Plug-and-Play Guidance for Discrete Diffusion Models via Gradient-Informed Logit Correction
Pith reviewed 2026-06-28 02:17 UTC · model grok-4.3
The pith
Gradient-informed logit correction enables training-free controllable generation in discrete diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GILC achieves state-of-the-art performance without additional training by estimating guidance signals through a Jacobian-free mechanism that directly corrects the clean prediction logits, repurposing the pretrained denoising network as a variational proxy; the method works for both differentiable and non-differentiable reward functions and frequently outperforms fine-tuning approaches on DNA, protein sequence, and molecular generation tasks.
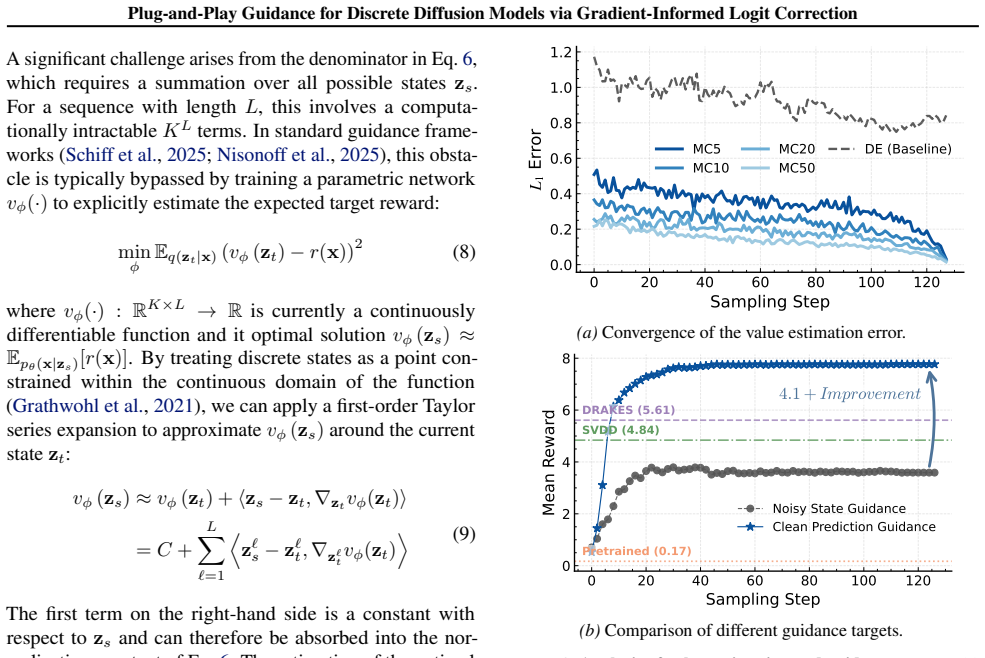
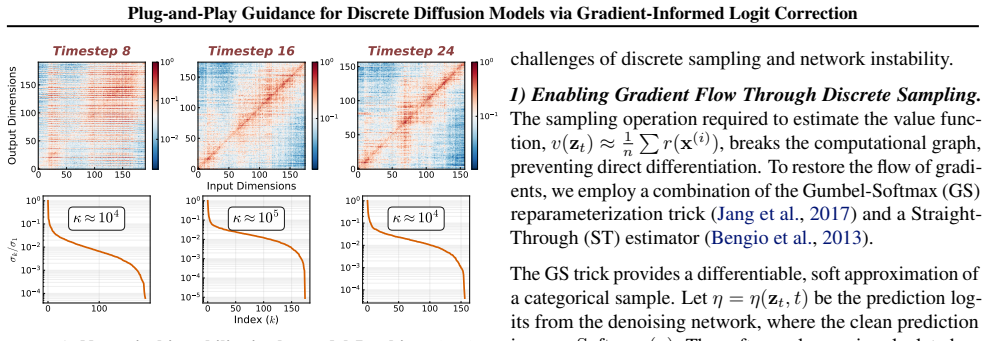
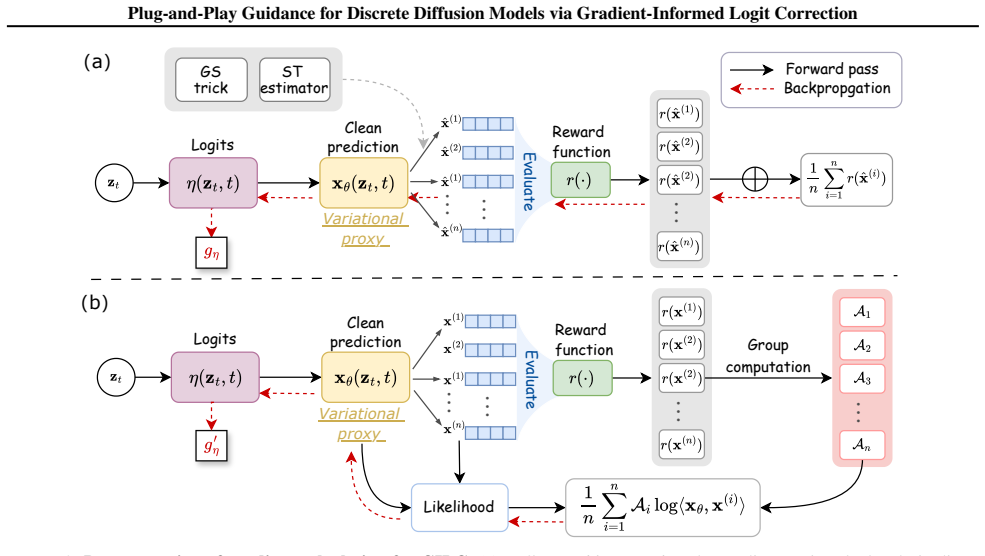
What carries the argument
Gradient-Informed Logit Correction (GILC), the Jacobian-free mechanism that directly corrects clean prediction logits using the pretrained denoising network as a variational proxy.
If this is right
- GILC accommodates both differentiable and non-differentiable reward functions for guidance.
- The approach reaches state-of-the-art results on DNA, protein sequence, and molecular generation tasks without any additional training.
- GILC frequently outperforms methods that require fine-tuning the diffusion model.
- The Jacobian-free logit correction removes the need for explicit gradient computation through the discrete space.
Where Pith is reading between the lines
- The same logit-correction idea could apply to other discrete generative settings such as text or graph generation if the pretrained network remains a reliable proxy.
- Removing the retraining step may lower the barrier to testing new reward functions on existing diffusion checkpoints.
- If the correction remains stable at larger model scales, it could enable rapid iteration on control objectives that currently require full retraining cycles.
Load-bearing premise
