Adapting Diffusion Language Models for Lossless Pixel-Level Image Transmission
Pith reviewed 2026-06-27 23:26 UTC · model grok-4.3
The pith
Adapting discrete diffusion models enables synchronized arithmetic coding for exact pixel recovery over noisy channels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
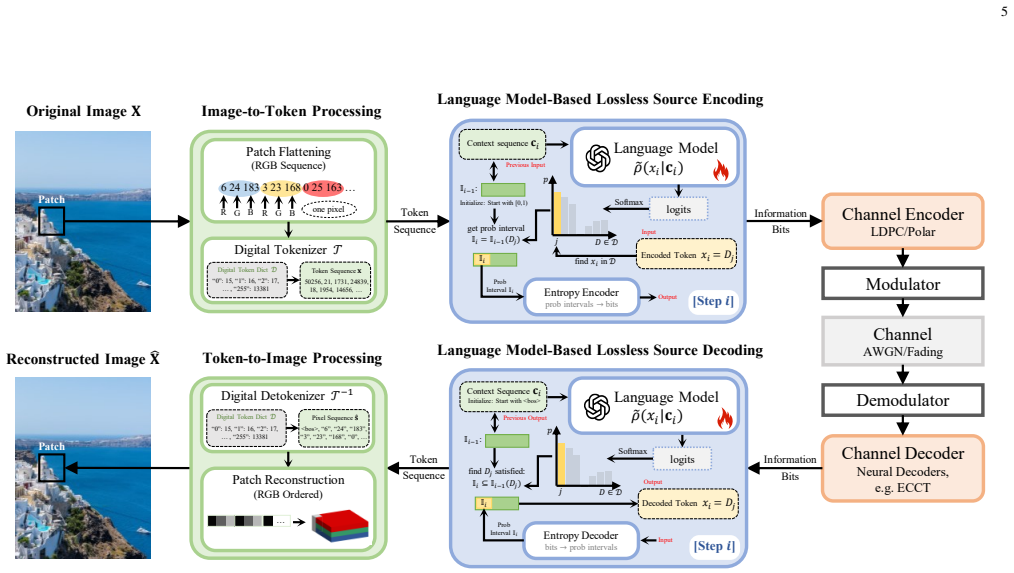
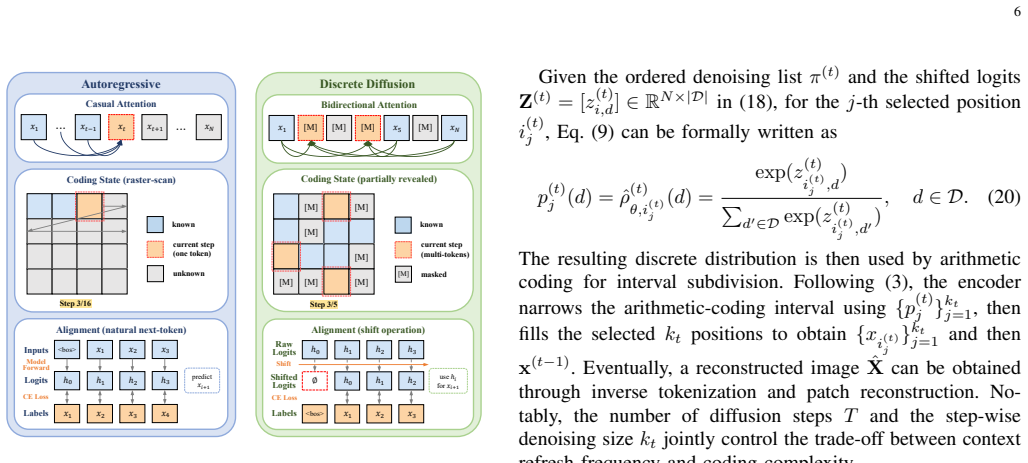
