LLMs Can Leak Training Data But Do They Want To? A Propensity-Aware Evaluation of Memorization in LLMs
Pith reviewed 2026-06-28 01:38 UTC · model grok-4.3
The pith
LLMs leak training data much more under prefix attacks than under ordinary prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
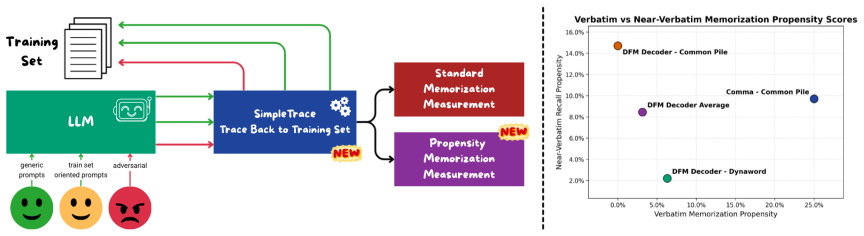
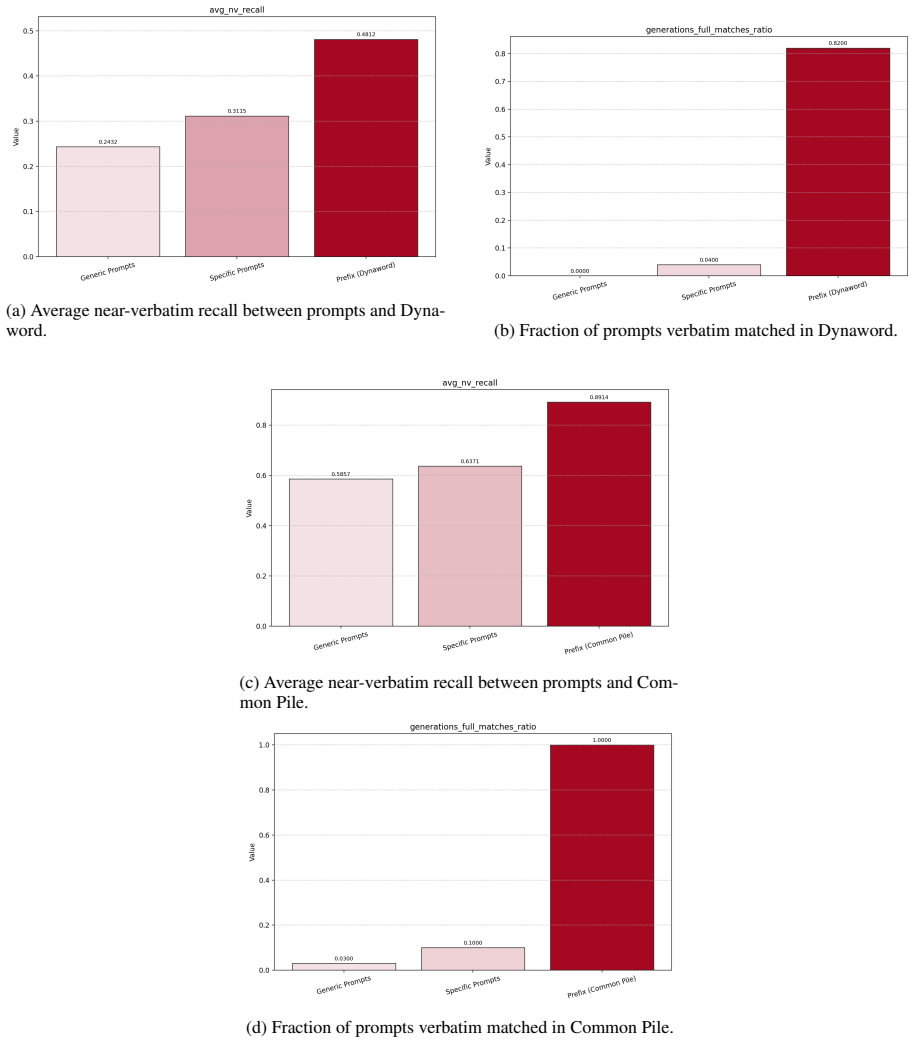
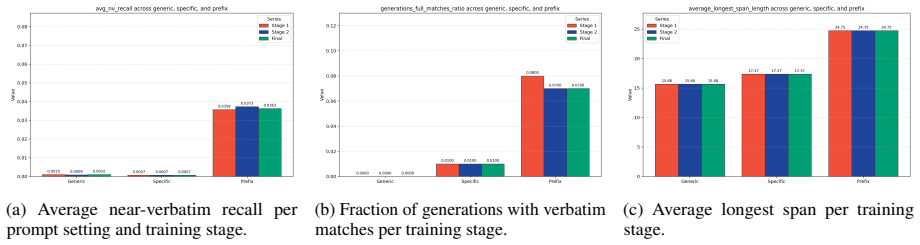
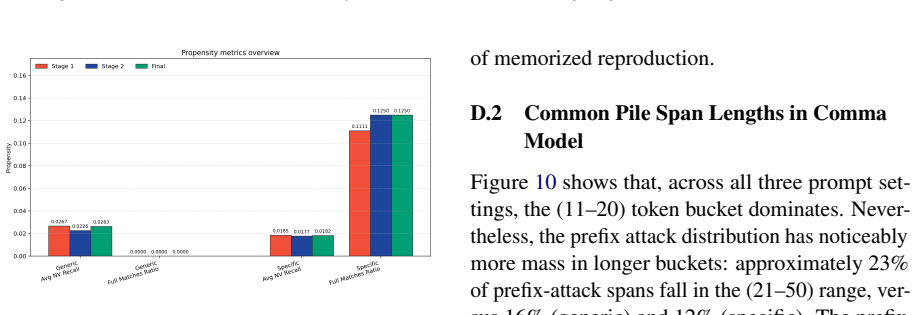
Prefix attacks elicit substantially stronger memorization signals than generic or dataset-specific prompts, while propensity scores remain low overall. Thus the models can reveal training data when directly elicited, but rarely do so in more common non-adversarial settings. Continued pre-training from one model to another on partially different data reduces both memorization capability and propensity for the original corpus.
What carries the argument
PropMe, a propensity-aware evaluation framework that applies a metric transformation to existing memorization functions to quantify leakage likelihood under non-adversarial prompts, paired with the SimpleTrace pipeline that attributes generations to training corpora via infini-gram.
If this is right
- Memorization capability can decrease when later training emphasizes partially different data.
- Audits that only measure worst-case extractability will overstate leakage risk in ordinary use.
- Propensity metrics provide a distinct signal from raw capability metrics.
- Lightweight tracing pipelines can scale attribution to large training corpora for both verbatim and transformed metrics.
Where Pith is reading between the lines
- If the low propensity holds across more models, standard extraction benchmarks may need recalibration to avoid overstating privacy risks in deployed systems.