The pretrained denoising network can be repurposed as a variational proxy to estimate stable guidance signals via Jacobian-free logit correction in high-dimensional discrete spaces.
What would settle it
Experiments in which GILC produces guidance signals that yield lower performance than fine-tuned baselines on protein sequence generation tasks, or that exhibit gradient instability, would falsify the central claim.
Figures



read the original abstract
Controllable generation with discrete diffusion models is often hindered by high computational overhead or the need for retraining. In this paper, we present \underline{\textbf{G}}radient-\underline{\textbf{I}}nformed \underline{\textbf{L}}ogit \underline{\textbf{C}}orrection (\textbf{GILC}), a plug-and-play framework that efficiently estimates guidance signals by repurposing the pretrained denoising network as a variational proxy. To circumvent the gradient instability inherent in high-dimensional discrete spaces, we introduce a Jacobian-free mechanism that directly corrects the clean prediction logits, facilitating stable and effective guidance. Our method accommodates both differentiable and non-differentiable reward functions. Extensive experiments across DNA, protein sequence, and molecular generation tasks demonstrate that GILC achieves state-of-the-art performance without additional training, frequently outperforming fine-tuning approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gradient-Informed Logit Correction (GILC), a plug-and-play framework for controllable generation using discrete diffusion models. It repurposes the pretrained denoising network as a variational proxy to estimate guidance signals and introduces a Jacobian-free mechanism to correct the clean prediction logits, enabling stable guidance for both differentiable and non-differentiable rewards. The method is evaluated on DNA, protein sequence, and molecular generation tasks, where it is claimed to achieve state-of-the-art performance without additional training, often outperforming fine-tuning approaches.