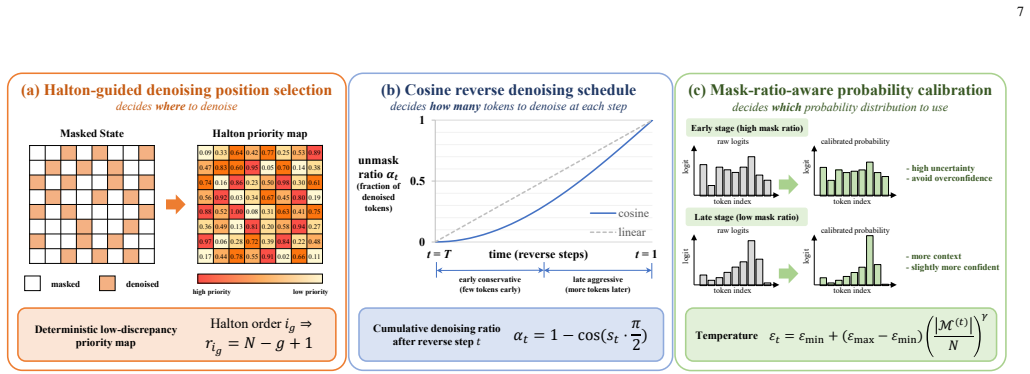
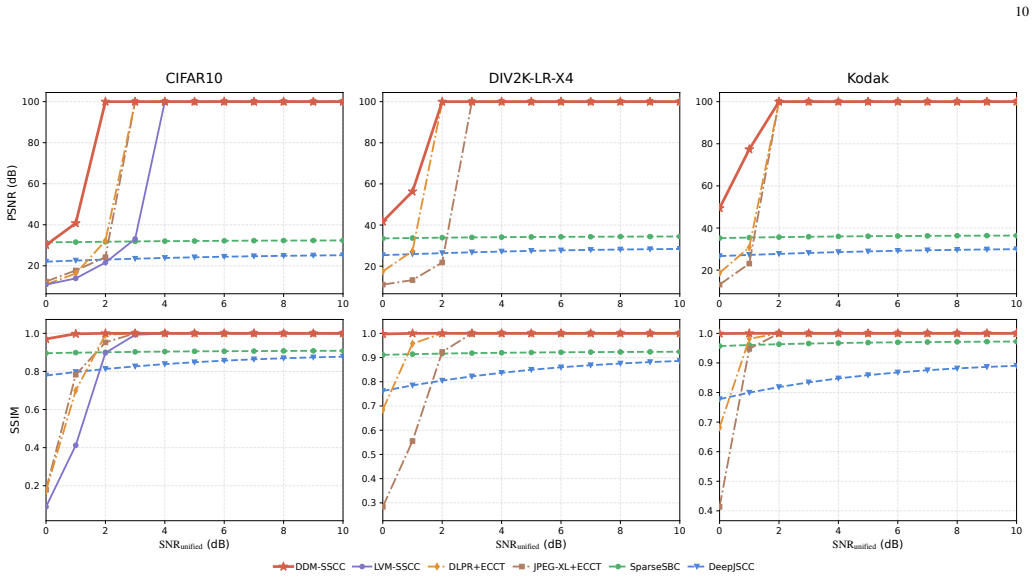
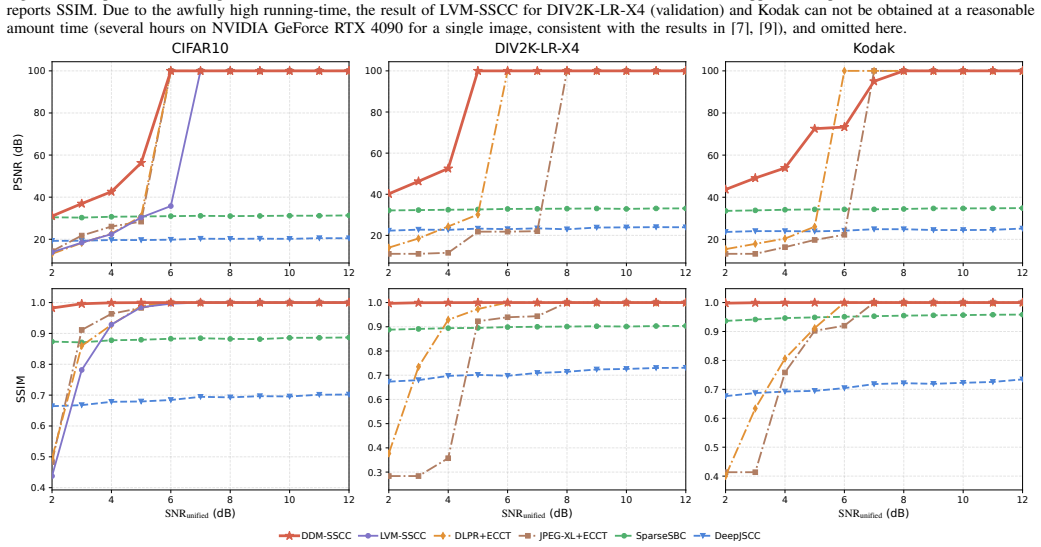
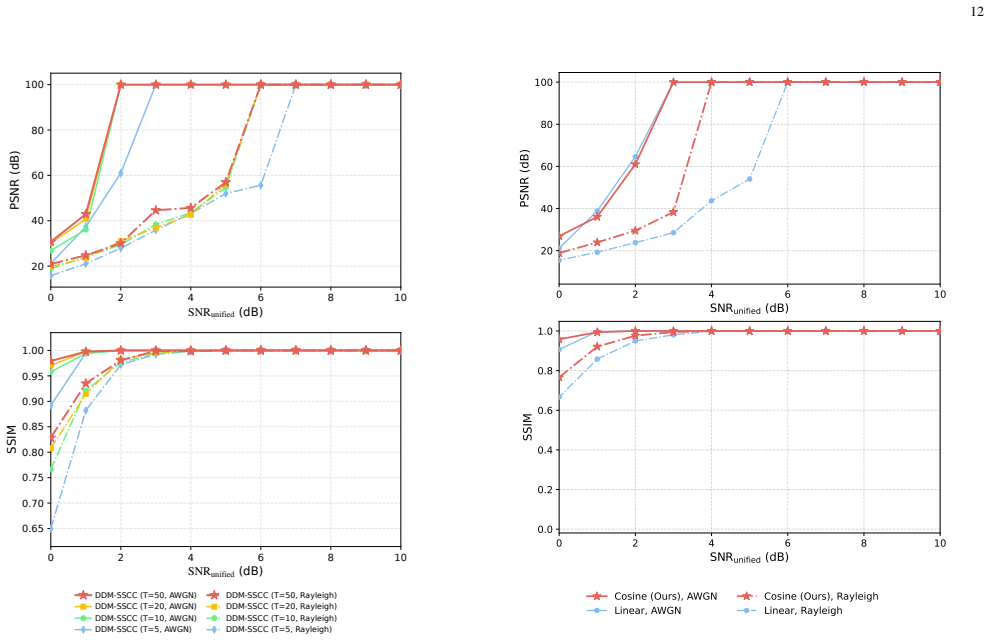
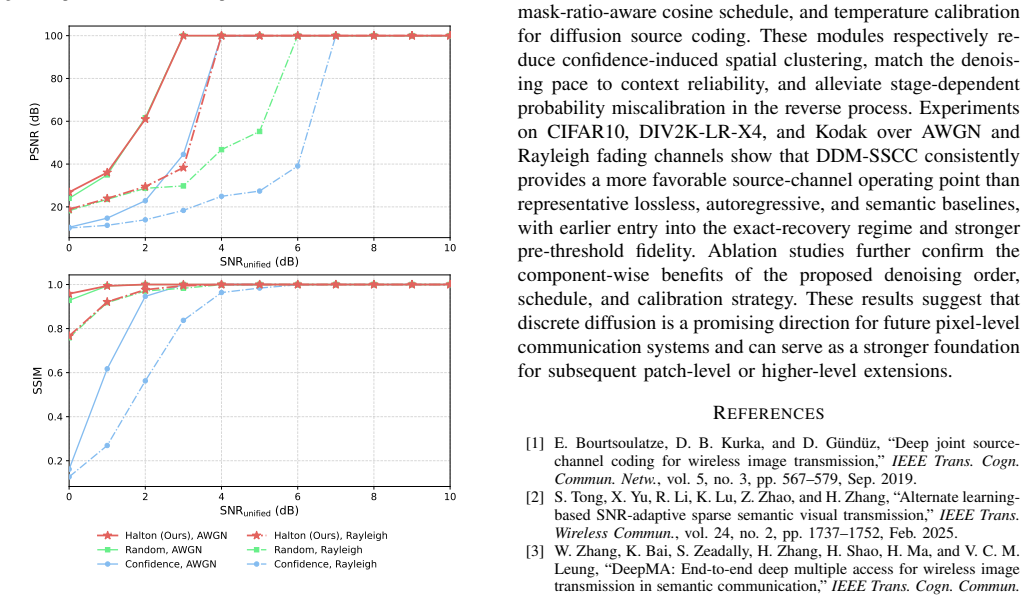
DDM-SSCC adapts a diffusion language model to pixel-token restoration and synchronized reverse arithmetic coding, allowing multiple masked tokens to be coded within one reverse denoising step; the progressive process supplies restored tokens as bidirectional context for subsequent steps, and the added Halton-guided order, mask-ratio-aware cosine schedule, and temperature calibration module together produce probability tables accurate enough for exact recovery, yielding higher exact-recovery rates than representative lossless and semantic baselines on CIFAR10, DIV2K-LR-X4, and Kodak over AWGN and Rayleigh channels.