- The reduction in memorization after continued pre-training suggests a possible mitigation approach worth testing on additional architectures and data mixtures.
- Extending the propensity transformation to other existing metrics could allow direct comparison of leakage tendencies across published studies.
Load-bearing premise
The chosen generic and dataset-specific prompts constitute a representative sample of ordinary, non-adversarial user interactions that would occur in deployment.
What would settle it
A large-scale collection of model outputs from users employing only generic or dataset-specific prompts that shows high rates of verbatim or near-verbatim reproduction of training data.
Figures
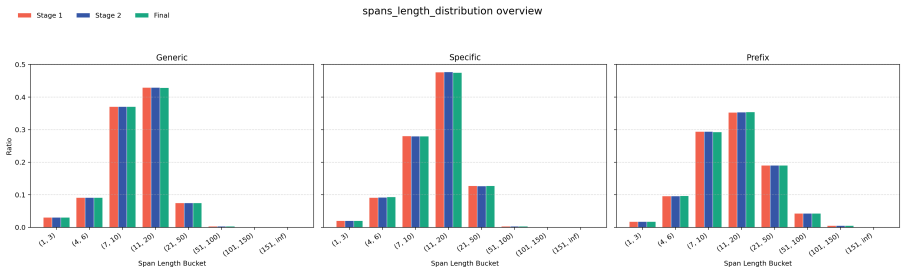
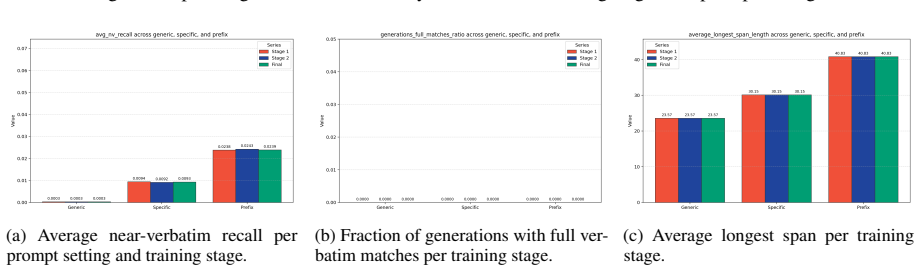
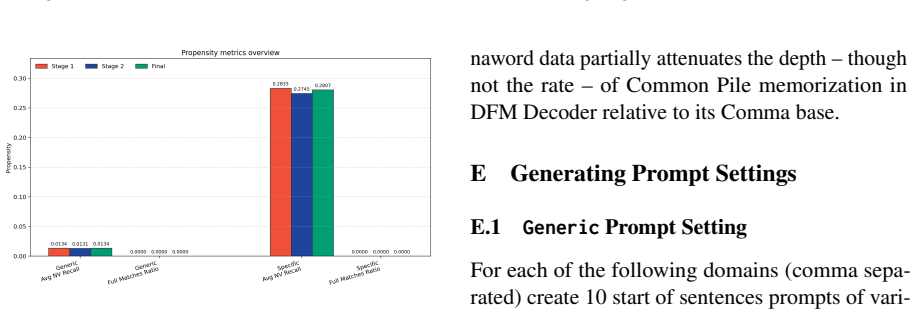
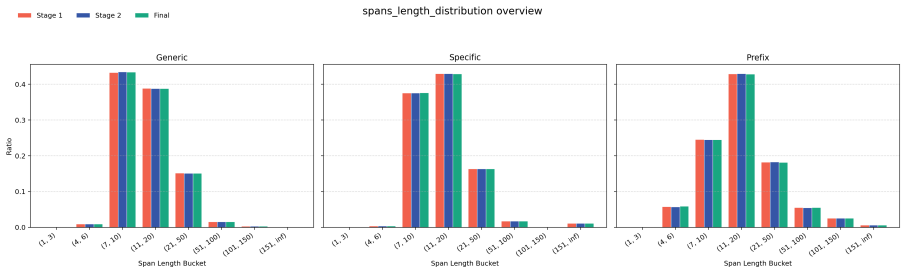
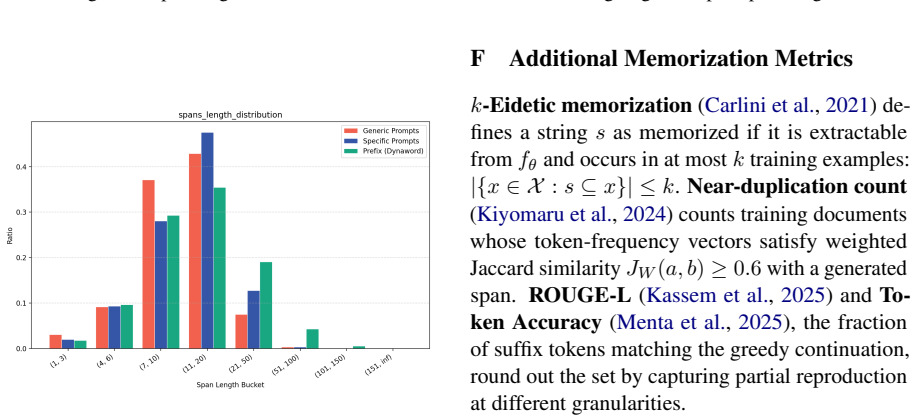

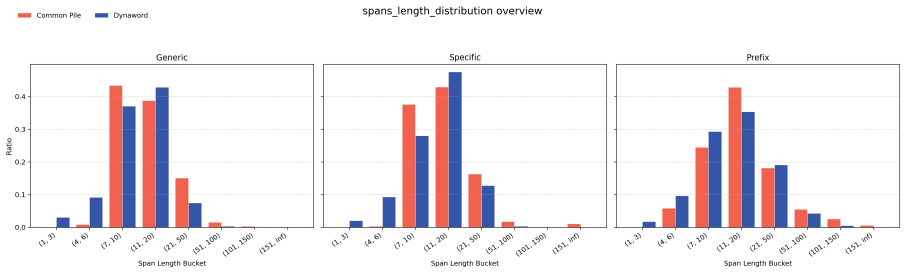
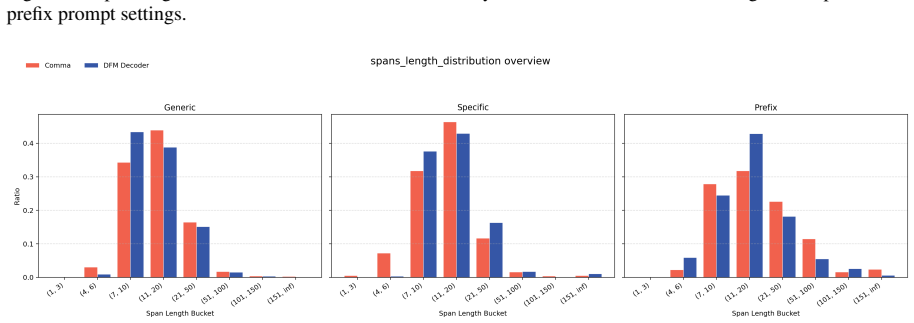
read the original abstract
Large language models can reproduce training data, but existing memorization evaluations mostly measure whether models can be forced to do so, rather than whether they do so under ordinary use. We introduce PropMe, a propensity-aware framework for memorization evaluation that contrasts prefix-based capability attacks with non-adversarial evaluations. We propose a metric transformation that, applied to existing functions, allows to create propensity metrics. We further introduce SimpleTrace, a lightweight tracing pipeline built on infini-gram that deterministically attributes model generations to large-scale training corpora and computes verbatim, near-verbatim, and propensity-transformed memorization metrics. Evaluating two fully-open models: Comma and DFM Decoder on two datasets: Common Pile and Dynaword in two languages, we find a consistent gap between capability and propensity: prefix attacks elicit substantially stronger