Tangram: Unlocking Non-Uniform KV Cache for Efficient Multi-turn LLM Serving
Pith reviewed 2026-06-28 02:21 UTC · model grok-4.3
The pith
Tangram enables non-uniform KV cache in multi-turn LLM serving by pre-assigning fixed memory budgets to each attention head.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
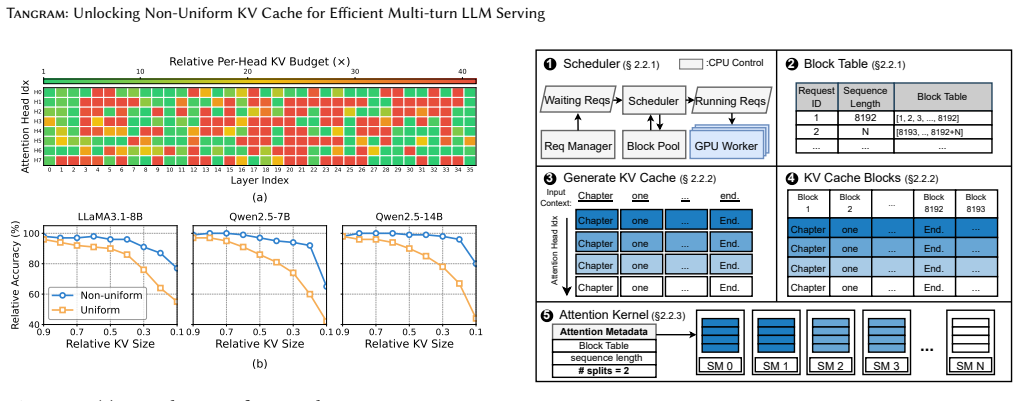
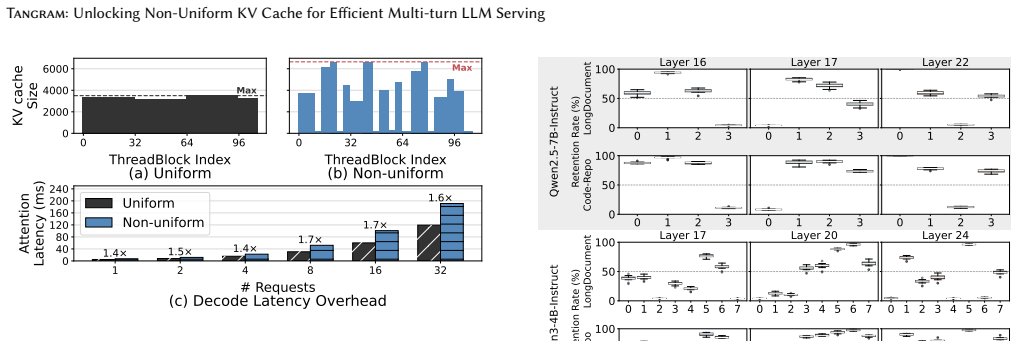
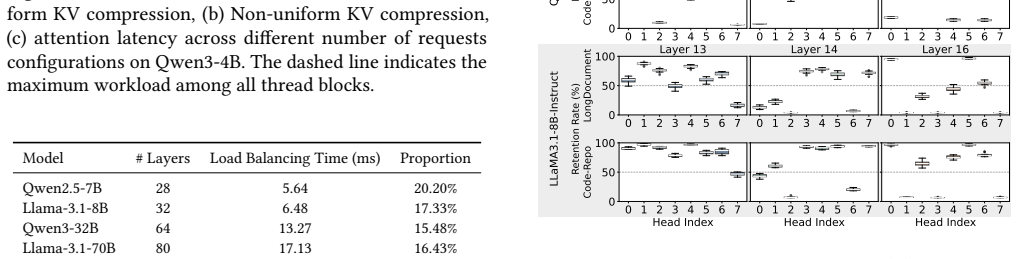
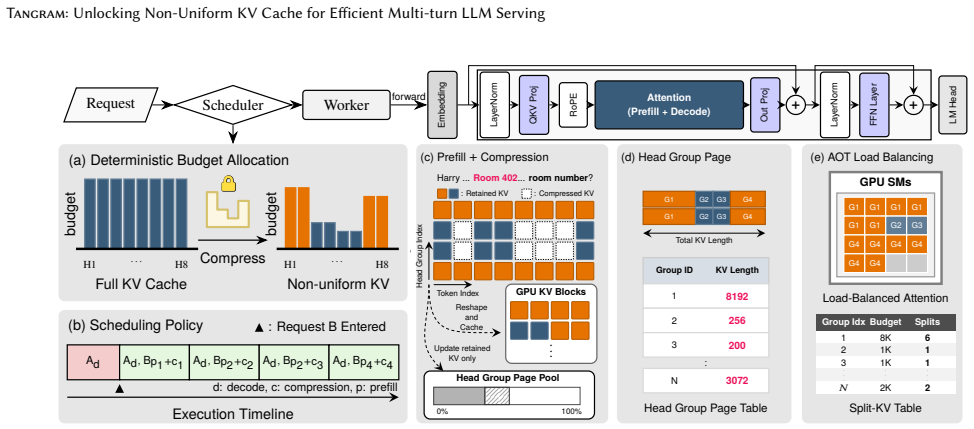
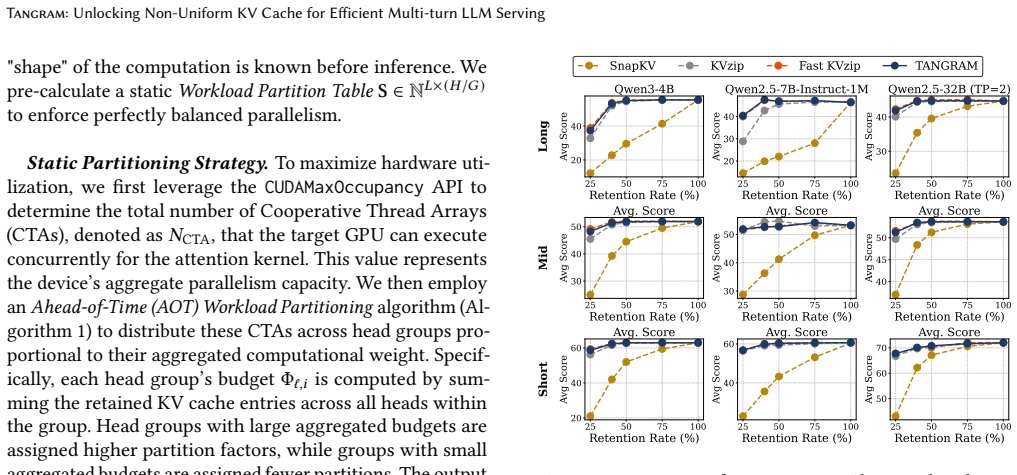
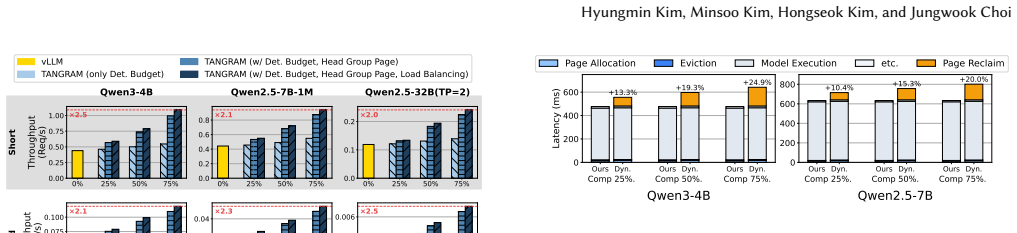
Tangram overcomes the systemic challenges of non-uniform KV cache—memory fragmentation, scheduling complexities, and diminished kernel utilization—by assigning a static memory footprint to each attention head based on its intrinsic retention pattern, clustering heads with similar demands under independent page tables, and using ahead-of-time load balancing from static profiles, thereby delivering up to 2.6x throughput gains with no accuracy loss.