What carries the argument
DDM-SSCC framework that adapts diffusion-language-model masked denoising to bidirectional arithmetic coding, using a Halton-guided denoising order, mask-ratio-aware cosine schedule, and temperature calibration to align generation probabilities with lossless coding requirements.
Load-bearing premise
The Halton-guided denoising order, mask-ratio-aware cosine schedule, and lightweight temperature calibration module successfully bridge the gap between masked denoising in diffusion models and the requirements of lossless arithmetic coding for exact pixel recovery.
What would settle it
Removing the three proposed modules and measuring whether exact-recovery rates on the same CIFAR10 and Kodak test sets over AWGN fall below those of standard raster-order autoregressive lossless coders would falsify the bridging claim.
Figures



read the original abstract
Lossless pixel-level image transmission is a fundamental regime beyond semantic communications, because exact recovery requires both accurate symbol probability modeling and reliable delivery over noisy channels. This paper proposes DDM-SSCC, a discrete-diffusion-model-based separate source-channel coding framework for lossless image transmission. Different from raster-order autoregressive coding, the proposed source codec adapts a diffusion language model to pixel-token restoration and performs synchronized reverse arithmetic coding under bidirectional attention, allowing multiple masked tokens to be coded within one reverse denoising step. This progressive restoration process also yields a more favorable source representation for noisy transmission, since newly restored tokens can serve as bidirectional context in subsequent denoising steps. To bridge the gap between generation-oriented masked denoising and lossless arithmetic coding, we further introduce a Halton-guided denoising order, a mask-ratio-aware cosine schedule, and a lightweight temperature calibration module. These designs respectively improve spatial coverage, adapt the denoising pace to context reliability, and calibrate the probability tables used by arithmetic coding. Experiments on CIFAR10, DIV2K-LR-X4, and Kodak over additive white Gaussian noise and Rayleigh fading channels show that DDM-SSCC achieves better exact-recovery performance than representative lossless and semantic communication baselines, while ablation studies verify the effectiveness of the proposed denoising order, schedule, and calibration modules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DDM-SSCC, a discrete-diffusion-model-based separate source-channel coding (SSCC) framework for lossless pixel-level image transmission. It adapts a diffusion language model to perform synchronized reverse arithmetic coding under bidirectional attention, replacing raster-order autoregressive modeling with masked denoising that restores multiple tokens per step. Three adaptations—Halton-guided denoising order, mask-ratio-aware cosine schedule, and lightweight temperature calibration—are introduced to align generation-oriented diffusion with the determinism required for exact arithmetic decoding. Experiments on CIFAR10, DIV2K-LR-X4, and Kodak over AWGN and Rayleigh fading channels report superior exact-recovery performance versus representative lossless and semantic baselines, with ablations supporting the three modules.
Significance. If the probability tables remain consistent and reversible across synchronized encoder/decoder steps, the approach could meaningfully extend diffusion models beyond generation to exact-recovery transmission tasks, leveraging bidirectional context for more robust source representations. The explicit ablation studies on the denoising order, schedule, and calibration constitute a strength in isolating component contributions.
major comments (2)
- [§3 and §4] §3 (Method) and §4 (Experiments): The central claim of exact pixel recovery on perfect channels requires that the Halton order, mask-ratio-aware cosine schedule, and temperature calibration produce identical probability tables at corresponding encoder and decoder steps. No formal argument, pseudocode verification, or empirical check (e.g., zero-error reconstruction rate on noiseless channels) is supplied to confirm that these modules preserve the determinism needed for arithmetic decoding; the skeptic concern therefore remains unaddressed and is load-bearing for the lossless guarantee.
- [Table 1 and §4.2] Table 1 and §4.2: The reported exact-recovery gains over baselines are presented without accompanying bit-rate tables, per-image error breakdowns, or statistical significance tests. This makes it impossible to determine whether the improvements are driven by the diffusion adaptations or by differences in effective rate allocation, undermining the cross-dataset and cross-channel claims.
minor comments (2)
- [§2] §2 (Related Work): The comparison to prior diffusion-based compression works omits recent discrete diffusion language model papers that also target token-level probability modeling; adding these would strengthen positioning.