memorization signals than generic or dataset-specific prompts, while propensity scores remain low overall. Thus, the models can reveal training data when directly elicited, but rarely do so in more common non-adversarial settings. We also find that DFM Decoder, which is continually pre-trained from Comma, exhibits reduced memorization and memorization propensity for Common Pile, confirming that memorization capability can decrease when later training emphasizes partially different data. Our results suggest, and we encourage, that memorization audits should report both worst-case extractability and ordinary leakage propensity in order to have a more comprehensive view of this phenomenon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PropMe framework for propensity-aware memorization evaluation in LLMs, which contrasts prefix-based capability attacks with non-adversarial (generic and dataset-specific) prompts. It proposes a metric transformation applied to existing memorization functions to derive propensity scores, and presents SimpleTrace, a tracing pipeline using infini-gram for deterministic attribution of generations to training corpora. Evaluations on the fully-open Comma and DFM Decoder models across Common Pile and Dynaword datasets (in two languages) report a consistent gap: prefix attacks produce substantially stronger memorization signals while propensity scores remain low overall. The work also observes reduced memorization and propensity in DFM Decoder (continually pretrained from Comma) on Common Pile, and recommends that audits report both worst-case extractability and ordinary propensity.
Significance. If the central empirical gap holds after addressing prompt representativeness, the distinction between capability and propensity offers a practical refinement for assessing real-world leakage risks, moving beyond purely adversarial evaluations. The provision of an open tracing pipeline and results on fully-open models are concrete strengths that could support reproducible follow-up work. The observation that continual pretraining can lower memorization propensity is a falsifiable claim worth testing in other settings.
major comments (2)
- [Abstract] Abstract: The headline claim that models 'rarely' leak training data in 'more common non-adversarial settings' rests on the assumption that the chosen generic and dataset-specific prompts are representative of ordinary user interactions, yet no sampling procedure, coverage argument, or comparison against real query logs is supplied to justify this choice.
- [Evaluation] Evaluation section (implied by abstract results): Without the full specification of data exclusion rules, exact prompt templates, and statistical testing procedures for the reported gaps, it is impossible to determine whether the consistent capability-propensity separation is robust to post-hoc analysis choices or dataset construction decisions.
minor comments (1)
- [Abstract] The abstract states evaluations occur 'in two languages' but does not name the languages or break out results by language, reducing clarity on the scope of the findings.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The distinction between capability and propensity is central to our contribution, and we address the concerns about prompt representativeness and methodological transparency below.
read point-by-point responses
-
Referee: [Abstract] The headline claim that models 'rarely' leak training data in 'more common non-adversarial settings' rests on the assumption that the chosen generic and dataset-specific prompts are representative of ordinary user interactions, yet no sampling procedure, coverage argument, or comparison against real query logs is supplied to justify this choice.
