DragOn: A Benchmark and Dataset for Drag-Based GUI Interactions
Pith reviewed 2026-06-28 01:35 UTC · model grok-4.3
The pith
DragOn dataset of 3.5 million tasks improves models on GUI drag interactions
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
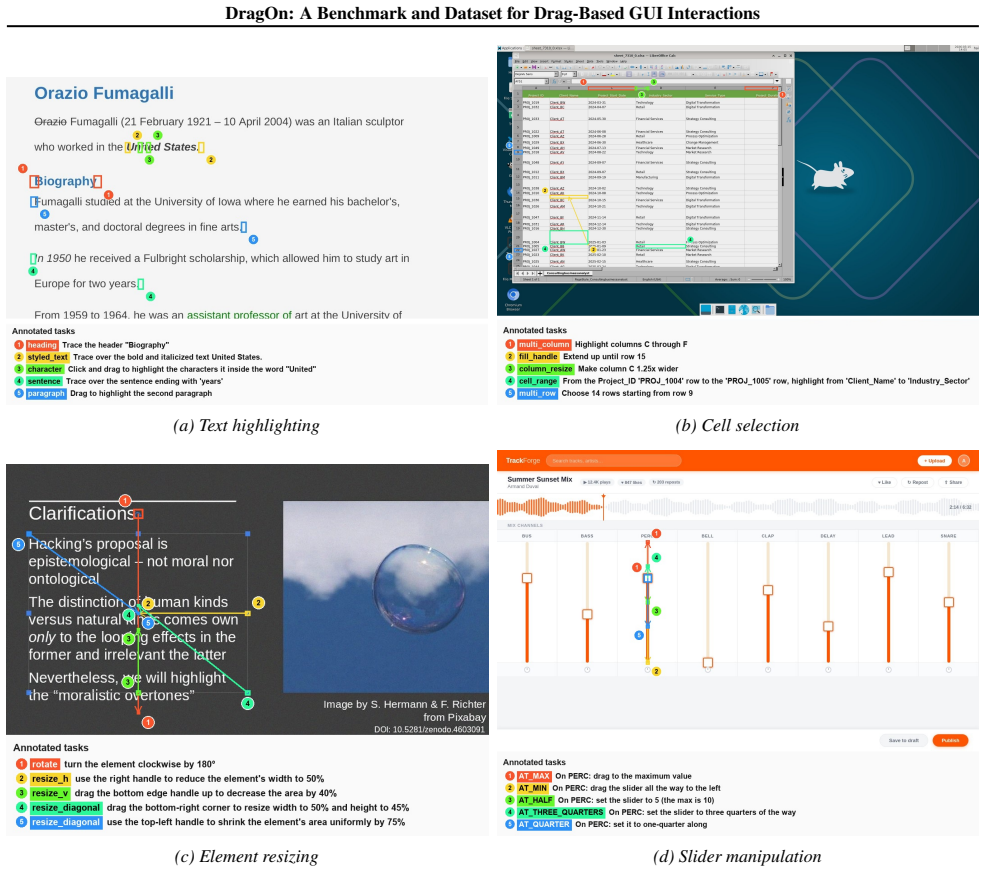
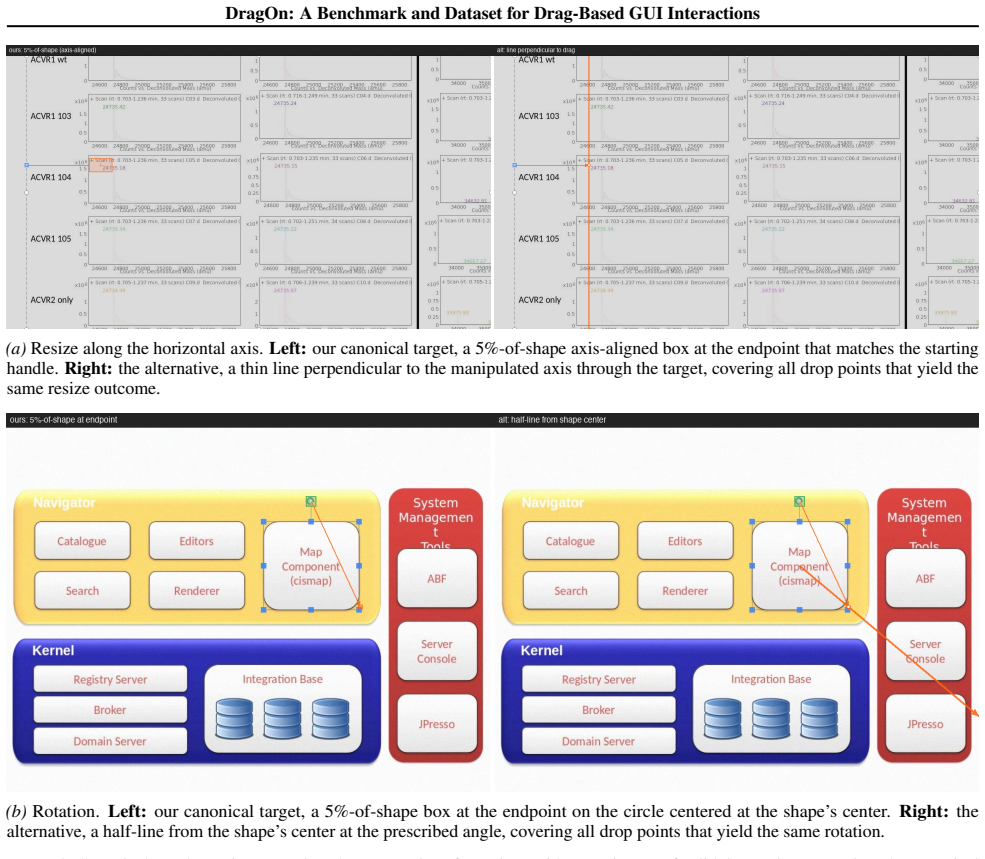
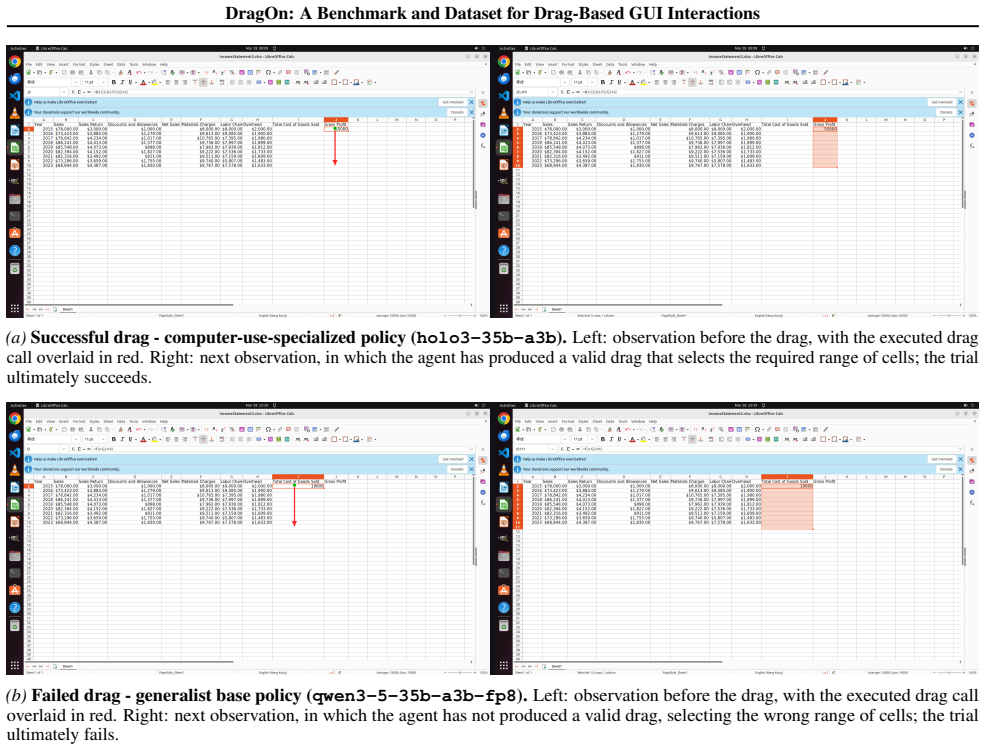
We introduce DragOn, a drag grounding benchmark and training dataset covering four domains: text highlighting, cell selection, element resizing and slider manipulation. The dataset comprises 286K training screenshots and 3.5M training tasks, plus a 2000-example held-out evaluation suite. Results suggest that our dataset could improve performance of state-of-the-art models on downstream computer-use tasks.