- [Figure 3] Figure 3: The visualization of the Halton-guided order would benefit from an explicit overlay of the corresponding mask-ratio schedule to illustrate their joint effect on spatial coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, indicating where revisions will be made to strengthen the presentation and validation of our claims.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): The central claim of exact pixel recovery on perfect channels requires that the Halton order, mask-ratio-aware cosine schedule, and temperature calibration produce identical probability tables at corresponding encoder and decoder steps. No formal argument, pseudocode verification, or empirical check (e.g., zero-error reconstruction rate on noiseless channels) is supplied to confirm that these modules preserve the determinism needed for arithmetic decoding; the skeptic concern therefore remains unaddressed and is load-bearing for the lossless guarantee.
Authors: We agree that an explicit verification of determinism is essential to support the lossless guarantee. Section 3 describes how the Halton-guided order, mask-ratio-aware schedule, and temperature calibration are designed to maintain consistent and reversible probability tables across synchronized steps, but we acknowledge the absence of a direct empirical check on noiseless channels. In the revised manuscript, we will add results in §4 showing 100% exact-recovery rates on perfect channels (zero-error reconstruction) for all datasets to empirically confirm this property. revision: yes
-
Referee: [Table 1 and §4.2] Table 1 and §4.2: The reported exact-recovery gains over baselines are presented without accompanying bit-rate tables, per-image error breakdowns, or statistical significance tests. This makes it impossible to determine whether the improvements are driven by the diffusion adaptations or by differences in effective rate allocation, undermining the cross-dataset and cross-channel claims.
Authors: We acknowledge that additional details on rates and variability would help isolate the contributions of our adaptations from rate allocation effects. The current experiments emphasize exact-recovery performance under the SSCC framework, where source rates are determined by the arithmetic coding with the learned probabilities. In the revision, we will augment Table 1 and §4.2 with bit-rate tables, per-image error breakdowns, and statistical significance tests (e.g., paired t-tests) to address this concern. revision: yes
Circularity Check
No significant circularity; independent adaptations validated experimentally
full rationale
The paper proposes DDM-SSCC by adapting a diffusion language model with three explicitly introduced components (Halton-guided order, mask-ratio-aware cosine schedule, temperature calibration) to enable synchronized bidirectional arithmetic coding. These modules are presented as new designs to address the generation-vs-determinism mismatch, with effectiveness shown via ablation studies and comparative experiments on CIFAR10/DIV2K/Kodak rather than any reduction to fitted inputs, self-definitional equations, or load-bearing self-citations. The central claim of exact-recovery superiority rests on measured performance, not on any quantity that equals its own construction by definition. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- cosine schedule parameters
- temperature calibration parameters
axioms (1)
- domain assumption Diffusion models can be synchronized with reverse arithmetic coding under bidirectional attention for multiple tokens.
Reference graph
Works this paper leans on
-
[1]
Deep joint source- channel coding for wireless image transmission,
E. Bourtsoulatze, D. B. Kurka, and D. G ¨und¨uz, “Deep joint source- channel coding for wireless image transmission,”IEEE Trans. Cogn. Commun. Netw., vol. 5, no. 3, pp. 567–579, Sep. 2019
2019
-
[2]
Alternate learning- based SNR-adaptive sparse semantic visual transmission,
S. Tong, X. Yu, R. Li, K. Lu, Z. Zhao, and H. Zhang, “Alternate learning- based SNR-adaptive sparse semantic visual transmission,”IEEE Trans. Wireless Commun., vol. 24, no. 2, pp. 1737–1752, Feb. 2025
2025
-
[3]
DeepMA: End-to-end deep multiple access for wireless image transmission in semantic communication,