Significance. This contribution could be significant for practical applications of discrete diffusion models in biology and chemistry, where controllable generation is important but retraining is costly. The plug-and-play aspect and handling of non-differentiable rewards are strengths. The Jacobian-free approach addresses a practical issue in discrete spaces. Credit is given for the coherent construction of the method.
minor comments (2)
- [Abstract] The abstract would benefit from including one or two key quantitative results or specific baselines to substantiate the SOTA claim.
- Check for consistency in the use of mathematical notation throughout the paper, particularly for the logit correction term.
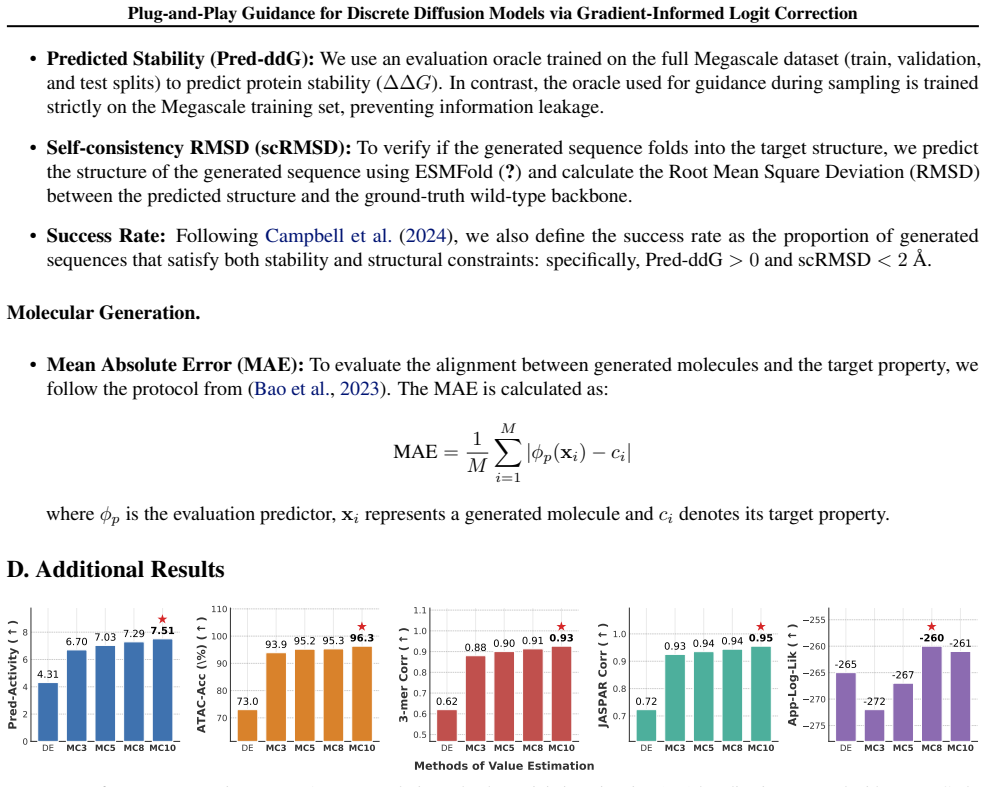
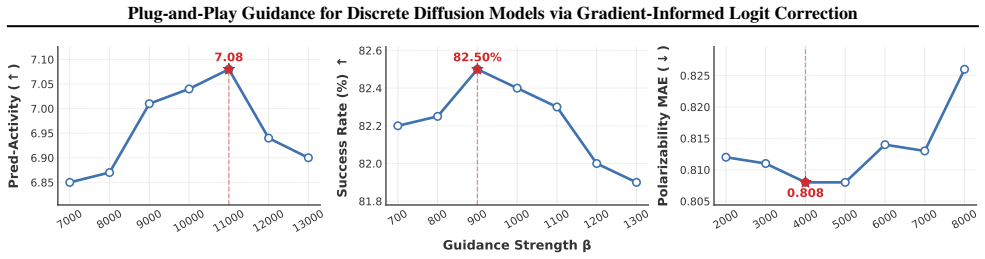
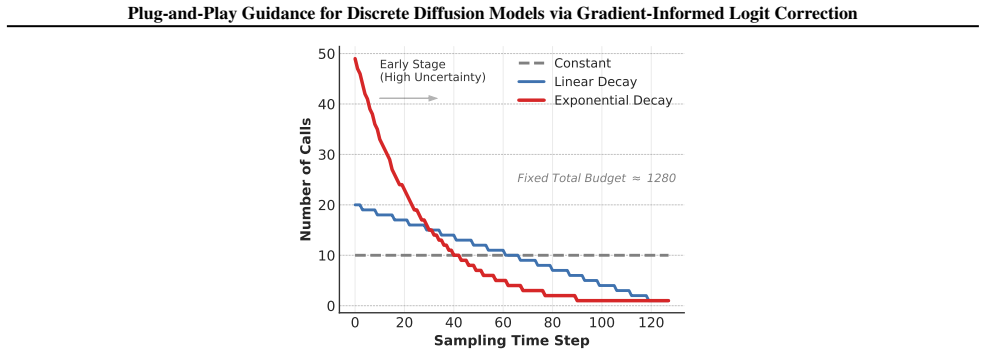
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical strengths of GILC (plug-and-play nature, handling of non-differentiable rewards, and Jacobian-free correction), and the recommendation for minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents GILC as a plug-and-play method that repurposes a pretrained denoising network as a variational proxy and applies Jacobian-free logit correction for guidance in discrete diffusion models. No equations, self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided abstract or method summary. The construction for handling differentiable and non-differentiable rewards is described directly without reducing to prior author results by definition. Experimental claims of SOTA performance rest on external validation across standard tasks rather than internal equivalence to inputs, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y ., L´eonard, N., and Courville, A. Estimating or propagating gradients through stochastic neurons for con- ditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training diffusion models with reinforcement learning
Black, K., Janner, M., Du, Y ., Kostrikov, I., and Levine, S. Training diffusion models with reinforcement learning. In International Conference on Learning Representations, volume 2024, pp. 4965–4987,
2024
-
[3]
T., Klasky, M
Chung, H., Kim, J., McCann, M. T., Klasky, M. L., and Ye, J. C. Diffusion posterior sampling for general noisy inverse problems. In11th International Conference on Learning Representations, ICLR 2023,
2023
-
[4]
Directly fine-tuning diffusion models on differentiable rewards
Clark, K., Vicol, P., Swersky, K., and Fleet, D. Directly fine-tuning diffusion models on differentiable rewards. In International Conference on Learning Representations, volume 2024, pp. 4793–4822,
2024
-
[5]
Manifold preserving guided diffusion