What carries the argument
The DragOn dataset for training and evaluating drag grounding in vision-based GUI agents across four domains.
If this is right
- Fine-tuned models achieve better results on drag tasks than base models.
- The dataset helps close the gap between click and drag data availability for GUI agents.
- Evaluations highlight limitations in current proprietary and open models for complex drags.
- Potential for better automation of tasks requiring dragging actions on desktops and mobile.
Where Pith is reading between the lines
- This dataset could be combined with existing click datasets to create more comprehensive GUI training.
- Improved drag handling may enable agents to perform tasks like file management or design work more effectively.
- Future work might test generalization to new domains like games or specialized software interfaces.
Load-bearing premise
The 2000-example held-out evaluation suite is representative of real-world drag interactions and that fine-tuning on the training data generalizes beyond the specific domains tested.
What would settle it
Evaluating the fine-tuned model on drag tasks from applications outside the four covered domains and finding no improvement over the base model.
Figures



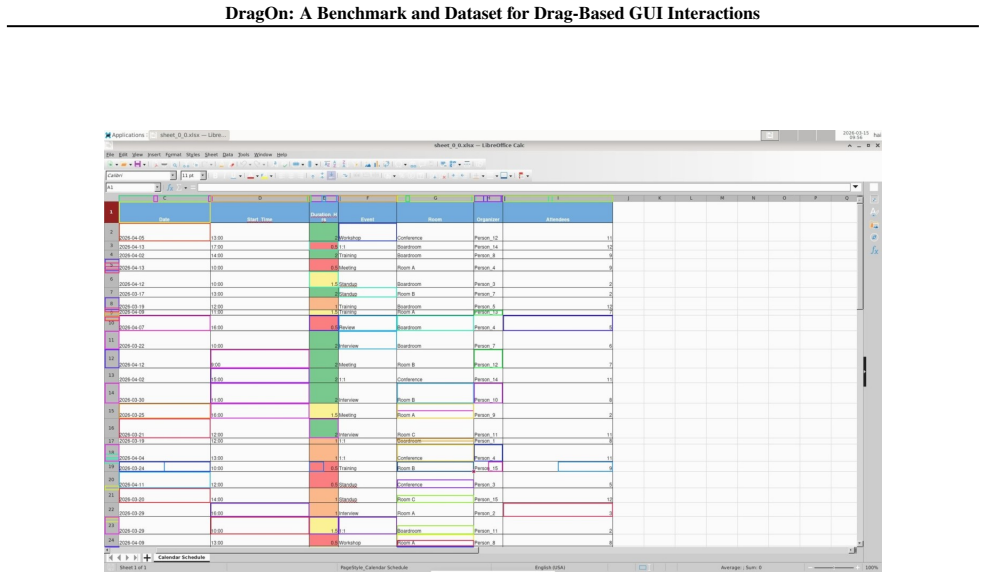
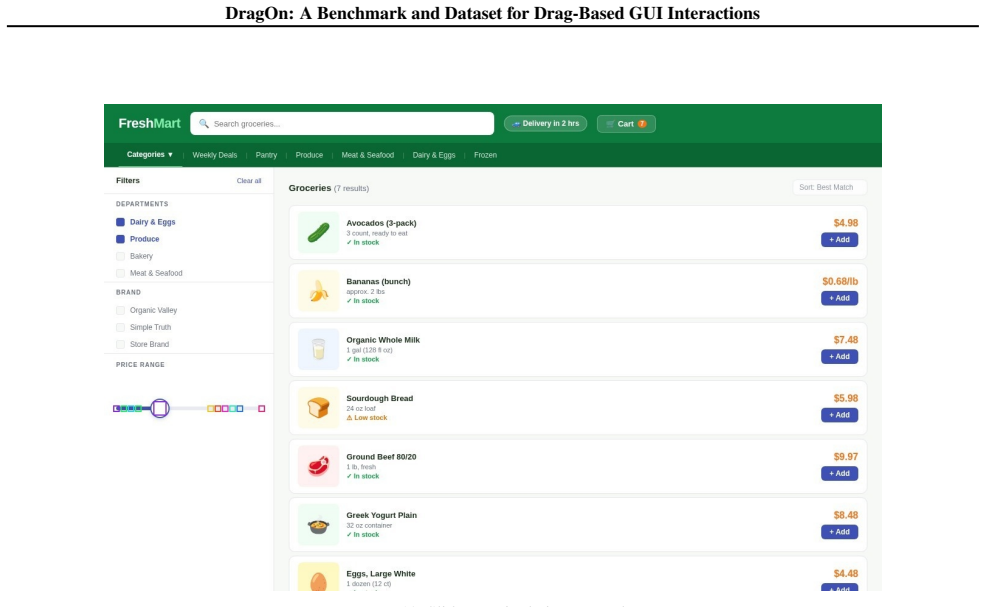
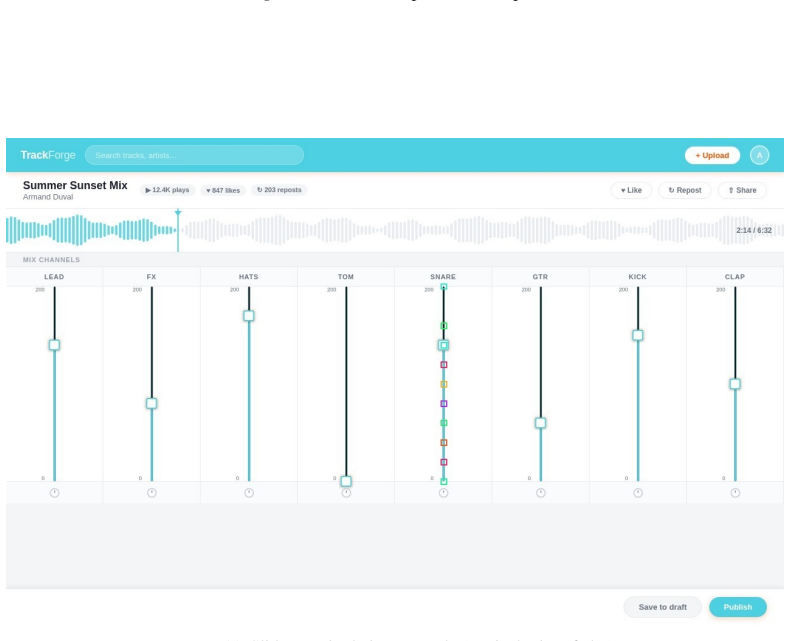
read the original abstract
GUI agents - vision-based models that control desktops, web browsers, and mobile devices through graphical user interfaces - promise to automate a wide range of digital tasks. While million-scale datasets have enabled substantial progress on click-grounding, drag grounding (e.g. drag-and-drop, swipe, highlight) data remains an order of magnitude smaller and current models fall short on complex drag-based interactions. We introduce DragOn, a drag grounding benchmark and training dataset covering four domains: text highlighting, cell selection, element resizing and slider manipulation. The dataset comprises 286K training screenshots and 3.5M training tasks, plus a 2000-example held-out evaluation suite. We evaluate proprietary (GPT, Claude) and open-weight (Qwen, Kimi, Holo) models, as well as a Qwen VLM fine-tuned on our training data. Results suggest that our dataset could improve performance of state-of-the-art models on downstream computer-use tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DragOn, a benchmark and dataset for drag-based GUI interactions covering four domains (text highlighting, cell selection, element resizing, slider manipulation). It provides 286K training screenshots and 3.5M training tasks plus a 2000-example held-out evaluation suite, evaluates proprietary and open-weight VLMs on the benchmark, and reports that fine-tuning Qwen on the training data yields gains; the authors suggest this dataset could improve state-of-the-art models on downstream computer-use tasks.