What carries the argument
Deterministic budget allocation that fixes a static memory footprint per attention head according to its intrinsic retention pattern, removing all dynamic scheduling.
If this is right
- LLM serving systems can support more simultaneous users or longer contexts on existing GPUs without accuracy trade-offs.
- Physical memory reclamation improves because page tables operate independently on head groups with similar needs.
- Prefill stages avoid stalls since no runtime budget decisions occur.
- GPU kernels maintain high utilization because load balancing is precomputed from static profiles.
Where Pith is reading between the lines
- If head patterns prove stable across model families, the same static profiles could be reused when swapping base models.
- Future accelerators might add native support for grouped page tables to reduce the software overhead Tangram currently handles.
- In production traces with highly variable conversation lengths, periodic offline re-profiling of budgets could extend the method without introducing runtime cost.
Load-bearing premise
The retention demands of attention heads follow stable intrinsic patterns that can be reliably determined in advance and stay consistent during serving.
What would settle it
Measure throughput and accuracy on a workload where attention-head retention patterns shift markedly between prompts or within long conversations; if gains fall below baseline or accuracy drops, the static-pattern premise fails.
Figures


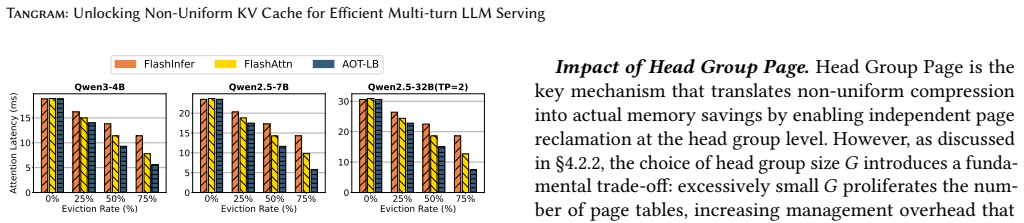
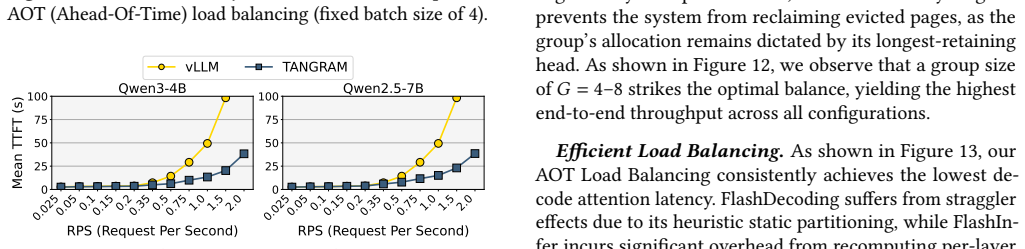
read the original abstract
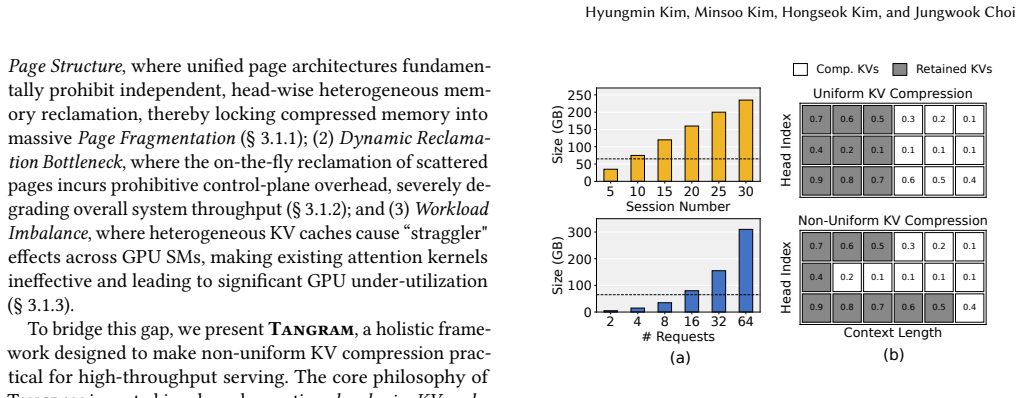
Multi-turn Large Language Model (LLM) serving is critical for consistent user experiences, yet the linear growth of the Key-Value (KV) cache imposes significant pressure on GPU memory and bandwidth. Non-uniform KV compression effectively preserves more information by considering the individual importance of each KV cache. However, such KV cache heterogeneity introduces various systemic challenges - including memory fragmentation, scheduling complexities, and diminished kernel utilization - which collectively lead to significant inefficiencies in existing LLM serving systems. To overcome these challenges, we present Tangram, a novel serving system designed to make Non-uniform KV caches practical. Tangram addresses systemic inefficiencies through three core techniques: (1) Deterministic Budget Allocation assigns a static memory footprint to each head based on its intrinsic pattern, entirely eliminating dynamic scheduling overhead and prefill stalls; (2) Head Group Page clusters attention heads with similar retention demands and manages them with independent, vectorized page tables, thereby maximizing physical memory reclamation; and (3) Ahead-of-Time (AOT) Load Balancing leverages static budget profiles to ensure uniform GPU utilization without runtime overhead. Experimental results show that Tangram improves throughput by up to 2.6x compared to existing