He, Y ., Murata, N., Lai, C.-H., Takida, Y ., Uesaka, T., Kim, D., Liao, W., Mitsufuji, Y ., Kolter, Z., Salakhutdinov, R., et al. Manifold preserving guided diffusion. InInterna- tional Conference on Learning Representations, volume 2024, pp. 44819–44850,
2024
-
[6]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
2000
-
[8]
Morgan Kaufmann. Li, X., Zhao, Y ., Wang, C., Scalia, G., Eraslan, G., Nair, S., Biancalani, T., Ji, S., Regev, A., Levine, S., et al. Derivative-free guidance in continuous and discrete dif- fusion models with soft value-based decoding.arXiv preprint arXiv:2408.08252,
-
[9]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Liu, Y ., Zhang, K., Li, Y ., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y ., Sun, H., Gao, J., et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y ., Wen, J.-R., and Li, C. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Unlocking guidance for discrete state-space diffusion and flow models
Nisonoff, H., Xiong, J., Allenspach, S., and Listgarten, J. Unlocking guidance for discrete state-space diffusion and flow models. InInternational Conference on Learning Representations, volume 2025, pp. 36052–36106,
2025
-
[12]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Peng, X. B., Kumar, A., Zhang, G., and Levine, S. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[13]
Prabhudesai, M., Goyal, A., Pathak, D., and Fragkiadaki, K. Aligning text-to-image diffusion models with re- ward backpropagation.arXiv preprint arXiv:2310.03739,
-
[14]
Steering masked discrete diffusion models via discrete denoising posterior prediction
Rector-Brooks, J., Hasan, M., Peng, Z., Liu, C., Mittal, S., Dziri, N., Bronstein, M., Chatterjee, P., Tong, A., and Bose, J. Steering masked discrete diffusion models via discrete denoising posterior prediction. InInternational Conference on Learning Representations, volume 2025, pp. 25383–25414,
2025
-
[15]
Simple guidance mechanisms for discrete diffusion models
Schiff, Y ., Sahoo, S., Phung, H., Wang, G., Boshar, S., Dalla-Torre, H., Almeida, B., Rush, A., Pierrot, T., and Kuleshov, V . Simple guidance mechanisms for discrete diffusion models. InInternational Conference on Learn- ing Representations, volume 2025, pp. 43776–43821,
2025
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Uehara, M., Zhao, Y ., Biancalani, T., and Levine, S. Un- derstanding reinforcement learning-based fine-tuning of diffusion models: A tutorial and review.arXiv preprint arXiv:2407.13734,
-
[18]
Fine-tuning discrete diffusion models via reward opti- mization with applications to dna and protein design
Wang, C., Uehara, M., He, Y ., Wang, A., Lal, A., Jaakkola, T., Levine, S., Regev, A., Wang, H., and Biancalani, T. Fine-tuning discrete diffusion models via reward opti- mization with applications to dna and protein design. In International Conference on Learning Representations, volume 2025, pp. 47871–47899,