Significance. If the dataset construction, quality controls, and evaluation protocol are sound, DragOn would fill a documented gap in drag-grounding data (currently an order of magnitude smaller than click data) and supply a reproducible resource for training GUI agents on complex interactions.
minor comments (3)
- The abstract and experimental outline leave the precise task-generation process, quality-control steps, and domain sampling strategy unspecified; a dedicated section or appendix detailing these would strengthen reproducibility claims.
- The downstream-transfer claim is presented only as a suggestion; if the manuscript contains any measured transfer results on external computer-use benchmarks, they should be moved from the discussion into the results section with explicit metrics.
- Clarify whether the 2000-example held-out suite was drawn from the same four domains used for training data generation and whether any cross-domain or out-of-distribution splits were performed.
Simulated Author's Rebuttal
We thank the referee for their positive summary of DragOn and for recommending minor revision. The review correctly identifies the gap in drag-grounding resources relative to click data and the potential utility of the released dataset and benchmark. No major comments were raised that require point-by-point rebuttal.
Circularity Check
No circularity; dataset release with no derivations or self-referential predictions
full rationale
The paper releases a dataset (286K screenshots, 3.5M tasks) and a 2000-example held-out benchmark across four GUI domains, then reports model evaluations including one fine-tune. No equations, fitted parameters, uniqueness theorems, or predictions appear; the sole forward-looking statement is explicitly hedged as a suggestion rather than a derived claim. The contribution is empirical data release and benchmarking, self-contained against external model performance without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhou, Hanzhang and Zhang, Xu and Tong, Panrong and Zhang, Jianan and Chen, Liangyu and Kong, Quyu and Cai, Chenglin and Liu, Chen and Wang, Yue and Zhou, Jingren and Hoi, Steven , urldate =. doi:10.48550/arXiv.2512.22047 , shorttitle =. 2512.22047 [cs] , note =
-
[2]
doi:10.48550/arXiv.2406.11896 , shorttitle =
Bai, Hao and Zhou, Yifei and Cemri, Mert and Pan, Jiayi and Suhr, Alane and Levine, Sergey and Kumar, Aviral , urldate =. doi:10.48550/arXiv.2406.11896 , shorttitle =. 2406.11896 [cs] , keywords =
-
[3]
trycua/cua , rights =
-
[4]
Beyond Clicking: A Step Towards Generalist
Liao, Zeyi and Lu, Yadong and Gou, Boyu and Sun, Huan and Awadallah, Ahmed , urldate =. Beyond Clicking: A Step Towards Generalist. doi:10.48550/arXiv.2601.06031 , shorttitle =. 2601.06031 [cs] , keywords =
-
[5]
doi:10.48550/arXiv.2512.24965 , shorttitle =
Hu, Siyuan and Lin, Kevin Qinghong and Shou, Mike Zheng , urldate =. doi:10.48550/arXiv.2512.24965 , shorttitle =. 2512.24965 [cs] , keywords =
-
[6]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
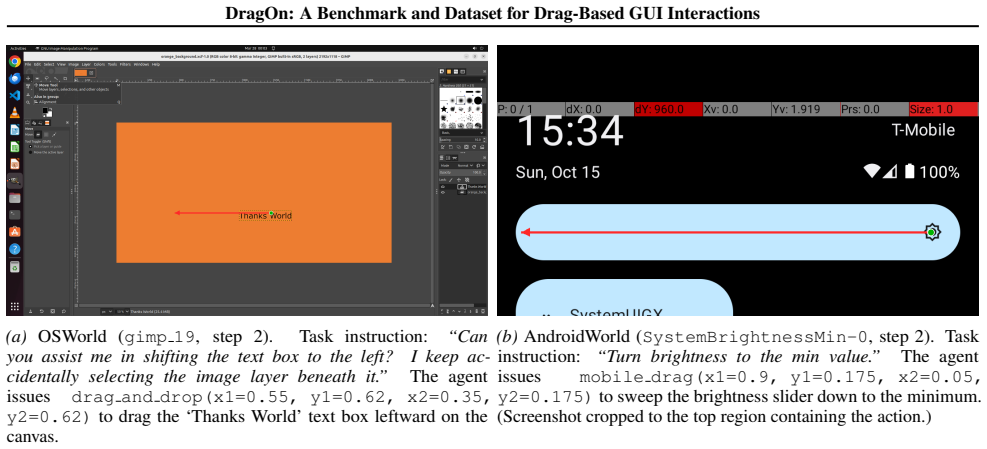
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and Liu, Yitao and Xu, Yiheng and Zhou, Shuyan and Savarese, Silvio and Xiong, Caiming and Zhong, Victor and Yu, Tao , urldate =. doi:10.48550/arXiv.2404.07972 , shorttitle =. 2404.07...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.07972
