Recognition: no theorem link
Finding Interpretable Prompt-Specific Circuits in Language Models
Pith reviewed 2026-05-15 22:03 UTC · model grok-4.3
The pith
ACC++ extracts causal attention signals from language models in a single forward pass, revealing many are interpretable via natural language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
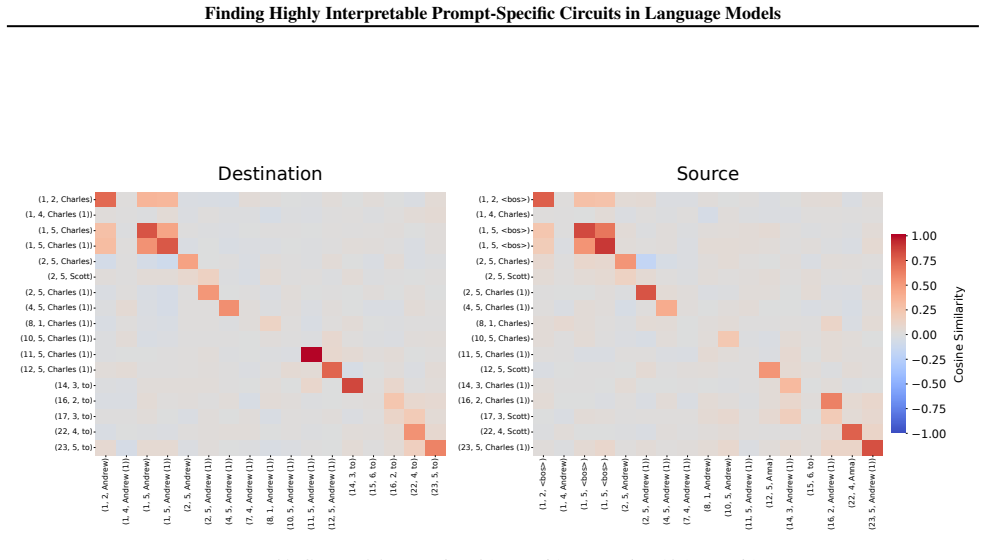
ACC++ extracts circuits consisting of components causal for the model's attention decisions together with the low-dimensional signals used to communicate between them. These signals are the contents of subspaces that cause attention on a token pair. The method works from a single forward pass. A substantial portion of the signals are interpretable, admitting short natural-language descriptions. Applied to indirect object identification, it characterizes sensitivity to prompt structure through prompt-specific circuit clusters and shows that in multilingual cases components are shared while signals are language-specific with distances consistent with linguistic relatedness.
What carries the argument
The attention-causal communication principle, which locates low-dimensional subspaces whose contents cause attention on specific token pairs.
If this is right
- Prompt-specific IOI circuits form clusters with heads receiving systematically different signals for distinct identification mechanisms.
- In multilingual IOI, model components are reused across languages while signals remain language-specific.
- Cross-language circuit distances are consistent with linguistic relatedness.
- ACC++ reveals how circuits adapt to prompt structure and enables characterization of model behavior across varied inputs.
Where Pith is reading between the lines
- The approach could map circuits for other tasks to show how models handle input variations more generally.
- If signals are causal, targeted changes to specific subspaces might steer attention without full model retraining.
- Clustering of circuits by prompt suggests models maintain modular strategies that could be selectively activated.
- Signal analysis might extend to phenomena like negation or coreference to uncover additional mechanisms.
Load-bearing premise
The low-dimensional subspaces identified are the actual causal signals driving attention decisions, and the natural-language descriptions assigned to them reflect genuine model mechanisms rather than post-hoc patterns.
What would settle it
An intervention that perturbs or removes the identified signals in the subspaces but leaves the model's attention patterns unchanged would show the signals are not causal.
Figures

































read the original abstract
Understanding the internal circuits that language models use to solve tasks remains a central challenge in mechanistic interpretability. A crucial part of finding circuits is understanding why each attention head attends where it does. To this end, we introduce ACC++, an improved circuit-tracing method based on the principle of attention-causal communication (ACC) [1], which identifies signals, i.e., contents of low dimensional subspaces that cause attention on a token pair. ACC++ extracts circuits from a single forward pass, without replacement models or patching. Circuits identified by ACC++ consist of components that are causal for the model's attention decisions, together with the low-dimensional signals used to communicate between them. Here, we first detail the conceptual advances that ACC++ makes over previous work. We then show that across multiple models, a substantial portion of ACC++ signals are interpretable: many signals admit a short natural-language description. We next present a number of new insights into model behavior obtained via ACC++. First, we use ACC++'s interpretable circuits to characterize the sensitivity of indirect object identification (IOI) circuits to prompt structure. We find that prompt-specific circuits form well-defined clusters, and across clusters, heads receive systematically different signals corresponding to distinct mechanisms for identifying the IO name. Next, in multilingual IOI, ACC++ circuits show that while model components are reused across languages, signals are often language-specific. In a four-language IOI case study, cross-language circuit distances are consistent with linguistic relatedness. Together, these results show that ACC++ can shed light on a broad spectrum of model behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ACC++, an improved circuit-tracing method based on the attention-causal communication (ACC) principle, which identifies low-dimensional signals causing attention on token pairs. It claims to extract circuits—consisting of causal components and the signals communicating between them—from a single forward pass without replacement models or patching. Across models, a substantial portion of these signals are reported as interpretable via short natural-language descriptions. The authors apply ACC++ to indirect object identification (IOI), finding that prompt-specific circuits form well-defined clusters with heads receiving systematically different signals for distinct mechanisms, and to multilingual IOI, showing component reuse but language-specific signals whose cross-language distances align with linguistic relatedness.