W. Zhang, K. Bai, S. Zeadally, H. Zhang, H. Shao, H. Ma, and V . C. M. Leung, “DeepMA: End-to-end deep multiple access for wireless image transmission in semantic communication,”IEEE Trans. Cogn. Commun. Netw., vol. 10, no. 2, pp. 387–402, Apr. 2024
2024
-
[4]
Lightweight joint source-channel coding for semantic communications,
Y . Jia, Z. Huang, K. Luo, and W. Wen, “Lightweight joint source-channel coding for semantic communications,”IEEE Commun. Lett., vol. 27, no. 12, pp. 3161–3165, Dec. 2023
2023
-
[5]
Language modeling is compression,
G. Del ´etang, A. Ruoss, P.-A. Duquenne, E. Catt, T. Genewein, C. Mat- tern, J. Grau-Moya, L. K. Wenliang, M. Aitchison, L. Orseau, M. Hutter, and J. Veness, “Language modeling is compression,” inProc. Int. Conf. Learn. Represent. (ICLR), Vienna, Austria, May 2024
2024
-
[6]
Compression represents intelligence linearly,
Y . Huang, J. Zhang, Z. Shan, and J. He, “Compression represents intelligence linearly,” Apr. 2024, arXiv preprint arXiv:2404.09937. 13
arXiv 2024
-
[7]
Lossless data compression by large models,
Z. Li, C. Huang, X. Wang, H. Hu, C. Wyeth, D. Bu, Q. Yu, W. Gao, X. Liu, and M. Li, “Lossless data compression by large models,”Nat. Mach. Intell., vol. 7, no. 5, pp. 794–799, May 2025
2025
-
[8]
Large language model for lossless image compression with visual prompts,
J. Du, C. Zhou, N. Cao, G. Chen, Y . Chen, Z. Cheng, L. Song, G. Lu, and W. Zhang, “Large language model for lossless image compression with visual prompts,” Feb. 2025, arXiv preprint arXiv:2502.16163
arXiv 2025
-
[9]
Large language models for lossless image compression: Next-pixel prediction in language space is all you need,
K. Chen, P. Zhang, H. Liu, J. Liu, Y . Liu, J. Huang, S. Wang, H. Yan, and H. Li, “Large language models for lossless image compression: Next-pixel prediction in language space is all you need,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), San Diego, USA, Dec. 2025
2025
-
[10]
Separate source channel coding is still what you need: An LLM-based rethinking,
T. Ren, R. Li, M. min Zhao, X. Chen, G. Liu, Y . Yang, Z. Zhao, and H. Zhang, “Separate source channel coding is still what you need: An LLM-based rethinking,”ZTE Commun., vol. 23, no. 1, pp. 30–44, Mar. 2025
2025
-
[11]
Error correction code transformer,
Y . Choukroun and L. Wolf, “Error correction code transformer,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), New Orleans, USA, Nov. 2022, pp. 38 695–38 705
2022
-
[12]
A foundation model for error correction codes,
——, “A foundation model for error correction codes,” inProc. Int. Conf. Learn. Represent. (ICLR), Vienna, Austria, May 2024
2024
-
[13]
U-shaped error correction code transform- ers,
D.-T. Nguyen and S. Kim, “U-shaped error correction code transform- ers,”IEEE Trans. Cogn. Commun. Netw., vol. 11, no. 2, pp. 975–986, Apr. 2025
2025
-
[14]
Self- critical alternate learning-based semantic broadcast communication,
Z. Lu, R. Li, M. Lei, C. Wang, Z. Zhao, and H. Zhang, “Self- critical alternate learning-based semantic broadcast communication,” IEEE Trans. Commun., vol. 73, no. 5, pp. 3347–3361, May 2025
2025
-
[15]
Semantic communications using foundation models: Design approaches and open issues,
P. Jiang, C.-K. Wen, X. Yi, X. Li, S. Jin, and J. Zhang, “Semantic communications using foundation models: Design approaches and open issues,”IEEE Wireless Commun., vol. 31, no. 3, pp. 76–84, Jun. 2024
2024
-
[16]
Large AI model-based semantic communications,
F. Jiang, Y . Peng, L. Dong, K. Wang, K. Yang, C. Pan, and X. You, “Large AI model-based semantic communications,”IEEE Wireless Com- mun., vol. 31, no. 3, pp. 68–75, Jun. 2024
2024
-
[17]
Generative AI-driven semantic communication networks: Architecture, technologies and applications,
C. Liang, H. Du, Y . Sun, D. Niyato, J. Kang, D. Zhao, and M. A. Imran, “Generative AI-driven semantic communication networks: Architecture, technologies and applications,”IEEE Trans. Cogn. Commun. Netw., vol. 11, no. 1, pp. 27–47, Feb. 2025
2025
-
[18]
Large AI model empowered multimodal semantic communications,
F. Jiang, L. Dong, Y . Peng, K. Wang, K. Yang, C. Pan, and X. You, “Large AI model empowered multimodal semantic communications,” IEEE Commun. Mag., vol. 63, no. 1, pp. 76–82, Jan. 2025
2025
-
[19]
DiT-JSCC: Rethinking deep JSCC with diffusion transformers and semantic representations,