-
[7]
Surfer 2: The Next Generation of Cross-Platform Computer Use Agents , url =
Andreux, Mathieu and Bakler, Märt and Barbier, Yanael and Benchekroun, Hamza and Biré, Emilien and Bonnet, Antoine and Bordie, Riaz and Bout, Nathan and Brunel, Matthias and Cambray, Aleix and Cedoz, Pierre-Louis and Chassang, Antoine and Cloix, Gautier and Connelly, Ethan and Constantinou, Alexandra and Coster, Ramzi De and Jonquiere, Hubert de la and De...
-
[8]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
He, Hongliang and Yao, Wenlin and Ma, Kaixin and Yu, Wenhao and Dai, Yong and Zhang, Hongming and Lan, Zhenzhong and Yu, Dong , urldate =. doi:10.48550/arXiv.2401.13919 , shorttitle =. 2401.13919 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.13919
-
[9]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Rawles, Christopher and Clinckemaillie, Sarah and Chang, Yifan and Waltz, Jonathan and Lau, Gabrielle and Fair, Marybeth and Li, Alice and Bishop, William and Li, Wei and Campbell-Ajala, Folawiyo and Toyama, Daniel and Berry, Robert and Tyamagundlu, Divya and Lillicrap, Timothy and Riva, Oriana , urldate =. doi:10.48550/arXiv.2405.14573 , shorttitle =. 24...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.14573
-
[10]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Wang, Haoming and Zou, Haoyang and Song, Huatong and Feng, Jiazhan and Fang, Junjie and Lu, Junting and Liu, Longxiang and Luo, Qinyu and Liang, Shihao and Huang, Shijue and Zhong, Wanjun and Ye, Yining and Qin, Yujia and Xiong, Yuwen and Song, Yuxin and Wu, Zhiyong and Li, Aoyan and Li, Bo and Dun, Chen and Liu, Chong and Zan, Daoguang and Leng, Fuxing a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.02544
-
[11]
doi:10.48550/arXiv.2504.07981 , shorttitle =
Li, Kaixin and Meng, Ziyang and Lin, Hongzhan and Luo, Ziyang and Tian, Yuchen and Ma, Jing and Huang, Zhiyong and Chua, Tat-Seng , urldate =. doi:10.48550/arXiv.2504.07981 , shorttitle =. 2504.07981 [cs] , keywords =
-
[12]
SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents
Cheng, Kanzhi and Sun, Qiushi and Chu, Yougang and Xu, Fangzhi and Li, Yantao and Zhang, Jianbing and Wu, Zhiyong , urldate =. doi:10.48550/arXiv.2401.10935 , shorttitle =. 2401.10935 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.10935
-
[13]
Singh, Aaditya and Fry, Adam and Perelman, Adam and Tart, Adam and Ganesh, Adi and El-Kishky, Ahmed and. doi:10.48550/arXiv.2601.03267 , abstract =. 2601.03267 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.03267
-
[14]
Holo3 - Open Foundation Models for Navigation and Computer Use Agents , url =
-
[15]
Team, Kimi and Bai, Tongtong and Bai, Yifan and Bao, Yiping and Cai, S. H. and Cao, Yuan and Charles, Y. and Che, H. S. and Chen, Cheng and Chen, Guanduo and Chen, Huarong and Chen, Jia and Chen, Jiahao and Chen, Jianlong and Chen, Jun and Chen, Kefan and Chen, Liang and Chen, Ruijue and Chen, Xinhao and Chen, Yanru and Chen, Yanxu and Chen, Yicun and Che...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02276
-
[16]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
Qwen , date =. Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[17]
International Conference on Learning Representations (