Authors: We agree that the abstract phrasing implies broader representativeness than our evaluation directly supports. The generic and dataset-specific prompts were constructed as illustrative non-adversarial baselines rather than a statistically sampled distribution of user queries. We will revise the abstract to qualify the claim (e.g., 'in the non-adversarial prompt settings we study') and add a limitations paragraph discussing the absence of real query-log validation while noting that the capability-propensity gap is robust across the two prompt families we tested. revision: yes
-
Referee: [Evaluation] Without the full specification of data exclusion rules, exact prompt templates, and statistical testing procedures for the reported gaps, it is impossible to determine whether the consistent capability-propensity separation is robust to post-hoc analysis choices or dataset construction decisions.
Authors: We will expand the Evaluation section (and add an appendix) with the complete data exclusion criteria, verbatim prompt templates for both generic and dataset-specific conditions, and the exact statistical procedures (including any multiple-comparison corrections) used to assess the gaps. These details exist in our internal experimental logs but were not fully reproduced in the submitted manuscript; the revision will make the pipeline fully reproducible. revision: yes
Circularity Check
No significant circularity; derivation applies independent transformation to existing metrics.
full rationale
The paper defines PropMe as a framework that applies a proposed metric transformation to existing memorization functions in order to produce propensity metrics, then evaluates the resulting quantities on Comma and DFM Decoder using SimpleTrace on Common Pile and Dynaword. No equation or definition reduces the propensity scores to quantities fitted from the same evaluation data by construction, nor does any central claim rest on a self-citation chain, imported uniqueness theorem, or renamed known result. The gap between capability (prefix attacks) and propensity (generic/dataset-specific prompts) is an empirical comparison whose validity depends on prompt representativeness rather than on any definitional or fitting circularity. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2012.07805 , year=
Extracting Training Data from Large Language Models , author=. arXiv preprint arXiv:2012.07805 , year=
arXiv 2012
-
[2]
Proceedings of the 40th International Conference on Machine Learning (ICML) , year=
Quantifying Memorization Across Neural Language Models , author=. Proceedings of the 40th International Conference on Machine Learning (ICML) , year=
-
[3]
International Conference on Learning Representations (ICLR) , year=
Detecting Pretraining Data from Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[4]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2024
-
[5]
Proceedings of the 17th International Natural Language Generation Conference (INLG) , year=
A Comprehensive Analysis of Memorization in Large Language Models , author=. Proceedings of the 17th International Natural Language Generation Conference (INLG) , year=
-
[6]
arXiv preprint arXiv:2504.07096 , year=
OLMOTRACE: Tracing Language Model Outputs Back to Trillions of Training Tokens , author=. arXiv preprint arXiv:2504.07096 , year=
-
[7]
arXiv preprint arXiv:2601.02671 , year=
Extracting books from production language models , author=. arXiv preprint arXiv:2601.02671 , year=
-
[8]
ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
Extracting memorized pieces of (copyrighted) books from open-weight language models , author=. ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
2025
-
[9]
arXiv preprint arXiv:2310.13771 , year=
Copyright Violations and Large Language Models , author=. arXiv preprint arXiv:2310.13771 , year=
-
[10]
International Conference on Learning Representations (ICLR) , year=
Privacy Auditing of Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[11]
Proceedings of the 39th International Conference on Machine Learning (ICML) , year=
Deduplicating Training Data Mitigates Privacy Risks in Language Models , author=. Proceedings of the 39th International Conference on Machine Learning (ICML) , year=
-
[12]
, title =
Wolfe, Cameron R. , title =. 2025 , note =
2025
-
[13]
arXiv preprint arXiv:2401.17377 , year=
Infini-gram: Scaling unbounded n-gram language models to a trillion tokens , author=. arXiv preprint arXiv:2401.17377 , year=
-
[14]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Demystifying verbatim memorization in large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[15]
Alpaca against vicuna: Using llms to uncover memorization of llms , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[16]
Sparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference , year=
Evaluating LLM Memorization Using Soft Token Sparsity , author=. Sparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference , year=
-
[17]