Significance. If the causal status of the identified subspaces is established, ACC++ would offer a computationally efficient alternative to patching-based methods for discovering interpretable circuits and prompt-specific behaviors, enabling broader analysis of model mechanisms such as sensitivity to prompt structure and cross-lingual processing.
major comments (3)
- [Abstract] Abstract: the claim that ACC++ signals 'cause attention on a token pair' and that circuits consist of 'components that are causal for the model's attention decisions' rests entirely on the untested ACC principle without any interventions, ablations, or counterfactual tests; no patching or replacement-model experiments are described to verify sufficiency or necessity of the subspaces.
- [Results on interpretability] Interpretability results: the assertion that 'a substantial portion of ACC++ signals are interpretable' provides no quantitative metrics (e.g., fraction of signals with descriptions, inter-rater reliability, or automated validation), error analysis, or details on how natural-language descriptions were assigned and verified, leaving the strength of the interpretability claim unassessable.
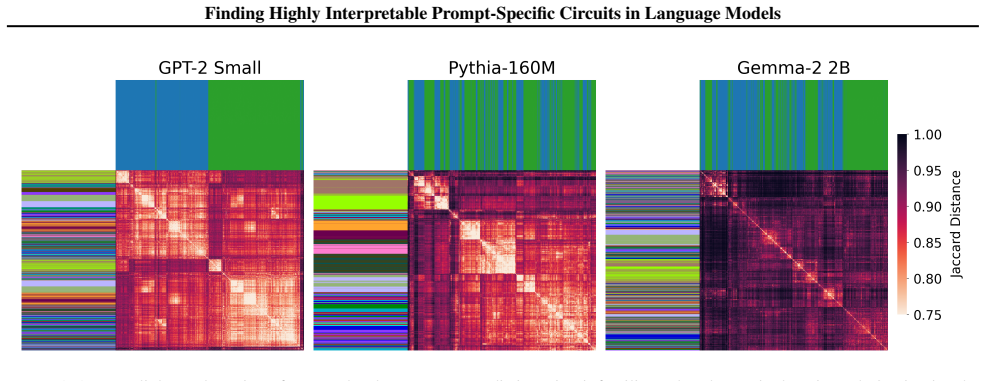
- [IOI case study] IOI analysis: the claims that prompt-specific circuits 'form well-defined clusters' and that heads 'receive systematically different signals corresponding to distinct mechanisms' lack specification of the clustering algorithm, distance metric, statistical significance tests, or controls showing that signal differences drive the observed behavioral distinctions rather than correlate with them.
minor comments (1)
- [Introduction] The description of conceptual advances over prior ACC work would benefit from an explicit comparison table or enumerated list of differences in assumptions and outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, proposing specific revisions to strengthen the paper while preserving its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that ACC++ signals 'cause attention on a token pair' and that circuits consist of 'components that are causal for the model's attention decisions' rests entirely on the untested ACC principle without any interventions, ablations, or counterfactual tests; no patching or replacement-model experiments are described to verify sufficiency or necessity of the subspaces.
Authors: The ACC principle was introduced and empirically validated via interventions in our prior work [1], which established the causal role of the identified low-dimensional subspaces for attention decisions. ACC++ extends this by providing an efficient extraction method without requiring new replacement models. To directly address the concern, we will revise the abstract and introduction to explicitly reference the validation experiments from [1], add a dedicated subsection summarizing those results, and include new ablation studies (e.g., subspace perturbation tests) on the models studied here to reconfirm sufficiency and necessity. revision: yes
-
Referee: [Results on interpretability] Interpretability results: the assertion that 'a substantial portion of ACC++ signals are interpretable' provides no quantitative metrics (e.g., fraction of signals with descriptions, inter-rater reliability, or automated validation), error analysis, or details on how natural-language descriptions were assigned and verified, leaving the strength of the interpretability claim unassessable.
Authors: We agree that quantitative support is needed to make the interpretability claim fully assessable. The current manuscript relies on qualitative examples; in revision we will add: (i) the exact fraction of signals assigned consistent natural-language descriptions across models, (ii) inter-rater reliability metrics (Cohen's kappa) from multiple annotators, (iii) a detailed description of the annotation protocol, and (iv) an error analysis categorizing uninterpretable signals. These additions will be placed in a new subsection under Results. revision: yes
-
Referee: [IOI case study] IOI analysis: the claims that prompt-specific circuits 'form well-defined clusters' and that heads 'receive systematically different signals corresponding to distinct mechanisms' lack specification of the clustering algorithm, distance metric, statistical significance tests, or controls showing that signal differences drive the observed behavioral distinctions rather than correlate with them.
