , journal =
2021
-
[20]
2022 , journal =
Toy Models of Superposition , author =. 2022 , journal =
2022
-
[21]
On the Similarity of Circuits across Languages: a Case Study on the Subject-verb Agreement Task , author =. 2024 , booktitle =. doi:10.18653/v1/2024.findings-emnlp.591 , url =
-
[22]
doi: 10.18653/v1/2021.acl-long.144
Causal Analysis of Syntactic Agreement Mechanisms in Neural Language Models , author =. 2021 , booktitle =. doi:10.18653/v1/2021.acl-long.144 , url =
-
[23]
1922 , journal =
On the Interpretation of ^2 from Contingency Tables, and the Calculation of P , author =. 1922 , journal =
1922
-
[24]
1966 , publisher =
The Design of Experiments , author =. 1966 , publisher =
1966
-
[25]
Finding Interpretable Prompt-Specific Circuits in Language Models , author =. 2026 , url =. 2602.13483 , archiveprefix =
Pith/arXiv arXiv 2026
-
[26]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling , author =. 2021 , journal =. 2101.00027 , timestamp =
Pith/arXiv arXiv 2021
-
[27]
How does
Jorge Garc. How does. 2024 , booktitle =
2024
-
[28]
Adversarial Circuit Evaluation , author =. 2024 , journal =. doi:10.48550/ARXIV.2407.15166 , url =. 2407.15166 , timestamp =
-
[29]
Goodman and Christopher Potts and Thomas Icard , year =
Atticus Geiger and Duligur Ibeling and Amir Zur and Maheep Chaudhary and Sonakshi Chauhan and Jing Huang and Aryaman Arora and Zhengxuan Wu and Noah D. Goodman and Christopher Potts and Thomas Icard , year =. Causal Abstraction:. J. Mach. Learn. Res. , volume =
-
[30]
2024 , booktitle =
Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations , author =. 2024 , booktitle =
2024
-
[31]
Localizing Model Behavior with Path Patching
Localizing Model Behavior with Path Patching , author =. 2023 , journal =. doi:10.48550/ARXIV.2304.05969 , url =. 2304.05969 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.05969 2023
-
[32]
2018 , booktitle =
FRAGE: Frequency-Agnostic Word Representation , author =. 2018 , booktitle =
2018
-
[33]
Gould, S. J. and Lewontin, R. C. , year =. The spandrels of. Proceedings of the Royal Society of London. B. Biological Sciences , volume =. doi:10.1098/rspb.1979.0086 , url =
-
[34]
Wang, Ben and Komatsuzaki, Aran , year =
-
[35]
GPT - N eo X -20 B : An Open-Source Autoregressive Language Model
Black, Sidney and Biderman, Stella and Hallahan, Eric and Anthony, Quentin and Gao, Leo and Golding, Laurence and He, Horace and Leahy, Connor and McDonell, Kyle and Phang, Jason and Pieler, Michael and Prashanth, Usvsn Sai and Purohit, Shivanshu and Reynolds, Laria and Tow, Jonathan and Wang, Ben and Weinbach, Samuel , year =. Proceedings of BigScience E...
-
[36]
Groeneveld, Dirk and Beltagy, Iz and Walsh, Evan and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tus...
-
[37]
Position-aware Automatic Circuit Discovery , author =. 2025 , booktitle =. doi:10.18653/v1/2025.acl-long.141 , url =
-
[38]
How does
Michael Hanna and Ollie Liu and Alexandre Variengien , year =. How does. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , url =
2023
-
[39]
2024 , booktitle =
Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms , author =. 2024 , booktitle =
2024
-
[40]
A circuit for
Heimersheim, Stefan and Janiak, Jett , year =. A circuit for
-
[41]
How to use and interpret activation patching
How to use and interpret activation patching , author =. 2024 , journal =. doi:10.48550/ARXIV.2404.15255 , url =. 2404.15255 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.15255 2024
-
[42]
Quanti- fying causal emergence shows that macro can beat micro
Quantifying causal emergence shows that macro can beat micro , author =. 2013 , journal =. doi:10.1073/pnas.1314922110 , url =. https://www.pnas.org/doi/pdf/10.1073/pnas.1314922110 , abstract =
-
[43]
2024 , booktitle =
Successor Heads: Recurring, Interpretable Attention Heads In The Wild , author =. 2024 , booktitle =
2024
-
[44]
Bulletin de la Soci
Jaccard, Paul , year =. Bulletin de la Soci
-
[45]
1954 , journal =
A Distribution-Free k-Sample Test Against Ordered Alternatives , author =. 1954 , journal =
1954
-
[46]
2019 , booktitle =
Similarity of Neural Network Representations Revisited , author =. 2019 , booktitle =
2019
-
[47]
Atp*: An efficient and scalable method for localizing llm behaviour to components
J. AtP*: An efficient and scalable method for localizing. 2024 , journal =. doi:10.48550/ARXIV.2403.00745 , url =. 2403.00745 , timestamp =
-
[48]
1952 , journal =
Use of Ranks in One-Criterion Variance Analysis , author =. 1952 , journal =