arXiv preprint arXiv:2407.14985 , year=
Generalization vs Memorization: Tracing Language Models' Capabilities Back to Pretraining Data , author=. arXiv preprint arXiv:2407.14985 , year=
-
[18]
Analyzing memorization in large language models through the lens of model attribution , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[19]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[20]
arXiv preprint arXiv:2508.02271 , year=
Dynaword: From One-shot to Continuously Developed Datasets , author=. arXiv preprint arXiv:2508.02271 , year=
-
[21]
2022 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks from first principles , author=. 2022 IEEE symposium on security and privacy (SP) , pages=. 2022 , organization=
2022
-
[22]
Membership Inference Attacks Against Machine Learning Models , year=
Shokri, Reza and Stronati, Marco and Song, Congzheng and Shmatikov, Vitaly , booktitle=. Membership Inference Attacks Against Machine Learning Models , year=
-
[23]
The Thirteenth International Conference on Learning Representations , year=
Scalable extraction of training data from aligned, production language models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[24]
arXiv preprint arXiv:2411.10242 , year=
Measuring non-adversarial reproduction of training data in large language models , author=. arXiv preprint arXiv:2411.10242 , year=
-
[25]
Proceedings of the 16th International Natural Language Generation Conference , pages=
Preventing generation of verbatim memorization in language models gives a false sense of privacy , author=. Proceedings of the 16th International Natural Language Generation Conference , pages=
-
[26]
1: An 8tb dataset of public domain and openly licensed text , author=
The common pile v0. 1: An 8tb dataset of public domain and openly licensed text , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
2026 , month = apr, day =
2026
-
[28]
arXiv preprint arXiv:2602.18182 , year =
Capabilities Ain't All You Need: Measuring Propensities in AI , author =. arXiv preprint arXiv:2602.18182 , year =. doi:10.48550/arXiv.2602.18182 , archivePrefix =. 2602.18182 , primaryClass =
-
[29]
arXiv preprint arXiv:2603.00063 , year =
Measuring What AI Systems Might Do: Towards A Measurement Science in AI , author =. arXiv preprint arXiv:2603.00063 , year =. doi:10.48550/arXiv.2603.00063 , archivePrefix =. 2603.00063 , primaryClass =
-
[30]
arXiv preprint arXiv:2305.15324 , year =
Model Evaluation for Extreme Risks , author =. arXiv preprint arXiv:2305.15324 , year =. doi:10.48550/arXiv.2305.15324 , archivePrefix =. 2305.15324 , primaryClass =
-
[31]
Advances in Neural Information Processing Systems 37 , year =
Stress-Testing Capability Elicitation With Password-Locked Models , author =. Advances in Neural Information Processing Systems 37 , year =
-
[32]
Proceedings of the 42nd International Conference on Machine Learning , year =
The Elicitation Game: Evaluating Capability Elicitation Techniques , author =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[33]
arXiv preprint arXiv:2406.07358 , year =
AI Sandbagging: Language Models can Strategically Underperform on Evaluations , author =. arXiv preprint arXiv:2406.07358 , year =. doi:10.48550/arXiv.2406.07358 , archivePrefix =. 2406.07358 , primaryClass =
-
[34]
arXiv preprint arXiv:2505.23836 , year =
Large Language Models Often Know When They Are Being Evaluated , author =. arXiv preprint arXiv:2505.23836 , year =. doi:10.48550/arXiv.2505.23836 , archivePrefix =. 2505.23836 , primaryClass =
-
[35]
Frontier Models are Capable of In-context Scheming
Frontier Models are Capable of In-context Scheming , author =. arXiv preprint arXiv:2412.04984 , year =. doi:10.48550/arXiv.2412.04984 , archivePrefix =. 2412.04984 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.04984
-
[36]
arXiv preprint arXiv:2603.01608 , year =
Evaluating and Understanding Scheming Propensity in LLM Agents , author =. arXiv preprint arXiv:2603.01608 , year =. doi:10.48550/arXiv.2603.01608 , archivePrefix =. 2603.01608 , primaryClass =
-
[37]
AgentMisalignment: Measuring the Propensity for Misaligned Behaviour in LLM-Based Agents
AgentMisalignment: Measuring the Propensity for Misaligned Behaviour in LLM-Based Agents , author =. arXiv preprint arXiv:2506.04018 , year =. doi:10.48550/arXiv.2506.04018 , archivePrefix =. 2506.04018 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.04018
-
[38]
Propensity Inference: Environmental Contributors to LLM Behaviour
Propensity Inference: Environmental Contributors to LLM Behaviour , author =. arXiv preprint arXiv:2604.21098 , year =. doi:10.48550/arXiv.2604.21098 , archivePrefix =. 2604.21098 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.21098
-
[39]
2016 , date =
Official Journal of the European Union , number =. 2016 , date =
2016
-
[40]
2024 , date =
Official Journal of the European Union , number =. 2024 , date =
2024
-
[41]
2019 , date =
Official Journal of the European Union , number =. 2019 , date =
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.