baselines, while fully preserving model accuracy. Our implementation is publicly available at https://github.com/aiha-lab/TANGRAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Tangram, a serving system for multi-turn LLMs that makes non-uniform KV cache practical by addressing memory fragmentation, scheduling, and kernel utilization issues. It proposes three techniques: (1) Deterministic Budget Allocation that statically assigns per-head memory based on an intrinsic retention pattern, (2) Head Group Page that clusters similar heads and uses independent vectorized page tables for reclamation, and (3) Ahead-of-Time Load Balancing that uses static profiles for uniform GPU utilization. The work reports up to 2.6x throughput gains over baselines while fully preserving model accuracy, with public code at https://github.com/aiha-lab/TANGRAM.
Significance. If the static retention patterns prove stable, the work could meaningfully advance practical LLM serving efficiency by enabling non-uniform compression without the usual overheads. The open-source release is a clear strength that supports reproducibility and allows direct verification of the engineering claims.
major comments (2)
- [Abstract] Abstract: The central claims of 2.6x throughput improvement and fully preserved accuracy rest on Deterministic Budget Allocation using fixed per-head budgets derived from a one-time 'intrinsic pattern.' No quantification of pattern variance across conversation turns, input domains, or context shifts is provided; if patterns are not invariant, fixed budgets risk either accuracy degradation or lost reclamation opportunities, directly undermining both performance and accuracy assertions.
- [Abstract] The three techniques (Deterministic Budget Allocation, Head Group Page, AOT Load Balancing) all inherit the static-profile premise. Experiments must demonstrate that retention demands remain sufficiently stable in multi-turn workloads for the 'no accuracy loss' result to generalize; absent such evidence, the load-bearing assumption remains untested.
minor comments (1)
- The abstract lacks any description of experimental methodology, specific baselines, model sizes, or statistical significance testing for the throughput numbers; adding these details would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the stability of retention patterns underlying Tangram's static allocation. We address the major comments point by point below and will revise the manuscript accordingly to provide the requested evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 2.6x throughput improvement and fully preserved accuracy rest on Deterministic Budget Allocation using fixed per-head budgets derived from a one-time 'intrinsic pattern.' No quantification of pattern variance across conversation turns, input domains, or context shifts is provided; if patterns are not invariant, fixed budgets risk either accuracy degradation or lost reclamation opportunities, directly undermining both performance and accuracy assertions.