K. Tan, J. Dai, S. Wang, G. Lu, S. Shao, K. Niu, W. Zhang, and P. Zhang, “DiT-JSCC: Rethinking deep JSCC with diffusion transformers and semantic representations,” 2026, arXiv preprint arXiv:2601.03112
Pith/arXiv arXiv 2026
-
[20]
Low-density parity-check codes,
R. G. Gallager, “Low-density parity-check codes,”IRE Trans. Inf. Theory, vol. 8, no. 1, pp. 21–28, Jan. 1962
1962
-
[21]
Channel polarization: A method for constructing capacity- achieving codes for symmetric binary-input memoryless channels,
E. Arikan, “Channel polarization: A method for constructing capacity- achieving codes for symmetric binary-input memoryless channels,”IEEE Trans. Inf. Theory, vol. 55, no. 7, pp. 3051–3073, Jul. 2009
2009
-
[22]
Deep learning methods for improved decoding of linear codes,
E. Nachmani, E. Marciano, L. Lugosch, W. J. Gross, D. Burshtein, and Y . Be’ery, “Deep learning methods for improved decoding of linear codes,”IEEE J. Sel. Top. Signal Process., vol. 12, no. 1, pp. 119–131, Feb. 2018
2018
-
[23]
Context-based, adaptive, lossless image coding,
X. Wu and N. Memon, “Context-based, adaptive, lossless image coding,” IEEE Trans. Commun., vol. 45, no. 4, pp. 437–444, Apr. 1997
1997
-
[24]
The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG- LS,
M. J. Weinberger, G. Seroussi, and G. Sapiro, “The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG- LS,”IEEE Trans. Image Process., vol. 9, no. 8, pp. 1309–1324, Aug. 2000
2000
-
[25]
JPEG XL next-generation image com- pression architecture and coding tools,
J. Alakuijala, R. van Asseldonk, S. Boukortt, M. Bruse, I.-M. Comsa, M. Firsching, T. Fischbacher, S. Gomez, E. Kliuchnikov, R. Obryk, K. Potempa, A. Rhatushnyak, J. Sneyers, Z. Szabadka, L. Vandevenne, L. Versari, and J. Wassenberg, “JPEG XL next-generation image com- pression architecture and coding tools,” inProc. SPIE Appl. Digit. Image Process. XLII,...
2019
-
[26]
Practical full resolution learned lossless image compression,
F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. V . Gool, “Practical full resolution learned lossless image compression,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, USA, Jun. 2019, pp. 10 629–10 638
2019
-
[27]
Integer discrete flows and lossless compression,
E. Hoogeboom, J. W. T. Peters, R. van den Berg, and M. Welling, “Integer discrete flows and lossless compression,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 32, Vancouver, Canada, Dec. 2019, pp. 12 134–12 144
2019
-
[28]
PILC: Practical image lossless compression with an end-to-end GPU oriented neural framework,
N. Kang, S. Qiu, S. Zhang, Z. Li, and S.-T. Xia, “PILC: Practical image lossless compression with an end-to-end GPU oriented neural framework,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, USA, Jun. 2022, pp. 3739–3748
2022
-
[29]
Learned lossless image compression based on bit plane slicing,
Z. Zhang, H. Wang, Z. Chen, and S. Liu, “Learned lossless image compression based on bit plane slicing,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Seattle, USA, Jun. 2024, pp. 27 579–27 588
2024
-
[30]
CALLIC: Content adaptive learning for lossless image compression,
D. Li, Y . Bai, K. Wang, J. Jiang, X. Liu, and W. Gao, “CALLIC: Content adaptive learning for lossless image compression,” inProc. AAAI Conf. Artif. Intell., vol. 39, no. 5, Philadelphia, USA, Feb. 2025, pp. 4679– 4688
2025
-
[31]
Deep lossy plus residual coding for lossless and near-lossless image compression,
Y . Bai, X. Liu, K. Wang, X. Ji, X. Wu, and W. Gao, “Deep lossy plus residual coding for lossless and near-lossless image compression,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 5, pp. 3577–3594, May 2024
2024
-
[32]
Fitted neural lossless image compres- sion,
Z. Zhang, Z. Chen, and S. Liu, “Fitted neural lossless image compres- sion,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Nashville, USA, Jun. 2025, pp. 23 249–23 258
2025
-
[33]
Generalized Kraft inequality and arithmetic coding,
J. J. Rissanen, “Generalized Kraft inequality and arithmetic coding,” IBM J. Res. Dev., vol. 20, no. 3, pp. 198–203, May 1976
1976
-
[34]
Arithmetic coding for data compression,
I. H. Witten, R. M. Neal, and J. G. Cleary, “Arithmetic coding for data compression,”Commun. ACM, vol. 30, no. 6, pp. 520–540, Jun. 1987
1987
-
[35]
Arithmetic coding for data compression,