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , date =. International Conference on Learning Representations (
-
[18]
Yang, Yuhao and Wang, Yue and Li, Dongxu and Luo, Ziyang and Chen, Bei and Huang, Chao and Li, Junnan , urldate =. Aria-. Findings of the Association for Computational Linguistics:. doi:10.18653/v1/2025.findings-acl.1152 , shorttitle =
-
[19]
doi:10.48550/arXiv.2506.03143 , shorttitle =
Wu, Qianhui and Cheng, Kanzhi and Yang, Rui and Zhang, Chaoyun and Yang, Jianwei and Jiang, Huiqiang and Mu, Jian and Peng, Baolin and Qiao, Bo and Tan, Reuben and Qin, Si and Liden, Lars and Lin, Qingwei and Zhang, Huan and Zhang, Tong and Zhang, Jianbing and Zhang, Dongmei and Gao, Jianfeng , urldate =. doi:10.48550/arXiv.2506.03143 , shorttitle =. 2506...
-
[20]
Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents
Gou, Boyu and Wang, Ruohan and Zheng, Boyuan and Xie, Yanan and Chang, Cheng and Shu, Yiheng and Sun, Huan and Su, Yu , urldate =. Navigating the Digital World as Humans Do: Universal Visual Grounding for. doi:10.48550/arXiv.2410.05243 , shorttitle =. 2410.05243 [cs] , note =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.05243
-
[21]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Wu, Zhiyong and Wu, Zhenyu and Xu, Fangzhi and Wang, Yian and Sun, Qiushi and Jia, Chengyou and Cheng, Kanzhi and Ding, Zichen and Chen, Liheng and Liang, Paul Pu and Qiao, Yu , urldate =. doi:10.48550/arXiv.2410.23218 , shorttitle =. 2410.23218 [cs] , note =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.23218
-
[22]
doi:10.5281/zenodo.14897662 , publisher =
Data Citation Corpus Data File , url =. doi:10.5281/zenodo.14897662 , publisher =
-
[23]
Adam: A Method for Stochastic Optimization
Kingma, Diederik P. and Ba, Jimmy , urldate =. Adam: A Method for Stochastic Optimization , url =. doi:10.48550/arXiv.1412.6980 , shorttitle =. 1412.6980 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980
-
[24]
Wikipedia Structured Contents , url =
Kaggle , urldate =. Wikipedia Structured Contents , url =
-
[25]
and Ehrenberg, Henry and Fries, Jason and Wu, Sen and R\'
Ratner, Alexander and Bach, Stephen H. and Ehrenberg, Henry and Fries, Jason and Wu, Sen and Ré, Christopher , date =. Snorkel: Rapid Training Data Creation with Weak Supervision , volume =. doi:10.14778/3157794.3157797 , shorttitle =
-
[26]
Domain randomization for transferring deep neural networks from simulation to the real world
Tobin, Josh and Fong, Rachel and Ray, Alex and Schneider, Jonas and Zaremba, Wojciech and Abbeel, Pieter , date =. Domain randomization for transferring deep neural networks from simulation to the real world , url =. doi:10.1109/IROS.2017.8202133 , booktitle =
-
[27]
Proceedings of the 28th International Conference on Computational Linguistics (
Li, Minghao and Xu, Yiheng and Cui, Lei and Huang, Shaohan and Wei, Furu and Li, Zhoujun and Zhou, Ming , date =. Proceedings of the 28th International Conference on Computational Linguistics (
-
[28]
European Conference on Computer Vision (
Kim, Geewook and Hong, Teakgyu and Yim, Moonbin and Nam, Jeongyeon and Park, Jinyoung and Yim, Jinyeong and Hwang, Wonseok and Yun, Sangdoo and Han, Dongyoon and Park, Seunghyun , date =. European Conference on Computer Vision (
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.