Authors: We agree that the manuscript would be strengthened by explicit quantification of retention-pattern variance. The intrinsic pattern is obtained via one-time profiling on representative data and is treated as model-intrinsic; our multi-turn experiments already show accuracy preservation across the tested workloads. We will add a dedicated analysis subsection (with standard-deviation metrics, domain-specific breakdowns, and sensitivity plots) that quantifies variance across turns, input domains, and context shifts. revision: yes
-
Referee: [Abstract] The three techniques (Deterministic Budget Allocation, Head Group Page, AOT Load Balancing) all inherit the static-profile premise. Experiments must demonstrate that retention demands remain sufficiently stable in multi-turn workloads for the 'no accuracy loss' result to generalize; absent such evidence, the load-bearing assumption remains untested.
Authors: We concur that explicit stability evidence is needed to support generalizability of the static-profile premise across all three techniques. While the current evaluation covers diverse multi-turn benchmarks with no accuracy loss, we will expand the experimental section to include additional multi-turn traces, measure retention-score consistency over successive turns, and report stability statistics that directly validate the static budgets used by Deterministic Budget Allocation, Head Group Page, and AOT Load Balancing. revision: yes
Circularity Check
No circularity in Tangram engineering techniques
full rationale
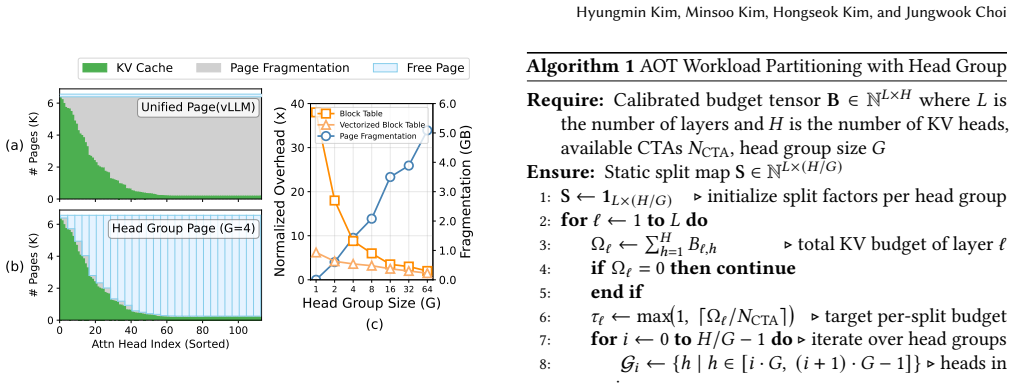
The paper presents three practical system techniques for non-uniform KV cache: static per-head budget allocation from observed intrinsic patterns, head-group paging, and AOT load balancing. These are engineering choices grounded in empirical profiling and system constraints, with throughput gains shown via experiments. No derivation chain reduces a claimed prediction or result to its own inputs by construction, no self-citations are load-bearing for core claims, and no fitted parameters are relabeled as independent predictions. The stability assumption on retention patterns is an explicit premise, not a circular step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention heads exhibit stable, intrinsic retention patterns suitable for static budget allocation.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al . 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774(2023)
Pith/arXiv arXiv 2023
-
[2]
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ramachandran Ramjee. 2023. Sarathi: Effi- cient llm inference by piggybacking decodes with chunked prefills. arXiv preprint arXiv:2308.16369(2023)
Pith/arXiv arXiv 2023
-
[3]
Anthropic. 2024. Using Claude’s Chat, Search, and Memory to Build on Previous Context.https://support.claude.com/en/articles/11817273
arXiv 2024
-
[4]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413(2025)
Pith/arXiv arXiv 2025
-
[5]
Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691(2023)
Pith/arXiv arXiv 2023
-
[6]
Tri Dao, Daniel Haziza, Francisco Massa, and Grigory Sizov. 2023. Flash-Decoding for long-context inference.https://crfm.stanford.edu/ 2023/10/12/flashdecoding.html
2023
-
[7]
Alessio Devoto, Maximilian Jeblick, Simon Jégou, et al. 2025. KVPress Leaderboard: Benchmarking KV Cache Compression for LLMs.https: //huggingface.co/spaces/nvidia/kvpress-leaderboard
2025
-
[8]
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirs- bilck, Min-Hung Chen, Yoshi Suhara, et al . 2024. Hymba: A hybrid-head architecture for small language models.arXiv preprint arXiv:2411.13676(2024)
arXiv 2024
-
[9]