1952
-
[49]
Towards Interpretable Sequence Continuation: Analyzing Shared Circuits in Large Language Models , author =. 2024 , booktitle =. doi:10.18653/v1/2024.emnlp-main.699 , url =
-
[50]
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla , author =. 2023 , url =. 2307.09458 , archiveprefix =
arXiv 2023
-
[51]
2023 , booktitle =
Tracr: Compiled Transformers as a Laboratory for Interpretability , author =. 2023 , booktitle =
2023
-
[52]
Distributed Specialization: Rare-Token Neurons in Large Language Models , author =. 2025 , url =. 2509.21163 , archiveprefix =
arXiv 2025
-
[53]
Repetitions are not all alike: distinct mechanisms sustain repetition in language models , author =. 2025 , url =. 2504.01100 , archiveprefix =
arXiv 2025
-
[54]
2024 , booktitle =
Is This the Subspace You Are Looking for? An Interpretability Illusion for Subspace Activation Patching , author =. 2024 , booktitle =
2024
-
[55]
1947 , journal =
On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other , author =. 1947 , journal =
1947
-
[56]
1967 , journal =
The Detection of Disease Clustering and a Generalized Regression Approach , author =. 1967 , journal =
1967
-
[57]
2025 , booktitle =
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author =. 2025 , booktitle =
2025
-
[58]
Copy Suppression: Comprehensively Understanding a Motif in Language Model Attention Heads , author =. 2024 , booktitle =. doi:10.18653/v1/2024.blackboxnlp-1.22 , url =
-
[59]
The Hydra Effect: Emergent Self-repair in Language Model Computations , author =. 2023 , url =. 2307.15771 , archiveprefix =
arXiv 2023
-
[60]
2025 , booktitle =
Everything, Everywhere, All at Once: Is Mechanistic Interpretability Identifiable? , author =. 2025 , booktitle =
2025
-
[61]
Mechanistic Interpretability as Statistical Estimation: A Variance Analysis , author =. 2025 , url =. 2510.00845 , archiveprefix =
Pith/arXiv arXiv 2025
-
[62]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , year =. Locating and Editing Factual Associations in. Advances in Neural Information Processing Systems , volume =
-
[63]
2024 , booktitle =
Circuit Component Reuse Across Tasks in Transformer Language Models , author =. 2024 , booktitle =
2024
-
[64]
2025 , booktitle =
On Linear Representations and Pretraining Data Frequency in Language Models , author =. 2025 , booktitle =
2025
-
[65]
2024 , booktitle =
Transformer Circuit Evaluation Metrics Are Not Robust , author =. 2024 , booktitle =
2024
-
[66]
Circuit Compositions: Exploring Modular Structures in Transformer-Based Language Models , author =. 2025 , booktitle =. doi:10.18653/v1/2025.acl-long.727 , url =
-
[67]
2025 , booktitle =
Aaron Mueller and Atticus Geiger and Sarah Wiegreffe and Dana Arad and Iv. 2025 , booktitle =
2025
-
[68]
Adaptive Circuit Behavior and Generalization in Mechanistic Interpretability , author =. 2024 , url =. 2411.16105 , archiveprefix =
arXiv 2024
-
[69]
Neel Nanda and Joseph Bloom , year =
-
[70]
2023 , booktitle =
Progress measures for grokking via mechanistic interpretability , author =. 2023 , booktitle =
2023
-
[71]
2023 , booktitle =
Towards Automated Circuit Discovery for Mechanistic Interpretability , author =. 2023 , booktitle =
2023
-
[72]
2025 , booktitle =
Arithmetic Without Algorithms: Language Models Solve Math with a Bag of Heuristics , author =. 2025 , booktitle =
2025
-
[73]
2025 , journal =
Illusion or Algorithm? Investigating Memorization, Emergence, and Symbolic Processing in In-Context Learning , author =. 2025 , journal =
2025
-
[74]
A theory of biological relativity: no privileged level of causation , author =. 2011 , journal =. doi:10.1098/rsfs.2011.0067 , url =
-
[75]
Interpreting
nostalgebraist , year =. Interpreting
-
[76]
Sparse Autoencoders Enable Scalable and Reliable Circuit Identification in Language Models , author =. 2024 , url =. 2405.12522 , archiveprefix =
arXiv 2024
-
[77]
Zoom in: An introduction to circuits
Zoom In: An Introduction to Circuits , author =. 2020 , journal =. doi:10.23915/distill.00024.001 , note =
-
[78]
2022 , journal =
Mechanistic Interpretability, Variables, and the Importance of Interpretable Bases , author =. 2022 , journal =
2022
-
[79]
2022 , journal =
In-context Learning and Induction Heads , author =. 2022 , journal =
2022
-
[80]
Competition of Mechanisms: Tracing How Language Models Handle Facts and Counterfactuals , author =. 2024 , booktitle =. doi:10.18653/v1/2024.acl-long.458 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.