P. G. Howard and J. S. Vitter, “Arithmetic coding for data compression,” Proc. IEEE, vol. 82, no. 6, pp. 857–865, Jun. 1994
1994
-
[36]
LLMZip: Lossless text compression using large language models,
C. S. K. Valmeekam, K. Narayanan, D. Kalathil, J.-F. Chamberland, and S. Shakkottai, “LLMZip: Lossless text compression using large language models,” Jun. 2023, arXiv preprint arXiv:2306.04050
arXiv 2023
-
[37]
Generative pretraining from pixels,
M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” inProc. Int. Conf. Mach. Learn. (ICML), ser. Proc. Mach. Learn. Res., vol. 119, Virtual Edition, Jul. 2020, pp. 1691–1703
2020
-
[38]
Structured denoising diffusion models in discrete state-spaces,
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, and R. van den Berg, “Structured denoising diffusion models in discrete state-spaces,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 34, Virtual Edition, Dec. 2021, pp. 17 981–17 993
2021
-
[39]
Diffusion-LM improves controllable text generation,
X. L. Li, J. Thickstun, I. Gulrajani, P. Liang, and T. B. Hashimoto, “Diffusion-LM improves controllable text generation,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 35, New Orleans, USA, Dec. 2022, pp. 4328–4343
2022
-
[40]
Simple and effective masked diffusion language models,
S. S. Sahoo, M. Arriola, Y . Schiff, A. Gokaslan, E. Marroquin, J. T. Chiu, A. M. Rush, and V . Kuleshov, “Simple and effective masked diffusion language models,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 37, Vancouver, Canada, Dec. 2024
2024
-
[41]
Block diffusion: Interpolating between autoregressive and diffusion language models,
M. Arriola, A. Gokaslan, J. T. Chiu, Z. Yang, Z. Qi, J. Han, S. S. Sahoo, and V . Kuleshov, “Block diffusion: Interpolating between autoregressive and diffusion language models,” inProc. Int. Conf. Learn. Represent. (ICLR), Singapore, Apr. 2025
2025
-
[42]
Large language diffusion models,
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J.- R. Wen, and C. Li, “Large language diffusion models,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), San Diego, USA, Dec. 2025
2025
-
[43]
Scaling diffusion language models via adaptation from autoregressive models,
S. Gong, S. Agarwal, Y . Zhang, J. Ye, L. Zheng, M. Li, C. An, P. Zhao, W. Bi, H. Peng, J. Han, and L. Kong, “Scaling diffusion language models via adaptation from autoregressive models,” inProc. Int. Conf. Learn. Represent. (ICLR), Singapore, Apr. 2025
2025
-
[44]
MaskGIT: Masked generative image transformer,
H. Chang, H. Zhang, L. Jiang, C. Liu, and W. T. Freeman, “MaskGIT: Masked generative image transformer,” inProc. IEEE/CVF Conf. Com- put. Vis. Pattern Recognit. (CVPR), New Orleans, USA, Jun. 2022, pp. 11 315–11 325
2022
-
[45]
Halton scheduler for masked generative image transformer,
V . Besnier, M. Chen, D. Hurych, E. Valle, and M. Cord, “Halton scheduler for masked generative image transformer,” inProc. Int. Conf. Learn. Represent. (ICLR), Singapore, Apr. 2025
2025
-
[46]
T. M. Cover and J. A. Thomas,Elements of Information Theory, 2nd ed. Hoboken, NJ, USA: John Wiley & Sons, 2006
2006
-
[47]
Algorithm 247: Radical-inverse quasi- random point sequence,
J. H. Halton and G. B. Smith, “Algorithm 247: Radical-inverse quasi- random point sequence,”Commun. ACM, vol. 7, no. 12, pp. 701–702, Dec. 1964
1964
-
[48]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inProc. Int. Conf. Mach. Learn. (ICML), ser. Proc. Mach. Learn. Res., vol. 70, Sydney, Australia, Aug. 2017, pp. 1321–1330
2017
-
[49]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Toronto, ON, Canada, Tech. Rep., 2009
2009
-
[50]
NTIRE 2017 challenge on single image super-resolution: Dataset and study,
E. Agustsson and R. Timofte, “NTIRE 2017 challenge on single image super-resolution: Dataset and study,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Honolulu, USA, Jul. 2017, pp. 1122–1131
2017
-
[51]
Kodak lossless true color image suite,
R. Franzen, “Kodak lossless true color image suite,” Available online: http://r0k.us/graphics/kodak/, 1999
1999
-
[52]
Block- based adaptive vector lifting schemes for multichannel image coding,
A. Benazza-Benyahia, J.-C. Pesquet, and H. Masmoudi, “Block- based adaptive vector lifting schemes for multichannel image coding,” EURASIP J. Image Video Process., vol. 2007, pp. 1–12, 2007
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.