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. 2024. Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference.arXiv preprint arXiv:2407.11550(2024)
Pith/arXiv arXiv 2024
-
[10]
Yu Fu, Zefan Cai, Abedelkadir Asi, Wayne Xiong, Yue Dong, and Wen Xiao. 2025. Not All Heads Matter: A Head-Level KV Cache Compression Method with Integrated Retrieval and Reasoning. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=FJFVmeXusW
2025
-
[11]
Nair, and Poulami Das
Ravi Ghadia, Avinash Kumar, Gaurav Jain, Prashant J. Nair, and Poulami Das. 2025. Dialogue Without Limits: Constant-Sized KV Caches for Extended Response in LLMs. InForty-second International Conference on Machine Learning.https://openreview.net/forum?id= SuYO70ZxZX
2025
-
[12]
Abhiram Rao Gorle, Amit Kumar Singh Yadav, and Tsachy Weiss- man. 2025. Quantifying Information Gain and Redundancy in Multi- Turn LLM Conversations. InFirst Workshop on Multi-Turn Interac- tions in Large Language Models.https://openreview.net/forum?id= 5gpABTkcUJ
2025
-
[13]
Yuanzhe Hu, Yu Wang, and Julian McAuley. 2026. Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions. InThe Four- teenth International Conference on Learning Representations.https: //openreview.net/forum?id=DT7JyQC3MR
2026
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
Pith/arXiv arXiv 2023
-
[15]
Jang-Hyun Kim, Dongyoon Han, and Sangdoo Yun. 2026. Fast KVzip: Efficient and Accurate LLM Inference with Gated KV Eviction.arXiv preprint arXiv:2601.17668(2026)
arXiv 2026
-
[16]
Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W Lee, Sangdoo Yun, and Hyun Oh Song. 2025. KVzip: Query-Agnostic KV Cache Compres- sion with Context Reconstruction.Advances in Neural Information Processing Systems(2025)
2025
-
[17]
Minsoo Kim, Arnav Kundu, Han-Byul Kim, Richa Dixit, and Minsik Cho. 2025. EpiCache: Episodic KV Cache Management for Long Conversational Question Answering. arXiv:2509.17396 [cs.CL]https: //arxiv.org/abs/2509.17396
Pith/arXiv arXiv 2025
-
[18]
Minsoo Kim, Kyuhong Shim, Jungwook Choi, and Simyung Chang
-
[19]
InfiniPot: Infinite Context Processing on Memory-Constrained LLMs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun- Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 16046–16060. doi:10.18653/v1/2024.emnlp-main.897
-
[20]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[21]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[22]
Dong-Ho Lee, Adyasha Maharana, Jay Pujara, Xiang Ren, and Francesco Barbieri. 2025. Realtalk: A 21-day real-world dataset for long-term conversation.arXiv preprint arXiv:2502.13270(2025)
arXiv 2025
-
[23]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 155–172
2024
-
[24]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen
-
[25]
SnapKV: LLM Knows What You are Looking for Before Gener- ation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum?id=poE54GOq2l 12 Tangram: Unlocking Non-Uniform KV Cache for Efficient Multi-turn LLM Serving
-
[26]
Yucheng Li, Huiqiang Jiang, Qianhui Wu, Xufang Luo, Surin Ahn, Chengruidong Zhang, Amir H Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang, et al . 2024. Scbench: A kv cache-centric analysis of long-context methods.arXiv preprint arXiv:2412.10319(2024)
arXiv 2024
-
[27]
Yubo Li, Xiaobin Shen, Xinyu Yao, Xueying Ding, Yidi Miao, Ra- mayya Krishnan, and Rema Padman. 2025. Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models. arXiv:2504.04717 [cs.CL]https://arxiv.org/abs/2504.04717
Pith/arXiv arXiv 2025
-
[28]
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al . 2024. Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887(2024)
Pith/arXiv arXiv 2024
-
[29]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Com...