2025
-
[19]
Aligning protein generative models with experimental fitness via direct preference optimization.bioRxiv, pp
Widatalla, T., Rafailov, R., and Hie, B. Aligning protein generative models with experimental fitness via direct preference optimization.bioRxiv, pp. 2024–05,
2024
-
[20]
Variational Autoencoding Discrete Diffusion with Enhanced Dimensional Correlations Modeling
Xie, T., Xue, S., Feng, Z., Hu, T., Sun, J., Li, Z., and Zhang, C. Variational autoencoding discrete diffusion with enhanced dimensional correlations modeling.arXiv preprint arXiv:2505.17384,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
13 Plug-and-Play Guidance for Discrete Diffusion Models via Gradient-Informed Logit Correction A. Related Works We review the landscape of diffusion models for constrained generation, focusing on the evolution from standard guidance to recent developments in diffusion with discrete state spaces. Classifier and Classifier-free Guidance.Classifier Guidance ...
2021
-
[22]
have extended these paradigms to discrete diffusion and flow models. However, both face significant practical hurdles: CG necessitates training a dedicated noise-aware classifier, which precludes the use of pre-trained models optimized solely for clean data. Conversely, CFG requires paired datasets for joint training, a requirement that limits flexibility...
2023
-
[23]
and SVDD (Li et al., 2024), rely on particle filtering or candidate selection. However, these methods are inherently limited to the explored candidate space; as the sequence length expands, the number of particles required grows rapidly, leading to prohibitive sampling times. Furthermore, while TFG-low (Lin et al.,
2024
-
[24]
Recently, Ou et al
show promise but are currently restricted to discrete diffusion with uniform transition matrices. Recently, Ou et al. (2026) suggests improving SMC by using reward gradient guidance as a better proposal distribution. In contrast, we directly derive our value function estimate from the variational objective and directly apply guidance to logits, which we f...
2026
-
[25]
have been used to fine-tune continuous models, extensions to discrete states (Venkatraman et al., 2024; Rector-Brooks et al., 2025; Zekri & Boull´e, 2026; Wang et al.,
2024
-
[26]
Unlike these approaches, our method adopts aplug-and-playfashion
are still gaining traction. Unlike these approaches, our method adopts aplug-and-playfashion. By utilizing reward functions without parameter updates, we avoid the heavy computational overhead of fine-tuning and mitigate the common pitfall of reward hacking. Tab. 5 shows a comparison between our proposed GILC framework and representative methods. Table 5....