Authors: We will clarify the clustering procedure in the revised Methods and Results sections: k-means clustering was applied to the signal embeddings using cosine distance. We will report silhouette scores, perform permutation tests for cluster significance, and add controls (e.g., comparison against shuffled signal labels) to demonstrate that the observed behavioral distinctions are driven by signal differences rather than mere correlation. Updated figures and quantitative tables will accompany these additions. revision: yes
Circularity Check
Minor self-citation to prior ACC principle; new claims are independent empirical observations
full rationale
The paper introduces ACC++ as building on the attention-causal communication (ACC) principle from reference [1] and applies it to extract circuits and signals from single forward passes. The central results on signal interpretability, prompt-specific circuit clusters in IOI, and cross-language signal differences are presented as direct observations from this application, without any equations, derivations, or reductions that make the outputs equivalent to inputs by construction. No fitted parameters are renamed as predictions, no self-definitional loops appear, and no uniqueness theorems or ansatzes are smuggled via self-citation in a load-bearing way for the new claims. The method is self-contained as an observational extension, warranting only a minor score for the reference to prior work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Data-driven Circuit Discovery for Interpretability of Language Models
Standard circuit discovery methods produce dataset-specific circuits rather than task-general ones, and a new clustering-based method discovers multiple more faithful circuits per dataset.
Reference graph
Works this paper leans on
-
[1]
the input residual embedding at token d at the input to layer ℓ
URL https://arxiv.org/abs/2308.0 9124. Hewitt, J., Geirhos, R., and Kim, B. Position: We can’t understand AI using our existing vocabulary. InForty- second International Conference on Machine Learning 10 Finding Highly Interpretable Prompt-Specific Circuits in Language Models Position Paper Track, 2025. URL https://openre view.net/forum?id=asQJx56NqB. Hub...
-
[2]
Set up the counterfactual.Choose an attention head and a destination–source pair, then decide whether we are searching fordestinationsignals (in the destination token) orsourcesignals (distributed across all source tokens that compete under Softmax)
-
[3]
Enumerate candidate signals.Decompose the residual stream into outputs of upstream components, and project each component’s contribution onto the head’s singular-vector directions to form a set of candidate signals
-
[4]
Build a contribution table.Convert candidates into a contribution matrix whose rows correspond to candidate signals and whose columns correspond to source positions in the destination row of attention scores
-
[5]
Score candidates with attribution.Use Integrated Gradients to assign each candidate a fixed importance score for the attention weight on the chosen source token, while accounting for Softmax competition across all sources
-
[6]
Solve the counterfactual by greedy removal.Starting from the full set of candidates, iteratively remove the highest- scoring candidates and recompute the attention weight until it drops below a chosen threshold; the removed candidates form the ACC++ explanation set. Destination intervention (find destination signals).Let Mdst denote a set of destination-s...
work page 2017
-
[7]
Interpretation Stage:we prompt an LLM with the top-40 examples for a signal to generate a single short interpretation
-
[8]
the [[cat]] sat on the << mat>>
Evaluation Stage:to score an interpretation, we take the top-20 examples (highest-scoring among the top-40) and mix them with 20 random control examplessampled independently for that same signal, then ask an LLM judge to decide whether the interpretation explains each example (Paulo et al., 2025). Interpretation stageGiven the top-40 activating examples f...
work page 2025
-
[9]
Return the results as a Python Dictionary
-
[10]
The keys must be the example numbers (1 to 10), and the values must be the binary label (0 or 1)
-
[11]
Do not assume the order; explicitly check the number I assigned to each example
-
[12]
Ignore any numbers or formatting artifacts INSIDE the text strings (e.g., if a text contains "4).", ignore it)
-
[13]
Output format: { 1: 0, 2: 1, ... 10: 0 } Here are the examples: <user_prompt> Feature interpretation: Words related to American football positions, specifically the tight end position. Text examples:
-
[14]
Getty Images [[ Patriots]]<< tight>> end Rob Gronkowski had his boss
-
[15]
posted You should know this[[ about]] offensive line coaches: they are large, demanding<< men>>
-
[16]
Media Day 2015 LSU [[ defensive]] end Isaiah Washington (94) speaks to<< the>>
work page 2015
-
[17]
running [[ backs]],’’ he said. .. Defensive << end>> Carroll Phillips is improving and his injury is
-
[18]
Then, Jack and Kelly went to the garden. Jack gave a basketball to
[[ line]], with the left side namely << tackle>> Byron Bell at tackle and guard Amini <assistant_response> { 1: 1, 2: 0, 3: 0, 4: 1, 5: 1, } Now evaluate the following examples: Signals for which the interpreter returns no valid interpretation found are treated as missing interpretations and are excluded from scoring-based analyses. Across models, the fra...
work page 1922
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.