-
[30]
OpenAI. 2024. Memory and New Controls for ChatGPT.https:// openai.com/index/memory-and-new-controls-for-chatgpt/
2024
-
[31]
Matanel Oren, Michael Hassid, Nir Yarden, Yossi Adi, and Roy Schwartz. 2024. Transformers are Multi-State RNNs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Process- ing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). As- sociation for Computational Linguistics, Miami, Florida, USA, 18724– 18741. doi:10.18653/v1...
-
[32]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[33]
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. 2023. Efficiently scaling transformer inference.Proceedings of machine learning and systems5 (2023), 606–624
2023
-
[34]
Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazari- dou, Orhan Firat, Julian Schrittwieser, et al. 2024. Gemini 1.5: Unlock- ing multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530(2024)
Pith/arXiv arXiv 2024
-
[35]
Hanlin Tang, Yang Lin, Jing Lin, Qingsen Han, Danning Ke, Shikuan Hong, Yiwu Yao, and Gongyi Wang. 2025. RazorAttention: Effi- cient KV Cache Compression Through Retrieval Heads. InThe Thir- teenth International Conference on Learning Representations.https: //openreview.net/forum?id=tkiZQlL04w
2025
-
[36]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mes- nard, Bobak Shahriari, Alexandre Ramé, et al . 2024. Gemma 2: Im- proving open language models at a practical size.arXiv preprint arXiv:2408.00118(2024)
Pith/arXiv arXiv 2024
-
[37]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2025. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InThe Thirteenth International Con- ference on Learning Representations.https://openreview.net/forum? id=pZiyCaVuti
2025
-
[38]
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. 2025. Retrieval Head Mechanistically Explains Long-Context Factuality. InThe Thirteenth International Conference on Learning Rep- resentations.https://openreview.net/forum?id=EytBpUGB1Z
2025
-
[39]
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, junxian guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. 2025. DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=cFu7ze7xUm
2025
-
[40]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. InThe Twelfth International Conference on Learning Representa- tions.https://openreview.net/forum?id=NG7sS51zVF
2024
-
[41]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. 2025. Flashinfer: Efficient and customizable atten- tion engine for llm inference serving.arXiv preprint arXiv:2501.01005 (2025)
Pith/arXiv arXiv 2025
-
[42]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 521–538
2022
-
[43]
Chen Zhang, Kuntai Du, Shu Liu, Woosuk Kwon, Xiangxi Mo, Yufeng Wang, Xiaoxuan Liu, Kaichao You, Zhuohan Li, Mingsheng Long, et al
-
[44]
InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles
JENGA: Effective memory management for serving LLM with heterogeneity. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 446–461
-
[45]
Yanqi Zhang, Yuwei Hu, Runyuan Zhao, John CS Lui, and Haibo Chen. 2025. DiffKV: Differentiated Memory Management for Large Language Models with Parallel KV Compaction. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 431– 445
2025
-
[46]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Re, Clark Barrett, Zhangyang Wang, and Beidi Chen. 2023. H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. InThirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/for...
2023
-
[47]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody_Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2023. Efficiently Programming Large Language Models using SGLang.arXiv preprint arXiv:2312.07104(2023)
Pith/arXiv arXiv 2023
-
[48]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang
-
[49]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19724–19731
-
[50]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210. 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.