2025
-
[27]
9:end for 10:Output:Generated samplex←z 0 Algorithm 2Correction-DB(Direct Backpropagation Estimator) 1:Input:Logitsη, reward functionr(·), sample sizen 2:Sample soft samplesx (1) soft,· · ·,x (n) soft ∼Gumbel-Softmax(η); 3:Compute straight-through samples ˆx(i) ←onehot arg maxx (i) soft −sg x(i) soft +x (i) soft, i= 1, . . . , n; 4:Evaluate rewardsR i ←r(...
2025
-
[28]
SMC is a general-purpose sampling framework that maintains a population of particles and applies filtering operations during generation to approximate the target distribution
Sequential Monte Carlo (SMC)(Wu et al., 2023). SMC is a general-purpose sampling framework that maintains a population of particles and applies filtering operations during generation to approximate the target distribution. While SMC is theoretically exact in the limit of infinitely many particles, practical implementations necessarily operate with a finit...
2023
-
[29]
SVDD is a derivative-free guidance method for diffusion models
SVDD(Li et al., 2024). SVDD is a derivative-free guidance method for diffusion models. At each diffusion time step, it samples multiple candidate states from the transition kernel, estimates the future value of each candidate using a deterministic 17 Plug-and-Play Guidance for Discrete Diffusion Models via Gradient-Informed Logit Correction evaluator, and...
2024
-
[30]
TFG-Flow was originally proposed as a training-free guided multimodal flow model that jointly generates continuous and discrete components
TFG-Flow(Lin et al., 2025). TFG-Flow was originally proposed as a training-free guided multimodal flow model that jointly generates continuous and discrete components. When restricted to discrete guidance, it can also be applied as a discrete diffusion model. TFG-Flow requires estimating a guided rate matrix; in our experiments, this estimation is perform...
2025
-
[31]
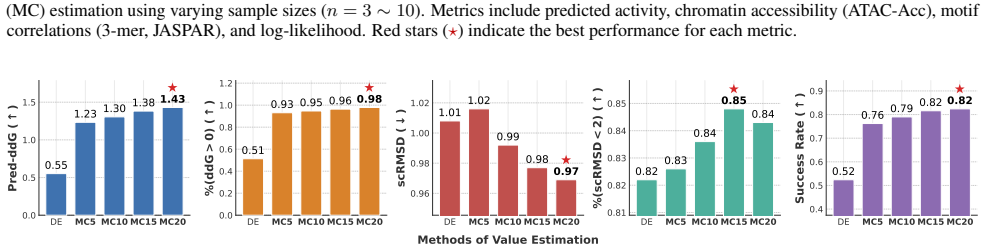
The deterministic estimation (DE) baseline is compared with Monte Carlo (MC) estimation using varying sample sizes (n= 5∼20 )
( ) 0.82 0.83 0.84 0.85 0.84 DE MC5 MC10 MC15 MC20 0.4 0.5 0.6 0.7 0.8 0.9Success Rate ( ) 0.52 0.76 0.79 0.82 0.82 Figure 6.Performance comparison on protein sequence design. The deterministic estimation (DE) baseline is compared with Monte Carlo (MC) estimation using varying sample sizes (n= 5∼20 ). Metrics evaluate stability (Pred-ddG, positive proport...
2000
-
[32]
As reported in Tab
is utilized to measure structural similarity against target molecules. As reported in Tab. 6, GILC-PG significantly outperforms all baselines, achieving the highest similarity score. Overall, these findings highlight the effectiveness and generality of the GILC framework in guiding discrete and multimodal flows toward both differentiable and non-different...
2025
-
[33]
and high-resolution text-to-image synthesis via Meissonic (Bai et al., 2024). D.3. Ablation Study We first perform a series of ablation studies to rigorously validate the effectiveness of our framework’s core components. Subsequently, we investigate the sensitivity of GILC-DB and GILC-PG to various hyperparameter configurations. Value Function Estimation....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.